Исследование возможности обфускации нейросетей и функционирования обфусцированных нейросетей в рамках задачи классификации

Автор: Сентюрев М.А., Макаров И.А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
В некоторых случаях возникает необходимость защитить знания, содержащиеся в нейронной сети, при этом не удаляя их из сети. Одна из проблем заключается в том, что атакующий может восстановить входные данные, приводящие к желаемому выводу, используя методы, значительно более эффективные, чем полный перебор. Для решения этой проблемы предлагается использовать подход обфускации, повышающий сложность атак на инверсию модели и уклонение. В данной работе представлен механизм защиты, основанный на немонотонных функциях активации (модификациях ReLU) с низкой параметризацией, разработанный для повышения сложности атак в условиях открытого доступа (белый ящик). В работе рассматриваются эвристики (стохастические перенос, обмен с эквивалентом) и компоненты (дополнительные варианты ReLU), которые улучшают сходимость сети с немонотонной функцией активации. Каждый нейрон с такой функцией способен эмулировать до двух стандартных нейронов, повышая энтропию хранимой информации, что в некоторых случаях позволяет уменьшить размер сети до 2 раз без существенной потери качества.
Функция активации, немонотонная функция активации, немонотонный ReLU, бессмертный ReLU, nmReLU, nmiReLU, iReLU, ilReLU, защита открытых нейронных сетей, защита от атак на нейронные сети
Короткий адрес: https://sciup.org/142247119
IDR: 142247119 | УДК: 004.032.26
Exploring the feasibility of neural network obfuscation and the operation of obfuscated neural networks in classification problem
There are cases when it may be necessary to protect the knowledge of the network without actually removing it from the network. The critical challenge is the ability of an attacker to efficiently reconstruct inputs that produce a desired output, using methods far more effective than brute-force search. To address this, we propose to use obfuscation approach, which increases the complexity of model inversion and evasion attacks. This paper presents a defense mechanism based on low-parameter non-monotonic activation functions (modifications of ReLU), designed to increase adversarial complexity and protect model internals in transparent-box (white-box) environments. The paper shows heuristics (stochastic transfer and equivalent exchange) and components (Immortal ReLU variants) that improve the convergence of a network with a non-monotonic activation function. Each neuron with such function can emulate up to two standard neurons, which can sometimes reduce the network size by up to 2 times without significant loss of quality.
Текст научной статьи Исследование возможности обфускации нейросетей и функционирования обфусцированных нейросетей в рамках задачи классификации
Развитие нейронных сетей в первую очередь ориентировано на производительность, скорость обучения и вычислительную эффективность, часто оставляя без должного внимания вопросы безопасности. Одной из серьёзных угроз являются атаки на инверсию модели, при которых злоумышленник восстанавливает конфиденциальные входные данные по выходам модели. Это представляет значительный риск для сетей, обученных на закрытых или частных данных. Использование открытых наборов данных снижает данный риск, однако раскрытие чувствительных обучающих примеров всё равно может привести к нарушению конфиденциальности. Один из способов решения этой проблемы — машинное разобуче-ние (machine unlearning), позволяющее выборочно удалять отдельные точки данных без необходимости полного переобучения модели. Это помогает «стереть» чувствительную информацию из модели при сохранении точности. Однако эта техника не применима, если конфиденциальные данные имеют большое значение для принятия правильных решений моделью.
Ещё одной важной проблемой являются атаки уклонения (evasion attacks), при которых входные данные изменяются таким образом, чтобы нейронная сеть выдала неверный результат.
Открытый доступ к моделям машинного обучения увеличивает количество угроз. В случае атак типа white-box (в условиях «белого ящика») злоумышленнику доступна информация о структуре и параметрах модели, тогда как при атаках чёрного ящика он полагается только на наблюдение входов и выходов. Однако обучающая выборка остаётся недоступной, что защищает конфиденциальные и интеллектуально значимые данные. Нарушение этой защиты может привести к утечке личной информации, краже интеллектуальной собственности или другим последствиям успешных атак на модель.
С точки зрения безопасности, знание, заключённое внутри нейронной сети, само же является основным барьером, предотвращающим полную компрометацию системы. Веса и обученные представления служат формой инкапсулированного интеллекта, защищающего информацию, на которой модель была обучена. Поэтому защита этих знаний имеет первостепенное значение для предотвращения несанкционированного использования.
В настоящей работе предполагается безопасная среда обучения, то есть исключаются атаки на этапе обучения, такие как отравление данных или утечка градиентов. В случае нарушения этого предположения возможно извлечение конфиденциальных данных, что приведёт к потере всех прочих мер безопасности.
Предложенный подход к увеличению сложности атак особенно актуален для разработки безопасной логики в открытых системах, таких как децентрализованные платформы (например, Ethereum). Эти системы, отличающиеся своей публичностью и отсутствием централизованного управления, подвержены повышенным угрозам безопасности. Интеграция предлагаемого метода позволяет повысить гибкость системы без ущерба для её устойчивости, особенно в таких компонентах, как умные контракты (smart-контракты). Таким образом, данный подход направлен на усиление защищённости децентрализованных экосистем путём внедрения механизмов, значительно повышающих сложность успешной атаки или манипуляции системой. По аналогии с методами защиты бизнес-логики программного кода, предложенный способ защиты внутреннего знания нейронных сетей (определяющего их поведение) в данной работе называется «обфускацией».
Основной целью данного исследования является разработка и демонстрация метода защиты нейронных сетей от атак на инверсию модели и атак уклонения в процессе инференса в условиях прозрачного доступа (белого ящика). Это достигается за счёт интеграции немонотонной функции активации, которая повышает сложность атак и тем самым усиливает защиту модели от попыток извлечения параметров или манипуляции результатами.
Дополнительным эффектом предлагаемого метода является снижение количества параметров сети на стадии инференса при практически полном сохранении исходной точности, что также может повысить вычислительную эффективность использования модели.
-
2. Связанные работы
-
2.1. Краткий обзор статей
-
2.2. Комментарий к статьям
Существует множество подходов к модификации функции активации, а также методов обучения с использованием изменённой функции активации. В данной работе рассматриваются несколько публикаций, «идеологически близких» к предложенному подходу.
В работе [1] предложена Symmetric-APL — обучаемая (как и обычные параметры) функция активации, обеспечивающая одинаковую выразительность по обе стороны от нуля и способная аппроксимировать любую непрерывную нелинейность, центрированную в нуле. Авторы утверждают, что замена ReLU на S-APL улучшает устойчивость к атакам на величину до 51% в отдельных моделях. Адаптивная параметризация повышает выразительность каждого нейрона, позволяя получать желаемый результат с меньшим количеством нейронов, что улучшает производительность на стадии инференса. Эта работа основана на более ранней [2], в которой была представлена асимметричная функция активации (APL). Ожидание значительного повышения устойчивости к атакам за счёт «обфускации» частично опирается на результаты [1].
В статье [3] представлен метод автоматической настройки функций активации с помощью эволюционного поиска для выявления общих форм и градиентного спуска для оптимизации параметров по всей сети. Работа исследует более широкий и сложный поисковый простор по сравнению с предыдущими методами, адаптируя параметры как пространственно, так и временно, в результате чего обнаруживаются как универсальные, так и архитектурно-специфичные функции.
В статье [4] предложена функция активации /(ж) := |ж|, одинаково обрабатывающая положительные и отрицательные значения. Это улучшает выразительность, но снижает обобщающую способность модели, вызывая флуктуации в точности. Функция менее подвержена переобучению, а её поведение зависит от размера батча (меньшие батчи увеличивают выразительность).
В работе [5] предлагается заменить стандартные функции активации на k-Winners-Take-А11 (k-WTA) — разрывную функцию, нарушающую гладкость градиента в ряде точек входа, с целью усиления защиты от градиентных атак. k-WTA может быть интегрирована в большинство сетей и методов обучения с минимальными накладными расходами. Авторы приводят теоретическое и эмпирическое обоснование того, что разрывы функции мешают эффективному поиску градиента атакующими, при этом не мешая обучению, и устойчиво повышают надёжность как в стандартных, так и в адверсариальных режимах обучения при атаках белого ящика.
В статье [6] предложена функция активации, повышающая устойчивость свёрточных сетей (CNN) к атакам путём внедрения пространственного внимания и зависимости от входных данных. Согласно авторам, данный подход превосходит актуальные функции активации по устойчивости к атакам, не снижая точность на чистых данных.
Данный комментарий преимущественно касается статьи [1] (Symmetric-APL), поскольку рассуждения в нём опираются на идею именно этой работы. Вместе с тем выводы комментария носят более общий характер и могут быть применены к другим связанным работам.
Для начала, следует отметить, что параметры функции активации являются частью архитектуры нейросети. Значительная параметризация функции активации может привести к возможности построения эвристик, основанных на её параметрах, позволяющих эффективнее использовать метод обратного распространения ошибки при атаке. Например, можно попытаться применить эвристику аппроксимации: приближать существующую немонотонную функцию (например, S-APL [1]) монотонной. Поскольку параметры таких функций обучаются, может возникнуть значительная асимметрия (как у ReLU), что делает возможным грубую, но в некоторых случаях полезную аппроксимацию.
Пусть f(ж) — функция с устранимыми разрывами, у которой на непрерывных участках вторая производная существует и равна нулю. Пусть д(ж) — приближённая монотонная версия f(ж), такая что
Vж1, Ж2 G Q, | sign (д(ж1 + 1) - д(ж1)) - sign (д(ж2 + 1) - д(ж2)) | < 1.(1)
Пример эвристики:
ЗЕ>0,(/(ж)-д(ж))2■
< Е
ДД ,„ = к • „д^ж^РМ ' , ж G Г1;5] , аж \ ах аж /1.5 J где f(ж) ~ функция TIma S-ABL [1]. д(ж) - её приближение, ж - вход функции активации, а - стандартное отклонение, к - коэффициент масштабирования, определяющий масштаб отклонения относительно интервала от последней точки излома до нуля, е - мера неточности аппроксим ации.
Поскольку для подобных функций часто используется нормализация входов (особенно для симметричных), логично ограничить вклад в метрику той частью функции, которая расположена ближе к нулю. Вес ошибки аппроксимации при этом пропорционален плотности вероятности из нормального распределения, поскольку именно оно чаще всего используется при нормализации.
Метрика (2) сходится и осмысленна, поскольку
∃
df (ж) ад(ж)
df (ж)
—-— ^ const 1 = с1, аж
аж ’ ад(ж) аж
аж
df (ж) ад(ж)
,f (ж) - ’|ж) = ( лат - ~жкт
const2 = с2, сз = const3 = const1
С4 = ■ С5 =
72^02
----й , 2а2’
с2 ж2
2 С4е
-
• ^2 С 5
<
Е,
lim (С2жД) = Г21 = lim (ДжбД) = lim ( х—^м Де1 с5 J LtoJ х—^м у (2ех с5)‘у х—^“ у
с22жс4
) ж,
- const2,
4жс5ех'2с5
=
= FI = ∞
...
/ 2с3 С4 А
^Х ^8ж2с5еж2С5 J
= 0.
Аппроксимация в (5) корректна, так как число точек излома у функции f(ж) мало, а на остальных участках производная постоянна.
Таким образом, первая задача — минимизировать е. Далее, производится обратное распространение ошибки с использованием градиента от приближённой функции (при этом инференс выполняется на оригинальной функции активации). Это грубая аппроксимация, но она может быть полезной в отдельных случаях, помогая сократить комбинаторную сложность. Следует отметить, что подобная эвристика оправдана лишь при обучаемых функциях активации с выраженной асимметрией формы.
Пример дополнительной эвристики
Sseg
= Ажо
УАж2 + (f (жо + Ажо) - f (жо))2
где жо - начало участка, на котором существует производная, Ажо ~ длина этого участка по оси ж, Sseg - площадь, возможная метрика потенциального потока данных. Она пропорциональна Ажо, поскольку отражает интервал изменения входа, а также гипотенузе, отражающей длину пути функции. Можно было бы ограничиться только гипотенузой, но учёт
Ахо введён по соображению, что при равной длине пути участки с менвшим изменением выходного значения могут соответствоватв более значимым признакам.
Далее, соотношения площадей могут использоваться для оценки вероятных распределений потока данных по областям функции и выбора начальных точек для оптимизационных процедур (например, градиентного спуска) при обратном распространении ошибки.
Можно прийти к выводу, что при параметризации функции активации для противодействия атакам необходимо соблюдать баланс между выразительной мощностью функции и полезностью её параметров для атакующих.
Предложенный в данной работе метод защиты не использует значительной адаптации параметров для повышения выразительности. Единственная задача параметров — реализация пространства, в котором сеть может сходиться, поскольку не все комбинации параметров приводят к сходимости. Таким образом, в рамках предложенного подхода параметры предполагается оставлять неизменными настолько, насколько это допускает факт сходимости сети. Дополнительно минимальная параметризация способствует ускорению инференса.
-
3. Подход3.1. Обобщённое описание
-
3.2. Бессмертный ReLU
В данной работе предлагается несколько вариантов модификации функции, а также методы обучения модифицированной функции. Каждый из предложенных вариантов может иметь свои применения, однако наиболее перспективным представляется последний из них.
Существует надёжный способ усложнения работы метода обратного распространения ошибки — усложнение топологии пространства оптимизации. Увеличение числа параметров действительно повышает сложность на этапе обучения, но может оказаться менее эффективным против атак, если критерии успешной атаки достаточно широки (например, любое входное значение, приводящее к желаемому выходу). Другой способ — использование немонотонной активационной функции — подобно увеличению числа параметров, также усложняет обучение, но делает проведение атак значительно труднее по сравнению с эквивалентным ростом числа параметров (поскольку стандартное обратное распространение ошибки больше не гарантирует достижение результата).
Как известно, при использовании стандартного ReLU во время обучения на некоторых нейронах может стабильно формироваться нулевое значение на всех обучающих данных, что делает невозможным их дальнейшее обучение — это явление называется проблемой «умирающего ReLU» [7].
В данной работе предлагается модификация ReLU, которая использует различные определения для значения функции и для её производной первого порядка.
Функция для вычисления yi задаётся следующим образом:
yi = irelu(st) := max(0,xi).(10)
А функция для вычисления производной задаётся так:
dyt d • irelu(Si) ,. , , . J1 , xi > 0,
=л------ = direlu(xi) :=I dxi dxi {ОС , иначе, h^ = hc I1’ ^ < 0,(12)
I factor, иначе.
где errorx i - текущая ошибка, передаваемая обратно к Тму нейрону; знак сравнения в errorx i < 0 зависит от определения функции потерв (loss) ; в данном случае предполагается, что loss > 0 соответствует необходимости двигатвся в отрицателвном направлении; factor - коэффициент усиления производной в области нуля, предполагается, что factor > 0 и factor ~ 0; hc - постоянная, задающая значение производной в отрицателвной области ReLU, hc G [0, 01; 0,1]; h fr 0 - переопределённое значение производной в отрицателвной области.
Ещё одним важным аспектом реализации данной функции является затухание значения hxiror при обратном распространении из слоя с функцией irelu в другие слои, не поддерживающие переопределение производной (например, при обратном распространении из irelu в Leaky-ReLU). Следует отметитв, что затухание применяется толвко к передаче hfi"0 при распространении ошибки; при локалвной оптимизации весов используется незатухшее значение hfrror. Это можно формализовать следующим образом:
direlu(xj), j G O,j G I, dyj d • irelu(xj) fade • direlu(xj), j G O,j G B,
dx j dx j 1, jGO,X j > 0
0, j / O, X j < 0
где I - слой, its которого в данный момент распространяется ошибка: B - слой, находящийся до I в прямом направлении (в который распространяется ошибка): O - множество нейронов, поддерживающих переопределение производной; fade - коэффициент затухания (0 < fade < 1, при этом fade ~ 1); j G I означает использование производной функции активации нейрона локально (в той же позиции, где она вычисляется).
Таким образом, передача переопределённой производной ограничена лишь теми кластерами слоёв, которые способны использовать переопределение производной в своей функции активации.
-
3.3. Немонотонный ReLU
В данной работе предложено несколько немонотонных модификаций функции ReLU. Первая модификация основана на Leaky-ReLU [8] и определяется следующим образом:
y i = nmrelu(xi) := max(-|xi| + /3, (-|xi| + 3)a), (14)
где y i - выходноe значение г-го нейрона; x i - взвешенная сумма входов г-го нейрона; 0 < a < 1 - параметр затухания Leaky-ReLU (в большинстве случаев a G [0,01; 0,1]); 3 G (0; k) - положительное смещение и одновременно максимальное возможное значение данной функции (где k - разумный предел, зависящий от архитектуры).
Вторая модификация основана на «бессмертном ReLU» (см. определение (10)) и определяется следующим образом:
yi = nmirelu(xi) := max(-|xi| +3, 0). (15)
Стоит отметить, что поведение «бессмертного ReLU» сохраняется в соответствии с ранее приведённым описанием (10).
Предложенные варианты модификации схожи, однако вторая модификация обладает рядом преимуществ: помимо дополнительной сюръективности в отрицательной области и уменьшения числа параметров, она также более предпочтительна при использовании некоторых эвристик обучения.
-
3.4. Обоснование методологии
-
3.5. Подходы к обучению
В зависимости от наличия и положения «долины» функции активации изменяется сложность задачи оптимизации. Если долина расположена таким образом, что результирующая функция становится выпуклой (необязательно строго выпуклой), сеть может сходиться при использовании стандартного метода обратного распространения ошибки. Если же долина приводит к невыпуклости функции, то стандартные методы могут успешно сработать только при удачной инициализации весов и при подаче обучающих данных в «правильном» порядке. Разумеется, не стоит исключать сходимость на выпуклой части невыпуклой функции, но не стоит считать такой вариант достаточно хорошим.
Более того, при сходимости желательно, чтобы использовались обе области немонотонной функции, что способствует повышенной устойчивости к атакам. Почти во всех случаях применения немонотонной функции осуществляется сюръекция, однако преимущество сюръективности на практике реализуется не всегда — если число нейронов, использующих обе области функции, невелико. Именно поэтому атакующий, собрав статистику по используемым диапазонам значений, может обойти усложнение, создаваемое сюръективностью, и достаточно эффективно применять метод обратного распространения ошибки.
Основой метода обучения служит метод обратного распространения ошибки [9]. В «решении» задачи невыпуклой оптимизации методу обратного распространения помогает наличие обучающей выборки, что также даёт возможность применения эвристических приёмов. В настоящее время для решения проблемы неиспользуемой области выходных значений предложены две эвристики: метод «стохастического переноса» и метод «обмена с эквивалентом».
Следует уточнить, что функция nmrelu(s) (14) не содержит долины, тогда как её отрицательное значение (— nmrelu(x)) такую долину имеет. Для рассматриваемых эвристик наличие или отсутствие долины не является принципиальным, однако в зависимости от ситуации это может влиять на качество сходимости.
Эвристика «стохастического переноса» может применяться двумя способами: с зеркальным расположением и без него. В обоих случаях происходит перенос выходного значения нейрона при определённом входе в область с противоположным знаком градиента (случай sign(x) = 0 не рассматривается).
Зеркальное расположение изменяет входные веса Wj при заданном входном значении так, чтобы выходное значение осталось прежним, но рассчитывалось в области с противо положным знаком градиента:
W j = W j -
Е i j
У^ W j i j ,i j G In,W j G W}1,
где I n - множество в ходов нейрона n' Wn - множество весов связей из In.
Схема без зеркального расположения вносит минимально возможные изменения во входные веса W j при заданном входе так, чтобы расчёт происходил в области с противоположным знаком градиента (при этом выходное значение меняется):
W j = W j -
( ^ W j i j + e • sign (^ W j i j
,i j G Inw G W П ,е > 0,e ~ 10 E i j
-5
где e - малая положительная константа, обеспечивающая выполнение переноса.
Важно уточнить, что эвристики «стохастического переноса» применяются на основе анализа распределения попаданий в различные области активационной функции / (х) на репрезентативной выборке обучающих данных. Для каждой области функции на каждом нейроне вычисляется количество попаданий значений х в эту область. Если зафиксировано отсутствие попаданий в какую-либо область, выбирается входной вектор из выборки, значение которого максимально приближено к точке перехода (где меняется знак градиента). Перенос не выполняется, если ближайшее значение х находится слишком далеко от точки перехода — порог определяется условием переноса, чтобы не вносить избыточный «шум»
в веса.
Для эвристики «стохастического переноса» не имеет значения, используется ли вариант немонотонной функции на основе Leaky-ReLU (14) или «бессмертного» ReLU (15). Однако для эвристики «обмена с эквивалентом» выбор функции более критичен.
Эвристика «обмен с эквивалентом» является более сложной и настраиваемой по сравнению с предыдущей. В этом контексте под эквивалентом понимается представление нейрона с немонотонной функцией (14) в виде нескольких нейронов с монотонной функцией, при этом смысл внутреннего представления nmrelu (14) / nmirelu (15) и эквивалента должен быть максимально близким.
Во-первых, необходимо определить базовую функцию, на которой будет построен эквивалент. Для nmrelu (14) эквивалент строится на основе Leaky-ReLU:
yi = relu(sj) := max(aXi,Xi), 0 < a < 1, (18)
где a - параметр затухания Leaky-ReLU (обычно a G [0,01; 0,1]). Во-вторых, пусть нейрон nmrelu определяется как:
y = nmrelu ( wo + У^ xiwi I « S + y, i=1..|L|
где L - текущий слой, содержащий нейроны; wo - смещение (bias); S - шумоподобная ошибка, возникающая из-за проекционного несовпадения между пространством nmrelu и пространством эквивалентного представления.
Далее, для функции на основе Leaky-ReLU (14) эквивалентное представление может быть задано как:
y = relu
( Wq + Xiw{ ] + relu ( - w0 + -Xiwf ] ,
' i=1..|L| ' ' i=1..|L| '
где w? - веса для перво го ReLU-нейрона, ws - для втор ого. Знак у ws имеет номинальное значение, так как может быть нивелирован в процессе обучения. Однако он полезен для начальной инициализации и отражает принцип проекции, описанный далее.
Аналогично, можно построить эквивалентное представление и для нейрона на основе «бессмертного» ReLU (15):
y = irelu ( w? + У^ x ? w? \ + irelu ( - w/ + ^ —Xiwf ).
' i=i..|L| 2 \ i=i..|L| 2
Проекция заключается в том, что для каждого входа Xi из пары relu/irelu выполняется манипуляция весами для получения весов nmrelu / nmirelu'.
w^ = 2 {
w? — w/, |w? I + и|,
spread* 1(w? , w/) > p, spread* 1(w? , w/) < p,
spread*1(w? ,ws) := (max(w? ,ws) — min(w? ,ws)) • sign(w? ws),
wQT = (w? — wQ )/2 — Д
где wfm - i-в входной вес nmrelu/nmirelu', (3 из (14)/(15); spread*1 - первая версия метрики пригодности весов к XOR-подобной задаче; p ~ —10-3 - конетанта (р ^ 1). Её можно задать как ~ —0 ~ —10-10, но требуется осторожность: преждевременная интерпретация веса как подходящего под XOR может быть ошибочной.
Более точной метрикой для XOR-подобных задач, вместо (23), может быть spread*2(w?,ws) := ( m^W?г W~ ) • sign(w?ws), (25)
\max(|w?|, |ws|) + e J где £ ~ 10-8 - малая константа для численной устойчивости. Для ^ в (22) при использовании spread*’2 рекомендуется начинатв подбор с ц ~ -0,5 (так как spread’2 (ж) € (—1; 1)). Эта метрика основывается на соотношении модулей весов, а не на их разности, что может быть полезнее: малые веса на практике могут 6bitb компенсированы! большими входными значениями.
Для эвристики обмена с эквивалентом выбор между relu и irelu важен, когда проекции суммируются по модулю, что используется для топологического решения XOR-подобной задачи.
В случае XOR-подобных ситуаций на relu может быть относительно «трудно» сформировать ноль на выходе эквивалентного представления (например, для 1 ф 1 нужно получить значения с противоположными знаками, которые в сумме дают ноль). Хотя эквивалент обучается хорошо, при проецировании оптимальных весов в немонотонное пространство возникает значительный «шум» 5 из (19), так как оптимальные веса различны в этих пространствах. В немонотонном пространстве оптимальные входные веса:
IB nm
= р • Bnm,Bnm = [Jj ,
... nm w0
' P,
где P из (14), Wnm - матрица весов нейрона с немонотонной функцией, wjm - bias-вес. Эквивалент на основе relu (18) имеет оптимальные веса:
W 1 = р • (1 + ау) • B 1 ,Bf =
Ws = P • (1 + ау) • BS,BS = wo "» = 0,
[-1] •
' •
где а взято из (18), P - некоторый масштабный коэффициент, коррелирующий с (26), у ~ 1,2 - величина, по смыслу близкая к константе для задачи XOR на эквиваленте, основанном на relw, W1 и wf - соответственно матрица весов и смещение для первого монотонного нейрона, W s и w) - аналогично для второго.
Таким образом, проецирование, вероятно, должно происходить до или после достижения оптимальных значений. Важно понимать, что задача эквивалента не в том, чтобы сразу получить финальные веса для немонотонного представления, а в том, чтобы упростить невыпуклую оптимизацию, предоставляя более удачную стартовую точку. Во всех случаях после проекции в немонотонное представление обязательно продолжается обучение в этом пространстве. Это необходимо, поскольку пространства остаются достаточно различными, и полностью устранить «шум» при переходе невозможно — можно только его уменьшить.
Можно заметить, что возникающий при проецировании «шум» может быть уменьшен путём уменьшения а (поскольку у уменьшить нельзя). Однако существенное уменьшение а 'замедляет обучение (поскольку для обучения нейрона в отрицательной области (ж < 0) потребуется больше итераций), а при экстремальном уменьшении ( а ^ 0) возникает проблема «умирающего ReLU».
В качестве решения проблемы выбора а, то есть нахождения баланса между высоким уровнем «шума» и медленным обучением с возможностью частичного переобучения (из-за относительно долгого «воскрешения» нейронов, «застрявших» на ~ 0), предлагается использовать ранее рассмотренный вариант irelu (10) (где формально « а = 0») в качестве основы для эквивалентного представления.
Можно заметить, что эквивалент, основанный на irelu, может быть уточнён. Это дости- гается посредством определения ilrelu (ограниченный irelu) следующим образом:
yi = ilrelu(xi) := max(0, min(xi ,3 )),
dy i dxi
d • ilrelu(xi) dx- i
= dilrelu(xi) :=
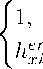
X i > 0 Л X i < /3, иначе ,
h^ = hc 1,
| factor,
(errorxi< 0 Л xi < 0) V (errorxi > 0 Л xi > 3), иначе ,
где 3 из (15); hc, errorxi и factor взяты из (12); очевидно, что обратное распространение ошибки (13) для ilrelu будет дополнено условием с параметром 3 в случаях j / О.
Использование эквивалента ilrelu позволяет более точно аппроксимировать немонотонное пространство nmirelu, что положительно влияет на снижение «шума» (благодаря тому, что значение ilrelu в положительной области x не может превышать 3, так же как и значение nmirelu). Поэтому этот вариант предпочтительнее для эвристики обмена с эквивалентом.
Из принципа проекции ясно, что проекция в nmrelu/nmirelu — сюръективна. Это означает, что нельзя просто взять модель с nmirelu и перевести её в более удобный для обратного распространения эквивалент ilrelu. Но также это означает, что после этапа обучения сети с nmirelu проекция весов в сеть с ilrelu невозможна. Таким образом, атакующий не может использовать эту эвристику в обратную сторону.
Чтобы выполнить проекцию «nmirelu-^ilrelu» (то есть чтобы обеспечить возможность двустороннего обмена), предполагается, что необходимо вычислить разницу между последней проекцией ilrelu-^nmirelu (которая была выполнена до последнего этапа обучения в немонотонном представлении) и текущим обученным представлением nmirelu. Затем нужно применить эти разности весов к варианту ilrelu, с учётом индивидуального пути проекции к nmirelu для каждого входного веса (то есть использовать информацию о том, был ли вес взят с минусом или взят по модулю при проекции).
-
4. Демонстрация
4.1. Обучение на малом наборе данных
Для проведения экспериментов использовался фреймворк собственной разработки, реализованный на C++, который обеспечивает гибкую настройку архитектуры нейросети, поддержку пользовательских компонентов и полный контроль над процессами обучения и инференса. Код и инструкции для воспроизведения экспериментов доступны в репозитории:

а) эквивалент па основе Leaky-ReLU
б) эквивалент па основе ilReLU
Рис. 1. График потерь кросс-эптропии с эвристикой обмена с эквивалентом
Стоит рассмотреть графики на рис. 1, основанные на результатах обучения на выборке с использованием различных эквивалентов и эвристик. Пример задачи, предложенной нейросети (довольно базовый, но показательный), заключался в классификации по 11 классам с использованием всего 11 нейронов (все в выходном слое). Десять классов имели по одному положительному примеру, а одиннадцатый класс - 117 примеров (он должен был выдаваться на выходе, если вход не соответствовал предыдущим 10 классам). Однако класс 11 не учитывался при расчёте точности.
На графике 1а обучается nmrelu (14) с эквивалентом на relu (18) (исходный код данного эксперимента находится в файле «exp_nmlReLU_svsg4.cpp» в репозитории проекта). Мы можем заметить два скачка ошибки - они выделены прямоугольниками. До красного (первый слева) прямоугольника обучается relu. В красном прямоугольнике происходит проекция в nmrelu, при этом используется метрика spread’1 (23). Далее, продолжается обучение nmrelu. Зелёный прямоугольник (справа) - завершение обучения и переход к этапу тонкой настройки nmrelu (когда на вход подаются только 10 классов для достижения точности в 100%). На графике видно явное ухудшение после проекции (это и есть та самая шумоподобная 5), также чётко видно, что nmrelu сходится медленнее. Первоначальное использование relu не только ускоряет обучение, но зачастую является причиной того, что сеть вообще сошлась. Без финальной настройки наблюдалось «катастрофическое переобучение» на 11 класс.
На графике 16 обучается nmirelu (15) с эквивалентом ilrelu (31) (исходный код данного эксперимента находится в файлах «exp_nmlilR.eLU_svsg2.cpp» (spread’1) и «exp_nmlilReLU_svsg3.cpp» (spread’2) в репозитории проекта). При сравнении этого графика с 1а, видно, что эквивалент на ilrelu сходится быстрее, чем на relu - в обоих случаях проекция весов происходила на 1300-й итерации, до этого условия были идентичны, за исключением типа нейронов в эквиваленте. Если на 1а наблюдалось недообучение на момент проекции, то на 16 ситуация ближе к переобучению. Проекция на 16 проводилась с использованием различных метрик обмена с эквивалентом: spread’1(23) для синей (жирной) линии и spread’2(25) для оранжевой (тонкой). Синяя линия почти точно обводит оранжевую (что говорит о совпадении графиков) до момента проекции. После проекции, хотя линии почти совпадают, видно, что spread’1 создаёт менее удачные веса — вносит больше шума (это заметно в прямоугольнике на графике), и сеть после проекции с использованием spread’1 требует больше итераций для сходимости (3500 против 3340 при использовании метрики spread’2). При использовании ilrelu и nmirelu нейросеть сошлась до 100% точности без финальной настройки. В то же время связка relu+nmrelu la требует значительно больше итераций даже без тонкой настройки (точность — около 80%,).
-
4.2. Обучение на наборе данных MNIST
-
5. Заключение
В рамках данного эксперимента было проведено обучение нескольких полносвязных нейронных сетей на наборе изображений рукописных цифр MNIST (разрешение 28 х 28). Исходный код данного эксперимента находится в файлах «exp_ReLU_mnistl.cpp» (обучение ReLU) и «exp_nmlilReLU_mnist2.cpp» (обучение ilReLU и nmiReLU). Цель заключалась в сравнении работы стандартной функции активации Leaky-ReLU и предложенной немонотонной функции активации nmiReLU, применяемой после этапа предобучения с функцией ilReLU. Архитектура всех моделей включала входной слой размерности 784 (векторизованное изображение), за которым следовал скрытый слой переменной размерности N (в зависимости от конфигурации - 32 или 64 нейрона), затем фиксированный промежуточный слой из 16 нейронов, и, наконец, выходной слой из 10 нейронов с функцией активации softmax для многоклассовой классификации (кросс-энтропия).
Обработка данных и гиперпараметры обучения были едины во всех конфигурациях для обеспечения корректного сравнения. Все изображения нормализовались в диапазон значений [0;1], тренировочная выборка перемешивалась перед каждой эпохой для увеличения случайности распределения данных в наборе. Размер батча был установлен равным 64, значительное увеличение приводило к ухудшению точности. Использовался оптимизатор Adam со скоростью обучения 0,001, функция Leaky-ReLU применялась с фиксированным коэффициентом утечки a = 0,01, который также использовался для переопределения градиента в nmiReLU. Максимальное выходное значение [3 у nmiReLU было задано как 8. Обучение проводилось на протяжении 10 эпох для каждой конфигурации.
Были протестированы три конфигурации. В первой сетв обучалась с использованием Leaky-ReLU и первым скрытым слоем размерности N = 64 в течение всех 10 эпох. Во второй конфигурации применялся двухфазный режим: сначала в течение 2 эпох обучалась сеть эквивалента с активацией ilReLU и размером скрытого слоя N = 64, после чего выученные параметры проецировались в немонотоннуго версию сети с функцией nmiReLU и уменьшенным числом нейронов (N = 32), далее обучение продолжалось ещё 8 эпох. При проецировании была использована метрики spread v2 с пороговым значением -0,4. Третья, (контрольная) конфигурация, представляла собой сеть с Leaky-ReLU и с размером скрытого слоя N = 32, обучавшуюся в течение 10 эпох, как и первая конфигурация. Каждая конфигурация была обучена не меньше 1000 раз, после каждого обучения производились атаки Carlini-Wagner L2 (CWL2) и Basic Iterative Method (BIM) на конфигурации 2 и 3.
Тесты показали, что средняя точность классификации в 1-й и 2-й конфигурациях достаточно схожая: 96, 7% в первой (дисперсия 0, 0338), 96, 2% во второй (дисперсия 0, 0387). Контрольная модель с уменьшенным скрытым слоем показала более низкую среднюю точность - 95, 6% (дисперсия 0, 0584). Взвешенная Fl-мера имеет близкий к единице коэффициент корреляции с точностью. В случае немонотонной конфигурации дополнительно рассчитывался процент использования участков функции nmiReLU на данных тестового набора. Усреднённая по всем нейронам эффективность использования областей (утилизация) составила около 12,1% (в среднем по всем результатам обучения), что, несмотря на значительную разницу с максимальным значением в 100%, указывает на активное использование преимуществ немонотонности для увеличения выразительности модели. Отдельные нейроны достигали близких к 100% значений, однако таких нейронов было немного, что может объясняться спецификой задачи и структурой модели.
Исполнение атак CWL2 и BIM на третью конфигурацию в среднем показало успешность выполнения атак в 99, 68% и 99, 99% случаев соответственно. Успешной атака считалась, если ей удалось найти такое входное значение, которому соответствует заранее заданный результат классификации (номер класса), выбираемый случайно перед атакой. Во второй конфигурации удалось значительно снизить успешность атак CWL2 и BIM, в среднем получилось 63, 21% II 70, 92% соответствешю.
Таким образом, двухфазный режим с переходом от ilReLU к nmiReLU позволяет значительно увеличить устойчивость к атакам без значительной потери в качестве (на 0, 5%), если сравнивать с конфигурацией 1, или с увеличением качества (на 0,6%), если сравнивать с конфигурацией 3. Если уделить подбору гиперпараметров больше внимания, то, вероятно, можно добиться более высоких результатов.
В данной работе показано, что разработанные функции активации - iReLU, nmReLU/nmiReLU, ilReLU — могут служить формой «нейронной обфускации», усложняя ландшафт функции потерь и затрудняя прямолинейные градиентные атаки без чрезмерного увеличения числа параметров. Сохраняя минимальные ненулевые градиенты в неактивных зонах (через iReLU/ilReLU) и вводя контролируемую немонотонность (nmReLU/nmiReLU), эти функции активации сохраняют обучаемость и одновременно улучшают защиту от атак. Отдельно стоит заметить, что при инференсе nmiReLU, даже при равных с Leaky-ReLU вариантом размерах слоёв, количество параметров и сложность вычисления будут одинаковыми, так как nmiReLU на стадии инференса имеет только параметр (3, a Leaky-ReLU - только параметр а, и при всём при этом, выразительность пространства nmiReLU выше.
Для упрощения задачи невыпуклой оптимизации были предложены две эвристики. Стохастический перенос стимулирует слабо используемые области активации. Обмен с эквивалентом использует монотонные суррогаты (ReLU или iReLU/ilReLU) для начального обучения, с последующей проекцией в немонотонное пространство с использованием метрик «spread» для оценки пригодности к решению задач XOR-типа. При выявлении
XOR-подобных структур в эквивалентном представлении, проекция в немонотонное пространство позволяет сократить необходимое число нейронов до 2 раз. Демонстрация показывает, что при обучении сети на наборе данных MNIST сеть с nmiReLU даёт более высокую точность, чем сеть с тем же числом параметров на ReLU, помимо этого, сеть nmiReLU имеет в среднем на ~ 37% большую устойчивость к атакам Сarlini-Wagner L2 и на ~ 29% большую устойчивость к атакам Basic Iterative Method.
-
6. Перспективы дальнейших исследований
Эвристика обмена с эквивалентом представляет собой достаточно продвинутый подход с большим потенциалом для дальнейшей разработки. В частности, планируется реализация и тестирование двух дополнительных метрик spread: первая — учитывающая распределение амплитуд, проходящих через веса сети на основе батча (что может существенно повысить точность распознавания XOR-задач); вторая — обучаемая метрика, то есть миниатюрная нейросеть, обученная распознавать XOR-структуры. Также рассматривается возможность использования функций активации со множеством немонотонных областей: f (ж) = nmirelu(((rt — 2 ) mod k) — 2), k ^ 4/3.
