Эволюционный алгоритм с механизмом снижения размерности на основе автоэнкодеров

Автор: Сопов А.Е., Сопов Е.А.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.27, 2026 года.
Бесплатный доступ
Многие современные прикладные задачи оптимизации формулируются как модели «чёрного ящика», для которых характерно отсутствие аналитической информации о целевой функции и её свойствах. Эволюционные алгоритмы стали популярным инструментом для решения подобных задач, однако их эффективность существенно снижается в задачах высокой размерности со сложной топологией пространства поиска. Вместе с тем, для эффективной работы такие алгоритмы требуют генерацию большого числа пробных решений, что может быть недостижимо в приложениях с дорогостоящей оценкой целевой функции. Для преодоления этих ограничений в работе представлен новый подход к эволюционной оптимизации. Его ядром является адаптивная процедура снижения размерности на основе автоэнкодера, который динамически обучается на основе данных популяций, полученных в ходе оптимизации. Стратегия основана на параллельной работе двух алгоритмов оптимизации: один исследует исходное пространство, а другой – латентное пространство, строящееся автоэнкодером как компактное нелинейное отображение текущей популяции. Такой подход позволяет алгоритму гибко подстраиваться под структуру конкретной задачи. Проведён анализ эффективности предложенного метода на наборе эталонных задач, исследованы сходимость алгоритма на разных стадиях эволюционного процесса и зависимость от выбора размерности сжатого пространства. Полученные результаты обработаны с помощью статистического критерия Манна – Уитни – Уилкоксона. В качестве метода оптимизации субпопуляций использован алгоритм L-SRTDE. В результате численных экспериментов было установлено, что предложенный алгоритм стимулирует более эффективное исследование пространства поиска на начальных этапах оптимизации, но в среднем незначительно уступает в эффективности базовому алгоритму.
Глобальная оптимизация, оптимизация черного ящика, эволюционные алгоритмы, автоэнкодеры, снижение размерности
Короткий адрес: https://sciup.org/148333107
IDR: 148333107 | УДК: 519.8 | DOI: 10.31772/2712-8970-2026-27-1-47-60
Evolutionary algorithm with an autoencoder-based dimensionality reduction mechanism
Many modern applied optimization problems are formulated as black-box models, characterized by a lack of analytical information about the objective function and its properties. While Evolutionary Algorithms (EAs) are frequently applied here, their performance degrades in high-dimensional spaces with complex landscapes. Moreover, these algorithms require generating a large number of trial solutions for effective operation, which may be unattainable in applications with expensive objective function evaluation. To overcome these limitations, we introduce a novel EA framework centered on adaptive, autoencoder-based dimensionality reduction. The autoencoder is retrained dynamically during the search using evolving population data. The strategy relies on the parallel operation of two optimization algorithms: one works in the original solution space, and another operates in a latent space – a compact, nonlinear representation of the current population generated by the autoencoder. This design enables the algorithm to adapt to the problem's specific structure. We evaluated the method on standard benchmark problems, analyzing its convergence dynamics and sensitivity to the latent space size. Statistical significance of the results was assessed using the Wilcoxon rank-sum test. The L-SRTDE algorithm was used as the subpopulation optimization method. Numerical experiments demonstrate that the proposed algorithm enhances search space exploration in first optimization stages but, on average, is slightly less efficient than the base algorithm.
Текст научной статьи Эволюционный алгоритм с механизмом снижения размерности на основе автоэнкодеров
Многие современные прикладные задачи оптимизации формулируются как модели «чёрного ящика», в которых целевая функция оценивается алгоритмически или путём имитационного моделирования. Аналитические методы оптимизации часто неприменимы к таким задачам в силу отсутствия априорной информации о свойствах целевой функции. Рост сложности и количества подобных приложений стимулировал создание новых методов, среди которых – алгоритмы прямого поиска и метаэвристики [1]. Важную роль в этой области играют эволюционные алгоритмы (ЭА) – стохастические популяционные методы, вдохновлённые процессами из эволюционной биологии. Они считаются одними из перспективных подходов к глобальной оптимизации «чёрного ящика». Благодаря активному развитию и высокой эффективности ЭА получили широкое распространение в многочисленных прикладных задачах [2]. Вместе с тем, для эффективной работы такие алгоритмы требуют создания большого количества пробных решений, что может быть недостижимо в приложениях с дорогостоящей оценкой целевой функции.
Для преодоления этого недостатка часто прибегают к комбинированию методов оптимизации и аппроксимации. В случае вычислительно сложных задач распространённым решением является использование суррогатных моделей. Такие модели, выступая в роли упрощённых аппроксимаций ландшафта целевой функции, применяются в ЭА для предсказания качества потенциальных решений. Это позволяет существенно сократить число вычислений самой целевой функции, так как её предсказание по аппроксимации не требует проведения дорогостоящих экспериментов. К числу распространённых суррогатных моделей относятся случайные леса [3], гауссовские процессы [4] и нейронные сети с радиально-базисными функциями [5]. Сущест- венной проблемой, однако, остаётся так называемое «проклятие размерности»: с увеличением размерности задачи для построения адекватной модели требуется непрактично большой объём данных, что приводит к резкому падению эффективности алгоритма оптимизации.
Существующие стратегии преодоления этой проблемы условно можно разделить на несколько категорий. Стратегии, основанные на декомпозиции, предполагают разделение исходной задачи на множество более простых независимо решаемых подзадач [6]. Второе направление делает акцент на разработке специализированных генетических операторов и их интеграции с методами локального поиска [7]. Альтернативный путь связан с применением методов обучения без учителя для реконструкции пространства поиска, прежде всего, для снижения размерности. Наряду с классическим анализом главных компонент перспективными являются методы на базе автоэнкодеров – нейронных сетей, которые строят сжатое (латентное) представление исходного пространства.
В данной работе предложен эволюционный алгоритм с динамическим снижением размерности на основе автоэнкодера. Основная идея подхода заключается в использовании автоэнкодера для анализа популяций, возникающих в процессе поиска, с целью построения латентного пространства, отражающего скрытые зависимости в ландшафте целевой функции. Предложенная архитектура ЭА задействует два совместно работающих метода оптимизации – в латентном и исходном пространствах поиска. Эффективность метода проверена на наборе тестовых функций. В работе приводится анализ сходимости и динамики популяций на разных этапах алгоритма.
Постановка задачи
Задачу непрерывной глобальной минимизации можно представить следующим образом:
f(x)→min,f :Rn→R, x∈Rn где f(x) – целевая функция, вектор X = (x1, …, xn), xi ∈ S представляет собой допустимое решение в n-мерном пространстве. Область поиска S ограничена гиперкубом, определённым для каждой переменной парой границ: нижней lbi и ubi. Решением задачи (1), или глобальным минимумом, называется вектор x*∈ S такой, что∀x∈S: f(x*) ≤ f(x). Заданы умеренные ограничения на количество вычислений целевой функции, т. е. бюджет слишком мал для применения стандартных ЭА, однако достаточен для того, чтобы не ограничиваться методами локального спуска.
Подразумевается, что структура, свойства и производные целевой функции f(x) неизвестны и метод оптимизации может оперировать лишь значениями входящих векторов и соответствующих значений целевой функции. Это обстоятельство затрудняет применение классических методов, создавая предпосылки для использования эвристик и метаэвристик. В частности, эволюционные алгоритмы относятся к числу наиболее распространённых и успешных подходов в данном классе задач.
Эволюционными алгоритмами называют класс стохастических методов оптимизации, вдохновлённых процессами из эволюционной биологии. ЭА основаны на взаимодействии с популяциями – массивами решений-кандидатов. Их работа носит итеративный характер: в каждом поколении к текущим решениям применяются генетические операторы, а популяция обновляется благодаря селекции наиболее перспективных кандидатов и внесению случайных изменений. Критерием качества (функцией приспособленности) обычно служит сама целевая функция задачи, однако возможны её модификации с учётом дополнительных ограничений. В ходе развития данной области было предложено большое количество эволюционных методов, многие из которых специализируются на задачах с определёнными типами переменных. В частности, для решения задач оптимизации с вещественными переменными одним из наиболее эффективных подходов считается семейство алгоритмов дифференциальной эволюции (ДЭ).
Дифференциальная эволюция на основе истории успеха
Алгоритм дифференциальной эволюции (ДЭ) был предложен Сторном и Прайсом в 1995 г. [8]. Классический вариант ДЭ начинает работу с инициализации случайной популяции размера N . Для каждой особи вычисляется значение целевой функции. Далее алгоритм выполняет итеративный цикл поколений. Его ключевой процедурой является оператор мутации, создающий новые пробные решения. Классическая стратегия, обозначаемая как rand/1 , определяется следующим выражением:
V ij x r 1 j + F ( x r 2 j x r 3 j ) ,
где Vi j – мутантный вектор; r 1, r 2, r 3 – случайно выбранные индексы ( r 1 ≠ r 2 ≠ r 3); i – индекс текущего индивида; j – номер переменной; F – параметр масштабирования. При нарушении границ пространства поиска j -й координатой её значение заменяется на случайное. После этого к мутантному вектору применяется оператор кроссовера (скрещивания). Наиболее распространённая схема – биномиальное скрещивание ( bin ), которая определяется следующим образом:
u ij
V ij- , если r < CR или j = j'r, x j , иначе,
где ui – пробный (trial) вектор; CR – вероятность кроссовера; CR ∈ [0;1]; jr – случайный индекс в диапазоне [1; n], обеспечивающий изменение хотя бы одной компоненты мутантного вектора.
Далее пробный вектор сравнивается с исходным индивидом (родителем), имеющим тот же индекс i . При решении задачи минимизации, если значение целевой функции для пробного вектора ниже, он замещает родителя в популяции. Данная операция называется селекцией и формализуется следующим образом:
u j =
u ij , если f ( u ij ) < f ( x ij ) ,
xij , иначе.
Указанные операторы применяются последовательно для генерации нового поколения. После этого начинается следующий цикл работы с обновлённым набором решений. Алгоритм повторяет данную процедуру до выполнения заданных условий завершения, коим обычно служит ограничение по количеству вычислений целевой функции ( FEs ) или времени работы. Существенным недостатком такой схемы является зависимость от ручного подбора параметров ( N, F , CR ) и стратегии мутации. В целях решения этой проблемы были предложены многочисленные механизмы самоадаптации параметров [9; 10].
Алгоритм L-SRTDE представляет собой модификацию ДЭ, предложенную В. Станововым и Е. Семёнкиным для специальной сессии конгресса по эволюционным вычислениям IEEE CEC 2024 [11]. Метод оперирует двумя популяциями равного размера: архивом наилучших решений ( xtop ) и популяцией новых решений ( xnew ). Инициализация предусматривает заполнение обеих популяций одинаковым набором решений. Одной из ключевых особенностей метода является стратегия мутации r-new-to-ptop/n/t , определяемая выражением:
new top new new top
Vij xr 1,j + F (xpbest,j xi,j ) + F (xr2,j xr3,j ) , где r1, r2, r3 – случайно выбранные индексы (r1 ≠ r3), индекс r2 определяется методом ранговой селекции с заданным селективным давлением; pbest – случайно выбранный индекс из лучших pb% решений. Кроссовер выполняется в соответствии с выражением (3).
Этап селекции формализуется следующим образом:
xnc
Uj , если f ( uj ) < f ( x new ) ,
_ xnc, иначе, где nc – индекс, который инкрементируется после каждой успешной селекции (замены решения пробным). Далее выполняется обновление популяции: особи ранжируются по значениям функции приспособленности, после чего применяется линейное сокращение её размера. Адаптация коэффициента масштабирования F основана на показателе успешности (Success Rate, SR): SR = NS/NP (где NS – число успешных операций селекции в поколении). Математическое ожидание параметра рассчитывается по правилу mF = 0.4 + 0.25 ∙ tanh(5 ∙ SR). Значение F для каждой особи выбирается из нормального распределения: F = randn(mF, 0.02). Доля лучших решений pb задаётся функцией pb = max (2,0.7e-7’SR). Для адаптации вероятности скрещивания CR задействуется массив памяти MCR, в котором хранится t последних «успешных» значений параметра. Новые значения генерируются случайным образом по правилу CRi = randn(MCr,k, 0.02), где индекс k обозначает циклическое перемещение по элементам памяти.
Снижение размерности с помощью автоэнкодеров
Автоэнкодером называют архитектуру нейронных сетей для обучения без учителя, задача которой заключается в обучении сжатого представления входных данных через их декодирование. Обобщённая схема автоэнкодера представлена на рис. 1.
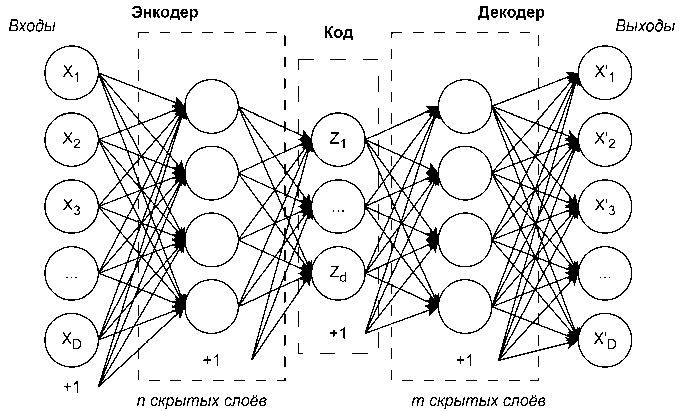
Рис. 1. Обобщённая структура автоэнкодера
Fig. 1. General structure of an autoencoder
Основными компонентами архитектуры являются: энкодер, код (bottleneck) и декодер. Размерность входного и выходного слоёв совпадает, тогда как размерность промежуточного слоя кода намеренно делается меньше с целью сжатия пространства. Энкодер g отображает входной вектор x в сжатое латентное представление c ( x ), а декодер f по этому коду генерирует приближение исходного входа. Обучение сети сводится к минимизации функции потерь L ( x , f ( g ( x ))), оценивающей ошибку реконструкции, т. е. расхождение между исходным вектором x и выходным f ( g ( x )).
Пусть дан автоэнкодер, где Zj - активация j-го нейрона слоя кода, j = 1, d . Этот слой образу- ет d-мерное латентное пространство поиска Z, для которого определены операции кодирования и декодирования. Рассмотрим архитектуру автоэнкодера с k1 скрытыми слоями в энкодере и k2 скрытыми слоями в декодере. Тогда значения нейронов на слое кода вычисляются следующим образом:
z j = f
aj+ E{ Х П ,
\ i
wn)
,
где f – функция активации; a n j и wi n – смещение и веса n -го слоя энкодера; xi n – выходы предыдущего слоя.
Значения на выходном слое определяются по формуле xj = f
a ’m+^ z ? , w ; m) v i )
где a jm и w j m - смещение и веса m -го слоя энкодера; z ? - выходы предыдущего слоя.
Автоэнкодеры хорошо зарекомендовали себя в таких приложениях, как частотный анализ, фильтрация данных и предобучение [12; 13]. Их ключевыми преимуществами перед альтернативными методами являются способность выявлять нелинейные зависимости в данных и относительно низкая стоимость обучения. Эти свойства делают автоэнкодеры перспективным инструментом для эволюционной оптимизации, где они могли бы использоваться для получения компактного представления пространства поиска. Тем не менее интеграция автоэнкодеров с ЭА в настоящее время остаётся малоизученной.
Среди ключевых исследований (М.Cui и др. [14]) был предложен алгоритм кооперативной коэволюции для организации взаимодействия между ЭА, работающими в исходном и латентном пространствах. Z. Hu и др. [15] было исследовано применение автоэнкодеров в задачах многокритериальной глобальной оптимизации больших размерностей. Обе публикации рассматривали применение сжимающих способностей автоэнкодера до инициализации ЭА. В этом исследовании эти процедуры расширяются до динамического изменения структуры латентного пространства в ходе оптимизации, что обеспечивает адаптацию алгоритма к различным стадиям эволюционного процесса.
Предложенный подход
Общая схема работы метода представлена на рис. 2. Инициализация включает в себя выбор гиперпараметров и создание обширной начальной выборки объёмом Ninit методом латинского гиперкуба (LHS) [16]. Из неё выбираются N индивидов с лучшими значениями целевой функции, формирующих начальную популяцию и в то же время служащих обучающей выборкой для автоэнкодера. Так как автоэнкодеры не требуют размеченных данных, обучение на лучших решениях, отражающих перспективные области поиска, эффективнее обучения на случайных данных. Это обеспечивает релевантное конкретной задаче снижение размерности, потенциально ускоряя сходимость на начальных этапах, сохраняя глобальные свойства алгоритма.
Основной цикл алгоритма включает три стадии: обучение автоэнкодера, поиск в латентном пространстве и поиск в исходном пространстве. Процесс начинается с обучения автоэнкодера на текущей популяции P , что позволяет переопределить границы и механизм декодирования латентного пространства. Популяция кодируется и оптимизируется с помощью ЭА в сжатом пространстве, полученные решения декодируются и образуют популяцию PAE . После этого популяция P оптимизируется в исходном пространстве высокой размерности, с результирующей популяцией PO . Затем происходит их объединение в популяцию P и перераспределение вычислительных ресурсов между алгоритмами оптимизации. Полученная популяция служит основой для следующей итерации, если не выполнен критерий остановки.
В ЭА автоэнкодер служит инструментом сжатия пространства поиска с целью получения более удобного для исследования представления. Корректно настроенный автоэнкодер, отображающий топологию исходного ландшафта f(x) в латентное пространство, способен ускорять нахождение перспективных областей. Ранее предложенные методы интеграции автоэнкодеров с ЭА [14; 15] в силу специфики задач чаще всего ограничивались однократным обучением модели перед началом оптимизации, что фиксирует латентное представление и приводит к сильной зависимости результата от инициализации модели. В предложенном методе это ограничение снимается за счёт использования итеративной процедуры дообучения автоэнкодера.
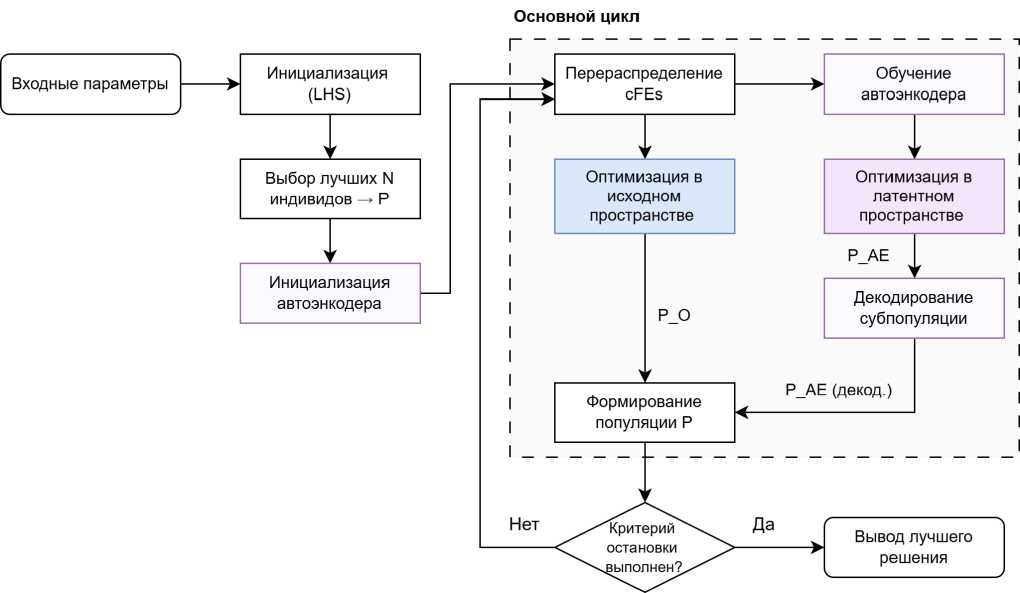
Рис. 2. Блок-схема предложенного алгоритма
Fig. 2. A flowchart of the proposed algorithm
Обучение автоэнкодера начинается с инициализации нейронной сети с заданной структурой. На вход подаётся текущая популяция, при необходимости данные нормализуются. Сеть обучается с помощью алгоритма Adam в течение некоторого числа итераций. В зависимости от разброса значений происходит корректировка границ латентного пространства. На основе обученной сети формируется новая целевая функция fLT ( z ) с операциями кодирования и декодирования. Размерность кода задаётся параметром d , её влияние на эффективность алгоритма исследуется в следующем разделе.
Функцией ошибки для обучения выбрана среднеквадратическая ошибка, вычисляемая между входным вектором x и его реконструкцией x' на выходе сети:
1 n 2
Loss ( x ) = ! ( x i - x i ) • n i = 1
Псевдокод предложенного метода (обозначен как AEDE) приведён в табл. 1. Параметры FEsAE и FEsO задают бюджет вычислений целевой функции (FEs) для алгоритмов оптимизации, работающих в латентном и исходном пространствах соответственно. Их сумма на цикл алгоритма фиксирована: FEsAE + FEsO = cFEs. Данные параметры позволяют балансировать распределение ресурсов между двумя алгоритмами. Поскольку эффективность поиска в каждом из них изменяется в процессе работы алгоритма, в работе используется адаптивная схема распре- деления ресурсов:
FEs AE
. ( cFEs 1 0.25 FEs = min I , -
I 10 4 max FEs
FEs O = cFEs - FEs AE ,
где FEs — текущее количество вычислений целевой функции, maxFEs – максимальное количество вычислений (критерий остановки).
Поиск в исходном и латентном пространствах осуществляется параллельно и независимо. Оптимизатор, работающий в исходном пространстве, сохраняет накопленную информацию:
он использует популяцию, полученную на предыдущем шаге, и не сбрасывает адаптивные настройки алгоритма. При оптимизации в латентном пространстве, напротив, настройки алгоритма сбрасываются. Подобное решение обусловлено тем, что ландшафт целевой функции в латентном пространстве может кардинально меняться после дообучения, что требует повторного накопления информации.
Следующее поколение создаётся путём объединения популяций по следующему правилу:
P ( P O U P AE Паа / n ) I n / n +m ,
где нотация |k / l обозначает взятие k / l доли лучших решений из соответствующей популяции, значение na выбрано равным
1 N
Данный селективный механизм предназначен для того,
чтобы ограничить доминирование латентного пространства в популяции. Поскольку оно является компактной проекцией исходного пространства и описывает лишь его регион, преобладание решений может привести к преждевременной сходимости алгоритма, особенно на ранних стадиях.
Таблица 1
Псевдокод предложенного алгоритма (AEDE)
Входы: D : размерность задачи, lb , ub : границы пространства поиска, N init – размер начальной выборки; a : архитектура автоэнкодера, cFEs : количество вычислений на цикл, maxFEs : бюджет вычислений
Выходы: x* : лучшее решение, f ( x *): лучшее значение целевой функции
|
1 |
Сгенерировать начальную выборку S размера Ninit методом латинских гиперкубов |
|
2 |
Вычислить значения f ( S ) |
|
3 |
Отсортировать S по f ( S ), выбрать N лучших индивидов, сформировать популяцию P |
|
4 |
пока ( FEs < max FEs ) нц |
|
5 |
Обучить автоэнкодер на популяции P |
|
6 |
Обновить бюджет FEsAE и FEsO ; согласно правилу (10) |
|
7 |
Выполнить оптимизацию в латентном пространстве |
|
8 |
Выполнить оптимизацию в исходном пространстве |
|
9 |
Отсортировать результирующие популяции P AE и P O |
|
10 |
Сформировать следующее поколение P согласно правилу (11) |
|
11 |
Сохранить лучшего индивида и значение целевой функции: x* , f ( x* ) |
|
12 |
кц |
После выполнения описанных действий начинается следующая итерация, если не выполнен критерий остановки.
Численные эксперименты и анализ результатов
В данном разделе представлены описание и результаты экспериментов. Эффективность предложенного подхода оценивалась на наборах тестовых задач глобальной оптимизации CEC 2017 и CEC 2022 [17; 18]. Исследование разделено на два этапа: анализ влияния размерности латентного пространства на эффективность алгоритма и сравнение предложенного алгоритма с L-SRTDE в условиях умеренных ограничений вычислительного бюджета. Испытания проводились для размерностей 20 и 100, статистическая оценка основывалась на 30 независимых прогонах для каждого теста.
С целью сохранения свойств базового алгоритма в предложенный фреймворк интегрирован механизм линейного сокращения размера популяции, аналогичный процедуре из L-SRTDE. Сокращение происходит пропорционально общему числу выполненных вычислений целевой функции. Данное правило постоянно действует в основном пространстве, тогда как в латентном пространстве процедура сокращения перезапускается после каждого этапа обучения авто-энкодера. Модифицированный таким образом алгоритм далее именуется как L-AEDE.
Начальный размер популяции установлен равным 200 для всех задач и размерностей. Ми-
1 N
нимальный размер популяции составляет 4 для оптимизатора основного пространства и для оптимизатора сжатого пространства. Автоэнкодер обучается в течение 200 эпох на этапе инициализации и 100 эпох в каждом последующем цикле алгоритма. Объём исходной выборки, сформированной методом латинского гиперкуба (LHS), равен 500. Остальные значения параметров L-SRTDE были установлены в соответствии с рекомендациями авторов. Структура эн-кодера – {64,32}, структура декодера – {32,64}, функция активации для скрытых слоёв – ELU, функция активации на выходных слоях – линейная. Эффективность алгоритма оценивалась на основе стандартного отклонения, лучшего, среднего и медианного значений. Для проверки статистической значимости различий в результатах применялся критерий Манна – Уитни – Уилкоксона с уровнем значимости α = 0,05.
В табл. 2 и 3 представлены результаты алгоритма L-AEDE для трёх задач бенчмарка CEC 2017 при бюджете в 100 000 вычислений целевой функции и различных размерностях латентного пространства d . Первый столбец содержит обозначения тестовых функций и их исходную размерность, в последующих столбцах приведены показатели эффективности.
Таблица 2
Результаты работы L-AEDE при разных размерностях латентного пространства (минимальное и медианное значения)
|
Задача, D |
d = 5 |
d = 10 |
d = 20 |
|||
|
Минимум |
Медиана |
Минимум |
Медиана |
Минимум |
Медиана |
|
|
f 1 , 20 |
1,000e+02 |
6,201e+02 |
1,019e+02 |
1,061e+03 |
– |
– |
|
f 6 , 20 |
6,000e+02 |
6,000e+02 |
6,000e+02 |
6,000e+02 |
– |
– |
|
f 25 , 20 |
2,910e+03 |
2,913e+03 |
2,910e+03 |
2,913e+03 |
– |
– |
|
f 1 , 100 |
3,355e+09 |
8,420e+09 |
4,798e+09 |
1,108e+10 |
2,519e+09 |
1,141e+10 |
|
f 6 , 100 |
6,164e+02 |
6,235e+02 |
6,166e+02 |
6,232e+02 |
6,171e+02 |
6,240e+02 |
|
f 25 , 100 |
3,547e+03 |
3,676e+03 |
3,538e+03 |
3,655e+03 |
3,559e+03 |
3,671e+03 |
Таблица 3
Результаты работы L-AEDE при разных размерностях латентного пространства (среднее значение и стандартное отклонение)
|
Задача, D |
d = 5 |
d = 10 |
d = 20 |
|||
|
Среднее |
Ст. откл. |
Среднее |
Ст. откл. |
Среднее |
Ст. откл. |
|
|
f 1 , 20 |
2,493e+03 |
3,113e+03 |
2,071e+03 |
2,746e+03 |
– |
– |
|
f 6 , 20 |
6,000e+02 |
3,872e-02 |
6,000e+02 |
3,893e-02 |
– |
– |
|
f 25 , 20 |
2,913e+03 |
7,465e-01 |
2,912e+03 |
1,027e+00 |
– |
– |
|
f 1 , 100 |
9,397e+09 |
5,040e+09 |
1,379e+10 |
7,038e+09 |
1,178e+10 |
5,522e+09 |
|
f 6 , 100 |
6,233e+02 |
3,434e+00 |
6,226e+02 |
3,388e+00 |
6,239e+02 |
3,319e+00 |
|
f 25 , 100 |
3,687e+03 |
9,210e+01 |
3,666e+03 |
8,618e+01 |
3,680e+03 |
7,721e+01 |
Как видно из табл. 2, 3, ни одно значение размерности латентного пространства (кода) не показало однозначного преимущества, что подчёркивает необходимость его настройки для каждой конкретной задачи. Тем не менее этот параметр оказывает влияние на эффективность поиска на различных стадиях алгоритма. Визуализация представлена на рис. 3, где на оси x отложено количество вычислений целевой функции, на оси y – текущее лучшее найденное решение в соответствующей субпопуляции. Графики позволяют увидеть, что в начале поиска качество решений в исходном и латентном пространствах может существенно различаться. Это различие сглаживается к поздним итерациям, что может быть связано с усилением локальной сходимости. Для наглядной оценки на рис. 4 приведены кривые, отражающие динамику глобально лучшего решения.
Далее проводится сравнительный анализ между предложенным подходом L-AEDE и базовым алгоритмом оптимизации, используемым во фреймворке (L-SRTDE). Для изучения влияния сокращения популяции на производительность метода в сравнение также включены два варианта алгоритмов без этого механизма, обозначенные как AEDE и SRTDE соответственно. Для всех тестов бюджет был фиксированным и составил 100000 вычислений целевой функции, тестирование проводились на шести задачах, отражающих разнообразные свойства ландшафтов целевой функции. Размерность латентного пространства задавалась равной 5 при D = 20 и 10 при D = 100.
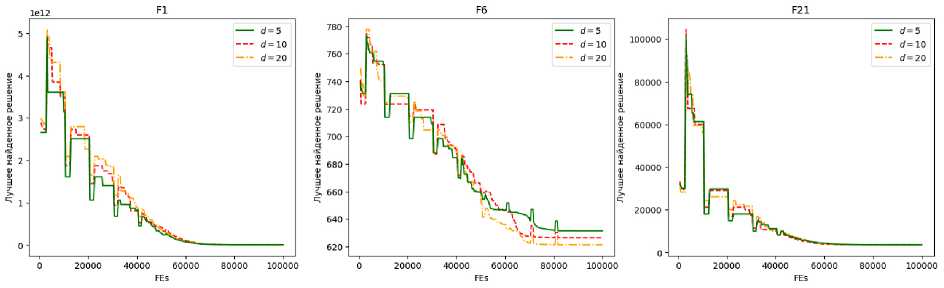
Рис. 3. Графики сходимости алгоритма для разного размера кода для задач размерности 100 (относительно субпопуляций)
Fig. 3. Convergence graphs comparison for different code dimensionality on 100D medium-budget problems relative to subpopulations
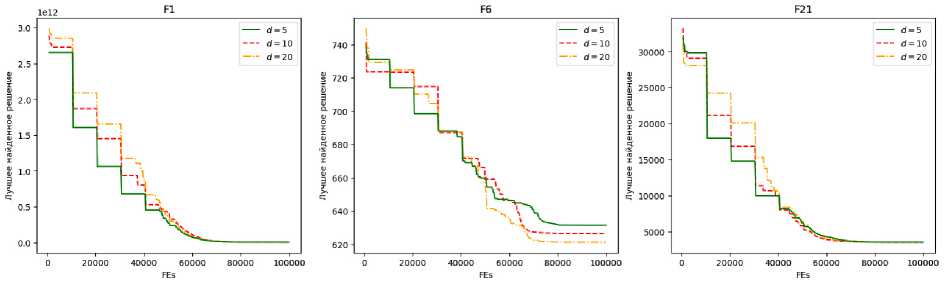
Рис. 4. Графики сходимости алгоритма для разного размера кода для задач размерности 100 (относительно общей популяции)
Fig. 4. Convergence graphs comparison for different code dimensionality on 100D medium-budget problems relative to overall population
Совокупные результаты работы алгоритмов представлены в табл. 4 и 5, где обозначение Fi соответствует i -й задаче набора CEC2022. В табл. 5 дополнительно представлено сравнение результатов с помощью критерия Манна – Уитни – Уилкоксона (уровень значимости α = 0,05). Символы означают, что алгоритм оказался статистически лучше («+»), хуже («–») или таким же («=»). Сравнения выполнены для пар: L-AEDE с L-SRTDE и AEDE с SRTDE.
Как видно из таблиц, механизм сокращения популяции оказывает существенное влияние на скорость сходимости алгоритмов. Следует отметить, что использование этого механизма в случае AEDE приводит к менее выраженной потере эффективности по сравнению с базовым мето- дом. Это, вероятно, объясняется тем, что автоэнкодер формирует латентные подпространства с более благоприятными локальными свойствами. В конфигурациях без сокращения популяции AEDE оказался более эффективен в 50 % случаев. Тем не менее при включённом механизме сокращения популяции L-SRTDE демонстрирует более стабильно высокие результаты, особенно в задачах с труднодостижимым глобальным оптимумом при ограниченном бюджете вычислений (например, f1).
Таблица 4
Результаты численных экспериментов (минимальные значения)
|
Задача, D |
L-AEDE |
L-SRTDE |
AEDE |
SRTDE |
|
f 1 , 20 |
1,000e+02 |
1,986e+02 |
2,164e+08 |
3,127e+08 |
|
f 6 , 20 |
6,000e+02 |
6,000e+02 |
6,186e+02 |
6,230e+02 |
|
f 21 , 20 |
2,306e+03 |
2,312e+03 |
2,428e+03 |
2,426e+03 |
|
f 25 , 20 |
2,910e+03 |
2,906e+03 |
2,914e+03 |
2,997e+03 |
|
f 1 , 100 |
4,798e+09 |
3,896e+09 |
3,728e+11 |
6,143e+11 |
|
f 6 , 100 |
6,166e+02 |
6,158e+02 |
6,265e+02 |
6,338e+02 |
|
f 21 , 100 |
2,614e+02 |
2,731e+02 |
2,645e+02 |
2,745e+02 |
|
f 25 , 100 |
3,538e+03 |
3,538e+03 |
3,546e+03 |
3,552e+03 |
|
F 5 , 20 |
1,143e+03 |
1,136e+03 |
1,233e+03 |
1,206e+03 |
|
F 11 , 20 |
2,900e+03 |
2,900e+03 |
2,964e+03 |
2,964e+03 |
Таблица 5
Результаты численных экспериментов (средние значения)
|
Задача, D |
L-AEDE |
L-SRTDE |
AEDE |
SRTDE |
|
f 1 , 20 |
2,071e+03 |
2,756e+02 + |
3,365e+08 |
3,647e+08 - |
|
f 6 , 20 |
6,000e+02 |
6,000e+02 = |
6,216e+02 |
6,230e+02 - |
|
f 21 , 20 |
2,642e+03 |
2,670e+03 - |
2,454e+03 |
2,451e+03 = |
|
f 25 , 20 |
2,912e+03 |
2,908e+03 = |
2,967e+03 |
3,011e+03 - |
|
f 1 , 100 |
1,379e+10 |
7,847e+09 + |
5,236e+11 |
6,935e+11 - |
|
f 6 , 100 |
6,226e+02 |
6,233e+02 = |
6,269e+02 |
6,339e+02 - |
|
f 21 , 100 |
2,616e+02 |
2,623e+02 - |
2,831e+02 |
2,846e+02 = |
|
f 25 , 100 |
3,666e+03 |
3,666e+03 = |
3,686e+03 |
3,695e+03 = |
|
F 5 , 20 |
1,168e+03 |
1,146e+03 + |
1,245e+03 |
1,239e+03 = |
|
F 11 , 20 |
2,900e+03 |
2,900e+03 = |
2,967e+03 |
2,964e+03 = |
|
+ \ – \ = |
vs. L-AEDE: |
3 \ 2 \ 5 |
vs. AEDE: |
0 \ 5 \ 5 |
Важным замечанием является тот факт, что обучение автоэнкодера на успешных решениях может приводить к охвату латентным пространством окрестностей уже найденных оптимумов, что, в свою очередь, ограничивает глобальный поиск. Разница в эффективности остаётся стабильной с увеличением размерности, что свидетельствует о меньшей или сопоставимой с традиционными ЭА чувствительности предложенного метода к «проклятию размерности».
Заключение
В работе был предложен эволюционный алгоритм с механизмом динамического снижения размерности на основе автоэнкодера. Основу метода составляет гибридная стратегия, ведущая поиск одновременно в исходном пространстве переменных и в сжатом латентном пространстве. Такая архитектура призвана повысить эффективность классических эволюционных алгоритмов и преодолеть трудности, характерные для задач высокой размерности в условиях малого бюджета вычислений целевой функции. В процессе работы адаптивно перераспределяются вычислительные ресурсы и происходит обмен решениями. Представленный подход позволяет динамически обучать модель, что даёт возможность выявлять перспективные области пространства поиска за счёт использования информации, полученной в ходе оптимизации.
Численные эксперименты на наборе тестовых задач подтвердили применимость алгоритма для сложных задач оптимизации «чёрного ящика», на их основе был выявлен ряд свойств авто-энкодеров при ускорении процесса поиска. Остаётся открытым вопрос о выборе оптимальной архитектуры и настройки гиперпараметров нейронной сети, а также способ отбора данных для контроля глобального и локального сходимости. Дальнейшая работа будет направлена на повышение робастности метода и расширение круга решаемых им задач оптимизации.
Acknowledgment. The study was supported by grant No. 24-21-00215 from the Russian Science Foundation,
