Исследование ускорения обработки данных в многоядерных вычислительных системах на основе имитационного моделирования

Автор: Лохвицкий Владимир Александрович, Захаров Анатолий Иванович, Брякалов Геннадий Алексеевич, Неретина Кристина Андреевна
Рубрика: Управление сложными системами
Статья в выпуске: 1, 2022 года.
Бесплатный доступ
Статья посвящена разработке имитационной модели гипотетической вычислительной задачи, а также исследованию на ее основе возможностей различных программно-аппаратных решений с точки зрения затрачиваемых на организацию вычислений временных ресурсов. Необходимость такой работы обусловливается требованиями, предъявляемыми к скорости обработки больших объемов информации, появлением новых аппаратно-программных средств распараллеливания и потребностью в их апробации. Особое значение в организации исследования имеет метод имитационного моделирования, применение которого обусловлено малоизученностью рассматриваемых аппаратно-программных платформ, а также необходимостью предварительных оценок их дальнейшего использования при решении трудоемких вычислительных задач.
Имитационное моделирование, распараллеливание алгоритмов, параллельные вычисления, графические процессоры
Короткий адрес: https://sciup.org/148324192
IDR: 148324192 | УДК: 004.7
Data processing acceleration study in multi-core computing based on simulation
The article is devoted to the development of a simulation model of a hypothetical computational problem, as well as to the study on its basis of the possibilities of various software and hardware solutions in terms of time resources spent on organizing calculations. The need for such work is caused by the requirements imposed on the processing speed of large amounts of information, the emergence of new hardware and software parallelization tools and the need for their approbation. Of particular importance in the organization of the study is the method of simulation modeling, the use of which is due to the little-studied hardware and software platforms under consideration, as well as the need for preliminary assessments of their further use in solving time-consuming computational tasks.
Текст научной статьи Исследование ускорения обработки данных в многоядерных вычислительных системах на основе имитационного моделирования
Мировая практика принятия сложных управленческих решений перешла на принципиально новый уровень методологической и инструментальной поддержки, когда те или иные варианты решений должны быть предварительно апробированы не на реальных объектах и людях, а на их аналогах, то есть на моделях [10]. В этой связи осуществление экономических, технических решений или новаций требует предварительных оценок финишных результатов при помощи имитационного моделирования (далее – ИМ) [10]. Этим объясняется актуальность темы данной работы.
Имитационное моделирование – это метод исследования, при котором изучаемая система заменяется моделью, достаточно точно описывающий реальную систему, с которой проводятся эксперименты для получения информации об этой системе [10].
Лохвицкий Владимир Александрович
Работа посвящена разработке имитационной модели, позволяющей исследовать процесс ускорения обработки данных, а также влияние аппаратных средств распараллеливания алгоритма гипотетической задачи на повышение оперативности обработки информации в многоядерных компьютерах.
Разработка алгоритма модели
При исследовании предельных возможностей различных программно-аппаратных решений, используемых в процессе организации вычислительно-трудоемких задач, возникает необходимость проведения ряда экспериментов. Так, при имитационном моделировании алгоритм, реализующий конкретную модель, воспроизводит процесс функционирования системы во времени и пространстве. В этом случае имитируются элементарные явления с сохранением логической и временной структуры процесса [5]. С этой точки зрения задачу синтеза целесообразно решать методом имитационного моделирования.
При разработке имитационной модели типовой процесс моделирования содержит следующие основные этапы [10].
-
1. Создание концептуальной модели.
-
2. Разработка алгоритма модели.
-
3. Программирование модели.
-
4. Планирование прогонов.
-
5. Машинный эксперимент.
-
6. Анализ результатов.
Исследование ускорения обработки данных в многоядерных вычислительных системах ...
Концептуальная модель включает в себя:
-
• целевые показатели;
-
• описание подсистем и их взаимодействия;
-
• числовые данные.
В целом в качестве объекта имитационной модели вычислительной задачи может использоваться гипотетическая задача, схема алгоритма которой, представлена на Рисунке 1.
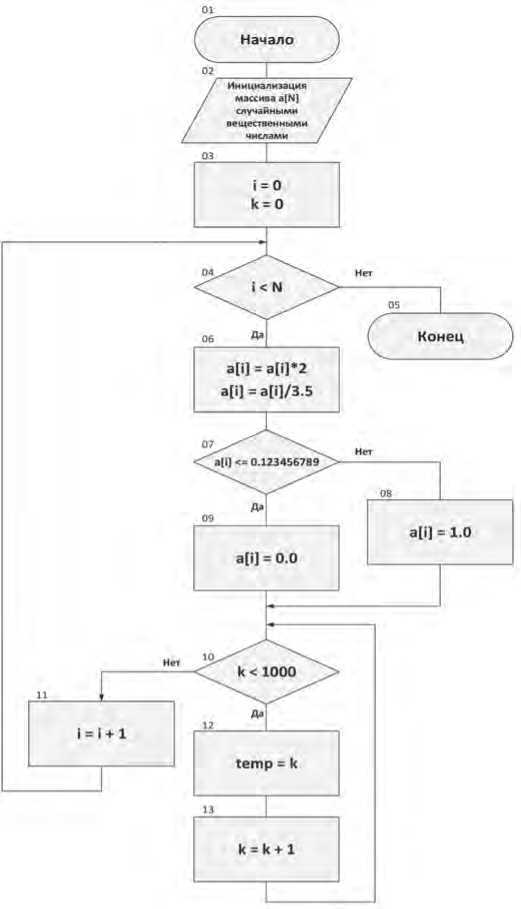
Рисунок 1. Схема алгоритма имитационной модели
Содержательная постановка задачи
Содержательная постановка задачи включает в себя описание аппаратной части исследования, алгоритм обработки данных и языки программирования.
Аппаратная часть базируется на современной технологии CUDA (англ. Compute Unified Device Architecture), получившей широкое распространение. Эта программно-аппаратная архитектура позволяет производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU [1].
В основе преимуществ использования технологии CUDA лежат архитектурные особенности построения графических процессоров (GPU), отличающие их от традиционных центральных процессоров (CPU) [11].
Выполнение расчетов на GPU показывает отличные результаты в алгоритмах, использующих параллельную обработку данных, особенно когда одну и ту же последовательность математических операций применяют к большому объему независимых блоков данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико [11].
Основой для эффективного использования возможностей GPU в научных и иных неграфических расчетах является распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в графических процессорах. Что касается технологии CUDA, она базируется на расширении с помощью видеокарт NVIDIA языков C++ и Python для параллельных вычислений. Эффект от применения видеокарт выражается в приросте скорости вычислений по сравнению с центральными процессорами общедоступных компьютеров [1].
Одной из основных проблем параллельных вычислений является определение возможности распараллеливания существующих последовательных алгоритмов решения задачи, а также непосредственно само распараллеливание алгоритмов с их дальнейшей программной реализацией [2–4].
Суть программного распараллеливания составляет декомпозиция – разбиение задачи на отдельные независимые части и параллельная их реализация на многоядерной вычислительной системе (далее – МВС).
Алгоритм имитационной модели был реализован в трех вариантах программно-аппаратных конфигураций вычислительной системы и отражает пошаговый процесс создания имитационной модели генерирования некоторой гипотетической задачи [5; 7; 9].
В первом варианте использовалась библиотека Numba языка Python, позволяющая применять графический адаптер с технологией CUDA для ускорения процесса вычислений.
Во втором варианте алгоритм был реализован на языке C++, а вычисления выполнялись в однопоточном режиме с использованием центрального процессора (CPU).
Третий вариант – это реализация алгоритма на языке Python версии 3.8 с использованием библиотеки Numpy и выполнением программы с использованием центрального процессора.
Конфигурация используемого в эксперименте ноутбука включала в себя:
-
• процессор Intel Core i7 8th Gen, ОЗУ – 16 Гб;
-
• видеоадаптер NVIDIA GeForce MX150;
-
• операционная система MS Windows 10 Домашняя x64.
Исследование ускорения обработки данных в многоядерных вычислительных системах ...
Математическая постановка задачи
Дано:
-
1. Программа имитационной модели в кодах языка программирования Python версии 3.8.
-
2. Конфигурация ноутбука, указанная выше.
Требуется:
-
1. Реализовать программу в трех вариантах программно-аппаратных конфигураций вычислительной системы:
-
• GPU (CUDA), Python3, Numpy, Numba;
-
• CPU, C++;
-
• CPU, Python3, Numpy.
-
2. Провести сравнительный анализ времени решения трех вариантов проведенного эксперимента по ускорению обработки данных [6; 8].
В ходе проведения эксперимента результаты сравнительного анализа времени решения задачи были сведены в Таблицу 1, а также представлены на графике Рисунка 2.
Таблица 1
Времена вычислений в зависимости от объема входных данных (N)
|
Размер массива, N |
Время, с |
||
|
GPU, Numba |
CPU, C++ |
CPU, Python3 |
|
|
100 |
0,0006 |
0,0002 |
0,0070 |
|
1000 |
0,0016 |
0,0028 |
0,0690 |
|
10000 |
0,0009 |
0,0213 |
0,6725 |
|
100000 |
0,0021 |
0,2004 |
8,6524 |
|
1000000 |
0,0127 |
1,6913 |
75,0906 |
|
10000000 |
0,1159 |
17,1848 |
731,8543 |
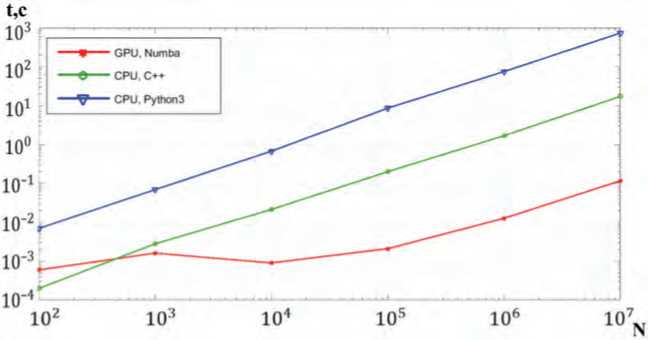
Рисунок 2. Зависимость длительности обработки данных от их объема при различных программно-аппаратных вариантах организации вычислений
В качестве входных данных использовался массив вещественных случайных чисел из диапазона [0,0; 1,0] размерности N = {102, 103, …, 107}.
В результате эксперимента установлено следующее:
-
• использование первого варианта конфигурации (GPU, Numba) позволяет обеспечить достаточно высокую оперативность решения задачи на всем диапазоне объемов входных данных;
-
• реализация алгоритма на C++ сопоставима по скорости обработки с первым вариантом только при малых объемах входных данных, а при их увеличении проигрывает на несколько порядков;
-
• использование «чистого» языка Python3 для реализации алгоритма и вычислений на центральном процессоре представляется нецелесообразным (для N = 107 данный вариант медленнее первого варианта в 6314,53 раз).
Заключение
Таким образом, в результате проведенного экспериментального исследования, можно сделать следующие выводы:
-
• снижение длительности решения задачи возможно на основе использования вычислительных возможностей графического ускорителя применительно к частям программы, допускающих параллельное выполнение;
-
• реализации вычислительно-трудоемких задач могут быть выполнены на языке Python с использованием библиотеки Numba;
-
• вычислительно-трудоемкие операции (допускающие независимую параллельную обработку) могут быть объединены в рамках отдельного вычислительного модуля (вебсервиса), доступ к которому целесообразно реализовать на основе унифицированного интерфейса, например, по протоколу jsonrpc .
Статья носит прикладной характер и может быть полезна для лиц, интересующихся вопросами повышения оперативности обработки информации.
Список литературы Исследование ускорения обработки данных в многоядерных вычислительных системах на основе имитационного моделирования
- Боресков А. В., Харламов А. А. Основы работы с технологией CUDA. М.: ДМК-Пресс, 2016. 232 с.
- Воеводин В.В., Воеводин Вл. В. Параллельные вычисления. СПб.: БХВ-Петербург, 2002. 584 с.
- Гергель В.П. Теория и практика параллельных вычислений. М.: Интернет-Университет, БИНОМ. Лаборатория знаний, 2007. 408 с.
- Горелик А.М. Средства поддержки параллельности в языках программирования // Открытые системы. 1995. № 2. С. 26.
- Захаров А.И., Пореченский М.А., Чмыхова Я.В. Имитационная модель исследования влияния распараллеливания информационных процессов на рост производительности многоядерных вычислительных систем // Сборник алгоритмов и программ прикладных задач. 2017. Вып. 34. С. 173–181.
- Захаров А.И., Лохвицкий В.А., Старобинец Д.Ю., Хомоненко А.Д. Оценка влияния параллельной обработки изображений на оперативность функционирования БКУ КА дистанционного зондирования Земли // Современные проблемы дистанционного зондирования Земли из космоса. 2019. Т. 16, № 1. С. 61–71.
- Захаров А.И., Брякалов Г.А., Неретина К.А. Влияние параллельных вычислений и структуры алгоритмов решаемых задач на оперативность обработки информации в многопроцессорных вычислительных системах // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2021. Вып. 1. С. 143–149.
- Лохвицкий В.А., Борозенец А.Г. Программный комплекс классификации неструктурированных данных на основе метода опорных векторов // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2015. Вып. 1. С. 27–31.
- Лохвицкий В.А., Хабаров Р.С. Модель оценивания оперативности многопоточной обработки задач в распределенной вычислительной среде с учетом процессов Split-Join // Вестник Российского нового университета. Серия: Сложные системы: модели, анализ и управление. 2019. Вып. 1. С. 26–34.
- Рыжиков Ю.И. Имитационное моделирование. Курс лекций. СПб.: ВКА имени А.Ф. Можайского, 2007. 125 с.
- Сандерс Д., Кэндрот Э. Технология CUDA в примерах. Введение в программирование графических процессов. М.: ДМК-Пресс, 2015. 232 с.
