Исследование и сравнительный анализ алгоритмов машинного обучения для определения их эффективности в задаче классификации деменции

Автор: А. П. Пашковская
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (1), 2025 года.
Бесплатный доступ
В данной работе проведено исследование и сравнительный анализ алгоритмов машинного обучения для классификации деменции у пожилых пациентов. Актуальность темы обусловлена значительным увеличением случаев деменции и важностью своевременной диагностики для улучшения качества жизни. Основная цель исследования заключается в определении эффективности различных методов классификации, применяемых к широкому набору медицинских данных о пациентах в возрасте от 60 до 90 лет, включая демографические и клинические характеристики, а также результаты когнитивных тестов. Работа охватывает этапы предобработки данных, применение различных машинных алгоритмов и их последующий анализ. Рассматриваемые методы включают деревья решений, случайные леса, метод K-ближайших соседей, логистическую регрессию и градиентный бустинг. Кроме того, исследование подчеркивает значимость интерпретируемости моделей и возможные ограничения, связанные с выборкой данных. Результаты работы свидетельствуют о том, что методы машинного обучения могут существенно улучшить диагностику деменции, что открывает новые перспективы для раннего вмешательства и оптимизации ресурсов в системе здравоохранения. Работа предоставляет полезные рекомендации для дальнейших исследований в данной области, а также подчеркивает важность интеграции новых технологий в практическую медицину.
Машинное обучение, алгоритмы, классификация, анализ данных, медицинская диагностика, деменция
Короткий адрес: https://sciup.org/14133007
IDR: 14133007 | УДК: 004.8:616.89 | DOI: 10.47813/2782-2818-2025-5-1-1041-1047
Текст статьи Исследование и сравнительный анализ алгоритмов машинного обучения для определения их эффективности в задаче классификации деменции
DOI:
Машинное обучение это метод анализа данных, который автоматизирует построение аналитической модели [1]. В последние годы машинное обучение и методы анализа данных становятся важнейшими инструментами в решении задач, возникающих в различных областях науки и практики. Проектами машинного обучения, лежащими в основе многих инновационных технологий искусственного интеллекта, пронизаны почти все сферы экономики и общества [2]. В медицине они могут помочь в диагностике и лечении различных заболеваний [3]. Классические алгоритмы машинного обучения представляют собой набор статистических методов, позволяющих моделировать зависимости между переменными, выявлять паттерны в данных и осуществлять прогнозирование. Эти методы основываются на математических принципах и статистических теориях, что делает их надежными инструментами для анализа больших объемов информации.
Классические методы машинного обучения включают, но не ограничиваются, такими алгоритмами, как линейная регрессия, логистическая регрессия, деревья решений, метод опорных векторов (SVM), k-ближайших соседей (k-NN) и т. д. Эти алгоритмы продемонстрировали высокую эффективность в задачах классификации и прогнозирования, особенно при обработке больших объемов данных. Их способность выявлять сложные паттерны и скрытые взаимосвязи делает их незаменимыми в условиях, когда традиционные аналитические методы оказываются недостаточными.
Деменция, являющаяся комплексным симптомом множества расстройств, существенно влияет на качество жизни пациентов и является распространенной причиной снижения когнитивных способностей у пожилых людей [4]. По данным Всемирной организации здравоохранения, ежегодно регистрируется около 10 миллионов новых случаев деменции, что делает её одной из ведущих причин смертности. Классификация типов и стадий деменции представляет собой важную задачу, поскольку своевременная и точная диагностика может значительно улучшить прогнозы и повысить качество жизни пациентов.
Основная цель данной работы заключается в исследовании и сравнительном анализе различных алгоритмов машинного обучения для определения их эффективности в задаче классификации деменции. Выявление наиболее подходящих методов позволит обеспечить высокую точность и надежность диагностики в этой критически важной области.
МАТЕРИАЛЫ И МЕТОДЫ
Для данного исследования был выбран датасет, посвященный болезни Альцгеймера, который содержит обширные медицинские данные о пациентах в возрасте от 60 до 90 лет. Датасет охватывает широкий спектр информации о состоянии здоровья пациентов, включая демографические характеристики, факторы образа жизни и результаты клинических исследований [5]. Кроме того, в нем представлены оценки когнитивных и функциональных способностей.
Важным аспектом работы с такими комплексными данными является предобработка, которая является неотъемлемым и критически важным этапом в процессе анализа и разработки моделей машинного обучения.
Первоначальным шагом в обработке данных стало выявление и устранение пропущенных значений. Для числовых признаков применялись методы заполнения пропусков средними значениями или медианами. Данный подход позволяет сохранить общую структуру данных, минимизируя искажения. Для категориальных переменных использовалась мода, что представляется целесообразным способом восстановления наиболее распространенных значений.
Следующий этап заключался в нормализации и стандартизации данных. В исследовании применялись методы MinMaxScaler и StandardScaler для приведения всех признаков к единому масштабу. Это имеет особое значение, поскольку многие алгоритмы машинного обучения чувствительны к масштабам входных данных.
Завершающим этапом предобработки данных стало разделение на обучающую и тестовую выборки. С использованием метода train_test_split данные были разделены на две части, что позволило эффективно оценить производительность модели на незнакомом наборе данных. Этот подход не только предотвращает переобучение, но и обеспечивает возможность проверки того, как хорошо алгоритм работает на реальных данных.
После завершения этапа предобработки данных исследование переходит к следующему важному шагу — применению различных алгоритмов машинного обучения. В данной работе рассматриваются несколько методов, каждый из которых обладает уникальными характеристиками и преимуществами:
-
• Деревья решений — простой и интерпретируемый метод, представляющий модель в виде дерева. Подходит для классификации и регрессии, но подвержен переобучению. Деревья можно
визуализировать [6];
-
• Случайные леса — ансамблевый метод, объединяющий множество деревьев решений для повышения точности и устойчивости к переобучению. Эффективен для больших наборов данных;
-
• Метод K-ближайших соседей (KNN) —
классифицирует объекты по близости к соседям в пространстве признаков. Прост в использовании, но чувствителен к размерности данных;
-
• Логистическая регрессия — используется для бинарной классификации, оценивает
вероятность принадлежности к классу с помощью сигмоидной функции. Легко интерпретируется;
-
• Градиентный бустинг — ансамблевый метод, комбинирующий несколько моделей для достижения высокой точности. Эффективен для сложных зависимостей;
-
• Метод опорных векторов (SVM) — находит оптимальные границы между классами в данных. Универсален благодаря возможности использования различных ядер.
В рамках исследования было уделено значительное внимание настройке гиперпараметров, так как они окажут существенное влияние на производительность моделей. Для реализации использованных моделей был разработан словарь с гиперпараметрами.
param_grids ={
'Decision Tree': {'max_depth': [3,
-
5, 7, 12, 15, 20, None]},
'Random Forest': {'n_estimators':
[10, 25, 50, 100, 150, 200,300],
'max_depth':[3,
-
5, 7, 12, 15, 20, None]},
'K-Nearest Neighbors': {'n_neighbors': [3, 5, 7,10]},
'Logistic Regression': {'C':[0.1,
-
1,10]},
'Support Vector Machine': {'C': [0.1, 1,10],
'gamma': [0.1, 1,'scale', 'auto']}, 'XGBoost': {'n_estimators': [10,
-
25, 50, 100, 150, 200,300],
0.1,1],
'learning_rate': [0.01,
'max_depth': [3, 5,7,
-
12, 15, 20]},
'CatBoost': {'iterations': [10,25,
-
50, 100, 150, 200, 250, 300],
'learning_rate':
[0.01, 0.1,1]}
}
Листинг 1. Словарь с гиперпараметрами для МОДЕЛЕЙ.
Listing 1. Dictionary of hyperparameters for models.
Для деревьев решений ключевым гиперпараметром является max_depth, который определяет максимальную глубину дерева и помогает контролировать переобучение.
Параметр min_samples_split задает минимальное количество образцов, необходимое для разделения узла, что также значительно влияет на общий размер дерева.
В случае случайных лесов важным аспектом является n_estimators, отвечающий за количество деревьев в лесу; увеличение этого числа может улучшить точность, однако ведет к росту вычислительных затрат. Параметр max_features, в свою очередь, определяет количество признаков, которые рассматриваются для наиболее оптимального разбиения, позволяя контролировать разнообразие деревьев.
При использовании алгоритма K-ближайших соседей важнейшим гиперпараметром является n_neighbors, который устанавливает количество ближайших соседей для применения в процессе классификации; его значение критически важно, поскольку слишком большое или маленькое число соседей может привести к снижению точности модели.
В логистической регрессии основное внимание уделяется коэффициенту регуляризации C; его значение влияет на степень регуляризации модели, причём низкие значения C подразумевают сильную регуляризацию.
Что касается моделей градиентного бустинга, таких как XGBoost и CatBoost, важными гиперпараметрами являются learning_rate, который задаёт скорость обучения и определяет, насколько сильно каждое дерево влияет на финальное предсказание, и max_depth, аналогичный по функции параметру деревьев решений, который помогает контролировать сложность модели. Параметр n_estimators также используется для определения количества деревьев в ансамбле.
Настройка всех этих гиперпараметров проводилась с использованием метода кроссвалидации на основе GridSearchCV, что позволяет находить наиболее подходящие комбинации гиперпараметров, исходя из отчетливых метрик оценки, таких как F1-score. Этот подход способствует улучшению результатов моделей и значительно повышает точность классификации, а также надежность предсказаний при тестировании.
models = {
'Decision Tree':
DecisionTreeClassifier(), 'Random Forest':
RandomForestClassifier(), 'K-Nearest Neighbors': KNeighborsClassifier(), 'Logistic Regression': LogisticRegression(), 'Support Vector Machine': SVC(), 'XGBoost': XGBClassifier(), 'CatBoost':
Листинг 2. Подбор моделей с использованием GridSearchCV ДЛЯ НАСТРОЙКИ ГИПЕРПАРАМЕТРОВ.
Listing 2. Model selection using GridSearchCV for hyperparameter tuning.
РЕЗУЛЬТАТЫ
Каждая модель оценивалась по ряду показателей, включая отчет о классификации с информацией о количестве истинных и ложных положительных предсказаний. Матрица ошибок показывала количество правильных и неправильных предсказаний по категориям. ROC-кривая использовалась для оценки способности модели различать позитивные и негативные классы, отображая зависимость между чувствительностью и специфичностью.
Для некоторых моделей также вычислялась важность признаков, что позволяло определить наиболее значимые переменные в предсказаниях.
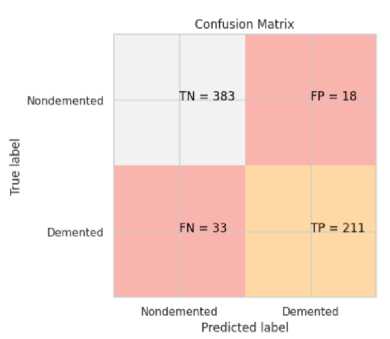
Рисунок 1. Матрица ошибок с результатами ПРЕДСКАЗАНИЯ МОДЕЛИ .
Figure 1. Confusion matrix with model prediction results.
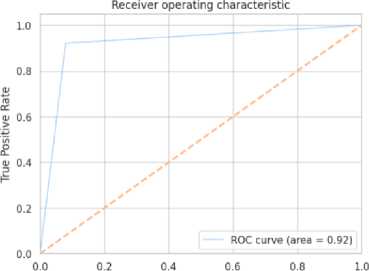
False Positive Rate
Рисунок 2. ROC- КРИВАЯ . Figure 2. The ROC curve.
Модель XGBoost продемонстрировала очень хорошую точность, составившую 95%. Оптимальные параметры для данной модели включали learning_rate, равный 0.01, max_depth, равный 5, и n_estimators, равный 200.
Второй по эффективности моделью стал CatBoost, который достиг точности 94%. Наилучшие параметры для этой модели включали 300 итераций и learning_rate также равный 0.01.
Третьей моделью по эффективности является классификатор на основе деревьев решений, который показал точность 92%. Оптимальный параметр max_depth для данной модели был установлен на уровне 5.
ОБСУЖДЕНИЕ
Наилучшие результаты были достигнуты с использованием алгоритмов XGBoost и CatBoost, которые продемонстрировали точность 95% и 94% соответственно. Эти модели основаны на методах градиентного бустинга, что обеспечивает им способность эффективно обрабатывать сложные паттерны в данных. В сравнении с более простыми алгоритмами, такими как Decision Tree Classifier, который показал 92% точности, видно, что увеличение сложности алгоритма значительно улучшает качество предсказаний.
Высокая точность XGBoost объясняется его мощными возможностями обучения на сложных данных и эффективной обработкой выбросов, что делает его особенно подходящим для задач, требующих высокой предсказательной способности. XGBoost — это оптимизированная распределенная библиотека повышения градиента, разработанная таким образом, чтобы быть гибкой и портативной [7]. CatBoost, в свою очередь, проявил отличные результаты благодаря своей устойчивости к переобучению и способности работать с категориальными признаками [8] без предварительной обработки, что делает его ценным инструментом в ситуациях с большим количеством категориальных признаков. Хотя деревья решений обеспечивают хорошую интерпретируемость результатов, их эффективность оказывается ниже по сравнению с градиентными методами, что связано со склонностью к переобучению.
Анализ важности признаков показал, что когнитивные и функциональные оценки, такие как "Функциональная оценка", "ADL" (Activities of Daily Living) и "MMSE" (Mini-Mental State Examination), имеют наибольшее влияние на результат классификации. Это согласуется с клиническими наблюдениями: ухудшение этих показателей часто связано с прогрессированием деменции. Использование таких характеристик в алгоритмах может привести к более точной диагностике и раннему вмешательству при заболевании.
Тем не менее, несмотря на высокую точность моделей, необходимо учитывать возможные ограничения исследования. Одним из таких вопросов является избыток или недостаток данных в некоторых категориях, что может привести к смещению результатов. Кроме того, интерпретируемость моделей остается ключевым аспектом, особенно в медицинской среде, где каждое принятое решение должно быть обосновано и понятным для клиницистов.
Успех алгоритмов в выявлении паттернов, связанных с деменцией, может оказать значительное влияние на практическую медицину. Это позволит врачам проводить более точный и ранний диагноз, что особенно важно для разработки программ по ранней диагностике и вмешательству в области общественного здравоохранения. В итоге использование таких моделей может способствовать улучшению качества жизни пациентов, повышению эффективности медицинской помощи в целом и потенциально способно обеспечить переход к персонализированной медицине в клинической практике [9].
ЗАКЛЮЧЕНИЕ
В представленном исследовании была проведена комплексная оценка эффективности алгоритмов классического машинного обучения для классификации деменции у пациентов пожилого возраста. На основе обширного табличного набора данных, включающего медицинские шкалы, лабораторные результаты, семейный анамнез и социально-демографические факторы, были предприняты попытки оценить способность этих алгоритмов к точной идентификации и классификации деменции.
Исследование продемонстрировало, что методы машинного обучения могут служить мощным инструментом в области диагностики психических заболеваний, позволяя врачам выявлять группы риска и предпринимать меры для раннего вмешательства. Это может привести к улучшению прогноза для пациентов и более эффективному распределению ресурсов в системе здравоохранения.
Тем не менее, важно отметить существующие ограничения исследования, такие как возможное смещение данных из-за демографического оверрепрезентирования и необходимость повышения интерпретируемости моделей для клинического применения. В дальнейшем следует рассмотреть возможность расширения выборки для включения более разнообразных групп пациентов, а также углубленного внедрения полученных результатов в клиническую практику.
Данное исследование подтвердило высокую эффективность алгоритмов машинного обучения в классификации деменции и продемонстрировало их потенциал в улучшении диагностики и лечения данного заболевания. Искусственный интеллект привносит новые возможности, повышая точность диагнозов, оптимизируя лечение и адаптируя подходы к уходу за пациентами [10].
