Mathematical Modeling and Analysis of Network Service Failure in DataCentre

Author: Malik UsmanDilawar, FaizaAyub Syed
Journal: International Journal of Modern Education and Computer Science (IJMECS) @ijmecs
Article in issue: 6 vol.6, 2014.
Free access
Malik UsmanDilawar, FaizaAyub Syed
Cloud Computing, Data Centre, Downtime, Poisson Process, Poisson distribution, Network Service Failure, Fault Prediction
Short address: https://sciup.org/15014660
IDR: 15014660
Text of the scientific article Mathematical Modeling and Analysis of Network Service Failure in DataCentre
Information Technology (IT), as a scientific innovation has changed the lifestyle of people in today’s world. A drastic change in technology appeared with the emergence of cloud computing [1]. Due to its high availability and on-demand services cloud computing has become very popular[2]. Many multinational companies have deployed their cloud based data centres at regional or global level depending upon the services provided by them [3, 4, 5]. According to US environment protection agency (EPA), for many government sectors like business, communications and education data centres have become a necessity now [6]. Flexibility, productivity, cost effectiveness and reliability are few other benefits of the cloud computing technology. The main idea of cloud is to combine a large number of hardware and software resources in a single unit called a data centre. Basic functions of any datacentre are to generate, gather, accumulate and impart data as per requirements and design. Itcontainsnumber of hi specs computing devices,interconnected to provide specific services to customers [2]. Effective tools and methods like load balancing and failover clustering are done to ensure availability of system to users.
Since, life has become very fast nowadays and the expectations of system availability have taken new forms. People demand all time availability ofservices [6]for their comfort, control and cost savings. Organizations have invested millions of dollars for deployment of thousands of servers on the basis of cloud technology to facilitate them.Owners of data centres pay full attention to any hindrances in provisioning of services to their customers. Non availability of a system is calculated in terms of money by owners whereas from user point of view timely availability of service is a priority [7]. Service providers face serious challenges in operating the system smoothly and keeping services available to users like quality, redundancy, security and confidence [8]. They make special arrangements for deployment of data centre hardware and its maintenance. Expert human resources are employed for its administration.But at the same time,servicedelivery may become susceptible to different type of failuresdue to intensive work load and other technical issues [9, 10]. Hardware and software faults, configuration issues and network problems are some major causes of system breakdown.Hence as a whole, managing and administering a data centre is really a demanding job [6]. And without proper design and planning, data centre can raise the cost of service provisioning for any organization [3].Moreover,there are very few studies thatfocus on the practical issues and problems of data centres,generating lot of opportunities to explore in this field due to its demand in market [2, 11]. This research is based on the analysis of practical network faults that appear in a conventional data centre. The fault trend rate of network failure, assumed as a Poisson Process, is made.
Poisson process and how it is applied to a specific event is discussed. It also covers why we have used this technique. Section IV is literature review. Section Vcontains a case study of conventional data centre and the number of network components involved. It also contains a fault trend analysis graph in which the events are modelled as per Poisson distribution. Section VI is conclusion.
-
II. Datacentre
Data centre is an entity that houses thousands of machines and various types of computer hardware. Beside them, there are number of important components kept in mind while deploying a data centre. Brief description about them is as following:
-
A. Infrastructure
To deploy a data centre, first of all, a suitable site is selected, keeping in mind its geostrategic location and business point of views. The building of data centre has to have multiple rooms, most important of which is equipment room. It is the room where all IT devices are located. The environment in this room is kept highly controlled. Arrangements are made to ensure uninterrupted power supply to this room. Mostly stand by generators and UPSs are placed to avoid uninterrupted shutting down of data centre. Special cooling arrangements are made inside the room, to control the heat dissipated by the hardware and keep the temperature at a desired level [12]. Most of the time in row cooling is used for the purpose.Humidity,dust and fire suppression are other factors that also play important role in controlled environment [13]. Special built racks are placed inside the equipment room for mounting the hardware devices
-
B. Network
Network design and configuration plays very important role in functioning of any data centre. Normally mix of network technologies are used in data centres [14]. Traditional data centre network consists of multiple routers, firewalls and switches in a properly designed hierarchy [12]. Routing,load balancing, traffic aggregation and network policies are well planned to meet the service requirements. As network cabling plays a key role in connectivity, special trays are placed in equipment room to house the network cables.
-
C. Servers
Normally two types of physical server are used in data centres. Rack mounted servers, which can be easily mounted in the racks by just sliding on the rails and blade servers which require special built casing to mount in. But at the same time, rack mountedservers require more space and other arrangements as compared to the blade servers.The software used, architecture of the application and operating systems are other major factors that play important role in selection of the type of server.
-
D. Storageand Database
The most critical thing in any data centre is its storage and database. It not only stores all the data but also need attention as the applications, used by customers, access them very frequently. Hence they play crucial role in performance and operations of any data centre.Specially built hardware is installed in data centre for both storage and data base services.For storage, generally storage area network (SAN) or network area storage (NAS) is used. Both of them provide hi speed communication through fibre cabling.
-
E. Call centre
Having made all the arrangementsmentioned above, the IT equipment and services still demand commitment and routine maintenance. Various problems and issues keep emerging on daily basis in data centres.To answer the complaints of users, call centres are established.Separate human resources are nominated which remain available in data centre to record and resolve the routine issues. The human resource management in a data centre revolves around the timely action on user complaints. Hence,software up gradation, routine maintenance and other technical matters of IT equipment installed in data centre play vital role in personal administration of data centre employees as well as customer satisfaction.
The advancements in IT have led to serious challenges in management of routine dealings in private and public sector. New innovative applications of IT have not only influenced social culture of community but also their performance [15]. People demand 24/7 availability of services in a professional way. Hence to meet the public demands, organizations have also modified their traditional ways of completing a task from manual working to online systems. A variety of systems are employed into organization’s business and communication functions [16]. They help organizations in storing large amount of data, increase computation and as a whole maximize the profit of organizations. Such systems are arranged in a way that they provide useful information for decision making and control over certain operations of the organization.
Most of companies have already invested a lot in IT sector by providing online services to customers. On the other hand people also demand online delivery of most of the facilities [17]. Since millions of dollars have been spent on thousands of machines in data centres [3], so service providers put in their best to keep down time of data centres to minimum low and provision of services to customers at maximum time. But risk management studies and research is low in this sector [11]. Hence despite offering flexibility and efficiency, data centres also trigger certain degree of loss exposure to the organizations e-g there was an incident where failure of a core switch created lot of inconvenience for millions of users for quite a long time [12]. Moreover the data centres are selected as per its uptime, availability, serviceability and response time [9]. Despite all the efforts loss of connectivity or interruption in services still happen as daily life problems thus making it really a challenging job for service providers as well as for customers [9, 10].
-
III. Poisson Process Approach
One of the topics of interest that become known in previous years is data centre networking. There is not much research work on the extent, depiction and analysis of data centre traffic. A continuous time probabilistic process that is applied to such problems for estimating future values as well as their failure rate are Poisson Process. [18] Named after its discoverer, French mathematician Simon Denis Poisson [19], at times Poisson distribution is also used as a building block for complicated problems [18]. The classic example in this regard is the chances of cavalryman killed by the kick of horse by von Bortkiewicz in 1898 [19]. In general,
characterization of a Poisson Process follows independent increase in occurrence of an event where intensity of the process can be calculated.
-
A. Poisson Process
A process can be modelled as a Poisson process if it satisfies following conditions [19]:
-
• The process Q(t) is collection of events that are countable.
-
• The occurrence of events is independent among themselves.
-
• For the specified time period, the average frequency λ of occurrence is known.
-
• Events occurred are countable in numbers.
-
B. Poisson Distribution
The distribution of a Poisson Process, is such that event occurrence Q(t) in a given finite interval of time t, is as following [20]:
Р {Q (О-к)-^^t !
where, t — i2 — ii and е = 2.71828 (Euler’s Number)
It is important to notice here, that numbers of events occurrence i-e Q (i ^ i2) and Q (i3, i4) in non-overlapping intervals ti< t2< t3< i4 are independent.
Different conventions are used by mathematicians to denote the Poisson Process. In this paper mathematically the process is described by [20]:
Q (t) = Occurrence of event in time interval (0, t)
Q ( i,.> t2) = Occurrence of event in time interval (i ^ i2)
-
C. Types of Poisson Process
No Homogeneous Poisson Process is the one, in which the intensity factor λ is not dependent on time. Its distribution is derived as [21]:
P{(Q^) — Q(tJ) = к) = (Я(t2 —, ^ e-я(£2-£ 1)
Substitutingi2 — i 1; the equation takes the form:
(A(t)) k
p{(QG)) = к}-^Ге-я'
Whereas in a Non Homogeneous Poisson Process the rate parameter Л changes with time. Hence the relation of distribution becomes [21]:
p{(Q(t2) — Q(ti)) - к) - (Жк,i2)) е-я(£1 ,£2)
Where, t2
(^£i,£2) - J ЯСО dT
-
D. Reasons for Using Poisson Approach
Different approaches are being used to describe probabilistic events that occur in our daily life. Main classes of models used are Auto regressive Process, Markov Process, Moving Average Process, Poisson Process and Gaussian Process. The modelling used in our case was based upon the Poisson Process mainly because [22]:
-
• The event of disruption, in provision of series to users is a regular process.
-
• Mostly, failure in provisioning of service to a certain user does not affect other user. This implies that occurrence of event at one particular time is independent of the same event in any other particular time.
-
• The process occurrence is a memory less process. Prediction of event occurrence in future can't be made from information currently available.
-
E. Other Applications Using Poisson Approach
Following are few other processes normally modelled on Poisson distribution [21]:
-
• Number of queries received at a web server.
-
• Number of vehicles passing through a barrier on road.
-
• Calls coming at telephone exchange.
-
IV. Related Work
Zhang, Cheng and Boutaba [2] discussed the architecture of a state of the art data centre where thousands of servers have been deployed to provide online services to users. They gave a detailed view of characteristics of cloud technology, there benefits and future challenges. At the end they conclude that cloud technology is not used to its full extent and a lot more can be done in this field especially regarding features like automatic resource scheduling and power management.
-
A. Zia and M. Khan [4] analyses the cloud technology provided by different vendors in the market. They suggest that quality of services (QoS) provided by current technology is not enough to meet the customer service requirements. They propose a framework to improve response time in the cloud which further has positive effects on over all provisioning of service to the clients.
Selvi andnishanthi [21] analyse the performance of a call centre by applying queuing theory in mathematical form. The highlight problems faced by both caller and call centre staff. Some of the major problems include excess amount of waiting time for connecting to operator, complaints not properly managed on time, broken communication, underprivileged working state, bogus maintenance and faults due to noise interruption. Since, all these jobs are handled in the form of queues; occurrence of requests at same time overloads the system thus, lowering the working state of call centre. All these faults are analysed using mathematical process. The incoming jobs at queue are assumed as a poison process. The results of analysis indicate that average waiting time between requests should be incremented to avoid the call centre from getting off net.
Abts and Felderman [23] discuss their views about data centre networking. A modern data centre homes tens and thousands of servers each consisting of more than one processors, high capacity memory, fast input output devices. Computing resources are grouped into racks and are in the form of distributed clusters. The traffic within a data centre network flows in the form of packet chunks. Sometimes congestion appears in the network due to overloading. The possibility of congestion can be reduced by overprovisioning the network with sufficient bandwidth. However, providing bandwidth to large scale networks is costly.
Kandula and Greenberg [24] investigate the network traffic temperament for observing various attributes like workflow duration, request arrival time, continuous congestion and workload conditions and patterns.Ersoz and Yousif [25] analyse the characteristics of network performance in a data centre that hosts multiple layers with a clustered network environment. The main focus is on the distribution of queries that arrive and served at individual server, traffic on the network and the size of packets sent among network nodes.
Guan, Zhang and Fu [26] suggest a mechanism for fault detection and prediction. This mechanism makes use a collection of Bayesian models for failure prediction in data centres. The system distinguishes between the normal and anomalous behaviours. The system collects the information and data performance probability distribution is estimated at runtime. A probabilistic model is constructed using group of Bayes model. Decision trees for fault prediction are maintained. The likelihood appearance of faults is maintained using these decision trees. This mechanism helps in boosting the performance level and management of data centre.
-
D. Singh, J. Singh and A. Chhabra[27] high lights that failover approach in critical in provisioning of cloud services to users. Different check points and feedback parameters can be applied to avoid failure of noes in a data centre. They proposed a failover strategy taking support of check points at multi levels and load balancing technique. A. Zia and M. Khan [8] make a detailed comparison of different schemes to improve QoS in the cloud technology. They critically analysed performance parameters at infrastructure, platform and software as service layers.
Yu et al. [28] states that network and application problems are different to identify in multi-tier environment. They analyse that a small network problem at times take very long time to even get identified after collecting and analysing detailed logs. They suggest scalable network application profiler (SNAP) that continuously collects TCP statistics, socket logs and at the end help administrators in narrowing down the problem.
-
V. Analysis Of Network Servicefailurein Datacentre
A conventional data centre was analysed that hosts multiple network services to 5400 customers. The no of workstations used by customers are 3500 where few customers use the system turn wise. The no of servers installed to host all applications are 150 and total storage being used is 10 TB. Peak working hours are from 8 AM to 4 PM but system remains under use for 24 hours. Mainly there are 150 Edge Switches, 15 Switches at Access Layer and 4 Switches at Core Layer. Beside this, at each network layer mentioned above, firewalls are installed to ensure security.
-
A. Basic Distribution of Network Layers
The distribution of network components involved in any data centre belongs to one of the following classes [28]:
-
• Edge Network: It is the component placed at the user end. Normally the end system used by user is directly connected to this component.
-
• Access Network: Access network mainly
interconnects different routers in a network. The link that connects end system to the first router in any network is also part of access network.
-
• Aggregate Network: Aggregate network consists of devices that connect access routers and switches. Policies are applied at this layer to aggregate and control the traffic.
-
• Core Network: Core network mainly consists of the main backbone of any network that provides IT services to customers.
The network devices used in any IT environment are well planned according to proper design and documentation. Normally network layers discussed above are exist in a hierarchical order [5] as shown in following Figure1.
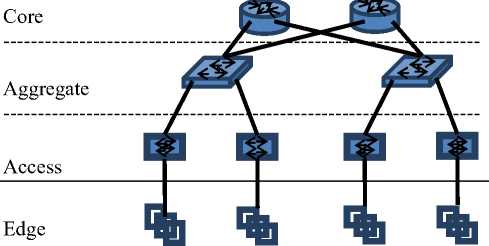
Fig 1. Basic Data centre Network Topology
-
B. Fault Trend Analysis
Average network complaints received at data centre for four months were observed to be 48 complaints per day which implies that there are 2 complaints after each hour. Graphical view of the number of complaints for last four months is as shown in Figure2.
-
C. Major Factors Contributing to Failure
The main factors that contributed to the failure of network components were:
-
• Traffic congestion
-
• Loop creation in network traffic flow
-
• Power failure
-
• Heating up
-
• Resource exhaustion
-
• Hardware failure
-
• Human error
-
• Configuration issues
-
• Incompatible components
-
• Loose connections
-
• Maintenance issues
-
D. Calculations
The recorded data was modelled as per Poisson distribution and future number of complaints was calculated. 90% prediction was observed to be accurate. The values of the probabilities, calculated by using Poisson distribution for different values of k≤4, with λ=2 are:
-
• For k=0, P(0)= 0.3153
-
• For k=1, P(1)= 0.2707
-
• For k=2, P(2)= 0.2707
-
• For k=3, P(3)= 0.1804
Hence, we can conclude that:
-
• Probability for value of k≤2 = Sum of all
probabilities for k≤2 = 0.6767
-
• Probability for value of k≤3 = Sum of all
probabilities for k≤3 = 0.8571
-
E. Results
Focusing on the results obtained, following different administrative tasks of data centre can be planned:
-
• Downtime of data centre
-
• Upgradation of application version
-
• Firmware upgradation
-
• Hardware replacement at certain location
-
• Working hours of data centre employees
-
• Routine Maintenance
-
• Customer satisfaction
100 90 80 70 60
• No of 50
Complaints 40 30 20 10 0
No of Complaints
1/Mar/13
1/Apr/13
1/May/13
1/Jun/13
1/Jul/13
Fig 2. Number of Network Complaints for Last Four Months
-
VI. Conclusion
Technology has always remained a prime source of human development. New discoveries and inventions not only help the society in daily life but also make the IT environment challenging. Cloud computing has revolutionised today’s world by offering benefits like scalability and productivity. Organizations are spending a lot in IT sector by offering online services to their customers. It has made people’s life more comfortable on one hand, while on the other it is also bringing more profit for the service providers. But at the same time, vulnerability to failure in provision of services can also bring huge loss for any organization. Keeping in mind, the significance of mathematical modelling and there results, number of approaches can be used for future predictions in such scenarios. They can help in calculating probabilities of failures as per the services and IT equipment used in different environments. We have used Poisson process to model the network service failure in a data centre. The results show that such approaches can be successfully applied to estimate the future failure rate.
References Mathematical Modeling and Analysis of Network Service Failure in DataCentre
- IlangoSriram and Ali Khajeh-Hosseini, "Research Agenda in Cloud Technologies", ACM Symposium on Cloud Computing, SOCC, 2010.
- Q. Zhang, L. Cheng, R. Boutaba, "Cloud computing: state-of-the-art and research challenges",Journal of Internet ServAppl, The Brazilian Computer Society, 2010, doi: 10.1007/s13174-010-0007-6.
- A. Greenberg, J. Hamilton, D. Maltz, P. Patel, "The Cost of a Cloud: Research Problems in Data Centre Netwroks", Microsoft Research, Redmond, WA, USA, editorial note submitted to CCR..
- A. Zia, M. Khan, "A Scheme to Reduce Response Time in Cloud Computing Environment", International Journal of Modern Education and Computer Science, Modern Education and Computer Science Press, 2013, doi: 10.5815/ijmecs.2013.06.08.
- T. Benson, A. Akella, D. Maltz, "Network Traffic Characteristics of Data Centres in the Wild", University of Wisconsin-Madison, Microsoft Research-Redmond.
- D. Veal, G. Kohli, "Some Problems in Network and Data Centre Management", Edith Cowan University, Perth, Western Australia.
- Judith Hurwitz, Robin Bloor, Marcia Kaufman, and Fern Halper, "Comparing Traditional Data Centre and Cloud Data Centre Operating Costs", http://www.dummies.com/how-to/content/comparing-traditional-data-centre-and-cloud-data-c.html.
- A. Zia, M. Khan, "Identifying Key Challenges in Performance Issues in Cloud Computing", International Journal of Modern Education and Computer Science, Modern Education and Computer Science Press, 2012, doi: 10.5815/ijmecs.2012.10.08.
- K. Choo, "Cloud Computing: Challenges and future directions", Trends & Issues in crime and criminal justice, Australian institute of Criminology, 2010.
- "Strategy Guide to Business Risk Mitigation for Financial Services", HP Tech Dossier.
- C. Fan, C. Chiang, T. Kao, "Risk Management Strategies for the Use of Cloud Computing ", International Journal of Computer Network and Information Security, Modern Education and Computer Science Press, 2012, doi: 10.5815/ijcnis.2012.12.05.
- J.Salo, "Data Centre Network Architectures", Seminar on Internetworking, 2012.
- "Data Centre Management", A newsletter for IT Professionals, Joint Universities Computer Centre Limited
- "IT Manager Survey on Networking and Storage for the Next-Generation Cloud", Cloud Computing Research for IT Strategic Planning, Intel Corporation, 2012.
- Javadi, M & Safari, H 2013, 'Assessing Office Automation Effect on Performance Using Balanced Scorecard approach Case Study: Esfahan Education Organizations and Schools', International Journal of Academic Research in Business and Social Sciences, vol. 3, no. 9.
- Jatain, R 2013, 'Different prospects of Office Automation Systems', International Journal of Computer Trends and Technology, vol. 4.
- "Unified Data Centre-Efficiency and Flexibility to Improve Business Agility", Cisco White Paper, 2012.
- K. S. Shanmugan and A. M. Breipohl, "Random Signals: Detection, Estimation and Data Analysis", John Wiley and sons, Inc, ISBN: 978-0-471-81555-6, July 1988.
- E. B. Brooks, "The Poisson Distribution", E Bruce Brooks, http://www.umass.edu/wsp/statistics/lessons/poisson/, 22 Sep 2005.
- J. Virtamo, Queueing Theory, http://www.netlab.hut.fi/opetus/s383143/kalvot/english.shtml, 2005.
- V.S. Selvi& M. Nishanthi, Mathematical Applications of Queueing Theory in Call Centres, International Journal of Scientific and Engineering Research, Volume 3, Issue 11, November -2012.
- Prof. Dr. R.W.J. Meester,VrijeUniversiteit Amsterdam, The Netherlands, "The Poisson `Process".Bowman, M., Debray, S. K., and Peterson, L. L. 1993. Reasoning about naming systems.
- D.Abts and B.Felderman, "A Guided Tour through Data-centre Networking" ACM Digital Library, May 3, 2012.
- S.Kandula, S.Sengupta, A. Greenberg, P. Patel, Ronnie Chaiken, "The Nature of Datacenter Traf?c: Measurements & Analysis", ACM Digital Library, 2009.
- D.Ersoz, M. S. Yousif and C. R. Das, "Characterizing Network Traf?c in a Cluster-based, Multi-tier Data Centre", in proceedings of 27th International Conference on Distributed Computing Systems (ICDCS'07), IEEE, 2007.
- Q. Guan, Z. Zhang, and S. Fu, "A Failure Detection and Prediction Mechanism for Enhancing Dependability of Data Centres", International Journal of Computer Theory and Engineering, Vol. 4, No.5, October 2012.
- D. Singh, J. Singh, A. Chhabra, "Failures in Cloud Computing Data Centres in 3-tier Cloud Architecture", International Journal of Information Engineering and Electronic Business, Modern Education and Computer Science Press, 2012, doi: 10.5815/ijieeb.2012.03.01.
- M. Yu, A. Greenberg, D. Maltz, J. Rexford, L. Yuan, S. Kandula, C. Kim, "Profiling Network Performance for Multi-Tier Data Centre Application", Princeton University, Microsoft.
- J. F. Kurose and K. W. Ross, "Computer Networking, A Top Down Approach", Addison-Wesley Publishing Company, USA, 5th edition, 2009.
- M. Vouk, "Cloud Computing- Issues, Research and Implementations", Journal of Computing and Information Technology, 2008.
