Эффективная интеграция операций машинного обучения в образовательные и исследовательские процессы

Автор: А. А. Зарубин, Н. М. Редругина, В. Е. Дрепа
Журнал: Современные инновации, системы и технологии.
Рубрика: Прикладные вопросы и задачи применения систем и технологий
Статья в выпуске: 4 (4), 2024 года.
Бесплатный доступ
В данной статье рассматриваются возможности и преимущества внедрения операций машинного обучения в научно-образовательных учреждениях, с акцентом на университетскую инфраструктуру, где сочетаются задачи образования, научных исследований и разработки. Описаны ключевые принципы машинного обучения, такие как автоматизация жизненного цикла моделей машинного обучения, эффективное управление вычислительными ресурсами и поддержка различных сред выполнения. Рассматриваются вопросы рационального использования ресурсов, включая виртуализированную кластеризацию для распределения задач между доступными системами. Особое внимание уделено разработке и внедрению лабораторных комплексов, реализованных на базе Jupyter Notebooks, которые предоставляют интерактивные и гибкие средства для выполнения учебных и исследовательских задач. Описываются преимущества использования готовых сред разработки, таких как Jupyter Lab и библиотеки для машинного обучения, позволяющие студентам и исследователям сосредоточиться на содержательной части экспериментов. Также обсуждаются практические аспекты внедрения машинного обучения в университетах, включая поэтапное внедрение и важность расширения таких решений на всю организацию, а не только на отдельные кластеры. В статье подчеркивается необходимость системного подхода для обеспечения гибкости, масштабируемости и эффективности использования ресурсов в рамках научных и образовательных процессов.
Машинное обучения, ML Ops, решения open-source, образование, среды разработки, управление вычислительными ресурсами.
Короткий адрес: https://sciup.org/14131311
IDR: 14131311 | DOI: 10.47813/2782-2818-2024-4-4-0215-0226
Текст статьи Эффективная интеграция операций машинного обучения в образовательные и исследовательские процессы
DOI:
Проекты, связанные с искусственным интеллектом и машинным обучением, требуют сложных и многослойных инструментальных сред, обеспечивающих эффективную разработку, развёртывание и сопровождение моделей. Для этого необходимо учитывать специфику потребностей различных организаций, будь то крупные компании, университеты или исследовательские центры.
В рамках научно-образовательных задач университета разрабатываются образовательные программы и курсы, реализуются научные и научно-технические проекты, связанные с искусственным интеллектом (ИИ) и машинным обучением (Machine Learning, ML, МО), результатом которых являются операции машинного обучения (MLOps).
MLOps [1] — это подход к автоматизации и управлению жизненным циклом моделей машинного обучения и включает в себя следующие задачи:
-
• управление, автоматизация сбора, мониторинг качества данных;
-
• автоматизация разработки и тестирования моделей машинного обучения;
-
• обеспечение актуальности моделей, контроль за изменениями данных;
-
• масштабирование вычислительных мощностей, развёртывание на облачных платформах или локальных кластерах.
MLOps требует комплексного набора инструментов и инфраструктуры, которые сильно варьируются в зависимости от требований по внедрению (от масштабных коммерческих проектов к базовым задачам обучения).
В коммерческом секторе исследования часто ограничены проверкой гипотез в рамках продукта. Существует заинтересованность в быстрой разработке решений, что требует сложных и надёжных инфраструктур для управления жизненным циклом ML-моделей. Отсюда и возможность инвестировать значительные средства в создание собственной инфраструктуры для ML [2] и поддержания её на высоком уровне (собственные вычислительные кластеры, использовать специализированные решения для хранения и обработки данных, сложные системы мониторинга, автоматизации и масштабирования).
ПРИМЕНЕНИЕ
В рамках данного исследования, рассматривается внедрение инфраструктуры в работу университета. Очевидно, что значительная часть ресурсов направлена на обучение студентов [3]. Основная задача — предоставить студентам доступ к современным инструментам машинного обучения, обучить их основам работы с ML и дать возможность проводить эксперименты. Для этого необходимы простые, доступные и гибкие решения, которые могут быстро настраиваться и не требуют сложной инфраструктуры. Часто выбор делается в пользу open-source решений и облачных платформ.
Помимо образовательной деятельности, имеются исследовательские проекты, которые направлены на изучение новых подходов, экспериментирование и публикацию научных результатов, а не на создание конечных продуктов для рынка.
Количество и разнообразие средств разработки постоянно увеличивается и предлагаемые продукты [4] затрагивают различный функционал как отдельных модулей, так и целой инфраструктуры.
Имеются среды для разработки и обучения моделей, где пользователи создают и тренируют модели машинного обучения. К таким решениям относятся такие инструменты как Jupyter Notebooks, локальные интегрированные среды разработки IDE (например, PyCharm, VS Code), предоставляющие доступ в том числе к ML-библиотекам (TensorFlow, PyTorch, Scikit-learn).
Системы управления данными (DataOps) позволяющие организовать хранение и управление большими объемами данных, используемых для обучения моделей. Для данного функционала можно рассматривать DVC (Data Version Control), Pachyderm для мониторинга наборов данных. DataOps работать как с локальными базами данных, облачными решениями (Google Cloud Storage, AWS S3, Azure Blob Storage), так и с распределенными файловыми системами (HDFS).
Университетская инфраструктура должна поддерживать как локальные ресурсы (например, GPU-серверы), так и облачные решения (с распределёнными вычислениями (Kubernetes, Spark).
Для воспроизводимости и успешной работы моделей важно иметь инструменты, которые позволяют отслеживать все этапы их жизненного цикла, выбор может быть сделан в пользу:
-
• MLflow или Kubeflow — для управления метаданными экспериментов
-
• TensorBoard, Comet.ml — для визуализации и анализа результатов обучения моделей.
ИНСТРУМЕНТЫ И МЕТОДЫ РАЗРАБОТКИ
Университеты, как правило, работают в условиях ограниченного бюджета и ресурсов. Это влияет на выбор инструментов и технологий, и зачастую предпочтение отдаётся open-source решениям и облачным сервисам, которые могут предложить бесплатные или недорогие учебные тарифы. Также университеты часто используют распределённые вычисления или локальные кластеры, которые требуют меньших затрат на оборудование. Так же обоснованием выбора открытых решений open-source является то, что они дают возможность адаптировать платформы под конкретные требования организации и интегрировать их в уже существующую инфраструктуру.
Система автоматически выделяет необходимое количество CPU, GPU, памяти и других ресурсов, избегая простаивания оборудования. Это важно с точки зрения долгосрочного планирования, так как гарантирует максимальную утилизацию ресурсов что позволяет избежать перегрузок и нецелевого использования, сохраняя при этом баланс между потребностями пользователей и наличием вычислительных мощностей.
Ориентируясь на потребности и инфраструктуру университета, фокус направлен на архитектуру и структуру системы MLOps с учётом особенностей образовательной, научной и деятельности разработки. Это три ключевых "кита", на которых строится университетская экосистема машинного обучения.
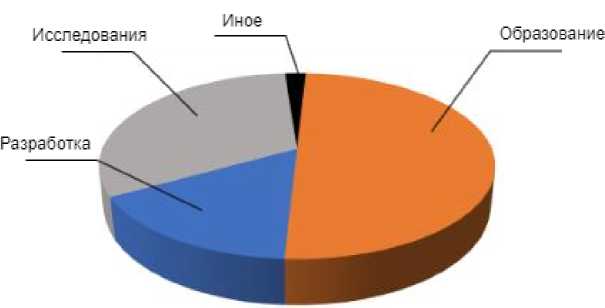
Рисунок 1. Три «кита» инфраструктуры университета.
Figure 1. Three "whales" of the university's infrastructure.
Предлагаемое решение предлагает интеграцию, которая позволяет программной платформе эффективно управлять распределением вычислительных ресурсов для разработки моделей и решений задач МО. Платформа будет поддерживать выполнение в различных средах, включая физические серверы («чистое железо»), виртуальные машины и контейнеризированные среды, что обеспечивает пользователям гибкость в зависимости от их требований и сложности задачи.
Виртуализация позволяет абстрагироваться от физической структуры вычислительных ресурсов, обеспечивая эффективное использование процессорных мощностей, памяти и графических процессоров за счет агрегирования этих ресурсов в единый кластер. Это решение предоставляет возможность эффективного использования оборудования и обеспечения балансировки нагрузки между разными пользователями и задачами, что поддерживает требования к инфраструктуре университета при ограничениях в ресурсах [5].
Основой и технологической новизной данного подхода является виртуализация вычислительных ресурсов на уровне кластера, что позволяет платформе динамически перераспределять мощности в зависимости от текущих потребностей пользователя. В этом процессе платформа анализирует запросы на обучение моделей и выделяет необходимый объем вычислительных мощностей, под решение задач МО [6].
В зависимости от сложности задачи и объема параллельных вычислений платформа выделяет соответствующее количество процессорных ядер (CPU) для оптимизации процесса обучения моделей.
Система анализирует требования к объему данных и резервирует необходимый объем оперативной памяти (RAM), чтобы избежать «узких мест» в производительности. Для моделей, таких как трансформеры или рекуррентные нейронные сети (RNN) это несет высокую значимость.
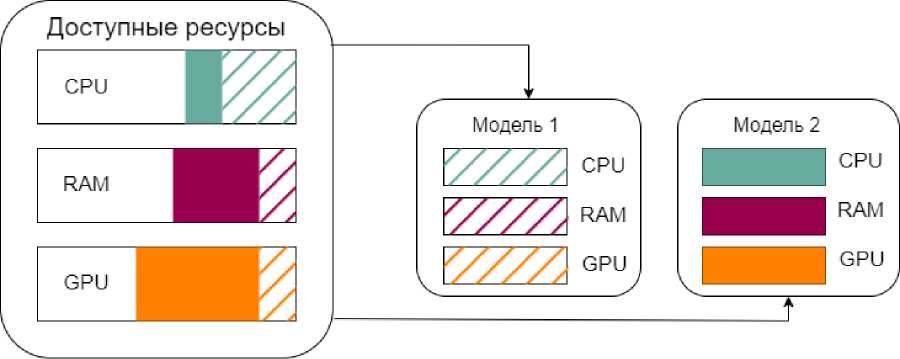
Рисунок 2. Распределение ресурсов для моделей.
Figure 2. Allocation of resources for models.
Поскольку графические процессоры значительно увеличивают скорость параллельных операций, их использование является основным способом ускорения вычислений. Это задачи с высокой интенсивностью вычислений, таких как обучение свёрточных нейронных сетей (CNN) или моделей глубокого обучения, требующих большого количества итераций [7].
РЕЗУЛЬТАТЫ
Разработанное решение схематично изображено на рисунке 3, за основу которого взята платформа Backend.AI. [8] Одной из ключевых особенностей платформы является механизм агрегации и распределения ресурсов, она подключает и объединяет ресурсы различных систем. Эта объединенная инфраструктура, из которой платформа динамически распределяет вычислительные ресурсы для каждого пользователя и задачи. Распределение задач между системами происходит с учетом их загруженности, специфики задачи и требуемых ресурсов (например, количество процессорных ядер, объем памяти или доступ к GPU). Это гарантирует рациональное использование оборудования: задачи получают оптимальный объем ресурсов без избыточного выделения, что особенно важно в условиях ограниченных университетских вычислительных мощностей.
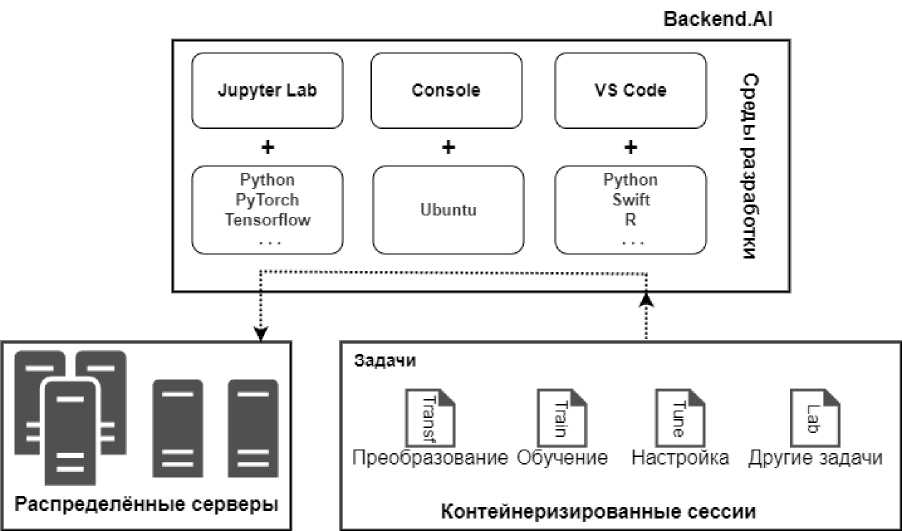
Рисунок 3. Схема предложенного решения.
Figure 3. Scheme of the proposed solution.
Исследователи могут работать в удобных им средах выполнения, таких как Jupyter Notebooks, используя Backend.AI для запуска кода [9-10]. Для данного проекта им нужно обучить модели на основе популярных фреймворков машинного обучения, таких как TensorFlow и PyTorch. В Backend.AI все необходимые библиотеки и зависимости уже предустановлены, что избавляет исследователей от необходимости тратить время на настройку окружений.
Одной из задач разработки было реализовать среду для выполнения студентами лабораторных работ по ИИ и МО. Для выполнения лабораторных работ, разрабатываемый комплекс реализует распределённую систему управления вычислительными ресурсами, где на каждый сервер устанавливается агент. Эти агенты обеспечивают взаимодействие с системой и управляют выделением ресурсов, таких как процессорные ядра (CPU), оперативная память (RAM) и графические процессоры (GPU), а также осуществляют запуск Docker-контейнеров для выполнения задач пользователей.
Каждый контейнер представляет собой изолированное вычислительное окружение с предустановленными инструментами и библиотеками, что упрощает процесс подготовки среды для студентов и исследователей. Внутри контейнеров уже настроены популярные инструменты для анализа данных и машинного обучения, такие как Jupyter Lab, который является интерактивной средой для написания и выполнения кода, а также такие библиотеки, как PyTorch, используемые для обучения и разработки моделей глубокого обучения.
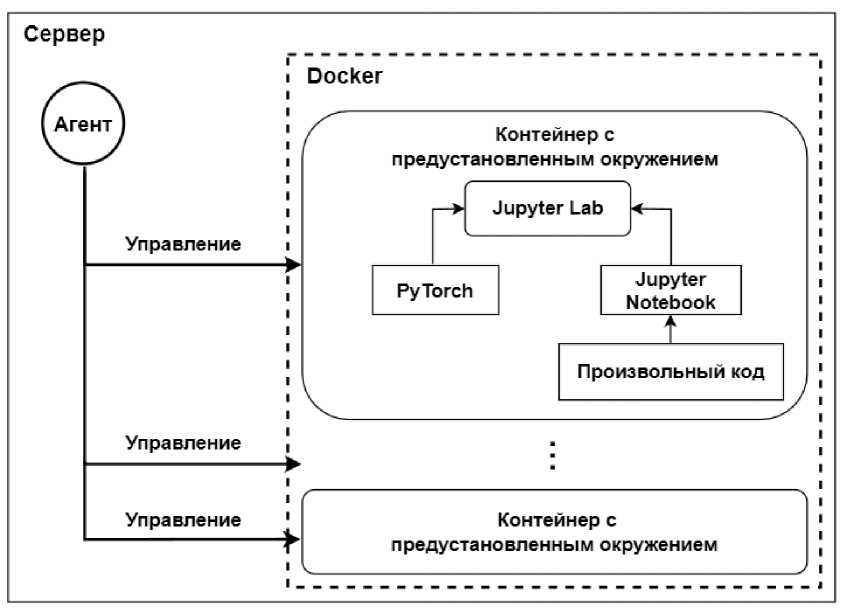
Рисунок 4. Комплекс для обеспечения лабораторных работ.
Figure 4. Complex for laboratory work.
Пользователи могут запускать свои Jupyter Notebooks с произвольным кодом, используя уже установленные библиотеки и фреймворки [11]. Это позволяет сосредоточиться на решении исследовательских задач, не тратя время на настройку окружения или установку необходимых зависимостей.
Блоки кода, встроенные в Notebooks, могут быть выполнены в любом порядке, что позволяет пользователю гибко выбирать последовательность выполнения задач в зависимости от их потребностей и уровня подготовки.
Вся инфраструктура спроектирована таким образом, чтобы поддерживать быструю и гибкую настройку контейнеров, соответствующую требованиям конкретных лабораторных работ или исследовательских проектов.
ЗАКЛЮЧЕНИЕ
Внедрение MLOps-подходов в научно-образовательных учреждениях становится важнейшим элементом в развитии как учебных, так и исследовательских процессов, что позволяет университетам значительно выиграть от применения MLOps обеспечив эффективное распределение ресурсов и улучшив взаимодействие между этими направлениями.
Стоит отметить, что внедрение MLOps должно быть постепенным. Для успешного перехода важно поэтапное развертывание, начиная с тестирования и внедрения отдельных инструментов и решений, что позволит наладить процессы, выработать стандарты и оптимизировать ресурсы. Поэтапное внедрение также помогает адаптировать систему к специфике университета, учитывая особенности учебных программ и исследовательских проектов.
Для достижения максимального эффекта MLOps следует развертывать на всю научнообразовательную организацию, а не ограничиваться только отдельными кластерами и подразделениями. Это обеспечит сквозное управление процессами, унификацию стандартов работы с моделями и ресурсами, а также повысит общий уровень автоматизации в организации.
