Исследование возможности применения нескольких парадигм программирования в научно-исследовательской работе

Автор: Яблокова Людмила Вениаминовна
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 4-4 т.18, 2016 года.
Бесплатный доступ
В статье предложены и исследованы способы конструирования прикладного программного обеспечения для научно-исследовательской деятельности, основанные на применении нескольких парадигм программирования и соответствующих им паттернов проектирования. Постановку задачи для исследования можно сформулировать следующим образом: необходимо проанализировать основные парадигмы программирования, сформировать представление о способах и мотивации к их применению. Для каждой парадигмы нужно с использованием одного из поддерживающих ее языков представить сценарий иллюстрирующий ситуацию, при которой возможно применение, как самой парадигмы, так и соответствующих ее уровню паттернов. Как результат исследования необходимо определить и применить такую стратегию разработки программ для физико-математических расчетов, которая была бы способна удовлетворить высоким требованиям, предъявляемым к качеству программного обеспечения, создаваемого в рамках научно-исследовательской работы. Исследование проводилось с целью формализации представлений о средствах решения проблем связанных со сложностью, являющейся следствием необходимого уровня гибкости программ, который нужно поддерживать для проведения математических расчетов в области теоретической физики.
Парадигмы программирования, императивное программирование, процедурное программирование, объектно-ориентированное программирование, обобщённое программирование
Короткий адрес: https://sciup.org/148204783
IDR: 148204783 | УДК: 004.43
Stady of the use of several paradigms in scientific research work
The article proposed and investigated ways of designing software applications for research activities based on the use of multiple programming paradigms and their respective design patterns. Formulation of the problem for the study can be summarized as follows: you need analyze the main programming paradigms, to form an idea of the methods and motivation to their use. For each paradigm needed using one of its supporting languages to imagine a scenario illustrating the situation in which the use is possible of both the paradigm and its respective level patterns. As a result, research is needed to identify and implement such a strategy for the development of programs of physical and mathematical calculations that would be able to meet the high requirements for the quality of the software produced in the framework of research work. The study was conducted with the aim of formalizing the notions of means of addressing the problems associated with the complexity which is a consequence of the necessary level of programming flexibility, which should be supported to carry out mathematical calculations in the field of theoretical physics.
Текст научной статьи Исследование возможности применения нескольких парадигм программирования в научно-исследовательской работе
Создание компьютерных систем для научных исследований – дело далеко не простое. По мере того как возрастает их сложность, процессы конструирования соответствующих программных продуктов становятся всё более трудоёмкими, причём затраты на разработку растут экспоненциально. Это относится и к процессу проектирования и реализации подсистем хранения, необходимых для функционирования приложений, использующихся в научной работе. Исследователям, проводящим эксперимент, необходимо получать и обрабатывать достоверную и полную информацию, относящуюся к научным проблемам. Но на процесс подобных исследований негативно влияют обстоятельства, требующие изменения структур хранения данных об исследуемой предметной области или решаемой задаче. Среди них: необходимость тщательного подбора в соответствии с форматом хранения экспериментальных данных, проведение комплексных исследований с использованием разнотипной исходной информации и, как следствие, необходимость ее интерпретации или нормализации для использования в рамках эксперимента. Преодолеть вышеуказанные недостатки можно осуществив выход на качественно новый уровень разработки, создав универсальную модель [1] хранения и обработки разнородной информации. Такая модель хранения могла бы служить основой или определенным паттерном [2] для построения различных информационно- Яблоков Денис Евгеньевич, ведущий инженер-программист Межвузовского научно-исследовательского центра по теоретическому материаловедению.
вычислительных систем и формирования среды накопления формализованных данных для их дальнейшего применения в любых областях экспериментальных наук. Как и в других областях науки, в процессе создания систем такого рода, наиболее подходящей основой является дедуктивный метод. Он обеспечивает декомпозицию сложных понятий на более простые компоненты с математически и семантически обоснованным поведением. Чтобы пояснить, из чего состоят предлагаемые решения и методологии, основанные на фундаментальных понятиях программирования и анализа предметной области, необходимо дать краткий обзор некоторых категорий идей, которые соответствуют этим понятиям.
УНИВЕРСАЛЬНАЯ МОДЕЛЬ ХРАНЕНИЯ
Объекты любого типа и их отношения могут быть описаны в терминах некоторой упрощенной концептуальной модели (рис. 1) основными понятиями которой являются: существительное (Noun), прилагательное (Adjective), глагол (Verb), наречие (Adverb) и дескриптор (Descriptor) – лексическая единица служащая для описания основного смыслового значения и однозначно ставящаяся в соответствие группе ключевых понятий рассматриваемой предметной области.
В случае когда подобные понятия определены, несложно перейти к более конкретному описанию распространяя семантику данной концептуальной модели на объекты, их аттрибуты (рис. 2), отношения между объектами и атрибуты отношений (рис. 3), применяя объектно-реляционный подход [3]. Суть этого подхода состоит в том, что при сохранении реляционного ядра
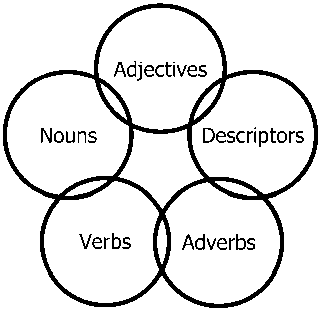
Рис. 1. Диаграмма универсальной модели данных
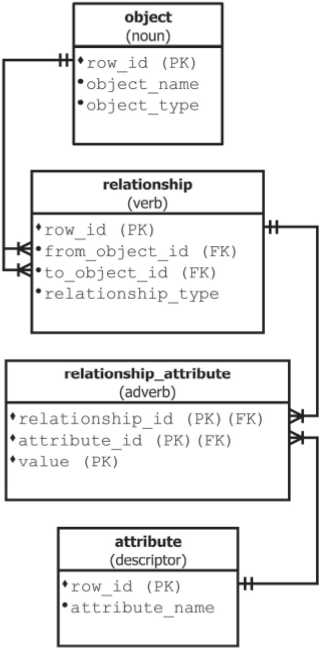
Рис. 3. Объектно-реляционный подход. Атрибуты отношений объектов.
системы хранения она наращивается более или менее удачными объектными надстройками. В качестве таких надстроек могут выступать, и расширяемая пользователем система типов, и средства описания иерархически взаимосвязанных данных, такие как наследование или композиция.
Этот пример является очень упрощенным, но, в тоже время, он может быть достаточно общим, чтобы поддерживать большинство приложений и обеспечивать добавление данных любого типа без указания конкретных имен таблиц или полей, которые необходимы при использовании реляционной модели данных в чистом виде [4]. В дополнение к этому важно отметить, что при использовании универсальной модели становится
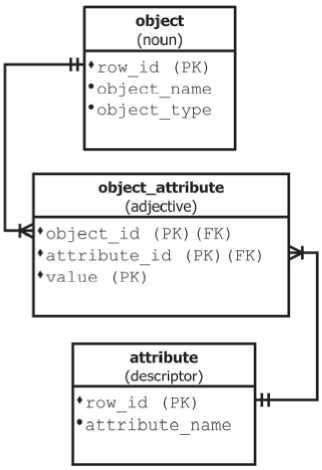
Рис. 2. Объектно-реляционный подход. Атрибуты объектов возможным ввод информации структура которой не определена заранее, а изменение структурных связей типа «сущность-аттрибут», «сущность-сущность» или «отношение-атрибут» может производиться во время работы приложения.
КЛАССИФИКАЦИЯ ДАННЫХ
Классификация [5] является наиболее простой и одновременно наиболее часто решаемой задачей универсальной модели хранения данных. Результат проведения классификации – это совокупность признаков, характеризующих группы исследуемых объектов как классы, к которым можно отнести новый объект, сохраняя общую концепцию, определяющую сходства и различия, а также другие особенности, уже классифицированной или вновь поступающей и анализируемой информации. По сути, классификацией является любое системное распределение объектов, явлений или понятий по каким-либо существенным признакам, выбранным для удобства их представления и обработки. Таким образом, классифицированная информация может быть представлена как упорядоченное по некоторому принципу множество абстрактных или конкретных сущностей, которые имеют сходные классификационные признаки (одно или несколько свойств), отобранные для определения критериев общности в описании, поведении или каких-либо других измерениях исходных неструктурированных данных. Обычно инструменты классификации разделяют по способу их воздействия на классифицируемый элемент информации. Например, возможна организация естественной классификации, которая может проводиться по существенным признакам, характеризующим общность предметов, понятий или явлений.
Предметная область, при этом, описывается элементарными единицами данных, соответственно относящихся к некоторым примитивам, перечень которых априори установлен (рис. 4). Основными понятиями при этом являются: «Мета-тип», «Тип объекта», «Объект».
Любой объект рассматривается как чистая абстракция [9], без привязки к какой-либо предметной области. Спецификация атрибутов объекта, согласно используемым объектно-ориентированным надстройкам для реляционной модели хранения, производится на уровне его типа, сущность «object_type». Семантика хранения предполагает, что каждый тип объекта наследует какому-либо базовому типу «meta_type», выраженному в терминах элементарных примитивов определяющих смысловой контекст как признак для возможной классификации всех дочерних элементов данных. Особое внимание нужно обратить на поле «parent_row_id» в описании сущности «object_type». Его предназначение, в создании древовидных иерархических структур, что можно рассматривать как эмуляцию множественного наследования.
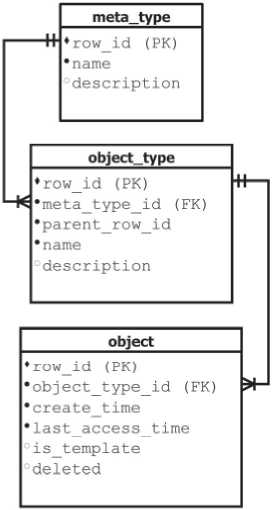
Рис. 4. Типизация данных. Фрагмент ER-модели
Также возможно применение искусственной или вспомогательной классификации, которая производится по внешнему или стороннему признаку и служит для придания множеству исследуемых элементов данных необходимого критерия упорядоченности. Такая классификация легко может быть выражена через категорирование, когда категории обеспечивают необходимый уровень косвенности, при определении критериев общности для элементов информации вне зависимости от их принадлежности к конкретному классу. Основными понятиями при этом становят- ся: «Тип категории», «Категория», «Подчиненная категория» и «Присоединенная категория» (рис. 5). Любой объект может быть связан через свой тип с одной или несколькими категориями, что делает возможным при анализе или декомпозиции получение представления о его структуре и свойствах в терминах множества связанных с ним категорий (рис. 6). Каждая категория (сущность «category») наследует определенному типу (сущность «category_type»), являющему своеобразным дескриптором для иерархии категорий. Сами же иерархии могут быть созданы как древовидные структуры (поле «parent_row_id» в описании сущности «category»), что с точки зрения структурной целостности можно интерпретировать как эмуляцию композиции или агрегирования [5]. Присоединенные категории (сущность «linked_category») позволяют проводить ассоциацию между категориями, находящимися на разных уровнях иерархии или же устанавливать взаимосвязь с категориями, располагающимися в других, контекстуально связанных иерархиях.
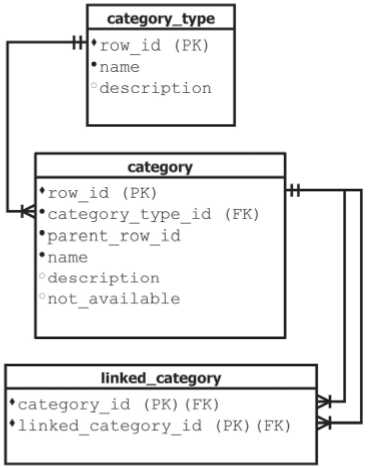
Рис. 5. Категорирование данных. Фрагмент ER-модели
Примером внешней классификации служит периодическая таблица химических элементов, где механизм категорирования может быть применен для указания принадлежности конкретного элемента к той или иной группе, например, щелочных металлов, галогенов и т.д.
Применение механизма типизации позволяет хранить информацию об объектах с подобным поведением и рассматривать их отношения как иерархию по принципу “от общего к частному”. Применение категорирования позволяет хранить информацию об объектах, используя понятия агрегирования и композиции, а их отношения рассматривать по принципу “от целого к его части”.
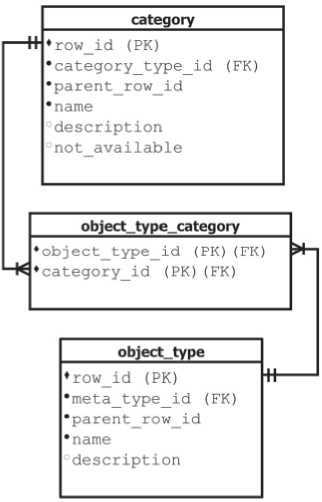
Рис. 6. Категорирование типов объектов. Фрагмент ER-модели
Структура хранилища, построенного по принципам универсальной модели данных, логически может быть разделена на несколько основных взаимосвязанных составляющих. К ним относятся: инструменты классификации (типизация, категорирование), экземпляры и типы объектов (с возможностью назначения каждому типу определенного набора атрибутов), отношения объектов (позволяющие специфицировать типы отношений и значения соответствующих атрибутов). Все это делает возможным применение предлагаемой универсальной модели данных в различных областях научных исследований. Это могут быть задачи из области теоретической или экспериментальной химии связанные с конструированием и структурным анализом новых веществ, классификацией и систематизированным представлением данных о типах химических соединений, предсказания химических и физических свойств у кристаллических структур. Кроме того, во многих задачах из области физики предлагаемая универсальная модель может использоваться для хранения разнородной информации о результатах экспериментов с различным уровнем детализации или быть источником данных для построения математических моделей при проведении исследований. К таким задачам можно отнести анализ, распознавание и пространственную классификацию изображений, повышение чувствительности оптических датчиков и т.п.
ПРИМЕРЫ РЕАЛИЗАЦИИ
Далее приводятся примеры кода из DDL-скрипта для создания базы данных использующей универсальную модель хранения информации.
Пример кода создания таблицы мета-типов, т.е. набора элементарных примитивов, относящихся к некоторым внутренним понятиям предметной области, перечень которых априори установлен.
CREATE TABLE IF NOT EXISTS meta_type ( row_id uuid NOT NULL
DEFAULT uuid_generate_v4(), name varchar (128) NOT NULL , description text, CONSTRAINT meta_type_pkey
PRIMARY KEY (row_id), CONSTRAINT meta_type_uindex
UNIQUE (alias) );
Пример кода создания таблицы типов объектов, т.е. перечня концепций определяющих некоторую совокупность свойств, отличающих их владельца от других сущностей, не содержащих идентичный набор свойств.
CREATE TABLE IF NOT EXISTS object_type ( row_id uuid NOT NULL
DEFAULT uuid_generate_v4(), meta_type_id uuid NOT NULL , parent_row_id uuid NOT NULL , name varchar (128) NOT NULL , description text, CONSTRAINT instance_type_pkey
PRIMARY KEY (row_id), CONSTRAINT instance_type_fkey
FOREIGN KEY (meta_type_id)
Список литературы Исследование возможности применения нескольких парадигм программирования в научно-исследовательской работе
- Кун T. Структура научных революций. С вводной статьей и дополнениями 1969 г. М.: Прогресс, 1977. 300 с.
- Stroustrup B. The C++ Programming Language. U.S. Addisson-Wesley, 2013. 1368 p.
- Chivers I. Introduction to Programming with Fortran. Switzerland: Springer, 2012. 621 p. DOI 10.1007/978-0-85729-233-9.
- Фаулер М. Рефакторинг. Улучшение существующего кода. Санкт-Петербург: Символ-Плюс, 2003. 432 с.
- Макконнелл С. Совершенный код. М.: Питер, 2007. 893 с.
- Гамма Э. Приемы объектно-ориентированного проектирования. М.: Питер, 2006. 368 с.
- Головашкин Д. Л., Яблокова Л.В. Совместное разностное решение уравнений Даламбера и Максвелла. Одномерный случай//Компьютерная оптика. 2012. Т. 36, №4. C. 527-534.
- Golovashkin D.L., Vorotnikova D.G. Long vectors algorithms for solving grid equations of explicit difference schemes//Computer Optics. 2015. Vol. 39(1). P. 87-93.
- MATLAB. The Language of Technical Computing. URL: http://www.mathworks.com/help/matlab/index.html (дата обращения: 12.03.16).
