Исследование эффективности применения технологий вейвлет-анализа в задачах распознавания образов

Автор: В.С. Мараев
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 1 (1), 2021 года.
Бесплатный доступ
Работа посвящена экспериментальному сравнению точности методов классификации на задаче распознавания образов на изображениях с использованием технологий вейвлет-анализа и без. В частности, исследуется взаимодействие кольце-проекционного вейвлет-фрактального метода для выявления признаков с классическими методами классификации, такими как «Наивный классификатор Байеса» и «Машины опорных векторов». Экспериментальные результаты тестирования приводятся в виде таблицы. В итоге устанавливается, что внедрение вейвлет-анализа в построение моделей классификации изображений оправдано, и приводит к относительно малому, но значимому повышению точности классификации.
Вейвлет анализ, распознавание образов, методы классификации, обработка данных, наивный классификатор Байеса, машины опорных векторов
Короткий адрес: https://sciup.org/14121888
IDR: 14121888 | УДК: 004.852 | DOI: 10.47813/2782-2818-2021-1-1-23-28
Текст статьи Исследование эффективности применения технологий вейвлет-анализа в задачах распознавания образов
Распознавание образов является передовой областью, в настоящее время возникает множество новых технологий в ней, и, как известно, не существует абсолютного решения для задачи распознавания образов. Поэтому предлагается исследовать применение технологий вейвлет-анализа в задаче распознавания образов.
Технологии вейвлет-анализа достаточно перспективны и гибки в использовании и в связке с некоторыми алгоритмами машинного обучения могут повысить их точность и эффективность, в том числе, крайне существенно. Они могут быть применены на совершенно разных этапах процесса машинного распознавания образов: от выделения признаков и до выполнения классификации [1].
Один из главных этапов в классификации изображений это выделение набора значимых признаков на изображениях. Именно сюда будет легче всего внедрить вейвлет-анализ. Задача выделения признаков состоит в том, чтобы охарактеризовать образ и, кроме того, уменьшить размерность пространства изображения до пространства, подходящего для применения методов классификации [2].
В данной статье мы исследуем применение технологий вейвлет-анализа для построения моделей распознавания образов. А также, проведём экспериментальное сравнение эффективности применения особых методов вейвлет-анализа для выделения признаков и применения классических алгоритмов выделения признаков для последующей классификации. Таким образом, спроектируем математическую модель распознавания образов на основе технологий вейвлет-анализа.
2. Методы
Для экспериментов же мы используем кольце-проекционный вейвлет-фрактальный метод (Ring-Projection-Wavelet-Fractal Method) [3]. Используемый метод можно отнести к классу методов выделения признаков ортогонального расширения.
Ранее, было выявлено, что в задаче анализа изображений двумерный вейвлет-анализ не особо эффективен, поэтому желательно свести задачу к одномерному вейвлет-анализу [4]. В этом и заключается основная идея кольце-проекционного вейвлет-фрактального метода: свести проблему двумерных объектов в одномерные, тогда мы можем использовать одномерное вейвлет-преобразование для решения проблемы распознавания. Блок схема алгоритма кольце-проекционного вейвлет-фрактального метода приведена на рисунке 1.
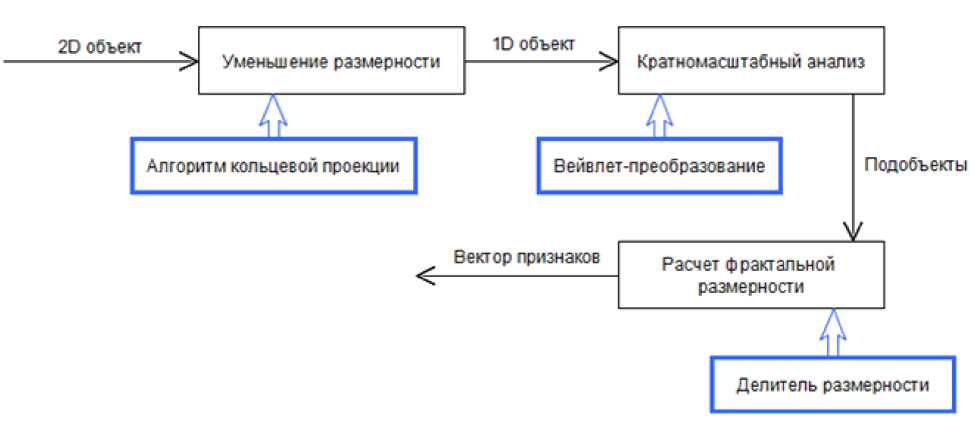
Рисунок 1. Блок схема алгоритма кольце-проекционного вейвлет-фрактального метода.
Используя кольце-проекционный вейвлет-фрактальный метод, мы получаем вектор признаков на выходе. Затем, можно использовать вектор признаков и базу данных всех признаков для классификации.
3. Результаты
Проведём сравнение точности работы некоторых популярных методов классификации на задаче распознавания образов на изображениях с использованием кольце-проекционного вейвлет-фрактального метода для выявления признаков с классическим свёрточным методом выявления признаков. Для исследования возьмём следующие методы классификации: «Наивный классификатор Байеса» и «Машины опорных векторов». Алгоритмы были реализованы на языке Python, с использованием библиотек scikit-learn [5] и PyWavelets [6].
В качестве набора данных для задачи распознавания образов на изображениях выбрана классическая база данных изображений рукописных цифр MNIST [7]. Пример изображений из набора приведён на рисунке 2.

Рисунок 2. Пример изображений из набора данных MNIST.
В качестве альтернативы для сравнения степени изменения точности классификации при применении описанного кольце-проекционного вейвлет-фрактального метода выделения признаков были взяты стандартные свёрточные алгоритмы выделения признаков из изображения.
Так как набор данных не бинарный, то используется мульти классовый SVM: решающее правило основано на разбиении задачи на бинарные по схеме "один против остальных" (One-vs-Rest).
Для каждой комбинации метода классификации и метода выделения признаков проведено обучение, валидация и оценка точности на тестирующем множестве (20% от выборки). Для каждого метода классификации был проведён подбор наиболее эффективных гиперпараметров по сетке (Grid search). В итоге, для каждого метода высчитана точность при проведении повторной 10-и блоковой перекрёстной проверки (10-fold cross-validation). Данные о точности и скорости собраны в таблице 1.
Таблица 1. Результаты экспериментов.
|
Метод выделения вектора признаков |
Наивный байесовский |
Метод опорных векторов (SVM) |
||||
|
Точно сть |
классификатор |
|||||
|
Время обучения (с.) |
Время предсказан ия (с.) |
Точно сть |
Время обучения (с.) |
Время предсказани я (с.) |
||
|
Кольце-проекционный вейвлет-фрактальный |
0.970 |
1.98 |
0.015 |
0.985 |
2.52 |
0.010 |
|
метод Свёрточный алгоритм |
0.942 |
1.15 |
0.009 |
0.973 |
1.88 |
0.006 |
4. Анализ
Первое что можно заметить – метод классификации SVM сработал во всех случаях лучше, чем наивный Байес. Однако нас интересует, способен ли исследуемый кольцепроекционный вейвлет-фрактальный метод выделения признаков превзойти стандартные свёрточные алгоритмы и дать выигрыш в точности классификации.
Как видно, нам удалость несколько повысить точность для обоих методов классификации. Статистическая значимость повышения точности подтверждается t-тестом Стьюдента при уровне значимости 0.05. При использовании наивного Байеса ошибка классификации была уменьшена на 93.3% (относительно), а при использовании SVM на 80.1%. Но в тоже время, использование вейвлет-анализа повышает как время обучения, так и время предсказания в обоих случаях. В среднем для обоих методов классификации, время обучения повышается на 53.1%, а время предсказания на 66.67%.
Таким образом, экспериментально установлено, что внедрение вейвлет-анализа в построение моделей классификации изображений полностью оправдано, как минимум в данной задаче распознавания образов рукописных цифр. Однако, нельзя утверждать, что представленный метод применения вейвлет-анализа будет также обеспечивать повышение точности при использовании других методов классификации, или же в иных задачах распознавания образов.
5. Заключение
В работе выполнено экспериментальное сравнение точности методов классификации на задаче распознавания образов на изображениях с использованием технологий вейвлет-анализа и без.
Установлено, что внедрение вейвлет-анализа в построение моделей классификации изображений полностью оправдано, и приводит к относительно малому, но значимому повышению точности классификации. Таким образом, данный метод обладает широким потенциалом для внедрения в автоматизированные системы.
Однако, нельзя утверждать, что представленный метод применения вейвлет-анализа будет также обеспечивать повышение точности при использовании других методов классификации, или же в иных задачах распознавания образов. Таким образом, дальнейшие исследования в этой области целесообразно направить эксперименты по взаимодействию кольце-проекционного вейвлет-фрактального метода с другими типами классификаторов, например, «K ближайших соседей», бустинг, случайный лес, с другими материнскими вейвлетами (помимо «мексиканской шляпы») и, конечно, на других, более сложных (чем MNIST) задачах распознавания образов.
Кроме того, использование вейвлет-анализа в распознавании образов не заканчивается только на методе выделения признаков. Исследование применения других технологий могут быть проведены в последующих исследованиях.
