Metadata Management System for E-learning Objects using Cloud

Author: Ashok Kumar.S
Journal: International Journal of Information Engineering and Electronic Business(IJIEEB) @ijieeb
Article in issue: 3 vol.8, 2016.
Free access
Existing e-learning systems suffer seriously from the problems of scalability, maintainability, manageability, which can be overcome by merging e-learning with the cloud environment. Cloud technologies can satisfy the need of efficient e-learning system, resource management, user management and security for maintaining the secret information. Efficient delivery of the learning content can be done using Learning Content Management System. It is an environment where multiple users can create, accumulate, reuse, administer and deliver learning content from a central object repository. Learning Content Management System contains only the content description. So metadata for that content created which acts as an index for the learning content and holds details regarding author, location, format etc., Metadata is data about the data which is used for efficient searching.
E-learning, Content manager, Metadata, Searching, Indexing
Short address: https://sciup.org/15013424
IDR: 15013424
Text of the scientific article Metadata Management System for E-learning Objects using Cloud
Published Online May 2016 in MECS
Metadata is used to structure, annotate data so that it can be reused, accessed, transformed etc., Example: the author, preferences, style, location, file size. Teachers will provide the metadata for the learning content they created. Accessing of entire table for finding the data is more complex. When the file has to be accessed, the location of file needs to be known in order to retrieve the file quick. To find the location of file, indexing can be used for better performance in searching a required file. The location of the files is managed by the indexes which help in accessing the file quicker from a large collection of files. Metadata is represented through XML which creates a easier way to read and exchange information in various formats for different users
-
A. Cloud Computing
Cloud computing provides a suitable access to virtualized information centre over the Internet at diverse levels PaaS, IaaS and SaaS. Infrastructure-as-a-Service (IaaS) providers offer the service to run complete virtual infrastructures (VIs) with many connected virtual machines. Platform-as-a-Service (PaaS) provider proposed a pre-configured environment for application developers, including web server packages as well as cloud-libraries. Software-as-a-Service (SaaS) is used for providing scientific applications. Service providers in this field have to either run their own data centre or to outsource the applications to a third party provider. The resources are utilized optimally without violating the Service Level Agreement (SLA) made with the customers. Cloud computing enables convenient, on demand access to shared resources in a network (example: servers, storage, applications and services).
-
B. Layers of Cloud Computing
Hardware Infrastructure Layer
This layer is associated with computing power, virtualization and storage. Virtualization is one of the key concepts to improve CPU utilization. Since the multiple servers use the same CPU, performance is increased. By maintaining a virtual server, it is not necessary to maintain a separate server for each application. In order to configure a virtual server, it is required to allocate memory and CPU power. Every physical server can serve 10 virtual servers.
One of the goals of using the cloud is access to a functioning storage space system in a reliable and efficient manner. Today's storage systems have these capabilities. Organization providing Cloud Computing services provide smart backup capabilities, allocating it to different clients along with data protection and security [1]. The requirement of storage systems and security is needed for many of the companies to maintain confidential information.
Platform Layer
The Platform layer consists of three components: the operating system, the application development environment and the database. In PaaS the internet is used as a computing platform by the user. Due to the growth in technology, it is possible to use a computer even without Operating System. The OS is accessible from the cloud. The application development environment includes .Net technology from Microsoft or Sandbox by Google.
Application Layer
The Application layer is dedicated to the applications such as customer relationship management (CRM) like Salesforce and project management software, like Clarizen. The various applications of cloud is growing exponentially. This layer consists of applications like Gmail and Facebook which are some of the applications of cloud. It is also called as software as a service (SaaS) where software application services are obtained from Internet.
will provide the metadata for the learning content what they created. Accessing of entire storage for finding the data is more complex. When the file has to be accessed, the location of file needs to be known in order to retrieve the file. To find the location of file, indexing can be used for better performance in searching a required file. The location of the files is managed by the indexes in the form of metadata which help in accessing the file quicker from a large collection of files. For efficient searching of learning content requested by student, metadata is also represented through individual tree for each subject with the root node as subject.
Consider the Fig.1 which shows searching in an efficient way. Here 1 represents C, 2 represent C++ and 3 represents Java programming language. Function concept is available in C, C++ and Java. A pointer is available in C and C++. Interface is available in Java only. When we search for any of these concepts, it will be searched only in that particular tree.

1-С2-С++3-Java
Fig.1. Efficient Searching
II. Metadata Management
Metadata is used to structure, interpret data so that it can be accessed, transformed used again etc., Example: the author, preferences, style, location, file size. Teachers will provide the metadata for the learning content they created. Accessing of entire table for finding the data is more complex. When the file has to be accessed, the location of file needs to be known in order to retrieve the file quick. To find the location of file, indexing can be used for better performance in searching a required file. The location of the files is managed by the indexes which help in accessing the file quicker from a large collection of files.
LCMS’s efficiency is improved by the representation of learning content through metadata that contains descriptive information about the resource for easy retrieving and reusability [13]. Learning content created through eXe authoring tool is SCORM complaint. Metadata is used to structure, annotate data so that it can be reused, accessed, transformed etc. For example, the author, preferences, style, location, files size. Teachers
A. Metadata Tree Construction
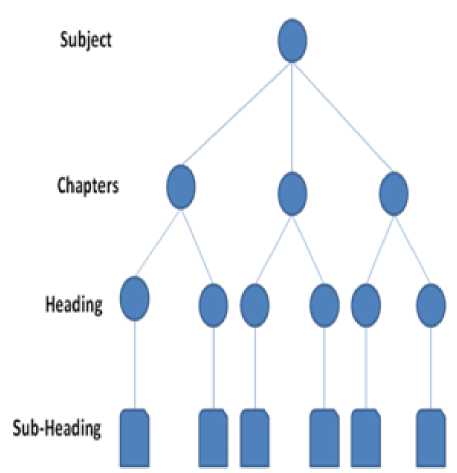
Fig.2. Content Package
Subject Tree T1 is constructed and represented in the form of XML file. Under each subject node, chapter node is added and under chapter node topic node is added [27]. Indexing of each node is done which is shown in Fig.2
For example if Subject id is ‘1’,then the first chapter which comes under that subject with id ‘1’ will be indexed as ‘11’ and the second chapter will be indexed as ‘12’ and it goes on. Similarly if the chapter id is ‘11’ then the first topic which comes under that chapter will be indexed as ‘111’, second topic will be ‘112’ and so on. This is shown in the following algorithm.
Algorithm: Metadata Tree Construction
Input: Learning Objects
Output: T1-Metadata Subject tree
Step 1: Initialize root node subject and add index by setting Subject Id=1
Step 2: Initialize chapters as child node and add index by setting chapter Id =11, 12, 13…
Step 3: Initialize sections as child node under chapter and add index by setting Section Id=111,112,121,122,131,132…
Step 4: Add available metadata information under each node.
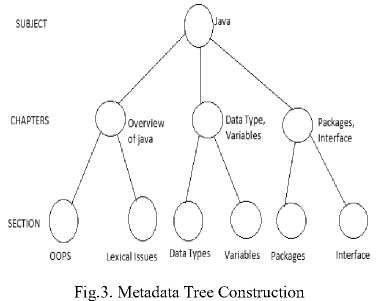
For efficient searching of learning content requested by student, metadata is also represented through individual tree for each subject with the root node as subject. Under subject root node chapter nodes are added. Chapter node contains topic nodes. Index for each node is created. These individual trees created for each subject. Here tree is created for Java is shown in Fig.3
-
B. Metadata Tree Merging
Subject trees which have the common domain can be merged together under that domain. For example Java, C, C++ Programming languages can be merged under the domain Programming Languages. Now the index of the subjects has to be appended. If the domain id of Programming Languages is ’1’ then Java subject id will be appended as ‘11’ and C-Programming will be ‘12’, C++ Programming will be ‘13’. This is shown in the following algorithm.
Algorithm: Metadata Tree Merging
Input: T1-Subject, T2-Subject-two trees to be merged Output: T12 Domain tree
Step 1: Initialize root node as “Domain” with index say ‘1’
Step 2: Add T1 tree and T2 tree as children of root node “Domain” by appending the subject id of T1 root node as ‘11’ and T2 root node as ‘12’.
-
III. System Architecture
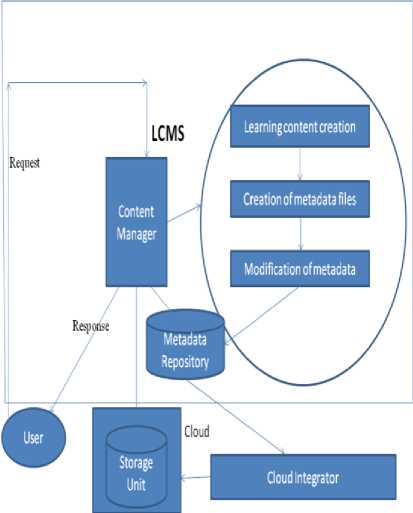
Fig.4. System Architecture
-
A. Content Manager
Content Manager is the one which processes user request and delivers the needed results. This does the most important task of processing. This content manager will maintain the students, teachers’ details in a database. New users (students) have to register their details before accessing the content whereas the old users who have already registered can simply authenticate themselves and access learning contents. Content manager allows only the authenticated teachers to view the metadata file and modify it. When student request for learning object, content manager will look for metadata in the local repository and locates the learning object from the cloud using the location information specified in the metadata and finally delivers to the student.
-
B. Learning Content Creation
Using an authoring tool learning contents are created by the teachers. Content created using the authoring tool will be in a XML format and it can be opened in a browser. These are the contents which has to be delivered to the users (students) based on their needs.eXe [eLearning XHTML editor] authoring tool is used here for creating e-Learning contents.eXe contains iDevices [instructional Devices] which describe learning content and activities.
Fig.5. Creation of Learning Content
Fig.6. Learning Content
-
C. Metadata Creation
Metadata is used to structure, annotate data so that it can be reused, accessed, transformed etc., for example: the author, format, style, location, file size. Teachers will provide the metadata for the learning content they created. These metadata files are stored within LCMS repository.
-
D. Modification of Metadata
Metadata created above contains only the narration of the learning content. Hence to make searching in a efficient way, modification of metadata is needed. Metadata for that content describing metadata is created which acts as an index for that and also holds location of metadata and learning content. This metadata will be in the form of tree structure with domain as root node, subject as the immediate child of domain, chapter node under subject and topic node under chapter.
-
E. Integrating with Cloud
Learning objects which are created using authoring tool is stored in the cloud. Metadata contains the location of learning content. The address which metadata holds is only the logical address of the content. So logical to physical address mapping has to be done. Fig.7 and Fig. 8 illustrates the process of uploading and retrieving the contents to/from the cloud respectively. SOAP (Simple Object Access Protocol) is used for exchanging over the Internet [19][21]. This protocol provides information regarding the authentication, Encoding of information and the Key to the recipient. By using the key provided by the SOAP, the recipient will able to decode the information which was sent. It commonly uses Hypertext Transfer Protocol (HTTP) for exchanging information. At certain times, it uses Simple Mail Transfer Protocol (SMTP).
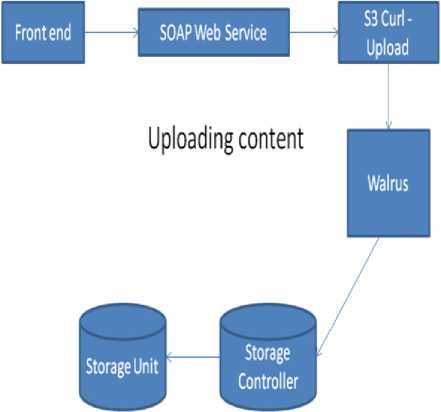
Fig.7. Uploading Content to Cloud
Walrus is used for storing the data. This type of service is provided by the Eucalyptus. Each container in walrus can store a maximum of 5 Terabytes of data and the accessing may be public or private. The data in the walrus are identified by using the Uniform Resource Identifiers (URI). There are several containers in Walrus and each container is unique for different accounts. Some of the services provided by walrus are, creating any number of containers, uploading downloading data from container. These services are provided via a SOAP web service. It can also control the permission for accessing the data.
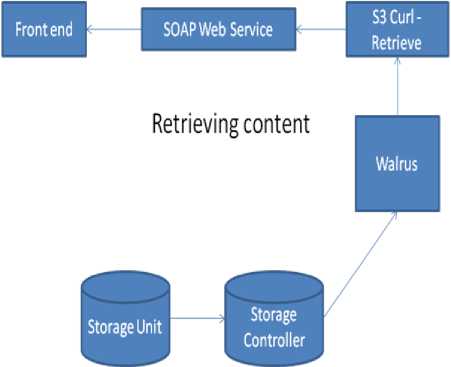
Fig.8. Retrieving Content from Cloud
-
F. E-Learning on the Cloud
Cloud computing technologies are used to build the next generation of platform-independent tools and scalable data storage e-Learning systems to provide smart formal and informal learning. This will reduce the overall cost of computing. Thus virtual learning environment [5] provides a large range of services available in the cloud. The proposed environment of cloud is used for creating a platform for exploring ideas and has a service oriented architecture that simplifies the management and increases the effective utilization of the underlying web resources. The system provides different approaches to learning and teaching under the same environment. This is better than the traditional learning management systems as it provides the learners a well known environment where they can easily achieve their learning goals, and flexible architecture enabling set of services that support different learning activities such as production, distribution, reflection, and discussion.
-
IV. Searching
When student wants to search the learning contents he may enter the keywords. First that keyword will be matched with the domain name, if the match is found the subject details under that matched domain will be shown to the student. Further Subject match is done by matching the given keyword with the subject title and the chapter under that matched subject will be shown. Similarly Chapter and Topic match will be shown [25]. This is shown in the following algorithm.
Algorithm: Searching (key)
Step 1: if (domain. match==key)
Print Subject details under that matched domain
Step 2: if (subject. match==key)
Print Chapter details under that matched subject
Step 3: if (chapter. match==key)
Print Topic details under that matched chapter
Step 4: if (topic. match==key)
Print the Topic details and attributes.
Subject Math-C Programming
Вотумам Programming languages
SubjedTite Ja>a
Chapter ri 111
SubjedTfle Jara
Chapter ri 112
SubjedTle Jara
Chapter ri 113
Daman Match Programming Languages
SubjectTte C Programming
Chapterri 121
SubjectTie C Programming
Chapter ri 122
SubjedTae c Programming
Chapter ri 123
Chapter Tie Geltng started wihC
Ciiaptefrii21
Topic id12l1
Chapter Tie Geltng started wffiC
Chapter ri 121
Tepicid1212
Chapter Tie Geltng started мяс
Chapter ri 121
Topic id1213
Subject Match-C Programming
ChapterTleDeusionCoitolStiicture
Chapter ri 122 ____________ Ж
, waM ^ R*L.Ml.. JW-mV™*-™ "^T
Ctiapterri122
Topic id1222
SutpKt Match -C Programming
Chapter Tie The Loop confrol siructuK
9apteridl23
Topic id 1231
Chapter Tie The Loop control stuctere
Chapter ri 123
Topic id1232
Chapter Tie The Loogcortolsbucfwe
Oiapterrii23
Topic id1233
Top i c Match -OtfBct Orenled Programirmg
Topicri1111
Topic name Object Onented Programming
Topic Match-First Simple Program
Topicid1113
Topic name Frst Simple Program теня
-
Fig.9. Efficient Search Based on Metadata Tree Algorithm
Get6ng started with С л17^тцедегяж!1"1*5М1*»в/5|$21е6^М*!яп1ге*лвб ^НеШ«1в[1ф№1е1тЫ1а^яп1е?1Ш411«^ ^j^yi6t^i^*ii*teetC5gee|rtett$|^Ae|eteert
Sj»»aoa weeieawiainn^mEwa^CiiteappeFOliftlrteBBttBPKi rtP/Hi^awfcemtirnMi«i«sf5it®h6^^^ лге ite ккаевае :>pi’jtofcsKairsMjsiMhieHJ 1314 *ядйк 11 Br“atsfta5dJ5W^e*uirair.»fterr:*:gtit?'sycKE)Bis?5zi:t* йя1Л»Ж5юае#Е!®^пкйи^»вдв1е:У^т?1 rteene егвзкР.
'jersiaaisKiSits
•5*
■Eatse
GeangSofciiitiC
(auat Fig.10. Display of Learning Content V. Performance of Metadata Service It explains an efficient Metadata (MD) management scheme for distributed file system of cloud computing. It minimizes the intercession of the manager and allows uninterrupted services. The Master Metadata Server (MMDS) [4] platform provides efficient metadata management by balancing the load and by reducing the network traffic by timely update. The Master Metadata Server (MMDS) and Metadata Look-up Table Server (MLTS) are placed between the metadata servers (MDS) and clients, which make it suitable for enhanced MD processing. It can adjust the loads of MDSs when choosing a more appropriate MDS from the selected MDSs. The MLTS efficiently update the MDSs. With MMDS and MLTS, the loads can be efficiently fair without increasing the traffic in the network. A. Taxonomic Indexing It explains an indexing structure named Taxonomic Indexing Trees (TItrees) [8] to efficiently manage documents. It is based on organizing the documents according to the metadata and representing the document by its structural information. All local TI-trees are merged into a global TI-tree. The two phases involved in this approach are Construction phase and a Search phase. In construction phase, TI-tree is generated for each local LOR. Then all TI-trees are merged into global TI-trees. When user submits their queries, the grid portal evaluates similarities with global tree and ranks the documents with transmission time. Thus users can choose suitable documents according to similarity and transmission time. In search phase the given keyword is searched from the contents. In search phase, the grid portal component receives query from users, process it and return results. When users specify documents from results, the portal access the site and retrieve the documents. When a user submits the query containing terms which do not match the vocabulary, portal suggests some synonym terms in vocabulary. A grid is a star graph G = The Query processing algorithm is used to search the global TI-tree for the top k relevant CPs with respect to a query given by a user. TI-tree construction algorithm, TI-merge algorithm, TI-insertion algorithm is discussed [27]. Analysis of storage requirements and time complexity can help us understand the performance of TI-trees. The storage requirement of a TI-tree structure is the product of the number of class nodes and the sum of storage required for a class node. B. Experimental Result The proposed searching algorithm with the available metadata for 3 subjects is tested and the results is shown, that for searching the domain it takes 87 milliseconds, for subject 80 ms, for chapter 73 ms and for topic 65 ms. This is shown in Fig.11. VI. Conclusion and Future Work The metadata management for E-learning objects in cloud the learning contents are created for a subject using eXe authoring tool and the corresponding metadata is also created. Two tables are created. One of the tables contains the student details and his username, password. Similarly the other table contains the teacher’s details along with their username and passwords. Metadata which contains the details of content describing metadata is created. This metadata is stored inside the repository within Learning Content Management System. Efficiently searching of learning content is done using the available metadata. On entering the keyword by the student, this keyword is matched with the contents in metadata and the complete details of the search content will be displayed. The learning objects which are created have to be stored inside the cloud storage resources. Metadata containing logical address of the learning content has to be mapped with the physical address to retrieve the appropriate content. Clustering approach for even more efficient searching can be done in future. Hierarchal approach can be adopted. Closely related entities will be in the nearby cluster. Locating contents can be done easily through this approach.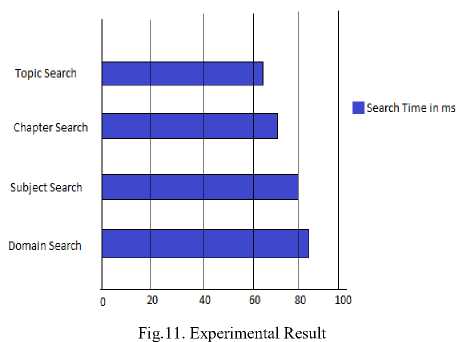
References Metadata Management System for E-learning Objects using Cloud
- Manpreet kaur, Hardeep Singh, "A Review of Cloud Computing Security Issues", International Journal of Modern Education and Computer Science(IJMECS), 2015, vol.5, no.4, pp. 32-41.
- Md. Imran Alam, Manjusha Pandey "A Comprehensive Survey on Cloud Computing", International Journal of Modern Education and Computer Science(IJMECS), 2015, vol.7, no.2, pp. 68-79.
- Irfan Sural, "Characteristics of sustainable Learning and Content Management System", "Procedia Social and Behavioral Sciences 9"Science Direct 2010, Vol. 9, pp. 1145-1152.
- Oliver Bohl, Dr. Jorg Schellhase, Ruth Sengler, Prof. Dr. Udo Winand,"Sharable Content Object reference model-a Critical review", International Conference on Computers in Education, IEEE 2002,Vol.2,pp. 950-951.
- Moo Chee Lee, Yun Kung Chung, "Using Object Orientation to Conceptualize an Adaptive Learning Content Management system modeling", International Conference on Advanced Computer Control, IEEE 2010, pp. 56-60.
- Myung Jin Hwang, Dae Gun Kim, Hee Yong Youn,"Enhancing the performance of Metadata Service for Cloud Computing", IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, IEEE 2010, pp. 402-405.
- Mohammed Al-Zoube, "E-Learning on the cloud", International Arab Journal of e-Technology, Volume 1, No 2, June 2009, pp. 58-64.
- Norman W.Y. Shao, Stephen J.H. Yang, Addison Y.S. Sue, "A Content Management system for adaptive eLearning", Fifth International Symposium on Multimedia Software Engineering, IEEE December 2003, pp. 206-214.
- Ashraf Zia, M.N.A. Khan, "A Scheme to Reduce Response Time in Cloud Computing Environment", International Journal of Modern Education and Computer Science (IJMECS), 2013, Vol.5, no.6, pp. 56-61.
- Shih, W.-C., Tseng, S.-S., & Yang, C.-T., "Using Taxonomic Indexing Trees to Efficiently Retrieve SCORM-compliant Documents in e-Learning Grids", Educational Technology & Society 2008, pp. 206-226.
- Li Zheng, Yintao Liu, Jing Wang, Fang Yang, "Multiple Standards Compatible Learning Resource Management", International Conference on Advanced Learning Technologies, IEEE 2008, pp. 657-661.
- Bernstein P A and Melnik, "Meta Data Management" Proceedings of the 20th International Conference on Data Engineering (ICDE'04), IEEE 2004, pp. 875.
- Scott A. Brandt Ethan, L. Miller Darrell, Long Lan Xue D.E, "Efficient Metadata Management in Large distributed Storage systems", Mass Storage Systems and Technologies, Proceedings 20th IEEE/11th NASA Goddard Conference , IEEE 2003, pp. 290-298.
- Chaitali Gupta, Madhusudhan Govindaraja, "Framework for Efficient Indexing and searching of scientific metadata", Cluster, Cloud and Grid Computing (CCGrid), 2010 10th IEEE/ACM International Conference on IEEE 2010, pp. 553-556.
- Bahman Rashidi, Mohsen Sharifi, Talieh Jafari, "A Survey on Interoperability in the Cloud Computing Environments", International Journal of Modern Education and Computer Science (IJMECS), 2013, vol.6, no.3, pp. 17-23.
- David Bregman, Isreal Dac, "Cloud Computing-the magical new ICT Paradigm for Academic X-learning", Seventh International Conference on ELearning for Knowledge based Society, December 2010.
- Yavuz Akpınar, Huseyin Simsek, "Development of a Learning Content Management System Based on Interactive Learning Object Approach", ITHET 6th Annual International Conference, July 2005.
- Jamal, S. M. Khalid, "Grid Approach with Metadata of Messages in Service Oriented Architecture", International Journal of Modern Education and Computer Science (IJMECS), 2014, vol.2, pp.64-71.
- P.Iyappan, V.Prasanna Venkatesan, "A Smart and Generic Secured Storage Model for Web based Systems", International Journal of Modern Education and Computer Science (IJMECS), 2014, vol.6, no.10, pp.48-56.
- Ronak Patel, Sanjay Patel. Survey on Resource Allocation Strategies in Cloud Computing. IJERT Vol. 2 Issue 2 Feb 2013, ISSN: 2278-0181.
- Aoun R, Doumith E.A, Gagnaire M, "Resource Provisioning for Enriched Services in Cloud Environment," IEEE Second International Conference on Cloud Computing Technology and Science, Feb. 2011, pp. 296- 303.
- Dikaiakos, M., katsaros, D., Mehra, P., Vakali, "A Cloud Computing: Distributed Internet Computing for IT and Scientific Research", in IEEE Transactions on Internet Computing, 2009, vol.5, no.13, pp. 10-13.
- C. Wang, N. Cao, J. Li, K. Ren, W. Lou, "Secure ranked keyword search over encrypted cloud data", IEEE International Conference on Distributed Computing Systems(ICDCS), 2010, pp. 253-262.
- Z. Xia, Y. Zhu, X. Sun and L. Chen, "Secure semantic expansion based search over encrypted cloud data supporting similarity ranking.", Journal of Cloud Computing, Springer 3.1, 2014, pp 1-11.
- P.Niranjan Reddy, Y.Swetha, "Techniques for Efficient Keyword Search in Cloud Computing", International Journal of Computer Science and Information Technologies, 2013, Vol. 4, no. 1, pp. 66 – 68.
- Y. Tao, J. Zhang, D. Papadias, and N. Mamoulis. An efficient cost model for optimization of nearest neighbor search in low and medium dimensional spaces. IEEE Trans. on Knowl. and Data Engineering, 2004, vol.16, no. 10, pp.1169–1184.
- Papadopoulos. A , Katsaros. D, "A-Tree: Distributed indexing of multidimensional data for cloud computing environments", DOI: 10.1109/CLoudcom.2011.61, pp.407-414.
