Методика построения программно-аппаратной системы локализации акустических сигналов

Автор: Шаход Д.М., Агафонов Е.Д.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 4 т.26, 2025 года.
Бесплатный доступ
В статье предложена методика построения программно-аппаратной системы для решения задачи локализации акустических источников в реальных акустических средах на основе синтеза нескольких моделей, в том числе интеллектуальных. Для достижения цели предлагается методика, включающая выбор технологий и оборудования для сбора и обработки акустических сигналов, обучение моделей на экспериментальных данных и проведение дополнительной серии экспериментов для оценки эффективности моделей. Были рассмотрены две модели: SI-GCC-CNN (Sound Intensity – Generalized Cross-Correlation – Convolutional Neural Network), которая основана на объединении признаков интенсивности звука и обобщенной кросс-корреляции – фазового преобразования в качестве входных данных для сверточных нейронных сетей, и SI-CNN (Sound Intensity – Convolutional Neural Network), которая основана на подаче признаков интенсивности звука в сверточную нейронную сеть. В рамках оценки эффективности моделей глубокого обучения, используемых для решения этой задачи с пространственным разрешением 10º, была проведена серия экспериментов в замкнутых реверберирующих помещениях. Обобщающая способность этих моделей оценивалась при изменении настроек конфигурации. Экспериментальные результаты продемонстрировали эффективность и способность модели SI-GCC-CNN к обобщению при работе в условиях реальной акустической среды. Модель SI-GCC-CNN превзошла модель SI-CNN, достигнув улучшения точности локализации в 2,9 раза при изменении размера помещения, в 2,5 раза при изменении расстояния между источником и центром микрофонной решетки и в 2 раза при изменении местоположения микрофонной решетки.
Программно-аппаратная система, локализация акустических источников, реальные акустические среды, акустическая интенсивность, глубокое обучение, реверберирующее помещение, обобщающая способность
Короткий адрес: https://sciup.org/148332523
IDR: 148332523 | УДК: 004.032.26, 004.048 | DOI: 10.31772/2712-8970-2025-26-4-507-516
Methodology for constructing a software-hardware system for localizing acoustic signals
This article proposes a methodology for constructing a software-hardware system for solving the problem of sound source localization in real acoustic environments based on the synthesis of several models, including intelligent ones. To achieve this goal, a methodology is proposed that includes the selection of technologies and equipment for collecting and processing acoustic signals, training models on experimental data, and conducting an additional series of experiments to evaluate the effectiveness of the models. Two models were considered: SI-GCC-CNN (Sound Intensity – Generalized Cross-Correlation Convolutional Neural Network), which combines sound intensity features and a generalized crosscorrelation phase transform as input to convolutional neural networks, and SI-CNN (Sound Intensity – Convolutional Neural Network), which feeds sound intensity features into a convolutional neural network. To evaluate the effectiveness of the deep learning models used to solve this problem at a spatial resolution of 10º, a series of experiments were conducted in closed reverberant rooms. The generalization ability of these models was assessed by varying configuration settings. The experimental results demonstrated the effectiveness and generalization ability of the SI-GCC-CNN model when working in real-world acoustic environments. The SI-GCC-CNN model outperformed the SI-CNN model, achieving a 2.9x improvement in localization accuracy when changing the room size, 2.5x when changing the distance between the source and the center of the microphone array, and 2x when changing the location of the microphone array.
Текст научной статьи Методика построения программно-аппаратной системы локализации акустических сигналов
Задача локализации акустических источников (Sound Source Localization, SSL) заключается в определении направления, с которого принимаются акустические волны, исходящие от источника звука. Обычно это достигается с помощью микрофонной решетки, которая улавливает акустические сигналы. Пространственно-временная информация, полученная от решетки, затем анализируется для нахождения направления акустического источника.
SSL играет важнейшую роль в различных инженерных и технологических приложениях, включая громкую связь [1], автоматическое слежение за камерой для телеконференций [2], взаимодействие человека с роботом [3] и удалённое распознавание речи [4]. В большинстве практических ситуаций направление акустического источника неизвестно и требует оценки. Эта задача становится ещё сложнее, когда её приходится решать в реальных акустических условиях, характеризующихся наличием шума и реверберации.
На сегодняшний день задача локализации акустических источников решается двумя группами методов: традиционными методами обработки сигналов и методами глубокого обучения (Deep Learning, DL). Традиционные методы, включая классификацию множественных сигналов (Multiple Signal Classification, MUSIC) [5], метод разности во времени приема сигнала (Time Difference of Arrival, TDOA) [6], формирователь луча с задержкой и суммированием (Delay-And-Sum beamformer, DAS) [7], обобщенную функцию взаимной корреляции с функцией преобразования фазы (Generalized Сross-Correlation – Phase Transform GCC – PHAT) [8] и управляемое фазово-энергетическое преобразование (Steered Response Power – Phase Transform SRP – PHAT)
-
[9], были разработаны в рамках парадигмы распространения звука в свободном поле, поэтому они имеют недостаток в виде серьезного ухудшения их эффективности при применении в замкнутых акустических средах со сложными характеристиками, т. е. в сценариях реверберации и шума [10].
Методы глубокого обучения способны превзойти традиционные методы в их устойчивости к шуму и реверберации за счет эффективной адаптации к различным сложным акустическим условиям, предоставленным в виде признаков в обучающих данных [11]. Однако это также является основным недостатком интеллектуальных методов, поскольку они менее способны к обобщению и менее универсальны, чем традиционные методы [10].
В [12] была предложена новая модель SI-GCC-CNN для локализации единственного источника с пространственным разрешением 10º. Модель SI-GCC-CNN основана на объединении признаков интенсивности звука (Sound Intensity, SI) и GCC-PHAT в качестве входных данных для сверточных нейронных сетей (Convolutional Neural Network, CNN). Модель достигла 100 % точности прогнозирования (локализации) в замкнутых реверберирующих средах, превзойдя модель SI-CNN [13], которая основана на использовании признаков SI в качестве входных данных для CNN.
В [12] обе модели SI-GCC-CNN и SI-CNN были обучены на синтетических (искусственных) данных, а затем была проверена их эффективность, в отличие от [14], где предложенная модель обучалась на реальных экспериментальных данных и, таким образом, не было необходимости повторять эксперименты, требующие интенсивных усилий по сбору большого объема данных для обучения моделей. В [15] показано, что разработанная модель SI-GCC-CNN способна к обобщению при изменении настроек конфигурации, а именно, при изменении размера помещения, расстояния между источником и центром микрофонной решетки и местоположения микрофонной решетки, что, в свою очередь, требует проверки ее способности обрабатывать несоответствия и различия между условиями моделирования и реальной среды путем проведения серии реальных экспериментов.
Фактически в [12; 15] сигналы микрофонов формировались с учетом линейного описания модели распространения звука в окружающей среде, а затем модели локализации были построены и обучены на входных данных, представленных признаками, извлеченными из сигналов микрофонов. Это означает, что процесс обучения не был выполнен на реальных данных, представленных условиями работы в реальных средах. Таким образом, проверка надежности и способности моделей локализации работать с реальными данными на основе серии экспериментов в условиях реальных помещений является актуальной .
Результаты проведения серии экспериментов позволят судить о гибкости разработанных моделей и возможности их практического применения во многих областях техники и технологий без ограничений по настройкам конфигурации.
Цель работы – построение программно-аппаратной системы для проведения реальных экспериментов и оценки эффективности моделей SI-GCC-CNN и SI-CNN в помещениях разных размеров и при разных настройках конфигурации.
Структурная схема установки и выбор технологий и оборудования для сбора и анализа акустических данных
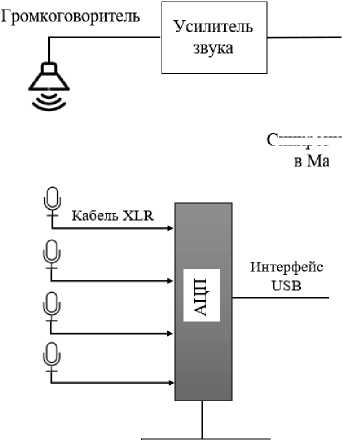
На рис. 1 представлена структурная схема экспериментальной установки. Для преобразования входного аналогового сигнала (сигнала микрофона) в его дискретное числовое представление используется аналого-цифровой преобразователь (АЦП), представленный внешней звуковой картой BEHRINGER UMC204HD с частотой преобразования 44100 отсчетов в секунду и разрядностью 24 бита. Интерфейс USB (Universal Serial Bus) типа B необходим для соединения компьютера с устройством BEHRINGER UMC204HD и далее для сбора и обработки информации. Профессиональные микрофоны BM - 800 JBH с кабелем XLR используются для подключения к входам звуковой карты.
Для устранения электрических помех также используется заземляющий фильтр, подключаемый к корпусу устройства АЦП через заземляющий контакт.
Компьютер
Компьютер
Фильтр с заземлением
Синхронизация
240 В
Рис. 1. Структурная схема экспериментальной установки
Fig. 1. Structural diagram of the experimental setup
В составе экспериментальной установки была использована микрофонная решетка размером 20 см, состоящая из четырех ортогональных микрофонов (рис. 2), аналогичная той, которая применялась при моделировании для формирования исходных данных и обучения моделей [12], Микрофонная решетка была размещена на высоте 1,5 м от пола.

Рис. 2. Микрофонная решетка
Fig. 2. Microphone array
В точках с заранее известными направлениями в горизонтальной плоскости решетки на высоте 1,5 м (рис. 3) размещается громкоговоритель (динамик) в качестве источника звука, который в свою очередь излучает аудиосигналы, взятые из базы данных TIMIT [16] с частотой дискретизации 16 кГц и длительностью 500 мс. Микрофоны принимают аудиосигналы, которые записываются с помощью программной среды MATLAB. Записанные аудиосигналы передискретизиру-ются с 44100 Гц до 16 кГц для соответствия характеристикам исходных данных моделей и фильтруются с помощью фильтра верхних частот (ФНЧ), который пропускает сигналы с частотой выше определенной частоты среза и ослабляет сигналы с частотами ниже частоты среза. Выбор частоты среза 100 Гц обеспечивает подавление фонового шума частотой 50 Гц.
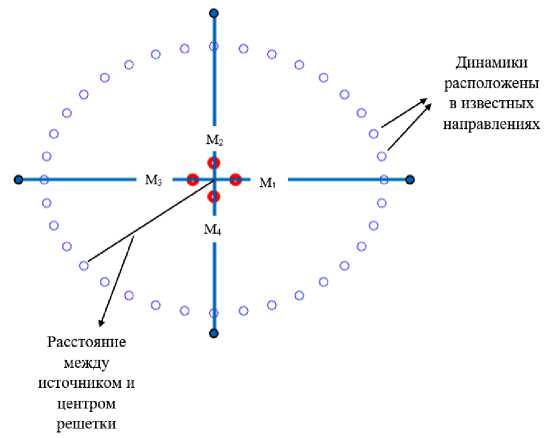
Рис. 3. Схема расположения громкоговорителей
Fig. 3. Speaker layout diagram
В [13] было показано, что размер решетки оказывает схожее влияние на все используемые методы локализации, включая предложенный в [13], основанный на использовании информации об акустической интенсивности в качестве входных данных. Эффективность локализации ухудшается, когда размер решетки слишком мал или слишком велик. Одна из причин ухудшения эффективности заключается в том, что признаки акустической интенсивности основаны на конечной разности сигналов акустического давления для аппроксимации скорости частицы с использованием ортогональной микрофонной решетки, как показано в [12]. В результате, по мере увеличения размера решетки, погрешность аппроксимации будет соответственно увеличиваться, что приведет к неточной оценке акустической интенсивности. С другой стороны, если размер решетки слишком мал, микрофонная решетка будет демонстрировать плохую чувствительность к шуму, особенно на низких частотах [17]. Также в [13] показано, что оптимальный диапазон размеров решетки для предложенного метода составляет 2–5,5 см, в то время как эффективность метода GCC-PHAT-CNN, основанного на использовании признаков GCC-PHAT в качестве входных данных, при малом размере решетки была значительно хуже, чем у аналогов, и лучше, чем у аналогов для относительно большого размера решетки, т. е. при размере 40 см.
Таким образом, для достижения согласованности размеров решетки, используемой в предлагаемом методе, и получения хороших результатов локализации, как при моделировании, так и при экспериментах, использовалась решетка размером 20 см.
Обучение моделей на экспериментальных данных
При конкретных настройках конфигурации обе модели, SI-GCC-CNN и SI-CNN, ранее обученные на синтетических данных [12], заново обучаются на реальных экспериментальных данных. Обе модели рассматриваются для локализации единственного источника с пространственным разрешением 10º.
Процесс сбора экспериментальных необработанных данных осуществляется в помещении размером 5,7×8,7×3,2 м3, где центр микрофонной решетки расположен в центре помещения в точке с координатами [2.85, 4.35, 1.5] м, а источники звука находятся на расстоянии 2 м от центра решетки.
Для каждого из 36 направлений из обучающего набора базы данных TIMIT случайным образом выбирается 10 аудиофайлов для воспроизведения через громкоговоритель, акустические сигналы принимаются микрофонной решеткой и записываются. Записанные сигналы представляют собой необработанные данные, из которых извлекаются признаки и обучаются модели.
Процесс подготовки данных и извлечения признаков, а также настройка обучения и гиперпараметры модели такие же, как при обучении на синтетических данных в [12].
Предварительная обработка данных, включая подготовку исходных данных и извлечение признаков, выполнялась в среде MATLAB R2020a. Затем модели глубокого обучения были построены с использованием Python 3.* в облачной вычислительной среде Google Colab. Этот гибридный подход использовал широкие возможности MATLAB по обработке сигналов для последующего проектирования признаков, а также обширную экосистему глубокого обучения Python для построения моделей.
Планирование и проведение серии экспериментов
Для оценки эффективности моделей и их способности к обобщению в условиях, отличающихся от тех, в которых они были обучены, проведена серия экспериментов. В табл. 1 показаны настройки конфигурации для каждого эксперимента.
Настройки конфигурации для экспериментов
Таблица 1
|
№ эксперимента |
Размер помещения [м3] |
Координаты центра микрофонной решетки [м, м, м] |
Расстояние между источником и центром микрофонной решетки [м] |
|
1 |
5,7×8,7×3,2 |
[2.85, 4.35, 1.5] |
2 |
|
2 |
9×7×3,2 |
[4.2, 3.5, 1.5] |
2 |
|
3 |
9×7×3,2 |
[4.2, 3.5, 1.5] |
3 |
|
4 |
9×7×3,2 |
[2.6, 4.7, 1.5] |
2 |
Для каждого эксперимента рассматриваются 36 направлений, равномерно распределенных в диапазоне –180º – 180º с шагом 10º .
Для каждой из настроек конфигурации, соответствующих каждому эксперименту, из тестового набора базы данных TIMIT выбираются 108 аудиофайлов таким образом, что каждому из 36 направлений соответствуют 3 аудиофайла, которые воспроизводятся с помощью громкоговорителя. Затем записываются акустические сигналы, соответствующие каждому известному направлению. Признаки извлекаются из исходных данных и подаются в обученные модели, которые, в свою очередь, оценивают направления акустических источников.
Для оценки эффективности моделей используется метрика точности локализации (localization accuracy, PA) [18].
В табл. 2 приведены средние значения метрики точности локализации для моделей SI-CNN и SI-GCC-CNN при проведении серии экспериментов.
В эксперименте № 1 эффективность моделей проверялась в той же комнате, в которой модели обучались, при сохранении тех же настроек конфигурации, в то время как в остальных экспериментах настройки конфигурации были изменены и ранее обученные модели были повторно протестированы для проверки их способности к обобщению.
Таблица 2
Средние значения метрики точности локализации для моделей SI-CNN и SI-GCC-CNN при проведении серии экспериментов
|
№ эксперимента |
SI-CNN (%) |
SI-GCC-CNN (%) |
|
1 |
70,37 |
94,44 |
|
2 |
29,6 |
86,1 |
|
3 |
32,4 |
80,6 |
|
4 |
41,7 |
83,3 |
В эксперименте № 1 предложенная модель достигла точности локализации 94,44 %, превзойдя модель SI-CNN, достигнув улучшения на 34,2 %.
В остальных экспериментах проверялась способность моделей к обобщению при изменении настроек конфигурации.
При изменении размера помещения (эксперимент № 2) модель SI-GCC-CNN продемонстрировала свою способность к обобщению, достигнув точности локализации 86,1 %, превзойдя модель SI-CNN, достигнув улучшения в 2,9 раза, в то время как модель SI-CNN не обеспечила удовлетворительных результатов, которая в свою очередь достигла точности локализации 29,6 %.
В эксперименте № 3 были сохранены те же настройки конфигурации размера помещения и расположения микрофонной решетки, что и в эксперименте № 2, но расстояние между источником и центром микрофонной решетки было изменено на 3 м. Модель SI-GCC-CNN показала свою обобщающую способность, достигнув точности локализации 80,6 %, в то время как модель SI-CNN не обеспечила удовлетворительной точности локализации, достигнув 32,4 %. Модель SI-GCC-CNN превзошла модель SI-CNN, обеспечив улучшение точности локализации в 2,5 раза.
В эксперименте № 4 были сохранены те же настройки конфигурации размера помещения и расстояния между источником и центром микрофонной решетки, что и в эксперименте № 2, но координаты центра микрофонной решетки были изменены. Модель SI-GCC-CNN показала свою обобщающую способность, достигнув точности локализации 83,3 %, в то время как модель SI-CNN не обеспечила удовлетворительной точности локализации, достигнув 41,7 %. Модель SI-GCC-CNN превзошла модель SI-CNN, обеспечив улучшение точности локализации в 2 раза.
Заключение
В работе предложена методика, в рамках которой построена программно-аппаратная система для оценки эффективности моделей локализации акустических источников с пространственным разрешением 10º при работе в реальных акустических средах. Для этого была проведена серия экспериментов, в которых как модель SI-GCC-CNN, так и модель SI-CNN сначала обучались на реальных экспериментальных данных в конкретном помещении, а затем оценивалась их способность к обобщению при изменении настроек конфигурации.
Экспериментальные результаты подтверждают надежность и эффективность модели SI-GCC-CNN для работы в условиях реальной акустической среды, что согласуется с результатами моделирования, полученными в [15]. Таким образом, можно сказать, что эффективность модели SI-CNN ухудшилась по сравнению с ее эффективностью при применении к синтетическим данным, в то время как модель SI-GCC-CNN практически сохранила свою эффективность при работе как с синтетическими, так и с экспериментальными данными. Это можно объяснить тем, что при обучении и тестировании обеих моделей на синтетических данных учитывалась линейная модель распространения звука, поскольку эхо-информация была включена в обучающие и тестовые данные без учета наличия шума. В то время как при обучении и тестировании обеих моделей на реальных данных в обучающие данные включалась не только информа- ция об эхосигналах, но и информация о шуме, поскольку предложенная модель показала эффективную устойчивость к шуму по сравнению с моделью SI-CNN.
Следует также отметить, что объём синтетических данных, на которых обучались модели, превышает объём реальных данных, поскольку в качестве необработанных синтетических данных использовалось 6000 аудиофайлов, по сравнению с 360 аудиофайлами, использованными в качестве необработанных реальных данных.
Дальнейшие исследования предполагают проведение серии экспериментов для оценки эффективности модели SI-GCC-CNN, использованной в [18] c методом разделения акустических источников, для одновременной локализации двух перекрывающихся источников звука в реальной акустической среде.
