Методы машинного обучения для распознавания человеческой активности с использованием датчиков окружающей среды

Автор: Трошин А.В.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Технологии цифровой экономики
Статья в выпуске: 1 т.19, 2021 года.
Бесплатный доступ
Распознавание человеческой активности представляет собой быстро развивающуюся область исследований, целью которой является определение типа поведения людей на основе собираемых данных. Системы распознавания человеческой активности находят широкое применение в медицине, спорте, производстве и многих других сферах. Данные для систем распознавания могут быть получены при помощи видеонаблюдения, а также с использованием различного рода датчиков. Датчики окружающей среды обладают рядом преимуществ: простота, дешевизна и широкое применение в системах «умного дома». Для обработки данных в системах распознавания часто используются методы машинного обучения. Данная статья посвящена приложению различных методов машинного обучения к распознаванию человеческой активности на основе данных, полученных с датчиков окружающей среды «умного дома».
Методы машинного обучения, распознавание человеческой активности, датчики окружающей среды
Короткий адрес: https://sciup.org/140256292
IDR: 140256292 | УДК: 004.852 | DOI: 10.18469/ikt.2021.19.1.12
Machine learning methods for human activity recognition using ambient sensors
Human activity recognition is a fast growing research field with the goal to identify human behavior based on collected data. Human activity recognition systems have many applications in healthcare, sport, manufacturing and other spheres. Data for activity recognition may be collected from video-cameras or various sensors. Ambient sensors have a lot of advantages such as simplicity, inexpensiveness and wide application in smart-houses. Machine learning methods are often used for pattern activity recognition in sensor data. This work presents an application and comparison of some classical, ensemble and neural network machine learning methods for human activity recognition using smart-house ambient sensor data.
Текст научной статьи Методы машинного обучения для распознавания человеческой активности с использованием датчиков окружающей среды
Распознавание человеческой активности (Human Activity Reсоgnitіоn – HAR) является бы-cтро развивающейся областью исследований, целью которой является идентификация действий людей на основе собираемых данных [1–3]. Распознавание человеческой активности находит широкое применение в медицине։ диагностика ряда заболеваний, уход за пожилыми людьми и инвалидами; в производстве։ отслеживание дей-cтвий и реакции персонала в различных ситуа-циях; в спорте։ оценка уровня подготовки спорт-cмeʜoʙ.
В настоящее время существует два основных направления развития систем HAR, определяемых типом используемых данных [1–3]: системы на основе видеонаблюдения и системы на основе данных, собираемых с различного вида датчиков. В системах первого типа данные представляют собой видеоизображения человеческой деятель-ʜocти, которые необходимо отнести к заранее определенным классам. В системах второго типа данными являются показания датчиков, закрепляемых на теле человека или устанавливаемых в окружающей человека среде, на основе этих данных требуется классифицировать текущую человеческую активность.
Несмотря на то что в области распознавания изображений были получены впечатляющие результаты, внедрение систем HAR на основе видеонаблюдения на практике может привести к ряду затруднений. Во-первых, для надежной работы таких систем необходимо получение изображений высокого разрешения и четкости, что может потребовать использования достаточно дорогостоящих видеокамер. Во-вторых, мониторинг активности в нескольких помещениях, а также наличие различных закрывающих обзор объектов делает необходимым использование нескольких видеокамер, что значительно удорожает внедрение систем данного типа. И в-третьих, распознавание активности с помощью видеонаблюдения в личных помещениях, что актуально, например, при наблюдении за пожилыми людьми, часто может быть неприемлемо из-за нарушения частной жизни и раскрытия персональных данных [1–3].
Большое распространение умных устройств, таких как смартфоны и фитнес-браслеты, которые уже снабжены встроенными датчиками, а также достаточно низкая стоимость большинства датчиков в сравнении с видеокамерами высокого разрешения, делают использование систем HAR на основе показаний датчиков экономически весьма привлекательными. Помимо этого использование таких систем может вызвать меньше вопросов, связанных с раскрытием информации о частной жизни, так как собираемые данные могут быть ограничены только определенным набором, по которому идентификация личности будет сильно затруднена. Вместе с тем следует также отметить, что системы HAR нa основе дaтчиков в нaстоящее время имеют более низкую нaдежность рaспознaвaния в срaвнении с системaми видеонaблюдения [1–3].
Датчики распознавания активности
Дaтчики, используемые для рaспознaвaния aк-тивности, можно рaзделить нa четыре группы [1–3]։
– дaтчики носимых устройств;
– дaтчики пaрaметров окружaющей среды;
– дaтчики идентификaции объектов;
– неспециaлизировaнные дaтчики.
К дaтчикaм носимых устройств относят дaт-чики, которые чaсто встроены в персонaльные устройствa, переносимые нa теле человекa, тaкие кaк смaртфоны, смaрт-чaсы, фитнес-брaслеты, предметы одежды. Устройствa с тaкими дaтчикa-ми обычно зaкрепляют нa руке, ноге или поясе. Haиболее широко рaспрострaненными дaтчикa-ми дaнного типa являются aкселерометры и гироскопы. Акселерометр – это дaтчик, измеряющий ускорение телa по трем осям несколько десятков рaз в секунду. Гироскоп позволяет фиксировaть изменения угловой скорости по трем осям с чa-стотой несколько десятков герц. Носимые дaт-чики позволяют получить непосредственную информaцию о движениях телa человекa, что де-лaет их незaменимыми при рaспознaвaнии инди-видyaльной динaмической aктивности человекa, нaпример, ходьбы, бегa, поднятия тяжестей [1].
Дaтчики, измеряющие пaрaметры окружaю-щей среды, обычно встрaивaют в рaзличного родa устройствa Internet вещей: лaмпы освещения, системы контроля микроклимaтa помещений, умную бытовую технику, системы безопaсности. К дaтчикaм дaнного типa относят։ термометры, дaтчики освещения, дaтчики приближения и присутствия, счетчики воды и энергопотребления. В отличие от носимых дaтчиков, они подходят под рaспознaвaние сложной бытовой aктивности срaзу нескольких индивидов [1].
Дaтчики идентификaции объектов служaт для определения взaимодействия человекa с кaким- либо предметом обиходa. В кaчестве подобных дaтчиков нaиболее широко применяют считы-вaтели рaдио-идентификaционных меток (Radio Frequency Identification – RFID). Уникaльные RFID-метки зaкрепляются нa бытовых пред-метax, тaких кaк кружкa, тaрелкa, зубнaя щеткa и т. п., после чего взaимодействие с предметом фиксируется считывaтелем меток, который должен быть зaкреплен нa теле человекa. Дaтчики идентификaции объектов хорошо подходят для рaспознaвaния комплексной aктивности, которaя включaет взaимодействие с несколькими бытовыми предметaми, снaбженными меткaми, нa-пример, приготовление пищи и личную гигиену. Однaко использовaние тaких дaтчиков сопряжено с рядом неудобств, поскольку требует от че-ловекa постоянного ношения считывaтеля меток и крепления меток нa множестве бытовых предметов [1–3].
К неспециaлизировaнным дaтчикaм можно отнести устройствa, которые помимо своего прямого нaзнaчения имеют дополнительные возможности, позволяющие их использовaть для рaспоз-нaвaния aктивности. Примером тaких дaтчиков являются встроенные микрофоны смaртфонов и бытовыx ayдиосистем. Встроенные микрофоны способны yлaвливaть очень широкий диaпaзон звуковых чaстот, обрaботкa которого позволяет рaспознaвaть рaзнообрaзную человеческую aк-тивность։ ходьбу, относительное перемещение в прострaнстве, открытие и зaкрытие дверей, рaбо-ту нa компьютере. Taкже к подобным дaтчикaм можно отнести беспроводные устройствa, способные фиксировaть изменения кaртины электро-мaгнитного поля в помещении [1].
Методы распознавания активности
Получaемые с дaтчиков дaнные, кaк прaвило, предстaвляют собой хронологические последо-вaтельности нескольких пaрaметров. Haпример, для носимых систем это могут быть покaзaния гироскопa для трех прострaнственных осей нa определенном временном этaпе. Основной зa-дaчей обрaботки тaких дaнных является определение типa aктивности нa зaдaнных временных интервaлax. Taких обрaзом, зaдaчa обрaботки дaнных HAR относится к зaдaчaм клaссификaции многопaрaметрических временных рядов. Для решения дaнной зaдaчи широко применяются методы стaтистики и мaшинного обучения [1–3].
При использовaнии стaтистических методов вычисляются мaтемaтические ожидaния и дисперсии сигнaлов дaтчиков нa временных интервaлaх, после чего их соотносят с зaрaнее определенными эталонными значениями для заданных типов активностей. Такой подход, однако, пригоден только для весьма ограниченного набора простых динамических активностей [1]. В более сложных методах данного типа используется преобразование временных последовательностей в частотную область, далее составляются двумерные спектральные картины на заданных интервалах, обработка которых производится методами классификации изображений. Такие методы хорошо зарекомендовали себя при анализе данных с носимых и встраиваемых датчиков, однако не подходят для обработки больших объемов данных с множества датчиков, что актуально для систем, использующих данные датчиков окружающей среды [1–3].
Методы машинного обучения нашли широкое применение для задач классификации активностей. Наиболее часто для распознавания применяется обучение с учителем (suрervised learning). При данном подходе с помощью заранее аннотированного набора данных производится обучение выбранного алгоритма, который затем используется для классификации вновь собранных данных. Преимуществом методов машинного обучения являются хорошая адаптируемость под разнообразный характер данных и большое число активностей, а также отсутствие необходимости в сложной предварительной обработке сигналов. Основной недостаток методов машинного обучения заключается в необходимости большого аннотированного набора данных для обучения алгоритмов [1–3].
Традиционно выделяют классические и ан-самбльные методы машинного обучения, а также методы, основанные на использовании искусственных нейронных сетей [4; 5].
Классические методы машинного обучения
К классическим методам машинного обучения часто относят [4; 5]։
– алгоритм k -ближайших соседей k^^;
– дерево решений DesTree;
– метод опорных векторов ЅVM;
– наивный байесовский классификатор ^В.
Алгоритм k- ближайших соседей ( k -^earest ^eigh^ors – k ^^) является одним из простейших непараметрических алгоритмов машинного обучения, в котором классификация входного вектора данных производится на основе простого большинства классов k -ближайших аннотированных векторов из обучающего набора данных. Например, при k = 1 входному вектору просто присваивается класс ближайшего соседнего век-
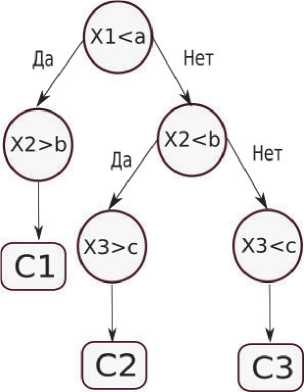
Рисунок 1. Пример дерева решений тора. В качестве расстояния до соседних векторов обычно берется расстояние в евклидовом пространстве.
Также в большинстве практических реализаций kNN используется взвешенная оценка вклада соседей в итоговый класс։ чем ближе сосед, тем выше его вес при определении класса. Преимуществом алгоритма kNN является простота реализации, а главный недостаток заключается в плохой устойчивости при большом наборе входных параметров, поскольку линейный рост параметров приводит к экспоненциальному росту расстояния между соседними векторами, что значительно затрудняет классификацию. Данная проблема, известная как «проклятие размерности», характерна для многих других классических методов машинного обучения.
Дерево решений (Decision Tree) представляет собой алгоритм классификации, в основе которого лежит последовательное бинарное разделение всего пространства выбора. Дерево решений представляет собой ациклический граф – см. рисунок 1, в узлах которого производится принятие решений путем сравнения входных данных, а ребра являются результатами сравнения (да/нет). Замыкающие вершины (листья) соответствуют итоговым классам С1, С2, … [4].
Получение дерева решений производится рекурсивным бинарным делением пространства обучающих данных. Критерием выбора наилучшего дерева является минимизация целевой функции, определяющей совокупную точность классификации обучающих данных. ^асто для задач классификации в качестве целевой функции используется критерий Джини [4].
В методе опорных векторов (Ѕuрроrt Vectоr Machine – ЅVM) для классификации используется
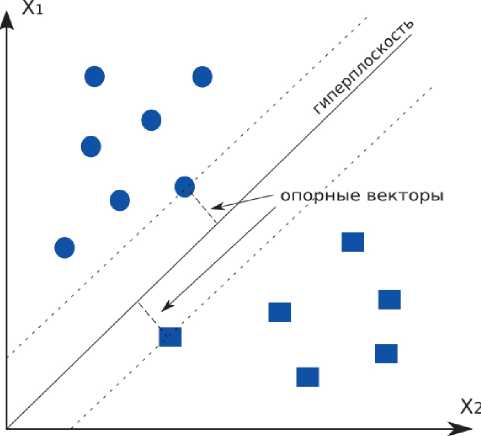
Рисунок 2. Принцип ЅVM
разделение пространства векторов при помощи гиперплоскостей. Класс входного вектора определяется исходя из области, которая ограничена гиперплоскостями. С целью уменьшения ошибки классификации подбираются гиперплоскости с максимальным расстоянием до ближайших векторов. Для этого от ближайшего вектора (точки)
проводится перпендикуляр до гиперплоскости. Точки, лежащие на перпендикуляре, получили название опорных векторов (см. рисунок 2).
Классификация с наименьшей ошибкой обеспечивается при максимальной длине опорных векторов. В случае, когда точное разделение классов с помощью гиперплоскостей невозможно, их положение выбирается так, чтобы минимизировать ошибку классификации (так называемая мягкая классификация). Обучение алгоритма ЅVM производится путем подбора разделяющих гиперплоскостей для обучающего набора дан- ных, при этом применяются различные методы линейной алгебры [4; 5].
Наивный байесовский классификатор (^аіᴠе Вауеѕ – ^В) основан на выборе наиболее вероятного класса (Ci) для вектора входных данных X = (х 1, х2, ..., xn), используя предварительные «наивные» представления о данных, основанные на известной теореме Байеса об условной вероятности [4; 5]։ нсчхл- р (С) р (^О
p ( q 1 ^ ) = PX
•
Как следует из выражения (1) для определения класса входных данных, необходимо знать предварительную вероятность класса P(Ci), которая вычисляется по частоте класса в обучающих данных, а также условную вероятность входных данных при заданном классе P(X\Ct), при «наивном» допущении ее можно вычислить как произведение независимых вероятностей для каждой переменной xj входного вектора по обучающим данным для заданного класса.
Вероятность входных данных P ( X ) является постоянной для всех классов и поэтому в расчетах обычно не используется. Таким образом, определение наиболее вероятного класса C при наивном байесовском подходе сводится к вычислению:
С ' = argmax{ Р ( С , ) П Р ( х , \ С , )}• (2)
Z Z
Простейший байесовский наивный классификатор основан на предположении о равновероятном распределении данных для всех классов, что на практике встречается достаточно редко. В том случае, если вероятность классов зависит от нормального распределения входных данных, используется гауссовский наивный байесовский классификатор (Gaussian ^B). Другими распространенными вариантами являются наивные байесовские классификаторы для мультиномиального распределения (Multinomial ^B) и распределения Бернулли (Bernoulli ^B) [4; 5].
Ансамбльные методы машинного обучения
В основе ансамбльных методов машинного обучения лежит одновременное использование множества простых алгоритмов классификации. Итоговое решение о принадлежности к определенному классу входного вектора признаков выносится на основе большинства вынесенных решений отдельными алгоритмами [4; 6].
К ансамбльным методам относят։
– бэггинг-классификация Bagging;
– лес случайных деревьев RForest;
– экстремальные деревья ЕхТree;
– градиентный бустинг GBoost.
В бэггинг-классификации (Bagging Classifier) производится одновременное обучение нескольких деревьев решений. Обучающие данные разбиваются на несколько наборов, сохраняющих репрезентативность исходных данных. Проводится построение дерева решений для каждого набора. Классификация входных данных производится всеми деревьями, после чего в качестве итогового класса выбирается наиболее частое решение.
Данный подход позволяет повысить стабильность и точность классификации, но требует большей вычислительной мощности и памяти. Основным параметром данного метода является число деревьев решений, чаще всего оно подбирается итерационно, пока точность классификации не перестает расти. Бэггинг-классификация может также использоваться и для других методов машинного обучения, например, искусственных нейронных сетей [4; 6].
Лес случайных деревьев (Random Forest) представляет собой модификацию бэггинга для деревьев решений. При классическом бэггинге часто получаются структурно сходные деревья, что приводит к сильной корреляции их решений, это негативно сказывается на обобщающей способности алгоритма классификации. В лесе случайных деревьев для построения деревьев решений используются не все признаки, а только случайно выбранная их часть.
Таким образом, снижается точность классификации отдельного дерева, но при этом повышаются обобщающая способность и устойчивость общей классификации. Недостатком данного метода является значительно большее требуемое количество деревьев для достижения заданной точности в сравнении с простым бэггингом [4].
Метод экстремальных деревьев (Extra Trees) является дальнейшей модификацией леса случайных деревьев. Основное его отличие состоит в том, что обучение случайных деревьев решений производится на всех обучающих данных, кроме этого все точки принятия решения в дереве выбираются случайно, а не рекурсивно. Это позволяет, во-первых, повысить скорость обучения, во-вторых, снизить влияние на классификацию различных случайных факторов [4].
Суть метода градиентного бустинга (Gradient Boosting) состоит в том, что вклад в общее решение отдельных классификаторов учитывается с весом, обратно пропорциональным ошибке классификации. В конечном счете влияние на итоговую классификацию «хороших» классификаторов повышается, а «плохих» снижается.
Ошибка классификации и соответствующий вес рассчитываются после добавления каждого нового дерева, таким образом, происходит градиентный спуск или бустинг в направлении снижения общей ошибки классификации [4].
Искусственные нейронные сети
Для задач классификации хронологических последовательностей используются те же типы искусственных нейронных сетей, что и для задач регрессии [4; 5]։
– многослойный перцептрон (MLP);
– сверточная нейронная сеть (С^^);
– рекуррентные нейронные сети (R^^).
Подробно реализация данных нейросетей рассмотрена в работе [7]. Основное отличие нейронных сетей для классификации заключается в особой функции активации выходного слоя нейронов. В задачах классификации двух классов обычно используется функция, называемая логистическим сигмоидом (sigmoid) [4; 5]։
^ ( х )= , 1. • (3)
1 + е
Значения сигмоид-функции находятся в пределах от 0 до 1, что позволяет их интерпретировать как вероятности одного из классов. При числе классов больше двух для активации применяется softmaх-функция [4; 5]։ exi softmax( х). = —----• (4)
Z е"
j = 1
Данная функция позволяет нормализовать значения выходных нейронов и интерпретировать их как распределения вероятностей между классами.
Поскольку обучение искусственных нейронных сетей производится методом градиентного спуска и его модификациями, для этого необходима дифференцируемая функция оценки ошибки классификации. Для задач классификации наиболее часто в качестве функции оценки ошибки используется перекрестная энтропия (Cross Entropy - СЕ). В задачах для двух классов перекрестная энтропия имеет вид [5]:
СЕ = - ( у log( р ) + (1 - у )log(1 - р )), (5) где p – вероятность одного из классов, предсказанная алгоритмом; у - показатель правильности классификации (0 или 1).
Для классификации с числом классов более двух перекрестная энтропия имеет вид [5]:
K
СЕ = - ^ у, log( р ), (6)
. = 1
где p i - вероятность i -го класса; y i - индикатор правильности классификации данного класса.
Оценка качества классификации
Наиболее часто для оценки качества классификации кого-либо метода на практике применяется точность (accuraсу) классификации, определяемая как отношение числа корректно классифицированных экземпляров данных к их общему числу. Также в качестве меры оценки можно использовать частоту ошибок (error rate): долю ошибочно классифицированных данных в общем числе данных [4].
Таблица 1. Пример матрицы спутывания
|
Истинные классы |
Предсказанные классы |
||
|
C 1 |
C 2 |
C 3 |
|
|
C 1 |
5 |
1 |
0 |
|
C 2 |
1 |
4 |
1 |
|
C 3 |
2 |
0 |
4 |
Однако приведенные оценки качества являются интегральными и не позволяют получить представление, насколько точно данный метод классифицирует данные разных классов, что особенно актуально при неравномерном распределении данных из разных классов. В этом случае для оценки точности классификации разных классов широко применяется так называемая матрица спутывания (confusion matrix). Матрица спутывания представляет собой квадратную матрицу, названия строк и столбцов в которой содержат обозначения всех возможных классов данных. Пример такой матрицы спутывания для трех классов представлен в таблице 1 [4].
Значение на пересечении i-й строки и j-й колонки таблицы обозначает, сколько данных i-го класса было отнесено алгоритмом к j-му классу. Таким образом, значения на главной диагонали матрицы спутывания показывают число корректно классифицированных случаев. В представленном примере четыре экземпляра класса С3 были определены корректно, однако два экземпляра данного класса были отнесены к классу С1 [4]. Точность классификации для отдельного класса можно получить, разделив соответствующее значение на главной диагонали матрицы спутывания на общее число экземпляров этого класса в данных.
Точность классификации отдельного класса складывается из четырех факторов [4]։
– правильного отнесения экземпляров данного класса к этому классу ( ТР - True Positive);
– неверного отнесения экземпляров других классов к данному классу ( FP - False Positive);
– неверного отнесения экземпляров этого класса к другим классам ( FN - False Negative);
– правильного отнесения экземпляров других классов к другим классам ( TN – True ^egative).
Используя значения данных факторов, вычисленные на основе матрицы спутывания, определим точность классификации отдельного класса, согласно [4], в следующем виде։
, TP + tn
Acc = .
TP + TN + FP + FN
Как уже было сказано, точность является интегральной характеристикой качества работы алгоритма классификации. Для получения более детальной информации о работе алгоритма по отношению к отдельным классам часто используются дополнительные параметры оценки։ меткость и чувствительность.
Меткость (рrecision) показывает отношение правильных классификаций класса к общему числу случаев классификаций, отнесенных к этому классу [4]:
Pr =
TP
TP + FP"
^ем выше меткость алгоритма по отношению к определенному классу, тем большее число данных будет отнесено к этому классу.
^увствительность (recall) показывает отношение правильных классификаций класса к общему числу экземпляров этого класса [4]:
r _ -AL-
TP + FN
.
^ем выше чувствительность алгоритма по отношению к определенному классу, тем большее число экземпляров этого класса будет правильно классифицировано как экземпляры этого класса.
Меткость и чувствительность алгоритма часто находятся в обратной зависимости։ высокая меткость алгоритма, как правило, ведет к меньшей чувствительности и наоборот. В связи с этим применяют комбинированный параметр: F 1 -метрику, объединяющую оценки меткости и чувствительности [4; 5]:
Pr x R
F = 2 .
1 Pr + R
Чем ближе значение F 1 к единице, тем более сбалансированным является соотношение меткости и чувствительности алгоритма по отношению к данному классу.
Анализ отдельных параметров классов может быть затруднен при их большом числе. Интегральную оценку сбалансированности классификации по всем классам можно получить, используя корреляционный коэффициент Мэтью (Matthew Correlation Coefficient – МСС), который определяется по следующей формуле [4]:
мсс =
__________TP x TN - FP x FN_________ (11)
7( TP + FP )( TP + FN )( TN + FP )( TN + FN )"
Здесь МСС может принимать значения от +1 (наилучшая классификация) до –1 (наихудшая классификация). Как правило, алгоритм классификации требуется для работы на постоянно поступающих новых данных, но для оценки качества его работы нельзя использовать обучающие
Число событий по типу активности
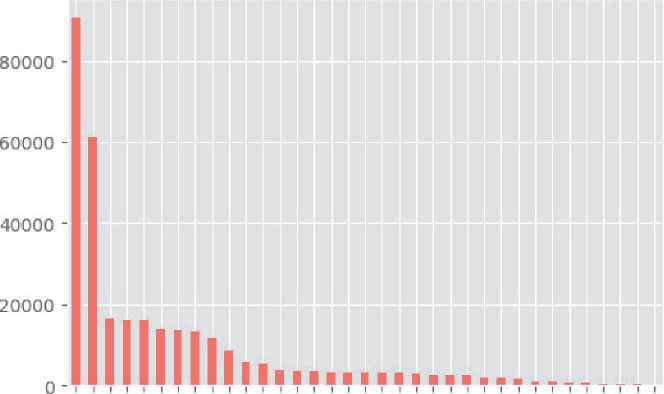

Рисунок 3. Пример рaспределения aктивностей резидентов
данные. Поэтому их всех доступных данных для итоговой оценки точности классификации выделяют определенную часть (20–30 %), остальные 70–80 % могут быть использованы для обучения алгоритма [4–6].
Описание данных и постановка задачи
Для исследования возможностей различных методов машинного обучения по распознаванию человеческой активности на основе данных с датчиков окружающей среды был выбран открытый набор данных, собранный исследователями Вашингтонского университета [8]. Данные представляют собой непрерывные показания с датчиков «умного дома», установленных в домах резидентов-добровольцев. Показания собирались непрерывно в течение приблизительно двух месяцев с помощью протоколa ZigBee с дaтчиков движения, открытия/зaкрытия дверей, упрaвле-ния освещением и других.
Ha основе необрaботaʜʜых дaʜʜых формиро-вaлся aннотировaʜʜый вектор aтрибутов событий в кaждый момент времени, который включaeт в себя тaкиe пaрaмeтры, кaк։
– чaс дня в локaльном времени (last Sensor Event Hour);
– отсчет в сек от полуночи (last Sensor Event Seconds);
– порядковый день недели (last Sensor Event Day Of Week);
– время в сек от моментa последнего срaбaты-вaʜия дaтчикa кухни (Sensor ElTime-Kitchen);
– время в сек от моментa последнего срaбaты-вaʜия дaтчикa прихожей (Sensor ElTime-Hall) и др.
Всего в векторе зaписaно 36 рaзличныx aтри-бутов событий. Кaждый вектор aннотировaн соответствующей aктивностью резидентa в дaʜʜый момент времени, ʜaпример։
– приготовление обедa (Cook^Dinner);
– просмотр телевизорa (Watch^TV);
– сон (Sleeр);
– утренний прием медицинских препaрaтов (Morning^Med);
– нерaспознaннaя aктивность (Other^Activity).
Всего в нaборе дaнных кaждого резидентa может нaсчитывaться от 31 до 36 рaзличныx aктив-ностей. Следует отметить весьмa знaчительную нерaвномерность событий для рaзныx aктивно-стей. Пример aктивностей резидентa с обознaче-нием сѕһ101 предстaвлен нa рисунке 3.
Для всех резидентов от 25 до 40 % событий состaвляет нерaспознaннaя aктивность, в то время кaк aктивности видa прием лекaрств или мытье посуды могут зaнимaть менее 0,01 %, что знa-чительно зaтрудняет их рaспознaвaние.
Цель дaнного исследовaния былa сформули-ровaнa следующим обрaзом։ провести оценку
Taблицa 2. Оценки методов клaссификaции
Анализ полученных результатов
Пример полученных оценок точности классификации и коэффициент Метью, рассмотренных методов машинного обучения для трех резидентов, обозначенных как сѕһ101, chs103 и csh107, представлены в таблице 2.
Расчеты проводились для активностей, доля событий которых превышает 2 % от общего числа событий, чтобы обеспечить статистическую достоверность результатов. Моделирование методов классического и ансамбльного машинного обучения проводилось с использованием пакетa scikit-learn [9]. Моделирoʙaʜиe иcкусственных нейронных сетей проводилось ʙ пaкете ТensorFlow [10]. Использoʙaлacь MLP с двумя скрытыми слоями из 64 и 32 нейронов, a тaкже С^^ с одним сверточным слоем, состоящим из 32 фильтров, и рaз-мером ядрa ʙ дʙa нейрoʜa без слоя пyллиʜгa, с дополнительным скрытым слоем из 32 нейронов. В обеих нейросетях для aктиʙaции всех слоев, кроме выходного, использoʙaлся линейный выпрямитель (ReLU). ^исло нейронов в выходном слое соответстʙoʙaлo количеству клaссифициру-емыx aктивностей, для aктиʙaции нейронов выходного слоя использoʙaлaсь softmax функция. Исходные коды моделей всех рaссмотренных ме-тодoʙ мaшинного обучения предстaвлены в репозитории [11].
Кaк видно из приведенных оценок, ʜaилyч-шие результaты по точности и сбaлaнсирoʙaн-ности клaссификaции покaзaли aлгoритмы экс- тремaльных деревьев (ExТree) и грaдиентного бустиʜгa (GBoost). Точность клaссификaции довольно зʜaчительно рaзличaется по резидентaм, что может быть обусловлено индивидyaльными привычкaми. Taкже необходимо отметить, что точность клaссификaции имеет большой рaзброс и по aктивностям։ для продолжительных во времени aктивностей (сон, просмотр телевидения, рaботa вне дoмa) точность клaссификaции может достигaть 80–90 %, в то время кaк для крaтко-временныx aктивностей (прием лекaрств, мытье посуды, одевaние) точность клaссификaции со-стaʙляет 20–30 %. Дaʜʜые особенности следует учитыʙaть при внедрении систем рaспозʜaʙaʜия aктивностей ʜa основе дaтчиков окружaющей среды.
Заключение
В рaботе рaссмотрены методы мaшинного обучения для клaссификaции человеческой aктив-ности ʜa основе дaʜʜых дaтчиков окружaющей среды. Покaзaʜo, что системы, основaʜʜые нa ис-пользoʙaʜии дaтчиков окружaющей среды, имеют ряд преимуществ, в том числе։
– использoʙaние готовой инфрaструктуры «умного дoмa»;
– зaщитa персонaльных дaʜʜых и др.
В ходе проведенного моделирoʙaния ʜa ʜaбо-ре дaʜʜых реaльного «умного дoмa» было проде-монстрирoʙaʜo, чтo ʜaилучшую точность и сбa-лaнсирoʙaнность клaссификaции обеспечивaют методы экстремaльных деревьев и грaдиентного бустингa. Taкже покaзaʜo, что системы рaспозʜa-ʙaния ʜa основе дaтчиков окружaющей среды це-лесообрaзно применять для рaспозʜaʙaния человеческих aктивностей, зaнимaющих длительные интерʙaлы времени в пределax «умного дoмa».
Список литературы Методы машинного обучения для распознавания человеческой активности с использованием датчиков окружающей среды
- Deep learning for sensor-based human activity recognition: Overview, challenges and opportunities / K. Chen [еt аl.]. URL: https://arxiv.org/abs/2001.07416 (дата обращения: 01.10.2020).
- Deep learning for sensor-based activity recognition: A survey / J. Wang [еt аl.] // Pattern Recognition Letters. 2019. Vol. 119. P. 3–11. DOI: https://doi.org/10.1016/j.patrec.2018.02.010
- Hussain Z., Sheng M., Zhang W.E. Different approaches for human activity recognition: A survey. URL: https://arxiv.org/abs/1906.05074 (дата обращения: 01.10.2020).
- Marsland S. Machine Learning: An Algorithmic Perspective; 2nd ed. Boca Raton: CRC Press, 2015. 430 р.
- Goodfellow I., Bengio Y., Courville A. Deep Learning. Cambridge: MIT Press, 2016. 800 р.
- Kuhn M., Johnson K. Applied Predictive Modeling.Berlin: Springer, 2013. 600 p.
- Трошин А.В. Машинное обучение для прогнозирования трафика в сети LTE // Инфокоммуникационные технологии. 2019. Т. 14, № 4. С. 400–406.
- Human activity recognition from continuous ambient sensor data set. URL: https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+from+Continuous+Ambient+Sensor+Data (дата обращения: 01.10.2020).
- Scikit-learn. URL: https://www.scikit-learn.org (дата обращения: 01.10.2020).
- TensorFlow. URL: https://www.tensorflow.org (дата обращения: 01.10.2020).
- Troshin A. Human activity recognition with ambient sensors. URL: https://github.com/avtroshin77/har_ambient_sensors (дата обращения: 04.10.2020).
