Использование векторных методов представления слов в задачах выявления трендов

Автор: Башков Александр Сергеевич, Соломенцев Ярослав Кириллович
Рубрика: Управление сложными системами
Статья в выпуске: 2, 2019 года.
Бесплатный доступ
В данной статье описываются методы обработки текстов естественного языка на основе нейронных сетей. Обрабатываются научные статьи для выявления тенденций развития научных направлений. Приводятся примеры разбора текста посредством морфологического анализатора Pullenti. В статье анализируется метод word2vec, основанный на нейронных сетях, описывается применение алгоритма этого метода Skip-gram. В заключении приводятся результаты использования метода word2vec для построения трендов развития научных направлений.
Интеллектуальный анализ данных, приоритетные направления, прогнозирование, нейронные сети, векторное представление слов
Короткий адрес: https://sciup.org/148309535
IDR: 148309535 | УДК: 004.8 | DOI: 10.25586/RNU.V9187.19.02.P.080
Vector word representation methods in trend detection tasks
Keywords: data mining, priority directions, prediction, neural networks, vector word representation
Текст научной статьи Использование векторных методов представления слов в задачах выявления трендов
Выявление тенденций (трендов) в научном прогрессе является важной задачей: она решается международными организациями, государствами, научными учреждениями и крупным бизнесом. Определение трендов важно для построения прогнозов, на основе которых принимаются решения о дальнейшем развитии государства, общества, компании, выделяются финансовые и другие ресурсы [4].
Башков А.С., Соломенцев Я.К. Использование векторных методов представления... 81
В научной среде все значимые результаты исследований и информацию об открытиях принято в первую очередь публиковать в рецензируемых научных журналах. Затем происходит обсуждение опубликованных результатов, выходят публикации в средствах массовой информации. Поэтому мониторинг трендов в науке целесообразно проводить путем анализа опубликованных научных статей как первоисточника новых знаний.
С учетом растущего объема научных публикаций (рис. 1) задача по их мониторингу усложняется и требует применения методов автоматизированного анализа.
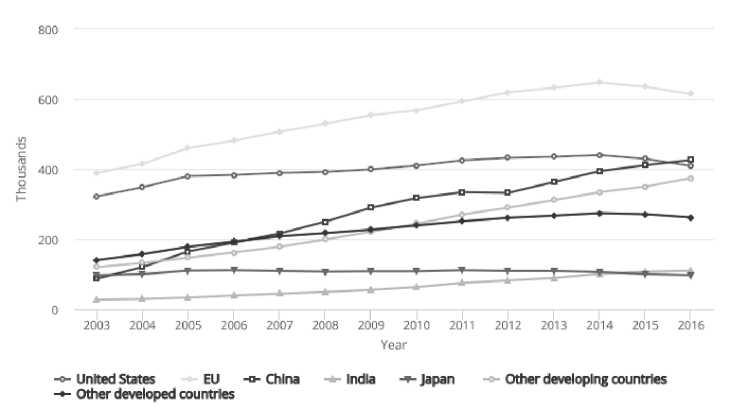
Рис. 1. Количество научных статей по отдельным странам в 2003–2016 гг.
(данные Национального совета по науке США) [8]
В 2018 г. в базе данных Web of Science зарегистрировано 1,62 млн научных статей [7]. Это число на 5% выше, чем в 2017 г., и является самым высоким за всю историю.
В базе данных Scopus содержится 83 тыс. статей российских ученых за 2017 г., Россия занимает 12-е место по количеству статей после США, Китая, Индии, Японии, Канады, Австралии и ряда европейских стран [10].
Машинная обработка текста
При машинной обработке текста необходимо закодировать текст в том виде, который может обрабатываться компьютером. Самый простой способ – пронумеровать все имеющиеся слова номерами по порядку. Но в этом случае номер слова не связан с его значением. Допустим, что слова в словаре следуют по алфавиту. Тогда близкие номера будут у слов, имеющих одинаковые буквы в начале слова. Чтобы получить модель, отражающую семантическую близость слов, необходимо сопоставить со словом вектор, который отображал бы его в пространстве по смыслу.
Возьмем вектор размерностью, равной количеству слов в словаре, и закодируем каждое слово проставлением единицы в одной позиции, соответствующей порядковому номеру слова в словаре. Такое представление называется one-hot encoding – OHE. Векторы в таком пространстве не отражают смысловой близости слов [11].
82 в ыпуск 2/2019
Смысл слова может определяться его контекстом, т.е. словами, стоящими с ним рядом. Приведем пример из задания «Вставьте в предложения пропущенные слова» учебника для начальных классов:
По ________мчатся машины.
Ученики ждали учителя у дверей ________.
В указанных примерах можно вставить различные слова, например: «дороге», «шоссе», «улице» и «класса», «школы», «автобуса». В первом примере все слова близки по смыслу, во втором – более далекие. Таким образом, использование контекста задает с некоторой вероятностью смысл слова, а в случае большого набора контекстов такие вероятности можно рассчитать достаточно точно.
Существуют различные методы задания векторного представления слов. Также используются представления в виде «слово-документ», которые порождают терм-документную матрицу для корпуса текстов.
До появления нейронных сетей для анализа близости слов составляли матрицы частотности каждого слова. В такой матрице по горизонтали и по вертикали были отложены слова, а в ячейках указывалась частота появления слова в указанной строке со словом, указанным в столбце.
Для реализации указанного подхода потребуется построить матрицу встречаемости слов, размерность которой будет равна N × N , где N – количество слов в языке. Расчет такой матрицы – слишком сложная вычислительная операция, поэтому были найдены другие методы, которые позволяют анализировать контекст [1].
Метод word2vec
В основе методов word2vec лежит предположение о том, что необходимо учитывать только наиболее близкий к слову контекст, т.е. не далее чем на 2–5 слов по тексту. Это предположение существенно упрощает задачу анализа контекста в текстах больших объемов.
Вначале word2vec необходимо обучить на определенном корпусе текстов. При обучении по корпусу текстов проходит скользящее окно задаваемого размера, в рамках которого и учитывается контекст. Для слов рассчитывается их векторное представление. При этом слова, встречающиеся в тексте близко, будут иметь близкие векторы (по косинусной мере) [9].
Полученная модель в дальнейшем используется для решения двух типов задач:
-
1. На вход задаем контекст (несколько слов), на выходе получаем наиболее подходящее слово в контексте (CBOW).
-
2. На вход задаем одно слово, на выходе получаем возможный контекст к этому слову (Skip-gram).
Алгоритм Skip-gram может использоваться в задачах по выявлению трендов, поэтому рассмотрим его реализацию подробнее.
Особенностью использования метода word2vec на русскоязычных текстах является необходимость нормализации слов (приведения всех форм слова к одной). Такая задача не возникает в случае работы с текстом на английском языке. Кроме того, перед обучением необходимо исключить из текста стоп-слова, не несущие смысла. Обе эти задачи могут быть решены с использованием открытого программного решения Pullenti.
Башков А.С., Соломенцев Я.К. Использование векторных методов представления... 83
Предобработка русскоязычного текста с помощью Pullenti
Программа Pullenti позволяет:
-
• разбивать текст на слова;
-
• производить морфологический анализ: определять все возможные части речи слова (независимо от контекста), нормализовать слова к единому падежу, роду, числу;
-
• выделять именованные сущности;
-
• производить ряд функций с числовыми, именными и глагольными группами, скобками, кавычками [2].
Приведем пример использования Pullenti через Python (Jupyter Notebook). Нижеприведенная программа выделяет именные группы из произвольного текста.
Пример текста: «Масштабный железнодорожный проект столичных властей заработает уже в 2019 году, заявил заммэра. Движение по первым центральным диаметрам запустят “в ускоренном режиме”. Прежде ввести их в эксплуатацию планировалось в конце 2018-го года».
В результате Pullenti выделила и привела к нормальной форме следующие именованные группы:
МАСШТАБНЫЙ ЖЕЛЕЗНОДОРОЖНЫЙ ПРОЕКТ
ЖЕЛЕЗНОДОРОЖНЫЙ ПРОЕКТ
ПРОЕКТ
СТОЛИЧНАЯ ВЛАСТЬ
ВЛАСТЬ
УЖ
ГОД
ДВИЖЕНИЕ
ЦЕНТРАЛЬНЫЙ ДИАМЕТР
ДИАМЕТР
УСКОРЕННЫЙ РЕЖИМ
РЕЖИМ
ЭКСПЛУАТАЦИЯ
КОНЕЦ
2018 ГОД
ГОД
Как видно из приведенного списка именованных групп, алгоритм включил слово «уже» в этот список, поскольку слово «уже» может принимать именованную группу от слова «уж». Pullenti не включает в себя функции определения контекста, поэтому в результате возможны такие погрешности.
Применение алгоритма Skip-gram
Рассмотрим простейший случай алгоритма Skip-gram, когда нужно предсказать одно соседнее слово, если дано одно слово. Далее можно распространить этот случай на несколько слов.
Для обучения нейронной сети на вход нужно подавать пары слов. Для этого нужно выбрать размер окна, пройтись окном по предложению и перебрать все пары слов в данном окне. Если выбрать окно, равное одному, то окно будет содержать одно слово слева
Выпуск 2/2019
от целевого и одно слово справа от целевого. В случае если окно было бы равным двум, то слева и справа от целевого слова было бы по два слова. Ниже приведен пример для окна, равного двум:
Старый
заброшенный дом
стоит на опушке леса
Тренировочные фразы :
(Старый, дом)
(Старый, заброшенный),
Тренировочные фразы : (заброшенный, Старый), (заброшенный, дом), (заброшенный, стоит)
Тренировочные фразы : (дом, Старый), (дом, заброшенный), (дом, стоит), (дом, на)
Старый заброшенный дом
стоит
на опушке леса
Тренировочные фразы : (стоит, заброшенный), (стоит, дом), (стоит, на), (стоит, опушке)
Нейронная сеть обучится статистике частоты появления каждой пары слов [12].
Каждое слово нужно преобразовать в цифровой вид. Представим его в виде one-hot encoding:
x =
Здесь наше слово, которое мы представляем в виде вектора, занимает второе место в словаре.
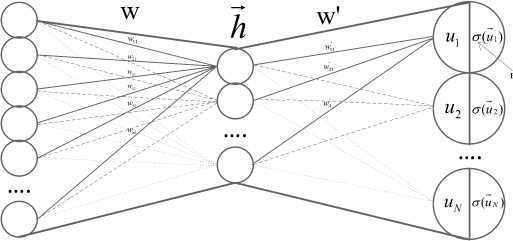
Преобразования при помощи нейронной сети представлены на рисунке 2.
x
y
w
w
h
σ ( u 1 )
w 1 '
σ ( u 2 )
u 2
w 2'1
uN u1
wi '1
w 1
w 21
w 31
w 41
w 5
Функция включения softmax
Рис. 2. Принципиальная схема нейронной сети
Башков А.С., Соломенцев Я.К. Использование векторных методов представления... 85
Здесь x – входное слово (или несколько слов), по которому (которым) мы хотим предсказать y – слово (или несколько слов);
H (скрытый слой нейронной сети) – вектор, получаемый при умножении вектора-слова x на матрицу весовых коэффициентов w :
h= wT x, где w – матрица, содержащая весовые коэффициенты, она имеет размерность: (длина словаря) × (количество признаков). Количество признаков задается один раз перед запуском нейронной сети, оно подбирается для получения лучшего результата. Например, Google использовал 300 признаков для обучения нейронной сети на множестве данных новостей Google. Весовые коэффициенты в начальный момент времени принимают случайные значения, далее они корректируются в соответствии с методом обратного распространения ошибки [5].
После скрытого слоя h c учетом другой матрицы весовых коэффициентов w’ образует- ся вектор u:
u = w ' T h = w ' T wT x .
Размерность вектора u совпадает с размерностью вектора x .
>
Чтобы нормализовать выходной вектор у в диапазоне [0; 1], применим функцию soft-max (используем в качестве функции активации, см. с ( U i ) на рис. 2):
e ui
У i = ^ ( u) = nn ----,
Z eu
k=i где N – количество признаков.
В результате получим, что yi – вероятность наблюдения (предсказания) i -го слова (или фразы) в словаре при входящем слове (контексте) x .
Целью нейронной сети (см. рис. 2) является определение весовых коэффициентов w и w’ . Критерием схождения вычислений выступает максимизация вероятности y при всех возможных выходных словах (фразах) . В результате математических преобразований (взятие логарифма вероятности y , далее вычисление производной логарифма вероятности y по переменной w ’ ) получится уравнение, у которого невозможно найти оптимум. Поэтому придется воспользоваться численными методами.
Одним из лучших численных методов является метод градиентного спуска. В результате получится, что нужно решить рекурсивную задачу:
new old w' ^ w'- G (w (1 - y)), где G – функция градиентного спуска [6].
Таким образом, если вероятность для перебираемого выходного слова максимальна, new old то скобка близка к нулю и w'← w'. В ином случае, когда вероятность выхода слова очень мала, то от w’ отнимается доля значений w. Таким образом, матрица w’ приближается к матрице w.
Аналогичным образом можно приблизить w к w ’ : new old w ^ w - G ( w ' (1 - y )) .
86 в ыпуск 2/2019
Но описанный метод не применяется на практике, поскольку вычисление функции softmax затратно по продолжительности. Поэтому в алгоритме используется поправка «Negative Sampling» (отрицательная выборка).
Пример работы алгоритма
Алгоритм был запущен на корпусе статей по медицинской тематике.
В исходных текстах было всего 218 137 слов.
После обработки Pullenti стало 165 590 слов.
После обработки модулем word2vec корпуса текстов после проведения обучения получились следующие контексты к ключевым словам:
ключевое слово «лечение» – контекст: [(‘медикаментозное’, 3.296358e-05), (‘головной’, 3.296348e-05), (‘лечение’, 3.2963446e-05), (‘хирургическое’, 3.2963435e-05), (‘проводится’, 3.296343e-05), (‘нарушений’, 3.2963384e-05), (‘местное’, 3.2963366e-05), (‘методами’, 3.2963337e-05), (‘головные’, 3.2963333e-05), (‘комплексное’, 3.2963275e-05)];
ключевое слово «профилактика» – контекст: стаканом, трава, настоять, головные, клиническая, процедить, течение, путей, перечной, можно;
ключевое слово «синдром» – контекст: болевой, нефротический, раствора, заболеваниях, смеси, кипятка, кровообращения, быть, использовать, воды.
Использование word2vec в задаче выявления трендов
Рассмотрим использование описанного выше метода Skip-gram для выявления трендов в статьях по мединской тематитике.
Выявление трендов состоит в необходимости анализа изменений, происходящих с корпусом статей по медицинской тематике с течением времени. Для этого необходимо выбрать временной интервал t , на котором будет проводиться анализ. Репрезентативные результаты на выборке статей даст применение метода при анализе корпуса статей не менее чем за один год. Можно разбить корпусы статей при t = 3 или t = 5 лет, для того чтобы изменения в тематиках статей были более заметными. Таким образом, при принятии промежутка t = 5 лет будут анализироваться следующие корпусы статей: с 31.12.2018 по 01.01.2014, с 31.12.2013 по 01.01.2009 и т.д.
Все статьи на исследуемом промежутке объединяются в один корпус, на нем производится обучение word2vec. После проведения обучения при помощи алгоритма Skip-gram устанавливаем контекст по ключевым для предметной области словам. Например, для слов: «лечение», «болезнь», «синдром», «диагностика», «профилактика», «рак».
Аналогичная операция выполняется для корпусов текстов других временных интервалов. При этом для каждого из них важно заново обучить word2vec.
Сравнение полученных слов, контекстных со словами-триггерами, в разные временные промежутки с учетом веса их встречаемости позволит отследить изменение трендов в исследованиях.
Заключение
Векторные методы анализа текстов могут успешно применяться в задачах выявления трендов. В качестве объекта исследований выбираются корпусы научных статей по ка-
Башков А.С., Соломенцев Я.К. Использование векторных методов представления... 87
кой-либо определенной тематике, разбитые на репрезентативные временные интервалы (от года до пяти лет).
Программа Pullenti позволяет провести нормализацию текста для анализа без учета окончаний слов. При этом она не учитывает контекст слова при его нормализации, из-за чего в редких случаях может обрабатывать слова некорректно. Однако на больших корпусах текстов такие погрешности не должны влиять на конечный результат.
Алгоритм Skip-gram word2vec позволяет найти контекст к ключевым словам в тематике, которые являются ключевыми для определения трендов. Недостаток этого подхода заключается в необходимости задавать ключевые слова самостоятельно, в результате чего возникает возможность упустить из анализа тренды, не связанные с ключевыми словами.
Список литературы Использование векторных методов представления слов в задачах выявления трендов
- Золотарев О.В., Шарнин М.М., Еромасова А., Тезадова Ф.М. Современные подходы к обработке многоязычных текстов, основанные на методах дистрибутивной семантики//Сборник трудов международной научной конференции по физико-технической информатике -CPT2018 (Пущино, 28-31 мая 2018 г.). Протвино, 2018. С. 43-47.
- Золотарев О.В., Шарнин М.М., Клименко С.В., Кузнецов К.И. Система PullEnti -извлечение информации из текстов естественного языка и автоматизированное построение информационных систем//Ситуационные центры и информационно-аналитические системы класса 4i для задач мониторинга и безопасности -SCVRT2015-16: сб. тр. Междунар. конф. (Пущино, 21-24 нояб. 2016 г.): в 2 т. Протвино, 2016. Т. 2. С. 28-35.
- Золотарев О.В., Шарнин М.М., Клименко С.В., Мацкевич А.Г. Исследование методов автоматического формирования ассоциативно-иерархического портрета предметной области//Вестник Российского нового университета. Серия «Сложные системы: модели, анализ и управление». 2018. № 1. С. 91-96.
- Микова Н., Соколова А. Мониторинг глобальных технологических трендов: теоретические основы и лучшие практики//ФОРСАЙТ. 2014. Т. 8. № 4.
- Ali Ghodsi, Lec 13: Word2Vec Skip-Gram. URL: https://www.youtube.com/watch?v=GMCwS7tS5ZM/
