Классификация рентгеновских изображений грудной клетки больных вирусной пневмонией и COVID-19 с помощью нейронных сетей

Автор: В.Г. Ефремцев, Н.Г. Ефремцев, Е.П. Тетерин, П.Е. Тетерин, Е.С. Базавлук
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 1 т.45, 2021 года.
Бесплатный доступ
В статье рассматривается применение нейронных сетей для классификации рентгенографических изображений больных пневмонией и COVID-19. Для выбора наилучших параметров изменения размеров и адаптивного выравнивания гистограммы яркости изображений, а также оптимальной архитектуры нейронной сети и ее гиперпараметров использовались precision, recall и f1-score. Высокие значения этих метрик качества классификации (> 0,91) убедительно свидетельствуют о надежном разграничении рентгенографических изображений больных пневмонией от больных COVID-19. Это открывает возможность создания модели c хорошей предсказательной способностью без привлечения готовых сложных моделей и без предварительного обучения на сторонних данных. Полученные результаты дают хорошие перспективы разработки чувствительных и надежных экспресс-методов диагностики заболевания COVID-19.
Обработка рентгенографических изображений, сверточная нейронная сеть, классификация, COVID-19.
Короткий адрес: https://sciup.org/140253877
IDR: 140253877 | DOI: 10.18287/2412-6179-CO-765
Текст статьи Классификация рентгеновских изображений грудной клетки больных вирусной пневмонией и COVID-19 с помощью нейронных сетей
Быстрое распространение по всему миру короно-вируса SARS-CoV-2 и связанного с ним заболевания COVID-19 [1, 2] в значительной степени объясняется отсутствием оперативной диагностики. Наибольшей достоверностью обладают методы на основе полимеразной цепной реакции, но результат, как правило, готов через несколько часов при обеспечении довольно высоких требований к соблюдению технологии анализа и к профессионализму медперсонала. Поэтому разработка быстрых и надежных систем обнаружения COVID-19 необходима для предотвращения пандемии этого заболевания.
Наиболее сильно при COVID-19 поражаются легкие [3]. Для распознавания пневмонии, вызванной различными вирусами, широко применяется компьютерная томография с анализом полученных изображений методами глубокого обучения [4, 5]. Рентгенологическая диагностика, хотя и обладает меньшей разрешающей способностью, является более распространенной из-за большей доступности рентгеновских аппаратов и оказывает меньшее радиационное воздействие на пациентов. В настоящее время появляются работы, в которых предлагается использовать нейронные сети (НС) для обнаружения COVID-19 на основе анализа рентгенографических изображений using neural networks. Computer Optics 2021;
(РИ) [6–8]. В [9] сверточную нейронную сеть вначале обучали на внешнем наборе данных ImageNet, а затем дообучали, используя 13800 РИ, из которых 183 были с COVID-19. В работе [10] для выявления заболеваний COVID-19 была создана НС путем уменьшения слоев и фильтров уже существующей DarkNet, и для получения модели применялось 127 рентгенограмм с диагнозом COVID-19. В [11] и [12] показана возможность применения готовых НС Alexnet, Googlenet, Resnet18 и Truncated Inception Net для диагностики COVID-19, используя всего 307 РИ, и отмечено преимущество Googlenet в некоторых сценариях. В этих исследованиях показана перспективность данного направления и подчеркнуто, что его развитие сдерживает крайне малое количество РИ с COVID-19, находящихся в открытом доступе. В [13], применяя предварительно обученные модели, показано, что из VGG19, MobileNet v2 Inception, Xception, Inception и ResNet v2 лучшие результаты дает MobileNet v2, при этом отмечается, что точность классификации сильно зависит от количества образцов, представленных в каждом классе. В работе [14] особое внимание уделяется предварительной обработке данных для повышения точности классификации.
Целью данного исследования является разработка классификатора РИ больных вирусной пневмонией и COVID-19 на базе наиболее простой НС, без исполь- зования готовых моделей других разработчиков и без предварительного обучения на сторонних данных, имея только небольшой набор РИ.
Предварительная обработка изображений и движение информационных потоков
Основные этапы подготовки данных и движения информационных потоков приведены на рис. 1. Рентгеновские снимки были получены из источника [15], где они находились в открытом доступе в виде архива, содержащего 219 РИ формата PNG больных COVID-19 и 1341 РИ больных вирусной пневмонией, с размером 1024 × 1024 пикселей. В сопроводительном файле указано происхождение РИ: "We have developed the database of COVID-19 x-ray images from Italian Society of Medical and Interventional Radiology (SIRM) COVID-19 DATABASE, Novel Corona Virus 2019 Dataset developed by Joseph Paul Cohen and Paul Morrison and Lan Dao in GitHub and images extracted from 43 different publications". Все исходные РИ на первом этапе были разделены на две группы по классификационному признаку и помещены в соответствующие папки. В папке COV_ALL поместились РИ больных COVID-19, а в папке VPN_ALL были размещены РИ больных пневмонией, и далее они поступали в блок предварительной обработки (блок PREPROCESSING).
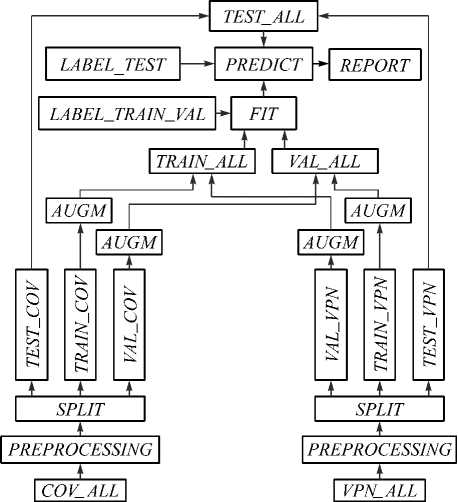
Рис. 1. Схема предварительной обработки изображений и движения информационных потоков
Предварительный анализ РИ показал, что по краям некоторых снимков находятся служебные символы, которые в закодированном виде могут нести информацию о принадлежности изображения к тому или иному классу.
Чтобы НС искала информационные признаки именно на изображениях легких, посредством опера- ции CROP на всех исходных снимках было удалено по 10 % периферийной части изображения. Так как изображение математически представляет собой матрицу, то вырезанное изображение получается путем копирования матрицы, пропуская по 10% первых и последних строк, а также пропуская по 10% левых и правых колонок изображений. На языке Python эта математическая операция формализуется следующим образом:
im_crop = im[102:922,102:922], где im – матрица исходного изображения, im_crop – матрица обрезанного изображения.
Дальнейший визуальный анализ РИ показал, что они крайне неоднородны по яркости. В информационно важных областях легких наблюдались или излишние затемнения, или осветления, т.е. значения пикселей были ограничены небольшим диапазоном и, соответственно, присутствовал узкий пик на гистограмме яркости. Простое растяжение гистограммы для всего изображения может привести к нежелательному изменению яркости. Поэтому для лучшего проявления информационных признаков к РИ была применена операция адаптивного выравнивания гистограммы посредством функции CLAHE библиотеки компьютерного зрения OpenCV.
В этом алгоритме изображения разбиваются на прямоугольные участки и для каждого рассчитывается функция распределения яркости пикселей, как функция относительного числа пикселей от конкретных значений яркости. Преобразованное изображение получается изменением яркости каждого пикселя Rj входного изображения в значение яркости Sk соответствующего пикселя выходного изображения, рассчитанное по формуле [16]:
k n j
Sk "^ , j=0 n где k – номер пикселя, изменяется от 0 до L-1,
L – максимальное число градации яркости, а j изменяется от 0 до k ;
nj – число пикселей с яркостью Rj, n – общее число пикселей изображения.
Затем для удаления артефактов на границах участков в виде эффекта шахматного поля применяется билинейная интерполяция, т.е. вычисление средневзвешенного значения яркости пикселей путем линейной интерполяции сначала в одном диагональном направлении, а затем в другом.
Для получения изображений необходимого размера, согласно рекомендации разработчиков библиотеки OpenCV, применялась функция cv2.imresize() с алгоритмом интерполяции cv2.INTER_AREA, так как применение этого алгоритма исключает появление искажений типа «муар».
Далее для каждого класса (блок SPLIT) формировались выборки обучения (train), проверки (val) и тестирования (test) НС. Для этого все РИ перемешивалась случайным образом при помощи функции Python3 random.shuffle(). В этом случае модуль random генерирует случайные числа, а расширение shuffle() обеспечивает случайное перемешивание снимков.
Затем в каждом классе также случайно выбиралось по 10 % РИ, и они помещались в тестовые выборки (блоки TEST_COV и TEST_VPN).
Оставшиеся данные для каждого класса были снова в случайном порядке разделены на два независимых набора в соотношении 90% и 10 % для обучения (блоки TRAIN_COV, TRAIN_VPN) и проверки (блоки VAL_COV и VAL_VPN). После этого все данные были нормализованы. Для того, чтобы каждый снимок попадал в тестовую выборку, все расчеты и соответственно случайные перемешивания были выполнены 50 раз.
Для уменьшения переобучения и частичной компенсации дисбаланса количество изображений в каждом классе для обучающей выборки было увеличено до 10000 путем добавления трансформированных снимков (блок AUGM). Трансформации представляли собой изменения в случайном порядке следующих параметров: поворот в интервале от +15 и до -15 градусов, сдвиг влево и вправо в интервале от 1 и до 15 пикселей, изменение масштаба и яркости в интервале от 0 и до 10%, поворот вокруг горизонтальной оси в интервале от 1 и до 180 градусов, что обеспечивалось функцией ImageDataGenerator, входящей в библиотеку Keras.
Далее слиянием соответствующих выборок двух классов были сформированы полные выборки обучения, проверки и тестирования (блоки TRAIN_ALL, VAL_ALL и TEST_ALL).
Для обучения НС (блок FIT) на ее вход подаются полные выборки обучения и проверки, а также метки классов этих выборок (блоки LABEL_TRAIN и LABEL_VAL). Результатом обучения является модель НС.
Для тестирования этой модели она поступает на блок PREDICT, куда также поступает полная выборка для тестирования (TEST_ALL) и соответствующий набор меток классов (блок LABEL_TEST).
Блок REPORT показывает результат работы модели на тестовых данных. По каждому классу выводится информация по основным критериям классификации: precision, recall и f1-score. Также показывается количество РИ в каждом классе.
Precision = TP /(TP + FP) показывает, сколько из предсказанных положительных результатов являются действительно положительными.
Recall = TP / (TP + FN) показывает, сколько от общего числа фактических положительных результатов было предсказано как положительные.
F1-score – среднее гармоническое precision и recall и применяется для расчета сбалансированного среднего результата.
Где TP, TN, FP и FN – истинно-положительный, истинно-отрицательный, ложно-положительный и ложно-отрицательный результат.
Для формирования отчета применялась функция classification_report библиотеки машинного обучения scikit-learn.
Структура сверточной нейронной сети
Для разработки классификатора РИ использовалась сверточная НС, на вход которой подаются РИ. Результатом работы обученной НС является метка, которая относит изображение к тому или иному классу. Методы перекрестной проверки и решетчатого поиска показали, что лучшие результаты дает НС, состоящая из пяти следующих друг за другом сверточных слоев (рис. 2). Эти слои имели 32, 64, 128, 192 и 256 фильтров для первого и последующих сверточных слоев и одинаковые размеры ядра (3 × 3). Подробное описание других слоев приведено в [17].
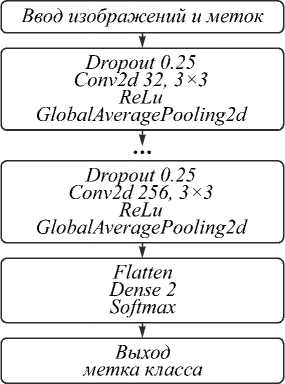
Рис. 2. Архитектура и основные параметры свёрточной НС
При обучении использовался оптимизатор Adam (lr= 0.001, beta_1 = 0.9, beta_2 = 0.999). В нашем случае лучшие результаты были получены, когда в качестве функции потерь использовалась не бинарная, а категориальная кросс-энтропия. Обучение проводили при 350 эпохах. Для предотвращения переобучения применялась регуляризация.
При выборе архитектуры и гиперпараметров НС использовалась метрика accuracy=(TP+TN) /(TP+TN+FP+FN), отражающая количество верно классифицированных результатов, поделенное на их общее количество [18].
Характер изменения значений accuracy и loss-функции для Train и Val выборок (рис. 3) указывает на отсутствие переобучения модели НС.
Качество классификатора оценивалось на тестовом наборе по наиболее часто используемым метрикам Precision, Recall и F1-score [18, 19].
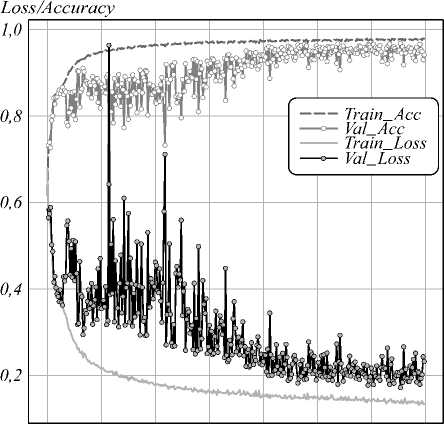
О 50 100 150 200 250 300 350
Epoch
Рис. 3. Изменение accuracy и loss-функции в процессе обучения свёрточной нейронной сети
Выбор наилучшей архитектуры и гиперпараметров НС осуществлялся по максимальным значениям этих метрик и по их равномерности для каждого класса.
Анализ полученных результатов
Для оценки предсказательной способности полученного классификатора были выбраны снимки с размером: 768 × 768, 512 × 512, 224 × 224, 112 × 112 и 64 × 64 пикселей. Лучшие результаты были получены на снимках с размером 224 × 224, и далее приведены результаты обработки этих изображений.
В табл. 1 для тестовой выборки представлены значения метрик качества этого классификатора для больных пневмонией и COVID-19.
Табл. 1. Метрики точности классификатора
|
precision |
recall |
f1-score |
Кол-во РИ |
|
|
Пневмония |
0,99 |
0,99 |
0,99 |
134 |
|
COVID-19 |
0,91 |
0,95 |
0,93 |
21 |
Приведённые высокие значения критериев классификации (>0,91) убедительно свидетельствуют о надежной классификации, т.е. о надежном отличии РИ больных пневмонией от РИ больных COVID-19.
Высокие значения precision, приведенные в табл. 1 (0,99 для пневмонии и 0,91 для COVID-19), указывают на небольшое количество ложно-положительных обнаружений этих заболеваний, а высокие величины recall (0,99 для пневмонии и 0,95 для COVID-19) свидетельствуют, что классификатор дает неверный результат не более чем в 5 % случаев с COVID-19. Более высокие значения метрик для пневмонии возмож- но связаны со значительно большим количеством РИ с этим заболеванием.
Все показатели, приведенные в табл. 1, указывают на высокое качество классификации, что однозначно свидетельствуют о возможности применения НС для обнаружения случаев COVID-19 по РИ грудной клетки.
Программные средства: Win 10x64, Python 3.7, Numpy 1.16.5, OpenCV 4.2.0, Matplotlib 3.1.1, Tensorflow 2.1.0, Scikit-Learn 0.22.
Аппаратные средства: Intel Corei i7-7700, 32GB DDR3, SSD Samsung 970 Pro 512GB, NVIDIA GeForce GTX 1080.
Выводы
Оценка предсказательной способности представленной НС показала, что при оптимальных пробопод-готовке и выборе архитектуры, а также правильном подборе гиперпараметров существует возможность создания классификатора РИ больных вирусной пневмонией и COVID-19 без привлечения готовых сложных моделей и без предварительного обучения на сторонних данных.
Увеличение количества РИ больных COVID-19 приведет к повышению предсказательной способности классификатора и созданию чувствительных и надежных экспресс-методов диагностики, что уменьшит нагрузку на систему здравоохранения.
Сознавая острую необходимость создания высокоточных и практических решений по оперативному обнаружению COVID-19, авторы готовы предоставить всю информацию, полученную в ходе выполнения данной работы, в т.ч. и исходный код НС, научному сообществу и заинтересованным разработчикам.
Работа выполнена при поддержке программы «Повышение конкурентоспособности ведущих университетов РФ» (проект 5-100), контракт №02.a 03.21.0005, 27.08.2013.
