Локализация и классификация аномалий в одномерных сигналах на основе вейвлет-анализа и математических методов оптимизации

Автор: Н.Д. Сакович, Д.А. Аксенов, Е.С. Плешакова, С.Т. Гатауллин
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 1 т.50, 2026 года.
Бесплатный доступ
Метод классификации типов нестационарностей во временных рядах на основе вейвлет-анализа для локализации и детекции границ нестационарности; математических алгоритмов для сравнения типов нестационарностей на основе шаблонов эталонных сигналов и классификации аномалий при помощи неградиентных методов оптимизации; с возможностью дальнейшего применения для разработки автоматизированных информационных систем комплексного мониторинга состояния электросети и ее отдельных компонент представлен в данном исследовании. Кодовая база размещена в открытом репозитарии проекта и доступна для воспроизведения вычислительных экспериментов. Предлагаемый подход имеет широкий спектр применения, но отдельного внимания заслуживает возможная интеграция в целях повышения надежности систем диагностики с технологиями Интернета вещей, построения цифровых двойников, агент-ориентированного моделирования сложных социально-экономических процессов, облачными высокопроизводительными вычислениями, позволяющими анализировать большие данные в реальном времени.
Цифровая обработка сигналов, вейвлет-анализ, численные методы, алгоритмы
Короткий адрес: https://sciup.org/140314081
IDR: 140314081 | DOI: 10.18287/COJ1683
Localization and classification of anomalies in one-dimensional signals based on wavelet analysis and mathematical optimization methods
A method for classifying types of non-stationarities in time series based on wavelet analysis for localization and detection of non-stationarity boundaries; mathematical algorithms for comparing types of non-stationarities based on templates of reference signals and classifying anomalies using non-gradient optimization methods; with the possibility of further application for developing automated information systems for comprehensive monitoring of the state of the power grid and its individual components is presented in this study. The code base is located in the open project repository and available to reproduce computational experiments. The suggested approach has a wide range of applications, but special attention should be paid to the possible integration in order to improve the reliability of diagnostic systems with Internet of Things (IoT) technologies, the digital twins construction, agent-based modeling (ABM) for complex socio-economic processes, and cloud high-performance computing (HPC) that allows real time big data analytics.
Текст научной статьи Локализация и классификация аномалий в одномерных сигналах на основе вейвлет-анализа и математических методов оптимизации
Проблематика обнаружения сбоев сигналов занимает ключевое место в сферах, связанных с анализом сейсмической активности [1 – 3], оценкой вибраций промышленного оборудования [4 – 6], контролем целостности конструкций и надежностью электрических сетей [7 – 9]. Эффективная диагностика сбоев позволяет оперативно выявлять и устранять проблемы, минимизируя риск аварий и повреждений оборудования. Однако существующие методы часто сталкиваются с ограничениями в точности и чувствительности, особенно при выявлении сложных и непосредственных сбоев. Традиционные методы, такие как оконное преобразование Фурье, не обеспечивают детального временно-частотного анализа сигналов, что затрудняет выявление незначительных изменений в сигналах. В связи с этим поиск новых и более эффективных методов диагностики становится одной из ключевых задач современной науки и инженерии. Одним из наиболее перспективных направлений в области обработки сигналов является использование вейвлет-преобразования. Вейвлет-анализ позволяет проводить детальный временночастотный анализ сигналов, что делает его особенно привлекательным для диагностики сбоев в электрических цепях. Множество исследований по применению вейвлет-преобразования в различных областях, включая медицинскую диагностику [10 – 14], обработку аудиосигналов и анализ данных [15 – 18], подтверждает его эффективность и гибкость. В частности, вейвлет-преобразование позволяет выявлять мелкие и сложные изменения в сигналах, что является критически важным для диагностики сбоев в электрических цепях.
В данной работе представлена система классификации типов ошибок в одномерных сигналах на основе разработанного авторами алгоритма вейвлет-анализа, дополненного численными методами. Предложенный подход использует вейвлет-преобразование для локализации сбоев в сигнале для последующей классификации с использованием методов оптимизации через минимизацию целевой функции ошибки. Это позволяет не только улучшить точность идентификации сбоев, но и обеспечивает более глубокое понимание их природы. Предложенный метод может быть использован после адаптации в агентном моделировании сложных социальноэкономических процессов в сочетании с высокопроизводительными вычислениями (HPC) [19 – 20].
Ранее авторами рукописи уже были получены значимые научные результаты в области приложений гибридных нейросетевых моделей цифровой обоработки сигналов. Так, в [21] была разработана и протестирована на наборе данных, собранном авторами в результате полевого исследования, нейросетевая модель вида Windowed Fourier Transform (WFT) – 2D-CapsNet мониторинга состояния промышленного оборудования для бурения. В работе [22] метод был модицицирован до вида Frequency Slice Wavelet Transform (FSWT) – 2D-CapsNet и произведено сравнение с базовым подходом. Несмотря на близкие количественные оценки производительности, модель FSWT – 2D-CapsNet оказалась более эффективной и была успешно использована авторами в задачах мониторинга физиологических показателей посредством анализа фотоплетизмограмм [23].
Современные подходы к задачам классификации данных всё чаще опираются на методы машинного обучения, в частности, на нейросетевые архитектуры. Однако использование нейронных сетей сопряжено с рядом ограничений, основное из которых заключается в необходимости формирования обширных обучающих выборок. Эти датасеты, как правило, собираются в рамках конкретной предметной области, что усложняет процесс адаптации модели к новым сферам применения и требует значительных вычислительных ресурсов для её переобучения.
В предлагаемом методе используется альтернативный подход, основанный на вейвлет-преобразовании и численных методах оптимизации. Вейвлет-преобразование [30, 31] выполняет задачу локализации значимых особенностей во входных данных, что позволяет эффективно выделять информативные признаки. В отличие от нейросетевых методов, требующих сложной процедуры обучения, классификация в нашем подходе осуществляется на основе математических моделей, использующих библиотеки базовых эталонных сигналов.
Ключевой аспект предлагаемого метода заключается в применении метрики среднеквадратичного отклонения (MSE) в качестве критерия сходства. Данный подход позволяет сравнивать входные данные с заранее сформированными эталонами и производить классификацию без необходимости предварительного обучения модели на специализированных выборках. Таким образом, обеспечивается гибкость метода и его переносимость в различные предметные области без значительных затрат на адаптацию.
Одним из важных преимуществ предлагаемого метода является его модульность. Данный подход можно рассматривать как сервисно-ориентированный, что даёт возможность заменять отдельные компоненты системы без нарушения её общей структуры. Например, этап классификации или локализации может быть заменён на нейросетевые модели, если это окажется целесообразным для конкретной задачи. Такой гибридный подход позволяет адаптировать алгоритм под различные сценарии, сочетая преимущества традиционных математических методов и машинного обучения.
Некоторые параметры алгоритма, такие как пороговые значения (threshold) и другие коэффициенты, зависят от предметной области и специфики решаемой задачи. Их выбор осуществляется с учётом характеристик данных и может требовать дополнительной калибровки для оптимального функционирования модели.
В целом, предложенный метод сочетает преимущества вейвлет-преобразования для локального анализа данных, численных методов оптимизации для эффективной классификации и гибкость модульного подхода, позволяя при необходимости интегрировать нейросетевые компоненты. Это делает его конкурентоспособной альтернативой чисто нейросетевым моделям, особенно в случаях, когда доступность больших обучающих выборок ограничена, а адаптация к новым данным должна быть выполнена с минимальными вычислительными затратами.
Организация настоящей рукописи выглядит следующим образом. В параграфе материалов и методов представлены базовые алгоритмы и подходы, схема многоуровневой архитектуры прикладного решения, схема и описание разработанного авторами метода локализации и классификации сбоев в сигнале; в экспериментальном параграфе приведены результаты численных экспериментов, описаны ограничения применимости метода и возможные пути улучшения эффективности работы системы, произведены тесты производительности; заключение финализирует исследование, обобщает полученные результаты и обозначает направления будущей работы.
-
1. Материалы и методы
Система [24] анализа сигналов (см. схему на рис. 1) на основе алгоритма вейвлет-анализа, дополненного численными методами (см. схему на рис. 2) использует следующие базовые методы и алгоритмы.
Данная архитектура представляет собой многоуровневую архитектуру, ориентированную на сбор, обработку, передачу, анализ и предоставление данных в рамках распределённой вычислительной среды. Она может быть рассмотрена как прикладной пример реализации алгоритмов обработки данных с использованием современных технологий распределенного хранения, распределенной обработки и анализа.
Алгоритм вейвлет-разложения, часто называемый алгоритмом Маллата [25] или быстрым вейвлет-преобразованием, представляет собой эффективный метод для разложения сигнала на несколько уровней детализации. Этот алгоритм является основой для многих приложений обработки сигналов, включая шумоподавление, сжатие данных и анализ особенностей. Псевдокод, представленный как ‘WaveletDecomposition‘, описывает схему алгоритма Маллата для одномерных сигналов и соответствует реализации в библиотеке ‘pywt.wavedec‘.
Метод Нелдера–Мида [26] является одним из популярных методов неградиентой оптимизации. Он основан на идее последовательного изменения и перемещения симплексов по пространству для поиска необходимого оптимума. В данном случае это актуально, так как не всегда получится взять градиент от целевой функции.
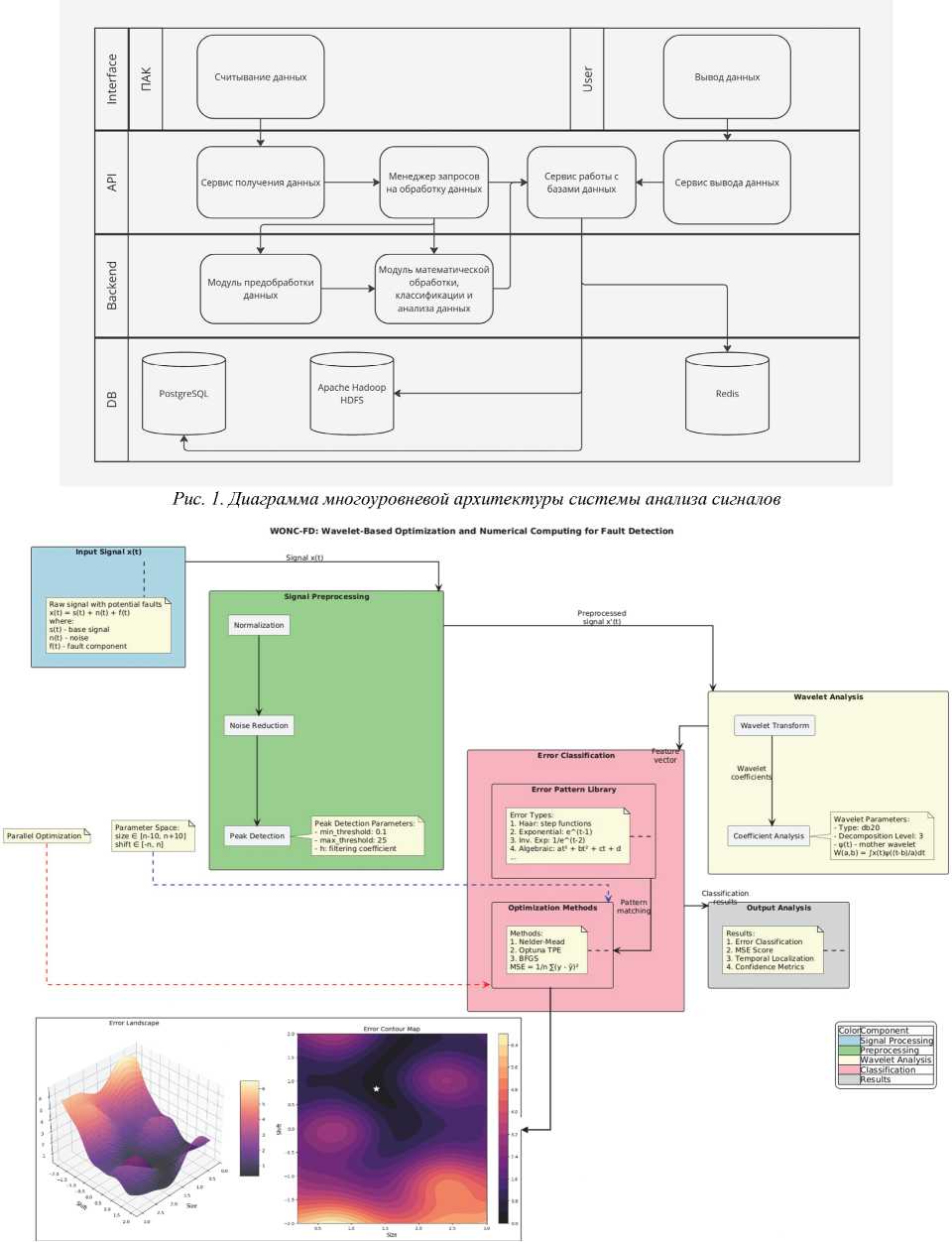
Рис. 2. Схема работы алгоритма локализации и классификации сбоев в сигнале
Алгоритм Бройдена–Флетчера–Гольдфарба–Шанно (BFGS) [27] – один из самых быстрых и точных алгоритмов оптимизации, использующий градиенты функций. В данном случае его эффективно использовать, если требуется быстрая скорость при необязательной высокой точности классификации.
Aлгоритм байесовской оптимизации (Tree-structured Parzen Estimator, TPE) [28] используется в Optuna для эффективного поиска оптимальных параметров в задачах, где вычисление целевой функции является затратным. TPE является sampler-ом, то есть методом, который определяет, какие параметры следует исследовать на следующей итерации оптимизации. В отличие от случайного поиска или grid search, TPE использует историю предыдущих испытаний, чтобы интеллектуально направлять поиск в наиболее перспективные области пространства параметров.
Алгоритм метода наименьших квадратов (Least Squares Method) [29].
-
1.1. Вейвлет-преобразование
Основополагающим методом для работы алгоритма является вейвлет-преобразование, которое позволяет разложить входной сигнал на детализирующие коэффициенты, которые можно использовать для последующего анализа сбоев и их локализации.
Алгоритм 1: WaveletDecomposition (схема Mallat’s Algorithm, pywt.wavedec)
-
1: Input: signal — входной одномерный сигнал,
-
2: Input: wavelet — тип вейвлета (например, 'db20'),
-
3: Input: level — глубина разложения
-
4: Output: массив коэффициентов coeffs = [cA i eve i , cDlevel cD1]
-
5: Инициализировать список коэффициентов coeffs пустым
-
6: current_signal ^ signal
-
7: for k^ 1 до level do
-
8: Выполнить свёртку current_signal с фильтром масштабирования (low-pass) из выбранного вейвлета ^cAk
-
9: Выполнить свёртку current_signal с фильтром детализации (high-pass) из выбранного вейвлета ^cDk
-
10: Произвести операцию «даунсэмплинга» (выбрать каждый второй отсчёт) для cAk и cDk
-
11: current_signal ^ cAk > Сигнал на следующем шаге — это апроксимирующие коэффициенты
-
12: Сохранить cDk во внутренний буфер
-
13: end for
-
14: Сохранить current_signal (т.е. cAlevel ) в coeffs
-
15: Добавить все детализирующие коэффициенты cDk в coeffs в порядке от последнего к первому
-
16: return coeffs
-
1.2. Методы предобработки данных
Далее необходимо рассмотреть методы предобработки данных, то есть полученного сигнала для последующего анализа: локализации и классификации.
-
1.2.1. Алгоритм intervals_errors
Алгоритм 2 : intervals_errors
-
1: Input: signal — одномерный массив
-
2: Input: wavelet — тип вейвлета (например, 'db20'),
-
3: Input: level = 3 — уровень разложения
-
4: Input: epsilon = 2
-
5: Input: min_threshold = 0.1, max_threshold = 25
-
6: Input: h= 10 " 6
-
7: Output: список интервалов (пар), где предполагаются ошибки
-
8: coeffs ^ WaveletDecomposition(signal, wavelet, level) > См. алгоритм 1.
-
9: cf_lvl ^ coeffs[level] > Коэффициенты на заданном уровне (детализирующие или
- апроксимирующие – зависит от библиотеки)
10: peaks ^ detect_faults(cf_lvl, min_threshold, max_threshold) 11: Построить список eps_peaks путём peak — £ для каждого peak Е peaks[0] 12: intervals ^ combinations(eps_peaks,2) 13: return intervals
Алгоритм intervals_errors предназначен для определения интервалов, в которых предположительно находятся ошибки или повреждения в сигнале. Он использует вейвлет-разложение, обнаружение пиков и генерацию пар для определения этих интервалов.
Замечания:
Алгоритм intervals_errors комбинирует вейвлет-анализ с обнаружением пиков и комбинаторикой для определения интервалов ошибок. Использование вейвлет-разложения позволяет анализировать сигнал на разных частотных уровнях и, возможно, лучше выделять особенности, связанные с повреждениями. Параметр £ и генерация пар могут быть связаны с попыткой определить интервалы вокруг пиков, в которых наиболее вероятно наличие ошибки. Настройка параметров вейвлета, уровеня разложения, порогов prominence и порога фильтрации, а также значения е критически важна для эффективности алгоритма в конкретных приложениях.
-
1.2.2. Прочие алгоритмы
Алгоритм find_peaks предназначен для обнаружения локальных максимумов (пиков) в одномерном числовом массиве. Основная цель алгоритма – выделить индексы точек, которые соответствуют пикам, удовлетворяющим заданным критериям, в частности, по 'prominence' (выделенности пика).
Алгоритм detect_faults предназначен для обнаружения потенциальных «повреждений» в одномерном сигнале. Он использует алгоритм поиска пиков find_peaks для идентификации пиков в абсолютном значении сигнала, которые интерпретируются как индикаторы повреждений.
Алгоритм clean_signal предназначен для «очистки» сигнала, представленного в виде структуры или массива с полями x и y . Алгоритм удаляет синусоидальную компоненту из сигнала y для исследования последующего исследования сбоев в сигнале.
Алгоритм pad_array предназначен для дополнения входного массива arr нулями до заданной длины length. Если входной массив уже имеет длину, большую или равную length, алгоритм возвращает исходный массив без изменений. В случае, если длина массива меньше требуемой, недостающие элементы добавляются симметрично с обеих сторон массива в виде нулей.
Алгоритм resize_vector предназначен для изменения размера одномерного массива (вектора) vector до новой заданной длины new_size. Алгоритм предусматривает два основных случая изменения размера: увеличение длины и уменьшение длины, и использует разные подходы для каждого случая.
-
1.3. Алгоритм
Теперь можно рассмотреть основные алгоритмы для локализации и классификации сбоев в сигнале, которые основываются на использовании предыдущих методов и алгоритмов.
Математически можно описать решаемую задачу следующим образом:
argminCs,£,a)e^xтxлMSE(у, ErrorFunction(s, t, а))
где:
-
1. у : исходный сигнал, представленный в виде временного ряда. Этот сигнал является эталонным и используется для оценки точности приближения.
-
2. у: приближенный сигнал, полученный в результате применения функции ошибки с определенными параметрами. Целью является максимально точное соответствие этого сигнала исходному сигналу у.
-
3. ErrorFunction : функция, которая принимает на вход параметры растяжения, сдвига и амплитуды и возвращает приближенный сигнал. Формально ErrorFunction(s, t, а) обозначает приближенный сигнал, полученный с учетом параметров s, t и а.
-
4. S: множество возможных значений параметра растяжения сигнала по оси OX. Каждый элемент этого множества представляет собой коэффициент растяжения, который может быть применен к исходному сигналу.
-
5. Т : множество возможных значений параметра сдвига сигнала. Каждый элемент этого множества представляет собой величину сдвига, которая может быть применена к исходному сигналу.
-
6. А : множество возможных значений параметра амплитуды сигнала. Каждый элемент этого множества представляет собой коэффициент амплитуды, который может быть применен к исходному сигналу.
-
7. SxTxA : декартово произведение множеств S, Т и А, которое представляет собой множество всех возможных комбинаций параметров растяжения, сдвига и амплитуды.
Целью работы метода является нахождение такой комбинации параметров (s, t, а), которая минимизирует среднеквадратическую ошибку между исходным сигналом у и приближенным сигналом у.
Таким образом, данная формула определяет процедуру поиска оптимальных параметров растяжения, сдвига и амплитуды, которые обеспечивают наилучшее приближение исходного сигнала в смысле минимизации среднеквадратичной ошибки.
-
1.3.1. Алгоритм WONC-FD mse_classification
Алгоритм 3: WoncFD_mse_classification
1: Input: 2: у — одномерный массив точек 3: errors — список возможных типов ошибок (например, ["haar", "haarl", ...]) 4: leng — базовая длина сигнала (например, 1000) 5: epsilon — маленький порог для проверки близости к 0 6: n — доля нулевых (по модулю) точек для отбраковки 7: Output: список: [название лучшего типа ошибки, MSE] 8: if (length(y) < leng x 0,05) or (X/ 1(|y;| <£) > length(y) x n) then 9: return ["Bad signal", "NaN"] 10: end if 11: Инициализировать пустой массив result 12: хь массив равномерных значений от 0 до 1 размером length(y) 13: ampl ь 1 14: size_values ь {length(y),length(y) + 10, ...,2 x length(y)} 15: shifts ь {-length(y), -length(y) + 1, .. ,length(y)} 16: for каждый err из errors do 17: mse_err ь 10s >Задаём начальное большое значение MSE 18: for каждый s из size_values do 19: for каждый shift из shifts do 20: Error ь resize_vector(Error_signal(err, x, ampl,1) s') 21: if shift > 0 then 22: arr_error ь массив Error, дополненный нулями в начале (сдвиг вперёд) 23: else 24: arr_error ь массив Error, дополненный нулями в конце (сдвиг назад) 25: end if 26: features_matrix ь матрица (length(x),2), где первая колонка — 1, вторая — arr_error 27: Найти коэффициенты в методом наименьших квадратов: min || features_matrix -в-У W2 28: approximated_signal ь features_matrix - в 29: mse ь MSE (у, approximated_signal) 30: if mse < mse_err then 31: mse_err ь mse 32: end if 33: end for 34: end for 35: Добавить mse_err в массив result 36: end for 37: Найти индекс i* = argminresult 38: return [errors[i*], result[i*]]
Алгоритм mse_classification предназначен для классификации типа «ошибки» или «дефекта» в одномерном сигнале y путем сравнения его с набором предопределенных «ошибочных сигналов» Error_signal различных типов, перечисленных в массиве errors. Классификация основана на минимизации среднеквадратической ошибки (MSE) между входным сигналом и аппроксимацией, полученной с использованием различных типов ошибок, размеров и сдвигов.
Основные шаги алгоритма
-
• Входные данные: алгоритм принимает на вход одномерный массив точек y (которые являются интервалами, полученными после применения вейвлет-преобразования и разделения на данные интервалы), список названий типов ошибок errors, базовую длину сигнала leng, малый порог е для проверки близости к нулю и долю нулевых (по модулю) точек n для отбраковки сигнала.
-
• Предварительная проверка сигнала: алгоритм выполняет начальную проверку входного сигнала y , чтобы отсеять «плохие» сигналы, которые могут привести к некорректным результатам.
-
- Проверка длины сигнала: Проверяется, не слишком ли короткий сигнал. Если длина y меньше или равна 5 % от базовой длины leng (т.е., length(y) < 0,05 xleng), сигнал считается «плохим».
-
- Проверка на наличие почти нулевых точек: подсчитывается количество точек в y , абсолютное значение которых меньше заданного малого порога е (|у / | <е ). Если количество таких точек превышает долю n от общей длины сигнала (т.е. число точек |у ; | <е > nx length(y)), сигнал также считается «плохим».
-
• Инициализация: для хороших сигналов алгоритм продолжает процесс классификации.
-
- Инициализируется пустой массив result для хранения значений MSE для каждого типа ошибки.
-
- Создается массив x , представляющий собой равномерно распределенные значения от 0 до 1,
размером с длину сигнала y . Это может служить в качестве нормированной «временной» оси для генерации ошибок.
-
- Определяется набор значений размеров size_values. В псевдокоде это размеры от length(y) с шагом 10 до 2 xlength(y). Эти размеры будут использоваться для изменения размера генерируемых сигналов ошибок.
-
- Определяется набор значений сдвигов shifts от -length(y) до length(y') с шагом 1. Эти сдвиги будут использоваться для смещения генерируемых сигналов ошибок относительно начала сигнала y .
-
• Цикл по типам ошибок (внешний цикл FOR): алгоритм итерируется по каждому типу ошибки err из списка errors. Для каждого типа ошибки выполняется следующий процесс:
-
- Инициализация минимальной MSE для типа ошибки: устанавливается начальное значение минимальной MSE mse_err для текущего типа ошибки на большое число (например, 10s). Это значение будет обновляться, если будут найдены меньшие значения MSE.
-
- Цикл по размерам (средний цикл FOR): для каждого размера s из набора size_values:
* Цикл по сдвигам (внутренний цикл FOR): для каждого сдвига shift из набора shifts:
-
1) Генерация и изменение размера сигнала ошибки: генерируется «базовый» сигнал ошибки с использованием функции Error_signal(err, x , ampl, 1) для текущего типа ошибки err, «временной оси» x , амплитуды ampl и масштаба 1. Затем с помощью функции resize_vector размер сгенерированного сигнала ошибки изменяется до длины s.
-
2) Применение сдвига к сигналу ошибки: в зависимости от знака сдвига shift, сигнал ошибки Error сдвигается либо вперед (если shift > 0), либо назад (если shift < 0) относительно сигнала у . Сдвиг реализуется путем добавления нулей в начало или конец сигнала ошибки и обрезания результата до длины length(x).
-
3) Построение матрицы признаков: создается матрица признаков features_matrix размером (length(x)2) Первый столбец матрицы заполняется единицами, а второй столбец - сдвинутым сигналом ошибки arr_error. Первый столбец с единицами позволяет учесть смещение в модели.
-
4) Метод наименьших квадратов (МНК): решается задача линейной регрессии методом наименьших квадратов для нахождения коэффициентов coefficients (в) минимизирующих норму разности || features_matrix -в-У II2 ■ Это позволяет найти оптимальную линейную комбинацию (смещение и масштабирование) сигнала ошибки для аппроксимации сигнала y .
-
5) Вычисление аппроксимированного сигнала: вычисляется аппроксимированный сигнал approximated_signal как произведение матрицы признаков features_matrix на найденные коэффициенты coefficients.
-
6) Вычисление MSE: вычисляется среднеквадратическая ошибка (MSE) между исходным сигналом y и аппроксимированным сигналом approximated_signal.
-
7) Обновление минимальной MSE: если вычисленное значение MSE меньше текущей минимальной MSE mse_err для данного типа ошибки, то mse_err обновляется этим новым, меньшим значением MSE.
-
• Сохранение минимальной MSE для типа ошибки: после завершения циклов по размерам и сдвигам минимальное найденное значение MSE mse_err для текущего типа ошибки err добавляется в массив result.
Определение лучшего типа ошибки: После завершения цикла по всем типам ошибок, алгоритм находит индекс минимального значения в массиве result. Этот индекс соответствует типу ошибки который обеспечил наименьшую MSE при аппроксимации сигнала y .
Выходные данные: алгоритм возвращает список, содержащий два элемента: название лучшего типа ошибки (из списка errors) и соответствующее минимальное значение MSE. Это указывает на тип ошибки, который лучше всего «объясняет» структуру сигнала y с точки зрения MSE.
Замечания: алгоритм mse_classification представляет собой метод классификации, основанный на сопоставлении сигнала с набором эталонных «ошибочных» сигналов. Использование MSE в качестве метрики качества аппроксимации позволяет количественно оценить, насколько хорошо каждый тип ошибки соответствует входному сигналу. Перебор различных размеров и сдвигов сигналов ошибок призван учесть возможные различия в масштабе и фазе между ожидаемыми ошибками и реальными отклонениями в сигнале. Метод наименьших квадратов используется для оптимальной «подгонки» масштаба и смещения сигнала ошибки к входному сигналу. Эффективность алгоритма зависит от репрезентативности набора errors, адекватности функции Error_signal для моделирования реальных ошибок, и правильного выбора параметров, таких как size_values, shifts, е и и . Алгоритм вычислительно интенсивен из-за вложенных циклов и многократного решения задачи МНК. Для решения проблемы вычислительной сложности вложенных циклов используются неградиентные методы оптимизации, такие как метод Нелдора–Мида, BFGS и TPESampler, которые находят локальные минимумы целевой функции ошибки по параметрам сдвига и растяжения «эталонных» сигналов, это позволяет заменить грубый перебор на более эффективные методы.
-
1.4. Эксперименты и анализ результатов
-
1.4.1. Численный эксперимент
Для оценки эффективности предлагаемого метода был проведён эксперимент, в котором анализировался сигнал, содержащий несколько различных сбоев на основе синтетических данных. Входные данные подавались на вход алгоритма, последовательно проходя через этапы локализации и классификации.
В качестве тестового сигнала для данного эксперимента был выбран сигнал, содержащий два типа аномалий: haar и algb (рис. 3). Эти типы сбоев характеризуются различными особенностями: haar представляет собой резкие скачки или провалы в данных, в то время как algb отражает схожий с видом некоторого полинома сбой.
Описание некоторых других видов аномалий:
-
- 'haar' – ошибки типа вейвлета Хаара,
-
- 'haar1' – одноступенчатая ошибка Хаара,
-
- 'exp' – экспоненциальная ошибка,
-
- '-exp' – отрицательная экспоненциальная ошибка,
-
- 'Invexp' – обратная экспоненциальная ошибка,
-
- 'Invexp+' – обратная экспоненциальная ошибка со сдвигом вверх,
-
- 'algb' – полиномиальная ошибка 3-й степени.
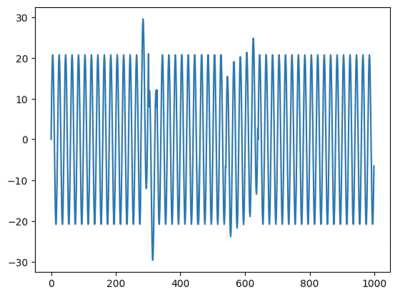
Рис. 3. Сигнал со сбоями
После предварительной обработки, включающей подавление шума и удаление синусоидальной составляющей, к сигналу были применены методы обнаружения аномалий. Целью данного этапа являлось разбиение сигнала на интервалы, с высокой вероятностью содержащие сбои (рис. 4).
Результаты работы алгоритмов представлены в табл. 1. Анализ таблицы показывает, что для всех интервалов, содержащих сбои типов haar и algb, алгоритмы продемонстрировали успешное распознавание. Количественная оценка качества, выраженная через среднеквадратичную ошибку (MSE), подтверждает этот вывод: для всех корректно идентифицированных сбоев haar и algb значение MSE не превышает 0,5.
Однако, помимо истинно положительных результатов, был зафиксирован один ложноположительный случай, связанный с алгоритмом Invexp. Интервал, ошибочно классифицированный как содержащий аномалию, на самом деле не имеет выраженных признаков сбоя.
Данную проблему можно решить несколькими путями:
-
1) Увеличение количества итераций: при оптимизации параметров алгоритма большее количество итераций работы методов оптимизации (BFGS, Nelder-Mead, TPESampler) может привести к более точной минимизации целевой функции и, как следствие, к снижению вероятности ложноположительных результатов.
-
2) Уменьшение порога допуска: в данный момент пороговое значение MSE для классификации интервала как аномального установлено на уровне 0,5. Снижение этого порога (например, до 0,4) повысит строгость критериев отбора и может уменьшить количество ложных срабатываний. Однако этот подход требует осторожности, так как слишком строгий порог может привести к пропуску реальных сбоев. Улучшение качества распознавания сигнала при увеличении количества итераций, описанное в пункте 1, позволит снизить порог без потери истинно положительных результатов.
-
3) Увеличение уровня детализации вейвлет-преобразования: Для вейвлет-анализа можно использовать более высокий уровень детализации (в рамках экспериментов использовался третий уровень детализации). Это позволит выявлять более тонкие особенности сигнала, что может способствовать более точному различению между нормальными участками и аномалиями.
-
4) Использование разных вейвлетов: разные вейвлеты обладают различной чувствительностью к различным типам аномалий. Экспериментирование с различными вейвлет-семействами (например, «Морле», «Мексиканская шляпа», «Добеши» и др.) может привести к улучшению качества распознавания для конкретного типа сигнала и сбоев.
Таким образом, несмотря на наличие ложноположительного срабатывания, результаты эксперимента в целом демонстрируют эффективность применения предложенного подхода для обнаружения сбоев типов haar и algb в зашумленном сигнале с синусоидальной составляющей.
-
1.4.2. Тестирование производительности
Экспериментальная оценка производительности системы проводилась в условиях нарастающего числа сбоев в сигнале. На рис. 5 представлены графики зависимости времени выполнения от эпохи, где эпоха соответствует одной итерации алгоритма, определяемой количеством сбоев в обрабатываемом сигнале. В экспериментах рассматривались пять эпох (от одного до пяти сбоев). Представленные результаты демонстрируют влияние количества сбоев на производительность алгоритма.
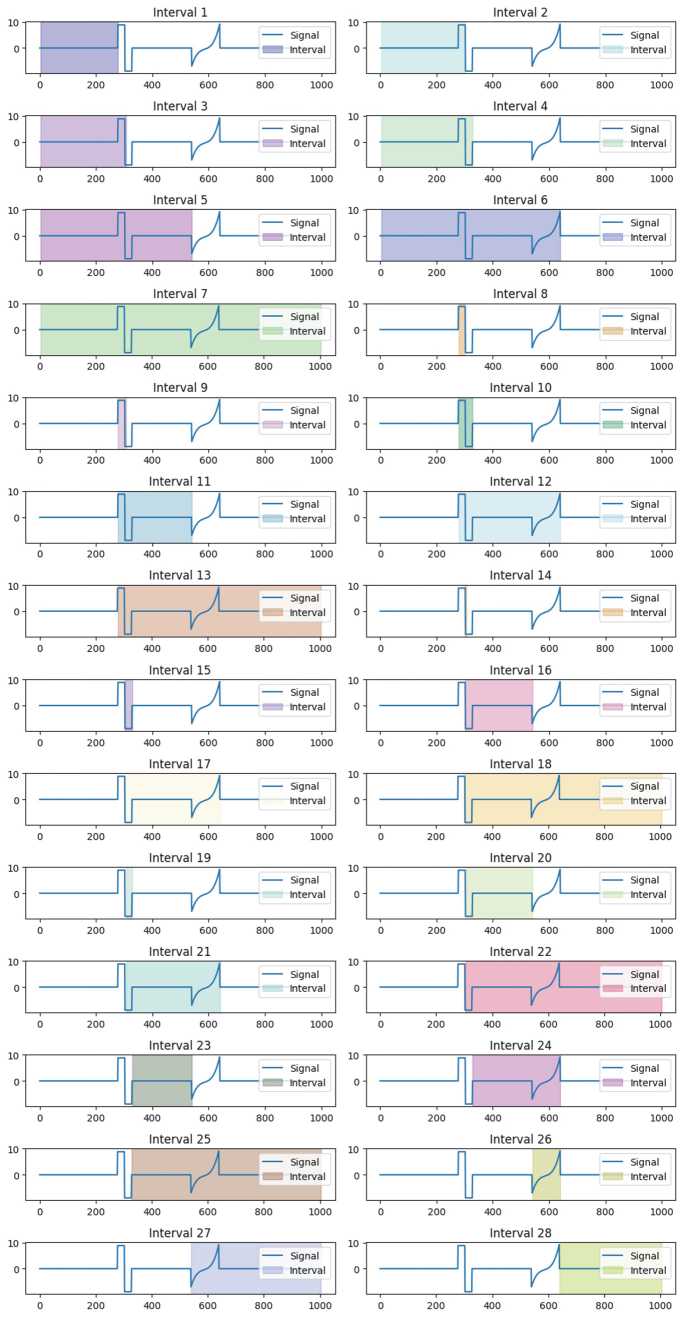
Рис. 4. Интервалы сигнала со сбоями
Табл. 1. Результаты
|
Interval |
Fault Type |
Error (MSE) |
|
1 |
Bad signal |
Nan |
|
2 |
Invexp |
0,739 |
|
3 |
Invexp |
0,927 |
|
4 |
haar |
0,448 |
|
5 |
haar |
1,644 |
|
6 |
haar |
1,662 |
|
7 |
haar |
1,209 |
|
8 |
Bad signal |
Nan |
|
9 |
Bad signal |
Nan |
|
10 |
Bad signal |
Nan |
|
11 |
haar |
0,383 |
|
12 |
haar |
1,505 |
|
13 |
Invexp |
3,785 |
|
14 |
Bad signal |
Nan |
|
15 |
Bad signal |
Nan |
|
16 |
Invexp |
0,696 |
|
17 |
algb |
2,142 |
|
18 |
Invexp |
1,922 |
|
19 |
Bad signal |
Nan |
|
20 |
Invexp |
0,481 |
|
21 |
-exp |
1,902 |
|
22 |
Invexp |
1,696 |
|
23 |
Bad signal |
Nan |
|
24 |
algb |
0,209 |
|
25 |
algb |
3,187e-13 |
|
26 |
algb |
0,251 |
|
27 |
algb |
2,174e-13 |
|
28 |
Bad signal |
Nan |
Результаты экспериментов демонстрируют тенденцию к увеличению времени выполнения алгоритма с ростом количества сбоев в сигнале. Это обусловлено особенностями вейвлет-анализа: большее число сбоев приводит к появлению большего количества значимых вейвлет-коэффициентов, что, в свою очередь, увеличивает число интервалов, требующих обработки алгоритмом. Однако следует отметить, что в отдельных случаях наблюдается отклонение от этой общей тенденции. Так, для некоторых сигналов с большим количеством сбоев время выполнения оказывалось меньше, чем для сигналов с меньшим числом сбоев. Это связано с тем, что вейвлет-преобразование не всегда приводит к равномерному увеличению количества интервалов при увеличении числа сбоев; в некоторых случаях структура вейвлет-коэффициентов может быть такова, что общее количество операций, необходимых для обработки, уменьшается. Таким образом, влияние сбоев на время выполнения алгоритма является нелинейным и зависит от конкретной структуры сигнала и его вейвлет-представления.
Заключение
В рукописи представлены метод, алгоритмы, пример многоуровневой архитектуры информационной системы и результаты тестирования системы анализа сигналов на основе разработанного авторами алгоритма вейвлет-анализа, дополненного численными методами. Несмотря на достигнутые результаты, дальнейшие исследования могут быть направлены на повышение вычислительной эффективности, расширение библиотеки модельных ошибок, исследование робастности к параметрам и изучение альтернативных метрик качества классификации. Ключевыми преимуществами предложенной системы алгоритмов являются использование методов оптимизации и параллельных вычислений. Система демонстрирует потенциал для применения в различных областях обработки сигналов, где требуется автоматическое обнаружение и классификация аномалий или дефектов, таких как диагностика оборудования высокопроизводительных вычислительных кластеров или мониторинг сенсорных данных, являясь мощным и универсальным инструментом для анализа и интерпретации сложных сигнальных данных.
Работа выполнена при поддержке Министерства науки и высшего образования Российской Федерации в рамках проекта № 075-15-2024-525 от 23.04.2024.
