LLMs Performance on Vietnamese High School Biology Examination

Author: Xuan-Quy Dao, Ngoc-Bich Le
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 6 vol.15, 2023.
Free access
Large Language Models (LLMs) have received significant attention due to their potential to transform the field of education and assessment through the provision of automated responses to a diverse range of inquiries. The objective of this research is to examine the efficacy of three LLMs - ChatGPT, BingChat, and Bard - in relation to their performance on the Vietnamese High School Biology Examination dataset. This dataset consists of a wide range of biology questions that vary in difficulty and context. By conducting a thorough analysis, we are able to reveal the merits and drawbacks of each LLM, thereby providing valuable insights for their successful incorporation into educational platforms. This study examines the proficiency of LLMs in various levels of questioning, namely Knowledge, Comprehension, Application, and High Application. The findings of the study reveal complex and subtle patterns in performance. The versatility of ChatGPT is evident as it showcases potential across multiple levels. Nevertheless, it encounters difficulties in maintaining consistency and effectively addressing complex application queries. BingChat and Bard demonstrate strong performance in tasks related to factual recall, comprehension, and interpretation, indicating their effectiveness in facilitating fundamental learning. Additional investigation encompasses educational environments. The analysis indicates that the utilization of BingChat and Bard has the potential to augment factual and comprehension learning experiences. However, it is crucial to acknowledge the indispensable significance of human expertise in tackling complex application inquiries. The research conducted emphasizes the importance of adopting a well-rounded approach to the integration of LLMs, taking into account their capabilities while also recognizing their limitations. The refinement of LLM capabilities and the resolution of challenges in addressing advanced application scenarios can be achieved through collaboration among educators, developers, and AI researchers.
ChatGPT, Microsoft Bing Chat, Google Bard, large language models, biology education
Short address: https://sciup.org/15019141
IDR: 15019141 | DOI: 10.5815/ijmecs.2023.06.02
Text of the scientific article LLMs Performance on Vietnamese High School Biology Examination
Several studies have investigated the use of artificial intelligence (AI) in education. Chen et al. [1] focused on the application of AI to help teachers manage administrative activities more effectively and adapt lesson plans to the unique demands of each student, resulting in encouraging improvements in education’s overall quality. Dao et al. [2] integrated text-to-speech and speech-driven-face technology to automatically create video lectures using the instructor’s voice and facial expressions, lowering workload and boosting learner engagement in online learning settings. Nguyen et al. [3] proposed an online learning platform that included a Vietnamese virtual assistant to help instructors with lesson delivery and student assessment, combining presentation slides with the instructor’s face, a synthesized voice, and simple editing tools without the need for video capture.
Large Language Models (LLMs), a type of AI system, are trained on massive amounts of text data to understand natural language and generate human-like responses. These models have become a potent tool for building chatbots with applications in a variety of fields, including education. LLMs have the potential to revolutionize the way we interact with technology and access information. The potential of LLMs in jobs like content creation, language translation, and instructional support is enormous. Notable developments in LLMs include the release of BERT [4] by Google in 2018, its extension RoBERTa [5] by Facebook in 2019, and T5 [6] by Google researchers in 2019. The 2020 release of OpenAI’s GPT-3 [7] received recognition for its outstanding results in a variety of NLP tasks, even with a small amount of training data.
The potential for LLMs to revolutionize biology education is a topic of interest. However, a comprehensive understanding of their competence and limitations across different question types and difficulty levels poses a significant challenge. Given that biology education involves the acquisition of factual knowledge, understanding of context, and the ability to apply critical thinking, it is crucial to assess the proficiency of LLMs in addressing these complexities. Given the aforementioned difficulties, the objective of this study is to conduct a thorough evaluation of ChatGPT1, Microsoft's Bing Chat2 (BingChat), and Google Bard3 using the VNHSGE biology dataset [8]. Our objective is to provide insights that facilitate the effective integration of different models into educational platforms and assessment designs by highlighting their strengths and limitations. The primary objective is to make a valuable contribution toward the advancement of customized LLM programs that are specifically designed to address the complexities of biology education. This will ultimately result in the promotion of a more enhanced and enriched learning experience for students.
The topic of this article focuses on assessing LLMs' ability in relation to biology tests. The study provides various contributions: (1) a thorough analysis of three cutting-edge LLMs, ChatGPT, BingChat, and Bard in the context of high school biology education in Vietnam; (2) a comparison of the performance of ChatGPT BingChat, and Bard with Vietnamese students; and (3) a thorough investigation of the advantages and drawbacks of using LLMs in the field of biology education in Vietnam. Through these contributions, this research highlights the issues that must be resolved for proper integration while illuminating the potential of LLMs to improve biology education.
2. Related Work 2.1. Large Language Models
ChatGPT, a language model created by OpenAI and based on the GPT-3.5 architecture, has the ability to provide human-like responses in natural language. It has the potential to be used in intelligent tutoring programs that enable assessment activities, offer tailored feedback, and automate grading procedures. BingChat, based on the GPT-4 architecture4, acts as a chatbot function within the Bing search engine and has a lot of potential as a teaching tool because it can deliver factual information. Google Bard is an experimental, conversational AI chat service developed by Google that was initially powered by Google’s Language Model for Dialogue Applications (LaMDA) 5 and later upgraded to use Google’s most advanced LLM, PaLM. These AI-powered solutions have the potential to revolutionize education by providing trustworthy and accessible educational support to both teachers and students.
2.2. Biology datasets for evaluation of LLMs
2.3. Evaluation of LLMs on biology
3. Methods3.1 Dataset
3.2 Prompt
Due to their thorough training with enormous volumes of data, LLMs have outstanding natural language comprehension abilities. They are therefore excellent candidates for upholding academic and professional standards, especially in the area of biology education. For LLMs working in the field of biology, existing datasets like BioASQ [9] and SciQ [10] provide challenges. When it addresses tasks like question-answering and biomedical semantic indexing, BioASQ generally concentrates on the medical sector as opposed to the biological one. The SciQ dataset, on the other hand, utilizes multiple-choice questions to assess LLMs' understanding of and rationale for biological science principles. The dataset presents a considerable challenge for LLMs because it contains 13,679 science exam questions from disciplines including biology, chemistry, and physics as well as supporting data for the correct responses. The biology dataset offered in MMLU dataset [11] also includes material from high school and college biology courses, covering a variety of topics like natural selection, heredity, the cell cycle, the Krebs cycle, cellular structure, molecular biology, and ecology. This dataset is used to evaluate the precision of LLMs in certain particular biological domains. A multimodal technique has been introduced in ScienceQA dataset [12], with a focus on molecular and cellular biology. With matching lectures, explanations, and photos captioned, it has approximately 21,000 multiple-choice queries. In comparison to earlier datasets, this dataset offers a wide variety of research topics and annotations, which helps to create a broader domain diversity. Despite LLMs' promise to revolutionize education, they still need to do better in certain areas, like biology. On the AP Biology dataset, ChatGPT-3.5 achieves an accuracy range of 62% to 85%, according to the GPT-4 Report by OpenAI [13]. This shows that although LLMs like ChatGPT have a promising future in education, more work needs to be done to improve their accuracy and performance in biologically-related activities. VNHSGE biology dataset [8] encompasses information derived from the Vietnamese National High School Graduation Examination. This comprehensive dataset encompasses a wide array of biological topics, including genetic principles, population genetics, genetic applications, human genetics, evolution, ecology, plant organismal biology, and numerous other facets of the field. It is essential to note that this dataset poses a formidable challenge to large language models due to the intricate nature of inference tasks and the complexity of the Vietnamese language.
The study conducted by Agathokleous et al. [14] examines the effects and investigates the practical uses and consequences of AI LLMs in the fields of biology and environmental science. The article examines the potential advantages of LLMs in diverse domains, including education, research, publishing, outreach, and societal translation. The paper extends its analysis by presenting illustrative instances via interactive sessions with LLM, thereby showcasing its capacity to streamline intricate undertakings. In a separate scholarly investigation, Tong et al. [15] examine the ramifications of ChatGPT within the domain of Synthetic Biology. This study investigates the potential of utilizing ChatGPT for the purpose of comprehending research patterns and enhancing research endeavors within this particular field. The paper acknowledges the dual nature of the sentiments surrounding the impact of LLMs on society and research, encompassing both enthusiasm and apprehension. In an alternative perspective, Kumar et al. [16] analyze the usefulness and advantages of ChatGPT in the realm of academic writing within the field of biomedical sciences. The evaluation encompasses the measurement of various aspects, including the speed of response, the caliber of content, the dependability, and the level of novelty exhibited in the text generated by ChatGPT. The research acknowledges the various strengths and limitations associated with the use of ChatGPT in the context of academic writing. Finally, Shue et al. [17] propose an iterative model that aims to refine instructions for guiding a chatbot, specifically ChatGPT, in the generation of code for bioinformatics data analysis tasks. This study evaluates the viability of implementing this model in various bioinformatics domains and examines the practical considerations and constraints associated with utilizing such a model for chatbot-supported bioinformatics instruction. The papers under review collectively highlight the significant influence of LLMs on different fields such as biology, environmental science, synthetic biology, academic writing in biomedical sciences, and bioinformatics. The authors emphasize the possible advantages and difficulties linked to the incorporation of LLMs within these domains. Through the execution of our research, our objective is to make a scholarly contribution to the ongoing discussion pertaining to the responsible and efficient incorporation of LLMs, namely ChatGPT, Bing Chat, and Bard, within the realms of biology education.
Fig.1 illustrates the evaluation process of LLMs on the VNHSGE biology dataset. Firstly, the Vietnamese National High School Graduation Examination biology test is converted into a text format so that LLMs can understand it, with mathematical formulas and symbols being converted into LaTeX format. Next, the questions in text format are sent to the LLMs API via the zero-shot method. Finally, the LLMs’ responses are scored, analyzed, and evaluated.
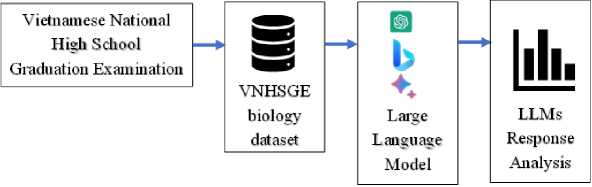
Fig. 1. Evaluation of LLMs on VNHSGE biology dataset
The biology questions in the VNHSGE dataset [8] are exceedingly challenging and intricate, necessitating a thorough understanding of biology in order to provide adequate answers. The VNHSGE dataset tests students' biology knowledge and abilities with a variety of questions of varying complexity. The dataset's questions are categorized as "knowledge" (easy), "comprehension" (intermediate), "application" (difficult), and "high application" (very difficult). The dataset is intended to be made up of 75% theoretical questions and 25% exercises, with a focus on higher-order thinking abilities and applications making up 30% of the questions and knowledge and comprehension levels being assessed by the remaining 70%. The dataset includes a range of questions, with an emphasis on the capacity for calculation and inference. While comprehension-level questions only call for one to three steps of deductive reasoning, knowledge-level questions necessitate a thorough understanding of biology. Application-level questions concentrate on issues including genetic principles, population genetics, inheritance mechanisms, and mutation, requiring the synthesis of knowledge. High application-level questions provide another level of complexity because they require on extensive analysis and problem-solving abilities. Due to the complex nature of the VNHSGE biology dataset, LLMs encounter substantial challenges in comprehending and answering questions that cover a range of biology topics correctly.
In this investigation, zero-shot evaluation was employed to gauge the effectiveness of LLMs in the evaluation of the VNHSGE dataset denoted as D . This dataset comprises a collection of question-answer pairs, designated as Q and S , respectively, where S represents the ground truth solutions. The contextual information represented by the term P is defined. LLMs’ answer A is computed according to the formula presented below:
A = f(P,Q) (1)
Here, the function f is embodied by LLMs and takes into consideration both the context P and the question Q . The context P , in this instance, is a specific structure that guides the response of LLMs. It instructs LLMs to generate the answer in the following format: (Choice: "A" or "B" or "C" or "D"; Explanation: Explain the answer; The question is: [the actual question]). By adhering to this format, LLMs generates its response A , which can subsequently be assessed and compared against the ground truth solution S . In the case of multiple-choice questions sourced from the VNHSGE dataset, the questions are adapted to align with the expected answer format and are then sent to the LLMs' API.
3.3 Grading
4. Experimental Results and Discussion
4.1 Performance evaluation
To assess the performance of LLMs in responding to questions, we conducted an evaluation by comparing LLMs' responses to the ground truth solution. The evaluation process was executed through a binary grading system, whereby the response provided by LLMs was categorized as either correct or incorrect. The ground truth solution S for each question Q was determined by a human expert. The response A generated by LLMs was subsequently compared to the ground truth solution using the subsequent equation:
G = g(Q,S,A) (2)
Fig.2a illustrates LLMs performance on VNHSGE biology dataset while Fig.2b shows their consistent responses. It is observed that Bard distinguishes itself with a mean performance score of 69.5% on the VNHSGE dataset, suggesting a tendency to produce a greater number of accurate responses to biology questions compared to other models. This observation implies that Bard possesses a comprehensive understanding of concepts related to biology and is capable of delivering precise and reliable responses within this field. Meanwhile, the performance of BingChat is notable, as it exhibits a robust accuracy rate of 69.0%. It is worth mentioning that BingChat consistently demonstrates a commendable performance in addressing inquiries related to biology, as evidenced by its relatively limited range of performance, spanning from 65.0% to 72.5%. The attribute of consistency is highly advantageous for an educational tool. Another finding is that the performance of ChatGPT, despite exhibiting the lowest mean performance of 58%, managed to attain a commendable degree of accuracy. It is noteworthy to mention that ChatGPT exhibited a marginally superior level of consistency in comparison to BingChat. This implies that ChatGPT could potentially serve as a dependable choice for educational applications, despite exhibiting a comparatively lower average accuracy. Furthermore, one intriguing observation pertains to the notable variability observed in Bard's responses, which span a range from 60.0% to 77.5%. Although Bard attained the highest average accuracy, the presence of variability suggests that its responses may occasionally lack consistency. The observed variability in LLM responses could potentially be an aspect that warrants further attention, especially in relation to the dependability of these responses within educational contexts.
In general, the findings of this study suggest that the three LLMs, namely Bard, BingChat, and ChatGPT, exhibit promise for educational utilization within the domain of high school biology. Bard and BingChat exhibit commendable performance with elevated mean accuracies, whereas ChatGPT, while marginally less accurate on average, showcases commendable consistency. Nevertheless, it is imperative to take into account the balance between precision and uniformity when choosing an LLM for educational objectives, as both aspects play a role in the dependability of these models in supporting students and instructors in the field of biology education. Additional refinement and optimization efforts have the potential to improve the performance and reliability of these LLMs in the context of educational applications.
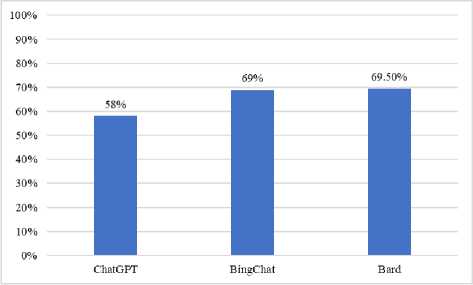
a. Performance
Fig. 2. Performance of LLMs on VNHSGE biology dataset
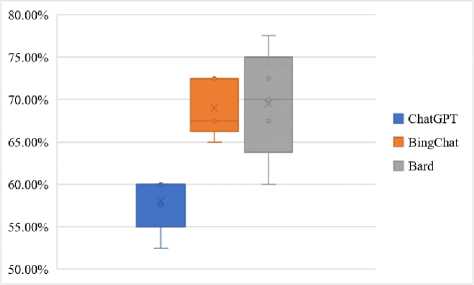
b. Stability of LLMs response
-
4.2 LLMs capabilities in different question levels
An essential component of this study involved examining the efficacy of various LLMs in addressing challenginglevel inquiries. The objective of the analysis was to evaluate the efficacy of ChatGPT, BingChat, and Bard in addressing various categories of challenging inquiries. The findings of the analysis are succinctly presented in Fig.3b, which illustrates the proportion of accurate responses across different categories of challenging questions for ChatGPT, BingChat, and Bard. The taxonomy of inquiries encompasses Knowledge-based inquiries, Comprehension-based inquiries, Application-based inquiries, and High Application-based inquiries (refer to Fig.3a). The following are the principal discoveries:
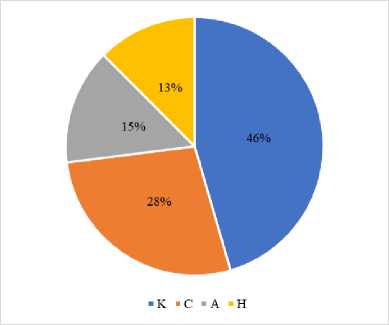
a)
Fig. 3. a) Question levels proportion, and b) Performance of LLMs on question levels
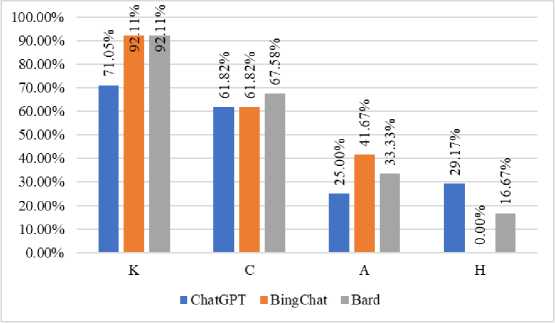
b)
First, knowledge questions are commonly associated with the retrieval of factual information. Both BingChat and Bard exhibited a significantly higher level of accuracy (92.11%) in responding to these inquiries when compared to ChatGPT (71%). The reason behind this is that BingChat and Bard use extensive training data and painstaking finetuning to provide accurate and reliable information. The models may have been exposed to a variety of real facts, improving their capacity to retrieve reliable information. Students seeking succinct explanations and definitions can use BingChat and Bard to quickly and accurately answer knowledge-based questions. However, these sources may not always provide complete explanations or contextual information, limiting their use in complex dialogue.
Second, comprehension questions pertain to the process of comprehending and interpreting provided information. All three models demonstrated comparable levels of accuracy in answering these questions. ChatGPT and Bard achieved an accuracy rate of approximately 61.82%, while BingChat slightly outperformed them in this regard. The similar efficacy of all three models in facilitating students' comprehension and interpretation of biology-related information indicates their overall capacity to grasp and elucidate concepts. This suggests that students have the option to refer to any of these models as a resource for understanding the content of a biology text, diagram, or concept. Educators have the opportunity to integrate these models into their instructional materials, thereby offering students supplementary explanations and alternative viewpoints, thereby augmenting their comprehension and fostering their critical thinking abilities.
Third, the application questions, which necessitate the utilization of acquired knowledge in specific scenarios, were found to be more difficult. Among the evaluated systems, BingChat demonstrated the most notable accuracy within this specific category, achieving a percentage of 41.67%. Subsequently, Bard attained a lower accuracy rate of 33.33%, while ChatGPT exhibited the lowest accuracy of 25.0%. This implies that although BingChat and Bard exhibit a greater capacity for the application of knowledge in practical situations, all models encounter challenges in this regard.
Finally, high-application questions necessitate the utilization of advanced analytical skills and the capacity to integrate knowledge in intricate situations. In this category, Bard demonstrated the highest level of accuracy, achieving a rate of 16.67%. Following closely behind was ChatGPT with a rate of 29.1%. Conversely, BingChat did not produce any correct responses within this category. This underscores the notable difficulties that the models encounter when confronted with inquiries that necessitate advanced cognitive abilities and the synthesis of ideas. It is understandable that AI models face inherent difficulties when confronted with high-application questions that necessitate intricate reasoning and the synthesis of ideas. The comparatively lower rates of accuracy observed within this particular category suggest that the models under consideration face challenges when confronted with tasks that necessitate higher-order cognitive skills, such as critical analysis, hypothesis formulation and testing, and the integration of knowledge from multiple disciplines. In order to enhance performance in this area, it is recommended that future advancements prioritize the augmentation of the models' reasoning capabilities, comprehension of context, and capacity to establish coherent connections between disparate pieces of information.
In summary, it is imperative to comprehend the merits and limitations of BingChat, Bard, and ChatGPT in relation to their ability to effectively address various categories of biology inquiries, as this knowledge is essential for their optimal utilization within educational environments. BingChat and Bard demonstrate proficiency in delivering accurate information and facilitating practical implementation. Conversely, ChatGPT distinguishes itself through its adaptability and reliability. Nevertheless, it is important to acknowledge that all models encounter difficulties when presented with challenging inquiries, underscoring the imperative for continuous advancements in artificial intelligence and the comprehension of natural language in order to effectively address the requirements of intricate educational assignments.
-
4.3 Comparision to other exam
-
4.4 Comparision to Vietnamese students
The evaluation of ChatGPT, BingChat, and Bard on the VNHSGE dataset not only yields valuable insights into their respective capabilities within the VNHSGE context but also presents an opportunity to compare their performance with ChatGPT's performance on the AP biology dataset provided by OpenAI [17]. Fig.4 presents a comprehensive comparison of the outcomes obtained by the models on the VNHSGE dataset, along with the performance of ChatGPT on the AP biology dataset. The score range previously determined by OpenAI for GPT-3.5/GPT-4 on the AP biology dataset is situated within the interval of 62% to 85%.
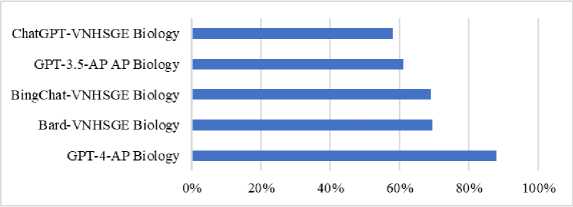
Fig. 4. Performance of LLMs on VNHSGE dataset and other exams.
A comparison between the LLMs' scores and those of Vietnamese students was conducted in order to evaluate how well the LLMs performed in the setting of high school biology education in Vietnam. Fig.5 analyzes and displays the converted scores from ChatGPT, BingChat, and Bard together with the average score (AVS) and the most attained score (MVS). The findings show that ChatGPT performed better than both AVS and MVS overall. This demonstrates that ChatGPT performs better than the typical scores obtained by Vietnamese students. But it is remarkable that across all the years considered, BingChat and Bard continuously surpassed AVS and MVS. This demonstrates the potential application of LLMs, particularly BingChat and Bard, in Vietnam's high school biology education. The results highlight the positive potential for incorporating cutting-edge language models into the educational system. Teachers can improve their students' learning experiences by utilizing the features of BingChat and Bard, giving them access to a variety of information and tools. These LLMs could help students develop their critical thinking, problem-solving, and comprehension abilities in the area of biology.
a. LLMs and Vietnamese students (the average score (AVS) and the most attained score (MVS))
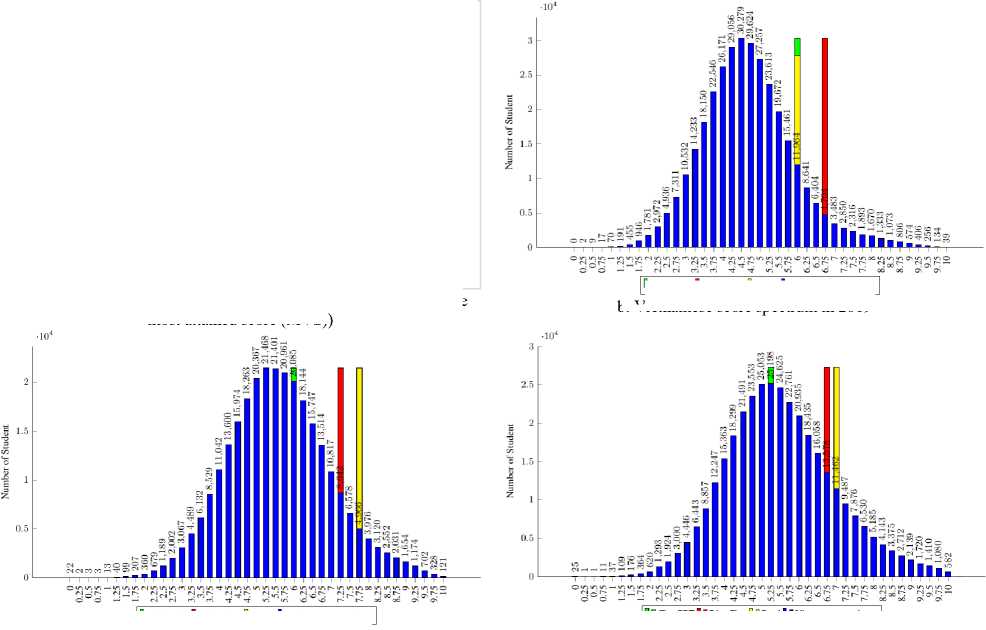
| D □ ChatGPT 11 BingChat [] □ Bard 11 Vietnamese students
Il ChatGPT 11 BingChat D 0 Bard 11 Vietnamese students
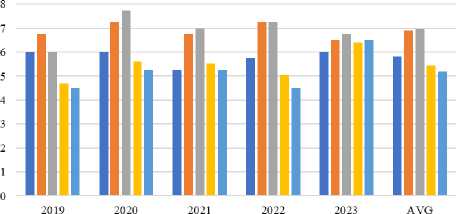
ChatGPT "BingChat "Bard nA VS "MVS
D I ChatGPT 1 1В ingChat D □ Bard 11 Vietnamese students b. Vietnamese score spectrum in 2019
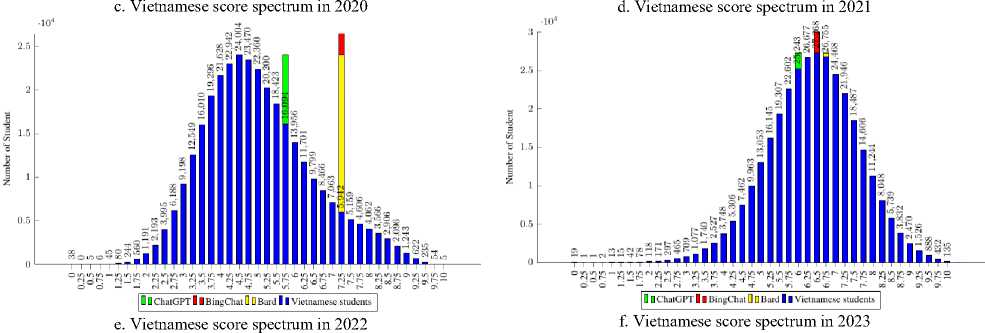
Fig. 5. Performance comparison of LLMs and Vietnamese students
-
4.5 Suggestion on using the right LLM for a certain circumstance
-
4.6 Improving the Efficiency and Quality of LLMs
Table 1 shows the evaluation of the academic performance of Vietnamese students and different LLMs - ChatGPT, BingChat, and Bard - across varying levels of questioning, offering insights into their proficiency and limitations. These results are valuable for users when querying information from LLMs. BingChat and Bard are the best choices for the Knowledge level, while Bard is a reasonable choice at the Comprehension level. However, none of the LLMs are reasonable choices for questions at the Application and High Application levels. The selection of LLMs should be aligned with the levels of questions when designing educational platforms. The limitations of LLMs in addressing intricate application questions should be acknowledged, emphasizing the role of human guidance. Therefore, it is not possible for LLMs to replace the role of teachers in the near future.
Table 1. Performance of Vietnamese student, ChatGPT, Bing Chat and Bard on different question levels of VNHSGE dataset.
|
Question level |
Best performance ← Worst performance |
|||
|
Knownlege |
BingChat ~ Bard |
ChatGPT |
Vietnamese students |
|
|
Comprehension |
Bard |
ChatGPT~BingChat |
Vietnamese students |
|
|
Application |
Vietnamese students |
Bing |
Bard |
ChatGPT |
|
High application |
Vietnamese students |
ChatGPT |
Bard |
BingChat |
The strategic utilization of specialized biology datasets for fine-tuning LLMs is an effective method for improving their performance. The utilization of these datasets can facilitate the familiarization of LLMs with biology-specific terminology, context, and nuances, which are essential for generating precise and accurate responses. Specialized datasets not only enhance the precision of factual information but also facilitate the comprehension of biology inquiries by LLMs, thereby resulting in more pertinent and enlightening responses for students.
The involvement of biology experts and educators in the refinement of LLMs is highly valuable. Professionals possess specialized knowledge and expertise, enabling them to offer valuable insights that are specific to a particular field. This ensures that the models created are in accordance with the latest biology curricula and teaching goals. Professionals with expertise in the field of biology can contribute to the development of well-crafted training examples that are both of high quality and contextually rich. This, in turn, facilitates a deeper comprehension of intricate biology concepts and their practical implications for LLMs.
The integration of multi-modal learning represents a progressive and forward-looking educational strategy. The field of biology education frequently utilizes visual aids, including but not limited to images, diagrams, videos, and interactive simulations, to enhance the learning experience. The integration of these modalities with text-based learning has the potential to offer students a holistic and all-encompassing educational experience. Multi-modal learning can additionally facilitate the comprehension and interpretation of visual content for LLMs, thereby enhancing their adaptability and appropriateness for a wide range of educational resources.
Meta-learning techniques enable LLMs to quickly adapt to novel tasks and domains, thereby enhancing their overall versatility. The significance of this aspect is particularly pronounced within the realm of biology education, given the diverse and dynamic nature of the subject matter. Meta-learning enables LLMs to effectively apply previously acquired knowledge from one domain to another, thereby enhancing their proficiency in addressing diverse biological inquiries and obstacles.
It is of utmost importance to regularly update LLMs with the most recent advancements and insights in the field of biology. This practice is essential in order to maintain the currency and pertinence of the information they offer to students. The field of biology is characterized by its rapid evolution, necessitating the continuous updating of learning materials and resources to ensure that students are provided with accurate and current information. This practice is crucial in cultivating a dynamic learning environment.
Developing feedback loops with educators can play a crucial role in enhancing LLM responses. Educational professionals possess the ability to identify and communicate any inaccuracies, ambiguities, or potential areas for enhancement within content generated by LLM technology. The utilization of an iterative feedback process serves to improve the caliber and pertinence of LLM responses, thereby establishing a stronger alignment with the educational objectives and expectations of both educators and students.
In summary, the successful incorporation of LLMs into biology education necessitates a comprehensive strategy that encompasses technological advancements. The responsible and effective utilization of LLMs in the field of biology education is facilitated by various factors. These include the utilization of specialized datasets, fostering collaboration with experts, incorporating multi-modal learning approaches, employing meta-learning techniques, ensuring regular updates to the models, and implementing feedback mechanisms. The integration of these elements collectively enhances the overall learning experience for students.
5. Conclusion
The integration of LLMs has presented new opportunities for the field of biology education within the dynamic and constantly changing educational landscape. The objective of this research endeavor was to investigate the efficacy of three prominent LLMs - ChatGPT, BingChat, and Bard - within the specific context of the Vietnamese National High School Biology Examination. After conducting thorough evaluation and analysis, a number of significant insights and recommendations have been identified, which offer valuable guidance for enhancing the efficacy and ethical utilization of LLMs in the field of biology education. The results of our study have unveiled the distinct advantages and obstacles associated with each LLM in relation to a wide range of biological inquiries. BingChat and Bard have exhibited remarkable competence in delivering accurate information and assisting students in the practical application of their knowledge, respectively. Conversely, ChatGPT exhibits consistency; however, it faces difficulties when applied in practical scenarios and when engaging in complex cognitive endeavors. These findings emphasize the significance of comprehending the distinct capabilities of each LLM in order to optimize their efficacy as educational instruments. In order to fully exploit the capabilities of LLMs in the field of biology education, we suggest adopting a comprehensive strategy. The process of fine-tuning these models using biology datasets that are specifically tailored to the domain, and engaging in collaborations with experts in the field of biology, can significantly improve their ability to comprehend and interpret context and knowledge within that domain. By incorporating multi-modal learning, utilizing meta-learning techniques, and ensuring consistent updates, the versatility and adaptability of individuals can be expanded. Moreover, the notable efficacy of LLMs, specifically BingChat and Bard, when compared to the average academic achievements of students on the Vietnam National High School Graduation Examination, indicates a potentially fruitful approach for improving the quality of biology education in Vietnam. These models possess the potential to be highly beneficial resources for educators, as they provide students with a wide range of information and tools that facilitate the development of critical thinking, problem-solving, and comprehension abilities.
In summary, this research offers significant contributions to our understanding of the capabilities and limitations of LLMs in the field of biology education. Additionally, it presents a comprehensive plan for the successful incorporation of LLMs into the educational journey. As we explore the continuously expanding realm of educational technology, the conscientious and knowledgeable utilization of LLMs has the potential to enhance the biology learning process, enabling students to engage in a voyage of exploration and comprehension within this crucial scientific domain.
References LLMs Performance on Vietnamese High School Biology Examination
- L. Chen, P. Chen, and Z. Lin, “Artificial Intelligence in Education: A Review,” IEEE Access, vol. 8, pp. 75264–75278, 2020, doi: 10.1109/ACCESS.2020.2988510.
- X. Q. Dao, N. B. Le, and T. M. T. Nguyen, “AI-Powered MOOCs: Video Lecture Generation,” ACM Int. Conf. Proceeding Ser., pp. 95–102, Mar. 2021, doi: 10.1145/3459212.3459227.
- T. M. T. Nguyen, T. H. Diep, B. B. Ngo, N. B. Le, and X. Q. Dao, “Design of Online Learning Platform with Vietnamese Virtual Assistant,” in ACM International Conference Proceeding Series, Feb. 2021, pp. 51–57, doi: 10.1145/3460179.3460188.
- J. Devlin, M.-W. Chang, K. Lee, K. T. Google, and A. I. Language, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv Prepr. arXiv1810.04805, 2018, doi: https://doi.org/10.48550/arXiv.1810.04805.
- Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv Prepr. arXiv1907.11692, 2019.
- C. Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” J. Mach. Learn. Res., vol. 21, pp. 1–67, 2020.
- T. B. Brown et al., “Language Models are Few-Shot Learners,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 1877–1901, 2020.
- X.-Q. Dao et al., “VNHSGE: VietNamese High School Graduation Examination Dataset for Large Language Models,” arXiv Prepr. arXiv2305.12199, May 2023, doi: 10.48550/arXiv.2305.12199.
- G. Tsatsaronis et al., “An overview of the BioASQ large-scale biomedical semantic indexing and question answering competition,” BMC Bioinformatics, vol. 16, no. 1, pp. 1–28, 2015, doi: 10.1186/s12859-015-0564-6.
- J. Welbl, N. F. Liu, and M. Gardner, “Crowdsourcing Multiple Choice Science Questions,” arXiv Prepr. arXiv1707.06209, pp. 94–106, 2017, doi: 10.18653/v1/w17-4413.
- D. Hendrycks et al., “Measuring Massive Multitask Language Understanding,” arXiv Prepr. arXiv2009.03300, 2020, [Online]. Available: http://arxiv.org/abs/2009.03300.
- P. Lu et al., “Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering,” Adv. Neural Inf. Process. Syst., vol. 35, pp. 2507--2521, Sep. 2022.
- OpenAI, “GPT-4 Technical Report,” arXiv Prepr. arXiv2303.08774, 2023, doi: https://doi.org/10.48550/arXiv.2303.08774.
- E. Agathokleous, C. J. Saitanis, C. Fang, and Z. Yu, “Use of ChatGPT: What does it mean for biology and environmental science?,” Sci. Total Environ., vol. 888, p. 164154, 2023, doi: https://doi.org/10.1016/j.scitotenv.2023.164154.
- Y. Tong and L. Zhang, “Discovering the next decade’s synthetic biology research trends with ChatGPT,” Synth. Syst. Biotechnol., vol. 8, no. 2, pp. 220–223, 2023, doi: 10.1016/j.synbio.2023.02.004.
- A. HS Kumar, “Analysis of ChatGPT Tool to Assess the Potential of its Utility for Academic Writing in Biomedical Domain,” Biol. Eng. Med. Sci. Reports, vol. 9, no. 1, pp. 24–30, 2023, doi: 10.5530/bems.9.1.5.
- E. Shue, L. Liu, B. Li, Z. Feng, X. Li, and G. Hu, “Empowering Beginners in Bioinformatics with ChatGPT,” Quantitative Biology, Vol. 11 (2), pp. 105-108, doi: 10.15302/J-QB-023-0327.
