Machine learning-based voice assistant: optimizing the efficiency of speech conversion for people with speech disorders

Author: Antor M.H., Chudinovskikh N.V., Bachurin M.V., Shurpikov A.A., Khlebnikov N.A., Bredikhin B.A.
Journal: Компьютерная оптика @computer-optics
Section: Численные методы и анализ данных
Article in issue: 1 т.49, 2025.
Free access
An automatic speech recognition system has the possibility of enhancing the standard of living for persons with disabilities by solving issues such as dysarthria, stuttering, and other speech defects. In this paper, we introduce a voice assistant using hyperkinetic dysarthria (HD) defect speeches. It contains the data preprocessing steps and the development of a novel convolutional recurrent network (CRN) model that is built depending on the convolutional neural networks and recurrent neural networks. We implemented data preprocessing methods, including filtering, down-sampling, and splitting, to prevent overfitting and decrease processing power as well as time. In addition, the technique of Mel Frequency Cepstral Coefficients (MFCC) has been utilized to extract speech characteristics. The proposed model is trained to recognize HD speech disorders using a dataset including 2000 Russian speeches. The experimental results demonstrate that the proposed method obtains a character error rate (CER) of 14.76 %. It indicates that approximately 85 % of characters are able to correctly recognize on the test dataset. We have created a telegram bot that utilizes our trained model to help people with hyperkinetic dysarthria speech disorder. This bot is capable of providing assistance independently, without the need for any third-party assistance.
Natural language processing, hyperkinetic dysarthria, speech recognition, feature extraction, optimization
Short address: https://sciup.org/140310450
IDR: 140310450 | DOI: 10.18287/2412-6179-CO-1482
Text of the scientific article Machine learning-based voice assistant: optimizing the efficiency of speech conversion for people with speech disorders
Hyperkinetic dysarthria is highlighted through abnormal spontaneous actions that have an impact on the articulatory, respiratory, and pronator systems, which eventually impact speech and deglutition [1]. According to the Department of Neurology at Mayo Clinic in the United States, the number of patients recognized with motor speech disorders over 1993-2008 was estimated with average 57 %. Among these group of people, around 20% were recognized with hyperkinetic dysarthria [2]. People with the hyperkinetic dysarthria problem face several difficulties in social and professional interactions. The human-computer interaction (HCI) technique is an approach to develop interactive systems; it generates designs that are userfriendly by focusing on the requirements and needs of the users [3]. Although the recently introduced entirely neural speech recognizers have shown positive performance [4], Hidden Markov Models (HMM) remain the fundamental component of effective speech recognition systems [5]. There are many methods that have been developed for the recognition of speech and other applications, including convolutional neural networks [6], gaussian mixture models [7], and hybrid systems that combine artificial neural networks with HMMs [8]. However, there has been very little research on people with hyperkinetic dysarthria.
Motivated by the considerable advancement obtained through neural networks in the field of natural language processing (NLP) [9], the implementation of combined neural networks for the hyperkinetic dysarthria speech recognition has become an attractive area [10]. According to the outcomes of previous investigations, the application of neural networks has not only decreased the necessity for speech preprocessing but also increased the accuracy of recognition. This research introduces a novel methodology for evaluating hyperkinetic dysarthria speech recognition. The neural networks based methodology encounters difficulties in training model due to insufficient speech dataset and defining most effective network model structures. Here is a summary of the major contributions:
-
• To overcome the insufficient disorder speeches, this work proposed a Russian hyperkinetic dysarthria disorder (RHDD) speech dataset, which can improve the neural network based model adaptability and ensure against the overfitting. The initial process refers to the collection of speeches by real hyperkinetic dysarthria disorder patient, which are then put through digital speech processing techniques, including data filtering, down-sampling, and splitting techniques.
-
• In order to enhance the efficiency and maintain numerical stability of feature extraction, this study proposes a convolutional recurrent network (CRN)
model. This model combines a convolutional neural network (CNNs) and a recurrent neural network (RNNs) for the analysis of RHDD speech. This model includes several modifications, including adjustments to the kernel size, several 2D convolution and linear blocks, and integrating an extra recurrent neural network block.
The findings of the experiment illustrate that the proposed CRN model performed better than the other baseline models, with a CER score of 14.76%. The recognition rate increases with using a dataset of 2000 RHDD speeches, which presents more effective generalization and robustness. The rest of the manuscript is divided into several sections. Initially, it introduces the related work. Afterwards, the methods employed are briefly described. The next section presented the results and discussion. The manuscript concludes with a summary of our research and a projection of future endeavors.
1. Related works
The evaluation of speech disorders has garnered significant focus from researchers because for the abilities to enhance the quality of life for people with disabilities. Consequently, multiple automatic speech recognition systems have been explored to minimize speech disorder problems using publicly available databases [11– 13]. Takashima et al. [14] proposed a convolutional neural network-based feature extraction to deal with the small local fluctuations of the speech uttered by a person with an articulation disorder. They evaluated on a word recognition task for one male with recorded 216 words included in the ATR Japanese speech database. The convolutional restricted Boltzmann machine parameters were obtained from training data and used as the initial value for the convolution layer for the convolutive bottleneck networks, achieving a maximum recognition accuracy of 86.11 %.
Muhammad et al. [19] utilized the conventional characteristics and categorization of automatic speech recognition approach in order to recognize the speech of patients who were suffering from voice disorder. The research investigated samples of Arabic speech from 62 patients with dysphonia and six vocal abnormalities, along with 50 participants who were considered as normal. The Arabic digits that were pronounced by normal people were recognized with a recognition accuracy of 100 percent. The authors [20] highlight the efficacy of multiple supervised learning techniques and an evaluation of performance has been conducted between end-to-end systems and hybrid systems utilizing deep neural network-hidden markov model (DNN-HMM).
The studies mentioned above highlight the extensive application of neural networks in the field of speech recognition, generating advantageous results. However, it is important to note that those studies mainly utilize CNN based models for the purpose of speech recognition, without introducing any additional improvements. In this study, we present a CRN model to recognition RHDD speech using CNNs and RNNs model to enhance the feature extraction. Additionally, this model is specifically engineered to handle audio data in real-time.
2. Methodology
The suggested procedure refers to the utilization of hyperkinetic dysarthria speech recognition technology for converting speech to text. The input contains mainly audio speeches, which are subsequently converted into MFCC coefficients. These are then fed into the CRN model in order to generate text. The generated text is after that transmitted to the telegram bot.
-
2.1. Dataset
The accessibility of datasets for Russian disordered speech is extremely limited. The dataset used in this study was collected at Ural Federal University, Russian Federation as part of a larger investigation into dysarthric Russian speech. The proposed dataset consists of 2000 RHDD sentences with a sampling rate of 48 kHz [21]. The audio samples have been collected from a person with dysarthria named Boris Andreevich Bredikhin, who is 24 years old and male. He has symptoms of a certain type of dysarthria called hypokinetic. During the data acquisition process, dysarthric patients were asked to read 2000 short Russian sentences. The defect speeches were recorded using a Realme C2 mobile with a 4× Cortex-A53 1.8 GHz processor and 4GB of RAM. Table 1 provides a brief description of the speech recording parameters used in this experiment.
2.2. Dataset Filtering and Down-sampling
The proposed HyperDysarthria-RusSpeechData dataset strength lies in its specificity and quality. It contains 2000 sentences from a single patient with hypokinetic dysarthria, providing rich, specific data. The recordings are high-quality, ensuring reliable research. On the other hand, the current EasyCall Corpus dataset [22] does not mention the dysarthria subtype and has noise due to different recording conditions.
Tab. 1. Recording speech parameters
|
Parameters |
Values |
|
Recording format |
wav |
|
Duration of recordings |
1.25 –12 seconds |
|
Recording frequency |
48000 Hz |
|
Bitrate |
128 kbps |
|
Channels |
2 |
The audio speech dataset goes through data filtering method to eliminate noise caused by different ambient conditions throughout the recording process.
Noisy Defect Speech ——————— Clean Speech . (1)
The signal is down-sampling to a sampling rate of 24000 Hz and filtered using a Band-pass filter with a frequency range of 20 to 2000 Hz.
Original 48ooo Hz — D wn sa mplmg > Compressed 24,000 Hz , (2)
where, original frequency is 48000 Hz, and the compressed frequency is 24000 Hz. This shows the compressed audio after the sampling rate has been decreased in by half.
-
2.3. Dataset Splitting
It essential to split the dataset into testing and training sets in order to minimize the overfitting. The dataset has been split using the most efficient K-Fold Cross Validation (k-FCV) technique [23]. The data has been divided into k-fold subsets, where one subset is identified as the test set and the remaining subsets are utilized for training. The training and testing subsections are allocated 85 % and 15 % of the total data, respectively. After splitting the dataset, there are 1700 samples in the training set and 300 samples in the testing set.
-
2.4. MFCC coefficients
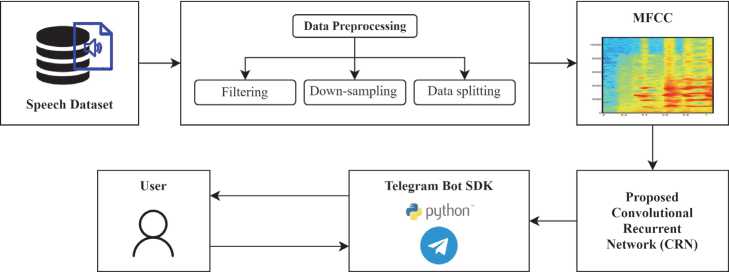
Fig. 1. Block diagram of speech recognition based hyperkinetic dysarthria speeches
The MFCC are a commonly employed technique in speech recognition [24], specifically targeting features such as the frequency spectrum for the vocal tract. The features collected from the MFCC coefficients are provided to the proposed model instead of the raw signal directly. The MFCC extraction processes includes window function, Fourier transform, Mel filter, logarithm, and discrete cosine transform. The following is the sequential procedure for converting MFCC coefficients:
-
• The use of the hamming window function smoothly minimizes spectral leakage, while each audio observe frame is 40 milliseconds in duration.
W[n] = 0.54-0.46cos(2nn / N-1); 0 < n < N-1, where, N is the length of the window, and n is the sample number.
-
• The frequency spectrum is gathered through the integration of a Fourier transform to each and every frame.
X[k] = £ x[n] x e(-j2*kn/N); 0 < k < N -1, where, x[n] is the nth sample of the signal, N is the total number of samples, and X[k] is the kth sample of the Fourier transform.
-
• The spectrum has been determined from the earlier Fourier transform and transformed to the Mel scale. The mapping has been conducted through triangular overlapping windows.
M (f) = 2595 log 10(1 + f /700), where, f is the frequency in Hz.
-
• A logarithmic scale has been constructed from magnitude numbers that represent the logarithm of a power at each Mel frequency.
-
2.5. Proposed Model
Y = log( X), where, X is the output of the Mel filter.
After that, the discrete cosine transform was implemented to modify the sequence of Mel log powers. The outcome is a set of coefficients known as the MFCC coefficients.
C [ m ] =2 (1/ N ) x Y [ n ] x cos[ n ( m ) (2 n + 1)/2 N ];
0 < m < N -1, where, Y[n] is the nth log Mel power, N is the total number of log Mel powers, and C[m] is the mth MFCC.
An convolutional recurrent network (CRN) model has been proposed for defect speech recognition based on CNNs [25] and RNNs [26]. The proposed model consists of 2D convolution (conv2d), linear, and recurrent blocks.
The 2D convolution and linear layers is employed for image recognition, and recurrent layers are utilized for text prediction. The input MFCC coefficients image size is 32×32×3 pixel, batch size 5 for every epoch and the optimizer used is AdamW [27] with connectionist temporal classification (CTC) loss function [28] for 35 epochs. The optimal rate of learning has been determined with a value of 0.0005.
■Convolutional Recurrent Network (CRN) Model'
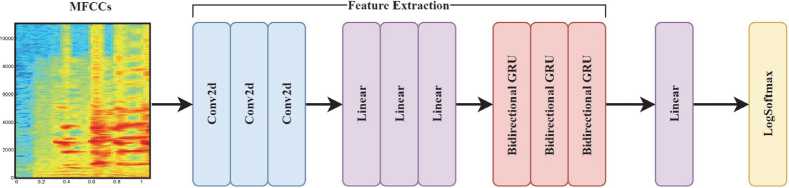
Fig. 2. The structure of proposed CRN model
Initially, a design block called Repealed-CNN is created, which is based on the typical CNN structure. A smaller kernel size leads to faster estimation and training times respectively, resulting in 32 kernels in the first conv2d layer with dimensions of 3×3. This differs from standard CNNs, that typically include a one-dimensional convolutional layer with dimensions of 7×7. The noise is filtered by the second conv2d layer using 64 kernels of dimensions 5×5. The third conv2d layer consists of 32 kernels, each with dimensions of 3×3. Gaussian Error Linear Unit (GELU) activation function has been used to overcome the vanishing gradient problem and BatchNorm2d normalization layer is subsequently implemented with each convolutional layer. This configuration is designed to enhance the network's capability to extract small features and faster estimation. The spectrogram image was then transformed into three linear blocks with LayerNorm and GELU activation function. It is responsible for transforming processed images into a linear structure. In this case, the data involves a transformation from its original lower-level features to a new set of higher-level features, resulting in an improvement in the speech's quality.
Following the development of the Repealed-CNN, the Repealed-RNN architecture is constructed. The architectural design encompasses a configuration comprising of three Bidirectional GRU (BiGRU) elements. The BiGRU layer receive a linear data structure as input from last linear layer. It enables the evaluation of linear data structures, which is essential for the recognition of word and letter sequences. According to different audio file lengths, BiGRU layers could improve recognition in situations where context is crucial. The last linear layer receives input from the BiGRU layer that includes the outcome of the processing of the data structures. In order to enhance efficiency and ensure numerical stability, the last layer is built as a LogSoftmax layer.
3. Results and discussion
This section contains the outcomes of the research study conducted based on the proposed methodology. This study is carried out on a personal computer platform (ASUS Vivo Book 15 M513UA, Processor AMD Ryzen 5 5500U with Radeon Graphics 2.10 GHz, Installed RAM 16GB DDR4), The Kaggle platform provides access to 2 types of video cards - NVIDIA TESLA P100 GPU, NVIDIA T4 (×2). The efficiency of the CRN model was evaluated using the character error rate (CER) and word error rate (WER) metrics [29]. As the Russian language is complex and has many suffixes, prefixes, endings, etc., we ignore WER as it evaluates too strictly and considers the whole word wrong for one wrong letter. CER is a more absorbent metric and looks at letters, not words. The levenshtein distance technique [30] was used to determine the incorrect characters and words. The CER and WER metrics equations are:
CER = Wrong Characters/Total Characters , (3)
WER = Wrong Words/Total Words. (4)
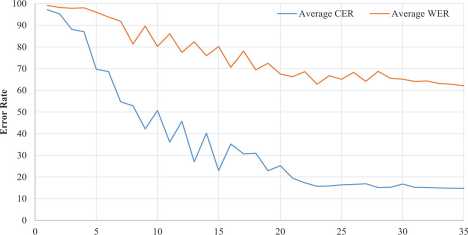
The results highlight that the CER achieves 14.76% while the WER achieves 62.13 %. The CER is stable at approximately 0.15, meaning that nearly 85 % of characters are accurately recognized from speech with defects. Furthermore, it has been noticed that the WER remains constant at approximately 0.62–0.65. This indicates that around 35–38% of words are accurately recognized from speech with defects. Comparatively, the proposed solution outperforms competitors in terms of learning speed and character error rate metrics.
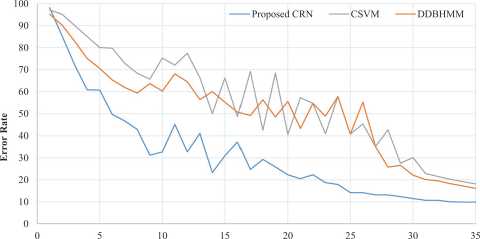
We compared the proposed CRN model performance with CSVM [15], and DDBHMM [18] models using training dataset in terms of train character error rate. We can observe that the CRN model is capable of an accuracy of up to 90.11 % for training, whereas the
CSVM has a maximum accuracy 81.83 % and DDBHMM has maximum accuracy 83.87 %. The error rate in the CSVM and DDBHMM models stopped decreasing by 3 points. The error rate in the proposed model continued decreasing and reached a low point of 9.89. The results show that CRN model does better than the CSVM and DDBHMM model on proposed dataset, when the same training conditions are used.
Tab. 2. Proposed CRN model configuration, Number of epochs: 35; Batch size: 5; learning rate = 0.0005; loss functions: CTC; optimizer: AdamW
|
Model Configuration |
|||||
|
Layer |
Kernel Size |
Input Neuron |
Output Neuron |
Stride |
Padding |
|
Convolutional Blocks |
|||||
|
Conv2d |
(4, 4) |
1 |
32 |
(3, 3) |
(2, 2) |
|
BatchNorm2d |
- |
32 |
32 |
- |
- |
|
GELU |
- |
- |
- |
- |
- |
|
Conv2d |
(3, 3) |
32 |
64 |
(1, 1) |
(1, 1) |
|
BatchNorm2d |
- |
64 |
64 |
- |
- |
|
GELU |
- |
- |
- |
- |
- |
|
Conv2d |
(3, 3) |
64 |
32 |
(1, 1) |
(1, 1) |
|
BatchNorm2d |
- |
32 |
32 |
- |
- |
|
GELU |
- |
- |
- |
- |
- |
|
Linear Blocks |
|||||
|
Linear |
- |
224 |
270 |
- |
- |
|
LayerNorm |
270 |
270 |
- |
- |
|
|
GELU |
- |
- |
- |
- |
- |
|
Linear |
- |
270 |
270 |
- |
- |
|
LayerNorm |
- |
270 |
270 |
- |
- |
|
GELU |
- |
- |
- |
- |
- |
|
Linear |
- |
270 |
270 |
- |
- |
|
Recurrent Blocks |
|||||
|
Bidirectional GRU |
- |
270 |
270 |
- |
- |
|
Bidirectional GRU |
- |
540 |
270 |
- |
- |
|
Bidirectional GRU |
- |
540 |
270 |
- |
- |
|
Linear |
- |
540 |
34 |
- |
- |
|
LogSoftmax |
- |
- |
- |
- |
- |
Epoch
Fig. 3. Error Rate (CER and WER) comparison curves for test dataset using proposed CRN model
A telegram bot has been developed to implement the proposed CRN model, that utilizes the model we have trained to assist people with hyperkinetic dysarthria speech impairment. The first part of this diagram illustrates the interface created using an input. Another part of the diagram displays the outcomes recognized by the proposed model. The function enables the reception of voice messages, which are then converted into text using a trained CRN model, and subsequently output a response message. We have developed a fundamental feature that allows users to listen to their message and respond accordingly.
Epoch
Fig. 4. CER Error on train dataset using existing CSVM, and DDBHMM model with proposed CRN model
Tab. 3. Comparison between proposed CRN model and existing CSVM and DDBHMM model based on character error rate using train dataset
|
Models |
CER |
|
Proposed CRN model |
9.89% |
|
CSVM |
18.17% |
|
DDBHMM |
16.13% |
Conclusion
The main objectives of this research work were to find out the solutions for voice conversion with speech defects. A comprehensive dataset consisting of 2000 RHDD speeches has been suggested to ensure an adequate quantity of defected speech. Furthermore, a CRN model was developed based on CNNs and RNNs. The obtained findings are considered satisfactory, as the proposed model exhibits a higher overall testing CER metric is 14.76 % compared to other models. Also, a voice assistant in the form of a telegram bot has been develop using proposed model that can help people.
The suggested approach could be utilized as a classroom assistance that provides speech-to-text features to assist students with hyperkinetic dysarthria. This would enable them to actively participate in discussions and successfully perform their assigned responsibilities. Another possible use could be in the healthcare sector, specifically in speech therapy treatments. It can be utilized to enhance the pronunciation and intelligibility of people with speech disorders. Adding more hyperkinetic dysarthria speeches from different person to the existing dataset is one way to further developing our research. Additionally, we can expand proposed dataset to include other speech disorders in order to build better models for the future. Additionally, the combination of a predictive typing system into an existing application can enhance the accuracy of transforming entire messages, compared to individual characters.
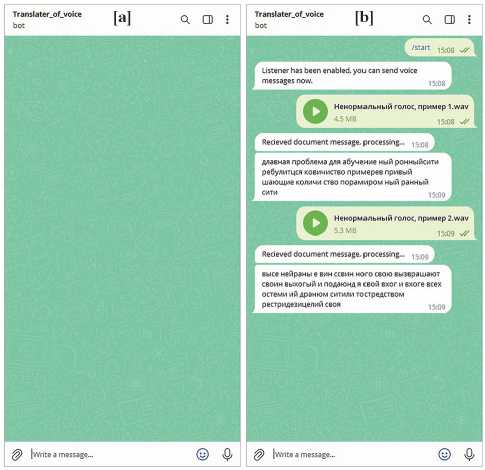
Fig. 5. Screenshot of developed Telegram bot: (a) interface; (b) recognized result
