Классификация и сравнительный анализ методов машинного обучения для обработки и моделирования глазодвигательной активности

Автор: Горячкин Б.С., Савельев А.А., Лобанов Д.С., Фонин М.А.
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 1, 2026 года.
Бесплатный доступ
Рассмотрены подходы к интеллектуальной обработке данных глазодвигательной активности. Подготовлен экспериментальный набор данных, включающий реальные координаты взгляда и синтетические тепловые карты. Реализованы и исследованы четыре группы алгоритмов: методы без учителя (DBSCAN, HMM), классификаторы с учителем (SVM, Random Forest), рекуррентные (LSTM, GRU) и сверточные (CNN) нейронные сети. Проведен сравнительный анализ эффективности моделей в задачах выделения зон интереса, классификации состояний и прогнозирования траекторий. Оценена устойчивость алгоритмов к шуму и способность выявлять поведенческие паттерны. Сформулированы рекомендации по выбору методов машинного обучения в зависимости от целей анализа визуального внимания.
Айтрекинг, движения глаз, машинное обучение, классификация, кластеризация, визуальное внимание, тепловые карты
Короткий адрес: https://sciup.org/148333230
IDR: 148333230 | УДК: 004.81 | DOI: 10.18137/RNU.V9187.26.01.P.160
Classification and Comparative Analysis of Machine Learning Methods for Processing and Modeling of Oculomotor Activity
The article considers the approaches to the intelligent processing of oculomotor activity data. An experimental dataset comprising real gaze coordinates and synthetic heatmaps was prepared. Four groups of algorithms have been implemented and investigated: unsupervised methods (DBSCAN, HMM), supervised classifiers (SVM, Random Forest), recurrent (LSTM, GRU), and convolutional (CNN) neural networks. A comparative analysis of the models’ performance in tasks involving area of interest identification, state classification, and trajectory prediction has been conducted. The robustness of the algorithms to noise and their capability to detect behavioral patterns have been evaluated. The article gives recommendations for selecting machine learning methods depending on the objectives of visual attention analysis.
Текст научной статьи Классификация и сравнительный анализ методов машинного обучения для обработки и моделирования глазодвигательной активности
Айтрекинг – это технология, которая позволяет отслеживать направление и траекторию взгляда человека. Благодаря этой технологии можно понять, какие элементы визуальной сцены привлекают внимание, как человек воспринимает информацию и как он принимает решения. Подобные данные находят применение в самых разных областях – от психологии и педагогики до маркетинга, эргономики автоматизированных систем [1] и цифрового дизайна. Современные системы регистрации взгляда способны фиксировать движения глаз с высокой точностью и частотой, создавая богатые массивы координат. Однако чтобы извлечь из этих данных полезную информацию, необходимо применить методы анализа, которые позволят выявить в них закономерности и интерпретировать поведение наблюдателя.
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2026. № 1
Одним из наиболее перспективных направлений в этой области является использование алгоритмов машинного обучения. Такие методы позволяют решать целый спектр задач: выделять фиксации и саккады, определять зоны интереса (areas of interest, AoI), классифицировать типы визуального поведения, а также строить предсказания дальнейших перемещений взгляда. Выбор конкретного подхода зависит от поставленной задачи, доступного объема данных и требований к результату: где-то важна высокая точность, где-то – интерпретируемость или способность обрабатывать большие массивы информации в реальном времени.
В данной работе рассматриваются четыре группы алгоритмов, которые активно применяются в анализе данных айтрекинга: методы без учителя (в том числе кластеризация и скрытые марковские модели), методы с учителем (например, опорные векторы и случайный лес), последовательные модели (LSTM, GRU) и сверточные нейронные сети (CNN). Каждая из этих групп решает свою подзадачу – от выделения устойчивых паттернов до анализа тепловых карт и прогнозирования движения взгляда во времени. В статье описаны особенности применения этих подходов, приведены примеры реализации, а также проведено их сравнение на общем наборе данных. В качестве исходной информации использовались как реальные записи координат взгляда, так и синтетически сгенерированные визуализации.
Цель работы – дать обоснованные рекомендации по выбору алгоритма в зависимости от конкретной задачи анализа визуального поведения.
Методология
Для анализа применялись координаты взгляда, собранные с помощью самописного айтрекинг-комплекса [2]. Система регистрирует положение глаз пользователя в реальном времени и сохраняет данные в виде последовательности экранных координат с временными метками. В рамках подготовки данных использовались как реальные записи, полученные в процессе взаимодействия с визуальными стимулами, так и синтетически сгенерированные тепловые карты, имитирующие различные стили визуального внимания. В качестве визуального стимула был выбран интерфейс личного кабинета студента МГТУ им. Н.Э. Баумана (см. Рисунок 1).
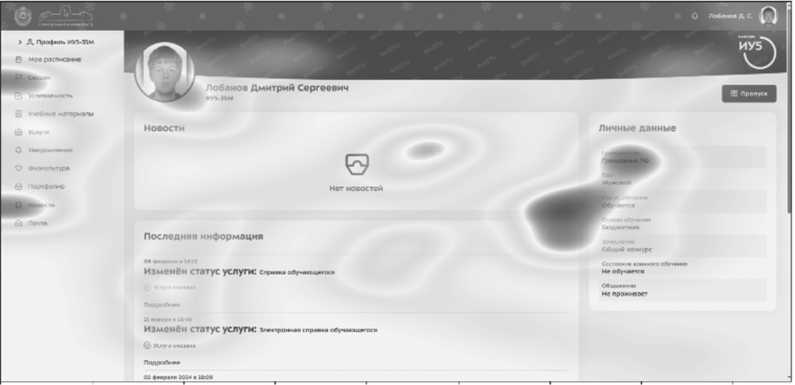
Рисунок 1. Тепловая карта, отображающая распределение фиксаций на изображении Источник: здесь и далее рисунки выполнены авторами
Классификация и сравнительный анализ методов машинного обучения для обработки и моделирования глазодвигательной активности
Перед подачей в модели координаты проходили базовую фильтрацию: устранялись аномалии, выходящие за границы экрана, применялось сглаживание по времени. Далее из временного ряда извлекались признаки: скорость и ускорение движения взгляда, расстояние между точками, направление перемещения, радиус разброса и др. Эти признаки использовались в моделях классификации и предсказания.
Для методов с учителем была выполнена полуавтоматическая разметка: на основе скорости и амплитуды движения точки делились на фиксации и саккады. Полученная разметка служила целевой переменной в задачах бинарной классификации. Для моделей, работающих с изображениями, координаты преобразовывались в тепловые карты заданного разрешения. Эти карты отражали плотность фиксаций в разных областях экрана и служили входом для сверточных нейросетей (см. Рисунок 2).
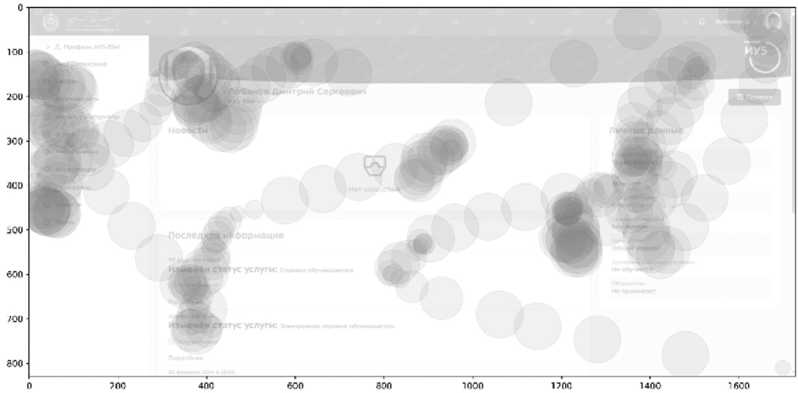
Рисунок 2. Визуализация тепловой карты данных взгляда, используемых для обучения и тестирования моделей
Алгоритмы машинного обучения
Для анализа данных движений взгляда в работе были реализованы четыре группы моделей, отличающиеся по способу обучения и типу входных данных. Такой выбор позволил охватить разные подходы – от простых интерпретируемых алгоритмов до нейросетевых архитектур. Каждая модель применялась в своей задаче: выделение зон внимания, классификация состояний, прогнозирование движения взгляда или анализ тепловых карт. Это обеспечило более полное представление о возможностях машинного обучения в контексте айтрекинга.
Модели без учителя не требуют заранее размеченных данных и применяются на начальном этапе, когда структура внутри выборки ещё не известна. Кластеризация с помощью DBSCAN позволила выделить области, в которых взгляд задерживался дольше всего, – так называемые зоны интереса. Алгоритм автоматически находит плотные скопления точек, не требуя заранее указывать их количество [3]. Дополнительно использовалась скрытая марковская модель, которая анализирует изменения скорости движения взгляда и делит последовательность на участки, соответствующие фиксациям и саккадам [4]. Эти
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2026. № 1
методы, развивающие подходы к стохастическому моделированию деятельности человека-оператора [5], особенно полезны, когда разметка отсутствует.
Алгоритмы с учителем , такие как метод опорных векторов и случайный лес, обучались на данных, где каждое наблюдение было подписано вручную или полуавтоматически. Целью таких моделей было определить, к какому типу относится текущее состояние взгляда [6]. В качестве признаков использовались скорость, угол между движениями, амплитуда и плотность точек. Эти модели показывают хорошую точность и не требуют больших вычислительных ресурсов, что делает их удобными для сравнительного анализа.
Последовательные модели – LSTM и GRU – были реализованы для обработки временных последовательностей координат. Такие сети позволяют учитывать не только текущую точку, но и историю движения взгляда, предсказывая следующую фиксацию. Это особенно полезно при анализе устойчивости поведения, поиске закономерностей в перемещении взгляда и построении адаптивных систем, реагирующих на внимание пользователя в реальном времени.
Сверточные нейронные сети применялись к изображениям – тепловым картам, на которых визуализировалась плотность фиксаций. Эти карты строились по координатам взгляда и подавались на вход CNN в виде матриц [7]. Модель обучалась различать типы распределения внимания (например, сфокусированное или рассеянное) на основе синтетических примеров, а затем тестировалась на реальных данных. Такой подход позволил использовать визуальное представление взглядов и применять методы компьютерного зрения к задачам анализа поведения (Рисунок 3).
Predicted class: dispersed
Predicted class: focused
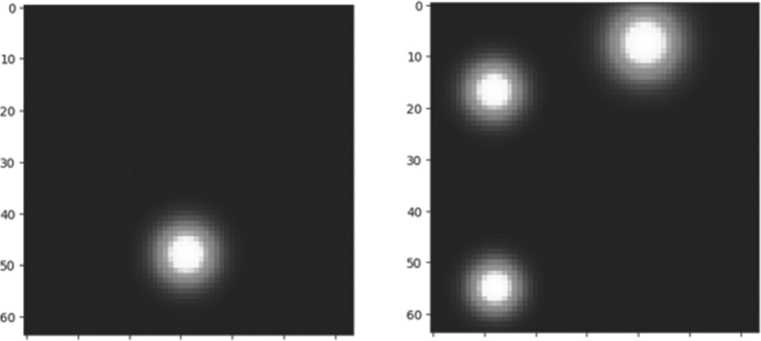
0 10 20 30 40 50 60 0 10 20 30 40 50 60
Рисунок 3. Примеры сгенерированных тепловых карт, на которых обучалась нейросеть
Эксперимент и визуализация результатов
Для оценки эффективности реализованных моделей был проведён ряд экспериментов на едином наборе данных. В качестве основной информации использовались реальные координаты взгляда, собранные в ходе визуальных заданий. Такой подход позволил протестировать алгоритмы в разных сценариях – от сегментации и классификации точек фиксации до распознавания пространственных шаблонов поведения. Результаты оценива-
Классификация и сравнительный анализ методов машинного обучения для обработки и моделирования глазодвигательной активности лись как количественно, так и визуально с помощью графиков, карт и сопоставления с базовой разметкой.
Кластеризация DBSCAN применялась к пространственным данным и визуализировалась в виде цветных облаков точек. Кластеры хорошо соответствовали зонам, в которых взгляд задерживался дольше всего. Алгоритм также продемонстрировал устойчивость к шуму: одиночные случайные точки не попадали в кластеры, что позволило отсеивать нерелевантные движения (Рисунок 4).
DBSCAN
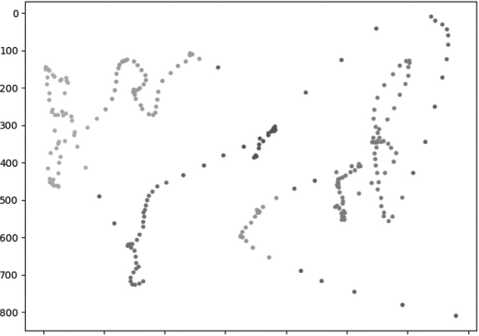
О 250 500 750 1000 1250 1500 1750
Рисунок 4. Кластеры, полученные с помощью DBSCAN на выборке фиксаций
Скрытые марковские модели позволяли автоматически сегментировать временные ряды без ручной разметки. При визуализации на графике координат модель выделяла участки, соответствующие фиксациям и саккадам. Это дало возможность сравнивать такие сегменты с разметкой из других моделей и убедиться в совпадении. Кроме того, HMM оказалась полезной как предварительный фильтр для отбора устойчивых фрагментов движения взгляда (Рисунок 5).
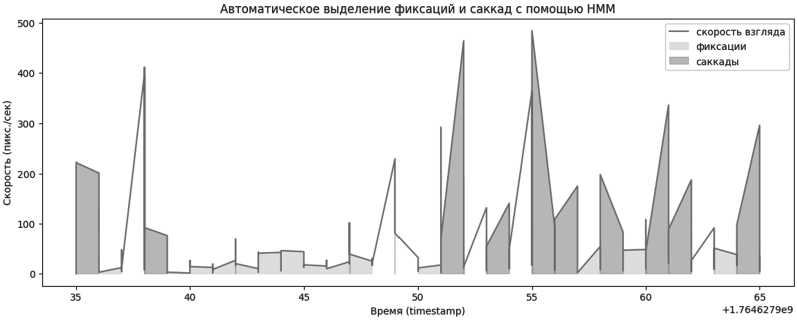
Рисунок 5. Сегментация траектории взгляда на фиксации и саккады (HMM)
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2026. № 1
Для классификации состояний взгляда (фиксация/саккада) использовались SVM и Random Forest. Их производительность оценивалась по точности, полноте и F1-мере на размеченной выборке. Оба алгоритма показали сопоставимо высокие значения метрик, однако визуализация результатов выявила различия в поведении моделей. На Рисунке 6 видно, что SVM формирует более чёткие и компактные области классов с меньшим количеством точек на границе между фиксациями и саккадами. В то же время Random Forest склонен к более рассеянной классификации: встречаются одиночные ошибки, и граница между классами менее выражена. Это указывает на то, что SVM более чувствителен к структуре признаков, тогда как случайный лес показывает лучшую устойчивость к шуму, но может давать менее уверенные границы.
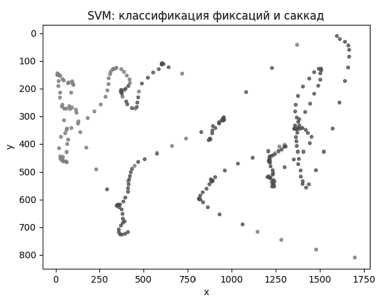
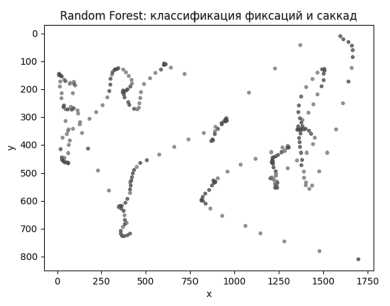
Рисунок 6. Результаты классификации SVM/Random Forest на изображении
Модели LSTM и GRU применялись для предсказания координат следующей точки взгляда по данным за предыдущие моменты времени. На представленных визуализациях (см. Рисунок 7) видно, что обе модели в целом следуют за истинной траекторией, воспроизводя форму движения взгляда. При этом GRU даёт более плавный прогноз и чуть лучше сохраняет направление перемещений. LSTM местами демонстрирует резкие отклонения, особенно при переходах между участками траектории. Это может быть связано с особенностями её внутренней памяти, которая чувствительна к резким скачкам. В целом обе модели способны воспроизводить общую структуру движения, но точность предсказания зависит от типа фрагмента: на прямолинейных участках результаты точнее, чем на резких поворотах или паузах.
Предсказание следующей точки взгляда с помощью GRU
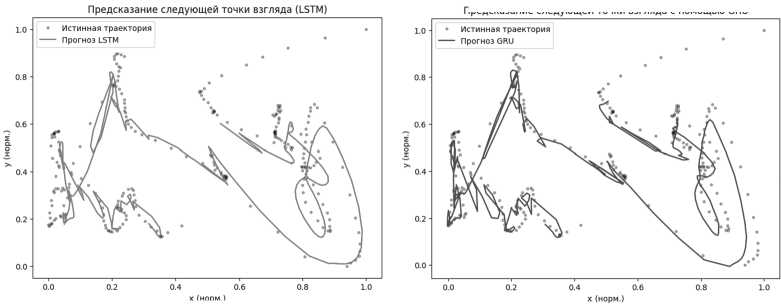
Рисунок 7. Сравнение предсказанных и реальных точек взгляда (LSTM/GRU)
Классификация и сравнительный анализ методов машинного обучения для обработки и моделирования глазодвигательной активности
Сверточная нейросеть обучалась на синтетических тепловых картах, представляющих разные стили визуального внимания. Классы карт задавались заранее и имитировали разные сценарии, например, сосредоточенное внимание в центре или рассеянное по краям. После обучения модель тестировалась на тепловых картах, построенных по реальным координатам взгляда. Визуальное сравнение показало, что модель способна обобщать признаки и корректно определять тип внимания даже на ранее не встречавшихся примерах (Рисунок 8).
Predicted: dispersed (85.2%) Predicted: focused (100.0%)

Рисунок 8. Примеры классификации тепловых карт моделью CNN
Обсуждение
Полученные результаты позволяют сопоставить возможности разных подходов к анализу данных айтрекинга.
Алгоритмы без учителя показали себя как удобный инструмент на этапе первичного изучения траекторий. DBSCAN оказался особенно полезен для выделения устойчивых зон интереса без необходимости в предварительной разметке, а HMM – для автоматической сегментации по типу активности. Однако эти методы ограничены в возможностях точной настройки и плохо подходят для задач, требующих индивидуального обучения под конкретного пользователя или сценарий.
Методы с учителем обеспечили хорошее качество классификации состояний взгляда. SVM продемонстрировал чёткое разделение классов, но требовал тщательной подготовки признаков. Случайный лес оказался более устойчив к шуму, но при этом менее уверенно разделял пограничные области. Оба метода показали, что даже на ограниченной выборке можно добиться высокой точности, если данные предварительно структурированы и размечены. Однако сам процесс разметки требует значительных временных затрат и не всегда легко масштабируется.
Рекуррентные модели (LSTM и GRU) дали возможность не только предсказывать направление взгляда, но и выявлять поведенческие шаблоны. GRU показал более стабильное поведение на длинных отрезках, тогда как LSTM оказался чувствителен к резким изменениям траектории. Такие модели особенно полезны для задач, где важно учитывать контекст движения взгляда, но для их обучения требуется значительно больше данных, чем для простых классификаторов. Кроме того, их поведение менее прозрачно по сравнению с классическими методами.
Сверточная нейросеть , обученная на тепловых картах, показала хорошие результаты при переносе на реальные данные, несмотря на обучение на синтетических. Это демон-
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2026. № 1
стрирует применимость визуального представления взглядов для задач классификации паттернов внимания. Однако модели такого типа требуют больших вычислительных ресурсов и заранее сформированных изображений, что ограничивает их применение в режиме реального времени.
Заключение
В работе проведён сравнительный анализ различных подходов к обработке и интерпретации данных движений взгляда с применением методов машинного обучения. Реализованы и протестированы четыре группы моделей: алгоритмы без учителя, методы с учителем, рекуррентные нейросети и сверточные сети. Эксперименты показали, что выбор модели зависит от конкретной задачи: кластеризация зон интереса, классификация состояний, предсказание траектории или анализ плотности внимания.
Модели без учителя оказались полезными на этапе первичного анализа и при отсутствии разметки; методы с учителем продемонстрировали высокую точность при условии подготовки обучающей выборки. Последовательные сети позволили учитывать временную структуру данных, а сверточные архитектуры – анализировать пространственное распределение внимания. Обобщив результаты, можно рекомендовать использовать комбинацию подходов: простые модели – для базовой фильтрации и классификации, более сложные – для выявления поведенческих паттернов и визуального анализа.
