Исследование моделей и процедур самоконфигурации генетического программирования для формирования деревьев принятия решений в задачах интеллектуального анализа данных

Автор: Липинский Л.В., Кушнарева Т.В.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 3 т.17, 2016 года.
Бесплатный доступ
Исследуются механизмы самоконфигурации алгоритма генетического программирования для автоматизированного формирования деревьев принятия решений. Рассматриваются известные и хорошо зарекомендовавшие себя в задачах самоконфигурирования генетического алгоритма модели Population-Level Dynamic Probabilities (PDP) и Individual-Level Dynamic Probabilities (IDP). За счет общности процедур выбора эволюционных операторов данные подходы достаточно просто обобщаются на все эволюционные алгоритмы в целом и на алгоритм генетического программирования в частности. Однако указанные процедуры ограничены в выборе конфигурации и управлении ходом эволюции. Такие пути развития эволюционного поиска, как перезапуск, введение в популяцию новых случайных индивидов, кардинальное изменение параметров и изменение ресурсов поиска (добавление итераций, расширение популяции и т. п.), сложно включить в PDP и IDP. Кроме того, процесс принятия решения, т. е. изменение конфигурации поискового алгоритма, скрыт от пользователя. Пользователь может наблюдать лишь результаты этого выбора. Рассматривается альтернативный подход к самоконфигурированию эволюционных алгоритмов с помощью нечеткого контроллера. Процедура принятия решения и управления конфигурацией поиска в нечетких логических системах аналогична рассуждению эксперта и легко обобщается на большинство путей и настроек эволюционного поиска, которые применяет в своей работе опытный пользователь. Кроме того, пользователь может включить в нечеткий контроллер те эвристические правила и процедуры, которые сам использует в своей практике. Показывается принципиальная возможность применения нечеткой системы управления для самоконфигурирования алгоритма генетического программирования в задаче автоматизированного формирования деревьев принятия решения. Предложен минимальный набор нечетких правил и лингвистических переменных, позволяющий управлять эволюционным поиском. Обсуждается потенциал нечеткого контроллера и пути повышения эффективности процедуры самоконфигурации. Сравнение эффективности процедур самоконфигурирования проводится на практических задачах - классификации ирисов Фишера и прогнозировании побочных эффектов при лечении эпилепсии. Проводится анализ статистической значимости различий в эффективности подходов и обсуж- даются результаты. Гибридный эволюционный алгоритм автоматизированного формирования деревьев принятия решений на основе генетического программирования с реализованными процедурами самоконфигурации может быть применен в различных областях, в том числе и в ракетно-космической отрасли.
Генетический алгоритм, генетическое программирование, деревья принятия решений, нечеткий контроллер, самоконфигурация
Короткий адрес: https://sciup.org/148177597
IDR: 148177597 | УДК: 159.688
Research of self-configurating models and procedures of genetic programming for formation of decision trees in problems of the intelligent data analysis
In this work mechanisms of a self-configuration of genetic programming algorithm for the automated decision trees formation are investigated. Known, and well proved in tasks self-configurations of genetic algorithm, the Population-Level Dynamic Probabilities (PDP) and Individual-Level Dynamic Probabilities (IDP) model are considered. At the expense of a procedures community of evolutionary operators of the choice these approaches are rather just generalized on all evolutionary algorithms in general and on algorithm of genetic programming in particular. However, the specified procedures are limited in the choice of a configuration and management of the evolution course. Such ways of development of evolutionary search as restart, introduction to population of new casual individuals, cardinal change of parameters and change of search resources (addition of iterations, expansion of population, etc.) are hard to include in PDP and IDP. Besides, decision-making process, i. e. change of a configuration of search algorithm, is hidden from the user. The user can observe only results of this choice. In the offered work alternative approach to a self-configuration of evolutionary algorithms by means of the fuzzy controller is considered. Procedure of decision-making and management of a search configuration in fuzzy logical systems is similar to a reasoning of the expert and is easily generalized on the majority of ways and settings of evolutionary search which are applied in the work by the experienced user. Besides, the user can include those heuristic rules and procedures which uses in the practice in the fuzzy controller. In the work the basic possibility of application of an fuzzy control system for a self-configuration of genetic programming algorithm in a problem of the automated formation of trees of decision-making is shown. The minimum set of fuzzy rules and linguistic variables allowing operating evolutionary search is offered. Potential of the fuzzy controller and a way of increase of self-configuration procedure efficiency are discussed. Comparison of self-configuration procedures efficiency is carried out on practical tasks: classifications of irises of Fischer and forecasting of side effects at treatment of epilepsy. The analysis of the statistical importance of distinctions in efficiency of approaches is carried out, and results are discussed. The hybrid evolutionary algorithm of the automated formation of decision trees on the basis of genetic programming with the realized procedures of a self-configuration can be applied in various areas including in space-rocket branch.
Текст научной статьи Исследование моделей и процедур самоконфигурации генетического программирования для формирования деревьев принятия решений в задачах интеллектуального анализа данных
Введение. Алгоритм автоматизированного формирования деревьев принятия решений методом генетического программирования [1; 2] показал свою эффективность при решении тестовых и прикладных задач [3–5]. Следовательно, его дальнейшая модернизация для повышения скорости работы, удобства пользователя и уровня автоматизации является актуальной задачей. Для улучшения алгоритма были рассмотрены и реализованы три процедуры самоконфи-гурации: Population-Level Dynamic Probabilities (PDP), Individual-Level Dynamic Probabilities (IDP) [6] и управление с помощью нечеткого контроллера [7]. Данные процедуры позволят снизить участие пользователя в настройке алгоритма, что, в свою очередь, приведет к повышению скорости работы, удобства интерфейса и уменьшит риск человеческого фактора. Следовательно, данный алгоритм можно будет применять для решения задачи ракетно-космической отрасли, где требуется высокая точность и минимизация рисков.
Population-Level Dynamic Probabilities и IndividualLevel Dynamic Probabilities. Метод PDP работает следующим образом: вероятности использования генетических операторов напрямую зависят от успешности одного или другого оператора, т. е. чем успешнее действие оператора, тем чаще он используется. Вероятности рассчитываются по формуле (1):
ров рассчитываются для каждого индивида отдельно по формуле (2):
p = P all +
(max cntk +1 - cnt 'j) * (100 - n * p all) 1< k < n n *(maxcntk+1) -^^ cnt kj
Г *(100 - n * P all ) scale
success2 20 n
-----, P all = —, scale X r j , used - n j = 1
где success – это число успешных применений -го оператора; used – общее число применений - го оператора; n – общее число операторов [6; 7].
В методе IDP каждому индивиду популяции присваивается счетчик (cnt j ) по числу неудачных применений оператора. Вероятности применения операто-
20 Pall = —, n где n – общее число операторов [6; 7].
Нечеткий котроллер. Нечеткий контроллер – это регулятор, построенный на базе нечетких правил [8–10]. Общую схему регулятора можно увидеть на рис. 1.
Управление системы на основании нечеткой логики состоит из трех основных этапов:
-
1) фаззификация;
-
2) нечеткий вывод;
-
3) дефаззификация.
На этапе фаззификации четкий вход (информация об управляемом объекте) переводится в нечеткую точку (если вход – скаляр) или точки (если вход – вектор), в соответствии с лингвистическими переменными.
На этапе нечеткого вывода по имеющимся нечетким точкам, полученным на этапе фаззификации, и базе нечетких правил находится нечеткий выход. Нечеткий выход представляет собой нечеткое множество, конкретный элемент которого выбирается на следующем этапе.
На заключительном этапе дефаззификации нечеткий выход, полученный на предыдущем этапе, переводят в четкий, используя соответствующие лингвистические переменные. Существуют несколько возможных вариантов такого перехода, например, первый максимум: из нечеткого множества (нечеткого выхода) выбирают наименьший элемент, принадлежность которого равна максимуму из принадлежностей точек, полученных при фаззификации.
Нечеткий контроллер управляет вероятностями селекции ( p s ), скрещивания ( p c ) и мутации ( p m ) на основании таких показателей, как номер итерации ( N i ), разнообразие популяции ( I i ) и средняя пригодность (sred i ). Общая схема управления представлена на рис. 2.
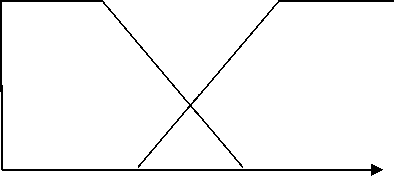
На рис. 3–5 представлены функции принадлежности для каждого входа и выхода.
В табл. 1–3 представлены базы правил. Формируются они следующим образом. Например, если номер итерации большой и разнообразие популяции не из-
менилось, то вероятность мутации изменяется слабо. Базы правил формулируются на основе многократного решения различных задач и обобщения полученного опыта.
Самоконфигурирующийся гибридный эволюционный алгоритм автоматизированного проектирования деревьев принятия решений. Три настройки были реализованы в существующем алгоритме, главное рабочее окно программы можно увидеть на рис. 6.
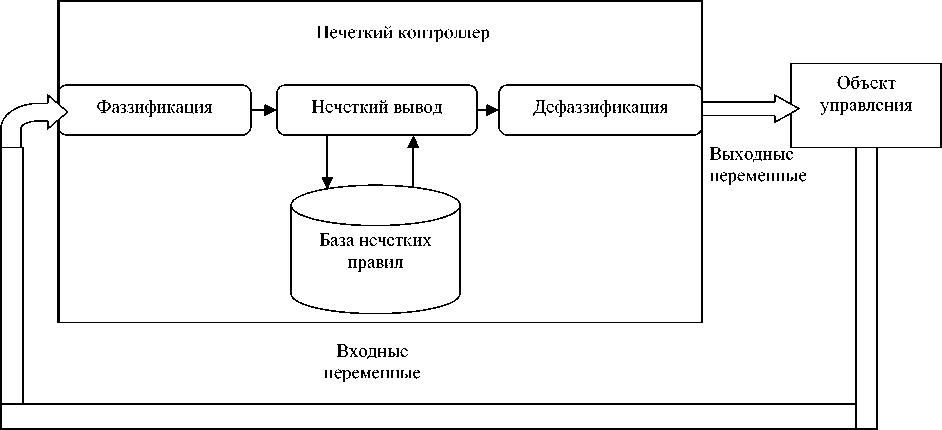
Рис. 1. Схема нечеткого контроллера
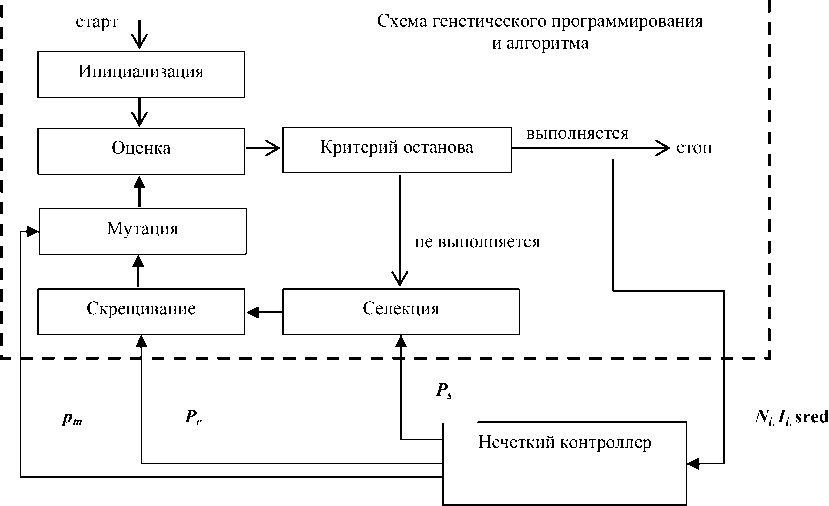
Рис. 2. Общая схема управления
µ ( N i ) t
µ ( I i )
Большой
Маленький
Средний

20 40 60 80
N i
Слабое Среднее Сильное
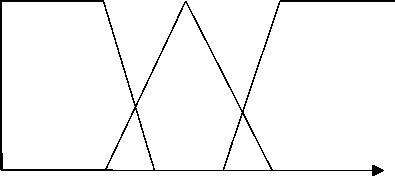
0 0,2 0,4 0,6 0,8 I i
µ (sred i )
Функция принадлежности для номера итерации ( Ni , для 100 итераций)
Функция принадлежности для разнообразия ( I i )
µ ( p m )
Низкая Средняя Высокая
0 0,2 0,4 0,6 0,8 p m
Функция принадлежности для вероятности мутации ( pm )
Рис. 3. Функции принадлежности входных и выходных параметров
µ ( p s ) A
Маленька я Средняя Большая
0 0,2 0,4 0,6 0,8 sred i
Низкая
Высокая
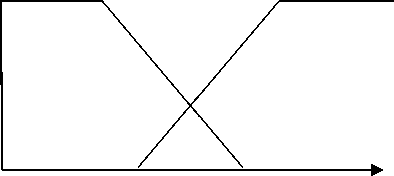
0,4
0,6
P s
Функция принадлежности для средней пригодности (sred i ) для каждого типа селекции
Функция принадлежности для вероятности селекции ( psi ) для каждого типа селекции
Рис. 4. Функции принадлежности для каждого входного и выходного параметра селекции
µ (sred i )
µ ( p c )
▲ Маленькая Средняя Большая
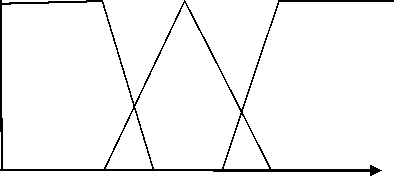
0 0,2 0,4 0,6 0,8 sred i
Низкая
Высокая
0,4
0,6
P c
Функция принадлежности для средней пригодности (sred i ) для каждого типа скрещивания
Функция принадлежности для вероятности скрещивания ( pсi ) для каждого типа скрещивания
Рис. 5. Функции принадлежности для каждого входного и выходного параметра скрещивания
Таблица 1
|
N i |
I i |
p m |
|
Если номер большой |
и разнообразие сильное |
то вероятность мутации не изменяется |
|
Если номер меньше или равен среднему |
и разнообразие ниже или равно слабому |
то вероятность мутации изменяется сильно |
|
Если номер больше или равен среднему |
и разнообразие ниже или равно слабому |
то вероятность мутации изменяется средне |
|
Если номер меньше или равен среднему |
и разнообразие среднее |
то вероятность мутации изменяется средне |
|
Если номер большой |
и разнообразие среднее |
то вероятность мутации изменяется слабо |
|
Если номер меньше или равен среднему |
и разнообразие сильное |
то вероятность мутации изменяется слабо |
Таблица 2
|
Sred 1 Sred 2 Sred 3 |
P 1 1 P 3 1 P 2 |
|
Если средние пригодности одинаковые (большие, средние или маленькие) |
то вероятности становятся равными |
|
Если две средние пригодности большие, а одна средняя |
то две соответствующие вероятности селекции увеличиваются, а одна уменьшается |
|
Если две средние пригодности средние, а одна маленькая |
то две соответствующие вероятности селекции увеличиваются, а одна уменьшается |
|
Если две средние пригодности средние, а одна большая |
то две соответствующие вероятности селекции уменьшаются, а одна увеличивается |
|
Если две средние пригодности маленькие, а одна средняя |
то две соответствующие вероятности селекции уменьшаются, а одна увеличивается |
|
Если одна средняя пригодность большая, вторая средняя, а третья маленькая |
то соответствующие вероятности: увеличивается, не изменяется, уменьшается |
База правил для управления скрещиванием
Таблица 3
|
Sred 1 Sred 2 |
P 1 |
P 3 |
|
Если средние пригодности изменились одинаково |
то вероятности становятся равными |
|
|
Если sred 1 > sred 2 |
то вероятность одноточечного скрещивания увеличивается |
то вероятность случайного скрещивания уменьшается |
|
Если sred1< sred2 |
то вероятность одноточечного скрещивания уменьшается |
то вероятность случайного скрещивания увеличивается |
База правил для управления мутацией
База правил для управления селекцией
Решение задачи классификации ирисов Фишера и задачи прогнозирования побочных эффектов при лечении эпилепсии. Оценка работоспособности алгоритма с реализованными методами самонастройки была проведена на репрезентативном множестве тестовых задач, решение одной из которых (классификации ирисов Фишера [11]) представлено в табл. 4 для сравнения эффективности настроек. После оценки было проведено исследование предложенного подхода на практической задаче прогнозирования нежелательных явлений при лечении эпилепсии [12]. Для решения этой задачи была построена выборка, содержащая сведения об около ста пациентах. Для каждого пациента в выборке были определены следующие параметры.
-
1. Входные: пол, возраст, степень обследования, характеристика приступов, МРТ, ВЭМ, терапевтический лекарственный мониторинг, фармакогенетика, вид мутации по трем цитохромам, наличие нежелательных лекарственных явлений.
-
2. Выходные: группа риска нежелательных явлений и со стороны каких систем организма есть нежелательные явления.
По первому выходу представлены 5 градаций: низкая, средняя, высокая группа риска, не уточнялась и данных для определения недостаточно. Для второго выхода выделены 11 систем: не зарегистрированы нежелательные явления, со стороны центральной нервной системы, со стороны желудочно-кишечного тракта, со стороны эндокринной системы, поражение кожи и ногтей, со стороны мочевыделительной системы, со стороны репродуктивной системы, данных для определения недостаточно, а также есть случаи, когда нежелательные явления проявлялись со стороны нескольких систем одновременно.
Алгоритму были предоставлены достаточные и равные вычислительные ресурсы. Проведены исследования всех трех подходов, получены результаты по 40 запускам для каждого подхода, рассчитываемые по формуле (3), впоследствии усредненные и отраженные в табл. 4. Также в табл. 4 содержится усредненный результат работы алгоритма без самонастройки:
n error = —, n
где error – ошибка классификации; n о – число неверно расклассифицированных измерений; n – общее число измерений.
Статистический анализ результатов. Для сравнения эффективности подходов был проведен статистический анализ [13].
Была выдвинута нулевая гипотеза о том, что нет статистически значимого различия между каждыми двумя генеральными совокупностями, т. е. их математические ожидания равны ( H 0 : M [ X ] = M [ Y ]), при конкурирующей гипотезе, что математическое ожидание первой совокупности больше, чем у второй ( H 1 : M [ X ] > M [ Y ]). Так как независимые выборки произвольно распределены и их дисперсии неизвестны, но при этом они имеют объем, больше 30 каждая, то выборочные средние распределены приближенно нормально, а выборочные дисперсии являются достаточно хорошими оценками генеральных дисперсий. Тогда можно применить следующий критерий (формула (4)):
X - Y
ID в ( X ) + D в ( Y )
nm
Критическая область в данном случае правосторонняя (рис. 7), уровень значимости равен 0,05, критическая точка равна 1,65 [14; 15]. Значения критерия соответствующих выборок приведены в табл. 5 и 6 (при z набл < z кр гипотеза H 0 принимается, иначе отвергается).
Таблица 4
|
Методы/задачи |
Классификация ирисов Фишера |
Прогнозирование побочных реакций при лечении эпилепсии |
|
Алгоритм без самонастройки |
0,044 |
0,173 |
|
IDP |
0,02 |
0,153 |
|
PDP |
0,022 |
0,156 |
|
Настройка с помощью нечеткого контроллера |
0,016 |
0,132 |
Результаты работы алгоритма с разными настройками
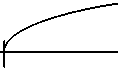
α = 0,05
Z кр = 1,65
Рис. 7. Правосторонняя критическая область
Таблица 5
Попарный статистический анализ для задачи классификации ирисов
|
IDP |
PDP |
Настройка с помощью нечеткого контроллера |
|
|
Алгоритм без самонастройки |
3,28 |
2,31 |
5,02 |
|
IDP |
0,90 |
1,86 |
|
|
PDP |
2,65 |
Таблица 6
Попарный статистический анализ для задачи прогнозирования побочных явлений
|
IDP |
PDP |
Настройка с помощью нечеткого контроллера |
|
|
Алгоритм без самонастройки |
2,04 |
1,69 |
4,37 |
|
IDP |
0,46 |
2,38 |
|
|
PDP |
2,82 |
Заключение. Проведенный попарный статистический анализ результатов выявил следующие результаты: алгоритм с любой процедурой самоконфигуриро-вания лучше, чем без нее; управление с помощью нечеткого контроллера лучше, чем методы PDP и IDP, при этом последние не имеют статистически значимого различия между собой, поэтому несравнимы. Следует заметить, что у нечеткого контроллера есть и дополнительные преимущества: прозрачность принятия решения, широкие возможности в управлении (включение перезапуска, добавление новых случайных индивидов и т. д.).
Последующая разработка процедур автоматизированной настройки правил позволит существенно увеличить эффективность алгоритма.
Список литературы Исследование моделей и процедур самоконфигурации генетического программирования для формирования деревьев принятия решений в задачах интеллектуального анализа данных
- Кушнарева Т. В., Липинский Л. В. Алгоритм генетического программирования для автоматизированного формирования деревьев принятия решения//Материалы XVIII Междунар. науч. конф., посвященной 90-летию со дня рождения генерального конструктора ракетно-космических систем академика М. Ф. Решетнева/СибГАУ. Красноярск, 2014. Т. 2. С. 84-86.
- Гибридный эволюционный алгоритм автоматизированного формирования деревьев принятия решения/Липинский Л. В. //Вестник СибГАУ. 2014. № 5 (57). С. 85-92.
- Кушнарева Т. В., Липинский Л. В. Автоматизированное формирование деревьев принятия решения для прогнозирования побочных эффектов при лечении эпилепсии//Актуальные проблемы авиации и космонавтики: материалы XI Междунар. науч.-практ. конф., посвященной празднованию 55-летия Сибирского государственного аэрокосмического университета имени академика М. Ф. Решетнева/СибГАУ. Красноярск, 2015. Т. 1. С. 334-336.
- Кушнарева Т. В., Липинский Л. В. Анализ и интерпретация результатов при автоматизированном формировании деревьев принятия решений методом генетического программирования//Материалы XIX Междунар. науч. конф., посвященной 55-летию Сибирского государственного аэрокосмического университета имени академика М. Ф. Решетнева/СибГАУ. Красноярск, 2015. Т. 2. С. 57-59.
- Кушнарева Т. В. О применении деревьев принятия решения в задачах медицинской диагностики//Проспект Свободный -2015: материалы науч. конф., посвященной 70-летию Великой Победы (15-25 апр. 2015, г. Красноярск)/Сиб. федер. ун-т. Красноярск, 2015. C. 31-32.
- Niehaus J., Banzhaf W. Adaption of operator probabilities in genetic programming//Proceeding EuroGP ’01: Proceedings of the 4th European Conference on Genetic Programming. London: Springer-Verlag Publ, 2001. Vol. 2038 of LNCS. P. 325-336.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. М.: Горячая линия. Телеком. 2006. C. 91-106.
- Yuceer C., Oflazer K. A rotation, scaling and translation invariant pattern classification system//Pattern Recognition. 1993. Vol. 26. P. 687-710.
- Zadeh L. A. Fuzzy sets//Information and control. 1965. Vol. 8. P. 338-353.
- Zadeh L. A. The concept of linguistic variables and its application to approximate reasoning//Information sciences. 1975. No 8(3). P. 199-249.
- Fisher R. A. The Use of Multiple Measurements in Taxonomic Problems//Annals of Eugenics. 1936. Vol. 7, iss. 2. P. 179-188.
- Академик . URL: http://dic.academic.ru/dic.nsf/enc_medicine/36047/Эпилепсия (дата обращения: 10.1.2013).
- Гмурман В. Е. Теория вероятностей и математическая статистика: учеб. пособие для вузов. М.: Высш. шк., 2003. С. 303-304.
- Прикладная статистика: Основы моделирования и первичная обработка данных/С. А. Айвазян М.: Финансы и статистика, 1983. 471 с.
- Румшиский Л. З. Математическая обработка результатов эксперимента. М.: Наука, 1971. 192 с.
