Methodology for solving problems of classification of appeals/requests of citizens to the “hotline” of the President of the Russian Federation

Author: Bunova E.V., Serova V.S.
Section: Информатика и вычислительная техника
Article in issue: 2 т.22, 2022.
Free access
The use of neural networks for the classification of text data is an important area of digital transformation of socio-economic systems. The article is devoted to the description of the methodology for classifying citizens' appeals. The proposed technique involves the use of a convolutional neural network. The stages of processing citizens' appeals in the amount of 7000 appeals are described. In order to reduce the dimension of the problem, methods of filtering and removing stop words were applied. The resulting data set allows you to choose the best classifier in terms of accuracy, specificity, sensitivity. Training and test samples were used, as well as cross-validation. The article shows the effectiveness of using this method to distribute requests on 15 topics of citizens' appeals to the “hotline” of the President of the Russian Federation. Automating the classification of received appeals by topic allows them to be processed quickly for further study by the relevant departments. The purpose of the study is automation of the distribution of citizens' appeals to the President's hotline by category based on the use of modern machine learning methods. Materials and methods. The development of software that automates the process of distributing citizens into categories is carried out using a convolutional neural network written in the Python programming language. Results. With the help of the prepared data set, the pre-trained model of NL BERT and sciBERT was trained by the deep learning method. The model shows an accuracy of 86% in the estimates of quality metrics. Conclusion. A pre-trained model was trained using a convolutional neural model using a prepared data set. Even if the forecast does not match the real category, the model gives a minor error, correctly determines the category of the appeal. The results obtained can be recommended for practical application by authors of scientific publications, scientific institutions, editors and reviewers of publishing houses.
Text processing, machine learning, convolutional neural networks, categorization of text, deep learning, text analysis
Short address: https://sciup.org/147237451
IDR: 147237451 | UDC: 004.85
Методика решения задач классификации обращений/запросов граждан на "горячую линию" Президента РФ
Применение нейронных сетей для классификации текстовых данных является важной сферой цифровой трансформации социально-экономических систем. Статья посвящена описанию методики классификации обращений граждан. Предлагаемая методика включает использование сверточной нейронной сети. Описаны этапы обработки обращений граждан в количестве 7000 обращений. С целью сокращения размерности задачи применены методы фильтрации, удаления стоп-слов. Полученный набор данных позволяет выбрать лучший классификатор по показателям точности, специфичности, чувствительности. Использованы обучающая и тестовая выборки, а также кросс-валидация. В статье показана эффективность использования данного метода для распределения запросов по 15 темам обращений граждан на «горячую линию» Президента РФ. Автоматизация классификации поступивших обращений по темам позволяет быстро их обработать для дальнейшей проработки соответствующих ведомств. Целью исследования является автоматизация распределения обращений граждан на горячую линию Президента по категориям на основе использования современных методов машинного обучения. Материалы и методы. Разработка программного обеспечения, автоматизирующего процесс распределения граждан по категориям, осуществляется с использованием сверточных нейронных сетей, написанных на языке программирования Python. Результаты. С помощью подготовленного набора данных предварительно обученная модель NL BERT и sciBERT была обучена методом глубокого обучения. Модель показывает точность 86 % в оценках показателей качества. Заключение. В ходе исследования с помощью подготовленного набора данных была обучена методом использования сверточной нейронной предобученная модель. Даже при несовпадении прогноза с реальной категорией модель дает незначительную ошибку, правильно определяет категорию обращения. Полученные результаты могут быть рекомендованы для практического применения авторами научных публикаций, научными учреждениями, редакторами и рецензентами издательств.
Text of the scientific article Methodology for solving problems of classification of appeals/requests of citizens to the “hotline” of the President of the Russian Federation
Е.В. Бунова, , В.С. Серова, , Южно-Уральский государственный университет, Челябинск, Россия
Currently, a lot of attention from the federal authorities and the leadership of the Russian Federation is paid to improving the “quality of life” of the population. In his Messages to the Federal Assembly, Russian President Vladimir Putin has repeatedly stated the need to improve the standard of living, ensure a decent, long life for Russians and improve its quality as the goal of the socio-economic development of the country and the implementation of National projects [1, 2]. The targets for improving the quality of life of Russians were formulated in Presidential Decree No. 204 of May 7, 2018 “On National goals and strategic objectives for the development of the Russian Federation for the period up to 2024” [3]. On July 13, 2020, at a meeting of the Council for Strategic Development and National Projects, Russian President Vladimir Putin said: “… we will discuss the key directions of the country's development, our further actions, and their main, unifying task is to improve the quality of life of citizens. I want to emphasize once again: a person should be at the center of all our decisions, plans, and programs” [4].
An important event held by the President of Russia V.V. Putin is the annual “hotline”, to which every citizen can send an appeal/request for solving urgent problems for him. So, for example, only in the Chelyabinsk region for a few days, about 4 thousand requests from citizens are received by the “hotline” of the President of the Russian Federation.
It is impossible to process these requests quickly using manual methods, and some appeals/requests from citizens require a quick response. Therefore, an urgent task is to develop a software application to automate the classification of incoming requests by topic and send these requests to the relevant structures that are authorized to solve the problems described by citizens.
This article describes the solution to the problem of classifying appeals /requests of citizens by topics, namely: COVID, Highways, Alimony, Banks and loans; Landscaping; Veterinary medicine; Water supply, Issues of remuneration and employment, Issues of pensions and retirement experience, Gas supply, Citizenship, Courtyards and common areas, Housing, Healthcare of the Russian Federation, Healthcare and medical care in the Chelyabinsk region.
These topics are the most popular, the number of requests/queries on these topics is about 70% of the total number of requests.
Currently, the following methods are most often used to classify text data by topic:
-
1. Define the document topic manually. The method is accurate, but usually has such a disadvantage as the inability to process large volumes in a sufficient amount of time, and there is also subjectivity in data processing. Manual classification is very limited in the ability to quickly process large arrays of texts, characteristic of many applications of automatic text classification methods. Such methods are widely used by modern Internet systems: news aggregators, such as the Yandex service.News or Google News to solve the problem of thematic classification of documents and news stories, email services, for example, Yandex.Mail, gmail, or Mail.ru use algorithms detect spam filter mail, search engines (Yandex, Google, Mail.ru, Yahoo and others) resolve the challenge of ensuring diversity of search results, etc. [5].
-
2. Determining the topic of the document automatically using the developed rules based on regular expressions. The method allows you to process large amounts of data, but requires efforts to develop and maintain the rules up to date. In addition, before defining the rules, a specialist is obliged to familiarize himself in depth with various data samples of all topics on which a large amount of time can be spent. The disadvantage of the described method is its high sensitivity to errors that may occur accidentally or systematically both during the digitization of the text and during its formation. It is the person who is the main factor of non-determinism when placing bibliographic information in texts [6].
-
3. Determining the topic of the document automatically using machine learning. When using this approach, the dependency of the theme on the sample is set automatically. Manual markup of the training sample is required beforehand, but this is often a simpler task than finding the rules for belonging to the topics of all samples. This approach is currently the most promising.
The direction of using machine learning is currently widely used. For example, machine learning is used in law enforcement agencies when employees receive tactical recommendations [7]. Artificial intelligence is already being introduced into medical institutions. For example, the processing of patient data, preliminary diagnosis and even the selection of individual treatment is implemented on the basis of information about a person's illness.
Implemented machine learning algorithms make predictions or make decisions not on the basis of strictly static program commands, but on the basis of a training sample, with the help of which the parameters of the model are adjusted. Various branches of mathematics are used for the process of setting up (fitting) a model based on data sampling: mathematical statistics, optimization methods, numerical methods, probability theory, linear algebra, mathematical analysis, discrete mathematics, graph theory, various techniques for working with digital data, etc. The result of the learning algorithm is a function that approximates (restores) an unknown dependence in the processed data.
When talking about machine learning, they often mean artificial neural networks (hereinafter – INS) and deep learning, which have become popular, which are machine learning models presented in Fig. 1, i.e. special cases of pattern recognition methods, discriminant analysis, clustering methods, etc.
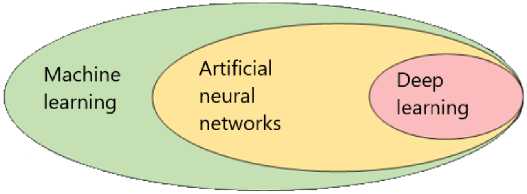
Fig. 1. Machine learning models
One of the machine learning models is INS. Currently, there is a revival of INS under the new brand “Deep Learning” (Deep Learning). So, in the article [8], with the help of deep learning, stroke risk factors are extracted from medical texts. Based on the results of the experiments, conclusions were drawn about the effectiveness of the developed methods and the text characteristics used to solve the problem.
A similar approach was used in the article [9] for clustering the corpus of documents in Russian. The results of applying the algorithms are demonstrated in the work on real data and show the high accuracy of the chosen method.
INS are hierarchical classifiers that are able to independently identify features in the original signal. A common indicator of the INS is the number of hidden layers. Some modern networks have hundreds or even thousands of hidden layers. There are a large number of INS architectures. Let's list the most popular of them.
Networks without feedbacks or direct signal propagation networks in which the signal passes from the outputs of the neurons of the i -th layer to the inputs of the neurons of the ( i + 1)-th layer and does not return to the previous layers:
-
- perceptrons (single-layer, multi-layer with cross-links, etc.), except perceptrons with feedbacks;
-
- Bayesian neural network;
-
- extreme learning machine;
-
- in fact, any INS that is a directed acyclic (without cycles) graph.
The article [10] reflects the disadvantages and advantages of these networks. The advantages of networks without feedbacks are the simplicity of their implementation and guaranteed receipt of a response after passing data through layers.
The disadvantage of this type of network is the minimization of the size of the network – neurons repeatedly participate in data processing.
Convolutional Neural Networks (SNN, Connews) , a distinctive feature of which is the convolution operation:
-
- AlexNet;
-
- LeNet-5;
-
- convolutional networks with region allocation (Region Based CNNs, R-CNN);
-
- deploying neural networks (deconvolutional networks, DN, DeConvNet) or reverse graphic networks, convolutional networks on the contrary.
In the article [11], the process of determining the subject of texts is automated using a convolutional neural network of deep learning.
The methods and tools used in the construction of a neural network for semantic classification of text are described in the article by authors V.I. Voronov and E.V. Martynenko [12].
The authors Y.V. Kotenko, S.A. Petrenko [13] described an approach to assessing the reliability of information posted on a social network. The reliability of information is considered from the point of view of its truth. It is proposed to evaluate the reliability of the information provided in the social network entry using classification algorithms. It is proposed to use convolutional neural networks to analyze the texts of records. The article also describes an algorithm for constructing and using a tool for assessing reliability, as well as possible options for its application.
Generative adversarial networks (hereinafter referred to as GAN), which consist of two competing INS: a generative model that generates samples, and a discriminative model that tries to distinguish correct (“genuine”) samples from incorrect ones. GAN is quite difficult to train, because the task is not just to train two networks, but also to maintain a balance, an equilibrium between them. If one of the networks (generator or discriminator) becomes much better than the other, then the GAN will not converge (learn).
The author U.D. Muratova [14] considered the development tools necessary for the implementation of an information system based on the analysis of text perception.
The disadvantage of GAN is the long process of learning the model [15].
Recurrent Neural Networks (SNN) or networks with memory . They contain neurons that can store information about their previous states during operation, such neurons receive information not only from the previous layer, but also from themselves as a result of the previous passage. Recurrent networks are the neural network embodiment of Markov chains. There are many architectures of recurrent INS:
-
- network with long-term and short-term memory (Long Short Term Memory, LSTM);
-
- fully recurrent network;
-
- recursive network;
-
- Hopfield neural network, a type of fully connected INS;
-
- Boltzmann machine and limited Boltzmann machine;
-
- Hamming neural network;
-
- Bidirectional associative memory (BAM) or Kosko neural network;
-
- bidirectional recurrent neural networks (bidirectional recurrent neural networks);
-
- Elman and Jordan networks;
-
- echo-networks and impulse (spike) neural networks;
-
- unstable state machines (liquid state machines, LSM);
-
- neural history compressor;
-
- recurrent networks of the second order;
-
- controlled recurrent neurons (Gated Recurrent Units, GRU);
-
- neural Turing machines (Neural Turing machines, NTM), etc.
In this article [16], recurrent neural networks are used in natural language text processing tasks.
The main disadvantage of these networks [17] is the lack of stability, and in cases when it is achieved, the network becomes equivalent to a single-layer neural network, which is why it is unable to solve linearly inseparable problems. As a result, the capacity of such networks is extremely small.
Convolutional neural networks have proven themselves well in the tasks of object recognition and machine vision. This has led to further research into the way they are applied, one of which is the task of classifying the text.
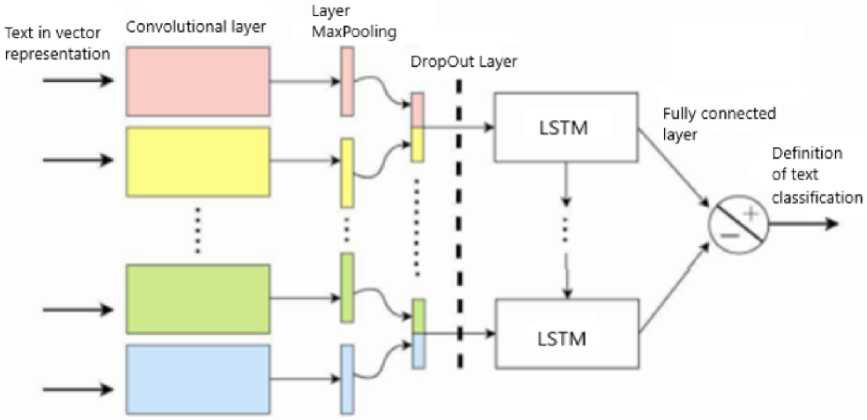
Fig. 2. Architecture of the designed neural network
To understand the architecture of the designed neural network, shown in Fig. 2, let's consider each layer separately:
-
- A convolutional layer is a layer that consists of a feature map, each map has its own core. The number of feature maps is determined by the requirements for the task, if you take a large number of maps, the accuracy of the model will increase, but the computational complexity will increase. The core is a filter or window that “slides” over the entire area of the previous map and finds certain signs.
-
- A subdiscretizing layer is a layer that performs a dimensionality reduction of the input feature map. The convolution layer has already identified some features, then for subsequent processing such a detailed feature map is no longer needed, and it is compacted to a less detailed one. In addition, filtering out unnecessary details helps to avoid retraining.
-
- A fully connected layer is a layer in which each neuron is connected to all the neurons on the previous layer, and each connection has its own weighting factor. In the Keras library, this layer has the name “Dense”.
-
- Dropout layer is a way to combat retraining in neural networks. This layer excludes a certain percentage (for example, 20%) of random neurons (located in both hidden and visible layers) at different iterations during neural network training. This technique significantly increases the learning rate, the quality of training on training data, and also improves the quality of model predictions on new test
data. In the architecture being developed, which is based on a convolutional neural network, cores of different sizes will be used, which are designed for parallel processing of the n-gram of text, respectively. After processing by convolution layers, feature maps arrive at the subdiscretization layers, which extract the most significant n-grams from the text. After that, it is combined into a common feature vector. Then the resulting vector is fed into a hidden fully connected layer. At the last step, the resulting feature map is fed to the output layer of a neural network with a sigmoidal activation function. The number of consecutive convolutional layers, the size of the cores of the convolutional layer and the subdiscretization is determined experimentally. Kernels of sizes 1, 2, 3, 4 and 5 are designed to process one word, bigrams, trigrams, 4-grams and 5-grams, respectively.
Let's consider a methodology for solving problems of classifying citizens' appeals/requests by topic, developed on the basis of a convolutional neural network.
The methodology for classifying citizens' appeals/requests by topic consists of the following stages :
Stage 1. Preliminary preparation of the data set.
When developing the classification model, data on appeals/requests of citizens to the “hotline” of the President of the Russian Federation living in the Chelyabinsk region were used. The number of requests/requests is about 7 thousand records.
Preparation of a set of this includes:
-
1. Clearing text data from unnecessary characters.
-
2. Converting text to lowercase.
-
3. Perform tokenization, normalization and filtering of text data.
Tokenization involves dividing the text into words in accordance with regular expressions, the specified template for which allows you to remove punctuation marks from the text. We will set the maximum number of tokens to be taken into account during processing, as well as the relative frequencies of token use that occur in the analyzed text. This allows you to exclude rare, as well as very frequently used words that will lead to the exclusion or retraining of the program. Solving the problem of normalization (lemmatization) allows you to bring the words selected as a result of tokenization to a normal form. Only single terminals of the analyzed text will participate in further processing.
To filter the data, a dictionary of words was created, shown in Fig. 3, which do not affect the definition of the category of treatment and were automatically removed without loss of semantic content from further processing of text data. The size of this dictionary is 28% of the total amount of text data.
гер1асе_7ОсаЬ={"аннотация" : " ",# словарик слов, которые не несут нагрузки
<рег5оп>ович" : " ", "<рег5оп>вна" : " ", здравствуйте" : "", "добрый день" : " ", "здравия желаю" : уважаемый" : " ", "ув " : " ", " с ув ":"", "вв": "
Сёмкина" Кустов" Любовь" Мажитова' Лопин" : Галайда"
"Азаркин "Клён" : ' "Валов" :
', "Лодвикова" : Червяковой Т Н" "Сагитова": " ",
"ТУРБАЛ" : ' "Будяк Надежда "Тишунова" : "
"Азаркин" : " ", ", "Червяковой О
"СЕМЬЯ НЕСВИТ" ' ", "Монахов" Твердохлеб" :
" ", "добрый вечер": " ", "Доброго времени суток": ", "Уважаемый Президент РФ" : " ",
: "
"Логовчина" Н" : " ",
’, "Землянская" "София" : " " Слущащ" : " ", ", "Чикалова"
Чикалова"
"Романов" : " Серго" : " ", " ", "Монахов'
"Здравст[
"Л В": "
", "Вера" "Харюшина"
врач Марьина
"В В Путей": " ", "Торбин " ", "Злоказова" : " ",
Щегликов"
: " ", "Мегрибан Гачай кызы" 'Фанизовна" : " ",
"Щегликова В М"
"Машина
**> "Трусов" : " ", , "Л П": " ", "Шумсп Надежда" : " ",
зовут меня" : года рождения Вызов № тел Очень хочется
"меня зовут" : " " ", "дата рождения"
представлюсь
моб тел " : " ", чтобы вы прочитали мое обращение"
"Очень надеюсь"
"Скажите пожалуйста"
"Спасибо" :
Заранее спасибо" : " ", "Дело в том что" : " ", "просьба" : " ", "Прошу помочь в
Очень прошу Вас решить эту проблему" :
Прошу разобраться" :
"Заранее большое спасибо'
"Спасибо за внимание'
"обращаюсь к вам с просьбой о помощи"
Я понимаю что у Вас много дел и Вы вряд ли будете заниматься этим сами
"просьба"
"Обратите внимание'
"Это же абсурд" , "прошу" : " "
"благод;
но может поручите кому нибудь разобраться с нашей п;
Fig. 3. A fragment of a dictionary of words that do not carry semantic words
Stage 2. Model training.
To conduct the training of the model, a dictionary of keywords was created to distribute citizens' appeals into 15 categories, which are the most in demand. The number of requests/queries on these topics is about 70% of the total number of requests.
A fr a g me nt of th e d ic t ion a ry is shown i n F ig . 4.
In [234]: def text_update_key(s):
vocab=['дороги', 'трамваи', 'рельсы', 'асфальт1, ’тросы', ’безопасность', ’пешеходы’, 'мост', ‘освещение’, ’отсыпка’, 'грейдЕ ’светофор1, ’придорожный1, ’сервис’, ’шум’, ‘реагенты', ’парковка’, ’подьездной’ 'путь', 'яма', 'общественный1, 'транс 'выхлопы', 'многодетная', 'семья', 'инвалид', 'ветеран', 'волонтеры', 'алименты', 'алиментщик', 'родительские', 'права', 'судебные', 'приставы', 'вкладчики', 'ипотека', 'мошенничество', 'накопления', 'каникулы', 'кредит', 'налог", 'вклад', 'девальвация', 'Сбербанк', 'обязательства', 'списание', 'пенсионные', 'взносы', 'комиссия', 'рефинансирование', 'заработная', 'плата', 'пирамида', ‘долг’, 'проценты', 'счет', 'сберегательная', 'книжка', ’банк', 'компенсация', 'потребительский', 'кооператив', 'карта', 'коллекторы', 'банкрот', 'наличные', 'индексация', 'благодарность', 'глава', 'города', 'губернатор’, ’благоустройство', 'околошкольная', 'территория', 'детская', 'площа; 'преображение", 'снег', 'мусор', 'деревья', 'памятник', 'чистить', 'поиск', 'работы', 'интернет', 'собак", 'пляж', 'городской', 'парк', 'аттракционы', 'радиочастотная', 'электромагнитная', 'антенна', 'зловоние', 'пи! 'вода', 'дворец', 'спорта', 'детский', 'садик', 'поликлиники’, ‘придомовая’, 'территория', 'облагораживание', "очистнь 'сооружения', "очистка1, ‘реки1, ‘канализации1, 'стоянки', 'автомобилей', 'тротуар', 'межевание', 'двора', 'незаконные 'лесной', ’массив', 'приют', 'выгул', 'пчелы', 'вода', 'трубы', 'водопровод', 'ЖКХ', 'водоснабжение', 'водоотведение', 'трудоустройство', 'инвалиды', 'работодатели', 'работа', 'индексирование', 'инфляция', 'пенсия', 'инвалидность', 'оплата', 'МРОТ', 'пособия', 'сокращение', ’РВП", 'вахтовый', 'метод', 'центр', 'занятости', 'бюджетники', 'неофициально', 'сокращение', 'социальная', 'польза', 'оклад', ‘прожиточный1, ’минимум", ‘трудовой1, ‘стаж’, "должность", ‘изобретательство’, ‘производство’, ‘цены1, ‘средний1, 'доход'.
-
Fig. 4. A fragment of the keyword dictionary
Next, we wil l a pp ly the a p ply () function of reducing all words to lowercase, the te xt_ update _k e y ( ) function to the e n ti r e ar ra y of t e xt data and the onlygoodsymbols() function usin g the a pp ly f unction, whi c h is u se d in ca ses when it is ne ce ss a r y to apply any function to all rows or columns of the matrix (or ar ra y s of la r g e r dime nsi on) . T he c ode of these function s i s shown in Fig . 5.
Х= X. apply (get_lower)|
Х= X.apply(text_update_key)
Х= X. apply{onlygoodsyfibols}
-
Fig. 5. Application of the apply function
-
F ig . 6 shows t he r esul t of thi s f unct ion .
: print(X.head())
-
0 лет города асфальт суд суд
-
6 ремонт
-
7 лет лет газ жилье
-
8 лет
-
9 тес детский
Name: Текст обращения, dtype: object
-
Fig. 6. A fragment of the processed data
We u se the t r ain_ te s t_sp li t module , shown in F ig . 7, o f t he Sc ik it-learn library, which is useful for s e par a t ing da t a sets, a nd to a v oid pr ob le ms with r etra in ing , we div ide the d a t a set:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split( X, y, tBst_s±26=6.1, stratify=y, random_state=42)|
-
Fig. 7. Using the train_test_split module
F ig . 8 re pre sents th e ou tput of th e first li ne fr om x_tr ai n.
In [244]: x_train[0]|
Out[244]: 'лет города асфальт суд суд'
-
Fig. 8. Output of the first line from x_train
To create a Sequential model, we import the libraries of optimizers Adam, RMSProp, SGD. First of all, the optimizer is a method of achieving the best results, helping to accelerate learning. In other words, it is an algorithm used to slightly change parameters such as weights and learning rate so that the model works correctly and quickly. It uses a first-order moment estimation and a second-order gradient moment estimation to dynamically adjust the learning rate of each parameter. The main advantage of Adam is that after correcting the bias, each iteration of the learning rate has a certain range, which makes the parameters relatively stable, also among the advantages of the optimizer can be distinguished: simple implementation, computational efficiency and small memory requirements. The RMSProp algorithm calculates only the corresponding average value, so this can alleviate the problem of the algorithm's rapid learning rate decrease. The stochastic Gradient descent (SGD) algorithm reads part of the data and immediately calculates the gradient of the cost function to update the parameters.
We also impor t t he ca l lba ck s class, shown in Fig. 9. Callback is a set of fu n c t io ns us e d a t c er tai n p oint s d ur i ng the t r aini ng pr oc edure. Callback functions are used to get inform a ti on about t he in te r n al s tate o f th e mode l during tra in ing . You ne e d to pass a list of callbacks (named with the callbacks argument) to t he me thod.f i t() Se que n tial or Model classes. Suitable callback methods will be ca l le d at e a c h stage of training.
-
Fig. 9. Importing optimizers and a class of callbacks.
Next, a Sequential m odel was created, which is a linear stack of layers that w e will a d d us ing t he .a dd( ) me thod, whe r e De n se ( 10 24), Dense(512), Dense(32) is a fully connected la y e r with 1024, 51 2 and 32 h idden ne u r ons, r es pe c t iv e ly . T h e ore t ic ally , th e numbe r of h idden la y e r s can be arbitrarily large. Then w e spec i f y the tra in i ng c onfiguration (optimizer, loss function, metrics). It is ne ce ss a r y to choose t he opt ima l size of the nu mbe r of training facilities (batcha). The model is traine d in t his wa y : spli t the data into “pa ckets ” of b a tc h_size size and sequentially iterate the entire dataset wit h a g iv e n numbe r o f “ e po c hs” . I t should be t a k e n into account that with large batch_size sizes, th er e ma y not be e noug h me mory on the v ide o c ar d, with too sma ll size s, tra in in g will b e unstable.
The cr e atio n o f a mode l a n d layers for it, as well as training with the optimize r RMS P r op i s show n in Fig. 10.
: model = Sequential()
model.compile(optimizer=RMSprop(momentum=:.9,learning_rate=.0061), loss=*categorical_crossentropy1, metrics=['acc’])
# print(mode L.summa ry())
-
Fig. 10. Creating and training a model
The pr o c e s s of lea r n ing the mode l, shown in F ig . 11, i s ta k ing pla ce .
Epoch 1/200
6/6 [===—======-—————==-—] - Is 51ms/step - loss: 2.0754 - acc: 0.1394 - val_loss: 2.0387 - val_acc: 0.2079 - In: 1.0 000e-04
Epoch 2/200
6/6 [==============================] - 0s 14ms/step - loss: 2.0207 - acc: 0.2047 - val_loss: 1.9600 - val_acc: 0.2944 - In: 1.0 000e-04
Epoch 3/200
6/6 [==============================] - 0s 16ms/step - loss: 1.9340 - acc: 0.2905 - val_loss: 1.8378 - val_acc: 0.3566 - In: 1.0 000e-04
-
Fig. 11. Model learning process
F ig . 12 shows the a c cura c y me tr ic s o f t he mode l tr ain in g .
-
# print ( пр, ar деюх (model, predict (xtest), axis--l)Jnp.argmax(y_testJ axis--1)) print(model.evaluate(x_test,y_test))
12/12 [==============================] - as 4ms/step - loss: 1.9722 - act: 9.8612 (1.0721339524336133, 9.8612921923063136]
In deep learning, loss is a value that a neural network tries to minimize: this is the distance between the true value and the predictions. To minimize this distance, the neural network learns by adjusting weights and offsets in such a way as to reduce losses, and the acc shows the percentage of instances that are correctly classified.
Thus, the evaluation of the quality of the model on the test sample is 86%.
The result of training the model. With a batch size of 512, the model under study needed 200 iterations (batches) for one training epoch.
Testing a trained model. Let's demonstrate how the model works on test data. To do this, we will create a separate csv file, which will contain 20% of the entire sample. The code for reading the file path is shown in Fig. 13.
-
Fig. 13. Reading the path to the test file
Let's output a list of requests. This list is shown in Fig. 14.
|
о |
obr |
|
0 ннотация дравствуйте формил кредит в овкомба...
1448 с моей семьей проживаю в г оркино елябинской... |
Name: Текст обращения, Length: 1453, dtype: object
-
Fig. 14. Output of requests in the test file
The result of training the model is shown in Fig. 15.
Q [4 5 1 ... 4 4 4] Льготы и соц. помощь Многоквартирные дома Вопросы пенсий и пенсионного стажа Многоквартирные дома Образование COVID Льготы и соц. помощь
Вопросы пенсий и пенсионного стажа Жилье
Жилье
Природа, Экология Жилье Образование Природа, Экология Вопросы пенсий и пенсионного стажа Льготы и соц. помощь
Conclusions
With the help of a prepared data set, a pre-trained model of NL BERT and sciBERT was trained by the deep learning method. The model shows an accuracy of 86% in the estimates of quality metrics.
The results obtained can be recommended for practical application by authors of scientific publications, scientific institutions, editors and reviewers of publishing houses.
References Methodology for solving problems of classification of appeals/requests of citizens to the “hotline” of the President of the Russian Federation
- Poslaniye Prezidenta Federal'nomu Sobraniyu 15 yanvarya 2020 goda [The President's Message to the Federal Assembly on January 15, 2020]. Available at: http://www.kremlin.ru/events/president/ news/62582 (accessed 20.12.2021). (In Russ.)
- Poslaniye Prezidenta Federal'nomu Sobraniyu 20 fevralya 2019 goda [The President's Message to the Federal Assembly on February 20, 2019]. Available at: http://www.kremlin.ru/events/president/ news/59863 (accessed 20.12.2021). (In Russ.)
- Ukaz Prezidenta Rossiyskoy Federatsii ot 07.05.2018 g. N 204 "O natsional'nykh tselyakh i strategicheskikh zadachakh razvitiya Rossiyskoy Federatsii na period do 2024 goda ". Vstupil v silu s 7 maya 2018 goda [Decree of the President of the Russian Federation No. 204 dated 07.05.2018 "On national goals and strategic objectives of the development of the Russian Federation for the period up to 2024". Entered into force on May 7, 2018]. Available at: http://www.kremlin.ru/acts/bank/43027 (accessed 20.12.2021). (In Russ.)
- Zasedaniye Soveta po strategicheskomu razvitiyu i natsional'nym proyektam 13 iyulya 2020 goda [Meeting of the Council for Strategic Development and National Projects on July 13, 2020]. Available at: http://www.kremlin.ru/events/president/news/63635 (accessed 20.12.2021). (In Russ.)
- Shagraev A.G. Modifikatsiya, razrabotka i realizatsiya metodov klassifikatsii novostnykh tekstov: avtoref. dis. kand. tekhn. nauk [Modification, development and implementation of methods of classification of news texts. Abstract of Cand. diss.]. Moscow; 2014. 19 p. (In Russ.)
- Sokolova T.A. An extraction of the elements from bibliography based on automatically generated regular expressions. Information and telecommunication technologies and mathematical modeling of high-tech systems: Materials of the All-Russian conference with international participation. Moscow; 2019. P. 313-316. (In Russ.)
- Ushakov O.V. [Application of automated information systems with machine learning integration in law enforcement agencies]. Problemy pravovoy i tekhnicheskoy zashchity informatsii. 2018;(6): 142-147. (In Russ.)
- Donitova V.V., Kireev D.A., Titova E.V., Akimova A.A. Natural language processing models for extraction of stroke risk factors from electronic health records. Trudy Instituta sistemnogo analiza Rossiyskoy akademii nauk = Proceedings of the Institute of system analysis of the Russian academy of sciences. 2021;71(4):93-101. (In Russ.) DOI: 10.14357/20790279210410
- Kolmogortsev S.V., Sarayev P.V. [Bibliography extraction from texts by regular expressions]. Novyye informatsionnyye tekhnologii v avtomatizirovannykh sistemakh. 2017;(20):82-88. (In Russ.)
- Gorbachevskaya E.N. Classification of neural networks. Vestnik Volzhskogo universiteta im. V.N. Tatishcheva. 2012;2(19):128-134. (In Russ.)
- Katenko Yu.V. Application of machine learning methods for text information analysis. Okhrana, bezopasnost', svyaz'. 2019;3(4):90-94. (In Russ.)
- Voronov V., Martinenko E. Research of parallel structures of neural networks for use in the tasks on the Russian text semantic classification considering limited computing resources (on the example of operational reports used in the RF MIA). Economics and Quality of Communication Systems. 2018;3(9):52-60. (In Russ.)
- Katenko Yu.V., Petrenko S.A. [The concept of control of the reliability of information in the professional social network using convolutional neural networks]. In: Mezhdunarodnaya konferentsiya po myagkim vychisleniyam i izmereniyam. Vol. 1. St. Petersburg; 2019. P. 140-143. (In Russ.)
- Muratova U.D. [Studying neural networks for chatbots]. In: Proceedings of the IX Congress of Young Scientists. St. Petersburg; 2021. P. 92-95. (In Russ.)
- Sukhan' A.A. Applying generative adversarial network to the problem of trend determenition. Moskovskiy ekonomicheskiy zhurnal. 2019;(6):180-191. (In Russ.) DOI: 10.24411/2413-046X-2019-16031
- Budyl'skiy D.V. [Application of recurrent neural networks in processing natural language texts]. Voprosy nauki. 2015;6:8-12. (In Russ.)
- Danchenko V.V. Overview of funds development of an information system based on analysis of text perception. Informatika iprikladnaya matematika. 2020;(26):31-34. (In Russ.)
