Комплексный обзор моделей извлечения контуров: классических и основанных на подходах ИИ

Author: Мухриддин Араббоев, Шохрух Бегматов, Анастасия Пузий
Journal: Современные инновации, системы и технологии.
Section: Управление, вычислительная техника и информатика
Article in issue: 4 (4), 2024.
Free access
Извлечение контуров является основной задачей в компьютерном зрении, служащей основой для обнаружения объектов, сегментации и понимания сцены в различных приложениях, включая автономные транспортные средства, медицинскую визуализацию и промышленную автоматизацию. В этой статье представлен углубленный обзор как классических, так и современных моделей извлечения контуров на основе искусственного интеллекта (ИИ). В ней рассматриваются классические методы, такие как детекторы краев и операторы на основе градиентов, а также передовые модели ИИ, включая сверточные нейронные сети и архитектуры семантической сегментации. Изучая сильные стороны, ограничения и применимость каждой модели к различным реальным задачам, мы стремимся предложить всеобъемлющее руководство по извлечению контуров, выделить ключевые проблемы и предложить потенциальные направления исследований в этой развивающейся области.
Извлечение контура, Canny, U-Net, Holistically-Nested Edge Detection (HED), ContourNet, Mask R-CNN
Short address: https://sciup.org/14131307
IDR: 14131307 | DOI: 10.47813/2782-2818-2024-4-4-0157-0175
Text of the article Комплексный обзор моделей извлечения контуров: классических и основанных на подходах ИИ
DOI:
Contour extraction, the process of identifying object boundaries within an image, is critical in various computer vision applications. Accurate contour extraction facilitates more effective object recognition, segmentation, and tracking, which are essential in fields such as robotics, healthcare, and geospatial analysis. Classical contour extraction techniques, such as edge detection and gradient operators, laid the foundation for this area; however, these methods often face challenges with complex images or scenes containing overlapping objects.
The advent of artificial intelligence (AI), particularly deep learning, has introduced powerful contour extraction models capable of handling complex structures, scale variations, and noise with high precision. This paper provides a structured review of both classical and AI-based contour extraction approaches, evaluating the strengths and weaknesses of each method. We explore edge detection, morphological operations, and energy-minimizing models, as well as modern AI architectures, including convolutional neural networks (CNNs) and segmentation networks. By analyzing these techniques, we aim to assist researchers and practitioners in selecting the most suitable contour extraction methods for their applications.
The remainder of this paper is organized as follows. We begin by introducing classical contour extraction techniques, followed by a description of AI-based contour extraction models. Next, we provide a comparison of classical and modern AI-based contour extraction approaches. We then discuss challenges, limitations, and future directions. Finally, we present our conclusions.
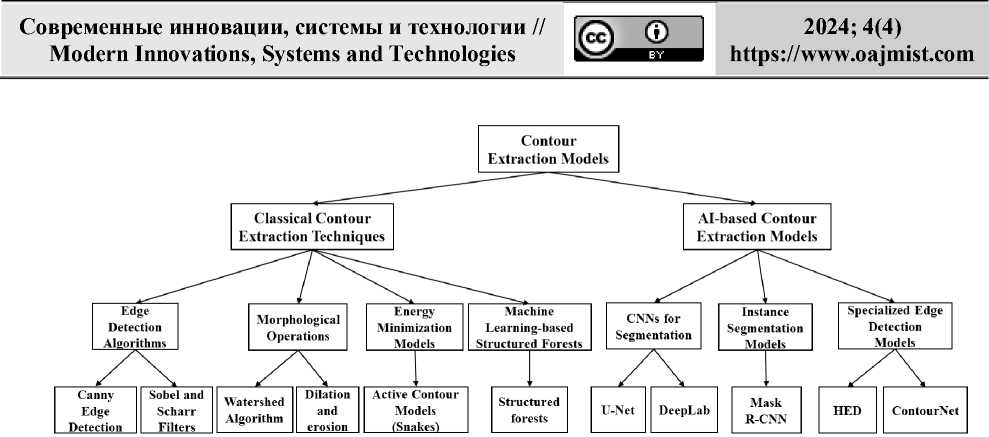
Figure 1. Contour extraction techniques/models.
CLASSICAL CONTOUR EXTRACTION TECHNIQUES
In this section, we provide a detailed review of classical contour extraction techniques (see Figure 1). The section is divided into four main subsections. The first subsection, “Edge Detection Algorithms,” discusses the earliest methods developed for contour extraction. The second subsection, “Morphological Operations,” explains techniques such as dilation, erosion, and watershed algorithm. The third subsection, “Energy Minimization Models (Snakes),” focuses on the active contour model, commonly referred to as snakes. Finally, the fourth subsection, “Machine Learning-based Structured Forests,” describes the structured forests approach.
Edge Detection Algorithms
Edge detection algorithms are some of the earliest methods developed for contour extraction. These algorithms identify regions with sharp intensity changes, which often correspond to object boundaries. Key examples include the Canny edge detection algorithm and the Sobel and Scharr filters.
Canny edge detection
The Canny Edge Detector is a widely used algorithm for detecting edges in images due to its simplicity and effectiveness [1]. The process begins with Gaussian smoothing to reduce noise, followed by gradient calculation to identify intensity variations that suggest potential edges. Next, non-maximum suppression is applied to thin the edges by retaining only the pixels with the highest gradient magnitude along the edge direction. Finally, double thresholding and edge tracking by hysteresis are used to distinguish strong edges from weak ones and connect related edge segments. This systematic approach ensures the detection of significant contours while maintaining robustness across various image processing and computer vision applications.
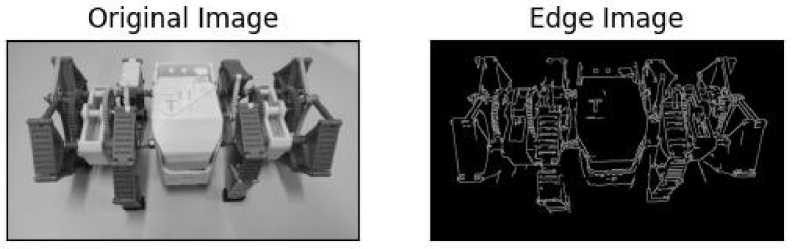
Figure 2. Edge detection result obtained using Canny Edge Detector.
Sobel and Scharr filters
The Sobel and Scharr filters are gradient-based operators widely used in image processing to compute image derivatives [2]. They emphasize regions of high spatial frequency where intensity changes rapidly, such as edges and corners [3]. The Sobel filter uses discrete differentiation kernels to approximate gradients in the horizontal and vertical directions, which are then combined to compute the gradient's magnitude and orientation at each pixel. The Scharr filter, an improved version of the Sobel filter, achieves higher accuracy by utilizing optimized kernel coefficients that reduce aliasing and enhance sensitivity to noise, particularly in diagonal directions. Due to their computational efficiency and ability to highlight structural details, both filters are extensively employed in tasks such as edge detection, feature extraction, and texture analysis.
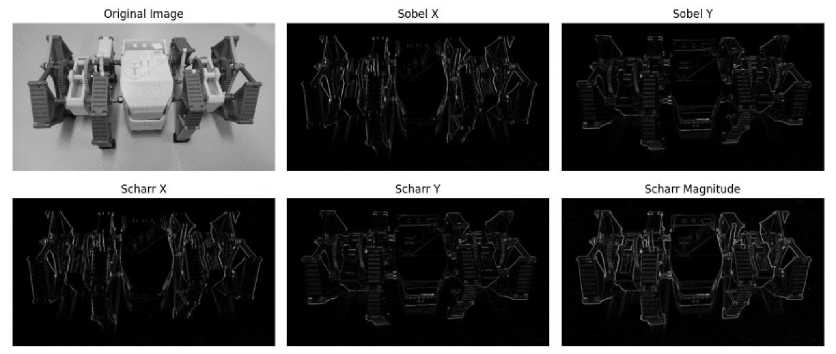
Figure 3. Edge detection result obtained using Sobel and Scharr filters.
Morphological Operations
Morphological operations, such as dilation, erosion, and the Watershed Algorithm, are commonly used to manipulate object boundaries and perform image segmentation.
Dilation
Dilation expands the boundaries of objects by adding pixels to their edges. This operation is carried out using a structuring element that slides across the image; if any pixel within the structuring element corresponds to an object pixel, the output pixel is assigned the object value. Consequently, dilation enlarges object regions and aids in bridging small gaps, connecting nearby objects, and emphasizing key features. It is commonly applied in tasks such as optical character recognition (OCR) preprocessing and medical imaging to enhance structures like blood vessels.
Erosion
Erosion reduces object boundaries by removing pixels from the edges, effectively shrinking the size of objects while expanding the background. This operation is performed using a structuring element; however, the output pixel is assigned to the background unless all the corresponding pixels in the structuring element belong to the object. Erosion is particularly effective for eliminating small noise, separating closely spaced objects, and simplifying complex shapes. When used together, dilation and erosion form powerful tools for tasks such as removing noise (opening) or filling small gaps (closing), providing flexibility and precision in addressing diverse image processing challenges.
Watershed algorithm
The Watershed algorithm is an image segmentation technique that visualizes an image as a topographic surface, where pixel intensity values correspond to elevation [4]. It identifies local minima, or low-gradient areas, as basins and simulates flooding these regions from the lowest points outward until they converge, forming boundaries that separate distinct regions. This approach is particularly effective for images with well-defined edges and clear regional differences, making it a popular choice in applications such as medical imaging, object detection, and texture segmentation, where precise boundary detection is essential. However, the algorithm can be prone to noise and over-segmentation, challenges often addressed by preprocessing steps like smoothing, applying marker-based methods, or integrating it with other segmentation techniques to enhance its accuracy and reliability.

Figure 4. Image segmentation result obtained using Watershed algorithm.
Energy Minimization Models (Snakes)
Active Contour Model (Snakes)
The Active Contour Model (Snakes) is an image segmentation method that iteratively adjusts a deformable curve, or contour, to fit object boundaries by minimizing an energy function [5]. This energy function combines internal forces, which enforce the smoothness and continuity of the contour, with external forces derived from image features such as edges or gradients, which pull the contour toward the target boundaries. This balance ensures that the extracted contours are both accurate and visually coherent, making the method particularly effective for capturing smooth, continuous boundaries in images with complex or irregular shapes. Widely used in fields such as medical imaging, shape analysis, and object tracking, Active Contour Models are powerful but require careful initialization and parameter tuning to address challenges like sensitivity to noise or convergence to local minima. These issues can be mitigated through preprocessing techniques or by integrating the model with other segmentation methods.
Active Contour Model (Snakes)

Figure 5. Contour detection result obtained using Active Contour Model (Snakes).
Machine Learning-based Structured Forests
Structured forests
Structured forests utilize machine learning, specifically structured random forests, to enhance edge detection by learning from labeled image datasets to recognize edge patterns and boundaries with greater accuracy [6]. Unlike traditional edge detection methods that rely on pixel intensity gradients or simple heuristics, structured forests capture complex features and spatial relationships, enabling more precise edge identification. This technique is highly efficient, leveraging decision trees to classify image patches quickly, offering a significant speed advantage over conventional methods [7]. By balancing speed and accuracy, structured forests are particularly well-suited for real-time applications such as object detection, image segmentation, and video analysis. Additionally, their adaptability allows them to be trained on specific datasets, optimizing performance for various tasks and broadening their applicability across diverse image processing scenarios.
Input image Result

Figure 6. Illustration of edge detection result obtained using Structured Forests.
AI-BASED CONTOUR EXTRACTION MODELS
In this section, we provide a detailed review of AI-based contour extraction techniques (see Figure 1). The section is divided into three main subsections. The first subsection focuses on the use of Convolutional Neural Networks (CNNs) for segmentation. The second subsection discusses instance segmentation models. Finally, the third subsection examines specialized edge detection models.
Convolutional Neural Networks (CNNs) for Segmentation
Deep learning, particularly Convolutional Neural Networks (CNNs), has significantly advanced contour extraction. Listed below are some prominent CNN architectures commonly used for segmentation and contour extraction.
U-Net
The U-Net architecture is a convolutional neural network (CNN) originally developed for biomedical image segmentation [8] and has since become widely adopted for various segmentation tasks due to its precision and versatility. It employs an encoder-decoder structure, where the encoder extracts features through convolution and pooling layers, while the decoder reconstructs spatial resolution using upsampling operations. A defining feature of U-Net is its skip connections, which link corresponding layers in the encoder and decoder. These connections enable the network to preserve fine-grained spatial details while leveraging high-level semantic information. This design makes U-Net particularly effective for capturing intricate structures and detailed contours, even in complex images. Its ability to achieve accurate segmentation with limited training data has made it indispensable in fields such as medical imaging, satellite imagery, and object detection. Additionally, its modular design supports integration with advanced techniques, such as attention mechanisms and multi-scale processing, further enhancing its performance on challenging segmentation tasks.
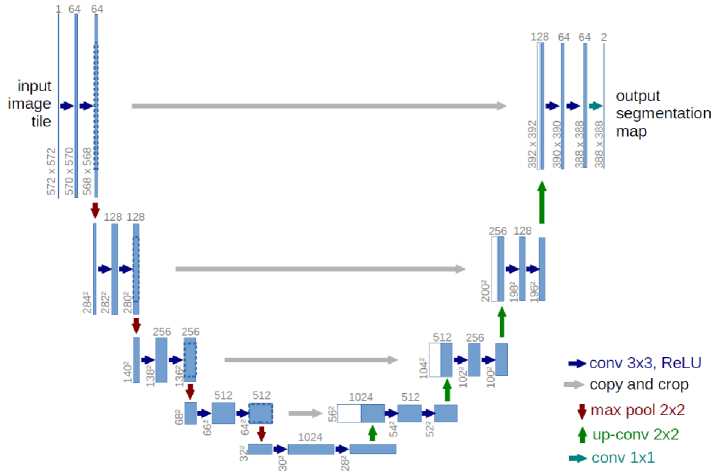
Figure 7. U-Net architecture [8].
DeepLab (V3 and V3+)
DeepLab is a state-of-the-art deep learning architecture designed for semantic image segmentation, utilizing advanced techniques such as dilated convolutions and Atrous Spatial Pyramid Pooling (ASPP) to excel in multi-scale segmentation tasks [9]. Dilated convolutions, also known as atrous convolutions, expand the receptive field of convolutional layers without increasing computational costs or losing spatial resolution. This capability enables the network to capture features and objects at varying scales, making it particularly effective for diverse segmentation scenarios. ASPP complements this by applying parallel convolutions with different dilation rates, allowing the network to aggregate contextual information from multiple scales. Together, these techniques ensure that DeepLab can robustly segment fine details and challenging contours, making it suitable for tasks involving complex boundaries and varying object sizes.
The evolution of DeepLab through its various versions has introduced significant enhancements. DeepLab V3 refined the segmentation process by improving the integration of encoder-decoder structures and incorporating batch normalization to stabilize and optimize training [10]. A key advancement in DeepLab V3 was the refinement of the ASPP module, which incorporated global average pooling to capture broader contextual information, enabling the model to segment objects with diverse shapes and sizes more effectively. These improvements marked a substantial leap in the architecture's ability to handle complex segmentation tasks while maintaining computational efficiency.
Building on these advancements, DeepLab V3+ introduced an explicit encoder-decoder design, enhancing its ability to recover spatial details lost during the encoding process [11]. In this architecture, the encoder extracts high-level semantic features, while the decoder reconstructs fine spatial details, producing more precise boundary delineations. Additionally, DeepLab V3+ integrated depthwise separable convolutions, significantly reducing computational complexity without compromising segmentation performance. This innovation made the model more practical for real-world applications, especially in scenarios with limited computational resources.
The versatility of DeepLab, particularly in its V3 and V3+ versions, has established it as a benchmark for semantic segmentation. Its ability to adapt to various segmentation challenges makes it an essential tool for applications such as autonomous driving, medical imaging, satellite imagery, and video analysis. Furthermore, its compatibility with modern backbone networks, including ResNet, Xception, and MobileNet, has enhanced its modularity and scalability, ensuring its continued relevance in addressing increasingly complex segmentation

Figure 8. DeepLab results on the PASCAL VOC 2012 validation set [9].

Figure 9. Visualization results using the authors' [10] best ASPP model on the validation set.
Instance Segmentation Models
Mask R-CNN
Mask R-CNN extends the capabilities of Faster R-CNN by introducing an additional segmentation branch that generates instance-specific binary masks, enabling it to precisely delineate the contours of each detected object [12]. This segmentation branch operates alongside the existing bounding box regression and classification tasks, allowing Mask R-CNN to perform both object detection and instance segmentation simultaneously [13]. A key innovation in its architecture is the RoIAlign layer, which resolves the misalignment issues of RoIPooling by accurately mapping regions of interest to the feature map. This ensures precise mask predictions, even for small or intricate objects, significantly enhancing the framework’s accuracy and reliability in generating high-quality segmentation outputs.
Beyond its core functionality, Mask R-CNN is highly versatile and adaptable. It supports multi-class segmentation and can be integrated with various backbone networks, such as ResNet, ResNeXt, and Feature Pyramid Networks (FPN), to enhance feature extraction and overall performance. Its modular design allows for easy customization to suit domain-specific tasks, enabling the incorporation of features like attention mechanisms or advanced postprocessing techniques for refined results. The ability of Mask R-CNN to simultaneously detect, classify, and segment objects has made it a preferred choice for applications requiring detailed object-level understanding, including medical diagnostics, autonomous driving, satellite imagery, and advanced robotics. Its robustness and flexibility continue to position it as a leading framework for instance segmentation in both research and industry.
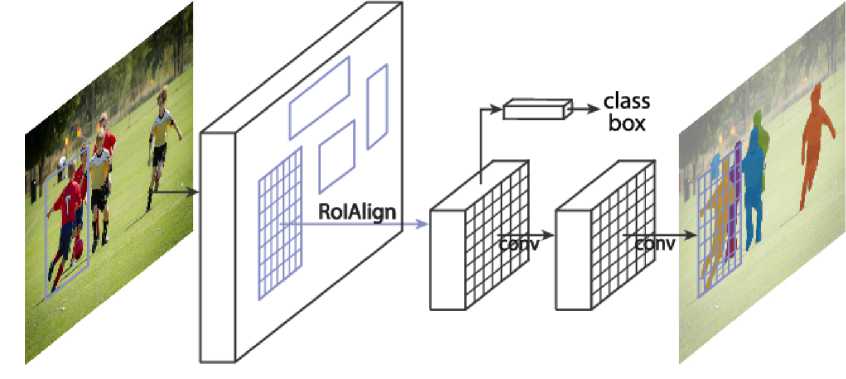
Figure 10. The Mask R-CNN framework for instance segmentation [12].

Figure 11. Mask R-CNN results on the COCO test set [12].
Specialized Edge Detection Models
Holistically-Nested Edge Detection (HED)
Holistically-Nested Edge Detection (HED) is a deep learning model specifically designed for edge detection, leveraging hierarchical feature extraction to capture fine details at multiple scales [14]. Unlike traditional edge detectors that rely solely on low-level image gradients, HED utilizes deep convolutional neural networks (CNNs) to learn rich, multi-scale feature representations [15]. This enables the model to detect both global structural contours and intricate fine edges effectively. The holistically nested architecture integrates features from intermediate layers, allowing it to seamlessly fuse coarse and fine details. This design makes HED particularly effective for complex images with varying levels of detail, excelling in scenarios where traditional methods struggle with noise or subtle boundaries.
A key innovation of HED is its use of deep supervision, where edge predictions are generated from multiple layers of the network and combined to produce a refined, high-quality edge map. This approach not only enhances the model's accuracy but also stabilizes and optimizes the training process by guiding intermediate layers to focus on edge detection tasks. HED's ability to generalize across diverse datasets and perform well in high-noise environments has made it a preferred choice for applications such as object detection, medical imaging, and scene understanding. By providing precise and reliable edge and contour information, HED has established itself as a leading solution for edge detection in both research and practical applications.

(g) Canny: a = 2
(h) Canny: a = 4
(i) Canny: <7 = 8
Figure 12. An illustration of the HED algorithm was proposed by Saining Xie and Zhuowen Tu [14].
ContourNet
ContourNet is a deep learning framework specifically designed for contour extraction, with a focus on accurately delineating detailed object boundaries [16]. By leveraging a multi-scale feature extraction approach, ContourNet captures both fine-grained details and contextual information at varying resolutions. This enables the model to handle challenging scenarios [17] where traditional edge detection methods struggle, such as differentiating intricate contours from background noise or overlapping structures. The integration of features across scales ensures that ContourNet achieves high accuracy in contour extraction, making it particularly effective for complex or cluttered images.
A key strength of ContourNet is its ability to combine global and local information, preserving broad structural outlines while maintaining fine object details. The architecture can be further enhanced with components such as feature pyramids or attention mechanisms, which improve its ability to focus on relevant regions of an image while ignoring unnecessary details. ContourNet has demonstrated success in applications such as medical imaging [18], autonomous navigation, and object recognition, where precise boundary detection is essential. Its modular and adaptable design also allows for seamless integration with other image processing tasks, such as segmentation or object detection, further expanding its utility across a wide range of real-world scenarios.
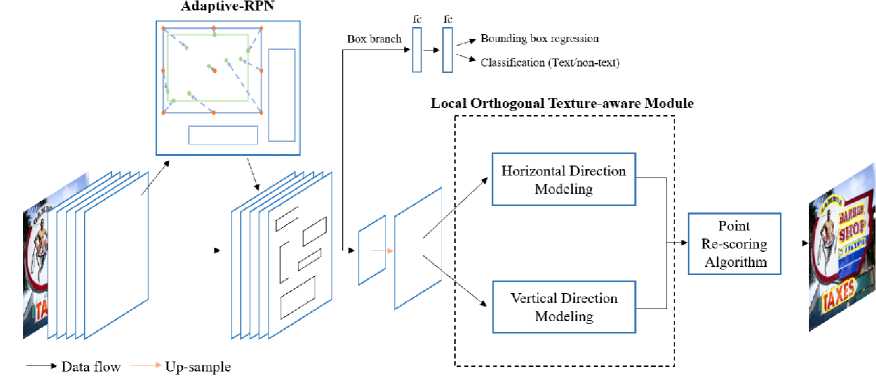
Figure 13. The pipeline of ContourNet [16].
Figure 13 illustrates that ContourNet consists of three main components: the Adaptive
Region Proposal Network (Adaptive-RPN), the Local Orthogonal Texture-aware Module
(LOTM), and the Point Re-scoring Algorithm.

(c) ICDAR2015
Figure 14. Results obtained on different datasets using ContourNet [16].
COMPARATIVE ANALYSIS OF CLASSICAL AND AI-BASED APPROACHES
The selection of a contour extraction model depends on various factors such as image complexity, real-time processing requirements, and computational resources. Classical algorithms like Canny Edge Detection and Sobel filters offer simplicity and speed, making them suitable for applications with limited computational power. In contrast, AI-based models, especially those based on CNNs, provide higher accuracy and robustness in challenging scenarios but require more significant resources and training data.
Table 1. Comparative analysis of contour extraction techniques/models.
|
№ Model/ |
Classical (C)/ Advantages Limitations |
|
Method |
AI-based (AI) |
|
1. Canny Edge Detection |
C Fast and efficient; Sensitive to noise and effective for may struggle with straightforward contour complex images extraction tasks |
|
2. Sobel and |
C Simple and directional; Less effective for |
|
Scharr |
effective for preliminary complex contours or |
|
Filters |
edge detection noisy images |
|
3. Watershed |
C Effective in separating Prone to over- |
|
Algorithm |
overlapping objects and segmentation in noisy defined regions regions |
|
4. Active |
C Effective for smooth Computationally |
|
Contour |
boundary extraction; expensive and sensitive to |
|
Model |
widely used in medical initialization |
|
(Snakes) 5. Structured |
imaging C Efficient for real-time Less effective for highly |
|
forests |
applications; moderately detailed contours or noisy accurate for simple tasks images |
|
6. U-Net |
AI Excels in handling Computationally complex, fine-grained expensive and requires contours labeled data for training |
|
7. DeepLab |
AI Robust for large-scale Requires considerable contour extraction in computational resources diverse scenes |
|
8. Mask |
AI Effective for images with High computational |
|
R-CNN |
multiple overlapping demands; requires large objects; outputs both datasets for optimal contours and results classifications |
|
9. |
HED |
AI |
Captures intricate edges; suitable for complex scenes |
Requires specialized edge-labeled data for training |
|
10. |
ContourNet |
AI |
State-of-the-art accuracy |
Computationally |
|
for detailed contour |
intensive; requires a large |
|||
|
extraction |
dataset for effective |
|||
|
training |
CHALLENGES, LIMITATIONS, AND FUTURE DIRECTIONS
Contour extraction in real-world applications faces several challenges that hinder its effectiveness and scalability. A primary issue is the presence of noise and variability in image data, which complicates the accurate delineation of contours. Variations in lighting, texture, and occlusions further exacerbate these difficulties. Additionally, AI-based contour extraction models heavily rely on large datasets with accurately labeled contours, which are often difficult and costly to obtain. Moreover, the high computational demands of deep learning models pose significant obstacles, particularly for real-time applications where rapid processing is essential.
To address these challenges, future research could focus on developing hybrid models that integrate traditional contour extraction techniques with AI-based approaches. These models can leverage the strengths of both methodologies, especially in managing noisy environments. Advances in unsupervised and semi-supervised learning also hold promise, as they can reduce the dependency on large labeled datasets while ensuring robust performance. Furthermore, designing lightweight models optimized for mobile and embedded systems could greatly enhance the accessibility and practicality of AI-driven contour extraction, facilitating deployment in resource-constrained environments.
CONCLUSION
This paper has reviewed classical and AI-based models for contour extraction, comparing their strengths, limitations, and applications. While classical methods offer efficiency and simplicity, AI-based models provide higher accuracy, especially in complex scenes with overlapping or intricate contours. By summarizing and comparing these techniques, we provide a guide to assist in selecting the appropriate model for various contour extraction needs. Future advancements will likely address current limitations in data dependency and computational demand, further expanding the potential of contour extraction in computer vision applications.
