Исследование способов ускорения поисковых запросов в базах данных

Автор: Коптенок Елизавета Викторовна, Подвесовская Марина Александровна, Хвостенко Татьяна Михайловна, Кузин Александр Владимирович
Статья в выпуске: 1 (13), 2019 года.
Бесплатный доступ
В статье рассмотрены способы ускорения выполнения запросов к базе данных. Рассматривается влияние индексов и секционирования на время выполнения поисковых запросов.
База данных, индекс, секционирование, поисковый запрос
Короткий адрес: https://sciup.org/140249584
IDR: 140249584
Research of ways to speed up search queries in databases
The article discusses how to speed up the execution of queries to the database. The influence of indexes and partitioning on the execution time of search queries is considered.
Текст научной статьи Исследование способов ускорения поисковых запросов в базах данных
Keyword . Database, index, partitioning, search query.
В течение последнего десятилетия все большее количество сфер деятельности общества активно автоматизируются, повсеместно внедряются автоматизированные рабочие места, электронный документооборот и так далее. Это приводит к стремительному росту потребности в быстром поиске информации в базах и хранилищах данных, количество которых также быстро растет. По различным оценкам, объем цифровой информации в следующие 10 лет вырастет десятикратно, при этом 60% этой информации будет генерироваться коммерческими предприятиями. Соответственно, важность эффективности поиска данных будет только расти. При этом, несмотря на возникновение принципиально новых архитектур баз данных (далее – БД), реляционные БД остаются наиболее популярными.
Основные инструменты для ускорения работы БД – индексирование и секционирование. Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение происходит за счет создания так называемого дерева индекса (используется сбалансированное дерево), которое упорядочивает доступ к данным.
Индексы делятся на кластеризованные и некластери-зованные. Различие в том, что кластеризованный индекс физически упорядочивает данные в файловых страницах, а некластеризованный – создает дополнительное дерево, хранящее не сами данные, а ссылки на них.
Данное различие для каждого из типов индексов несет как преимущества, так и недостатки. Кластеризованный индекс может работать быстрее (за счет прямого доступа к данным), однако времени на создание и поддержку такого индекса требуется больше. Также возможно создание лишь одного кластеризованного индекса для таблицы, при этом первичный ключ как раз и является кластеризованным индексом. Некластеризованных индексов можно создать несколько, при этом они требуют меньше времени на построение и поддержку.
Также существует фильтруемый индекс – оптимизация некластеризованного индекса. Дерево индекса строится только для определенной части таблицы, удовлетворяющей условиям фильтра.
Отдельно стоит отметить Columnstore – постолбцовое хранение данных. Это эффективно для больших объемов хранимых данных при условии относительно редкого обновления. Ускорение поисковых запросов происходит за счет того, что сначала происходит перебор значений столбцов поиска, а затем извлечение полных кортежей данных.
Еще одним эффективным средством ускорения запросов к БД является секционирование. Объекты базы данных разделяются на отдельные части с раздельными параметрами физического хранения. Это повышает управляемость и производительность больших БД.
В отличие от индексов, разбитие таблицы на несколько секций не просто ускоряет выполнение поисковых запросов, но и дефрагментирует данные. Это важно, так как в процессе регулярного обновления данных в таблице файлы, в которых эти данные физически хранятся, беспорядочно переписываются, в результате данные фрагментируются, что замедляет процесс работы с записями.
В ходе работы проведен эксперимент по измерению времени выполнения различных поисковых запросов к
БД с использованием различных индексов и секционирования. Объектом эксперимента являлась база данных, таблицы которых содержали случайные текстовые и числовые данные (натуральные числа до 106 и строки длиной 10 символов, состоящие из случайных символов). Количество записей в таблицах варьировалось от 103 до 107.
Для измерения времени поиска необходимых данных составлены несколько простых SQL-запросов на поиск данных с сортировкой, выборкой по условию и группировкой (с условием и без).
Каждый запрос выполнялся несколько раз, за итоговое время будет бралось среднее арифметическое. Для достоверности результатов перед каждым выполнением запроса очищались буфер и кэш, чтобы сервер БД не подставлял уже просчитанные результаты. Вывод данных производился в отдельный файл, чтобы непосредственно вывод данных не сказывался на общем времени выполнения. Запросы выполнялись с извлечением как только индексируемых данных, так и полных кортежей. Результаты эксперимента приведены ниже.
Результаты выполнения запросов к БД, оптимизированных различными индексами, приведены на рис.1. при возврате проиндексированных столбцов.
В остальных случаях при дальнейшем увеличении количества записей эффективность индексирования будет устойчивой, а время выполнения запросов будет примерно вдвое меньше.
На рис.2. приведено сравнение времени выполнения запросов к таблицам с разным количеством записей с использованием секций и без. Также отдельно разнесены результаты для запросов, возвращающих полный кортеж
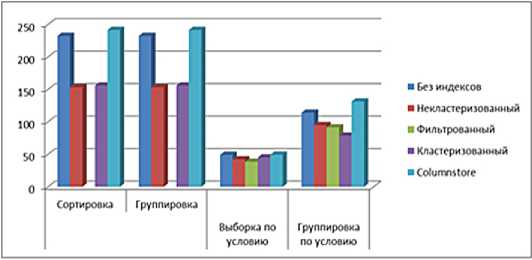
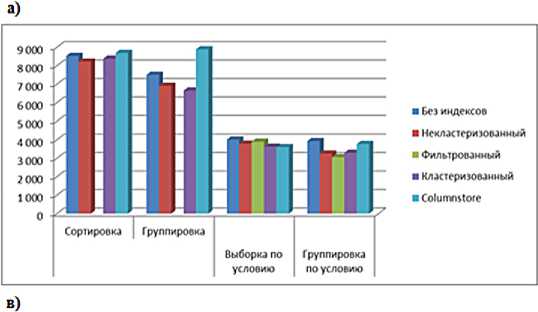
Рисунок 1. Время выполнения различных запросов к таблицам данных а) 10000 записей, б) 100000 записей; в) 1000000 записей г) 10000000 записей
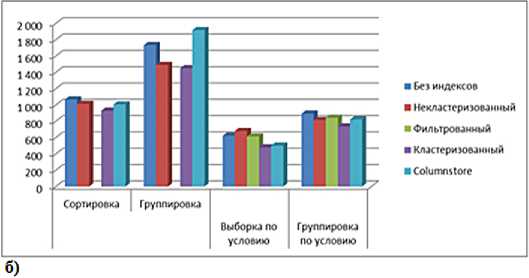
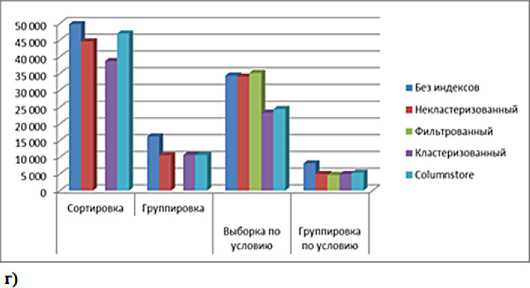

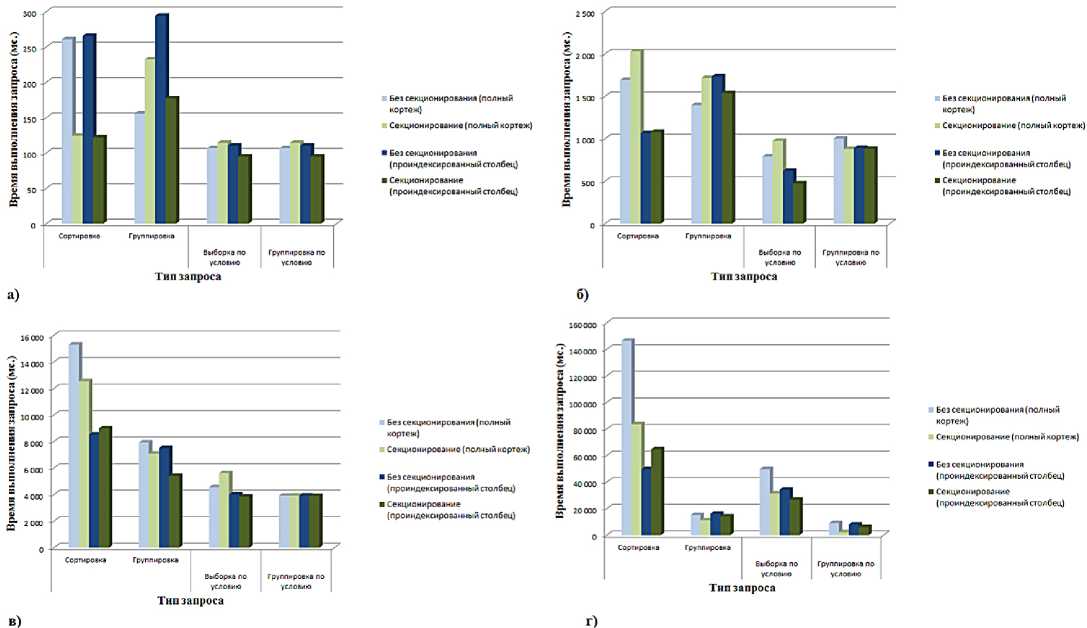
Рисунок 2. Время выполнения различных запросов к таблицам данных а) 10000 записей, б) 100000 записей; в) 1000000 записей г) 10000000 записей.
данных и запросов, возвращающих только значения полей, по которым проведено секционирование.
На основе результатов, полученных в ходе эксперимента, были сделаны следующие выводы:
-
1. Для таблиц размером менее 104 записей применение индексов практически не имеет эффективности, columnstore и вовсе замедляет выполнение запросов в случаях группировок и выборок по условию;
-
2. Columnstore показывает резкий скачок эффективности при увеличении количества записей в таблице до 107.
-
3. Кластеризованный индекс является наиболее универсальным способом оптимизировать время выполнения запросов к БД, почти всегда ускоряя поиск данных, но не дающим решающего преимущества;
-
4. Индексирование таблиц с количеством записей от 107 дает почти двукратное ускорение запросов, связанных с группировкой данных;
-
5. Использование индексов при выполнении запросов с выборкой по условию не оказывает положительного влияния.
-
6. Секционирование гораздо эффективнее, если результатом выполнения запросов будет возвращение полных кортежей данных;
-
7. Даже для небольших объемов данных применение секционирования дает ощутимое преимущество при выполнении запросов с сортировкой результирующего набора и возвращением полного кортежа, а при возвращении только проиндексированной части наблюдается обратный эффект;
-
8. При выполнении запросов на выборку по условию при возврате полного кортежа секционирование замедляет выполнение запроса, при возврате только индексированного столбца – ускоряет. Такая же зависимость наблюдается при выполнении запросов на группировку данных;
-
9. При выполнении запросов, подразумевающих и группировку, и выборку по условию, наоборот, секционирование дает стабильное преимущество при большом количестве записей.
Список литературы Исследование способов ускорения поисковых запросов в базах данных
- Дунаев, В. В. Базы данных. Язык SQL для студента / В.В. Дунаев. - М.: БХВ-Петербург, 2017. - 288 c
- Карвин, Билл Программирование баз данных SQL. Типичные ошибки и их устранение / Билл Карвин. - М.: Рид Групп, 2018. - 336 c
- Коптенок Е. В., Кузин А. В., Шумилин Т. Б., Храмченко В. Д., Крахмалев Н. О. Применение индексирования для ускорения запросов к базе данных // Молодой ученый. - 2019. - №4. - С. 8-12. - URL https://moluch.ru/archive/242/55870
- Коптенок Е. В., Кузин А. В., Шумилин Т. Б., Храмченко В. Д., Крахмалев Н. О. Применение секционирования таблиц для ускорения запросов к базе данных // Молодой ученый. - 2019. - №4. - С. 4-8. - URL https://moluch.ru/archive/242/55869
