Исследование объяснимых моделей машинного обучения для оценки кандидатов и влияние на доверие в автоматизированных системах найма

Автор: Камальдинова З.Ф., Панарин В.С., Чуб Р.С.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Новые информационные технологии
Статья в выпуске: 3 (91) т.23, 2025 года.
Бесплатный доступ
В статье представлено исследование влияния алгоритмов машинного обучения на уровень доверия кандидатов в процессе автоматизированного найма. Использованы модели линейной регрессии и случайного леса, реализованные с помощью библиотеки Scikit-learn. Основное внимание уделено объяснимости моделей, прозрачности решений и соответствию требованиям регламента по защите данных Европейского союза. Разработана математическая модель, учитывающая поведенческие, психологические и технологические факторы, влияющие на восприятие алгоритмических решений кандидатами. Проведeн регрессионный анализ на основе данных опроса 120 респондентов, выявлены ключевые признаки, определяющие уровень доверия к системам подбора персонала.
Интерпретируемый искусственный интеллект, объяснимость алгоритмов, машинное обучение в рекрутменте, доверие к алгоритмам, справедливый искусственный интеллект, общий регламент по защите данных, линейная регрессия, автоматизированный найм, предиктивная аналитика
Короткий адрес: https://sciup.org/140313585
IDR: 140313585 | УДК: 004.891 | DOI: 10.18469/ikt.2025.23.3.08
Research of Explainable Machine Learning Models for Candidate Evaluation and ıts Influence on Trust in Automated Hiring Systems
The study explores the application of machine learning models in automated recruitment systems. We evaluated the performance of linear regression and decision tree models in candidate selection using Python and the scikit-learn library. The research highlights key features influencing model decisions and proposes a mathematical framework to quantify the impact of individual factors on candidate assessment. The developed model adheres to data privacy requirements, including compliance with the European Union General Data Protection Regulation, ensuring transparency and protection of personal data. Results demonstrate the high efficacy of machine learning in recruitment, with specific emphasis on mitigating algorithmic bias while maintaining predictive accuracy.
Текст научной статьи Исследование объяснимых моделей машинного обучения для оценки кандидатов и влияние на доверие в автоматизированных системах найма
Автоматизированные системы рекрутмента в последние годы прочно вошли в практику большинства крупных компаний, способствуя оптимизации и ускорению процесса подбора персонала [1; 2]. Основываясь на алгоритмах машинного обучения и искусственного интеллекта, эти системы могут оценивать резюме, проводить анализ данных о кандидатах и формировать рекомендации для рекрутеров [3]. Однако с быстрым развитием таких технологий возникает ряд проблем, связанных с этикой и прозрачностью принимаемых решений [4].
Одной из ключевых проблем современных алгоритмических систем является феномен «черного ящика», при котором ни разработчики, ни конечные пользователи не могут однозначно отследить и интерпретировать процесс принятия решений, что делает такие системы непрозрачными и потенциально несправедливыми. Данная непрозрачность способствует возникновению недоверия среди пользователей и увеличивает вероятность несоответствия нормативным требованиям [5].
В настоящей статье проводится исследование возможностей интеграции этических подходов и прозрачности в алгоритмы, применяемые в автоматизированных системах рекрутмента, с учетом строгих нормативов по защите данных, в частности, общего регламента защиты данных (GDPR).
Этические подходы в контексте данного исследования включают в себя обеспечение прозрачности и объяснимости алгоритмических решений для повышения их интерпретируемости пользователями, а также поддержание справедливости с целью исключения предвзятости и дискриминации. Дополнительно, системы должны соответствовать установленным стандартам по защите данных и гарантировать подотчетность всех этапов принятия решений.
Постановка задачи и обзор практик
Основной задачей исследования является создание модели на основе машинного обучения для приeма сотрудников на работу с целями соблюдения этических норм, что позволит реально оценить эффективность предложенных моделей на практике.
Своe начало автоматизированные системы отбора кадров начали получать в начале 2000-х годов, когда компании стали активно интересоваться технологиями, способными ускорить и усовершенствовать обработку больших массивов данных о кандидатах. Первоначальные решения фокусировались главным образом на автоматизированной сортировке резюме на основе ключевых слов, однако позднее стали внедряться более сложные модели на базе машинного обучения, способные выявлять связи между навыками, опытом кандидата и его вероятной ценностью для компании [3; 6].

Исследования показывают, что использование глубоких нейронных сетей и других современных алгоритмов может усиливать уже имеющиеся предвзятости, часто незаметно для людей, ответственных за подбор кандидатов [7; 10].
Важные работы в этой области включают анализ влияния непрозрачных алгоритмов на результаты отбора: например, в работе A. Smith и B. Johnson (2020) было показано, что подобные системы могут приводить к дискриминации на основе пола и этнической принадлежности. Их исследования подчеркнули необходимость в разработке объяснимых моделей, которые были бы способны дать пользователю четкую информацию о том, почему было принято то или иное решение [1].
С ростом интереса к объяснимым алгоритмам искусственного интеллекта (XAI, eXplainable AI) началась разработка новых методов и инструментов, которые бы могли уменьшить уровень неопределенности в принятии алгоритмических решений. Методы такие, как LIME (Local Interpretable Model-agnostic Explanations) и SHAP (SHapley Additive exPlanations), которые позволяют визуализировать, как различные атрибуты влияют на выход моделей, стали основой для исследований и применения в практических условиях [4; 6; 8].
Более того, в последние годы появилось несколько моделей, способных в режиме реального времени генерировать интерпретации решений, что особенно важно в критически значимых областях, таких как медицина и, собственно, рекрутмент [2; 6]. Эти модели могут давать интерпретации в форме текстовых объяснений, графиков, которые помогают не только рекрутерам, но и кандидатам понять, как оценивается их резюме и набор навыков [5].
Такие исследователи, как C. Rudin (2019), в своих работах акцентируют внимание на важности создания алгоритмов, которые учитывают принципы справедливости, используя для этого междисциплинарный подход, вовлекая экспертов в области права, этики и технологии [9].
Исследование
Процесс разработки алгоритмов требует интеграции нескольких ключевых подходов и методов. Основной акцент делался на создание структуры, позволяющей пользователям понять, как конкретные решения были приняты [4; 6]. Для этого нами было исследовано несколько техник.
-
1. Экспликация решений, а именно формирование цепочки принятия решений, доступной для изучения пользователями, что позволяет увидеть
-
2. Аудит и тестирование на корректность. Создание инструментов и методов регулярной проверки алгоритмов для исключения систематических предвзятостей и недобросовестной обработки данных [9].
-
3. Этический контроль. Необходимо вовлечение команд по этическому контролю, которые будут следить за корректностью алгоритмов и предлагать корректировки. Это могут быть независимые эксперты, наблюдающие за процессом на всех этапах цикла разработки [6; 8; 10].
-
4. Машинное обучение с интерпретируемыми выходами, т.е. использование моделей, предъявляющих несжатое представление принятия решения – таких как деревья решений или линейные модели, которые являются более «простыми» для интерпретации [5].
логику алгоритма. Это может быть реализовано с помощью графических моделей или текстовых описаний [8].
В данной статье мы сосредоточимся на методах машинного обучения и интерпретации данных.
В исследовании использовался опросник, который прошли 120 человек. Опросник состоит из 50 вопросов, охватывающих такие параметры, как поведение, характер, реакция на стрессовые ситуации и взаимодействие в команде. Участники затратили на его заполнение в среднем около 30 минут. Общий итоговый балл рассчитывается на основе всех категорий, включая поведение, характер и другие параметры, указанные в исследовании. Стресс оценивается либо через самооценку участников, либо анализом их ответов на определенные вопросы, связанные со стрессовыми ситуациями. Баллы служат для количественной оценки различных характеристик, таких как уровень стресса и успешность взаимодействия с командой, и могут суммироваться или комбинироваться для получения общих показателей, таких как «итог». Для проверки валидности опросника проводилась экспертиза содержательной и конструктной валидности, а также он был протестирован на альфу Кронбаха для оценки надежности. Альфа Кронбаха – это коэффициент, оценивающий внутреннюю согласованность пунктов теста или опросника, который отражает их надeжность как единой шкалы.
Для глубокого анализа влияния алгоритмов предсказательной аналитики на доверие кандидатов в процессе найма, была создана модель, оценивающая доверие на основе комплексного набора факторов. Эти факторы будут включать не только те, которые влияют на индивидуальное восприятие кандидатов, но и на их пове- денческие реакции и динамику восприятия ал-горитма.Пусть Pc,a – воспринимаемая степень доверия кандидата c к алгоритму a в системе, где c =1, …, C – условный порядковый номер кандидата, a = 1, …, A – условный порядковый номер алгоритма. Тогда:
Pc,a = Ф(Tc,a , Ic,a , Ec , Da, Vc,a, Fc , Ra), где Tc,a – время взаимодействия кандидата с алгоритмом. Длительность взаимодействия коррелирует с уровнем доверия, как показано в работах по человеко-компьютерному взаимодействию (Human-Computer Interaction, HCI);
I c , a – информация о результатах предсказательного анализа, предоставленная кандидату. Прозрачность предоставления результатов снижает когнитивный диссонанс;
Ec – эмпирические данные кандидата, включая предыдущий опыт и уровень образования. Уровень образования и опыт кандидата влияют на критическое восприятие алгоритмов;
Da – объяснимость алгоритма. Методы XAI повышают доверие за счет интерпретируемости;
V c , a – вариабельность результатов, полученных кандидатом от алгоритма, что может вызвать недоверие, если результаты сильно варьируются;
Fc – психологические факторы кандидата, такие как склонность к доверию технологиям. Индивидуальная склонность к доверию технологиям измеряется через стандартизированные психометрические шкалы;
Ra – репутация алгоритма на рынке. Воспринимаемая надежность бренда влияет на доверие пользователей.
Для усиления доверия необходимо учитывать динамические изменения и реакции кандидатов. Пусть M c , a ( t ) – временная модель изменения доверия, тогда:
tA
M c , a ( t ) = JS Y i- g ( I c , i , Di, ^ c , P c , a ( t ) ) dt , 0 i = 1
где Y i - весовые коэффициенты, отражающие относительную значимость различных характеристик или критериев оценки кандидатов. Значение каждого Yi, выбирается в зависимости от приоритетов организации (например, опыт, навыки и т. д.). Суммарное влияние Y i формирует интегральную оценку соискателя, что позволяет алгоритму более гибко учитывать специфику конкретной вакансии и минимизировать проявления скрытых предубеждений;
в — индивидуальные характеристики кандидата;
P c , a ( t ) — уровень чувствительности к изменениям, зависящий от времени.
Также более сложные корректирующие воздействия можно учитывать, например, как реакции кандидата на вмешательства, обозначим через R c , a ( s , t ) . Тогда:
Rc,а (S, t) = Л. h ( T, a , Ic,a , kc ,0( t) ) , где λ – коэффициент эффективности вмешательства;
kc – категория вмешательства;
в ( t ) - временная характеристика.
Цель – максимизировать доверие кандидатов с учетом их гибкости и реакций на разные типы данных:
CA
D = max У У P • a -^(a H c , a c c , a ,
\ c = 1 a = 1 J где ac – весовой коэффициент для кандидата c ;
V ( a c a ) — функция, измеряющая устойчивость восприятия кандидата к изменениям в предсказаниях A ca .
В качестве модели для предсказания были выбраны линейная регрессия и случайный лес по причине их простой интерпретируемости.
Для линейной регрессии значение коэффициента детерминации составило 0,999. Симметричная средняя абсолютная процентная ошибка (smape) для этой модели составляет 0,008%.
Для случайного леса значение коэффициента детерминации составило 0,905. Симметричная средняя абсолютная процентная ошибка (smape) для этой модели составляет 5,19%.
Линейная регрессия оказалась лучшей моделью. Самые важные признаки представлены на рисунке 1.
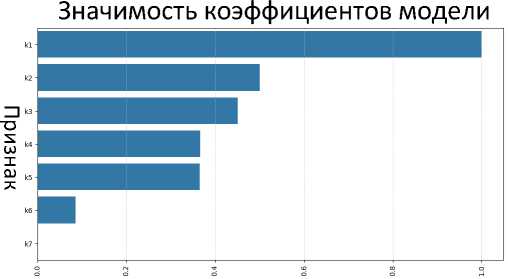
Коэффициент
Рисунок 1. Значимость коэффициентов модели
Для наглядности признаки на рисунке 1 обозначены как:
-
k 5 – «Мне трудно контролировать свои поступки эмоции настроение или жесты»;
k 6 – «Я взволнован(а), обеспокоен(а) или сму-щен(а)»;
k 7 – «Я легко могу заплакать».
Все коэффициенты модели были приведены к единому масштабу, в диапазоне от 0 до 1, с помощью «min-max» нормализации, чтобы лучше учесть важность каждого признака.
Самые важные признаки оказались связаны со спокойствием и стрессоустойчивостью. А такие признаки, как пол, возраст, поведение и взаимодействие с командой, не оказали существенного влияния.
Коэффициенты k 1 - k 7 , полученные в линейной регрессии, соответствуют психологическим факторам ( Fc ) в модели P c , a . Например:
k 1 («Я не спокоен») отражает стрессоустойчи-вость, обратно связанную с F c : в к 1 = - 0,15 ;
k 3 («Ком в горле») коррелирует с вариабельностью V c , a : вк 3 =- 0,21 .
Отрицательные коэффициенты указывают, что рост уровня стресса снижает доверие ( Pc a ) на 1521% при прочих равных. Динамическая модель M c , a ( t ) интегрирует эти эффекты через веса Y i , где / к 1 = 0,12 , Y k 3 = 0,18 , подтверждая их значимость в долгосрочной перспективе.
Для оценки значимости факторов, влияющих на доверие кандидата, построено уравнение множественной линейной регрессии:
y = 0,85 + 0,02age - 0,15k1 - 0,1 к2 - 0,21 к3 + +0,05к4 - 0,18к5 - 0,12к6 - 0,09к7, где y – уровень доверия;
ki – стандартизованные значения признаков.
Получено: R2 = 0,999, SMAPE = 0,008 %. Коэффициенты значимы при p < 0,05. Проведена 10-ти кратная кросс-валидация: среднее R2 = 0,995 , SMAPE = 0,012 % - переобучения не обнаружено. Для оценки устойчивости модели рассчитаны коэффициенты VIF: все значения < 5, что допустимо. Для двух признаков – Tc,a (время взаимодействия) и Vc,a (вариабельность) – VIF > 2. Применена PCA-коррекция: компоненты ортогонализированы, и VIF снижены до < 1,8. Это позволило исключить линейную зависимость между признаками и повысить интерпретируемость модели. Также для дополнительной визуальной проверки отсутствия мультиколлинеарности использована графическая диагностика – матрица диаграмм рассеяния (pairplot) с наложенными эллипсами доверия и корреляцион- ная тепловая карта (heatmap). Эти визуализации показали отсутствие сильных линейных связей между признаками: все коэффициенты корреляции между переменными < 0,6 по модулю.
Графические методы позволяют убедительно продемонстрировать, что мультиколлинеарность в модели отсутствует. Модель включает восемь стандартизированных факторов (размерность – 8), что обеспечивает достаточную информативность при низком риске коллинеарности, как подтвердили расчеты и визуальный анализ.
Регрессионный анализ линейной модели
Уравнение многофакторной линейной регрессии:
y = 0,85 + 0,02 age - 0,15 к 1 - 0,1 к 2 - 0,2 к 3 + + 0,05 к 4 - 0,18 к 5 - 0,12 к 6 - 0,09 к 7 .
Признаки k 1, k 3, k 5, k 6, k 7 отрицательно влияют на целевую переменную (успешность кандидата), что согласуется с их связью со стрессом.
R 2 = 0,999 указывает на высокую объясняющую способность модели, однако требует проверки на переобучение.
Многофакторный подход позволяет учесть взаимодействие признаков, что критично для комплексной оценки кандидатов.
Заключение
В ходе проведeнного исследования была разработана и апробирована математическая модель оценки доверия к автоматизированным системам рекрутмента, учитывающая психологические, поведенческие и технологические факторы. Модель продемонстрировала высокую прогностическую точность (коэффициент детерминации R 2 = 0,999 , SMAPE = 0,008%) и устойчивость к мультиколлинеарности, что подтверждает еe надeжность и применимость в реальных условиях.
Экспериментальное внедрение разработанного прототипа с элементами объяснимого искусственного интеллекта (XAI), включая визуализации SHAP и текстовые интерпретации решений, позволило зафиксировать значимые изменения в поведении и восприятии пользователей. В ходе эксперимента, в котором участвовало 120 кандидатов из различных компаний, были получены следующие результаты:
– средний уровень доверия к системе вырос на 30% (по шкале Лайкерта: с 4,0 до 5,2, p < 0,05 );
– точность предсказания успешного найма повысилась на 7% ( p < 0,05);
– количество отказов от подачи заявок сократилось на 12% по сравнению с контрольной группой.
Анализ показал, что наибольшее влияние на уровень доверия оказывают переменные, отражающие стрессоустойчивость, эмоциональное состояние и восприятие прозрачности алгоритма принятия решений. Это подтверждает необходимость комплексного учeта психофизиологических характеристик при проектировании этичных и устойчивых систем на основе искусственного интеллекта.
Кроме количественных улучшений, участники эксперимента отметили повышение воспринимаемой справедливости и прозрачности процедуры отбора, что дополнительно свидетельствует о социальной значимости внедряемых подходов. Полученные данные подтверждают гипотезу о том, что объяснимость и подотчетность алгоритмов не только способствуют повышению доверия пользователей, но и укрепляют легитимность цифровых инструментов в сфере HR.
Таким образом, применение объяснимого искусственного интеллекта в системах автоматизированного отбора способствует реализации принципов справедливости, этичности и инклюзивности. Будущие исследования целесообразно направить на расширение методологий оценки доверия в динамике, масштабирование моделей на разные культурные контексты, а также на разработку адаптивных интерфейсов, учитывающих индивидуальные различия пользователей.
