Использование нечетких нейросетевых алгоритмов в интеллектуальных системах обработки информации

Автор: Ковалев И.В., Энгель Е.А.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 3 (20), 2008 года.
Бесплатный доступ
Рассмотрены проблемы использования алгоритмов Fuzzy Neural Networks для обработки данных. Модифицированные алгоритмы Apriori и PredictiveApriori основаны на нечетких нейронных сетях (FNN). Рассмотрена система нечетких нейронных данных и результаты испытаний.
Короткий адрес: https://sciup.org/148177822
IDR: 148177822
Usage of algorithm of fuzzy neural networks at intellectual system of data processing
It is covered problems of usage Fuzzy Neural Networks algorithms for data processing. Modified Apriori and PredictiveApriori algorithms base on Fuzzy Neural Networks (FNN). The Fuzzy Neural Data Mining system and results of tests are considered.
Текст научной статьи Использование нечетких нейросетевых алгоритмов в интеллектуальных системах обработки информации
Введение. Одним из магистральных направлений развития информационных технологий является переход от обработки данных к обработке знаний, что требует наличия эффективных методов и средств выделения знаний. В настоящее время постоянно увеличивающаяся мощность средств вычислительной техники позволяет внедрять методы интеллектуальной обработки данных во все более широкие области. Этому способствует достигнутый в настоящее время уровень разработки теоретической и практической базы систем с искусственным интеллектом [1]. Важным направлением интеллектуализации обработки данных следует считать появление систем класса Data Mining, назначение которых состоит в автоматизации процессов поиска новых знаний при обработке больших баз данных.
Применение интеллектуализации в обработке данных позволяет использовать формальные модели знаний в условиях недостатка квалифицированных исполнителей и существенно повысить уровень обработки данных за счет использования новых моделей представления данных.
В настоящее время большинство программных продуктов, таких как SAS Enterprise Miner, PolyAnalyst, WEKA, в основу которых положены идеи Data Mining, ориентировано на использование в сфере бизнеса, однако средства интеллектуального анализа данных находят применение таких областях, как медицина, биология, физические исследования, телекоммуникационные системы.
Авторами было проведено исследование эффективности применения алгоритмов Data Mining, в частности нечетких нейросетевых алгоритмов ассоциации, для выделения различных участков телеметрической информации (ТМИ). Исходными данными являются множество телеметрических (ТМ) сигналов, снятых с реальных объектов. Требуется построить нейросетевые классификаторы на основе нечетких ассоциативных правил и оценить ошибку построенных классификаторов.
Особенности задачи анализа ТМИ. Типовой задачей анализа ТМИ является задача обработки быстроменяю-щихся параметров (БМП). Применение систем автоматического приобретения знаний в задаче обработке ТМИ открывает пути к созданию эффективных программных комплексов обработки ТМИ, использование которых возможно при минимальных затратах человеческих ресурсов.
Основные этапы анализа ТМИ с использованием технологии Data Mining представлены ниже (рис. 1). Процесс приобретения знаний основан на построении нечетких продукционных правил, описывающих особенности ТМИ-сигнала. На основе нечетких продукционных правил строятся нейросетевые классификаторы [2]. Примерами классов выделяемых событий могут являться временные участки соответствующие ударным вибрациям, вибрациям на переходных режимах, вибрациям на установившихся стационарных, квазистационарных режимах.
Процесс приобретения знаний состоит из нескольких этапов:
-
- предварительной обработки сигнала и получения векторного описания сигнала с использованием спект-
- рально-временного анализа Фурье и разложения сигнала по алгоритму вейвлет-пакета;
-
- кластер-анализа на основе полученных векторных описаний сигнала, решающего задачу автоматической сегментации ТМ-сигнала с целью выделения стандартных и нерегламентированных событий. Выделенные участки используются в качестве эталонов;
-
- получения описания знаний в виде нечетких продукционных правил с помощью алгоритмов «Деревья решений» и построения ассоциативных правил;
-
- реализации полученных правил для автоматического анализа ТМ-сигнала.
Одной из особенностей задач обработки БМП ТМИ является необходимость обработки очень больших массивов телеметрических данных. Следует отметить, что алгоритмы ассоциации хорошо зарекомендовали себя именно для обработки больших объемов данных. В отличие от классификаторов, построенных на основе деревьев решений, классификаторы, построенные на основе алгоритмов ассоциации, являются более точными. Однако эти классификаторы, как правило, не являются полными. Достоинством продукционных правил, построенных на основе алгоритмов ассоциации, является принципиальная (для понимания человеком) вычислительная простота, а основным недостатком - резкий (экспоненциальный) рост объема вычислений с увеличением числа параметров и фактически полное непринятие в расчет редко встречаемых параметров. Если формализовать продукционные правила нечеткими нейросетями, то указанные недостатки нивелируются. В результате получается гибридная система приобретения знаний на основе нечетких нейросетевых алгоритмов ассоциации.
Ассоциация используется для поиска групп характеристик, наблюдаемых большей частью одновременно. Анализ ассоциации имеет смысл в том случае, когда несколько характеристик связаны друг с другом. Модели, построенные на базе нейросетевых алгоритмов ассоциации, характеризуют близость различных одновременно наблюдаемых категориальных характеристик и могут быть выражены в виде нечетких правил.
Использование нечетких нейросетевых алгоритмов ассоциации для обработки ТМИ. Наиболее широко используемым и хорошо зарекомендовавшим себя алго ритмом в настоящее время является алгоритм Apriori [3], который используется во многих коммерческих и свободно распространяемых системах. Основным достоинством алгоритма Apriori, с точки зрения анализа данных является его гибкость. Эксперт имеет возможность задавать два основных параметра: минимальную поддержку и минимальную достоверность правила, что позволяет получать существенно различные группы правил.
Опыт решения практических задач обработки ТМИ показывает, что использование только алгоритма Apriori является недостаточным. На начальных этапах обработки данных в ряде случаев сложно задать значения параметров минимальной поддержки и минимальной достоверности. В этом случае удобно применять алгоритм PredictiveApriori [4], который осуществляет поиск наиболее точных правил. На вход алгоритма PredictiveApriori подается только число правил, которые следует найти.
Поскольку эти алгоритмы не предполагают наличия целевой переменной, авторами для решения задачи анализа БМП ТМИ предложена модификация данных алгоритмов. В частности, модифицирован этап генерации нейросетевых кандидатов и этап построения нечетких правил. На этапе генерации нейросетевых кандидатов рассматриваются только кандидаты, в состав которых входит целевая переменная. При построении нечетких правил строятся только правила, в левой части которых расположена целевая переменная.
Алгоритмы Apriori и PredictiveApriori можно описать следующим образом.
Модифицированный алгоритм Apriori:
F = {часто встречающиеся 1-элементные наборы} для (k = 2; Fk1 <> 0 ; k ++) {
Ck = Apriorigen(Fk1) // генерация наборов нейросетевых кандидатов, в состав которых входит целевая переменная для всех объектов Т {
Fk = { с е Ck | c.count >= minsupport} // отбор нейросетевых кандидатов для каждого/е Fk вызов RuleGen(f) // построение нечетких правил,
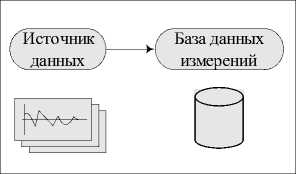
База данных результатов анализа

Результаты анализа

Анализ методами
Data Mining
Интерпретация
Визуализация
Дальнейший анализ
Рис. 1. Основные этапы анализа ТМИ
// в правой части которых расположена целевая переменная
Результат ^полученных правил}
Модифицированный алгоритм PredictiveApriori:
-
1. Пусть т = 1 (начальное значение минимальной поддержки).
-
2. For i = 1... kdo построить набор i-элементных ассоциативных правил [х ^ у]. Определить их достоверность. Пусть п i ( c ) -распределение достоверности правил.
-
3. Пусть для всех c
-
4. Пусть A ~ {0}, и пусть A} ~ {{aj, ...,{aj} - 1-элементные наборы.
-
5. For i = i...k- 1 While (i= 1 orA^O):
-
5.1. Ifi> 1 Then определить i-элементный набор нейросетевых кандидатов, в состав которых не входит целевая переменная.
-
5.2. Подсчитать поддержку сгенерированных нейросетевых наборов. Удалить изХ. наборы, поддержка которых меньше т .
-
5.3. Для всех x е X i вызвать процедуру RuleGen(x), которая осуществляет поиск наилучших нечетких правил с левой частью.^. В правой части располагается целевая переменная.
-
5.4. If best был изменен Then увеличить т так, чтобы оно принимало минимальное значение, при котором выполняется
-
-
5.5. Ifт увеличен на последнем шаге Then удалить изХ. наборы, у которых поддержка меньше, чем т .
-
6. Вывести best [1]... best [n], список из n наилучших нечетких правил ассоциации.
„ . ) = 2 k>. < = )( k Х2—1)
2 L< k )(2 ' -d '
E ( c 11, т) > E ( c ( best [ n ] | conf ( best [ n ]), s ( best [ n ])).
IfT > размер базы данных Then выход.
Использование описанных выше алгоритмов требует предварительного разбиения значений признаков на интервалы, т. е. преобразования количественных признаков в качественные [5]. Существующие системы таких преобразований, как правило, используют фильтр дискретизации [6]. Однако использование только фильтра дискретизации является недостаточным, поскольку в этом случае не учитываются следующие основные проблемы, возникающие при разбиении значений количественных признаков на интервалы:
-
- низкая поддержка. Если число интервалов, на которые производится разбиение значений признака велико (интервалы малы), то поддержка каждого отдельного интервала может оказаться ниже минимального порога и часть правил, содержащих признак, будет потеряна;
-
- низкая достоверность. Часть правил может получить достаточную поддержку, только если количественный признак имеет определенное значение или если интервал разбиения мал. С увеличением интервала разбиения увеличивается число теряемых правил.
Возникшие проблемы можно решить, если рассматривать все возможные интервалы разбиения количественного признака. В этом случае будут найдены наи меньшие возможные интервалы, которые имеют достаточную поддержку. Однако при этом возникают другие проблемы:
-
- время выполнения. Пусть количественный признак принимает n значений, тогда необходимо рассмотреть ~O(n2) интервалов;
-
- ненужные правила. Если значение количественного признака имеет достаточную поддержку то достаточную поддержку будут иметь все интервалы, которые включают это значение, и, следовательно, увеличится число неинтересных правил.
Описанные выше проблемы особенно остро встают при анализе ТМИ, поскольку там речь идет о работе с большим объемом количественных данных.
Использование нечетких нейросетей помогает найти решение, которое позволит за приемлемое время найти ассоциативные правила и потеря информации при этом будет минимальной. Также следует учитывать, что в ряде случаев эксперт имеет априорную информацию о ТМ-сигнале. Эта информация может быть получена в том числе и при помощи простейших средств визуализации.
Имеющийся опыт решения реальных задач анализа ТМИ показывает, что целесообразно использовать следующий набор фильтров:
-
- ручной фильтр;
-
- фильтр на основе расчета энтропии [6];
-
- равномерное разбиение значений количественных характеристик;
-
- разбиение на равные интервалы значений количественных характеристик.
Система анализа ТМИ на базе нечетких нейросетевых алгоритмов. Для описания процесса выделения основных событий, содержащихся в записях ТМИ, была разработана нечеткая нейросетевая система Data Mining (рис. 2). В этой системе реализован процесс приобретения знаний, основанный на построении нечетких продукционных правил, описывающих особенности ТМ-сигнала.
Данные, поступающие на вход системы, располагаются в таблицах базы данных и представляют собой ТМ-сигналы.
Подсистема предварительной обработки предназначена для получения векторного описания ТМ-сигнала с использованием спектрально-временного анализа Фурье [7] и разложения сигнала по алгоритму вейвлет-пакета [8].
Подсистема кластер-анализа решает задачу автоматической сегментации ТМ-сигнала с целью выделения стандартных и нерегламентированных событий. В подсистеме кластер-анализа реализованы следующие алгоритмы:
-
- алгоритм расширяющегося нейронного газа;
-
- алгоритм максимизации ожидания (ЕМ) [9].
В подсистеме построения деревьев решений используются следующие алгоритмы:
-
- алгоритм построения деревьев решений С4.5 [10];
-
- алгоритм построения деревьев решений CART [11].
В подсистеме ассоциации применяются следующие алгоритмы:
-
- модифицированный алгоритм построения ассоциативных правил на основе нечетких нейросетей Apriori;
-
- модифицированный алгоритм построения ассоциативных правил на основе нечетких нейросетей PredictiveApriori.
В результате работы алгоритмов построения деревьев решений и алгоритмов нечетких нейросетей получается описание событий в ТМ-сигнале в виде следующих нечетких правил:
Если
(компонента AS1 лежит в интервале 1) и (компонента AS2 лежит в интервале 2)
-
и , (компонента ASi лежит в интервале i);
То класс сегмента = значение класса.
Под компонентами ASi понимаются компоненты векторного описания сегментов сигнала.
Записанные в таком виде правила создают нечеткую базу знаний, описывающую различные события в телеметрическом сигнале.
Описание проведенных экспериментов. С помощью разработанной авторами системы был проведен ряд экспериментов с реальными сигналами, поступающими от различных датчиков. Сигналы подавались на вход системы после предварительной обработки (применялось преобразование Фурье, число сглаженных спектральных коэффициентов Фурье -16). Классы событий определялись по результатам кластер-анализа: класс 1 - переходный процесс; класс 2 - ударный процесс; класс 3 - установившиеся вибрации; класс 4 - остальные участки сигнала. Исследование было проведено на десяти различных сигналах. Ошибки построенных нейросетевых классификаторов находятся в диапазоне 2...10 %.
Анализ результатов применения нечетких нейросетевых алгоритмов ассоциации для обработки ТМИ. Анализ проведенных экспериментов показал, что основная причина возникновения ошибок нейросетевого классификатора на основе нечетких ассоциативных правил состоит в неполноте построенного нейросетевого классификатора, что является прямым следствием маленького объема выборки.
Возможны следующие решения возникшей проблемы: - увеличение объема обучающей выборки;
-
- увеличение числа правил за счет добавления правил с низким значением параметра поддержки (сильные правила), однако это может привести к тому, что полученный набор нечетких правил будет сложно анализировать и увеличится время работы классификатора.
Проведенные авторами исследования показали, что нейросетевые классификаторы на основе нечетких ассоциативных правил являются высокоэффективными, если обучающая выборка обладает следующими свойствами:
-
- выборка имеет большой объем (порядка нескольких сотен векторов);
-
- в состав наименьшего из классов, полученных в результате кластер-анализа, входит не менее 10% векторов от общего числа векторов обучающей выборки.
Полученные результаты показывают работоспособность разработанной системы и подтверждают эффективность использования алгоритмов Data Mining. Применение этих алгоритмов позволяет повысить уровень достоверности результатов обработки данных телеметрии и приводит к повышению эффективности работы специалистов по анализу ТМИ.
