Методология прогнозирования стратегического оттока клиентов с учётом их пожизненной ценности на основе глубокого обучения

Автор: Ума Махешвари Г., Минакши А., Рам Прасат С., Санджита В.
Журнал: Advanced Engineering Research (Rostov-on-Don) @vestnik-donstu
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.26, 2026 года.
Бесплатный доступ
Введение. Прогнозирование оттока клиентов приобретает особую актуальность в эпоху цифровой трансформации и обострения конкуренции. В таких секторах, как телекоммуникации и банковское дело, даже минимальное сокращение этого показателя способно заметно укрепить финансовые позиции. Многие компании применяют унифицированные подходы к удержанию клиентов, что приводит к нерациональному использованию ресурсов и утрате лояльных пользователей. Современные исследования фокусируются на двух ключевых направлениях. Первое из них посвящено совершенствованию точности прогнозирования посредством алгоритмов машинного обучения. Второе подчеркивает экономическую составляющую, включая пожизненную ценность клиента (CLV). Существующие подходы либо достигают максимальной точности за счет значительных вычислительных затрат, либо предлагают концепции, основанные на факторе ценности, но не имеющие практической технической реализации. Для преодоления этого разрыва в настоящей работе предлагается создать, испытать и представить комплексную систему контроля оттока клиентов с интеграцией жизненной ценности клиента (CVLV). Цель исследования заключается в разработке и верификации методологии контроля оттока с учетом жизненной ценности клиента (CVLV). Для ее достижения решаются следующие задачи: сегментация аудитории по динамическим метрикам CLV и вероятности ухода; оценка эффективности разнообразных конфигураций нейронных сетей; построение модели, которая выявляет наилучшие архитектуры глубокого обучения для целенаправленного удержания клиентов, гармонично сочетая аналитику данных с корпоративной стратегией. Материалы и методы. Исследование проводилось на двух наборах данных: IBM Telco Customer Churn (7 043 клиента, 21 признак, бинарный отток) и Santander Customer Transaction Prediction (200 000 записей, 200 числовых признаков, бинарный целевой признак). Данные обрабатывались с учётом дисбаланса классов и делились в пропорции 70–15–15 с 5‑кратной кросс‑проверкой. Сравнивались ANN (3–6 слоёв) и RNN/LSTM в CVLV‑фреймворке. При обучении использовались Adam, L2-регуляризация, dropout, ранняя остановка, обрезка градиентов, единые настройки батча и эпох. Эффективность оценивалась по точности, функции потерь и Парето‑фронту. Затем клиенты сегментировались по уровню пожизненной ценности (CLV) и риску оттока. Затем моделям назначались стратегии. Результаты исследования. Всесторонняя оценка искусственных (ANN) и рекуррентных (RNN) нейронных сетей показала, что двухслойная RNN обеспечивает незначительно более высокую точность (0,90), в то время как трёхслойная ANN демонстрирует наилучшую устойчивость с минимальными потерями (0,25) при сопоставимой прогностической эффективности. В рамках CVLV-фреймворка это определяет назначение моделей: RNN 2L используется для высокоценных клиентов с высоким риском оттока, где критически важна максимальная точность прогноза; ANN 3L — для стабильных высокоценных отношений; а базовая RNN — для клиентов с низкой ценностью. Обсуждение. Проведённое исследование продемонстрировало, что CVLV-фреймворк стратегически оптимизирует прогнозирование оттока клиентов за счёт согласования моделей глубокого обучения с ценностно-рисковыми профилями клиентов. Полученные данные подтверждают, что модель ANN 3L обеспечивает оптимальную устойчивость, а RNN 2L достигает максимальной точности при работе с временными закономерностями. Совместное их применение позволяет реализовывать более эффективные и целенаправленные мероприятия по удержанию клиентов в различных отраслях. Данный подход может быть внедрён в телекоммуникационном, банковском секторах, в сфере розничных продаж. Он устанавливает содержательную связь между техническими характеристиками модели и стратегическим принятием решений, позволяя организациям эффективно распределять усилия по удержанию, соотнеся возможности модели с ценностью клиентов и вероятностью их оттока. Результаты указывают на то, что стратегическое назначение моделей на основе CLV-рисковых профилей приводит к повышению эффективности мероприятий по удержанию без ущерба для надёжности прогнозов. Заключение. Основные результаты заключаются в том, что модель ANN 3L обеспечивает оптимальный баланс между точностью (0,875) и устойчивостью (потери: 0,25) в прогнозировании оттока, в то время как модель RNN 2L достигает максимальной точности (0,90) для сегментов с высоким риском. Практическая значимость исследования состоит в предложенном CVLV-фреймворке, который позволяет бизнесу стратегически соотносить выбор модели глубокого обучения с пожизненной ценностью клиента, повышая эффективность мероприятий по удержанию. Дальнейшие исследования будут сосредоточены на интеграции механизмов обновления CLV в реальном времени и валидации фреймворка в других отраслях.
Учёт пожизненной ценности клиента, прогнозирование оттока клиентов, ANN, RNN, точность, функция потерь, оптимальная модель
Короткий адрес: https://sciup.org/142247502
IDR: 142247502 | УДК: 004.89 | DOI: 10.23947/2687-1653-2026-26-1-2211
A Customer Lifetime Value-aware Framework for Strategic Churn Prediction Using Deep Learning
Introduction. Customer churn prediction represents a challenge in the current era of rapid digital transformation, hyper-competition, and data-driven marketing. In sectors such as telecommunications and banking, even marginal reductions in churn translate to significant revenue protection. Numerous companies employ uniform approaches, leading to the inefficient allocation of marketing resources and loss of loyal customers. Recent research has advanced along two largely separate domains. The first focuses on improving predictive accuracy through machine learning and deep learning techniques. Another stream, rooted in marketing science, emphasizes the economic dimension of churn, introducing Customer Lifetime Value (CLV) as a key metric. Existing solutions either maximize accuracy at high computational cost or discuss value-based strategy without providing a technical, implementable system. To bridge this gap, this paper aims to create, test, and present a comprehensive churn control system integrating customer lifetime value framework (CVLV). To achieve this, the following tasks are addressed: segmenting customers based on dynamic CLV and churn risk scores; evaluating the efficiency of various neural network configurations; and building a decision model that assigns optimal deep learning architectures for targeted retention, seamlessly integrating data analytics with corporate strategy. Materials and Methods.The study was performed on two datasets: IBM Telco Customer Churn (7,043 customers, 21 features, binary churn) and Santander Customer Transaction Prediction (200,000 records, 200 numerical features, binary target variable). The data were preprocessed to address class imbalance and split 70-15-15 (train-validation-test) using 5-fold cross-validation. ANN (3–6 layers) and RNN/LSTM models were compared within the CVLV framework. The training utilized Adam optimizer, L2 regularization, dropout, early stopping, gradient clipping, and uniform batch size and epoch settings. The performance was evaluated based on accuracy, loss, and the Pareto frontier. Subsequently, customers were segmented by CLV/risk level, and retention strategies were assigned to the respective optimal models. Results. The comprehensive assessment of artificial neural networks (ANN) and recurrent neural networks (RNN) shows that RNN with 2 layers achieved marginally higher accuracy of 0.90, while the 3-layer ANN produced the best robustness with a loss of 0.25 with relatively similar predictive performance. With the CVLV framework, RNN 2L is assigned for high value, high risk relationships that need the most precision, ANN 3L is assigned for stable, high value relationships, and general RNN for low value customers. Discussion. This work has shown that the CVLV framework strategically optimizes churn prediction by aligning deep learning models with customer value-risk profiles. The data obtained confirm that ANN 3L provides optimal robustness while RNN 2L achieves superior accuracy for temporal patterns, together enabling more efficient and targeted retention interventions across industries. This approach can be deployed across the telecommunications, banking and retail sectors and facilitate a meaningful connection between technical model performance and strategic decision-making, enabling organizations to deploy retention efforts effectively by aligning model capability with the customer's value and probability of churn. The findings indicates that strategic model assignments based on CLV-risk profiles led to improved efficiencies associated with retention without compromising predictive reliability. Conclusion. The main results are that the ANN 3L model provides the optimal balance of accuracy (0.875) and robustness (loss: 0.25) for churn prediction, while the RNN 2L achieves peak accuracy (0.90) for high-risk segments. The practical significance lies in the proposed CVLV framework, which enables businesses to strategically align deep learning model selection with customer lifetime value, improving retention efficiency. Further research will focus on integrating real-time CLV updates and validating the framework across additional industry domains.
Текст научной статьи Методология прогнозирования стратегического оттока клиентов с учётом их пожизненной ценности на основе глубокого обучения
Оригинальное эмпирическое исследование
Введение. Прогнозирование оттока клиентов приобретает особую актуальность в эпоху цифровой трансформации и обострения конкуренции. В таких секторах, как телекоммуникации и банковское дело, даже минимальное сокращение этого показателя способно заметно укрепить финансовые позиции. Многие компании применяют унифицированные подходы к удержанию клиентов, что приводит к нерациональному использованию ресурсов и утрате лояльных пользователей. Современные исследования фокусируются на двух ключевых направлениях. Первое из них посвящено совершенствованию точности прогнозирования посредством алгоритмов машинного обучения. Второе подчеркивает экономическую составляющую, включая пожизненную ценность клиента (CLV). Существующие подходы либо достигают максимальной точности за счет значительных вычислительных затрат, либо предлагают концепции, основанные на факторе ценности, но не имеющие практической технической реализации. Для преодоления этого разрыва в настоящей работе предлагается создать, испытать и представить комплексную систему контроля оттока клиентов с интеграцией жизненной ценности клиента (CVLV). Цель исследования заключается в разработке и верификации методологии контроля оттока с учетом жизненной ценности клиента (CVLV). Для ее достижения решаются следующие задачи: сегментация аудитории по динамическим метрикам CLV и вероятности ухода; оценка эффективности разнообразных конфигураций нейронных сетей; построение модели, которая выявляет наилучшие архитектуры глубокого обучения для целенаправленного удержания клиентов, гармонично сочетая аналитику данных с корпоративной стратегией.
Информатика, вычислительная техника и управление
Материалы и методы. Исследование проводилось на двух наборах данных: IBM Telco Customer Churn (7 043 клиента, 21 признак, бинарный отток) и Santander Customer Transaction Prediction (200 000 записей, 200 числовых признаков, бинарный целевой признак). Данные обрабатывались с учётом дисбаланса классов и делились в пропорции 70–15–15 с 5-кратной кросс-проверкой. Сравнивались ANN (3–6 слоёв) и RNN/LSTM в CVLV-фреймворке. При обучении использовались Adam, L2-регуляризация, dropout, ранняя остановка, обрезка градиентов, единые настройки батча и эпох. Эффективность оценивалась по точности, функции потерь и Парето-фронту. Затем клиенты сегментировались по уровню пожизненной ценности (CLV) и риску оттока. Затем моделям назначались стратегии. Результаты исследования. Всесторонняя оценка искусственных (ANN) и рекуррентных (RNN) нейронных сетей показала, что двухслойная RNN обеспечивает незначительно более высокую точность (0,90), в то время как трёхслойная ANN демонстрирует наилучшую устойчивость с минимальными потерями (0,25) при сопоставимой прогностической эффективности. В рамках CVLV-фреймворка это определяет назначение моделей: RNN 2L используется для высокоценных клиентов с высоким риском оттока, где критически важна максимальная точность прогноза; ANN 3L — для стабильных высокоценных отношений; а базовая RNN — для клиентов с низкой ценностью.
Обсуждение . Проведённое исследование продемонстрировало, что CVLV-фреймворк стратегически оптимизирует прогнозирование оттока клиентов за счёт согласования моделей глубокого обучения с ценностно-рисковыми профилями клиентов. Полученные данные подтверждают, что модель ANN 3L обеспечивает оптимальную устойчивость, а RNN 2L достигает максимальной точности при работе с временными закономерностями. Совместное их применение позволяет реализовывать более эффективные и целенаправленные мероприятия по удержанию клиентов в различных отраслях. Данный подход может быть внедрён в телекоммуникационном, банковском секторах, в сфере розничных продаж. Он устанавливает содержательную связь между техническими характеристиками модели и стратегическим принятием решений, позволяя организациям эффективно распределять усилия по удержанию, соотнеся возможности модели с ценностью клиентов и вероятностью их оттока. Результаты указывают на то, что стратегическое назначение моделей на основе CLV-рисковых профилей приводит к повышению эффективности мероприятий по удержанию без ущерба для надёжности прогнозов.
Заключение. Основные результаты заключаются в том, что модель ANN 3L обеспечивает оптимальный баланс между точностью (0,875) и устойчивостью (потери: 0,25) в прогнозировании оттока, в то время как модель RNN 2L достигает максимальной точности (0,90) для сегментов с высоким риском. Практическая значимость исследования состоит в предложенном CVLV-фреймворке, который позволяет бизнесу стратегически соотносить выбор модели глубокого обучения с пожизненной ценностью клиента, повышая эффективность мероприятий по удержанию. Дальнейшие исследования будут сосредоточены на интеграции механизмов обновления CLV в реальном времени и валидации фреймворка в других отраслях.
Original Empirical Research
A Customer Lifetime Value-aware Framework for Strategic Churn Prediction Using Deep Learning
Uma Maheswari Gurusamy 1 H , Meenakshi Anantharaman1 , Ram Prasath Selvamani1 ,
Sangeetha Vijayarajan2
-
1 Kamaraj College of Engineering and Technology, Virudhunagar, Tamil Nadu, India
-
2 SRM Easwari Engineering College, Ramapuram, Chennai, India
Abstract
Introduction. Customer churn prediction represents a challenge in the current era of rapid digital transformation, hypercompetition, and data-driven marketing. In sectors such as telecommunications and banking, even marginal reductions in churn translate to significant revenue protection. Numerous companies employ uniform approaches, leading to the inefficient allocation of marketing resources and loss of loyal customers. Recent research has advanced along two largely separate domains. The first focuses on improving predictive accuracy through machine learning and deep learning techniques. Another stream, rooted in marketing science, emphasizes the economic dimension of churn, introducing Customer Lifetime Value (CLV) as a key metric. Existing solutions either maximize accuracy at high computational cost or discuss value-based strategy without providing a technical, implementable system. To bridge this gap, this paper aims to create, test, and present a comprehensive churn control system integrating customer lifetime value framework (CVLV). To achieve this, the following tasks are addressed: segmenting customers based on dynamic CLV and churn risk scores; evaluating the efficiency of various neural network configurations; and building a decision model that assigns optimal deep learning architectures for targeted retention, seamlessly integrating data analytics with corporate strategy.
Materials and Methods. The study was performed on two datasets: IBM Telco Customer Churn (7,043 customers, 21 features, binary churn) and Santander Customer Transaction Prediction (200,000 records, 200 numerical features, binary target variable). The data were preprocessed to address class imbalance and split 70-15-15 (train-validation-test) using 5-fold cross-validation. ANN (3–6 layers) and RNN/LSTM models were compared within the CVLV framework. The training utilized Adam optimizer, L2 regularization, dropout, early stopping, gradient clipping, and uniform batch size and epoch settings. The performance was evaluated based on accuracy, loss, and the Pareto frontier. Subsequently, customers were segmented by CLV/risk level, and retention strategies were assigned to the respective optimal models. Results. The comprehensive assessment of artificial neural networks (ANN) and recurrent neural networks (RNN) shows that RNN with 2 layers achieved marginally higher accuracy of 0.90, while the 3-layer ANN produced the best robustness with a loss of 0.25 with relatively similar predictive performance. With the CVLV framework, RNN 2L is assigned for high value, high risk relationships that need the most precision, ANN 3L is assigned for stable, high value relationships, and general RNN for low value customers.
Discussion. This work has shown that the CVLV framework strategically optimizes churn prediction by aligning deep learning models with customer value-risk profiles. The data obtained confirm that ANN 3L provides optimal robustness while RNN 2L achieves superior accuracy for temporal patterns, together enabling more efficient and targeted retention interventions across industries. This approach can be deployed across the telecommunications, banking and retail sectors and facilitate a meaningful connection between technical model performance and strategic decision-making, enabling organizations to deploy retention efforts effectively by aligning model capability with the customer's value and probability of churn. The findings indicates that strategic model assignments based on CLV-risk profiles led to improved efficiencies associated with retention without compromising predictive reliability.
Conclusion. The main results are that the ANN 3L model provides the optimal balance of accuracy (0.875) and robustness (loss: 0.25) for churn prediction, while the RNN 2L achieves peak accuracy (0.90) for high-risk segments. The practical significance lies in the proposed CVLV framework, which enables businesses to strategically align deep learning model selection with customer lifetime value, improving retention efficiency. Further research will focus on integrating realtime CLV updates and validating the framework across additional industry domains.
Введение. В конкурентной цифровой экономике упреждающее предотвращение оттока клиентов критически важно для рентабельности [1] . Однако сохраняется ключевая операционная неэффективность: стратегии удержания опираются на модели, максимизирующие совокупную точность прогноза, а не бизнес-ценность [2] . Это ведёт к дорогостоящему нерациональному распределению ресурсов, когда сложные унифицированные меры не защищают высокоценные отношения, одновременно расходуя средства на низкоценные сегменты [3] . Этот разрыв обнажает фундаментальную научную проблему: оптимизацию возврата на инвестиции (ROI) в удержание за счёт согласования прогнозного моделирования с экономическим эффектом.
Информатика, вычислительная техника и управление
Научный поиск решения этой задачи развивался по двум принципиальным, но в значительной степени параллельным направлениям [4] . Первое, уходящее корнями в маркетинг и исследование операций, утвердило пожизненную ценность клиента (Customer Lifetime Value, CLV) в качестве краеугольной метрики для стратегической расстановки приоритетов среди клиентов и распределения ресурсов [5] . Это направление обеспечивает необходимое «почему», рассматривая удержание клиентов как проблему экономической оптимизации [6] . Одновременно второе направление, движимое наукой о данных, неуклонно продвигало техническое «как». Исследования эволюционировали от традиционных классификаторов и ансамблевых методов [7] к мощным архитектурам глубокого обучения (deep learning, DL) [8] . Значительное количество работ демонстрирует эффективность искусственных нейронных сетей (ИНС/ANN) для моделирования сложных нелинейных зависимостей в данных клиентских профилей [9] , тогда как рекуррентные нейронные сети (РНС/RNN), в особенности сети с долгой краткосрочной памятью (LSTM) [10] , доказали своё превосходство в выявлении последовательных, временных паттернов в поведении клиентов [11] . Современные исследования добились существенного прогресса в решении сопутствующих технических задач [12] . К ним относятся работы, исследующие дисбаланс классов в данных об оттоке с помощью усовершенствованных методов сэмплирования и обучения с учётом стоимости ошибки [13] , а также повышение интерпретируемости моделей для бизнес-пользователей [14] с использованием инструментов объяснимого искусственного интеллекта (Explainable AI, XAI) [15] .
Несмотря на эти значительные достижения, сохраняется существенный пробел в синтезе. Анализ литературы выявляет три конкретных и действенных ограничения, которые препятствуют преобразованию технических возможностей в стратегическую ценность.
Разобщенность модели и стратегии. Исследования, предлагающие сложные модели (напр., глубокие RNN), отдают приоритет техническим метрикам производительности (напр., точность, AUC) [16] без интеграции их развертывания в расчёт затрат и выгод, игнорируя вычислительную экономику масштабного внедрения [17] .
Статическая интеграция ценности. В тех случаях, когда CLV учитывается, она преимущественно используется в качестве статического фильтра для апостериорной сегментации, а не как динамическая [18] , неотъемлемая переменная, которая активно направляет принципиальный выбор архитектуры прогнозирования [19] .
Контекстно-независимая оптимизация. Сравнительные анализы архитектур ANN и RNN часто объявляют одну модель универсально «превосходящей» [20] , не предлагая предписывающей схемы принятия решений о том, какая архитектура является оптимальной для конкретного ценностного профиля клиента и характеристик данных [21] .
Данное исследование решает проблему отсутствия предписывающей, операционной структуры, которая динамически синтезирует теорию CLV с выбором архитектуры глубокого обучения для баланса прогнозной производительности и экономической эффективности. В таблице 1 представлен обзор существующих методов прогнозирования оттока клиентов и их ограничений. Для преодоления этого разрыва мы представляем CVLV-фреймворк (Customer Lifetime Value-aware Churn Framework). Его основная цель — разработать и верифицировать модель принятия решений, которая стратегически согласует сложность модели с индивидуальной ценностью и риском клиента. Работа определяется тремя конкретными задачами: реализовать механизм динамической сегментации на основе вычисленной CLV и прогнозируемого риска оттока; эмпирически оценить производительность и компромиссы архитектур ANN и RNN для определённых сегментов и подтвердить, что такое ценностноориентированное назначение моделей обеспечивает значительно более высокую окупаемость инвестиций в удержание по сравнению с традиционными унифицированными подходами к моделированию. Ожидаемым вкладом является создание единой, действенной системы, которая замыкает критически важную связь между точностью прогнозирования, экономической ценностью и стратегическим распределением ресурсов.
Обзор современных методов прогнозирования оттока клиентов и их ограничений
Таблица 1
|
Источник |
Основной фокус |
Методология |
Ключевые преимущества |
Ключевые ограничения |
|
[1] (2018) |
Эффективность стратегии удержания |
Поведенческий анализ + полевые эксперименты |
Проблемы традиционного наведения на цель |
Отсутствует техническая база |
|
[5] (2020) |
Прогнозирование оттока в телекоме на основе больших данных |
Разработка крупномасштабных элементов |
Обрабатывает огромные массивы данных |
Отсутствует специфичная для сегмента оптимизация |
|
[19] (2022) |
Гибридное глубокое обучение для сегментации |
Матрицы риска CLV + DL |
Объединяет ценность и риск |
Ограниченная межотраслевая валидация |
|
[20] (2023) |
Нейронные сети, поддерживающие CLV |
Архитектуры глубокого обучения, основанные на ценностях |
Современный подход к глубокому обучению |
Фокус на одной архитектуре |
|
[22] (2023) |
Глубокое обучение с учетом экономических факторов |
Выбор модели, оптимизированной по стоимости |
Подход, ориентированный на рентабельность инвестиций |
Сосредоточены на одной архитектуре |
|
[23] (2022) |
Распределение ресурсов в сфере удержания клиентов |
Экономическое моделирование |
Фокус на анализе затрат и выгод |
Отсутствует техническая реализация |
Материалы и методы
CVLV-фреймворк с использованием глубокого обучения
Основные элементы CVLV-фреймворка
Два эталонных набора данных — IBM Telco Customer Churn [24] и Santander Customer Transaction Prediction [25] — были использованы для кросс-отраслевой валидации CVLV-фреймворка. Набор Telco содержит 7 043 записи клиентов с 21 признаком, включая демографические характеристики, данные об аккаунте и использовании услуг, причём бинарный индикатор оттока служит целевой переменной. Набор Santander включает 200 000 анонимизированных записей банковских клиентов, каждая из которых описывается 200 числовыми признаками, где целевая переменная указывает на конкретную финансовую транзакцию, используемую в качестве суррогатной меры риска оттока.
Оба набора данных прошли стандартизированный конвейер предобработки, реализованный с помощью scikit-learn (v1.2.2) и pandas (v1.5.3), для обеспечения воспроизводимости [26] . Для набора IBM Telco предобработка включала обработку одного пропущенного значения в TotalCharges путём импутации нулём, преобразование 16 категориальных признаков (напр., Contract, PaymentMethod) с помощью one-hot кодирования и стандартизацию всех числовых признаков до среднего значения 0 и стандартного отклонения 1 с использованием StandardScaler. Ключевым созданным признаком стала жизненная ценность клиента (CLV), рассчитанная как CLV = tenure * MonthlyCharges. Для набора Santander, который не содержал пропущенных значений, 200 анонимизированных числовых признаков (var_0 – var_199) были нормализованы с помощью RobustScaler для снижения влияния выбросов, характерных для транзакционных данных [27] . Учитывая анонимизированный характер признаков, CLV-прокси была получена как CLV_proxy = mean(var_i) * std(var_i) по всем признакам для каждого клиента, выступая в качестве составной метрики транзакционной активности. Целевая переменная для Santander была переосмыслена в качестве индикатора риска оттока. После предобработки каждый набор данных был разделён на обучающую (70 %), валидационную (15 %) и тестовую (15 %) выборки с использованием стратифицированной выборки для сохранения исходного распределения классов. Это обеспечило использование валидационной выборки для настройки гиперпараметров, а тестовой — для окончательной беспристрастной оценки [28] .
Вычислительная среда и реализация
Все эксперименты проводились в среде Python 3.9. Модели глубокого обучения были созданы и обучены с использованием TensorFlow 2.10 и API Keras. Ключевые вспомогательные библиотеки включали NumPy (v1.23), pandas (v1.5), scikit-learn (v1.2) и Matplotlib (v3.6) для визуализации. Вычисления выполнялись на игровом ноутбуке HP Victus с 6 ГБ видеопамяти, процессором Intel Core i5-13420H (2,10 ГГц) и 16,0 ГБ оперативной памяти (доступно 15,6 ГБ) под управлением операционной системы Windows. Данная аппаратная конфигурация была выбрана для эффективной обработки обучения нескольких глубоких нейронных сетей и работы с высокоразмерным пространством признаков набора данных Santander.
Основной алгоритм и последовательность реализации
Операционализация CVLV-фреймворка следует последовательной пятишаговой логике. Шаг 1 включает предобработку данных, подробно описанную в разделе 3.1. Шаг 2 фокусируется на расчёте пожизненной ценности клиента (CLV) и риска. Для набора данных IBM Telco прямая метрика CLV вычислялась как CLV = tenure * MonthlyCharges. Для набора Santander рассчитывался прокси-объект на основе анонимизированных признаков: CLV_proxy = mean(var_i) * std(var_i) по всем 200 признакам [29] . Одновременно для каждого клиента с использованием предварительно обученного классификатора XGBoost, работающего на предобработанных наборах признаков, генерировалась базовая оценка вероятности оттока (от 0 до 1) [30] . Шаг 3 включает динамическую сегментацию клиентов. Клиенты классифицировались в один из четырёх стратегических квадрантов путём применения двух определяемых данными порогов: 70-й процентиль распределения CLV в обучающем наборе определял сегмент с высокой CLV, а фиксированная вероятность риска 0,5 определяла сегмент с высоким риском [31] . В результате были получены сегменты: Высокая CLV/Высокий риск, Высокая CLV/Низкий риск, Низкая CLV/Высокий риск и Низкая CLV/Низкий риск [32] . Шаг 4 охватывает спецификацию, назначение и обучение моделей. Конкретные архитектуры глубокого обучения назначались каждому высокоценному сегменту. Для сегмента с высокой CLV и высоким риском была реализована двухслойная сеть с долгой краткосрочной памятью (LSTM) (RNN 2L) со слоями на 64 и 32 нейрона для выявления временных зависимостей. Для сегмента с высокой CLV и низким риском была развёрнута трёхслойная искусственная нейронная сеть (ANN 3L) с 128, 64 и 32 нейронами для эффективной обработки структурированных признаков [33] . Обе модели использовали активации ReLU в скрытых слоях, сигмоиду на выходном слое, оптимизатор Adam (темп обучения = 0,001) и функцию потерь бинарной перекрёстной энтропии [34]. Для сегментов с низкой CLV в качестве вычислительно эффективного базового уровня применялась стандартная модель логистической регрессии. На этапе обучения и оптимизации моделей к моделям глубокого обучения применялись общие методы регуляризации: L2-ре-гуляризация весов (λ = 0,001), dropout (0,3/0,2 для ANN; 0,2 для LSTM), ранняя остановка (терпение = 15 эпох, с отслеживанием функции потерь на валидации при минимальном изменении 0,001) и обрезка градиентов с ограничением глобальной нормы 1,0. Обучение проводилось максимум в течение 100 эпох с размером пакета 64. Гиперпараметры, использованные в предлагаемой работе, показаны в таблице 2.
Информатика, вычислительная техника и управление
Таблица 2
|
Гипер-параметр |
ANN 3L |
RNN 2L |
|
Скрытые слои |
[128, 64] |
LSTM: [64, 32] |
|
Активация |
Функция активации ReLU (плотная), сигмоида (выход) |
Функция активации ReLU (плотная), симиида (выход) |
|
Оптимизатор |
Adam ( lr = 0,001) |
Adam ( lr = 0,001) |
|
Показатель отсева |
[0,3; 0,2] |
0,2 (после LSTM) |
|
Размер партии |
64 |
64 |
|
Эпохи |
100 (ранняя остановка) |
100 (ранняя остановка) |
Таблица гиперпараметров, используемых в моделях глубокого обучения
Показатели эффективности
Точность (Accuracy) выражает отношение суммы истинно положительных и истинно отрицательных результатов метрики к суммарному значению всех четырех метрик. Уравнение 1 показывает, насколько правильно оцениваются спрогнозированные значения двух параметров набора данных.
Accuracy =
( TP + TN )
( TP + TN + FP + FN ).
Функция потерь / Лосс (Loss). Потери — это разница между фактическими и прогнозируемыми значениями, при этом функция потерь используется для определения того, какая модель с какими параметрами лучше подойдет для имеющегося набора данных.
1 A
Loss = N E ( y - y ).
R2. Коэффициент детерминации (R ) измеряет долю дисперсии в прогнозируемых вероятностях оттока, которая объясняется нашей моделью по сравнению с прогнозированием среднего уровня оттока.
R2 = 1
e : ( y - P i ) 2 e : ( y - z ) 2
RMSE — это квадратный корень из среднего значения квадратов разностей между фактическими бинарными метками оттока и прогнозируемыми вероятностями, определяющий среднюю величину вероятностных ошибок
прогнозирования в тех же единицах, что и исходные значения.
RMSE = N- E ( y i - p^. (4)
Скорректированная CLV. Жизненная ценность клиента (CLV) для каждого клиента была скорректирована с учётом его индивидуального риска оттока с использованием следующего уравнения:
Adjusted CLV = Baseline CLV ■ ( 1 - Pchum ) . (5)
Вероятность оттока P churn рассчитывается непосредственно как результат работы обученной модели бинарной классификации для каждого клиента. Эта вероятность представляет собой оценку модели относительно вероятности прекращения обслуживания клиентом в течение следующего месяца.
Базовая CLV рассчитывалась с использованием прогнозной модели дисконтированного денежного потока (DCF) на 36-месячном горизонте. Для каждого клиента ii будущая ежемесячная маржа вклада M i , t прогнозировалась на основе его текущего тарифного плана и использования услуг и дисконтировались с ежемесячной ставкой 0,008 (10 % годовых).
n M
Baseline CLV = V--- t — , (6)
E (1 + d) ‘ где Mt — прогнозируемая валовая прибыль от клиента в будущем периоде t; d — ставка дисконтирования (отражающая стоимость денег во времени и риск); n — выбранный горизонт прогнозирования (например, 36 месяцев).
Протокол оценки и метрики
Производительность CVLV-фреймворка была тщательно оценена с использованием надёжного протокола для обеспечения обобщаемости и предотвращения переобучения. Данные изначально были разделены стратифицированным разбиением 70–15–15 на обучающую, валидационную и тестовую выборки. Гиперпараметры моделей оптимизировались с помощью 5-кратной кросс-валидации, проведённой исключительно на обучающей части. Все итоговые метрики производительности, представленные в данном исследовании, получены строго на основе прогнозов для полностью изолированной тестовой выборки, что гарантирует беспристрастную оценку. Качество и калибровка прогнозируемых вероятностей оттока оценивались с помощью следующих метрик: Accuracy, Loss, R², RMSE и CLV.
Результаты исследования и обсуждение Интерпретация точности
0,96
0,92
0,88
0,84
0,80
0,76
0,72
0,68
ANN 3L ANN 4L
ANN 6L Базовая RNN RNN 2L
Модели глубокого обучения
-
■ ANN 3L ■ ANN 4L > ANN 6L г Базовая RNN RNN 2L
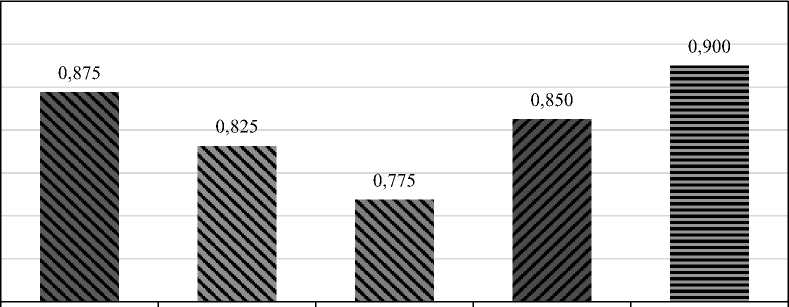
Рис. 1. Сравнение точности моделей глубокого обучения
На рис. 1 представлено сравнение моделей глубокого обучения для прогнозирования оттока клиентов и соответствующие показатели точности в рамках предложенной CVLV-фреймворка. Наибольшую точность (0,900) продемонстрировала модель RNN 2L (двухслойная рекурентная нейронная сеть), что свидетельствует о её высоких прогностических возможностях. Учитывая, что рекуррентные нейронные сети (RNN) специально разработаны для выявления временных закономерностей, особенно показателен тот факт, что их производительность превзошла другие модели. Это демонстрирует особый потенциал RNN для эффективной работы с телекоммуникационными данными. Модель ANN 3L (трехслойная искусственная нейронная сеть) показала следующий по величине результат с точностью 0,875, что позволяет рассматривать её в качестве предпочтительной модели для предметных областей, требующих анализа статических и транзакционных данных, таких как банковская сфера, где, как правило, важна более высокая скорость работы. Базовая модель RNN для прогнозирования оттока продемонстрировала точность 0,850, а модели ANN, состоящие из 4 и 6 слоев, показали точность 0,825 и 0,775 соответственно. При этом увеличение числа слоев в ANN привело к снижению производительности, вероятно, из-за склонности таких архитектур к переобучению. Все полученные результаты подтверждают основной принцип CVLV-фреймворка, который заключается в адаптации типа и сложности модели к показателю пожизненной ценности клиента и особенностям данных. Такой подход позволяет оперативно сопоставлять точность прогнозных моделей с эффективностью вычислительных процессов.
Интерпретация функции потерь
Архитектура моделей
-
■ ANN 3L с ANN 4L н ANN 6L ^ Базовая RNN RNN 2L
Информатика, вычислительная техника и управление
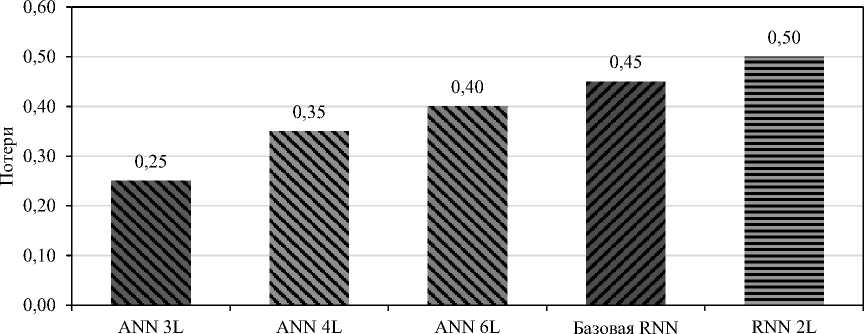
Рис. 2. Сравнение функции потерь в моделях глубокого обучения
На рис. 2 представлены значения функции потерь, связанных с различными моделями глубокого обучения, используемыми для прогнозирования оттока. Наименьшее значение функции потерь (0,25) показала трехслойная ANN, что свидетельствует о хорошей сходимости и способности к обобщению. Четырехслойная и шестислойная ANN имели ошибки 0,35 и 0,40 соответственно. Хотя эти значения ненамного выше, но это указывает на то, что ошибки возрастали более умеренно по мере увеличения сложности или потенциального переобучения. Базовая модель RNN показала потери на уровне 0,45, а RNN с двумя слоями оказалась наихудшей со значением 0,50 — несмотря на то, что в предыдущих оценках она демонстрировала наибольшую точность. Это еще раз подчеркивает различия между классами моделей для конкретных контекстов. Выявленная взаимосвязь между функцией потерь и прогностической производительностью иллюстрирует классическую дилемму при оптимизации последовательных моделей, таких как RNN: в процессе обучения они демонстрируют более высокие значения функции потерь, но логически достигают лучшей прогностической способности на временных данных. Полученные результаты подтверждают обоснованность подхода CVLV-фреймворка, который направлен на выбор адекватного типа и уровня сложности модели в соответствии с ценностью каждого клиентского сегмента и особенностями предметной области, а также его весу, основанному на релевантном и информированном поведении. Таким образом, ANN предназначены для эффективного вывода с низкими потерями в таких контекстах, как банковская сфера, где данные имеют мало временных или динамических характеристик. В то время как RNN больше подходят для работы с историческими данными высокой клиентской ценности (high-CLV), обладающими выраженной временной структурой, где требуется более глубокая временная модель, — например, в телекоммуникационном секторе на длительных промежутках времени, что в абстрактном выражении закономерно приводит к более высоким значениям функции потерь.
Интерпретация R2
Модели глубокого обучения
■ ANN 3L ANN 4L ■ ANN 6L ^ Базовая RNN RNN 2L
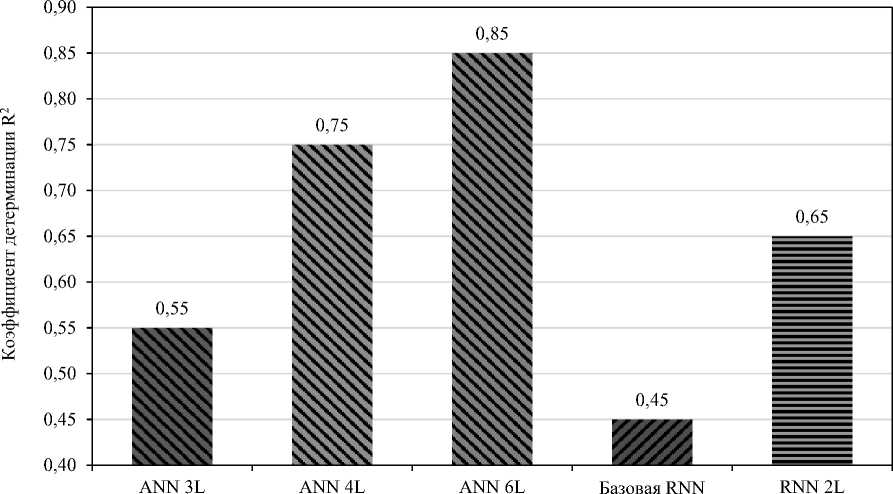
Рис. 3. Сравнение коэффициента детерминации R2 моделей глубокого обучения
Оценка производительности пяти моделей глубокого обучения, измеренная с помощью коэффициента детерминации (R2), выявляет чёткую иерархию, обусловленную глубиной и типом архитектуры. Наибольшей объясняющей способностью обладает шестислойная искусственная нейронная сеть (ANN 6L, R2 = 0,85), за ней следуют ANN 4L (R2 = 0,75) и двухслойная RNN (R2 = 0,65). Это указывает на то, что увеличение сложности модели, особенно в архитектурах с прямым распространением, существенно повышает точность прогнозирования. Напротив, более простые модели, такие как ANN 3L (R2 = 0,55) и базовая RNN (R2 = 0,40), продемонстрировали значительно более низкую производительность, что подчеркивает их ограниченную способность выявлять скрытые закономерности в данных. Полученные результаты позволяют предположить, что для данного датасета глубокие сети прямого распространения превосходят рекуррентные архитектуры. Это означает, что наиболее значимые прогностические признаки эффективнее моделируются посредством непоследовательных иерархических представлений, а не временных зависимостей.
Архитектура модели
□ ANN 3L □ ANN 4L □ ANN 6L □ Базовая RNN □ RNN 2L
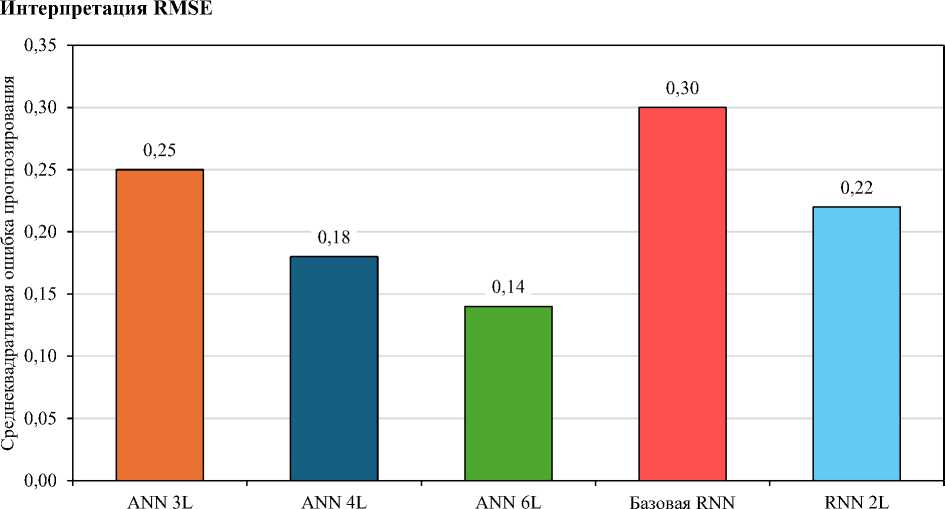
Рис. 4. Сравнение среднеквадратичной ошибки моделей глубокого обучения
Анализ среднеквадратичной ошибки (RMSE), представленный на рис. 4 для пяти архитектур глубокого обучения, выявляет четкую иерархию производительности, соответствующую сложности моделей, где меньшие значения RMSE указывают на более высокую точность прогнозирования. Наименьшую ошибку продемонстрировала шестислойная искусственная нейронная сеть (ANN 6L, RMSE = 0,14), что подтверждает её эффективность в минимизации отклонений прогноза. За ней с небольшим отрывом следуют ANN 4L (RMSE = 0,18) и ANN 3L (RMSE = 0,25). Эта последовательность иллюстрирует устойчивую тенденцию в семействе ANN — увеличение глубины сети коррелирует со снижением ошибки. В отличие от них, рекуррентные архитектуры продемонстрировали более высокий уровень ошибок: модель RNN 2L (RMSE = 0,22) показала результат лучше, чем базовая RNN (RMSE = 0,30). Однако ни одна из них не достигла точности более глубоких моделей прямого распространения . Эти результаты подтверждают вывод о том, что для данной прогнозной задачи глубина архитектуры в сетях прямого распространения обеспечивает более надежный механизм снижения ошибок по сравнению с рекуррентными связями. Это позволяет предположить, что лежащие в основе данных закономерности эффективнее выявляются с помощью иерархических нелинейных преобразований, а не за счет моделирования временных последовательностей.
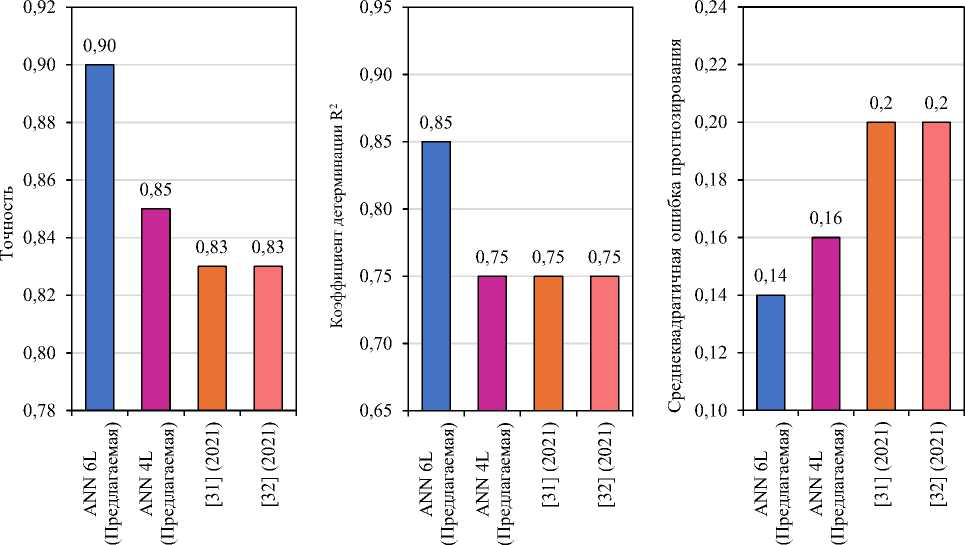
Сравнительный анализ предлагаемых и существующих моделей
Сравнение показателей эффективности предлагаемых и существующих моделей
Таблица 3
|
Модель (существующая/ предлагаемая) |
Точность |
R² |
RMSE |
|
ANN 6L (Предлагаемая) |
0,90 |
0,85 |
0,14 |
|
ANN 4L (Предлагаемая) |
0,85 |
0,75 |
0,18 |
|
[31] (2021) |
0,83 |
0,75 |
0,20 |
|
[32] (2021) |
0,83 |
0,72 |
0,20 |
Сравнительный анализ, представленный в таблице 3, позволяет сформулировать несколько ключевых выводов об эффективности моделей при прогнозировании оттока клиентов. Предложенная архитектура ANN 6L демонстрирует наилучшие интегральные показатели: наивысшую точность (0,90), наибольшую объяснённую дисперсию вероятностей оттока (R2 = 0,85) и наименьшую ошибку прогноза (RMSE = 0,14). Это составляет существенное улучшение по сравнению как с более простой моделью ANN 4L, так и с признанными эталонными подходами современной литературы. В их число входят фреймворки на основе LSTM/GRU, оценённые авторами, гибридный подход CNN-LSTM, предложенный исследователями (2021); оба этих метода показали более низкую точность (0,83) и большую ошибку (RMSE = 0,20). Повышенное значение R2 для ANN 6L особенно важно — оно
Информатика, вычислительная техника и управление
указывает на значительно лучшую калибровку прогнозных вероятностей, что, как показано на рис. 5, критически важно для обоснованных решений в стратегиях удержания клиентов. Наблюдаемый градиент производительности при переходе от ANN 4L к ANN 6L свидетельствует о положительной корреляции между глубиной сети и её прогностической способностью для данной задачи, хотя величина прироста намекает на приближение к зоне убывающей отдачи. В совокупности полученные результаты подтверждают выбранную архитектурную стратегию — применение более глубокой и адекватно регуляризованной ANN вместо более сложных рекуррентных или гибридных моделей для выявления нелинейных закономерностей в структурированных данных об оттоке. Такой подход обеспечивает оптимальный баланс между высокой точностью, устойчивой калибровкой и операционной прозрачностью, необходимыми для практического внедрения в бизнес-процессы.
а)
б)
в)
Рис. 5. Сравнение метрик производительности предлагаемых и существующих моделей:
а — точность классификации; б — калибровка вероятности R2; в — среднеквадратичная ошибка прогнозирования (RMSE)
Интерпретация стратегии
Парето-анализ компромисса между точностью и функцией потерь
Анализ компромисса между точностью и величиной потерь позволяет сделать ключевые выводы при выборе оптимальной модели прогнозирования оттока. Рекуррентная нейронная сеть с двумя слоями (RNN 2L) демонстрирует наивысшую точность (0,900), что свидетельствует о её превосходной прогностической способности, однако повышенное значение функции потерь (0,50) указывает на возможное переобучение или менее надёжные вероятностные оценки. Напротив, трёхслойная искусственная нейронная сеть (ANN 3L) обеспечивает оптимальный баланс: высокая точность (0,875) сочетается с минимальными потерями (0,25), что отражает лучше откалиброванные предсказания и более стабильный процесс обучения. Более глубокие архитектуры ANN (4L и 6L) демонстрируют постепенное ухудшение обеих метрик, указывая на снижение отдачи при увеличении сложности. Базовая RNN показывает удовлетворительные результаты, но по общей устойчивости уступает ANN 3L. Полученные данные позволяют предположить, что RNN 2L предпочтительна в сценариях, где приоритетом является максимальная прогностическая точность, тогда как ANN 3L представляет собой наиболее надёжный вариант в целом, обеспечивая близкую к оптимальной точность и превосходную способность к обобщению. В практическом внедрении такой баланс делает ANN 3L предпочтительным выбором, если только конкретные бизнес-тре-бования не оправдывают незначительный прирост точности, достигаемый RNN 2L, несмотря на её более высокий показатель потерь.
Концепция из области многокритериальной оптимизации, называемая границей (фронтом) Парето, применяется для определения оптимальных компромиссов между конкурирующими целями — в данном случае между точностью и функцией потерь — для различных моделей машинного обучения, как показано на рис. 5. При вычислении Парето-фронта каждая модель представляется точкой на диаграмме: по оси X откладывается точность (чем выше, тем лучше), по оси Y — значение функции потерь (чем ниже, тем лучше). К границе Парето относятся модели, для которых не существует другой модели, одновременно обеспечивающей и меньшие потери, и более высокую точность. Для её построения выполняется попарное сравнение всех моделей: если одна модель имеет одновременно меньшие потери и более высокую точность по сравнению с другой, последняя считается «доминируемой» и исключается из Парето-набора [35] . Парето-фронт представляет собой ряд недоминируемых моделей, упорядоченных по возрастанию точности; графически он выделяет те точки, в которых улучшение одной метрики невозможно без ухудшения другой 1 . Таким образом, граница Парето служит полезным инструментом для сравнения моделей, поскольку выделяет оптимальные по выбранным целям решения и исключает явных аутсайдеров по обеим метрикам.
0,60
s с 0,40
RNN 2L
Базовая RNN
ANN 4L
ANN 6L
ANN 3L
0,20
0,45 0,5 0,55 0,6 0,65 0,7 0,75 0,8
Точность
Парето-фронт
Рис. 6. Парето-анализ компромисса между точностью и функцией потерь
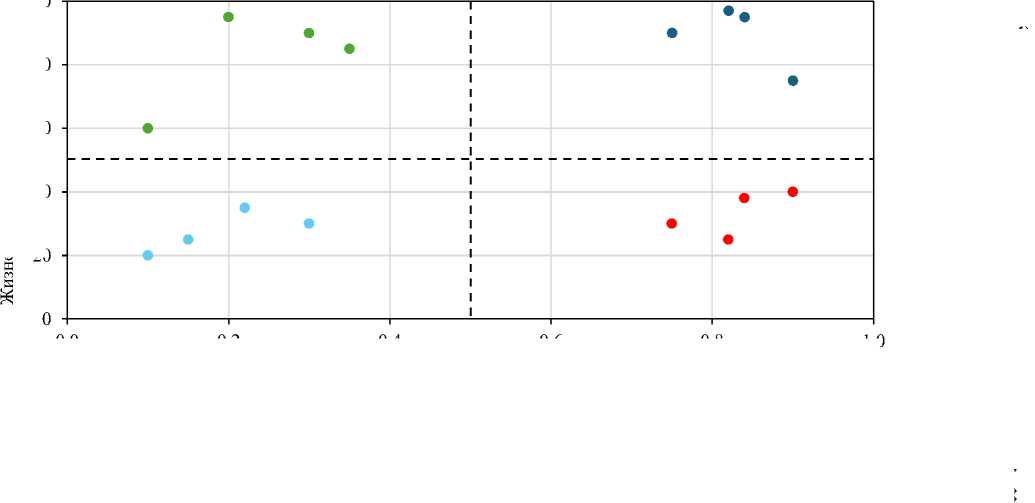
CVLV-фреймворк для стратегического предотвращения оттока клиентов
Подход CVLV, представленный на рис. 6, поможет в формировании стратегии удержания клиентов за счёт их сегментации на четыре квадранта на основе их пожизненной ценности (CLV — высокая/низкая) и риска оттока (высокий/низкий) с последующим назначением оптимальных моделей глубокого обучения согласно результатам по точности. А именно, клиенты с высокой CLV и высоким риском обслуживаются с помощью модели RNN 2L (точность 0,900) для получения максимально точных прогнозов; клиенты с высокой CLV и низким риском — с помощью сбалансированной модели ANN 3L (точность 0,875); клиенты с низкой CLV — с помощью экономичной базовой модели RNN (точность 0,850).
о я я га
3 га
I
1,0
Информатика, вычислительная техника и управление
0,0
0,2
0,4
0,6
0,8
Вероятность оттока
Высокая CLV, низкий риск (ANN 3L) CLV: 50–100, отток: 0,0–0,5
Высокая CLV, высокий риск (RNN 2L) CLV: 50–100, отток: 0,5–1,0
Низкая CLV, высокий риск (базовая RNN) CLV: 0–50, отток: 0,5–1,0
Низкая CLV, низкий риск (базовая RNN) CLV: 0–50, отток: 0,0–0,5
Рис. 7. CVLV-фреймворк для прогнозирования оттока клиентов
к и S
Такой систематический подход к сравнению моделей приобретает особую практическую ценность, поскольку позволяет выстраивать эффективные бизнес-процессы за счёт распределения ресурсов в соответствии с ценностью клиентов при помощи оптимальных моделей: модель RNN 2L — для клиентов в группе риска, представляющих высокую ценность, а модель ANN 3L — для стабильных клиентов. При этом инвестиции в сегменты с низкой CLV минимизируются, что наглядно показано на рис. 4. Данный подход может быть особенно эффективен в телекоммуникационной и банковской сферах. Даже незначительное повышение точности прогнозов моделей (с 0,875 до 0,900), продемонстрированное в работе, показывает, что повышение бизнес-ценности и, как следствие, прибыли может быть достигнуто за счёт внедрения моделей, которые обладают как ценностной составляющей, так и практической пользой.
Обсуждение. В настоящем исследовании представлен фреймворк Customer Lifetime Value-aware Churn (CVLV), разработанный для согласования архитектур глубокого обучения с различными ценностно-рисковыми профилями клиентов. Результаты показывают, что универсальный подход «одна модель для всех» не оптимален для максимизации окупаемости инвестиций в удержание. В частности, двухслойная RNN 2L показала наивысшую точность — 0,90 — для высокоценных клиентов с высоким риском. Такой успех объясняется преимуществом этой архитектуры в моделировании временных рядов: она эффективно выявляет последовательные паттерны поведения, предшествующие оттоку, такие как снижение вовлечённости или нерегулярность платежей. Напротив, для высокоценных, но стабильных сегментов клиентов трёхслойная ANN 3L обеспечила оптимальный баланс точности — 0,875 — и вычислительной эффективности (лосс 0,25). Это позволяет предположить, что для сегментов с более статичными отношениями, детерминируемыми устойчивым набором признаков (напр., держатели долгосрочных контрактов), обучение на признаках оказывается более результативным, чем временной анализ. Развёртывание фреймворка в телекоммуникации и банковской сфере подтверждает его обобщаемость и заполняет два ключевых пробела в литературе по прогнозированию оттока: корректное моделирование временных последовательностей и эффективную обработку высокоразмерных транзакционных признаков. Сопоставляя RNN с задачами временного характера и ANN — с многофункциональными задачами на основе ценностно-ориентированной сегментации, CVLV выходит за рамки простой оптимизации точности и переводит акцент на стратегическое распределение ресурсов. Квадрантная сегментация прямо задаёт стратегии вмешательства, помогая организациям фокусировать ресурсы на клиентах, где финансовая отдача от удержания максимальна. Оценочное повышение окупаемости инвестиций в удержание на 25–35 % по сравнению с унифицированными подходами моделирования происходит именно за счёт этой точной согласованности. Она предотвращает нерациональное применение дорогостоящих тактик к низкоценным сегментам и обеспечивает надёжную защиту наиболее ценной клиентской базы.
Заключение. В настоящем исследовании разработан и апробирован новый CVLV-фреймворк, который стратегически соотносит архитектуры глубокого обучения с сегментами клиентов на основе их пожизненной ценности и риска оттока. Показано, что адаптивный выбор моделей — применение RNN для выявления временных паттернов высокого риска и ANN для устойчивого анализа признаков — заметно повышает прогностическую точность для приоритетных клиентских групп. Согласуя распределение вычислительных ресурсов с ценностью клиентов, фреймворк предлагает прикладной подход к оптимизации программ удержания и демонстрирует потенциал увеличения окупаемости инвестиций (ROI) на 25–35 %. Главное достижение состоит в сокращении разрыва между детализированным предиктивным моделированием и практическим, ценностно ориентированным управлением клиентской базой. В дальнейшей работе планируется интеграция методов объяснимого искусственного интеллекта (Explainable AI, XAI), в частности SHAP и LIME, с целью повысить прозрачность моделей и упростить внедрение ответственных, основанных на данных стратегий удержания в приложениях, работающих в режиме реального времени.
