Исследование метода оптимизации структурной идентификации динамических процессов в классе разностных уравнений заданного порядка

Бесплатный доступ
Рассмотрены вопросы исследования метода оптимизации структурной идентификации динамических процессов в классе разностных уравнений заданного порядка. Предложен подход однократного вычисления Q F и Z F , формирования Q S и Z S , соответствующих различным структурам моделей, для вычисления параметров и критерия структурной идентификации при больших значениях N выборки данных, значительно снижающий трудоемкость алгоритмов структурной идентификации при использовании выборок данных большого объема.
Оптимизация, структурная идентификация, случайный поиск, динамические процессы
Короткий адрес: https://sciup.org/140129841
IDR: 140129841
Текст научной статьи Исследование метода оптимизации структурной идентификации динамических процессов в классе разностных уравнений заданного порядка
а для динамического процесса модель имеет вид
„ Ns
Ук = ^Рг ' Ч>$У^Ук-п’Ук-п+1’"-’Ук-1’^к-д+1’"-’^к-1’-^к^ * (3)
с соответствующей выборкой данных
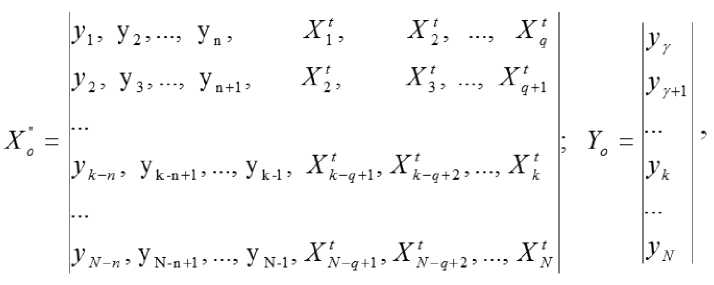

где
q, если q > n;
у = 5 , yk, к = 1..... N
[ и +1, если
q
значение отклика объекта в k-й момент дискретного времени; Хk – значение вектора параметров объекта в k -й момент дискретного времени, ( xk, j – значение j -го параметра объекта в k-й момент дискретного времени); m – размерность пространства параметров объекта; N – объем выборки данных предыстории объекта; – операция транспонирования; и – наборы линейных и нелинейных функций с известными коэффициентами (параметрами) из некоторого заданного
упорядоченного множества допустимых структурных элементов; – вектор коэффициентов (параметров) модели; n – порядок разностного уравнения модели динамического объекта; Ns – число функций из некоторого за-
-
3. Ns := Ns + 1;
-
4. Jnew := J ; {выполнить структурную идентификацию, Jnew присвоить значение критерия структурной идентификации и запомнить snew [ i ], i = 1, ..., Ns };
-
5. если J > J d , то перейти на 8;
-
6. J old := J new ; s ( i ):= s new [ i ], i =1, ..., Ns ;
-
7. перейти на 3;
-
8. Ns := Ns - 1;
-
9. J := Jold ; {критерию структурной идентификации присвоить значение Jold , структура модели определена в s ( i ), i =1, ..., Ns };
-
10. конец.
С целью уменьшения трудоемкости алгоритма структурной идентификации целесообразно не хранить матрицу XF с функциями , k = 1, ..., Mz
данного упорядоченного множества допустимых структурных элементов, входящих в модель (априорно неизвестно); s [ i ] – индекс (номер) структурного элемента (функции k = 1, ..., Mz ) из заданного упорядоченного конечного множества допустимых структурных элементов; Mz – мощность (размерность) упорядоченного множества допустимых структурных элементов.
При известном порядке разностного уравнения модели динамического объекта и величине запаздывания по независимым входным переменным структурная идентификация статического (1) и динамического (3) объектов одинаковы, что позволяет использовать модель объекта вида (3). При неизвестном порядке разностного уравнения модели динамического объекта его можно определить, исследуя ряды разностей зависимой переменной.
При структурной идентификации по выборке данных предыстории процесса эффективны алгоритмы, удовлетворяющие двум базовым принципам [4]:
-
1. принципу Геделя – только внешние критерии, основанные на новой информации, позволяют найти истинную модель объекта, скрытую в зашумленных данных;
-
2. принципу Габора – всякая однорядная процедура структурной идентификации может быть заменена многорядной (обладающей меньшей трудоемкостью) только при условии сохранения «свободы выбора» нескольких лучших решений каждого предыдущего ряда.
Одним из наиболее широко применяемых на практике методов, удов-летворяющим этим принципам, является метод группового учета аргументов (МГУА), предполагающий использование внешних критериев, например критерия минимума смещения [4]. Метод МГУА решает задачу выбора Ns элементов из множества допустимых структурных элементов мощностью Mz , оптимизирующих выбранный критерий структурной идентификации.
В целом алгоритм структурной идентификации (с учетом принципов Геделя и Габора), минимизирующий значение критерия структурной идентификации, сводится к следующей последовательности действий:
-
1. Ns := Nsmin ; {присвоить Ns минимально допустимое значение}
-
2. Jold := J ; {выполнить структурную идентификацию, Jold присвоить значение критерия структурной идентификации и запомнить s [ i ], i = 1, ..., Ns }
^x^^x^.^^x^
9i (^2) 92 (^2) 9^ (^2)
F
91 №) 92 №) 9jtiz (^v)
а один раз вычислить и хранить меньшую по размерности нормальную матрицу Гаусса множества допустимых структурных элементов
N
-^^Zv.^a-tp/^a
z = Mz; i = 1, Mz,
,
С учетом симметричности относительно главной диагонали матрицы QF целесообразно хранить лишь ее верхний наддиагональный треугольник и главную диагональ. Также достаточно один раз вычислить и хранить вектор ZF размерности Mz
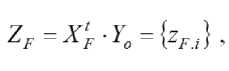
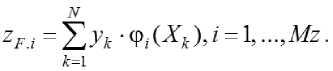
Под структурой модели будем понимать входящие в нее Ns конкретных структурных элементов в упорядоченном множестве допустимых структурных элементов { s [ i ]}, i = 1, ..., Ns . Если известна структура модели, то из матрицы QF и вектора ZF можно сформировать нормальную матрицу Гаусса для модели с известной структурой
- ^Mj]
t
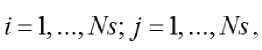

и соответствующий вектор ZS с элементами с использованием которых возможно определить вектор параметров P модели и критерии структурной идентификации
А—- О О ' О О ' D U
В выражении (8) матрица XS структурно подобна матрице XF, однако она содержит лишь столбцы функций
, i =1,..., Ns , k =1,..., N , принадлежащих модели с заданной структурой.
При использовании критерия минимума смещения выборка исходных данных (2), (4) делится на две подвыборки ( XA , YA ) и ( XB , YB ), например, на основе вероятностного критерия разбиения [5]. Искомое разделение исходной выборки на две подвыборки (их объемы NA и NB , N = NA + NB ) минимизирует отклонение функции распределения вероятности критерия для истинной модели от единичной функции и позволяет выбрать разделение с более острой зависимостью значения критерия от сложности модели ( Ns ) и достигаемым минимумом критерия более глубоким, чем при других возможных разделениях.
Критерий минимума смещения записывается в виде писать в виде
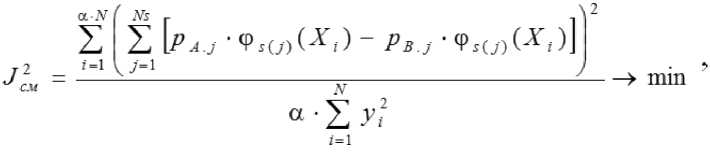
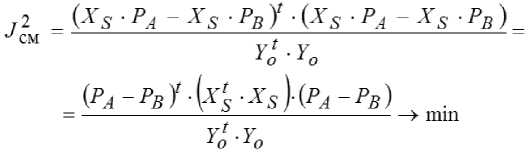
или
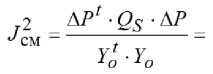
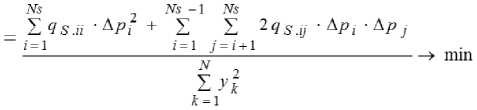
где △ P = PA - PB. Выражение ' 1 х достаточ но вычислить один раз. Для каждой структуры необходи- мо определять параметры на обеих подвыборках (PA, PB) и формировать нормальную матрицу Гаусса QS из матрицы QF. Критерий регулярности отличается меньшей вычислительной сложностью, поскольку нормальную систему уравнений Гаусса приходиться решать только для подвыборки A, а на подвыборке B оценивается адекватность модели для задаваемой структуры. Критерий регулярности можно за-
где XFA , XFB – матрицы, подобные XF , для подвыборок A и B ; XSA , XSB – матрицы, аналогичные матрице XS , для подвыборок A и B ; QSA , QSB – нормальные матрицы Гаусса для моделей заданной структуры { s [ i ]}, i =1,..., Ns , получаемых на двух подвыборках A и B ; ZSA , ZSB – векторы, соответствующие вектору ZS для подвыборок A и B ; PA , PB – векторы параметров для моделей заданной структуры, полученных на подвыборках A и B , с элементами pA.i , pB.i , i =1, ..., Ns ; α -коэффициент экстраполяции, α = 1.0 - 3.0, позволяющий описать дополнительные данные Xk , k = N +1,..., α N , которые определяет исследователь объекта в качестве потенциальной области их изменения.
С целью снижения трудоемкости вычисления критерия минимума смещения выражение (11) преобразуем к виду
N в ( Ns А
5 I У В.к - Z РАл -ф^Овл)
N в
Т. У В .к к = 1
где yB.k – k -е значение зависимой переменной в подвыборке B ; XB.k – k -й век-тор независимых переменных в подвыборке B ; pA.i – i -й элемент вектора параметров, определенный на подвыборке A .
С целью снижения трудоемкости вычисления критерия регулярности выражение (13) преобразуем к виду
= (Уов - xsb -рА У -^Хов - х sb -ра) _
Уов УоВ
NB Ns Ns Ns -1 Ns
Z У Вл "" 2'2 25Вл " P Ал + 2 ЧВВЛ! ' Р Ал + 2 2 2 Ч SB у ' Р Ал " Р A.J
_ 1 = 1 7 = 1 7=1 7 = 1 У = 7 + 1
-> min,
£ у вл
Таблица. Исследование состоятельности методики структурной идентификации
|
№ п/п |
Уровень шума |
ФПВ шума |
ФПВ независимых входов модели |
Точно ли синтезирована структура? |
|
1 |
0 |
Нет ошибки |
R (0, l ) |
Да |
|
2 |
N (0, σ x ) |
Да |
||
|
3 |
L (0, σ x ) |
Да |
||
|
4 |
0.05 σ v |
R (0, l ) |
N (0, σ x ) |
Да |
|
5 |
N (0, σ v ) |
Да |
||
|
6 |
L (0, σ v ) |
Да |
||
|
7 |
0.1 σ v |
R (0, l ) |
N (0, σ x ) |
Да |
|
8 |
N (0, σ v ) |
Да |
||
|
9 |
L (0, σ v ) |
Нет |
||
|
10 |
0.2 σ v |
R (0, l ) |
N (0, σ x ) |
Да |
|
11 |
N (0, σ v ) |
Да |
||
|
12 |
L (0, σ v ) |
Нет |
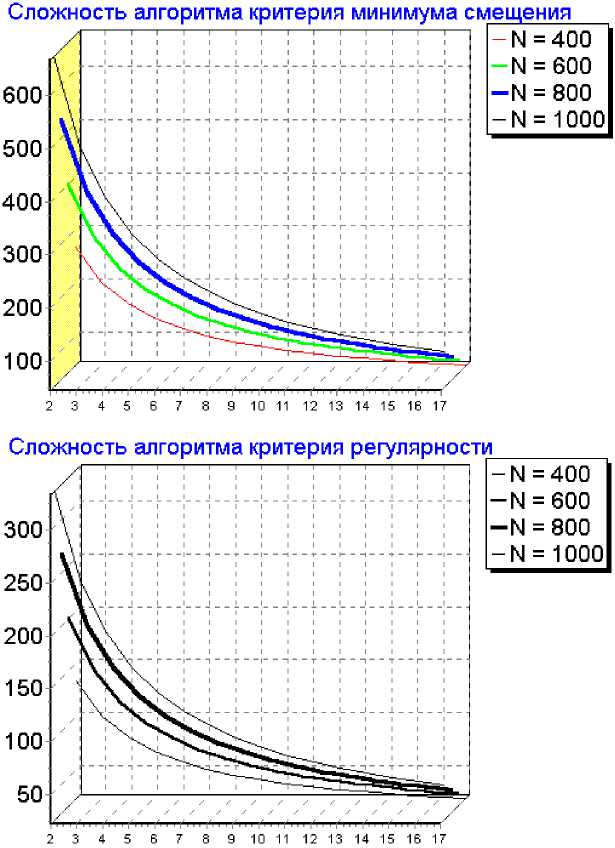
Рис.1 Исследование выигрыша в вычислительной сложности предложенных алгоритмов вычисления критериев минимума смещения и регулярности по сравнению с известными

где XSA , XSB – матрицы, соответствующие матрице XS для подвыборок данных A и B ;
Алгоритм выбора наиболее информативных Ns структурных элементов из множества допустимых структурных элементов Mz [2] предполагает реализацию итерационной процедуры, позволяющей целенаправленно, с учетом результатов вычисления критерия структурной идентификации на каждой итерации, перейти от ситуации с равновероятным использованием в модели всех допустимых структурных элементов к ситуации, выявляющей искомые Ns структурных элементов.
Результат исследования состоятельности предложенной методики структурной идентификации представлен в таблице 1. Значения элементов матрицы независимых входов модели Xo (количество независимых входов 80, объем выборки данных предыстории процесса 1000) формировались на основе генерирования псевдослучайных чисел со следующими функциями плотности вероятностей (ФПВ): равномерное распределение R(0, l ), нормальное (Гауссово) распределение
N (0, σ x ) и Лапласово распределение L (0, σ x ). Двупараметрические распределения R (0, l ), N (0, σ x ) и L (0, σ x ) являются центрированными, т.е. их математическое ожидание равно нулю. Задавались вектор параметров и структура модели из 12 структурных элементов ( Ns = 12) в классе полиномов второго порядка. По выражению (2) расс ~ читывался вектор функционально зависимой переменной Yo .
Уровень ошибки модели (столбец 2 таблицы) задавался следующим образом. Для одного из трех видов плотности распределения задавался параметр, характеризующий мощность шума ( l или σ ) ка ~ к долю стандартного отклонения зависимой переменной Yo . Тогда вектор зависимой перем ~ ен-ной с учетом шума определяется по выражению Yo = Yo + E , где E = { ε k }, k =1, …, Nw – вектор шума, генерируемый
датчиками псевдослучайных чисел с заданными законами распределения. Мощность шума увеличивалась до тех пор, пока точно определялась структура модели.
В строках 9 и 12 таблицы структура модели определяется неверно. В обоих случаях в структуру модели входит лишний структурный элемент (парное произведение) и структурные элементы задаваемые в экспе-рименте.
На рис. 1 представлен выигрыш в вычислительной сложности реализации критериев минимума смещения и регулярности по предложенной методике. Анализ выражений (11) – (14) показывает, что они содержат приблизительно одинаковое количество умножений и сложений. Выигрыш в вычислительной сложности определяется как отношение количества операций умножения (или сложения) при вычислении по предлагаемой методике критериев структурной идентификации к количеству операций умножения (или сложения) при вычислении по традиционной методике.
Например, для объема выборки данных предыстории процесса – 1000 измерений векторов независимых переменных и количества структурных элементов, входящих в модель, – 10 выигрыш в вычислительной сложности для критерия минимума смещения составляет 180 раз, а для критерия регулярности 90 раз.
Предлагаемый подход однократного вычисления QF и ZF , формирования QS и ZS , соответствующих различным структурам моделей, для вычисления параметров и критерия структурной идентификации при больших значениях N выборки данных значительно снижает трудоемкость алгоритмов структурной идентификации при использовании выборок данных большого объема. Методика использовалась при разработке программного обеспечения для осуществления структурной идентификации объектов на основе метода случайного поиска с адаптацией.
Список литературы Исследование метода оптимизации структурной идентификации динамических процессов в классе разностных уравнений заданного порядка
- Ильин А.А., Ильин Р.А. Реализация алгоритмов экспериментальной структурной идентификации объектов, линейных по параметрам на основе критерия минимума смещения//Известия Тульс. гос. ун-та. Серия Математика. Механика. Информатика. Том 1. Выпуск 3. 1996. С. 58 -66.
- Ивахненко А.Г. Индуктивный метод самоорганизации моделей сложных систем. -Киев: Наук. думка, 1982 -296 с.
- Растригин Л. А. Адаптация сложных систем. Рига: Зинатие, 1981. -384 с.
- Щедринов А.В., Кравченко А.Ю. Случайный поиск с параметрической адаптацией//Автоматизация и современные технологии. № 12. 2002. С. 17 -20.
- Юрачковский Ю.П., Грошков А.Н. Оптимальное разбиение исходных данных на обучающую и проверочную последовательности на основе анализа функции распределения критерия. -Автоматика, 1980, № 2. С. 5 -12.
