Mechanism and Algorithm for Indirect Schema Mapping Composition

Author: Bo Wang, Bo Guo
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 1 vol.1, 2009.
Free access
There are a large number of indirect schema mappings between peers in the network. To improve the efficiency of data exchange and queries, indirect mappings are needed to be composed. Direct mappings can be derived directly by the constraints defined between schemas, but not for indirect mappings’ composition. Defined the combination operations of schema elements in indirect mappings, and gave the expression of indirect mappings. Analyzed the composition of indirect mappings, and proposed a strategy, named schema element back, to solve the problem of indirect mapping composition, and gave the indirect mapping composition generation algorithm based on such strategy. Experiments showed that indirect mapping composition can improve the efficiency of data exchange, and compared with other non-full mapping composition generation algorithms, and indirect mapping composition generated by our algorithm based on schema element back strategy can completely eliminate the infection of media schema with no reduction of the composition efficiency.
Indirect mapping composition, combination operation, schema element back
Short address: https://sciup.org/15011960
IDR: 15011960
Text of the scientific article Mechanism and Algorithm for Indirect Schema Mapping Composition
Published Online October 2009 in MECS
Many data management tasks, such as data translation, information integration, and database design require manipulation of database schemas and mappings between them[1]. Schema mappings define the relationship between instances of two given schemas which can be divided into direct and indirect ones by the relationships of elements. Indirect mappings are widely existed, especially when schemas evolve, most mappings that used to be direct become indirect. In indirect mappings, elements between schemas are not directly associated, but related by some algebra operations.
Mapping composition refers to combining two mappings into a single one, which is useful for a variety of data management problems. Figure 1 shows a topology of a data sharing network, each node can be a data sources, an integrated data center or a logical mediator. When data are exchanged from node E to the integrated schema G, instances of E should be translated to G by mapping sequences: E — C, C — A and A — G, and chaining mappings at run-time may be expensive because we may need to follow long and possibly redundant paths in the network. Note that different paths between a pair of nodes may yield different sets of query answers. To ensure the reliability of data exchange, we usually need to get all of the possible paths, and execute each possible data transplantation process according to the paths. Cost of performing such work will be quite large when there are a large amount of data sources. If certain nodes leave the network, then we may lose the mapping paths. Addressing these issues raises several static analysis questions regarding the network of mappings, and mapping composition lies at the core of them all. By precomposing a select set of mapping chains in the network, we can directly execute the data exchange between the source schema and the target schema, which leads to significant run-time savings. Moreover, mapping composition arises in many practical settings like data integration, schema evolution and database designing:
In data integration, a query needs to be composed with a view definition. If the view definition is expressed using global-as-view (GAV), then this is an example of composing two functional mappings: a view definition that maps a database to a view, and a query that maps a view to a query result.
In schema evolution, a schema evolves to a new one, and the relationships between the two schemas may be described by a mapping. The original mappings on the old schema can be updated by mapping composition.
In a database design process, schema may evolve frequently via a sequence of incremental modifications. This produces a sequence of mappings between successive versions of the schema until the desired schema is reached, so a mapping from the original schema to the final one is needed, which can be obtained by composing the mappings between the successive versions of the schema. With this mapping, the designer can migrate data from the old schema to the new schema.
Manuscript received Febuary 11, 2009; revised June 21, 2009; accepted July 21, 2009.
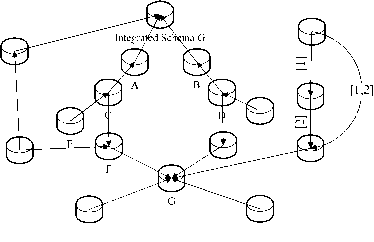
Figure 1. The topology of a data sharing network.
Another motivation for mapping composition comes from the framework of model management[2]. One of the basic operators in model-management algebra is composition, and mappings are treated mostly as syntactic objects. Mapping management can be achieved by defining the composition and inverse operations.
Query composition is widely supported by most of the commercial data management tools, while the mapping composition is still rest on researches and experiments. If the mappings are functional, we can do the composition similarly as the query composition. However, there are a large number of non-functional mappings, most of which are indirect mappings, and we can not directly give the composition. Different from the query composition, indirect mappings can not be composed directly.
In this paper, we mainly discus the composition problems of indirect mappings, and the rest of the paper is organized as follows. In section 2, we show the related works on mapping composition. In section 3 we introduce some concepts of mapping composition. In section 4 and 5, we firstly define the indirect mappings composition, and then propose an indirect mapping composition algorithm. Section 4 presents the experimental results. And the last part is the conclusion.
II.Related works
Mapping composition is a challenging problem[3] whose difficulty is quite sensitive to the expressiveness of the allowed mappings, and there are several researches on such problem [4, 5, 6, 7, 8], including methods based on tuple generation constraints and schema transformation[9, 10, 6], etc. Those mapping composition methods based on schema transformation define complicated schema transformation operations, which only support the computing of direct mappings, and not for those indirect ones with complex algebra operations between schema elements. Model management is a generic approach to solving problems of data programmability where precisely engineered mappings are required[2]. A model management system supports the creation, compilation, reuse, evolution, and execution of mappings between schemas represented in a wide range of meta-models, where the composition operation is one of the ways to realize mapping reusing.
Researches on indirect mappings mostly consider the definitions and basic operations of non-direct element-to- element mappings between the source and target schemas[11] without any further discussions about composition. Madhavan and Haleby[5] showed that the composition of two given mappings expressed as GLAV formulas may not be expressible in a finite set of first-order constraints. Fagin et al[4]. proved that the composition of certain kinds of first-order mappings may not be expressible in any first-order mappings, even by an infinite set of constraints, because the mapping language is not closed under composition. Nash et al[8]. showed that for certain classes of first-order languages, it is undecidable to determine whether there is a finite set of constraints in the same language that represents the composition of two given mappings. In [4], Fagin et al. demonstrated the second-order mapping language, namely second order source- to-target tuple-generation dependencies (denoted by SOtgd), is closed under composition, and they also present a composition algorithm for this language. The second-order languages uses existentially quantified function symbols, which essentially can be thought of as Skolem function. A tuplegenerating dependency specifies an inclusion of two conjunctive queries, Q1⊆ Q2. It is called source-to-target when Q1 refers only to symbols from the source schema and Q2 refers only to symbols from the target schema. However, for implementation, such kind of languages is not supported by standard SQL-based database tools.
Yu and Popa extended the algorithm of Fagin’s to handle nesting and apply it to some schema evolution scenarios, and they also discussed the optimizations of the composition result. Nash et al[8]. studied the composition of first-order constraints that are not necessarily source-to-target. They considered dependencies that can express key constraints and inclusions of conjunctive queries Q 1 ⊆ Q 2 , where Q 1 and Q 2 may reference symbols from both the source and target schema, but the composition of constraints in this language is not closed and whether a composition result exists is undecidable. They also gave an algorithm that produces a composition.
Berstein et al[3]. explored the mapping composition problem for constraints that are not restricted to being source-to-target, which extended the work of Nash and Fagin. They applied a “left-compose” step which allows the algorithm to handle mappings on which the algorithm in [8] fails. They used algebra-based instead of logicbased language to express mappings, which can be directly supported by database tools. We call their method “best effort composition approach” (denoted by BECA). BECA tries to eliminate as many relation symbols from the middle schema as possible. Given schemas σ1、σ2 andσ3 , mappings computed by BECA have the form ofσ1 →σ2′ →σ3, where σ2′ ⊂ σ2. That means, in come cases it may be better to eliminate some symbols fromσ2 successfully, rather than insist on either eliminating all them or failing. Since there may be some elements in the middle schema remain at the end of BECA, the result is not a perfect composition.
A main reason that σ 2 ′ is not empty after BECA, is that there may be indirect mappings. In this paper, we use a strategy namely schema elements back to solve the problem. Although this method expands σ 1 : σ 1 → σ 1 ′ , it can completely eliminate σ 2 , and a composed mapping only depends on the source and target schema will be generated.
-
III. Mapping composition
Definition 1 Let R 1 and R 2 be two binary relations, the composition R 1 o R 2of R 1 and R 2 is the binary relation: R 1 o R 2 = {( x , y ) : ( ∃ z )(( x , z ) ∈ R 1 ∧ ( z , y ) ∈ R 2)} .
Let M = ( S , T , Σ )be a schema mapping model, where S and T are the schemas with no relation symbols in common and Σ is a set of formulas of some logical formulas over < S , T >. Then let Inst ( M )be a binary relation between instances over S and T . We define composition of two schema mappings M 12 and M 23 using the composition of the binary relations Inst ( M 12) and Inst ( M 23).
Definition 2 [4] Let M 12 = 〈 S 1, S 2, Σ 12 〉 and M 23 = 〈 S 2, S 3, Σ 23 〉 be two schema mappings such that the schemas S 1, S 2, S 3have no relation symbol in common pairwise. A schema mapping M = 〈 S 1, S 3, Σ 13 〉 is a composition of M 12 and M 23 if Inst ( M ) = Inst ( M 12) o Inst ( M 23) which means that Inst ( M ) = { 〈 I 1, I 3 〉 |( ∃ I 2)( 〈 I 1, I 2 〉∈ Inst ( M 12) ∧〈 I 2, I 3 〉∈ Inst ( M 23))} ,where Ii is the instance of Si with 1 ≤ i ≤ 3.
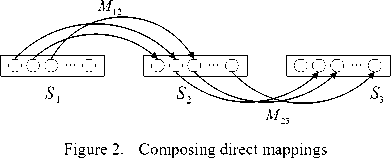
Figure 2 shows an example of direct mapping composition, where S 2 is the middle schema. Data exchange between S 1 and S 3 is achieved by composing M 12 and M 23 . Fagin et al. have proved the existence inevitability of mapping composition, and Alan Nash[7] gives the prerequisite for the existence of mapping composition, that is two mappings have a common schema, which is consistent with Fagin’s result. Both of them proved the existence of mapping composition by the relationship between query and mappings, and the instance isomorphism.
Example 1: Consider the following schemas S1, S2 and S3 . S1 consists of a single binary relation symbol Maint, which associates the name of maintenance person with the equipment he maintains. Schema S2 consists of a similar binary relation symbol Maint1, which is a copy of Maint, and of an additional binary relation symbol MP, that associates each person with an id. Schema S3 consists of one binary relation symbol Reg, that associates person ids with the equipments the persons take. Consider the following schema mappings M12 =(S1,S2,Σ12) and
M 23 = ( S 2 , S 3 , Σ 23 ) , where
Σ 12 = { ∀ n ∀ c ( Maint ( n , c ) → Maint 1( n , c )), ∀ n ∀ c ( Maint ( n , c ) → ∃ sMP ( n , s ))},
Σ 23 = { ∀ n ∀ s ∀ c ( MP ( n , s ) ∧ Maint 1( n , c )) → Reg ( s , c ))}.
Give the instances of S 1, S 2, S 3as follows:
I 1 : MaintI 1 ={(A, Eq1),(A, Eq2)}
I 2 : MaintI 2 = MaintI 1, MPI 2 ={(A, 0001) , (B, 0002)}
I 3 : RegI 3={(0001, Eq1),(0001, Eq2)}
According to Σ 12 and Σ 23 , we have 〈 I 1, I 2 〉∈ Inst ( M 12) and 〈 I 2, I 3 〉∈ Inst ( M 23). By definition 2, if there is a mapping M 13 that satisfies 〈 I 1, I 3 〉∈ Inst ( M 13), then M 13 is the composition of M 12 and M 23 , so M 13 can be expressed as ∀ n ∀ c ( Maint ( n , c ) → ∃ sReg ( s , c )).
Theory 1 The mapping composing operation Inst ( M 12) o Inst ( M 23) = Inst ( M 13) is closed under the homomorphism of instances.
Proof: Given 〈 I 1, I 3 〉∈ Inst ( M 13), for the instances I 1 ′ and I 3 ′ , satisfying I 1 ′ ≅ I 1 and I 3 ′ ≅ I 3 (“ ≅ ”denotes homomorphism), we just need to show that 〈 I 1 ′ , I 3 ′ 〉∈ Inst ( M 13). Since Inst ( M 12)and Inst ( M 23)are closed under homomorphism, and Inst ( M 12) o Inst ( M 23) = Inst ( M 13), there exists an instance I 2 that 〈 I 1, I 2 〉∈ Inst ( M 12) ∧〈 I 2, I 3 〉∈ Inst ( M 23). So there is an instance I 2 ′ ≅ I 2 such that 〈 I 1 ′ , I 2 ′ 〉∈ Inst ( M 12), and also 〈 I 2 ′ , I 3 ′ 〉∈ Inst ( M 23), then 〈 I 1 ′ , I 3 ′ 〉 ∈ Inst ( M 13). This was to be shown.
-
IV. Indirect mapping
A direct mappings can be given by a Source-to-Target tuple generating dependency (denoted by S2Ttgd): ∀ x ( φ S ( x ) → ∃ y ψ T ( x , y )), where φ S and ψ T are respectively the formulas on S and T , and x, y are the set of variables. A full S2Ttgd mapping can be expressed by ∀ x ( φ S ( x ) → ψ T ( x )), and a mapping expressed by ∀ x ( φ S ( x ) → ∧ i k = 1 Ri ( xi ))equals to the set of some full S2Ttgds ∀ x ( φ S ( x ) → Ri ( xi )), where i = 1, K , k , and Ri (x) is the atomic formula.
-
A. Describe indirect mappings
In indirect mappings, the algebra operation results of the elements in both the source and target schema are related, as shown in figure 3.

S 1 S 2
M 12 --ЧП^^[2]
-
Figure 3. Indirect mappings
In element correspondence “[1]” (see Fig. 3), nodes in the pane of the source schema are mapped to an element in the target schema after some algebra operations. The algebra operations of schema elements includes some basic ones, like Union, Cartesian, Projection and Selection, and some compositions, like Intersection, Join, Nature Join and division etc.
Definition 3 Indirect elements correspondence (denoted by ICO E ) is the set of element correspondences that elements are mapped after some algebra operations. Let φ S be the formulas of S , and S i be the scheme of S , the algebra operations have six forms, as shown bellow, where 1~4 are the basic ones and 5~6 can be derived from 1~4:
Union Let φS(x)=∧(Si(x)∨K ∨Si(x)),Si(x)∈S, k,i and it is the same forψT .
ICO E : ∀ e ( S 1( e ) ∨ S 2( e ) ∨ L ∨ Sn ( e )→ T ( e )) (or
∀ e ( S 1( e ) ∨ S 2( e ) ∨ L ∨ S n ( e )→ ∃ wT ( e , w )) if there is an existence quantifier).
Cartesian φ S ( x ) = ∧ ( Si ( x ) × K × Si ( x )), Sm ( x ) ∈ S
ICO E : ∀ e ( S 1( e ) × S 2( e ) × L × Sn ( e ) → T ( e )) (or
∀ e ( S 1( e ) × S 2( e ) → ∃ wT ( e , w ))).
Projection φ S ( x ) =∧ ( π k 1, K km ( Sk ( x ))), Sk ( x ) ∈ S .
k
ICO E : ∀ x( π m , n ( S 1 ( a 1 , a 2 , K , a n 1)) ∧ π l , k ( S 2 ( b 1 , b 2 , K , b n 2))
Let ⊗ ={∧,∨,σ,θ}be the basic algebra operation symbol set (see 1~4 in definition 3), and indirect mappings can be expressed as φS′ (x) = ⊗(πi1 im (Sk)), Sk (x) ∈ S. Take the indirect k k,K k mapping shown in figure 4 as an example, M12 can be expressed as:
∀ x(( π m 1 ( R 1 S 1( x 11 )) ⊗ π n 1 ( R 1 S 1( x 12 ))) ∧ ( π m 2 ( RkS 1( x k 1 ))
⊗ π n 2( RkS 1 ( x k 2 ))) → ∃ y ( R 1 S 2 ( y 1 ) ∧ π l R 2 S 2 ( y 2 ))), and M 23 :
∀ y( R 1 S 2 ( y 1 ) ∧ ( π l ( R 2 S 2 ( y 11 )) ⊗ π p ( R 2 S 2 ( y 12 ))) → ∃ z( R 1 S 3 ( z 1 ) ∧ R 3 S 3 ( z 2 ))) .
If ψ T ′ ( x , y ) has the same form with φ S ′ ( x ), then the nonfull indirect mapping can be expressed as: ∀ x( φ S ′ (x) → ∃ y ψ T ′ (x,y)).
M 12
| | о op \
S 1 S 2 S 3
M 23
-
Figure 4. Indirect mappings between schemas.
B.Exchange data under indirect mappings
Now we give the concept of homomorphic instances under indirect mappings ( concept of homomorphic direct mappings is given in [4], and we do not discuss it here). Consider the following example:
Example 2: Given schemas S 1, S 2and S 3 . S 1 consists of a single binary relation symbol Consistof , which associates the name of equipments with the parts they have. S 2 consists of a similar binary relation symbol Consistof 1 , which is a copy of Consistof , and of an additional binary relation symbol MCode , that associates each equipment name with an id. S 3 consists of a single binary relation symbol MRegister , which associates the code of equipments with the related parts. Consider the following mappings: M 12 = ( S 1, S 2, Σ 12) and M 23 = ( S 2, S 3, Σ 23), where
Σ 12 = { ∀ e ∀ p ( Consistof ( e , p ) → Consistof 1( e , p )), ∀ e ∀ p
→ T ( am , an , bl , bk , K ))(or ∀ x( π m , n ( S ( a 1, a 2, K , an 1)) ∧
( Consistof ( e , p ) → ∃ cMCode ( e , c ))},
π l , k ( S ( b 1, b 2, K , bn 2)) → ∃ y T ( am , an , bl , bk , K , y 1, y 2, K , yn 3))
), where x and y are the set of variables.
-
1. Selection This operation considers the conditional mappings, which represents the user’s integrality. It has the form of
-
2. Intersection refers to several schemas, which is a kind of selection operation essentially.
-
3. Join is the composition of Cartesian and Selection
φ S ( x ) = ∧ ( σ F ( Si ( x ))) = ∧ ( Si ( x ) ∧ F ( t )), Si ( x ) ∈ S , t ∈ Inst ( S ) . ii
ICO E : ∀ e (( S ( e ) ∧ ( Inst ( e ) | = θ )) → T ( e )).
Σ 23 = { ∀ e ∀ c ∀ p ( MCode ( e , c ) ∧ Consistof 1( e , p )) → MRegister ( c , p ))}
The second formula in Σ 12 is a direct mapping that associate equipment name e in the source schema to the equipment name e in the target schema. According to Theory 1 , let I , J be the instance of a mapping M , that means 〈 I , J 〉∈ Inst ( M ), and if there is an instance pair 〈 I ′ , J ′ 〉 that 〈 I ′ , J ′ 〉 ≅ 〈 I , J 〉 , then 〈 I ′ , J ′ 〉∈ Inst ( M ). For the converse, if 〈 I ′ , J ′ 〉 and 〈 I , J 〉 are respectively the instance of M , then we have 〈 I ′ , J ′ 〉≅〈 I , J 〉 . The above conclusion is true for that M is the direct mapping. For the indirect mappings, the homomorphism between instances is different. For example, let S 1 ′ be a schema,
which is a copy ofS1 with a little differences that certain element in S1 splits into several parts in Si. For example, the equipment name in S‘ contains two parts (supername+name), and the corresponding formula set is X’2. Therefore, under the condition of homomorphism, there may be some non-one-to-one correspondences.
Let S、T be the source and target schema respectively, and Ri is a scheme of S. If there is an indirect mapping M from S to T, and let Ri be the scheme constructed as follows: substituting each element combination that participates in the indirect mappings with a single element. We call Ri a generating scheme. If we define mappings from Rii to T with the form of Vx(R/(x) > ^T (x)) , and mappings from Ri to T with the form of Vx(Ri(x) —Indirect > ^T (x)) , then mappings from Ri to yT (x) are direct, and those from Ri (x) to ^T (x) are indirect, as shown in figure 5:
Figure 5. Instance homomorphism under indirect mappings
We define the homomorphism function h under indirect mappings as:
h ( a i ) =
e , e e Inst( n k ( R i ))
compound ( e 1 , к , e l ), e i e Inst( n i ( R j ))
Then h is called a general homomorphism function , where compound is the algebra operation of elements.
Definition 4 Let R and R' be two schemas, h is the general homomorphism function shown above. Let J, J' be the instances ofR and R' respectively. If for each scheme symbol Ri in R , and each tuple (a1, к, an) e RJ , there is a tuple (h(a1),K, h(an)) e RJ , then R and R are homomorphic instances under h , then the data exchange process under indirect mappings can be implemented by the homomorphism given in Definition 4 comparing with the process under direct mappings (see[12] ).
V. Mechanic of indirect mapping composition
-
A. Schema-elements-back
As shown in figure 4, although there is a common schema S2 , we can not directly construct the mappings from S1 to S3 according to M12 andM23 , even can not give the mapping composition directly. Using direct mapping composition, elements in S1 can only map to part of the certain elements of S3 . During the data exchange procedure, a complete instance of S3 may consist part of the instance from S2 , so data exchange from S1 to S3 by direct mapping composition M12 o M23 may lose some information, that is because M12 andM23 contains some elements that is not in common, there is no such an instance I2 of S2 satisfying conditions in Definition 2.
Since the expressions of indirect mapping composition can not be derived by Definition 2 directly, we deal with this problem based on general instance homomorphism, the main idea of which is to construct a schema that can be directly used for mapping composition, and make sure that the instances of the constructed schema is homomorphic with the instances of the original schema under the general instance homomorphism function . We propose a strategy named schema-elements-back by constructing some virtual elements in the source schema to deal with the composition of indirect mappings. Compared with BECA, schema-elements-back can eliminate the infection of the middle schema.
Definition 5 Let M ST = ( S , T , X ST ) be a model of indirect schema mapping, where X ST is the formula set with the form of V x( ^ S (x) > 3 yy'T (x,y)), and mappings from S to T are sound[13]. Let DomM ( S ) be the domain of S , and Dom ( T ) be the domain of T , and then we have Dom M ( S ) c Dom(T ) . Let y In and x In be the set of variables that participate in the indirect mappings in T and S respectively, and we construct the virtual elements in S by set y In - x In . As shown in figure 6, the newly constructed source schema is denoted by S' . We can construct direct mappings from T to S' on DomM ( DomM ( S )) . Let M S T be the mapping from S' to T , and M ST be the inverse of M S , T , and then the process of virtual elements construction is called a schema-elements- back process.
M ST
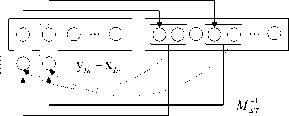
Figure 6. Inverse of indirect mappings based on virtual elements
Definition 6 Let M 12 = ( S 1 , S 2 , X 12 ) and M 23 = ( S 2, S 3 , X 23 ) be two indirect schema mappings such that the schemas S 1, S 2, S 3have no relation symbol in common pairwise. We construct a new schema S ^ by adding virtual elements according to Definition 5 with the mapping M 1 - 2 and its inverse M 1' 2 . Let M = ( S 1 , S 3 , £ 113 ) be the newly constructed mapping model. If Inst ( M ) = Inst ( M 12 ) o Inst ( M 23) , that means Inst ( M ) = « I ', 1 3 ) I ( 1 2X < I ', 1 2 ) e Inst ( M 12 ) л( 1 2 , 1 3 ) e Inst ( M 23 ))} , then M is the composition of indirect mappings M 12 and M 23 .
-
B. Indirect mapping composition algorithm
When data are exchanged under the strategy of schema-elements-back , instance of some elements in the middle schema may be firstly transformed to the source, and there is a reverse data flow during the data exchanging process from the source to the target. Such a data flow can be implemented by the reverse mapping from the element in the middle schema to the newly added element in the source schema. Since the object of composing two schema mappings is to directly construct the mapping from the source to the target without considering the middle schema, schema-elements-back can insure that under the condition of indirect mapping, directly data exchange from the source to the target can be realized, which can improve the efficiency of data transformation. Now we show the process of indirect mapping composition.
Schema-elements-back is the process of adding new elements to the source schema according to the middle schema, in order to achieve a directly mapping from the source schema to the target schema under the condition that new elements are introduced. As shown in figure 7, the dashed lines represent the correspondences between the newly added schema elements and elements in the middle schema, from which we can see that when S1 is translated to S1′ , by Theory 2, mapping composition M1′3 can be directly constructed from S1′ to S3 .
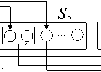
Figure 7. Process of Schema-elements-back
M 12
S 1 ′ S
Lkincnl
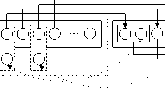
S 3
M 23
Now we give an indirect mapping composition algorithm (denoted by IMCA), without loss of generality, we consider the case shown in figure 7, and for the other cases we just need some small modifications.
Algorithm IMCA
Input: M 12 = ( S 1, S 2, Σ 12) and M 23 = ( S 2, S 3, Σ 23), where Σ 12 and Σ 23 are extended S2Ttgds that describe indirect schema element correspondences.
Output: A schema mapping M 1 ′ 3 = ( S 1 ′ , S 3, Σ 1 ′ 3), which is the composition of M 12 and M 23 .
Step1. Normalize Σ 12 and Σ 23 :
Rename the function and element symbols so that the symbols that appear in Σ 12 are all distinct from those in Σ 23 .
Step2. Construct virtual elements in S 1 :
If M 12 : πθ 1( Ri 1 S 1( xi 1)) → πθ 2( RiS 22( xi 2)) and
M 23 : πθ 2 ′ ( RiS 22( xi 2)) → πθ 3( RiS 33( xi 3))satisfying that θ 2 ′ ⊃ θ 2.
Then For each i do projection operation πθ ′ - θ RiS 2 ( xi ), and get an attribute set E = { E 1 , K El }, where E i is the set of attributes generated by πθ ′ - θ RiS 2 ( xi ).
Add each set Ei into S 1 and combine it with attributes computed by πθ ( RiS 1 ( xi )), which is called a schema elements back process. As shown in the left dashed box of figure 7, we get the new constructed schema S 1 ′ by combining elements in E to S 1 ( virtual elements are from S 2 ). Then we get the mapping M 1 ′ 2 from S 1 ′ to S 2 with the formula set Σ 1 ′ 2 . Since the mapping from S 2 to S 1 ′ is one-to-one, we get M 1 - ′ 2 1 = M 21 ′ , where Σ 21 ′ gives the data back rules from S 2 to S 1 ′ during the data exchange process from S 1 ′ to S 3 .
Step3. Construction of S 12 and S 23
-
( 3.1 ) Initialize S 12 and S 23 to each be the empty set.
Assume the formulas in Σ 1 ′ 2 is
( ∀ x 1( φ 1 → ψ 1)) ∧ K ∧ ( ∀ xn ( φ n → ψ n ))
-
( 3.2 )Pu t each of the n implications φ i → ψ i , for 1 ≤ i ≤ n , into S 12 . We do likewise for Σ 23 and S 23 . Each implication χ in S 12 has the form φ (x) → ⊗ ( πθ ( RSj 2(x j )) ⊗ K ⊗ πθ ( RjS 2(x j ))) where every
member of x is a universally quantified variable, and each x j , for1 ≤ j ≤ k , is a sequences of terms on x .
-
( 3.3 )Re place each such implication χ in S 12 with k implications:
φ (x) → π θ ( R 1 S 2 (x 1 )) ⊗ K ⊗ π θ ( R 1 S 2 (x 1 )), K , φ (x) → π θ ( R k S 2(x k )) ⊗ K ⊗ π θ ( R k S 2(x k )).
Step4. Compose S 12 and S 23 :
Repeat the following until every schema symbol in the left-hand side of every formula in S 23 is from S 1 .
For each implication χ in S 23 of the form ψ → γ where there is an atom R ( y ) ( R is a scheme symbol in S 2 ), perform the following steps to replace R ( y ) with atoms in S 1 ′ .
-
( 4.1 ) Let φ 1 → R ( t 1), K , φ p → R ( tp )be all the formulas in s 12 whose right-hand side has R in it. If no such implications exist in S 12, we remove χ from S 23. Otherwise, for each such formula φ i → R ( ti ), rename the variables in this formula so that they do not overlap with the variables in χ .
-
( 4.2 ) Remove χ from S 23 and add p formulas to S 23 as follows: replace R ( y ) in χ with φ i and add the resulting formula to S 23 , for 1 ≤ i ≤ p .
Step5. Construct M 13 :
Let S 23 = ( X i , . , X r ) where X i , k , X r are all the formulas from step4, Let S 1 , 3 be V z 1 x 1 a . . aV zrxr where z , is the set of variables found in x , for 1 ^ i ^ r ■ i i
Return M 13 = ( S ‘ S 3, S r3) »
A new source schema should be maintained by the composition algorithm, and such a schema may not be useful in other mapping compositions. However, if the scale of data to be exchanged is large, such new extended schema can improve the efficiency of data exchange.
VI. Experiments
-
A. Complexity of ICMA
Let the elements that schema S 1 , S 2 and S 3 respectively contains be N 1 , N 2 and N 3 . In step1 of ICMA, the rename operation need to match each elements among S 1 , S 2 and S 3 , whose complexity is O ( N 1 x N 2 x N 3 ) .
Let the correspondences in M 12 be N 12 and correspondences in M 23 be N 23 , where N 12 and N 23 are the numbers of atom elements. The number of virtual elements constructed in schema-element-back process is N 23 - N 12 , so the complexity for constructing virtual elements is O ( N 23 - N 12 ) .
The complexity for composing is decided by the atom implications that S r2 and S 23 contains. Let N C be the number of implications in S 12 with the form of ф i ^ y i and n1 be the atom formula in y i , and then the number of formulas in S r2 is N C x n C . If the number of implications with the form of y i ^ y . in S 23 is NC3 , where y i is the set of atom formulas. The number of pairs of atom formulas that should be matched during the replacing process is N C x n i 12 x N C , so the composing complexity is O ( NC x n C x NC 3) . The whole complexity for indirect mapping composition is O ( N 1 x N 2 x N 3) + O ( N 23 - N 12 ) + O ( N C 2 x n i 12 x N C 3) . The complexity of direct mapping composition process is O ( N 1 x N 2 x N 3 ) + O ( N C 2 x n i 12 x N C 3) , both are polynomial complexities.
-
B. Results and analysis
-
(1) Query efficiency under indirect mapping composition
Given the numbers of elements in schema S 1 , S 2 and S 3 , and the numbers of implications in S r2 and S 23 . Given different scales of indirect mappings, now we compute the numbers of virtual elements constructed during the process of schema-element-back . We use the example in DBLP, chose 20 literature base by the sequence of letters, and pick up the meta-information of each literature. We construct the mappings manually as follows (take three of them for example):
Author ® Author ® ■ • ■ ® Author ^ AuthorSet
Country ® University ® l ® City ^ AuthorAddress
Country ® Street ® l ® City ^ ConferenceLocation
The relationship between the number of indirect element correspondences and the number virtual elements constructed are shown in table 1.
Table 1. Relationship between the number of virtual elements generated during the indirect mapping composition process and the number of indirect element correspondences.
|
( S 1 ^ S 2 ) |
5 |
10 |
15 |
20 |
25 |
30 |
35 |
40 |
45 |
|
( S 2 ^ S 3 ) |
5 |
11 |
15 |
22 |
23 |
30 |
36 |
45 |
45 |
|
virtual elements |
2 |
5 |
4 |
7 |
5 |
10 |
11 |
9 |
15 |
Since virtual elements are introduced during the process of indirect mapping composition, figure 8 show a comparison for numbers related by the queries for nonmapping-composition and mapping-composition respectively.
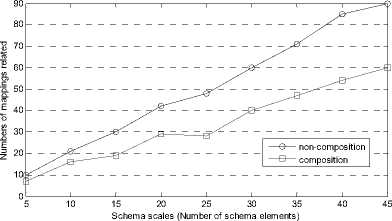
Figure 8. Comparison for mappings related under different condition.
As we can see that, although some virtual elements participate the querying and data exchanging, compared with the non-composition way, indirect mapping composition can reduce the number of mappings related by the query and improve the query efficiency.
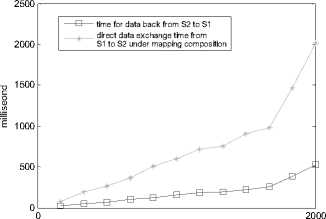
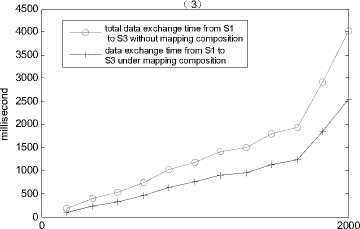
Consider the indirect mappings shown in figure 4, we simulate the data exchange process from S 1 to S 3 , and compare the executing times between indirect mapping composition and non-composition under different scale of instances. We use Oracle 9i as the database, and the time for reading records in the oracle database is the increase function of record scale and attributes numbers.
In the case of non-composition, instances { I 1 } of S 1 are firstly transformed to instances of S 2 according to M 12 , denoted as { I 2 }, then { I 2 } are transformed to { I 3 } of S 3 . the read and write of data happens among three schemas.
In the case of composition, since there are indirect mappings from S 1 to S 3 , using the schema element back given in IMCA, instance for part attributes S 2 of are firstly transformed to S 2, and we get the new instances { 1 1 }, then instances { 1 3} of S 3 are generated according to M 13 .
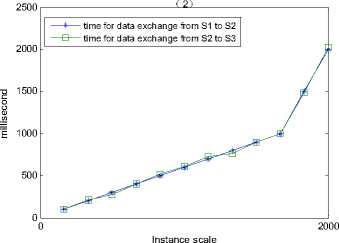
Now we give the executing time (milliseconds) for the data exchange process from S 1 to S 3 under different instance scale of S 1 . Figure 9 show the data exchange executing time comparison results:
( 1 )
instance scale
Instance scale
0 0
exchange time from S1 to S2 exchange time from S2 to S3 exchange time from S1 to S2 under non-composition exchange time from S2 to S1 exchange time from S1 to S3 total exchange time from S1 to S3 under mapping composition

instance scale
Figure 9. data exchange process executing time comparisons.
-
(2) Comparison of BECA and IMCA
In BECA, symbols in the middle schema are eliminated by some algebra operations step by step using view unfolding, left composing and right composing. The main idea of BECA is to replace the symbols in the middle schema by the symbols in the source and target schemas as much as possible. Let the elements that participate in the process of elimination obey the equality distribution, and the numbers of virtual elements are decided by step 2 of IMCA, figure 10 shows the comparison between number of element symbols eliminated by BECA and number of virtual elements constructed in IMCA.
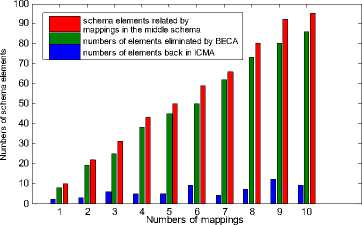
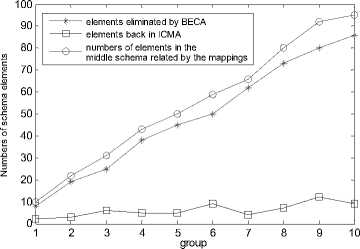
Figure 10. Comparison for affection of middle schema between BECA and ICMA
Seen from the results, the affections of the middle schema on both BECA and IMCA are almost the same. Besides, number of virtual elements in IMCA and number of elements in the middle schema that is not eliminated are equal. But using IMCA, we can completely eliminate the affection of middle schema, which can be seen as a real composition process.
VII. Conclusion
Mapping composition is an active aspect in the research of schema mapping management, the object of which is to reuse mappings as a model, and simplify the process of data exchange. Especially when the scale of peers in the network is large, composing mappings can improve the data exchange efficiency. In this paper, we give the definition of indirect mappings, and discuss the composability of indirect mappings. Then we propose an indirect mapping composition algorithm using the schema-element-back strategy. Experiment results show that although IMCA dose not improve the query performance, but the affection of middle schema can be eliminated.
References Mechanism and Algorithm for Indirect Schema Mapping Composition
- A. Fuxman, M. A. Hernández, C. T. H. Ho, R. J. Miller, P. Papotti, L. Popa. Nested Mappings: Schema Mapping Reloaded. [C], VLDB 2006, Seoul Korea, 67-68,2006
- P. A. Berstein, S. Melnik. Model Management 2.0: Manipulating Richer Mappings [C], SIGMOD, Beijing, China, 1-12,2007
- P. A. Berstein, T. J. Green, S. Melnik. Implementing mapping composition [J]. VLDB Journal, 2008,17): 333-353
- R. Fagin, P. G. Kolaitis, L. Popa. Composing Schema Mappings: Second-Order Dependencies to the Rescue [J]. ACM TODS, 2005, 30 (4): 994-1055
- J. Madhavan, A. Y. Halevy. Composing Mappings Among Data Sources [C], VLDB 03, Berlin, Germany, 572-583,2003
- P. McBrien, A. Poulovassilis. Data Integration by Bi-Directional Schema Transformation Rules [C], ICDE03, Boston, 227-238,2003
- A. Nash. Foundations of Information Integration, SAN DIEGO, UNIVERSITY OF CALIFORNIA, 2006
- A. Nash, P. A. Berstein, S. Melnik. Composition of Mappings Given by Embedded Dependencies [C], PODS 2005, Baltimore, Maryland, USA, 2005
- M. Boyd, S. Kittivoravitkul, C. Lazanitis, P. McBrien, N. Rizopoulos. AutoMed: A BAV Data Integration System for Heterogeneous Data Sources [C], CAiSE04, Riga Latvia, 3084,82-97,2004
- M. Boyd, P. McBrien. Comparing and Transforming Between Data Models via an Intermediate Hypergraph Data Model [J]. COMPUTER SCIENCE, 2005, 3730 (69-109)
- LiXu, D. W. Embley. A Composite Approach to Automating Direct and Indirect Schema Mappings [J]. information System, 2006, 31 (8): 697-132
- L. Popa, Y. Velegrakis, R. J.Miller, M. A. Hernandez, R. Fagin. Translating Web Data [C], Proceedings of the 28th VLDB Conferences(VLDB'02) Hong Kong, China, 598-609,2002
- M. Lenzerini. Data Integration: A Theoretical Perspective [C], PODS'02, 233-246,2002
- Y. Velegrakis, R. J.Miller, L. Popa. Mapping Adaptation under Evolving Schemas [C], 29th VLDB Conference, Berlin, Germany, 2003
- R. Fagin, P. G. Kolaitis, R. J.Miller, L. Popa. Data Exchange: Semantics and Query Answer. [J]. Theoretical Computer Science 2005, 336 (89-124)
