Комбинирование подходов кластеризации и классификации для задачи распознавания эмоций по речи

Автор: Полякова А.С., Сидоров М.Ю., Семенкин Е.С.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 2 т.17, 2016 года.
Бесплатный доступ
Общение - это важная способность человека, которая основана на лингвистике и эмоциональной составляющей. В области техники распознавание эмоций компьютером до сих пор остается сложной проблемой, особенно когда распознавание основывается исключительно на голосе, который является основным средством общения. Выбор множества параметров для автоматической классификации и распознавания является необходимым этапом в математической постановке задачи. Эффективность распознавания эмоций зависит от типа базы данных, используемой в системе. Распознавание эмоций говорящего - это непростая задача, требующая выполнения последовательных операций, таких как идентификация голосовой активности, выделение признаков, обучение и классификация. Идентификация эмоций по речи (по акустическим характеристикам) является одной из самых популярных и обсуждаемых задач в области компьютерной лингвистики. В этой области основным критерием обработки данных является точность. В данной работе для решения задачи автоматического распознавания эмоций предлагается использовать различные методы интеллектуального анализа данных, такие как искусственные нейронные сети, метод опорных векторов, логистическая регрессия и др. В качестве метода предобработки данных предлагается использовать предварительную кластеризацию с последующим применением алгоритмов классификации. Для выделения значимых признаков используется метод главных компонент. Тестирование предлагаемого подхода, объединяющего в себе кластеризацию и классификацию, проведено на задаче распознавания эмоций по акустическим характеристикам.
Распознавание эмоций, кластеризация, классификация, искусственные нейронные сети, метод опорных векторов
Короткий адрес: https://sciup.org/148177566
IDR: 148177566 | УДК: 004.93
Combining clustering and classification approaches for speech-based emotion recognition problem
Communication is an important ability of a human, which is based on linguistics and the emotional component. In the field of technology, the emotion recognition is still a challenge, especially when the recognition is based solely on the voice, which is the primary means of human communication. Selecting of relevant features for automatic classification and recognition is an important step. Recognition efficiency of speaker’s emotions depends on the database used in the system. Recognition of speaker’s emotions is a difficult task, since it requires a set of consecutive operations, such as voice activity identification, feature extraction, training and classification. Speech-based emotion recognition is one of the most popular and common task in the field of the computer linguistics. In this area, the main criterion is the accuracy of the classification procedures. In current work, a variety of data mining techniques, such as artificial neural networks, logistic regression, support vector machines, are proposed to solve the problem of automatic emotion recognition. To improve the performance of emotion recognition we used pre-clustering and classification approaches. The method of principal component analysis is used for selecting important features. Testing of the proposed approach was carried out with the task of emotion recognition based on acoustic characteristics.
Текст научной статьи Комбинирование подходов кластеризации и классификации для задачи распознавания эмоций по речи
Введение. Речевая аналитика - новое направление в области речевых технологий, ориентированное на автоматический анализ разговора с целью выявления степени удовлетворенности беседой. Эволюция компьютеров, с одной стороны, и требования рынка -с другой, неуклонно стимулируют развитие систем распознавания эмоций, а также иных систем голосового анализа, определяющих уровень стресса, депрессии, усталости и т. п.
На современном этапе развития информационных технологий разработка методов автоматического определения эмоционального состояния человека по голосу является актуальной задачей, позволяющей решить ряд экономических, социальных и бытовых проблем и, кроме того, играющей важную роль в вопросах безопасности [1].
Самыми значимыми сферами деятельности с повышенной ответственностью являются космические системы (космонавты, сотрудники ЦУП), авиация (летчики, диспетчеры аэропорта), обслуживание АЭС (персонал диспетчерской и оперативных служб) и др.
К примеру, работа летчика и космонавта связана с воздействием на организм целого ряда экстремальных факторов окружающей среды и условий полета и вызывает, как правило, значительное нервноэмоциональное напряжение. Огромный интерес представляет изучение эмоциональных реакций у космонавтов во время их профессиональной деятельности, связанной с новизной обстановки, элементами риска и неопределенности, со спецификой жизни и работы в тесном замкнутом помещении, с отсутствием ряда привычных и необходимых условий комфорта, с социальной изоляцией и отрывом от Земли.
Чем сложнее полет или его отдельные элементы, тем выше уровень эмоциональных реакций. При выполнении особенно сложных полетов, связанных с новизной обстановки или повышенной опасностью, эмоциональное напряжение может являться причиной снижения работоспособности и качества выполнения полетного задания.
Однако, несмотря на множество исследований и коммерческих предложений в данной области, проблема автоматического распознавания эмоционального состояния по речи на данный момент не является полностью решенной. Процесс интерпретации (распо знавания) эмоций человека по естественной речи является весьма сложной задачей как в области математической формализации, так и в плане поиска способов четкой конкретизации эмоционального состояния, т. е. однозначного детектирования эмоции по речевому сигналу.
В общем случае системы автоматического распознавания эмоций состоят из двух компонентов (рис. 1): первый осуществляет акустическую обработку входного речевого сигнала, выделяя из него набор признаков, а второй содержит классификатор, который на основе выделенных признаков распознает эмоциональное состояние человека. Исследователями разработано множество программных систем для анализа голосовых сигналов, позволяющих извлекать акустические характеристики (OpenSMILE, Praat и др.) [2; 3]. В общем случае распознавание эмоций может производиться на основе множества входных данных, например, видеосигналы, физиологические характеристики (пульс, электроэнцефалограмма и др.), жесты, мимика и др. Однако в данной работе рассматривается распознавание эмоций, основанное только на акустических характеристиках.
В настоящее время отсутствует универсальная математическая модель для описания речевых образцов в условиях проявления разных видов эмоций.
Задача распознавания эмоций - это задача классификации, которая решается, в частности, с помощью методов интеллектуального анализа данных при постановке эксперимента в виде обучения с учителем.
Наиболее популярными алгоритмами классификации являются следующие [4]: метод ближайших соседей, метод опорных векторов, скрытые марковские модели, модель смеси нормальных распределений, модели на основе нечеткой логики и байесовские классификаторы.
Однако невозможно знать заранее, какая из моделей окажется наиболее эффективной в конкретном случае. В работе [5] для повышения надежности процедуры распознавания были разработаны технологии принятия решений коллективом классификаторов. Коллективы классификаторов были сформированы с помощью трех алгоритмических схем, которые позволяют учитывать предсказания различных моделей для принятия окончательного решения.
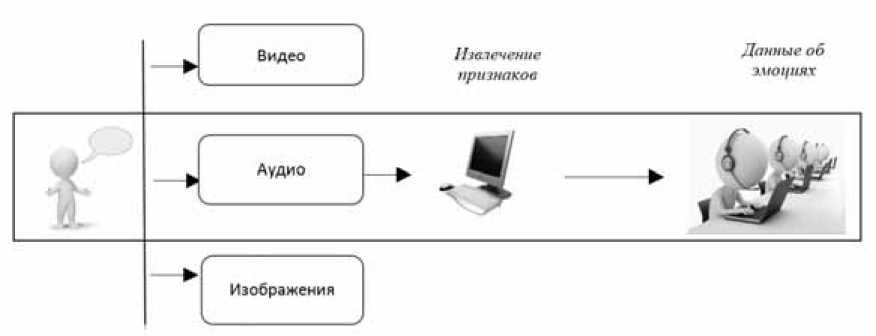
Рис. 1. Этапы задачи распознавания эмоций
Разрабатываемый подход. Среди методов интеллектуального анализа данных особое место занимают классификация и кластеризация. Когда необходимо классифицировать большие объемы информации на пригодные для дальнейшей обработки группы, кластерный анализ может оказаться полезным и эффективным.
Чтобы воспользоваться всеми преимуществами обоих подходов рядом исследователей было разработано множество способов комбинирования классификаторов и алгоритмов кластеризации [6-9].
В работе [10] в качестве дополнительного шага к классификации текстов используется кластеризация, которая применяется не только на обучающей выборке, но и на тестовых данных. Кластеризация используется как метод сжатия или извлечения признаков или смысл, заложенный в текстовых документах. Такой подход позволяет изучать структуру всего набора данных. Использование этих знаний повышает эффективность работы классификатора.
В работе [11] показано, что комбинирование простых классификаторов с ансамблем кластеров может быть эффективнее, чем работа отдельного метода интеллектуального анализа данных. Данный подход применялся к задаче определения положительных и отрицательных эмоций, мнений и другого отношения к ситуации по твиттер-сообщениям [12].
В данной работе предлагается применить подход предварительной кластеризации объектов выборки к задаче распознавания эмоций (рис. 2). В процессе решения задачи идентификации эмоций предварительная кластеризация подразумевает разбиение аудиозаписей на группы (кластеры), в каждой из которых задачу классификации решает отдельный алгоритм.
Традиционные методы кластерного анализа работают с объектами, параметры которых заданы исключительно в четком виде, что затрудняет их практическое использование при работе с объектами нечеткой природы. В настоящее время для кластеризации подобных объектов активно развиваются методы, основанные на нечеткой логике. Данные методы формируют кластеры, границы которых размыты, а объект может одновременно относиться к нескольким из них с различными степенями принадлежности.
В данной работе для кластеризации применяются 2 алгоритма: алгоритм k-средних (k-means) и алгоритм нечеткой кластеризации (fuzzy c-means). Для задачи классификации применяется несколько методов интеллектуального анализа данных: искусственные нейронные сети (ANN), метод опорных векторов (SMO), линейная регрессия (LR), а также алгоритм k-ближайших соседей (k-NN).
Использование всего набора численных признаков в процессе распознавания может существенно замедлить работу алгоритма и снизить точность получаемого решения. Поэтому важным для снижения размерности в процессе решения задачи идентификации эмоций является извлечение наиболее информативных признаков, используемых алгоритмами распознавания. Для того, чтобы выбрать наиболее подходящие характеристики, могут быть использованы статистические методы, такие как факторный анализ, а также более сложные, к примеру, основанные на генетических алгоритмах (GA).
В работах [13; 14] рассматривается процедура извлечения информативных признаков, основанная на адаптивном многокритериальном генетическом алгоритме, исследуется ее эффективность в сочетании с различными классификационными моделями.
В данной работе для отбора информативных признаков используется метод главных компонент (PCA).
Решение задачи распознавания эмоций по акустическим характеристикам. Для исследования работоспособности и качества предложенной схемы была использована база данных Emo-DB [15], содержащая более 500 эмоциональных записей говорящего. База данных включает в себя звуковые файлы с эмоциональными высказываниями 10 актеров на немецком языке. Каждое высказывание имеет свою эмоциональную метку: счастье, нейтральность, гнев, печаль, страх, скука, отвращение.
Каждый звуковой файл описывается 384 числовыми признаками, представляющими собой статистическое описание таких параметров звуковой волны, как кепстральные коэффициенты, форманты, интенсивности и др. В базе Emo-DB имена классов дискретны и изменяются от 0 до 6. Тестирование проводилось как с исходным количеством классов (7), так и с тремя классами. Три класса были сформированы путем разбиения эмоций на положительные, отрицательные и нейтральные (1-й класс - счастье; 2-й класс - нейтральность, скука; 3-й класс - гнев, печаль, отвращение, тревожность).
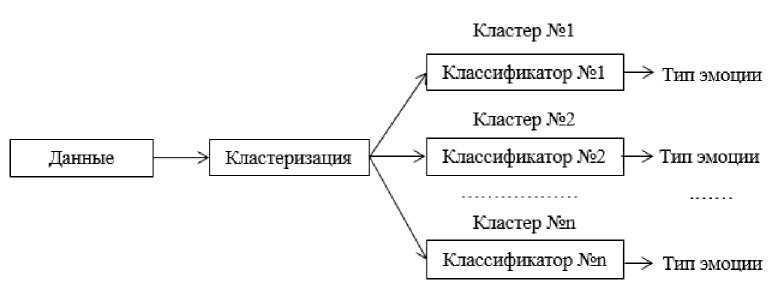
Рис. 2. Схема разработанного подхода к задаче классификации
Для анализа эффективности применения предварительной кластеризации была проведена оценка точности классификации на полном наборе признаков. Критерием качества работы классификатора является среднее значение точности, полученное на множестве прогонов (50), представленных на рис. 3-6 (статистически значимое различие эффективности алгоритмов, определяется на основе t -критерия Стьюдента, обозначение на рисунке «*»). В алгоритмах кластеризации параметр k меняется от 2 до 5.
По результатам, представленным на рис. 3, алгоритмы ANN, SMO, SL и k -NN ( k = 7) дали значимое ухудшение среднего значения точности при применении предварительной кластеризации. Алгоритмы k -NN ( k = 2, k = 4) показали меньшую эффективность, но статистически незначимую.
По результатам, представленным на рис. 4, только алгоритм k-NN при k = 2 показал улучшение по среднему значению точности, но улучшение статистиче ски незначимо. Алгоритм k-NN при k =4 показал ухудшение с применением предварительной кластеризации, но ухудшение статистически незначимо. Оставшиеся классификаторы не показали улучшений при применении предварительной кластеризации.
При сравнении двух методов кластеризации для исходного набора данных, содержащего семь классов, со всеми средними значениями точности, алгоритмы ANN, SMO, SL показывают значительно лучший результат, чем алгоритм k -NN.
По результатам, представленным на рис. 5, применение предварительной кластеризации для алгоритмов SMO и k -NN ( k = 4) позволяет добиться лучшего результата по среднему значению точности, но различия не являются статистически значимыми. Для алгоритмов ANN, SL, k -NN ( k = 2, k = 7) по среднему значению точности результат ухудшился, но различия являются статистически значимыми только для алгоритма SL.

-
□ с кластеризацией

К-NN (К=2) К-NN (К=4) К-NN (К=7)*
-
□ без кластеризации
Рис. 3. Наилучшее среднее значение точности для каждого алгоритма классификации при k от 2 до 5, полученное с помощью алгоритма кластеризации k -means (7 классов)

Список литературы Комбинирование подходов кластеризации и классификации для задачи распознавания эмоций по речи
- Классификация эмоционально окрашенной речи с использованием метода опорных векторов/И. Э. Хейдоров //Речевые технологии. 2008. Вып. 3. С. 63-71.
- Eyben F., Wöllmer M., Schuller B. Opensmile: the munich versatile and fast open source audio feature extractor//Proceedings of the international conference on Multimedia. 2010. P. 1459-1462.
- Boersma P. Praat, a system for doing phonetics by computer//Glot international. 2002. 5 (9/10). P. 341-345.
- Pantic M., Rothkrantz L. J. M. Toward an Affect-Sensitive Multimodal Human-Computer Interaction//Proceedings of the IEEE, Spec. Issue on Human-Computer Multimodal Interface. 2003. Vol. 91, No. 9. P. 1370-1390.
- Эффективная процедура аутентификации студента по речи в дистанционном образовании/К. Ю. Брестер //Вестник СибГАУ. 2014. № 5(57). P. 51-57.
- A differential evolution algorithm to optimise the combination of classifier and cluster ensembles/L. F. S. Coletta //International Journal of Bio-Inspired Computation. 2014. Vol. 7, No. 2. P. 111-124.
- Rahman A., Verma B. Cluster-based ensemble of classifiers//Expert Systems. 2013. Vol. 30. No. 3, P. 270-282.
- Lefever E., Fayruzov T., Hoste V. A combined classification and clustering approach for web people disambiguation//Proceedings of the 4th International Workshop on Semantic Evaluations. 2007. P. 105-108.
- Papas D., Tjortjis C. Combining Clustering and Classification for Software Quality Evaluation//Proceedings 8th Hellenic Conference on AI, SETN 2014. Ioannina, 2014. P. 273-286.
- Kyriakopoulou A., Kalamboukis T. Combining Clustering with Classification for Spam Detection in Social Bookmarking Systems//Proceedings of The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases Discovery Challenge, (ECML/PKDD RSDC ’08). 2008. P. 47-54.
- Ghosh J., Acharya A. Cluster ensembles//Wiley Interdisc. Rew.: Data Mining and Knowledge Discovery. 2011. Vol. 1, No. 4. P. 305-315.
- Combining Classification and Clustering for Tweet Sentiment Analysis/L. F. S. Coletta //Proceedings of the Brazilian Conference on Intelligent Systems (Bracis 2014). São Carlos, 2014. P. 210-215.
- Self-adaptive multi-objective genetic algorithms for feature selection/C. Brester //Proceedings of the International Conference on Engineering and Applied Sciences Optimization. Kos Island, 2014. P. 1838-1846.
- Speech-Based Emotion Recognition: Feature Selection by Self-Adapted Multi-Criteria Genetic Algorithm/M. Sidorov //Proceedings of the 9th edition of the Language Resources and Evaluation Conference (LREC). Reykjavik, 2014. P. 3481-3485.
- A database of german emotional speech/F. Burkhardt //Proceedings of the International Speech Communication Association. Baixas, 2005. P. 1517-1520.
