Эволюции эвристик для синтеза селекции в генетическом алгоритме

Автор: Кораблева А.А., Становов В.В.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.27, 2026 года.
Бесплатный доступ
Предлагается метод автоматического проектирования операторов селекции для генетического алгоритма, основанный на подходе Evolution of Heuristics (EoH), который объединяет возможности больших языковых моделей (LLM) и эволюционного поиска. Проектирование селекции проводилось на трех задачах псевдобулевой оптимизации, а тестирование на 17 функциях из набора IOHprofiler. Проводились два эксперимента с явным знанием о типе решаемой задачи и без него. В качестве языковой модели использовалась DeepSeek-Coder-V2, которая была локально развернута с помощью фреймворка Ollama. Качество спроектированных эвристик определялось на основании сравнения с результатами стандартной ранговой селекции. Проведено сравнение качества полученных решений с классическими схемами селекции (турнирной, пропорциональной, ранговой), а также с методом FunSearch, ранее применявшимся для генерации новых реализаций ранговой селекции. Сравнение различных эвристик проводилось по множеству запусков на каждой из 17 задач с помощью непараметрического статистического теста Манна – Уитни. Было показано, что автоматически спроектированные эвристики обладают уникальными свойствами, причем отсутствие информации о типе и структуре решаемой задачи привело к большему разнообразию сгенерированных решений. А именно в одном из запусков спроектированный код без информации о типе задачи выбирает особей, чья приспособленность отличается от максимальной менее чем на половину расстояния от максимальной приспособленности до медианной. Иными словами, это вариант турнирной селекции с адаптивным размером турнира, основанным на распределении качества. Наличие информации о типе решаемой задачи приводило к тому, что языковая модель генерировала типовые известные решения, в частности варианты простой турнирной селекции. Предложенный подход может быть применен и для других задач автоматического проектирования алгоритмов целиком или в виде компонентов алгоритмов.
EoH, генетический алгоритм, селекция, FunSearch, LLM, IOHprofiler, гиперэвристики, автоматическое проектирование алгоритмов
Короткий адрес: https://sciup.org/148333105
IDR: 148333105 | УДК: 519.87 | DOI: 10.31772/2712-8970-2026-27-1-21-32
Evolution of heuristics for selection synthesis in a genetic algorithm
A method for the automatic design of selection operators for a genetic algorithm is proposed, based on the Evolution of Heuristics (EoH) approach, which integrates the capabilities of Large Language Models (LLMs) and evolutionary search. The design of selection operators was carried out on three pseudo-Boolean optimization problems, and testing was performed on 17 functions from the IOHprofiler benchmark set. Two experimental setups were considered with and without explicit knowledge of the type of problem being solved. The language model used was DeepSeek-Coder-V2, which was deployed locally using the Ollama framework. The quality of the designed heuristics was determined based on the comparison with the results of standard rank selection. The quality of the obtained solutions is compared with classical selection schemes (tournament, proportional, and rank-based), as well as with the FunSearch method, previously used to generate new implementations of rank-based selection. A comparison of various heuristics was carried out for multiple runs on each of the 17 tasks using the nonparametric Mann-Whitney statistical test. It has been shown that automatically designed heuristics have unique properties, and the lack of information about the type and structure of the problem being solved has led to a greater variety of generated solutions. Namely, in one of the launches, without information about the type of task, the designed code selects individuals whose fitness differs from the maximum by less than half the distance from the maximum fitness to the median. In other words, it is a variant of tournament selection with an adaptive tournament size based on the distribution of quality. The availability of information about the type of problem being solved led to the fact that the language model generated typical known solutions, in particular, variants of simple tournament selection. The proposed approach can be applied to other tasks of automatic design of algorithms as a whole or components of algorithms.
Текст научной статьи Эволюции эвристик для синтеза селекции в генетическом алгоритме
Large Language Models (LLM) – это тип моделей машинного обучения, обученных на огромных корпусах текстовых данных для предсказания и генерации последовательностей текста. Они обладают способностью понимать инструкции на естественном языке и трансформировать их в программный код или алгоритмические структуры.
В контексте автоматического создания эвристик LLM используются для генерации новых вариантов функций, операторов или компонентов алгоритмов на основе текстового описания задачи и существующих решений. После генерации вариантов моделью LLM, эволюционный процесс выбирает наилучшие реализации по заранее заданной функции приспособленности, что позволяет автоматически синтезировать эффективные эвристики без ручного кодирования [1; 2].
Такой подход сочетает гибкость LLM с проверкой качества решений через заранее заданный метод оценки, позволяя находить нестандартные и эффективные алгоритмические решения.
Одним из перспективных направлений является использование LLM для разработки гиперэвристик – высокоуровневых стратегий, которые управляют поиском решений в задачах оптимизации.
Генетические алгоритмы (ГА) – классический метод эволюционных вычислений, вдохновленный принципами естественного отбора [3]. ГА широко применяются в задачах оптимизации, машинного обучения. Основная сложность применения ГА заключается в подборе параметров и настройке операторов эволюции (селекция, скрещивание, мутация). Неправильная настройка может приводить к преждевременной сходимости или снижению эффективности поиска.
Цель данной работы состояла в исследовании креативности LLM при разной степени информированности о типе исследуемой задачи. В частности, рассматривалась эволюция эвристики селекции в генетическом алгоритме – поиск такой функции селекции, которая будет лучше управлять процессом эволюции и повышать эффективность ГА. Эта идея реализуется через фреймворк EoH – Evolution of Heuristics [4], в которой LLM помогает синтезировать и улучшать код эвристик, а генетический алгоритм оценивает их качество.
Генетический алгоритм и подходы автоматической генерации эвристик
Генетический алгоритм представляет собой эвристический метод оптимизации, заимствующий идеи из биологии, такие как коллективный поиск оптимума с использованием популяции особей, а также представление и передачу генетической информации через специальные операторы. Алгоритм начинается с формирования начальной популяции, где каждая особь кодируется в виде генотипа – числового или бинарного вектора, представляющего потенциальное решение задачи. Для каждой особи вычисляется фенотип, т. е. реальное значение переменных задач, и функция приспособленности, отражающая качество решения. На основе этих значений осуществляется селекция – отбор родителей для следующего поколения. Наиболее распространённые методы селекции: турнирная, пропорциональная и ранговая. Затем применяется оператор скрещивания, который комбинирует гены родителей для создания новых особей (потомков), после чего к потомкам могут применяться мутации, вносящие случайные изменения и поддерживающие генетическое разнообразие. Популяция обновляется, и процесс повторяется заданное число итераций или до достижения критерия сходимости [5].
Оператор селекции определяет, какие особи будут выбраны для порождения потомков на основе их приспособленности. Более приспособленные особи имеют более высокую вероятность сохранения своих генов в следующем поколении [6].
EоH является реализацией концепции LLM4AD. Large Language Model for Algorithm Design – это исследовательская платформа, предложенная Liu et al. [7], предназначенная для автоматизированного проектирования алгоритмов с использованием LLM в сочетании с эволюционными и обучающими методами. Её основная цель – научить LLM не просто генерировать код, а эволюционировать алгоритмы, улучшая их производительность на основе обратной связи от системы тестирования.
EoH осуществляет совместную эволюцию “мыслей” (thoughts) – текстовых описаний принципов эвристик и соответствующих им реализаций в коде. Для генерации и модификации эвристик используется LLM в составе эволюционного цикла, включающего пять стратегий генерации: две исследовательские (E1, E2) и три модифицирующие (M1–M3) [8].
Операторы E1, E2 направлены на улучшение существующих идей (реализаций), т. е. берут текущие программы и «мысли» из популяции и генерируют новые варианты на основе этих известных хороших решений. Операторы M1–M3 ориентированы на внесение разнообразия, создают новые варианты функций или идей, слегка модифицируя существующие, чтобы исследовать новые области пространства решений. Эти стратегии моделируют процесс генерации идей человеком, их уточнения и упрощения, обеспечивая как исследование новых концепций, так и эксплуатацию перспективных решений.
Эксперименты на задачах комбинаторной оптимизации Online Bin Packing, Traveling Salesman Problem и Flow Shop Scheduling показали, что EoH превосходит классические и современные автоматические методы, включая FunSearch, обеспечивая высокое качество решений при существенно меньших вычислительных затратах [4].
Алгоритм FunSearch представляет собой родственную концепцию. FunSearch – это метод автоматического поиска и эволюции функций или операторов, который также сочетает в себе возможности LLM и случайного поиска. Его основная идея состоит в том, что LLM генерирует новые версии функций или компонентов алгоритма на основе текстовых описаний задачи и существующих решений, отбирает наилучшие варианты по заданной целевой функции [9].
FunSearch и EoH являются схожими по концепции подходами, но обладают рядом существенных отличий. [10]. Преимуществами EoH над FunSearch является наличие полноценного эволюционного алгоритма с популяцией и эволюционными операторами, а также наличие «эволюции мыслей», а не только кода.
Для демонстрации эффективности подхода можно привести пример использования FunSearch для автоматизированного поиска структуры оператора селекции. А именно, FunSearch генерировал и эволюционировал новые варианты ранговой селекции, направленные на улучшение производительности алгоритма. На примере задач OneMax, LeadingOnes и Harmonic Function было продемонстрировано, что модифицированные с помощью FunSearch функции назначения рангов превосходят классическую ранговую селекцию по качеству решения [11]. Помимо FunSearch, существуют и другие альтернативные подходы, например, такие как Effortless Algorithmic Solution Evolution [12].
В данной работе используется реализация EоH из проекта LLM4AD, но применяется она для специализированной задачи – автоматического синтеза операторов селекции в генетическом алгоритме.
Предлагаемый подход
В данном исследовании предлагается применить EoH для автоматической эволюции функции выбора индекса особи в генетическом алгоритме при заданных значениях пригодности.
Реализован ГА с различными задачами псевдобулевой оптимизации из набора PBO (Parameterized Boolean Optimization), а именно OneMax, LeadingOnes и HarmonicFunction with Harmonic Weights [13].
В состав ГА входят:
-
– инициализация: генерация случайных бинарных хромосом фиксированной длины;
-
– селекция: по умолчанию используется ранговая селекция, где вероятность выбора особи пропорциональна её рангу (может заменяться на версию от EoH);
-
– скрещивание: равномерное;
-
– мутация: побитовая с настраиваемой вероятностью;
-
– замена: полная замена родительской популяции потомками с сохранением лучшего решения.
Процесс работы EoH реализован следующим образом:
-
1. Инициация основной популяции: EoH генерирует набор программ-кандидатов на основе шаблона (template_program) и описания задачи (task_description). Каждая программа-кандидат представляет собой потенциальную реализацию функции выбора индивида.
-
2. Многошаговая эволюция:
-
– на каждой итерации выполняются операторы E1, E2, M1, M2, которые генерируют новые кандидаты на основе существующих решений;
-
– LLM создаёт текстовые версии функций, которые затем преобразуются в исполняемый код.
-
3. Оценка производительности: каждая сгенерированная функция запускается в песочнице (sandbox) внутри генетического алгоритма. Генетический алгоритм с сгенерированной функцией селекции запускается при 12 разных конфигурациях, которые отличаются размером популяции, количеством поколений, длиной бинарной строки и типом решаемой задачи. Полученные по пяти запускам результаты сравниваются с результатами стандартного ГА с ранговой селекцией. Параметры конфигурации представлены в табл. 1.
-
4. Эволюционный отбор: функции с наилучшей производительностью сохраняются в популяции, а менее эффективные отбрасываются. Генерируются новые кандидаты с помощью операторов E1, E2, M1, M2.
-
5. Многопоточная обработка: EoH использует многопоточность для параллельной генерации и оценки функций, ускоряя процесс поиска оптимальных операторов.
-
6. Завершение поиска: после достижения максимального числа итераций или числа оценённых функций выбирается лучшая реализация функции селекции.
В табл. 1 используются следующие обозначения: N – количество особей в генетическом алгоритме; G – количество поколений; F – индекс функции; L – длина хромосомы, т. е. количество битов в хромосоме; Mean – среднее наилучшее значение целевой функции.
Таблица 1
Настройки параметров генетического алгоритма
|
N |
G |
F |
L |
Mean |
|
50 |
30 |
1 |
500 |
0,81282 |
|
50 |
30 |
3 |
500 |
0,84372 |
|
50 |
30 |
2 |
50 |
0,56080 |
|
30 |
50 |
1 |
500 |
0,81789 |
|
30 |
50 |
3 |
500 |
0,84864 |
|
30 |
50 |
2 |
50 |
0,66220 |
|
30 |
30 |
1 |
400 |
0,78974 |
|
30 |
30 |
2 |
40 |
0,62099 |
|
30 |
30 |
3 |
400 |
0,81351 |
|
50 |
50 |
1 |
600 |
0,86081 |
|
50 |
50 |
2 |
60 |
0,63599 |
|
50 |
50 |
3 |
600 |
0,88465 |
В следующем разделе приведено описание условий эксперимента, включающих параметры EoH, и представлены результаты.
Результаты
Использовались 17 тестовых функций из фреймворка IOHprofiler. Он предоставляет среду для запуска алгоритмов на задачах псевдобулевой оптимизации. В нашем исследовании были использованы функции, охватывающие различные аспекты сложности:
-
– функция OneMax, цель которой максимизировать количество единиц в бинарной строке;
-
– функция LeadingOnes, подсчитывающая количество подряд идущих единиц в начале строки, пока не встретится первый ноль;
-
– функция Linear Function with Harmonic Weights – линейная с возрастающими целыми весами. Каждый бит в хромосоме имеет вес, т. е. биты в конце строки важнее, чем в начале.
Также использовались модифицированные версии вышеописанных функций согласно W -модели:
-
– Dummy Variables – уменьшение числа бит в хромосоме. Из n бит выбираются только m < n , остальные игнорируются;
-
– Neutrality – блоки битов агрегируются в один бит путём мажоритарного голосования. Биты разбиваются на блоки некоторой длины. Для каждого блока берётся большинство значений (например, если 2 из 3 битов – единицы, то выходной бит = 1);
-
– Epistasis – биты делятся на блоки некоторой длины, к каждому блоку применяется перестановка битов, например, строка 1100 становится 0011. Перестановка построена так, чтобы нарушить локальную структуру;
-
– Fitness Perturbation – искажение значений функции, т. е. значения функции трансформируются так, чтобы нарушить порядок или ввести плато.
Эти модификации служат для создания настраиваемых уровней сложности, имитации свойств реальных задач, проверки устойчивости и адаптивности алгоритмов. Их использование позволило оценить поведение алгоритма.
Алгоритм EoH был реализован на Python 3.12. Все эксперименты проводились на компьютере под управлением Linux Ubuntu 22.04, оснащённом процессором AMD Ryzen 7950X3D (16 ядер) и графическим процессором NVIDIA RTX 3090. Исходный код доступен в [14].
В качестве языковой модели использовалась локально развернутая DeepSeek-Coder-V2. Эта модель была выбрана за её высокую скорость обработки, доступность и относительно низкие вычислительные требования, что делает её подходящей для проведения экспериментов на персональном компьютере без специализированного оборудования. Локальное развертывание LLM выполнялось с использованием фреймворка Ollama [15].
На рис. 1 представлен шаблон функции, ее тело будет модифицировано с помощью LLM. Без шаблона LLM не знало бы, какую функцию создавать, какие аргументы использовать и какие возвращать значения. После функции приводится текстовое описание задачи, которое используется для формирования запроса для LLM.
В данной работе было предложено две конфигурации алгоритма EоH с разной базовой структурой функции, которую LLM будет изменять и улучшать:
-
1) EоH (GA-specific): шаблон функции предназначен для выбора индивида в генетическом алгоритме на основе массива пригодностей (рис. 1);
-
2) EоH (general): шаблон функции задан в более общем виде, функция выбирает элемент на основе массива качества без явного знания о ГА (рис. 2).
-
#Prompt:
template program = import numpy as np import random def GA_Selection(Fitness) -> int:
Args:
Fitness: Fitness array
Рис. 1. Пример подсказки LLM для первого шаблона запроса
Fig. 1. Example of LLM prompt for the first prompt template
На рис. 1 можно увидеть, что функция получает на вход массив пригодностей (Fitness) всех особей и должна вернуть индекс выбранного индивида. Такой подход предоставляет EOH явный контекст задачи, позволяя модели понимать, что она работает именно с генетическим алгоритмом, а не с абстрактным набором значений.
-
#Prompt:
template_program = import numpy as np import random def Choose(Quality) -> int:
Args:
| Quality: Quality array
Return:
Рис. 2. Пример подсказки LLM для второго шаблона запроса
Fig. 2. Example of LLM prompt for the second prompt template
На рис. 2 представлен шаблон функции, где EоH не знает о том, что используется ГА, и решает задачу в абстрактной форме, без конкретной информации о структуре алгоритма.
Метод EoH был запущен [16] со следующими параметрами:
– максимальное количество выборок 4000;
-
– максимальное количество поколений 50;
-
– размер популяции 40;
-
– операторы поиска: E1, E2, M1, M2.
Для каждого шаблона подсказки выполнялось пять независимых запусков, каждый из которых занимал 1,5 часа. Из каждого запуска выбиралась лучшая эвристика и тестировалась на 34
конфигурациях – 17 тестовых функциях с двумя различными наборами параметров. В первом наборе параметров размер популяции составлял 30, количество поколений 30, длина хромосомы 50. Во втором наборе параметров размер популяции составлял 50, количество поколений 50, длина хромосомы 500.
Для оценки эффективности различных модификаций оператора селекции, предложенных системой EoH, был проведён статистический анализ с использованием U-критерия Манна – Уитни. Этот непараметрический тест широко применяется для определения наличия значимых различий между двумя выборками на основе ранговых значений [17]. Результаты U-критерия Манна – Уитни представлены в табл. 2.
Таблица 2
Сравнение эффективности операторов селекции (U-критерий Манна – Уитни)
|
# |
Wins |
Ties |
Losses |
Score |
|
EoH (prompt 1), run 1 |
11 |
15 |
8 |
16,41 |
|
EoH (prompt 1), run 2 |
11 |
17 |
6 |
16,83 |
|
EoH (prompt 1), run 3 |
11 |
14 |
9 |
15,51 |
|
EoH (prompt 1), run 4 |
11 |
17 |
6 |
18,72 |
|
EoH (prompt 1), run 5 |
12 |
15 |
7 |
20,78 |
|
EoH (prompt 2), run 1 |
9 |
20 |
5 |
16,25 |
|
EoH (prompt 2), run 2 |
10 |
17 |
7 |
20,14 |
|
EoH (prompt 2), run 3 |
7 |
19 |
8 |
–9,871 |
|
EoH (prompt 2), run 4 |
11 |
11 |
12 |
–5,682 |
|
EoH (prompt 2), run 5 |
10 |
18 |
6 |
13,32 |
|
FunSearch |
5 |
19 |
10 |
–23,69 |
Значение Wins отражает количество случаев, в которых модифицированный оператор селекции статистически значимо превзошёл базовую реализацию. Ties указывает на количество случаев, где разница не достигла статистической значимости, а Losses – это количество случаев, в которых базовый оператор превзошёл модифицированный. Score представляет собой сумму Z-значений по всем сравнениям.
Лучшие запуски с первого и второго шаблонов были выбраны, в частности, запуски 5 и 2. На рис. 3 и 4 приведены примеры ответов LLM для двух шаблонов подсказок.
#Response:
import random def GA_Selection(Fitness) -> int:
Args:
Fitness: Fitness array
Return: Returns index of selected individual if sum(Fitness) == 0: return random. randint (0, len(Fitness) - 1)
-
# Adaptive tournament size up to a maximum of 15 individuals tournament_size = min(max(5, int(len(Fitness) ** 0.5)), 15)
-
# Select participants with weighted random choice based on fitness values participants = random. choices (range(len(Fitness)), weights=Fitness, k=tournament_size)
-
# Find the fittest individual among the participants selected_index = max (participants, key=larnbda i: Fitness [i])
return selected_index
Рис. 3. Пример ответа LLM для первого шаблона подсказки, запуск 5
-
Fig. 3. Example of LLM response for the first prompt template, run 5
Код на рис. 3, по сути, представляет собой вариант турнирной селекции, где размер турнира равен квадратному корню из размера популяции, но не менее 5 и не более 15, т. е., поскольку
LLM была информирована о типе задачи – селекция в ГА, она реализовала наиболее широко используемый оператор.
Код на рис. 4, по-видимому, реализует вариант пропорциональной селекции по приспособленности, но со случайными возмущениями значений приспособленности. При этом в ответе нет упоминания о пропорциональной селекции, так как LLM не была проинформирована о задаче.
♦Response: import random def Choose(Quality) -> int:
Args :
Quality: Quality array
Return:
Returns index of chosen perturbed_quality = [q + random.uniform(-0.1, 0.1) for q in Quality]
max_quality = -float(’inf’) candidates = []
-
# Find the maximum quality value and indices where this occurs for i, quality in enumerate(perturbed_quality):
if quality > max_quality: : max_quality = quality candidates = [i]
-
# If there is only one candidate, return it directly
if len(candidates) == 1: return candidates[0]
-
# Calculate the weights based on the perturbed qualities weights = [perturbed_quality[index] for index in candidates] total_weight = sum(weights)
-
# Normalize the weights and generate a random choice based on these probabilities
probabilities = [weight / total_weight for weight in weights]
selected index = random.choices(candidates, weights=probabilities, k=l)[0]
return selected index
Рис. 4. Пример ответа LLM для второго шаблона подсказки, запуск 2
-
Fig. 4. Example of LLM response for the second prompt template, run 2
На рис. 5 показан более необычный оператор селекции, сгенерированный в запуске 4 со вторым шаблоном подсказки.
-
♦ Response:
import random def Choose(Quality) -> int
Args :
s Quality: Quality array
Return:
i Returns index of chosen n = len(Quality) if n = 0: return -1
-
# Calculate the median quality value sorted_quality = sorted(Quality)
median_quality = sorted_quality[n fl 2]
-
# Select candidates with maximum quality and low variance around the median top_variance_candidates = [i for i in range(n) if Quality[i] >= max(Quality)
(max(Quality) - median_quality) / 2]
return -1
Рис. 5. Пример ответа LLM для второго шаблона подсказки, запуск 4
Fig. 5. Example of LLM response for the second prompt template, run 4
Код в запуске 4 со вторым шаблоном подсказки выбирает особей, чья приспособленность отличается от максимальной менее чем на половину расстояния от максимальной приспособленности до медианной, т. е. это турнирная селекция с адаптивным размером турнира, основанным на распределении качества.
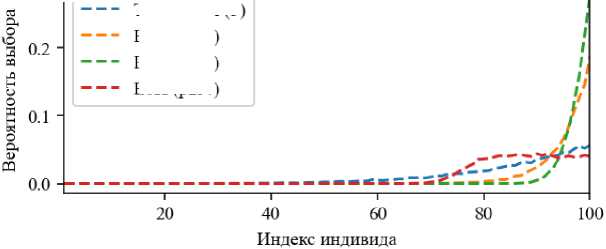
Рис. 6. Сравнение селективного давления турнирной селекции и трёх сгенерированных эвристик
Турнирная (3) ЕоН (plr5) ЕоН (р2г2) ЕоН (р2г4)
Fig. 6. Comparison of the selective pressure of tournament selection and three heuristics
На рис. 6 представлены графики селективного давления трёх эвристик с рис. 3–5, а также турнирной селекции для сравнения. Эвристика p2r2 характеризуется наибольшим селективным давлением, тогда как эвристика p2r4 выбирает одного из верхних 25 % особей с одинаковой вероятностью. Эвристика p1r5 представляет собой турнирную селекцию с большим размером турнира.
В табл. 3 приведён сравнительный анализ трёх стандартных методов селекции и двух разработанных эвристик, а именно эвристики сгенерированной с первым шаблоном подсказки, запуск 5 (p1r5), и сгенерированной со вторым шаблоном подсказки, запуск 2 (p2r2). Показаны значения приспособленности для каждой из 34 тестовых конфигураций.
Сравнительный анализ стандартных и сгенерированных операторов селекции
Таблица 3
|
# |
Турнирная |
Пропорциональная |
Ранговая |
EoH (p1r5) |
EoH(p2r2) |
|
1 |
0,9872 (0,014) + |
0,832 (0,041) + |
0,9656 (0,024) + |
1 (0,000) = |
1 (0,000) |
|
2 |
0,8422 (0,013) + |
0,611 (0,015) + |
0,8181 (0,013) + |
0,886 (0,012) – |
0,8649 (0,019) |
|
3 |
0,408 (0,065) + |
0,372 (0,078) + |
0,3072 (0,071) + |
0,5016 (0,109) + |
0,604 (0,103) |
|
4 |
0,04632 (0,014) = |
0,03904 (0,009) + |
0,03296 (0,009) + |
0,03776 (0,012) + |
0,04912 (0,009) |
|
5 |
0,9861 (0,009) + |
0,8724 (0,022) + |
0,9803 (0,011) + |
0,9996 (0,001) – |
0,9989 (0,002) |
|
6 |
0,8695 (0,012) = |
0,6362 (0,014) + |
0,8501 (0,016) + |
0,9096 (0,013) – |
0,8799 (0,014) |
|
7 |
1 (0,000) = |
0,9408 (0,041) + |
1 (0,000) = |
1 (0,000) = |
1 (0,000) |
|
8 |
0,9411 (0,011) = |
0,671 (0,021) + |
0,9128 (0,014) + |
0,965 (0,013) – |
0,947 (0,011) |
|
9 |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) |
|
10 |
1 (0,000) – |
0,9096 (0,029) + |
1 (0,000) – |
1 (0,000) – |
0,9952 (0,009) |
|
11 |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) |
|
12 |
0,9889 (0,007) – |
0,7535 (0,025) + |
0,9773 (0,011) = |
0,9805 (0,011) = |
0,9747 (0,015) |
|
13 |
0,7152 (0,019) – |
0,7192 (0,018) – |
0,72 (0,026) – |
0,696 (0,015) – |
0,68 (0,017) |
|
14 |
0,5762 (0,007) = |
0,5772 (0,007) = |
0,5745 (0,005) = |
0,5747 (0,006) = |
0,5728 (0,008) |
|
15 |
0,5048 (0,014) + |
0,4184 (0,022) + |
0,4976 (0,009) + |
0,5192 (0,004) = |
0,52 (0,000) |
|
16 |
0,4236 (0,007) + |
0,3072 (0,007) + |
0,4105 (0,006) + |
0,4436 (0,008) – |
0,4308 (0,007) |
|
17 |
0,9784 (0,021) + |
0,7968 (0,033) + |
0,9552 (0,019) + |
1 (0,000) = |
1 (0,000) |
|
18 |
0,8387 (0,010) + |
0,6111 (0,016) + |
0,8182 (0,011) + |
0,8826 (0,015) – |
0,8572 (0,013) |
Окончание табл. 3
|
# |
Турнирная |
Пропорциональная |
Ранговая |
EoH (p1r5) |
EoH(p2r2) |
|
19 |
0,6792 (0,031) = |
0,6824 (0,034) = |
0,6824 (0,040) = |
0,6664 (0,040) = |
0,6736 (0,036) |
|
20 |
0,5506 (0,012) = |
0,5494 (0,009) = |
0,5519 (0,008) = |
0,5516 (0,011) = |
0,5518 (0,008) |
|
21 |
0,7808 (0,168) + |
0,7536 (0,150) + |
0,6384 (0,139) + |
0,9488 (0,092) = |
0,936 (0,106) |
|
22 |
0,09504 (0,023) = |
0,08032 (0,016) + |
0,06064 (0,020) + |
0,08032 (0,026) + |
0,1043 (0,028) |
|
23 |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) = |
1 (0,000) |
|
24 |
0,4944 (0,098) – |
0,3888 (0,101) = |
0,2936 (0,096) = |
0,396 (0,127) = |
0,376 (0,113) |
|
25 |
0,96 (0,127) – |
0,99 (0,038) – |
0,9225 (0,129) – |
0,8125 (0,277) = |
0,685 (0,291) |
|
26 |
0,0906 (0,019) – |
0,07639 (0,029) = |
0,0747 (0,017) = |
0,06361 (0,024) = |
0,06916 (0,022) |
|
27 |
0,2064 (0,035) – |
0,172 (0,026) – |
0,1928 (0,032) – |
0,1192 (0,027) = |
0,144 (0,038) |
|
28 |
0,02312 (0,004) = |
0,01808 (0,003) + |
0,02408 (0,005) = |
0,01144 (0,003) + |
0,02224 (0,004) |
|
29 |
0,2192 (0,038) = |
0,1792 (0,049) + |
0,1432 (0,029) + |
0,2576 (0,059) = |
0,2432 (0,045) |
|
30 |
0,02184 (0,006) = |
0,02184 (0,006) = |
0,01464 (0,004) + |
0,01864 (0,006) = |
0,02176 (0,005) |
|
31 |
0,3856 (0,067) + |
0,2272 (0,139) + |
0,3112 (0,092) + |
0,5184 (0,159) = |
0,5344 (0,135) |
|
32 |
0,0504 (0,012) = |
0,01784 (0,014) + |
0,02816 (0,008) + |
0,02784 (0,013) + |
0,04608 (0,013) |
|
33 |
0,1256 (0,048) = |
0,144 (0,061) = |
0,1272 (0,043) = |
0,136 (0,054) = |
0,1472 (0,044) |
|
34 |
0,0176 (0,003) = |
0,0148 (0,005) = |
0,01416 (0,004) = |
0,01616 (0,005) = |
0,01472 (0,005) |
|
Сумма |
7–/17=/10+ |
3–/11=/20+ |
4–/13=/17+ |
8–/21=/5+ |
0–/34=/0+ |
В каждой ячейке «+» означает, что эвристика 4 была статистически значимо лучше по тесту Манна – Уитни на данной задаче, «-» означает, что она была значительно хуже, «=» указывает на отсутствие значимой разницы.
Среднее значение приспособленности отражает общую эффективность алгоритма, а стандартное отклонение указывает на стабильность и надёжность его работы. Низкое стандартное отклонение подтверждает устойчивость предлагаемого метода к случайным вариациям, тогда как высокое стандартное отклонение свидетельствует о нестабильности поведения алгоритма при решении некоторых типов задач.
Как видно из табл. 3, разработанные эвристики превосходят стандартные в большинстве случаев. Разработанные эвристики демонстрируют схожую производительность, однако эвристика, сгенерированная со вторым шаблоном подсказки, показывает результаты лучше. Разработанные эвристики были хуже стандартных операторов селекции лишь в трёх случаях из 34, а именно, в конфигурациях 13, 25 и 27.
Заключение
Проведённые в этом исследовании эксперименты показали, что метод эволюции эвристик работает значительно лучше, чем ранее использовавшийся алгоритм FunSearch. Два шаблона подсказок привели к различному поведению LLM. В первом случае, когда LLM была информирована о задаче, она генерировала классические структуры, такие как турнирная селекция. Во втором случае креативность LLM была значительно выше и она создала несколько весьма различных подходов к селекции, например, с использованием медианных значений. Также различные запуски одного и того же подхода без информирования LLM давали очень разные структуры операторов селекции.
Некоторые направления будущей работы могут включать данный метод, но не ограничиваться применением того же метода к целому метаэвристическому алгоритму, т. е. генерацией нового алгоритма полностью. Другим направлением может быть модификация самого EoH, например, путём изменения процедуры селекции.
