Методы машинного обучения для решения задач по определению очагов возгорания

Автор: Копытов А.П., Кузин Д.А.
Журнал: Журнал Сибирского федерального университета. Серия: Техника и технологии @technologies-sfu
Рубрика: Информационно-коммуникационные технологии
Статья в выпуске: 1 т.19, 2026 года.
Бесплатный доступ
В данной статье представлен анализ алгоритмов машинного обучения «Случайный лес», «Логистическая регрессия» и «Сверточная нейронная сеть». Проведен обзор научной и научно- технической литературы по теме исследования, проанализированы ключевые преимущества и ограничения рассмотренных алгоритмов. Особое внимание уделено применению алгоритмов в задачах классификации изображений, сбору данных и подготовке спутниковых снимков к обучению. Статья содержит практическую реализацию и сравнительный анализ эффективности алгоритмов в различных условиях. Цель статьи – предоставить понимание математических основ алгоритмов и практических аспектов применения алгоритмов машинного обучения в определении пожаров на спутниковых изображениях.
Логистическая регрессия, случайный лес, сверточная нейронная сеть, спутниковые изображения, природный пожар, спектральные каналы, матрица ошибок, метрика ROC-AUC
Короткий адрес: https://sciup.org/146283258
IDR: 146283258 | УДК: 004.032.26
Machine Learning Methods for Solving Fire Detection Problems
This article presents an analysis of the machine learning algorithms «Random Forest», «Logistic Regression» and «Convolutional Neural Network». A review of scientific and technical literature on the topic of the study is conducted, the key advantages and limitations of the considered algorithms are analyzed. Particular attention is paid to the application of algorithms in image classification problems, data collection and preparation of satellite images for training. The article contains a practical implementation and comparative analysis of the efficiency of the algorithms in various conditions. The purpose of the article is to provide an understanding of the mathematical foundations of the algorithms and the practical aspects of applying machine learning algorithms to detect fires in satellite images.
Текст научной статьи Методы машинного обучения для решения задач по определению очагов возгорания
В России в год регистрируется от 9 до 35 тыс. лесных пожаров, охватывающих площади от 500 тыс. до нескольких млн га. Согласно данным МЧС России и Федерального агентства лесного хозяйства (Рослесхоз), с начала 1992 по конец 2018 г. в России было зарегистрировано более 630 тыс. лесных (затронувших земли лесного фонда) пожаров. Среди лидеров по масштабу охвата пожарами в России занимает Республика Саха. По данным Федерального агентства лесного хозяйства, за 2020 г. огонь охватил более 6 млн га лесных массивов, за 2021 г. – показатель приблизился к отметке 8 млн га [3].
Множество крупных городов и целых регионов оказались в опасной ситуации из-за задымления, которое продолжалось неделями. Среди причин, приведших к таким последствиям, можно назвать несвоевременное обнаружение очагов возгорания, позднее введение особого противопожарного режима и режима чрезвычайной ситуации на начальных этапах борьбы с огнём, а также аномальные погодные условия [1].
Для анализа спутниковых изображений используются различные методы и инструменты. Один из основных методов – это классификация изображений, когда спутниковые снимки делятся на категории в зависимости от типа местности или объекта. Другой метод – это измерение и анализ спектральных характеристик, когда анализируется отражательная способность различных участков поверхности Земли в разных частях электромагнитного спектра.
Современные технологии позволяют обрабатывать большие объемы данных за короткие сроки, что делает анализ изображений доступным и оперативным. Благодаря этому, специалисты могут быстро получать необходимую информацию и принимать решения на ее основе. Это особенно важно в такой области, как обнаружение чрезвычайных ситуаций. Такие технологии используют алгоритмы и машинное обучение для автоматического анализа и классификации изображений.
Отсутствие исследований в области обнаружения природных пожаров в доступных публикациях с применением алгоритмов машинного обучения, рассмотренных далее, создаёт научно-практический пробел, который необходимо восполнить для повышения эффективности систем обнаружения пожаров.
Целью данной статьи является сравнительное исследование эффективности алгоритмов логистической регрессии, случайного леса и сверточной нейронной сети в задаче классификации спутниковых изображений по признаку наличия очагов возгорания. Особое внимание уделяется влиянию отдельных спектральных каналов Landsat-8 на точность моделей.
Обзор литературы
Россия, обладая крупнейшими в мире лесными массивами, сталкивается с угрозой лесных пожаров в особенно острой форме. Ежегодно огонь уничтожает миллионы гектаров леса, нанося ущерб экосистемам, экономике и здоровью населения.
По данным Рослесхоза, в 2023 г. в России было зарегистрировано 12,8 тысячи лесных пожаров, охвативших площадь 4,6 миллиона гектаров [2]. Однако, несмотря на снижение общей площади пожаров, отдельные регионы продолжали испытывать силу стихии. Так, в Якутии возникло 823 лесных пожара на площади 1,5 миллиона гектаров, в Хабаровском крае – 821 пожар на 821,6 тысячи гектаров, а в Магаданской области – 334 пожара на 395 тысяч гектаров.
Такие масштабы лесных пожаров обусловлены сочетанием природных и антропогенных факторов. Среди природных причин выделяются аномально высокие температуры, засухи и сухие грозы.
В условиях столь масштабной угрозы особую актуальность приобретает разработка и внедрение эффективных методов раннего обнаружения и мониторинга лесных пожаров. Традиционные способы, такие как наземные наблюдения и использование авиации, часто оказываются недостаточно оперативными и охватывают ограниченные территории. В этой связи применение спутниковых данных в сочетании с методами машинного обучения представляет собой перспективное направление для автоматического обнаружения лесных пожаров, в частности в труднодоступных районах.
В данном разделе рассматривается три популярных базовых алгоритма машинного обучения – логистическая регрессия, метод случайного леса и градиентный бустинг – с точки зрения их применимости, обработки признаков и чувствительности к дисбалансу классов. В конце раздела проведен анализ сравнительных характеристик точности (accuracy, ROC-AUC, recall), вычислительная сложность и скорость обучения методов, применяемых в опубликованных исследованиях.
Логистическая регрессия
Логистическая регрессия является одним из базовых методов бинарной классификации, основанным на вероятностной модели. Она эффективна при линейной разделимости классов и обеспечивает интерпретируемость результатов.
Однако в задачах классификации спутниковых изображений, где данные часто имеют высокую размерность и сложные взаимосвязи, логистическая регрессия может демонстрировать ограниченную производительность.
Данный метод активно используется в целях предсказания пожароопасности территорий. В частности, исследование [5] демонстрирует применение логистической регрессии для прогнозирования риска природных пожаров в регионе Хазарского моря. Авторы отмечают, что модель, основанная на данном методе, достигла приемлемых результатов для метрики ROC = 87,3 %. В исследовании учитывается множество факторов – от плотности растительности и влажности почвы до расстояния до дорог и поселений. В работе [10], посвящённой лесным пожарам в Западной Греции, была реализована комплексная система оценки пожароопасности на основе климатических, географических и антропогенных факторов. Логистическая регрессия продемонстрировала высокую чувствительность при определении пожароопасных участков и использовалась как базовая модель в сравнительном анализе.
Также метод логистической регрессии является одним из основных в поиске и определении границ выгоревших территорий. В работе [4] модель использовалась для оценки принадлежности пикселей к зонам выгорания по временным рядам спутниковых индексов. Результаты показали, что логистическая регрессия сохраняет высокую интерпретируемость и стабильность при работе с ограниченными данными. В классическом исследовании [8], выполненном на снимках Landsat, логистическая регрессия была использована для классификации выгоревших участков, продемонстрировав уверенные результаты при анализе изменений в спектральных характеристиках.
Таким образом, данный подход подтверждает свою применимость как в задачах прогнозирования, так и в ретроспективной оценке последствий лесных пожаров. Однако применение данного метода с целью определения признаков пожара в реальном времени в доступных публикациях обнаружено не было, что может указывать на недостаточную разработанность данного направления. Это свидетельствует о существующем научно-практическом пробеле, связанном с адаптацией традиционных алгоритмов машинного обучения к задачам онлайн-обработки спутниковых данных.
Случайный лес
Это алгоритм машинного обучения, который используется для решения задач классификации и регрессии. Он основан на объединении множества деревьев решений для улучшения точности и устойчивости модели.
Он создаёт множество решающих деревьев и использует их для предсказания классов объектов. Каждое дерево строится на случайном подмножестве обучающих данных и случайном подмножестве признаков. В результате каждое дерево в ансамбле получается немного разным, что позволяет уменьшить эффект переобучения и повысить качество предсказаний.
Алгоритм случайного леса, основанный на ансамбле деревьев решений, продемонстрировал высокую эффективность в задачах классификации лесных пожаров. В исследовании, проведённом в Пакистане [4], модель Random Forest достигла точности 87,5 % и ROC 93,4 % при классификации лесных пожаров. В другом исследовании, проведённом в Северо-Восточной Индии, модель Random Forest достигла ROC 87 % при идентификации зон, подверженных лесным пожарам [7].
В статье «Исследование по обнаружению дыма от лесных пожаров на основе алгоритма случайного леса и метода субпиксельного картирования» [9] целью метода было определить пространственное распределение дыма на снимках спутника Himawari-8 с разрешением 2 км. Метрика accuracy модели случайного леса, обученной и проверенной на двух изображениях лесных пожаров, составила 83,52 и 84,68 %. Однако дым имеет разную концентрацию в различных пространственных масштабах, что приводит к разным значениям коэффициента отражения пикселей. На картах результатов классификации пиксели внутри дыма классифицированы правильно, но пиксели на границе дыма часто классифицируются неправильно из-за ограничений масштаба пикселей.
В своей работе автор рассматривает дым и облака как два вида независимых конечных элементов. Благодаря такому разделению удалось установить некоторые зависимости коэффициентов отражения от рассматриваемого канала изображения спутника Himawari-8. В диапазоне видимого света и в ближнем инфракрасном диапазоне 4 (0,86 микрометров) средние значения коэффициента отражения дыма ниже, чем у облаков. Кроме того, средние значения коэффициента отражения облаков являются самыми высокими среди четырёх наземных объектов: облака, дым, растения, голые земли. Для растительности и голых земель эти значения меньше, чем у дыма. В ближнем инфракрасном диапазоне 5 средние значения коэффициента отражения голых земель выше, чем у дыма. Средние значения коэффициента отражения дыма в ближнем инфракрасном диапазоне 6 являются самыми низкими среди четырёх наземных объектов.
В другом исследовании авторов Bao Zhou, Sha Gao и других [7] взяты за основу данные изображений спутника Sentinel-2. Количество изображений в целом составило 4500, которые охватили область исследования, включающую некоторые регионы Китая. Сравнение модели случайного леса проводилось с методами, не относящимися к алгоритмам машинного обучения. Для алгоритма случайного леса авторы исследования провели оценку важности признаков, в результате чего наиболее значимыми оказались два коротковолновых инфракрасных канала и один ближний инфракрасный канал спутника Sentinel-2.
Среди пяти методов обнаружения Random Forest показал наивысшую метрику accuracy = 86 %. Ближайший преследователь выдал значение accuracy = 75 %, что указывает на эффективность алгоритмов машинного обучения и в частности модели случайный лес.
Градиентный бустинг
Градиентный бустинг – это ансамблевый метод машинного обучения, который строит предсказательную модель в виде последовательности слабых моделей, каждая из которых корректирует ошибки предыдущих.
В исследовании, проведенном на данных спутника MODIS с охватом территорий Пиренейского полуострова, использован метод градиентного бустинга с деревьями принятия решений с целью определения выгоревших участков земной поверхности. Результаты метода сравниваются с алгоритмом логистической регрессии, обученным на том же наборе данных. Задача перед авторами статьи заключается в бинарной классификации спутниковых снимков. При сравнении алгоритмов модель логистической регрессии превзошла бустинг по метрике accuracy. Алгоритм XGBoost чаще ошибался, но реже пропускал изображения с выгоревшими участками. По итогу работы авторы делают вывод в неоднозначности использования модели градиентного бустинга в задачах обнаружения территорий, пострадавших от пожара, так как точность моделей, рассмотренных в данной работе, оказалась примерно схожей, а время, затраченное на обучение моделей, отличается в сотни раз [4].
В другой работе, проведённой в Марокко, гибридная модель Frequency Ratio-XGBoost достигла ROC 0,989 при прогнозировании подверженности лесных участков пожарам [6].
Подготовка изображений со спутника
В данной работе сбор данных, а именно спутниковых снимков, производился вручную. К сожалению, в открытых источниках не нашлось набора, удовлетворяющего задаче данного исследования.
Выбор спутника был осуществлен исходя из таких параметров, как зона покрытия Российской Федерации, относительно высокая разрешающая способность, доступность в получении данных.
Исходя из вышеперечисленных требований, было решено использовать снимки спутника Landsat 8. Спутник был разработан в сотрудничестве Национального управления по аэронавтике и исследованию космического пространства (НАСА) и Геологической службы США и запущен на орбиту в 2013 г.
Landsat-8 получает изображения в видимом диапазоне волн, в ближнем инфракрасном и в дальнем инфракрасном, с разрешением снимков от 15 до 100 метров на точку, более подробно можно посмотреть в табл. 1. Производится съемка суши и полярных регионов. В сутки
Таблица 1. Спектральные диапазоны спутника Landsat 8
Table 1. Spectral ranges of the Landsat 8 satellite
Сенсор OLI (Operational Land Imager, в переводе Оперативный Наземный Тепловизор) получает изображения в 9 диапазонах видимого света и ближнего ИК, TIRS (Thermal InfraRed Sensor, в переводе Тепловой Инфракрасный Датчик) – в 2 диапазонах дальнего (теплового) ИК (табл. 1).
Размер изображения Landsat 8 составляет 185 км в поперечном направлении на 180 км вдоль трассы. Разрешение одного снимка составляет 7771х7871 пиксель.
Было решено использовать метод классификации изображений на 2 группы: изображения без пожара, с наличием пожара. Так как все исходные снимки имели очаги пожаров, было принято решение классифицировать каждую часть изображения визуально в программе Qgis. Разметка проводилась с использованием второго, третьего и четвертого каналов спутника Landsat 8 с построением цветного изображения, а также отдельно седьмого канала, на котором отчетливо видна тепловая интенсивность.
Практическая реализация алгоритмов
Обучение моделей производилось на языке программирования python версии 3.10 с применением инструментов, рассмотренных далее.
Логистическая регрессия
В целях исследования влияния различных каналов спутникового снимка на предсказательную способность алгоритма был проведен ряд обучений логистической регрессии на каждом канале по отдельности, на комбинации из двух, а также из трех каналов.
Для оценки точности полученных алгоритмов предпочтение было отдано метрике ROC-AUC (ROC – receiver operating characteristic, AUC – area under the curve). Это всеохватывающая метрика качества классификации. Она была выбрана как основная из-за меньшего влияния дисбаланса классов.
Наивысшая метрика ROC для одного канала получена на шестом ближнем инфракрасном и составила 0,7775, матрица ошибок модели представлена на рис. 1. Метрики моделей, обученных на спектральных каналах ближнего инфракрасного диапазона, а именно пятого, шестого и седьмого каналов, находятся выше порога в 0,7. ROC моделей на остальных спектральных каналах значительно ниже. Для комбинации из двух каналов модель логистической регрессии на шестом и седьмом ближних инфракрасных каналах показала точность ROC метрики со значением 0,8336, матрица ошибок модели представлена на рис. 2. Модели, обученные на комбинациях из трех каналов, подверглись переобучению.
Важным аспектом задачи данной работы по определению природного пожара является избегание ошибочного предсказания класса с наличием пожара, так как данная ошибка и несвоевременное реагирование служб борьбы с природными стихиями может существенно сказаться на природном ландшафте и подвергнуть риску жизни людей.
Исходя из выше указанного условия, в матрице ошибок стоит обращать внимание на ошибки второго рода, то есть на значения, которым модель присвоила класс 0, а на самом деле достоверным является класс 1. С данной точки зрения обученная на комбинации 6 и 7 каналов изо- – 132 –
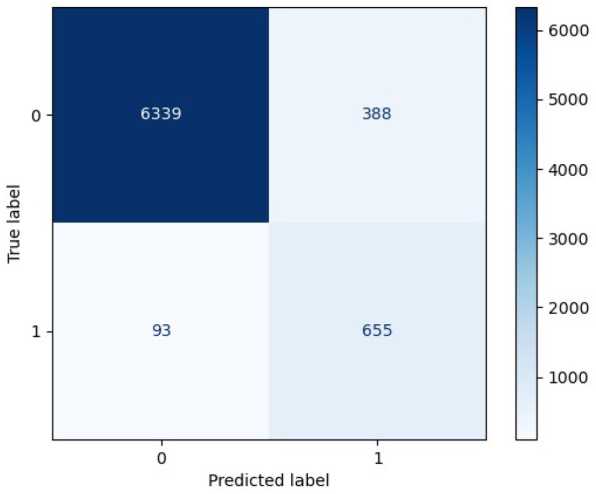
Рис. 1. Матрица ошибок модели, обученной на шестом спектральном канале изображений. Логистическая регрессия. Класс 0 – изображение без очагов пожара, класс 1 – изображение с пожаром
Fig. 1. Confusion matrix of the model trained on the sixth spectral channel of images. Logistic regression. Class 0 – image without fire sources, class 1 – image with fire
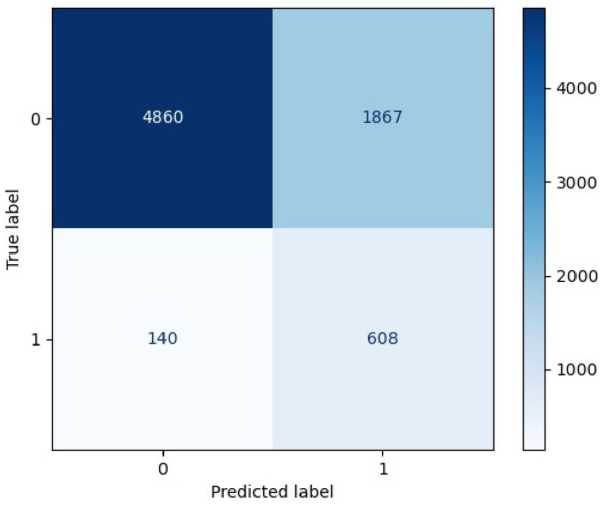
Рис. 2. Матрица ошибок модели, обученной на комбинации шестого и седьмого спектральных каналов изображения. Логистическая регрессия. Класс 0 – изображение без очагов пожара, класс 1 – изображение с пожаром
Fig. 2. Confusion matrix of the model trained on a combination of the sixth and seventh spectral channels of the image. Logistic regression. Class 0 – image without fire sources, class 1 – image with fire бражений модель значительно превосходит модели, обученные на одном из каналов. Большое количество объектов с неверно предсказанным классом 0 говорит о высокой силе, с которой модель балансирует классы на обучении. Комбинация двух каналов повышает эффективность работы модели, количество ошибок второго рода сокращается примерно на 100 объектов, что делает ее более оптимальной для решения данной задачи.
Далее был проведен ряд проверок на тестовых изображениях с различными характеристиками и классами. По результатам рассмотренные ранее модели логистической регрессии успешно справились с определением класса изображений с пожаром, однако наличие населенных пунктов для такого класса является серьезной проблемой. В исходном наборе данных имеется много примеров с высоким инфракрасным излучением от тепловых станций, бань, зданий промышленности и металлических крыш большой площади. Примеров с пожарами возле населенных пунктов почти не наблюдалось, вследствие чего обученная модель логистической регрессии вне зависимости от спутникового канала плохо уловила закономерность и выдала очень низкую вероятность пожара на снимке.
Случайный лес
Для сравнения с уже рассмотренным алгоритмом был взят ансамблевый алгоритм случайный лес. У моделей, основанных на данном алгоритме, не возникло эффекта переобучения даже на комбинации всех спектральных каналов изображений, метрика ROC составила 0,8572. Однако модель на комбинации 2–7 каналов показала большую точность, ROC = 0,8603. Параметры моделей: 200 деревьев принятия решений, стандартная балансировка весов классов. Для первой модели максимальная глубина дерева решений 15, минимальное число изображений в листе 2, минимальное число изображений в узле 5. Для второй – максимальная глубина дерева решений 20, минимальное число изображений в листе 5, минимальное число изображений в узле 2.
Матрицы ошибок для моделей, обученных на всех семи, а также шести спектральных каналах, не включающих канал аэрозолей, представлены на рис. 3 и 4 соответственно.
На матрицах ошибок (рис. 3 и 4) можно заметить, насколько неэффективно модели предсказывают класс 1 изображений с пожаром. Две трети таких изображений ошибочно отнесены к классу 0 без пожара, такой результат предсказания не приемлем для задачи обнаружения очагов огня для оперативного тушения. Модель случайного леса, обученная на всех спектральных каналах, дает более точный прогноз по первому классу, но и больше ошибочных предсказаний для нулевого класса. Стандартные методы балансировки классов не подходят в случае с алгоритмом случайный лес.
По итогу проверки на тестовых изображениях модели не увидели очагов пожара ни на одном изображении. Обучение на всех доступных спектральных каналах изображений не спасло ситуацию, те же методы борьбы с несбалансированным набором классов, что и для алгоритма логистической регрессии, оказывают меньший эффект. В связи с полученными результатами нецелесообразно дальнейшее рассмотрение метода случайный лес в качестве средства достижения поставленной задачи.
Сверточная нейронная сеть
Альтернативой классическим методам машинного обучения выступают нейронные сети. За счет возможности обучать модель с использованием графического процессора сроки обучения значительно снижаются, что позволяет использовать более сложные архитектуры алгоритмов и повысить предсказательную способность модели.
Сверточные нейронные сети разработаны для обработки изображений. Они эффективно усваивают грани, текстуры и формы, поэтому и был выбран данный тип нейронной сети.
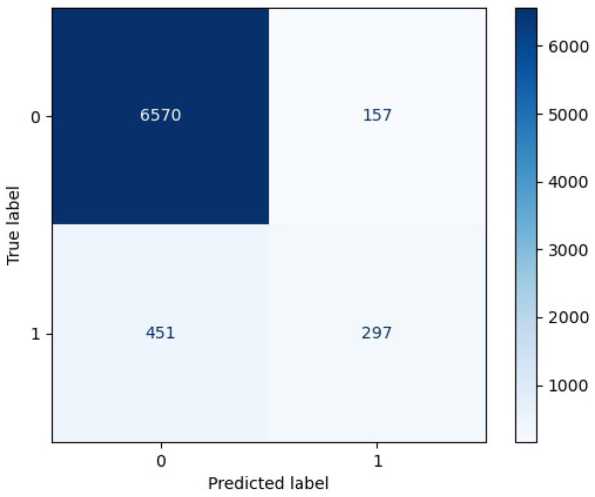
Рис. 3. Матрица ошибок модели, обученной на комбинации семи спектральных каналов изображения. Случайный лес. Класс 0 – изображение без очагов пожара, класс 1 – изображение с пожаром
Fig. 3. Confusion matrix of the model trained on a combination of seven spectral channels of the image. Random forest. Class 0 – image without fire, class 1 – image with fire
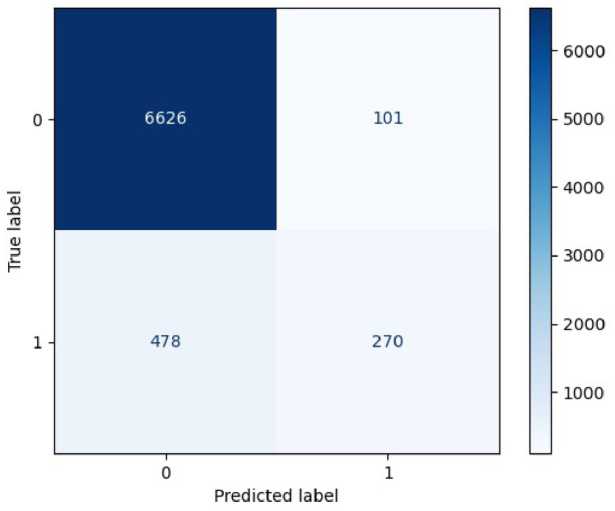
Рис. 4. Матрица ошибок модели, обученной на комбинации шести спектральных каналов изображения, не включающих первый канал. Случайный лес. Класс 0 – изображение без очагов пожара, класс 1 – изображение с пожаром
Fig. 4. Confusion matrix of the model trained on a combination of six spectral channels of the image, not including the first channel. Random forest. Class 0 – image without fire sources, class 1 – image with fire
В качестве функции активации используется ReLU (Rectified Linear Unit, выпрямительная линейная функция). Ее целью выступает задание нелинейности нейронной сети для более эффективного решения сложных задач. Данная функция лишена проблем с «затухающим градиентом». Данный термин описывает замедление процесса обучения модели из-за малых изменений весов признаков в результате прохождения через множество слоев сети.
Функция MaxPooling уменьшает размер признакового пространства, то есть оставляет более важные признаки. Данное решение помогает снизить вычислительную нагрузку.
Для оценки работы модели в процессе обучения была использована функция потерь под названием BCEWithLogitsLoss, она объединяет в себе бинарную кросс-энтропию и сигмоиду. Данная функция снижает ошибки при округлении значений и более устойчива к значениям, лежащим на границах числового диапазона. Параметр вес положительного класса (positive class weight) функции потерь позволил уравновесить перекошенность в классах изображений, тем самым увеличив значимость снимков с пожаром.
Поиск минимума функции потерь, упомянутой выше, осуществлялся оптимизатором Adam (Adaptive Moment Estimation, Адаптивная оценка моментов). Данный метод сводит функцию к локальному минимуму быстрее всех популярных оптимизаторов.
Полученное значение метрики ROC значительно превосходит точность рассмотренных ранее алгоритмов и составляет 0,97. Максимально возможная эффективность предсказаний обоих классов достигается за счет подбора порога предсказания, равного 0,67. Матрица ошибок модели с шагом обучения 0,0001 и dropout = 0,2 представлена на рис. 5.
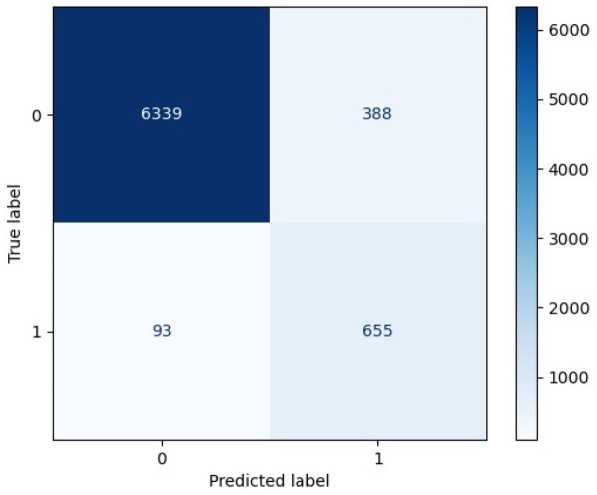
Рис. 5. Матрица ошибок модели трехслойной сверточной нейронной сети
Fig. 5. Confusion matrix of the three-layer convolutional neural network model
Финальная модель была протестирована на тестовых изображениях, для визуализации наиболее значимых областей был применен метод Grad-CAM (Gradient-weighted Class Activation Mapping). Он позволяет отобразить области изображения, на которые фокусируется модель, чтобы распознать определенный класс.
В результате проведенной проверки модель относительно точно определяет класс изображений с пожаром, однако облачность и туманы затрудняют работу и снижают эффективность предсказательной способности. Населенные пункты также сбивают модель с верного предсказания за счет вырабатываемого тепла от производств и обогрева жилищ традиционными методами.
Выводы
В исследовании было рассмотрено три алгоритма машинного обучения: логистическая регрессия, случайный лес и сверточная нейронная сеть. Первые два алгоритма работают с вектором входных чисел, последний – с двумерным пространством.
Результаты точности моделей были ожидаемы, за счет работы с двумерными массивами сверточная нейронная сеть с тремя слоями в кратчайшие сроки обучилась на исходном наборе изображений и показала отличную точность.
Остальные модели хуже справились с дисбалансом классов в наборе изображений. Для алгоритма случайный лес данная особенность является критичной, поэтому модель, обученная на этом алгоритме, в подавляющем большинстве случаев относит изображения к наиболее представленному классу без пожара.
Благодаря моделям логистической регрессии был установлен факт наибольшей значимости спектральных каналов изображения ближнего инфракрасного излучения. Наиболее тяжелым в обучении по времени и обработке данных оказался именно алгоритм логистической регрессии.
