Методика статического анализа для поиска дефектов естественной семантики программных объектов и ее программная реализация на базе инфраструктуры компилятора LLVM и фронтенда Clang

Автор: Викторов Д.С., Жидков Е.Н., Жидков Р.Е.
Журнал: Журнал Сибирского федерального университета. Серия: Техника и технологии @technologies-sfu
Статья в выпуске: 7 т.11, 2018 года.
Бесплатный доступ
В статье описывается методика статического анализа для поиска функциональных дефектов программ, разработка которой обусловлена необходимостью создания качественного отечественного программного обеспечения автоматизированных систем военного назначения в условиях временных и финансовых ограничений процесса разработки. Использование статического анализа позволит автоматизировать процесс выявления дефектов и упростит их локализацию в рамках мероприятий процесса верификации, при этом приоритетным объектом проверок должно быть специальное программное обеспечение вновь создаваемых автоматизированных систем ввиду своей эксклюзивности, масштабности и логической сложности. Предлагается подход, основанный на контроле выполнения принципа размерной однородности физических уравнений, представленных в программе, для чего идентификаторам программных объектов назначается неизменный признак в виде вектора физической размерности интерпретируемой величины. Совокупность всех векторов образует семантический домен, используемый при проверке соотношений между программными объектами по аналогии с анализом зависимостей при абстрактной интерпретации...
Автоматизированные системы, программное обеспечение, программный объект, верификация, статический анализ, функциональные дефекты, абстрактное синтаксическое дерево
Короткий адрес: https://sciup.org/146279548
IDR: 146279548 | УДК: 004.43 | DOI: 10.17516/1999-494X-0095
Static analysis technique for searching natural semantic defects of program objects and software implementation of this approach based on the LLVM compiler infrastructure and the Clang frontend
The article proposes a static analysis technique for searching functional software defects. Development is caused by the need to create high quality domestic military automated system software in conditions of temporary and financial constraints. The use of static analysis makes it possible to automate the process of error detection and it allows to localizing defects simply. The priority object of inspections should be special software for newly created automated systems because it is exclusively, scale and logical complexity. An approach based on controlling the implementation of principle of dimensional homogeneity of the physical equations presented in the software. For this purpose, program objects identifiers are assigned an invariable attribute in the form of a physical dimension vector of interpreted value. The set of all vectors forms a semantic domain used in verifying the relationships between program objects by analogy with the analysis of dependencies in the abstract interpretation. The technique uses a program internal representation for calculations of derivate vectors on the basis of operations with initial program objects. The software implementations uses the LLVM compiler and Clang frontend to translate code in C, C++, Objective-C. Clang API internal representation in the form of abstract syntax tree is modified to store data about program objects vectors.
Текст научной статьи Методика статического анализа для поиска дефектов естественной семантики программных объектов и ее программная реализация на базе инфраструктуры компилятора LLVM и фронтенда Clang
Статический анализ (СА), применяемый в рамках верификации программного обеспечения, зарекомендовал себя высокоэффективным методом, позволяющим снижать суммарные трудозатраты на поиск и локализацию дефектов ПО и, как следствие, уменьшать стоимость разработки за счет значительной степени автоматизации процедуры его проведения при наличии достаточных вычислительных ресурсов [2, 3]. Кроме того, возможность применения СА во время кодирования позволяет сокращать до пяти раз стоимость исправления дефектов ПО в сравнении с этапом тестирования, что дополнительно актуализирует необходимость использования анализаторов [1].
Выигрыш в снижении трудозатрат на верификацию ПО может быть увеличен за счет расширения характерного для СА множества обнаруживаемых дефектов, которое в основном образовано нефункциональными дефектами (НФД) [4]. Примерами НФД для наиболее востребованных языков программирования С и C++ , используемых при создании ПО автоматизированных систем (АС) военного назначения (ВН), являются: использование неинициализированного (освобожденного) указателя или указателя на NULL, утечка ресурсов, выход за границы статических и динамических объектов и др.
В настоящее время основным методом обнаружения функциональных дефектов (ФД), которые являются следствием нарушений спецификации функциональных возможностей программной системы, признано тестирование [5]. Данный подход в общем случае не может быть автоматизирован, а с ростом размера и сложности программ, при выполнении требования о полном тестовом покрытии, становится высоко трудоемким, кроме того, требующим тратить дополнительные силы на локализацию причин невыполнения теста [2]. Следовательно, актуальна задача поиска альтернативных решений для выявления ФД с использованием менее трудоемких способов, например методик СА.
Нарушение требований функциональности ПО АС ВН зачастую связано с искажением алгоритмов СПО, реализующих информационно-расчетные задачи (ИРЗ), что выражается не только в нарушении порядка вычислений (дефекты в уловных и циклических конструкциях), но и в ошибочной записи вычисляющих выражений в операторах программы (подмена истинных значений операций и операндов). Для ряда АС ВН, СПО которых оперирует данными с ясным физическим смыслом, проверку программ на отсутствие дефектов первого и второго видов возможно организовать по принципу размерной однородности физических уравнений ИРЗ.
Обнаруживаемые вышеуказанным способом дефекты предлагается называть дефектами естественной семантики (ДЕС) программных объектов (переменных, функций, полях и методах классов) с целью акцентировать внимание на их различную природу с семантическими дефектами, вызываемыми нарушением требований спецификации языка программирования.
Применение СА в качестве инструмента для поиска ФД возможно реализовать по аналогии с анализом зависимостей между программными объектами при абстрактной интерпретации, где для описания состояния программы используется подмножество логических утверждений, описывающих состояние объектов программы в текущий момент времени. Возможные предикаты разбиваются на утверждения о значениях объектов и утверждения о зависимостях между ними. Домен возможных значений программных объектов выбирается в соответствии с решаемой задачей [6].
Под размерностью физической величины понимается выражение, показывающее ее связь с основными величинами выбранной системы физических величин [7]. В Международной системе величин (СИ) в качестве основных выбраны: длина ( L ), масса ( M ), время ( T) , электрический ток ( I ), термодинамическая температура ( 0 ), количество вещества ( N) и сила света ( J ). А в качестве дополнительных – две безразмерные величины: плоский ( α ) и телесный угол ( Q ). Таким образом, размерность произвольной физической величины ( A ) возможно записать в виде произведения степеней сомножителей, соответствующих семи основным физическим величинам и двум дополнительным, в которых опущены численные коэффициенты: dim(A) = L e Me 2 T 3 Iе 4 0е 5 Ne 6 Je 7 a e3 Qe 9 , где e j - степень j -го сомножителя формулы размерности физической величины. Если зафиксировать порядок сомножителей в указанной выше формуле, то для описания размерности будет достаточно вектора, состоящего только из степеней этих сомножителей.
Применительно к рассматриваемой задаче программным объектам ставится в соответствие размерность интерпретируемой в них физической величины, такие утверждения относительно свойств программных объектов имеют точный характер и представляются в виде вектора естественной семантики (ВЕС): vobj = e 1 х e 2 х...х e 9 , e е Q , где e - степень сомножителя формулы размерности физической величины, интерпретируемой в программном объекте; Q – множество рациональных чисел.
Совокупность возможных ВЕС образует пространство ( V) , которое используется в качестве семантического домена. Формирование домена происходит из внешних источников на основании данных о программных объектах. В данном пространстве естественным образом заданы операции поэлементно сложения и умножения на скаляр, исходя из операций со степенями сомножителей:
s l + s 2 ( e ll + e 21 , e 12 + e 22 ,..., e 19 + e 29,), s P s 2 ^ ^ ;
X s = ( X e 1 ,Xe 2 ,...,Xe 9 ,), Xe Q , s e 5 .
Представленные операции удовлетворяют основным аксиомам линейного пространства, что позволяет говорить о принадлежности к рассматриваемому пространству ВЕС, являющихся результатом выполнения заданных операций.
Связь между программными объектами осуществляется через значения их ВЕС ( νobj ) и имеет различный характер:
арифметические зависимости: arith ( v Ob , v^ , 8 , v Ob ) : v Ob = v^ 8 v Ob , где 8 е {+, -} - арифметическая операция с ВЕС;
зависимости сравнения: comp ( v Ob , О , v^ ) : v Ob 0 v^ , где О е {=, ^} - операция сравнения ВЕС.
Выбор промежуточного представления ИК программы
СА развился из теории компиляторов и потому тесно связан с принципами их работы, где для генерации кода на целевом языке могут использоваться различные промежуточные представления программы: дерево разбора (ДР), абстрактное синтаксическое дерево (АСД), граф потока управления (ГПУ) и др. [8].
Для анализа достижимости используется ГПУ, который показывает множество всех возможных путей исполнения программы, при этом узлы графа соответствуют базовым блокам – прямолинейным участкам кода без операций передачи управления и точек, принимающих управление из других частей программы. Такое представление программы исключает возможность работы с вычисляющими выражениями, необходимыми для поиска ДЕС.
Результатом грамматического анализа является ДР (иногда конкретное синтаксическое дерево), применительно к решаемой задаче оно имеет избыточную структуру, показывающую последовательность применяемых при разборе кода синтаксических правил, которые не отражают семантику исследуемой программы.
АСД представляет собой конечное помеченное дерево, в котором внутренние вершины обозначены операторами языка программирования, а листья - соответствующими операндами. Эта структура данных сохраняет семантику исходной программы, не перегружена особенностями применения синтаксических правил и может формироваться уже на второй стадии трансляции - синтаксическом анализе. При этом обход дерева позволяет производить вычисления выражений в терминах исходной программы (идентификаторы программных объектов). Вышесказанное в совокупности предопределяет использование АСД в качестве промежуточного представления программы при поиске ДЕС.
Для организации работы с ВЕС требуется в АСД ( NS ) хранить дополнительную информацию о программных объектах, для чего предлагается модифицированная структура узла ( n ), представляющая из себя шестерку:
n = m n , , v n , P n , a n , f n , C n , , p)Y (1)
где mn e LS - метка узла; vn e VS - ВЕС программного объекта; pn e NS - ссылка на «родительский» узел; a n – счетчик количества заходов в узел при обходе АСД; f n – признак наличия дефекта в узле; ( C n , V) - упорядоченное множества «потомков» узла, представленного непосредственно самим множеством Cn с N S , а также отношением порядка ^ на Cn . Далее по тексту упорядоченное множество «потомков» ( C n ,^) для упрощения будем обозначать Cn .
Методика СА для поиска ДЕС
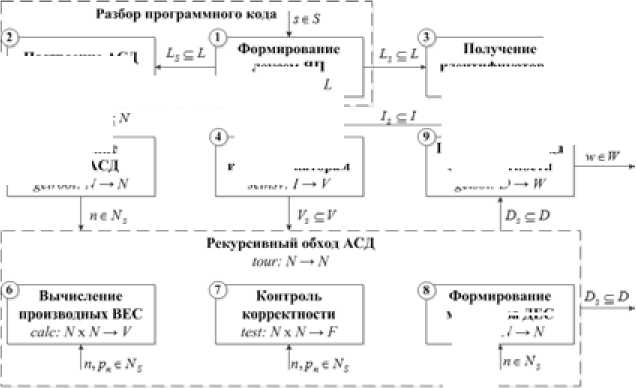
Реализация механизма поиска ДЕС на базе СА представлена в виде набора функций, использующих исходный код (ИК) программы и данные о ВЕС программных объектов, для получения и манипулирования АСД. Структурная схема методики изображена на рис. 1.
Входными данными для методики является ИК программы в виде последовательности символов 5 e S , по которому происходит формирование АСД на стадиях лексического и синтаксического анализа. Принципы исполнения данных стадий зависят от типа выбранного компилятора (статического анализатора); абстрагируясь от особенностей реализации, представим их работу в виде функций.
Работа лексического анализатора может быть описана многократным применением функции lexical : S ^ L . В результате для входной последовательности символов ( 5 e S ) формируется подмножество лексем ( L S ⊆ L ), представляющее собой LS = IS ∪ CS ∪ OS ∪ KS ∪ DS , где I S ⊆ I – идентификаторы; C S ⊆ C – константы; O S ⊆ O – знаки операций; K S ⊆ K – ключевые слова; D S ⊆ D – разделители.
I
Построение AC J syntactic: L —* N
иножгстм ЛЕС getdff: N
Рис. 1. Структурная схема методики СА для поиска ДЕС
Fig. 1. Structural scheme of the static analysis technique for natural semantic defects detection
леютм ям lexical: S —*
ИЦИIII фи к» I орон gelid: L-*l
I Io. мнение корим
Упановкл BEC мдснтифнка торим
Получение вывод»
О коррск'1 IHXI и gctsol: D
Синтаксический анализатор, который возможно изобразит функцией syntactic : L ^ N, на основе выделенных лексем L строит внутреннее представление программы в виде АСД S
( N s Е N ).
Программные объекты, признаками которых являются ВЕС, в ИК программы представ лены идентификаторами IS. Их выявление из полученных лексем LS производится с помощью многократного применения функции getid: L^I. Реализация функции следующая:
Г l , если l е I ;
getid (l ) = L
I0 , иначе.
Для хранения ВЕС ν ∈ V S в модифицированной структуре узла АСД предусмотрено поле, заполнение которого производится путем отображения множества идентификаторов программных объектов Is с I на множество возможных ВЕС: setnsv : I^V.
Выполнение и контроль корректности операций с ВЕС производится во время обхода модифицированного АСД, который начинается с корневого узла. Для получения корня АСД применяется функция getroot : N -^ N , в результате возвращающая узел, который не имеет «родителя»:
getroot ( n )J " • если p " =0 ; (3)
; l0 , иначе.
Функция для обхода tour: N-^N принимает значение корневого элемента дерева n е N. Затем для узла n, полученного в качестве параметра, проверяется условие существования «потомков», которые не были посещены ac = 0, и функция tour вызывает сама себя с непосещенным узлом cn в качестве параметра, при этом счетчик посещения узла an увеличивается на единицу (спуск вниз). В случае обхода всех «потомков» ac > 0 узла n или если рассматриваемый узел является листом Cn = 0, функция tour вызывает себя с параметром узла «родителя» pn, счет-– 806 – чик узла ap увеличивается на единицу, выполняется расчет значения ВЕС узла «родителя» pn с помощью функции calc (n, pn), осуществляется контроль условия корректности операций с ВЕС функцией test (n, pn) (подъем вверх). При получении функцией обхода корневого узла, у которого все «потомки» уже были хотя бы раз пройдены, рекурсивный вызов прекращается и функцией tour возвращается значение полученного узла. Рекурсивная функция tour имеет следующую реализацию:
tour ( cn = me, , vc , Pc , ( ac + 1) , f= , Cc )) , если 3cn e Cn : ac = 0;
tour ( n ) = -
/ / , х , х , х если Cn = 0
tour ( P n = m p , calc ( n , P n ) , P p , ( a p + 1 ) , test ( n , P n ) , C P }) , M Г Л (4)
v ' v ' И или V c n e C n : ac > 0;
иначе .
m , v , p ,(a +1), f ,C ), n , n , n , n , n , n ,
Получение производных значений ВЕС в «родительских» узлах АСД вычисляются функцией calc : N х N ^ V, которая возвращает значение ВЕС в зависимости от метки узла mp . Реализация функции calc основана на формулах преобразования ВЕС программных объектов для операторов языков С и C++ :
|
v p |
vP + v n , |
если V m p e { *,* =} : a p > 1; |
|
|
vp |
= v„ - v ., pn |
если V m„ e { /,/ = } : a„ > 1; pp |
|
|
calc ( n , P n ) = - n |
|||
|
если V mD e { = , + , + = , - , -= , == ,! = , < , <= , > , >= } p |
|||
|
v |
V n , |
||
|
p |
n |
или V m p e { *,* = ,/,/ = ,%,% = } : a p < 1; |
|
|
v p |
= v p , |
иначе . |
|
Функция формирования признака наличия ДЕС test : N х N ^ F вызывается при возвращении в «родительские» узлы. Множеством возможных значений функции является F = {0,1}, где ноль соответствует отсутствию ДЕС, а единица – наличию. Функция реализуется исходя из особенностей условий корректности операций с ВЕС программных объектов следующим образом:
test ( n , Рп ) = ’
0,
если V m p e { + , - , = , + = , -= , == ,! = , < , > , <= , >= } : a p > 2, v * vp или V mp e { %, * = , / = , % = } : a p > 2, v n * 0;
иначе .
Формирование множества ДЕС D S £ D осуществляется функцией getdef: N ^ N , применяемой к каждому помещаемому узлу АСД. Данная функция реализуется следующим образом:
getdef ( n )
если f * 0;
иначе .
Правильность программы в целом на предмет отсутствия ДЕС производится функцией getsol : D ^ W, где получение элемента множества W = {1,0}, равного единице, говорит о наличии ДЕС в программе, ноль – об их отсутствии:
| 1, если D S * 0 ; getsol ( n ) = <
1 0, иначе.
В итоге на выходе предлагаемой методики получается признак w s е W, характеризующий правильность программы, на основании множества выявленных в процесса анализа ДЕС ,
D s Е D .
Программная реализация методики СА для поиска ДЕС
Программная реализация описанного способа поиска ФД осуществлена на основе инфраструктуры компилятора LLVM и фронтенда Clang для языков программирования C, C++, Objective-C . Архитектура компилятора LLVM сходна с другими современными компиляторами и представлена на рис. 2.
Осуществление поиска ДЕС возможно производить до этапов оптимизации и кодогенера-ции, что позволяет в работе ограничиться фронтендом фреймворка LLVM – Clang . Основным преимуществом Clang является его ориентация на максимальное сохранение информации о ходе процесса компиляции и коде программы, что гарантирует его точное воспроизведение в АСД.
Фронтенд дает возможность доступа к АСД через механизм курсоров (узлов), а также удобный инструментарий для его обхода и манипулирования. Стандартной структуры, описывающей курсор в Clang ( CXCursor ), недостаточно, поэтому при решении задачи на ее основе был создан ее модифицированный вариант (рис. 3), соответствующий выражению (1).
Cling LLVM wtr

Рис. 2. Архитектура компилятора LLVM
Fig. 2. LLVM compiler architecture
typedef struct (
CXCursor cursor; //исходный курсор, содержап^Л метку узла АСД v [ ] — ( , , , , , , , , ) ; W , - г ■•:---- - - = , - .
int parent • ; //ссмяха на родительехиГс алемеи? камер племекта * векторе int counter - ; //счетчик количества заходов в узел при обходе bool defect - : //признак наличия дефекта в узле
) ExtcndedCXCursor; //pa 4:iq •■ шак тругтура кур - ра АСД
Рис. 3. Структура модифицированного узла АСД
Fig. 3. Structure of a modified abstract syntax tree node
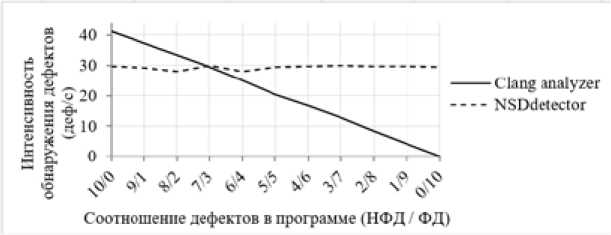
Рис. 4. График зависимости интенсивности обнаружения дефектов от соотношения НФД и ФД в программе для Clang analyzer и NSDdetector
Fig. 4. Schedule of dependence defects detection rate from the ratio between NFD and FD in software for Clang analyzer and NSDdetector
Для компилируемого кода Clang создает единицу трансляции (CXTranslationUnit ), содержащую данные о процессе разбора, дл я которой возможно получить корень АСД ( clang_ getTranslationUnitCursor() ) и начать его обход ( clang_visitChildren() ). Проверяя тип курсора ( clang getCursorKindQ ) при каждом шаге обхода, можем организовать вычисление значений ВЕС программных объектов по выражению (5) и проверку корректности операций с ВЕС согласно (6). Такой подход дает возможность по текущему курсору детектировать ДЕС с точностью до строки кода в файле и позиции в операторе.
Для оценки эффективности программной реализации предлагаемой методики воспользуемся показателем в виде интенсивности обнаружения дефектов, то есть количеством выяв-
NДЕФ ляемых дефектов в единицу времени: J. = —-—, где ^деф - количество обнаруживаемых де-TА фектов; TА – время анализа. Логично полагать, что чем выше интенсивность обнаружения, тем эффективнее работает анализатор.
Опыт проводился при одинаковых вычислительных ресурсах на ИК размером 1000 строк исходным Clang analyzer и созданным на его основе программным средством ( NSDdetector). Варьируя соотношением ФД (в данном случае ДЕС) и НФД при неизменном общем их количестве, зафиксировали значения времени анализа и количества обнаруженных дефектов. Результаты опыта представлены на рис. 4.
Анализ полученных результатов показал, что применение NSDdetector согласно выбранному критерию является оправданным на начальном этапе создания ПО, когда в ИК широко представлены как НФД, так и ФД. При снижении представительства ФД в коде ниже соотношения 7/3 целесообразно применять исходный Clang analyzer.
Заключение
Полученная методика разработана как альтернатива традиционным способам поиска ФД и позволяет автоматизировать процесс их поиска, что положительно сказывается на времени и объективности проверок. Программная реализация подхода может использоваться как разработчиками ПО АС ВН для раннего обнаружения дефектов, так и орга-– 809 – низациями, осуществляющими испытания ПО АС ВН, в качестве диверсной методики испытаний.
Список литературы Методика статического анализа для поиска дефектов естественной семантики программных объектов и ее программная реализация на базе инфраструктуры компилятора LLVM и фронтенда Clang
- Lobanova N.M., Dubrovin D.A. Evaluation of software quality costs. University herald, 2016, 6, 87-91
- Kuljamin V.V. Methods of software verification. Moscow, Institut sistemnogo programmirovanija RAN, 2008, 117 p.
- Itsykson V.M., Moiseev M.Ju., Tsesko V.A., Zakharov A.V., Akhin M.H. Interval analysis algorithm for detecting defects in the software source code. Information-control systems, 2009, 2, 34-41
- Egorov V.V., Tomilova N.I., Amirov A.Zh., Kasylkasova K.N. Software verification methods. Young scientist, 2016, 21, 138-141
- Andreev G.I., Sozinov P.A., Tikhomirov V.A. Managerial decisions in the design of radio engineering systems. Moscow, Radiotehnika, 2018, 560 p.
- Glukhikh M.I., Itsykson V.M., Tsesko V.A. The use of dependencies for improving the precision of program static analysis. Modeling and analysis of information systems, 2011, 4(1), 68-79
- Bridzhmen P. Dimensional analysys. Izhevs, NITS "Regulyarnaya i khaoticheskaya dinamika", 2001, 128 p.
- Aho A., Seti R., Ul’man Dzh. Compilers: principles, technologies, tools. Moscow, Izdatel’skij dom "Vil’yams", 2003, 768 p.
