КОРРЕКЦИЯ ФЛУОРЕСЦЕНТНЫХ СИГНАЛОВ, ИСКАЖЕННЫХ НАЛОЖЕНИЕМ СПЕКТРАЛЬНЫХ ПОЛОС, В СЕКВЕНАТОРЕ НАНОФОР СПС

Автор: В. В. Манойлов, А. Г. Бородинов, А. Я. Логинов, А. И. Петров, И. В. Заруцкий, В. Е. Курочкин,
Журнал: Научное приборостроение @nauchnoe-priborostroenie
Рубрика: Приборостроение физико-химической биологии
Статья в выпуске: 2, 2025 года.
Бесплатный доступ
Важным этапом в технологии массового параллельного секвенирования нуклеиновых кислот является процесс измерения сигналов флуоресценции. Спектральный состав сигнала флуоресценции несет информацию о типе объекта флуоресценции (нуклеотида), входящего в состав образца ДНК, анализируемого секвенатором. Чем больше нуклеотидов в процессе чтения будет распознано верно, тем точнее будет результат прочтения всего генома. Явление наложения спектральных составляющих сигналов флуоресценции нуклеотидов A, C, G и T (явление перекрестных помех, в англоязычной литературе: сross-talk) – один из негативных факторов, препятствующий достоверному прочтению генома. Для борьбы с этим явлением необходим алгоритм цветокоррекции. Этот алгоритм является решающим в определении типа нуклеотида, находящегося в данных координатах (кластере) в данном цикле чтения. В работе рассматривается алгоритм цветокоррекции, позволяющий с помощью метода линейной регрессии определить матрицу перекрестных помех. На основе этой матрицы определяется обратная матрица, использование которой позволяет существенно снизить влияние наложения спектральных полос на точность оценки измерений сигналов флуоресценции. Алгоритм апробирован на экспериментальных данных и показал высокую достоверность результатов.
Секвенирование нуклеиновых кислот, математическая обработка данных, явление перекрестных помех, матрица перекрестных помех, линейная регрессия, метод наименьших квадратов
Короткий адрес: https://sciup.org/142244851
IDR: 142244851 | УДК: 543.07
CORRECTION OF FLUORESCENT SIGNALS DISTORTED BY OVERLAPPING SPECTRAL BANDS IN THE "NANOFOR SPS" SEQUENCER
An important stage in the technology of massively parallel sequencing of nucleic acids is the process of measuring fluorescence signals. The spectral composition of the fluorescence signal carries information about the type of the fluorescence object (nucleotide) included in the DNA sample analyzed by the sequencer. The more nucleotides are correctly recognized during the reading process, the more accurate the result of reading the entire genome will be. The phenomenon of overlapping spectral components of the fluorescence signals of nucleotides A, C, G and T (cross-talk) is one of the negative factors that prevents reliable reading of the genome. To combat this phenomenon, a color correction algorithm is needed. This algorithm is decisive in determining the type of nucleotide located in these coordinates (cluster) in a given reading cycle. The paper considers a color correction algorithm that allows one to determine a crosstalk matrix using the linear regression method. Based on this matrix, an inverse matrix is determined, the use of which allows one to significantly reduce the influence of spectral band overlap on the accuracy of fluorescence signal measurement evaluation. The algorithm has been tested on experimental data and has shown high reliability of the results.
Текст научной статьи КОРРЕКЦИЯ ФЛУОРЕСЦЕНТНЫХ СИГНАЛОВ, ИСКАЖЕННЫХ НАЛОЖЕНИЕМ СПЕКТРАЛЬНЫХ ПОЛОС, В СЕКВЕНАТОРЕ НАНОФОР СПС
В Институте аналитического приборостроения РАН разработан первый отечественный аппаратно-программный комплекс (АПК) для расшифровки последовательности нуклеиновых кислот методом массового параллельного секвенирования Нанофор СПС [1, 2]. Метод массового параллельного секвенирования еще называют технологией секвенирования методом синтеза. В АПК Нанофор-СПС молекулы флуорофора (флуоресцентного красителя), которыми помечены нуклеотиды A, C, G и T, возбуждаются под действием лазерного излучения. Сигналы флуоресценции каждого нуклеотида имеют длину волны, соответствующую типу нуклеотида. Сигналы флуоресценции регистрируются с помощью четырех видеокамер (по числу типов нуклеотидов) [3]. Регистрируемое излучение проходит через различные светофильтры, соответствующие длинам волн сигналов флуоресценции каждого из четырех красителей, которыми помечены нуклеотиды, — зеленый, оранжевый, красный и темно-красный. "Различные химические процессы, включенные в технологию секвенирования методом синтеза, вызывают смещения в значениях регистрируемых интенсивностей, включая эффекты фазирования / префазирования (phasing / prephasing), затухания сигнала (signal decay) и перекрестные помехи (cross-talk)" [4]. В настоящей работе рассматриваются методы коррекции флуоресцентных сигналов, искаженных влиянием перекрестных помех (cross-talk).
Предполагается, что методы коррекции флуоресцентных сигналов, искаженных другими факторами, будут рассмотрены в другой работе авторов.
Частоты излучения (эмиссии) используемых флуоресцентных красителей частично перекрываются, что приводит к корреляции показаний интенсивностей. Это в свою очередь приводит к тому, что с ростом интенсивности сигнала, например в канале нуклеотида A, растет и интенсивность сигнала в канале нуклеотида C, и наоборот.
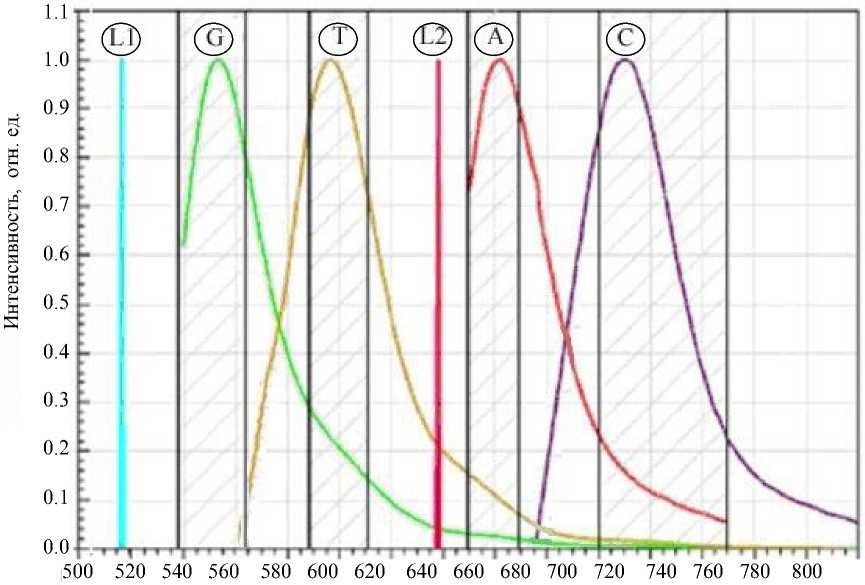
Наибольшее взаимное влияние друг на друга попарно оказывают сигналы каналов А и С, G и T соответственно (рис. 1). Также данное явление может быть названо как паразитная флуоресценция или перекрестные помехи: cross-talk.
На рис. 1 буквами G, T, A и C обозначены спектры высвечивания флуоресцентных красителей, используемых для окрашивания соответствующих нуклеотидов, а L1 и L2 — спектральные линии
Длина волны, нм
Рис. 1. Спектры эмиссии флуоресцентных меток и лазеров.
лазерных излучателей 515 и 638 нм оптической системы прибора Нанофор СПС. Штриховкой показаны полосы пропускания светофильтров в каналах регистрации. Длины волн лазерного возбуждения флуоресценции выбраны, исходя из обычных требований оптимальной квантовой эффективности каждой пары красителей. Можно ожидать эффективности возбуждения красителя G около 92% от эффективности на длине волны максимума экстинкции, красителя T — около 26%, красителя A — около 90%, красителя C — около 17%. Из данных, представленных на рис. 1, видно, что взаимное паразитное влияние присутствует для всех четырех каналов. Выбор полос пропускания светофильтров каналов регистрации основывается на соображениях охвата такого диапазона спектра полезного сигнала, интенсивность в котором превышает заданный порог и при этом паразитное влияние других каналов минимально. В данном случае эти два требования конфликтуют между собой, поэтому на практике реализовано компромиссное решение. В дальнейшем, после съема изображений с видеокамер прибора и ряда процедур цифровой обработки этих изображений, описанных в работах [3, 5] и других, явление наложения спектральных составляющих сигналов флуоресценции корректируется в программном обеспечении. Программы, реализующие коррекцию данных, искаженных перекрестными помехами, являются обязательной составной частью программ первичного анализа данных, описанных в работах [6–9].
В настоящей работе описывается алгоритм, предназначенный для коррекции данных, искаженных в результате явления наложения спектральных составляющих оптических сигналов, регистрируемых прибором Нанофор СПС, и показывается, что отсутствие такой коррекции приводит к существенным ошибкам в проведении генетического анализа.
ПРЯМАЯ И ОБРАТНАЯ МАТРИЦЫ ПЕРЕКРЕСТНЫХ ПОМЕХ
Явление перекрестных помех заключается в том, что один и тот же кластер нуклеотида флуоресцирует одновременно во всех каналах. В отсутствие перекрестных помех данный кластер флуоресцировал бы только в одном канале, соответствующем красителю, которым мечен нуклеотид, находящийся в данный момент в данном кластере. Говоря иначе, сумма измеренных в каждом канале значений интенсивности флуоресценции в данном кластере строго соответствовала бы значению интенсивности только в одном канале, являющемся в данный момент каналом полезного сигнала. То есть интенсивности сигнала флуоресценции в остальных каналах равны нулю. Математически интенсивность сигнала флуоресценции в случае
отсутствия перекрестных
вить соотношением (1)
помех можно предста-
I i ( x , y ) =
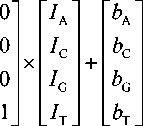
В соотношении (1):
-
- Ii ( x , y ) — сумма измеренных значений интенсивности во всех каналах в пикселе с координатами x и y ;
-
- I A , I C , I G , I T — измеренные чистые значения интенсивности в каждом канале;
-
- b , b , b , b — значения фона в ПЗС-
- ACGT матрице.
В случае наличия перекрестных помех суммарная померенная интенсивность уже не будет соответствовать интенсивности сигнала только в одном канале, при этом соотношение (1) примет вид (2)
|
[ 1 |
w 12 |
w 13 |
w 14 |
[ I A 1 |
Г Ь A 1 |
[ 1 A 1 |
Г b A 1 |
||||||
|
I i ( x , У ) = |
w 21 |
1 |
w 23 |
w 24 |
X |
I C |
+ |
b C |
= M X |
I C |
+ |
b C |
. (2) |
|
w 31 |
w 32 |
1 |
w 34 |
Ic G |
Ь G |
Ic G |
Ь G |
||||||
|
_ w 41 |
w 42 |
w 43 |
1 _ |
1 1 T J |
_ b T _ |
1 1 T J |
_ b T _ |
В соотношении (2): M — матрица перекрестных помех; w ij — коэффициенты матрицы перекрестных помех, называемые также угловыми коэффициентами.
Задачей алгоритма цветокоррекции является сведение к минимуму влияния перекрестных помех. Математическое решение данной задачи можно представить в виде (3), как умножение правой части (2) на матрицу M –1, обратную матрице M .
руются так называемые попарные графики рассеивания интенсивности. На рис. 2 и рис. 3 представлены соответственно пары каналов С–А и каналов T–G. Графики пар каналов G–A, T–A, и других не представлены, т.к. искажения интенсивностей сигналов флуоресценции из-за наложения спектральных составляющих в этих каналах практически отсутствуют.
I , ,co, ( x , У ) = M - 1 X
Ii A I
I i G I
.
В соотношении (3) I i ,corr ( x , y ) — скорректированное суммарное значение интенсивности сигнала кластера с координатами x и y . Для решения данной задачи первоначально необходимо определить значения всех коэффициентов матрицы перекрестных помех.
ПОПАРНЫЕ ГРАФИКИ РАССЕИВАНИЯ ИНТЕНСИВНОСТЕЙ
По данным измеренных значений сигналов флуоресценции во всех четырех каналах, форми-
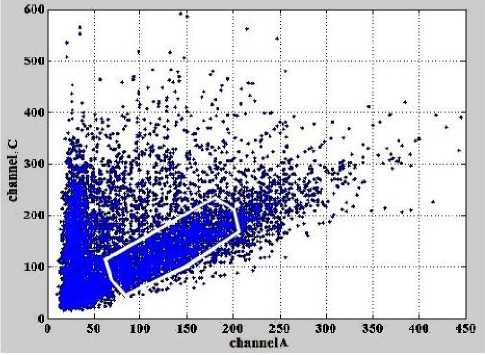
Рис. 2. Зависимость интенсивностей сигналов флуоресценции в канале С от интенсивностей сигналов флуоресценции в канале А.
Белым контуром выделена область данных, которая используется для определения параметров линии регрессии
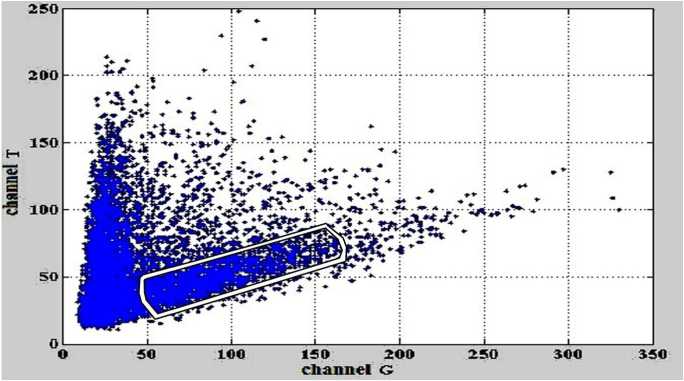
Рис. 3. Зависимость интенсивностей сигналов флуоресценции в канале T от сигналов флуоресценции в канале G.
Белым контуром выделена область данных, которая используется для определения параметров линии регрессии
Каждый из двух графиков формируется следующим образом: по оси абсцисс откладывается значение интенсивности сигнала флуоресценции кластера с координатами x i и y i в одном канале, а по оси ординат откладывается значение интенсивности сигнала флуоресценции в этом же пикселе, но уже в другом канале;
Очевидно, что наибольшее значение интенсивности в кластере с координатами x i и y i будет наблюдаться в канале полезного сигнала. Таким образом, из всего набора данных, отображаемых на попарном графике рассеивания, отчетливо формируются две группы, для каждой из которых полезный сигнал относится только к одному из двух каналов.
АЛГОРИТМ ОЦЕНКИ КОЭФФИЦИЕНТОВ МАТРИЦЫ ПЕРЕКРЕСТНЫХ ПОМЕХ И ПОСЛЕДУЮЩЕЙ ЦВЕТОКОРРЕКЦИИ
-
• Выделение области данных интенсивностей обнаруженных кластеров, которые искажены явлением перекрестных помех, шумом, выбросами и т.п. Данная область используется для определения параметров линии регрессии [6].
-
• Оценка матрицы перекрестных помех путем линейной регрессии данных попарных графиков.
-
• Вычисление обратной матрицы к матрице перекрестных помех.
-
• Применение найденной обратной матрицы к искаженным перекрестными помехами данным попарных графиков рассеивания.
ОСНОВНЫЕ ФУНКЦИИ ПРОГРАММЫ, РЕАЛИЗУЮЩЕЙ АЛГОРИТМ ЦВЕТОКОРРЕКЦИИ
Общая характеристика
Перед реализацией алгоритма цветокоррекции в среде разработки программ необходимо сделать несколько уточнений, касающихся применения этого алгоритма к АПК Нанофор СПС. Входными данными алгоритма цветокоррекции является массив интенсивностей обнаруженных сигналов флуоресценции, полученных в кластерах с координатами, соответствующими координатам шаблона [3]. Для построения шаблона используется алгоритм, основанный на свертке со второй производной двумерного гауссового пика. В результате применения алгоритма свертки из обнаруженных сигналов флуоресценции практически удаляется фон [5]. В ходе описания алгоритма коррекции прежде всего будет рассмотрено взаимовлияние каналов А и С. Затем будет рассмотрено взаимовлияние каналов G и Т. В связи с этим окончательные входные данные представлены в виде двухстрочного массива экспериментально полученных значений интенсивностей в каналах А и С. При этом общую задачу цветокоррекции можно привести из вида (3) в вид (4):
Ii ,corrAC ( x , y ) = M AC x
I ,
M AC =
w 21
w 12
Очевидным становится факт, что выходными данными алгоритма является двухстрочный массив откорректированных входных данных. Общая концепция алгоритма заключается в следующем.
-
• Создание подпрограммы, выделяющей области данных интенсивностей обнаруженных кластеров, которые искажены явлением перекрестных помех и устраняющей влияние шумов и базовой линии — " BuildPrc ".
-
• Создание подпрограммы для оценки угла наклона полинома линейной регрессии входных данных — " SlopeEstimateN ".
-
• Реализация полного алгоритма (совместной работы " SlopeEstimateN " и " BuildPrc ").
-
• Нахождение корректирующей матрицы M и ее преобразование в обратную матрицу M –1.
-
• Итоговое тестирование алгоритма с использованием референтного генома бактериофага Phix 174.
Подпрограмма " BuildPrc "
Основное назначение данной подпрограммы — формирование вектора данных, которые могут быть использованы для вычисления углового коэффициента наклона линии регрессии.
Этот вектор формируется из вектора входных данных, искаженных перекрестными помехами, шумом и другими мешающими полезной информации факторами. Согласно данным работы [6], кластеры (пиксели), значение интенсивности которых ниже 60-го и выше 90-го процентилей, не могут быть использованы для корректной оценки углового коэффициента. Поэтому, чтобы оценить чистое влияние перекрестных помех без постороннего шума, кластеры с подходящими под критерий шума и других мешающих факторов значениями интенсивности должны быть удалены из вектора входных данных. Это и реализует подпрограмма " BuildPrc ". После удаления "плохих" кластеров участок значений интенсивности в канале полезного сигнала разбивается на несколько равных интервалов (бинов). В каждом интервале (бине) берется среднее значение интенсивности по оси канала полезного сигнала и минимальное по оси канала паразитного сигнала [6]. Это и есть значения интенсивностей в векторе, который далее подвергается обработке подпрограммой " SlopeEstimateN " .
На рис. 2 и рис. 3 белым контуром выделены данные, которые используются для определения параметров линии регрессии.
На рис. 4 представлена линия регрессии (пунктирная линия), построенная после процедуры оценки процентилей, разбиения на интервалы (би- ны) и нахождения минимумов в этих интервалах с помощью подпрограммы "BuildPrc" для данных, представленных на рис. 2. Линия регрессии была построена по 100 точкам, количество которых соответствовало количеству интервалов (бинов).
Угловой коэффициент — тангенс угла наклона линии регрессии, представленной на рис. 4, равен 0.6032, и, соответственно, угол наклона α равен 0.5428 рад. Далее в подпрограмме " Slope-EstimateN " с помощью матрицы поворота MrRt (6) производится поворот вектора данных, полученных в подпрограмме " BuildPrc ", на угол наклона α по часовой стрелке:
MrRt =
cos( α )
- sin( a )
sin( α ) cos( α )
Результат поворота представлен на рис. 5.
Подпрограмма " SlopeEstimateN "
Данная подпрограмма является по сути ядром алгоритма. Ее основное назначение — поиск углового коэффициента вектора входных данных, к которому применяется линейная регрессия (7):
N
2 ( У - ax - b )2 ^ min a , b . (7)
i = 1
Поиск углового коэффициента представляет собой итерационную процедуру приближения угла наклона линии регрессии к нулевому значению. В каждой итерации вычисляется матрица поворота на угол α — MrRt (6), которая обновляется в каждой итерации; α — угол между линией регрессии и горизонтальной осью.
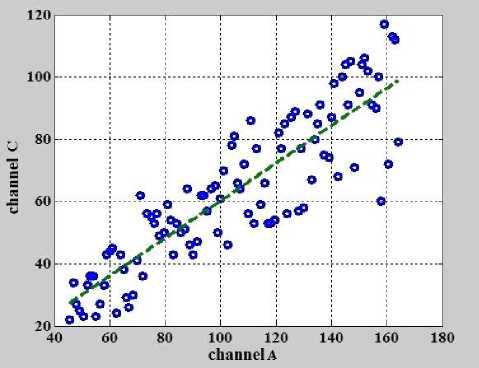
Рис. 4. Линия регрессии (пунктирная линия), построенная после выделения данных с помощью подпрограммы " BuildPrc " для данных, представленных на рис. 2.
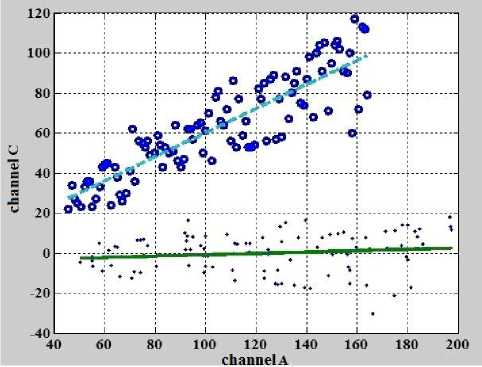
Рис. 5. Данные (o) и линия регрессии (пунктирная линия), показанные на рис. 4, и данные (точки), линия регрессии (сплошная линия), полученные после поворота на угол α.
Поворот на угол α является первым шагом итерационного процесса, который выполняет подпрограмма " SlopeEstimateN ". Следующим шагом этого итерационного процесса является оценка угла наклона α 1 полученной линии регрессии. Например, для линии регрессии, показанной внизу рис. 5 (сплошная линия) угловой коэффициент — тангенс угла наклона равен 0.0342 и, соответственно, угол наклона α 1 равен 0.0342 рад. Затем углы α и α 1 складываются и осуществляется поворот на суммарный угол, значение которого присваивается переменной α . Далее подпрограмма " SlopeEstimateN " продолжает итерационную процедуру, осуществляя повороты, вычисления тангенсов углов наклона, значений самих углов и суммы значения угла, полученного на очередном шаге итерации, со значением угла, полученного на предыдущем шаге с учетом знака. Итерационная процедура заканчивается после того, как абсолютное значение тангенса угла наклона не станет меньше заданного порогового значения ( th ) . Другим параметром окончания итерационного процесса является количество выполненных итераций N . Для рассматриваемого примера th = 5 · 10–5, а N = 8.
Полученный после итерационной процедуры тангенс угла наклона является элементом w 21 искомой матрицы M AC .
Для нахождения элемента w 12 искомой матрицы M AC (5), т.е. для оценки перекрестных помех из канала С в канал А должна строиться еще одна регрессия, для которой также используются рассмотренные подпрограммы " BuildPrc " и " Slope-EstimateN ". В качестве входных данных используется зависимость интенсивностей в канале А от интенсивностей в канале С, а не зависимость интенсивностей в канале С от интенсивностей в канале А, как представлено на рис. 2. То есть то, что было функцией, стало аргументом, а то, что было аргументом, стало функцией. Зависимость интенсивностей в канале А от интенсивностей в канале С представлена на рис. 6. Белым контуром показана область данных, которая используется для оценки параметров линии регрессии.
С помощью подпрограмм " BuildPrc " и " Slope-EstimateN " был найден угловой коэффициент линии регрессии для данных, выделенных белым цветом на рис. 6, значение которого является значением коэффициента w 12 . Для рассматриваемого примера w 12 = 0.0421.
Таким образом, теперь по известным элементам матрицы M AC можно найти обратную матрицу M - A 1 C и рассчитать откорректированные значения интенсивностей в каналах А и С по формуле (4).
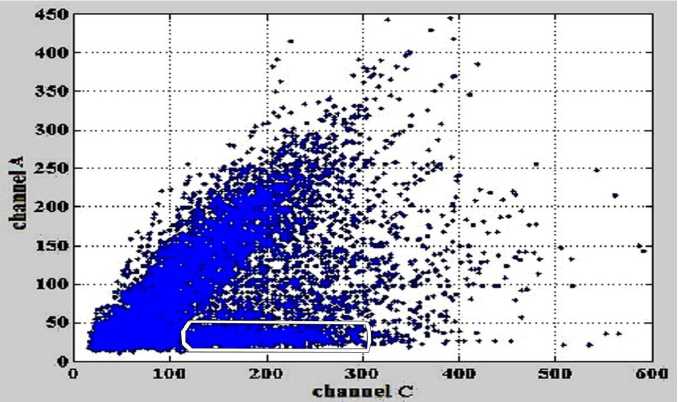
Рис. 6. Зависимость интенсивностей сигналов флуоресценции в канале А от интенсивностей сигналов флуоресценции в канале С.
Белым контуром выделена область данных, которая используется для определения параметров линии регрессии
ОТОБРАЖЕНИЕ РЕЗУЛЬТАТОВ
ЦВЕТОКОРРЕКЦИИ ДЛЯ КАНАЛОВ А–С И G–T
Откорректированные данные для каналов А и С представлены на рис. 7.
Мы рассмотрели коррекцию влияния перекрестных помех на интенсивности сигналов флуоресценции в каналах А и С.
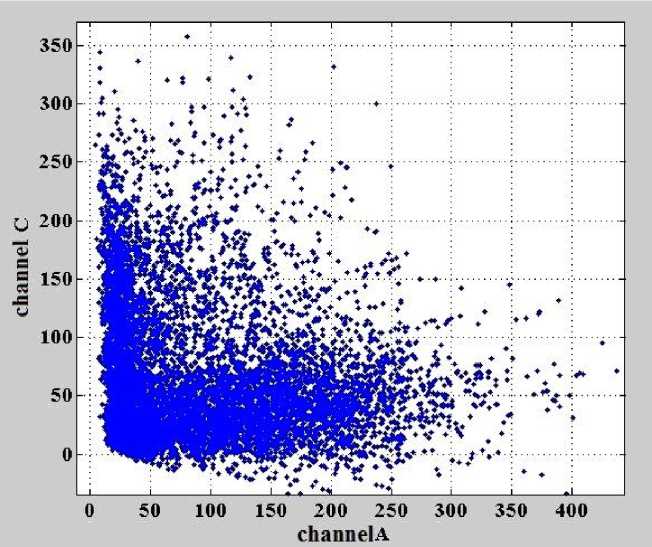
Рис. 7. Зависимость интенсивностей сигналов флуоресценции в канале С от интенсивностей сигналов флуоресценции в канале А после коррекции влияния перекрестных помех.
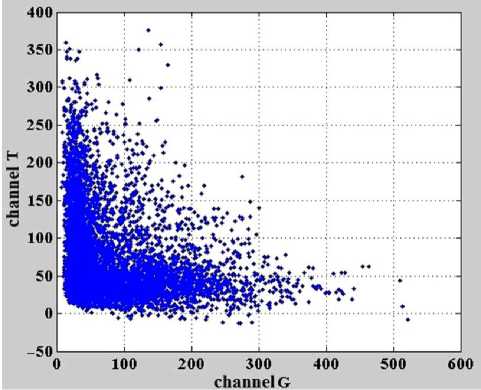
Рис. 8. Зависимость интенсивностей сигналов флуоресценции в канале T от интенсивностей сигналов флуоресценции в канале G после коррекции влияния перекрестных помех.
Коррекция влияния перекрестных помех на интенсивности сигналов флуоресценции в каналах G и T производится аналогично с помощью рассмотренных выше подпрограмм " BuildPrc " и " Slope-EstimateN " . Откорректированные данные для каналов G и T представлены на рис. 8.
Мы рассмотрели процедуру коррекции влияния перекрестных помех на значения интенсивностей сигналов флуоресценции в каналах A–C и G–Т для результатов измерений в одном цикле. Аналогично производятся коррекции влияния перекрестных помех последовательно во всех циклах эксперимента.
По откорректированным значениям интенсивностей сигналов флуоресценции с помощью процедуры " BaseCalling " и программного обеспечения сборки генома строится последовательность букв нуклеотидов для исследуемой пробы.
Сравним результаты сборки генома для исходных и откорректированных на влияние перекрестных помех измеренных интенсивностей сигналов флуоресценции.
СРАВНЕНИЕ РЕЗУЛЬТАТОВ СБОРКИ ГЕНОМА ДЛЯ ОТКОРРЕКТИРОВАННЫХ И НЕОТКОРРЕКТИРОВАННЫХ ДАННЫХ
Сборка генома и оценка ее характеристик для исходных и откорректированных на влияние перекрестных помех измеренных интенсивностей сигналов флуоресценции проводилась с помощью программ " Ugene " и " Qualimap ". С помощью этих программ был определен процентный состав содержания нуклеотидов A, C, G и T в пробе, содержащей геном бактериофага Phix174. Этот геном содержит 5386 нуклеотидов с известным процентным содержанием каждого из нуклеотидов. Этот геном является стандартом для проверки получаемой в секвенаторах генетической последовательности. Содержание отдельных нуклеотидов в этом геноме следующее: A — 24.0%, C — 21.5%, G — 23.3%, T — 31.2%. [10]. В результате эксперимента оценки процентного содержания нуклеотидов по интенсивности сигналов флуоресценции, для которых была выполнена корректировка влияния перекрестных помех по рассмотренному выше алгоритму, процентное содержание нуклеотидов получилось следующее: A — 23.5%, C — 21.5%, G — 23.6%, T — 31.4%, что соответствует стандартному геному Phix 174.
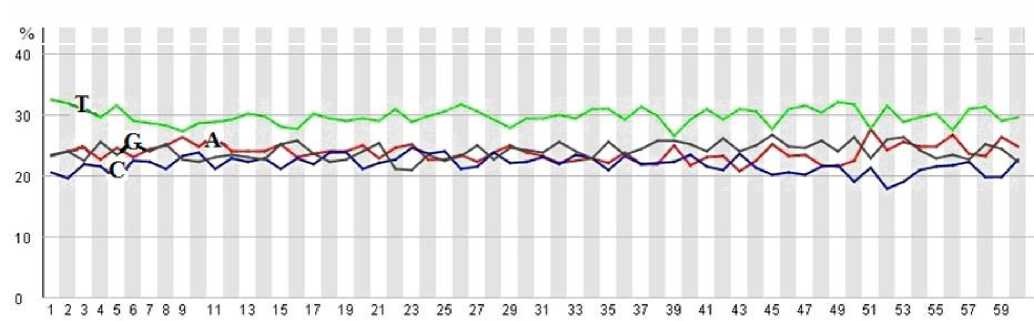
Номер цикла
Рис. 9. Процентное содержание нуклеотидов A, C, G, и T в зависимости от номера цикла измерений в секвенаторе при применении алгоритма коррекции наложения спектральных полос.
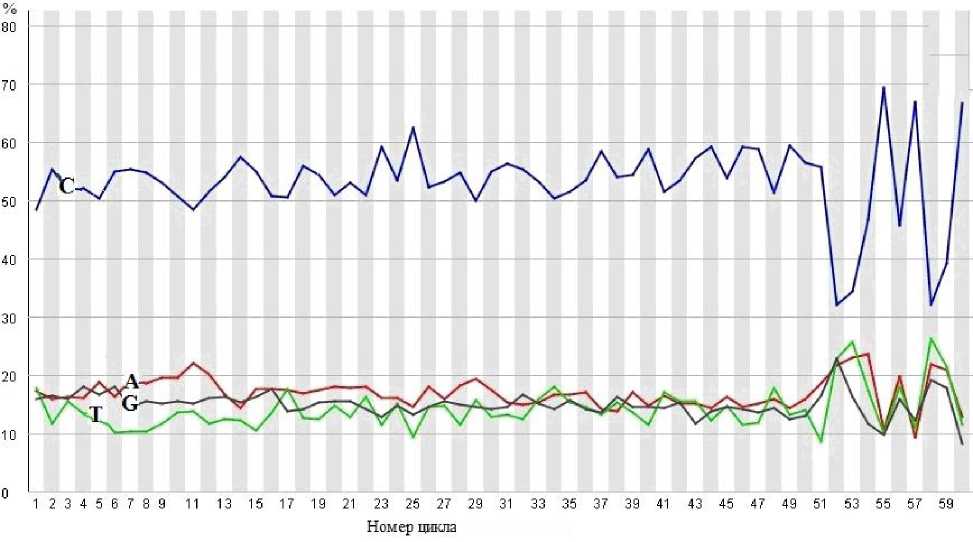
Рис. 10. Процентное содержание нуклеотидов A, C, G, и T в зависимости от номера цикла измерений в секвенаторе без применения алгоритма коррекции наложения спектральных полос
На рис. 9 представлен результат процентного содержания отдельных нуклеотидов для исходных данных интенсивностей сигналов флуоресценции, которые подвергались корректировке на влияние перекрестных помех. На рис. 9 показано процентное содержание нуклеотидов A, C, G и T в зависимости от номера цикла измерений в секвенаторе.
Как видно из данных, представленных на рисунке, процентное суммарное содержание нуклеотидов G и C практически во всех циклах приблизительно составляет 44%, что соответствует содержанию этих нуклеотидов в стандарте Phix174.
На рис. 10 представлен результат определения процентного содержания отдельных нуклеотидов для данных интенсивностей сигналов флуоресценции, для которых не была проведена корректировка на влияние перекрестных помех по рассмотренному выше алгоритму.
Как видно из данных, представленных на рисунке, процентное суммарное содержание нуклеотидов G и C практически во всех циклах превышает 65%. Этот факт свидетельствует о том, что интенсивности сигналов флуоресценции в канале C были искажены интенсивностями сигналов флуоресценции в канале А.
Сравнение результатов, представленных на рис. 9 и 10, показывает эффективность применения рассмотренного алгоритма.
Следует отметить, что использование коррекции перекрестных помех облегчает нам формирование обучающей выборки при применении машинного обучения в программном обеспечении секвенатора Нанофор СПС [4, 11]. В этом случае параметры моделей становятся менее коррелированными. С другой стороны, мы можем возложить саму коррекцию на методы машинного обучения.
ВЫВОДЫ
-
1. Явление перекрестных помех при измерениях сигналов флуоресценции приводит к ошибочным оценкам величин интенсивностей сигналов в соседних каналах секвенатора, искажающих последующую идентификацию буквенного кода нуклеотида.
-
2. Для коррекции ошибочных величин интенсивностей флуоресцентных сигналов необходимо определить матрицу перекрестных помех. На основе этой матрицы определяется обратная матрица, использование которой позволяет существенно снизить влияние наложения спектральных полос на точность оценки измерений сигналов флуоресценции.
-
3. Алгоритм нахождения элементов матрицы перекрестных помех включает следующие операции:
-
а) с помощью оценки 60 и 90 процентилей определяется диапазон величин интенсивностей
сигналов флуоресценции в канале, которые искажают величины интенсивностей в соседнем канале из-за явления наложения спектральных полос;
-
б) полученный диапазон величин интенсивностей сигналов разбивается на ряд равных интервалов;
-
в) в каждом интервале находится минимальная интенсивность;
-
г) полученные значения минимумов в каждом интервале используются для построения линии регрессии в итерационной процедуре;
-
д) находится угловой коэффициент, который является элементом матрицы перекрестных помех.
-
4. Явление перекрестных помех в секвенаторе Нанофор СПС искажает величины интенсивности только в двух парах каналов: A–C и G–T. В других парах каналах, таких как A–G, A–T, C–G, C–T и т.п., искажения величин интенсивностей из-за явления перекрестных помех практически отсутствует. Это обстоятельство позволяет для коррекции влияния явления перекрестных помех упростить матрицу перекрестных помех и использовать две матрицы размером 2 × 2. Одну матрицу для коррекции искажений в каналах А–С, а другую для каналов G–T.
-
5. Результат генетического анализа стандарта Phix174 при использовании интенсивностей сигналов флуоресценции, не скорректированных на влияние перекрестных помех, показал, что процентное содержание нуклеотидов C и G существенно искажено, тогда как для скорректированных интенсивностей процентное содержание нуклеотидов C и G соответствует стандарту.
-
6. Методы коррекции флуоресцентных сигналов, искаженных эффектами фазирования / префазирования (phasing/prephasing), в настоящей работе не были рассмотрены, хотя эти методы также основаны на оценке параметров данных с помощью линейной регрессии. Предполагается рассмотрение этих методов в следующей работе.
Работа выполнена в ИАП РАН в рамках Государственного задания 075-01157-23-00 Министерства науки и высшего образования.
