Многоагентная организация системы обработки входящих писем с использованием метаграфовой модели

Автор: Дурова М.А., Зейн А.Н.
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 3, 2025 года.
Бесплатный доступ
В работе предложена гибридная интеллектуальная информационная система для классификации писем, основанная на метаграфовой модели знаний и холонической многоагентной архитектуре. Система сочетает статистические, лексико-семантические и глубокие семантические методы в единой структуре, что позволяет обеспечить как высокую точность, так и прозрачность решений. Предложен механизм самоорганизации на основе обратной связи от пользователя. Эксперименты на реальном корпусе университетских писем показали, что гибридный подход позволяет повысить точность классификации на 4…5 % по сравнению с однометодными системами. Результаты демонстрируют перспективность использования метаграфов для построения адаптивных и объяснимых информационных систем.
Гибридная интеллектуальная система, метаграф, многоагентная система, BM25F, MinHash, LSH, SBERT, фактографический анализ текста
Короткий адрес: https://sciup.org/148331946
IDR: 148331946 | УДК: 004.89 | DOI: 10.18137/RNU.V9187.25.03.P.72
Multi-agent organization of an incoming mail processing system using a metagraph model
The article proposes a hybrid intelligent information system for letter classification based on a metagraphic knowledge model and a holonic multi-agent architecture. The system combines statistical, lexico-semantic and deep semantic methods in a single structure, which allows for both high accuracy and transparency of solutions. A mechanism of self-organization based on user feedback is proposed. Experiments on a real corpus of university letters have shown that the hybrid approach can improve classification accuracy by 4–5 % compared to single-method systems. The results demonstrate the promise of using metagraphs to build adaptive and explicable information systems.
Текст научной статьи Многоагентная организация системы обработки входящих писем с использованием метаграфовой модели
Одной из актуальных задач автоматизации информационных систем в наши дни является обработка входящих писем электронной почты. Чаще всего требуется определение писем, относящихся к категории спама, однако в корпоративной среде возникает также потребность в дополнительной категоризации входящих писем. Эти категории зависят от специфики области. Например, для университетской среды необходимо разделять письма от студентов и от преподавателей, так как это определяет приоритет ответов. Однако традиционные методы классификации, как правило, не обеспечивают объяснимость при решении этой задачи, а также не позволяют пользователю задавать собственные правила обработки. Одним из способов устранения этого недостатка является разработка системы поддержки принятия решений, способной к дообучению и масштабируемости.
Цель настоящего исследования – изучение применимости к разработке такой системы холонического принципа организации агентов, а также метаграфовой модели знаний.
Объект исследования – процесс обработки и категоризации входящих электронных писем сотрудников и преподавателей университета.
Предмет исследования – гибридная интеллектуальная система, сочетающая NLP-обработку текста, поиск похожих документов через MinHash + LSH, точное ранжирование с помощью BM25F, семантическую коррекцию через SBERT, интерфейс сбора обратной связи и экспертные правила. Все эти компоненты объединены в холоническую структуру, где контейнерный агент управляет их работой и может менять порядок, веса и добавлять новые правила.
Постановка задачи
Предполагается, что применение гибридной системы, сочетающей несколько методов обработки естественного языка, позволит повысить точность и объяснимость классификации по сравнению с одноагентными решениями. С целью доказательства этой гипотезы были сформулированы следующие задачи:
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 3
-
1) исследовать возможность применения гибридного подхода к задачам анализа и классификации текстовых сообщений;
-
2) формализовать знания через метаграфовый подход;
-
3) реализовать систему, основанную на комбинированном использовании нескольких моделей машинного обучения и экспертных правил;
-
4) реализовать механизм самоорганизации системы на основе обратной связи;
-
5) протестировать эффективность на реальных данных.
Состояние вопроса по рассматриваемой проблеме
Гибридные интеллектуальные информационные системы. В области реализации современных интеллектуальных систем как интегрированных / гибридных систем распределенного искусственного интеллекта (далее – ИИ) применены и развиты идеи, выдвинутые Д.А. Поспеловым. Проблематике создания таких систем посвящены, в частности, ежегодные Всероссийские Поспеловские конференции с международным участием «Гибридные и синергетические интеллектуальные системы», проводимые в Калининградской области под председательством профессора БФУ имени И. Канта А.В. Колесникова [1]. Серьезный вклад в проработку теории разработки ГИС внесли А.В. Колесников [2], Н.Г. Яруш-кина [3]. Как было сформулировано В.М. Черненьким и Ю.Е. Гапанюком, гибридные интеллектуальные информационные системы (далее – ГИИС) – это комбинированная система, где «интеллектуальные системы… встраиваются в виде модулей в традиционные информационные системы для решения задач, связанных с интеллектуальной обработкой данных и знаний» [4–6]. В работе [7] формулируется важное свойство ГИИС: в отличие от ансамблей методов машинного обучения, где несколько моделей участвуют в решении одной и той же задачи, например, повышая точность за счёт голосования или взвешивания, гибридная система строится на принципе разделения функций между её компонентами. Каждый модуль ГИИС решает свою подзадачу: предобработку текста, поиск похожих документов, семантическую коррекцию, точное ранжирование или интерфейс взаимодействия. Такая организация позволяет заменять или дообучать только те модули, которые связаны с изменённой предметной областью, оставляя остальные без изменений.
В рамках такого подхода возникает вопрос формального описания знаний, так как от способа хранения и организации информации зависит эффективность работы всей системы. В традиционных ИИ-системах знания могут быть представлены в виде правил, онтологий или графов, однако такие подходы зачастую ограничены либо уровнем абстракции, либо сложностью описания динамических изменений. Для преодоления этих ограничений может использоваться метаграфовый подход.
Метаграфовый подход к моделированию знаний. Метаграф как новый подход к представлению данных и знаний был предложен А. Базу и Р. Блэннингом еще в работе [8], однако Э.Н. Самохвалов, Г.И. Ревунков и Ю.Е. Гапанюк в своей работе [9] ввели новое определение. Оно достаточно близко к определению Базу и Блэннинга, но адаптировано для описания семантики и прагматики информационной системы. В частности, они дополнили концепт метаграфа понятием метаребра, отсутствующим в раннем определении, но необходимым для применения смысловых связей между элементами в контексте, а также при вызове действий, процессов и реакций. На сегодняшний день теория метаграфа как способа формализации данных и знаний в интеллектуальных системах продолжает развиваться.
Многоагентная организация системы обработки входящих писем с использованием метаграфовой модели
Холонический принцип организации агентов. Как только модель знаний становится не просто статической, а взаимодействует с внешней средой, возникает потребность в иерархической и автономной организации её обработки.
Для этого при разработке может быть использован холонический принцип, предполагающий, что система строится из автономных, но взаимодействующих частей, каждая из которых может быть частью более крупной системы. Это идеальный подход для построения гибридной системы. Как указал в своей работе В.Б. Тарасов [10], холон – это целое, которое одновременно является частью более крупной системы. На сегодняшний день этот подход продолжает активно использоваться при построении интеллектуальных систем и систем поддержки принятия решений [11–17].
Метод решения и допущения
При постановке задачи были приняты следующие допущения:
-
• письма содержат достаточно информации для классификации;
-
• можно использовать гибридную модель, где каждая часть отвечает за свой уровень знаний;
-
• обратная связь от пользователя ограничена, поэтому важна самоорганизация;
-
• система не требует полного обучения, а работает на основе поиска похожих документов.
Формализация знаний через метаграфовый подход. Датасетом для обучения системы является набор входящих писем из корпоративной (университетской) почты, предварительно размеченных на семь категорий: «Внешнее: научная и публикационная деятельность», «Письмо по организации учебного процесса», «Письмо от студента», «Приглашение на мероприятие/курсы/etc», «Письмо по делам кафедры/университета», «Личная почта», «Внешнее: спам».
При стартовом запуске системы происходит формирование знаний согласно метагра-фовому подходу:
-
• вершины: термины из писем (например: барс , внести , оценки );
-
• рёбра: шинглы (например: барс выставить , выставить оценки );
-
• метавершины: категории писем (например: письмо от студента , внешнее: научная и публикационная деятельность ).
После первой итерации обучения системы метаграф пополняется метарёбрами , содержащими правила и веса, определяющие, какие шинглы с какой степенью уверенности влияют на выбор категории. Кроме того, при сравнении эффективности различных подходов к классификации метаребра использовались для фиксации каждого из методов относительно результата.
Использованные методы машинного обучения
Мера Жаккара
Для каждого документа строится множество всех его биграммных шинглов. Для двух документов A и B рассчитывается мера Жаккара между их множествами шинглов:
-
1S (A )^ S (BI sh( , ) IS(A)oS(B)l,
где S ( A ) - множество шинглов документа A ; S ( B ) - множество шинглов документа В. В качестве документа В выступает новое (классифицируемое) письмо. Число операций
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 3
растет квадратично от числа документов. Кроме того, полное сравнение всех пар неэффективно: время вычисления меры Жаккара для одной пары
Tpair = O ( k 2 ) , где k = max (l Sq I, I Sd l), для всех пар Tall - pairs = O (D2 k2), где D = число документов. Для решения этой проблемы существуют расширения меры Жаккара.
Алгоритм MinHash
В частности, алгоритм MinHash позволяет строить сигнатуры (хэши) для приближённой оценки меры Жаккара между множествами. Вероятность совпадения минимального значения хэша для двух множеств равна их мере Жаккара
P ( MinHash i ( A ) = MinHash i ( B ) ) = J ( A , B ) .
Эту меру уже можно использовать для оценки сходства, однако тестирование показало, что этот метод плохо поддается масштабированию.
Алгоритм LSH
Для использования в растущем корпусе документов на основе сигнатур можно сгруппировать документы в «близкие» с помощью LSH (Locality-Sensitive Hashing):
P(h (A) = h (B))« J(A, B), где A, B - два документа в виде множества шинглов; h (A), h (B) - значения хэшей для A и B; (h (A) = h (B)) - вероятность того, что документы попадут в одну ячейку (бакет).
Сложность вычислений по этому принципу составляет O ( D + log D ).
Косинусное сходство
Одним из способов количественной оценки сходства между двумя документами d 1 и d 2 является вычисление косинусного сходства их векторных представлений V ( d 1 ) и V ( d 2 ) :
sim ( d 1 , d 2 )
V (di) V (d 2)
|V ( d 1 )| | V ( d 2 )|
где числитель представляет собой скалярное произведение векторов V ? ( d 1 )
и
V ( d 2 ) ,
а знаменатель – произведение их евклидовых длин. Этот подход компенсирует влияние
длины документа.
Алгоритм TF-IDF
Другим подходом к оценке сходства документов является TF-IDF (Term Frequency – Inverse Document Frequency), работающий на преобразовании текстовых документов в числовые векторы. Этот метод является классическим в задачах обработки естественного языка [17], поэтому в рамках данной статьи мы не будем раскрывать подробности его применения.
Алгоритмы BM25 и BM25F
Большой интерес представляет нелинейный аналог TF-IDF – BM25 (Best Match 25). Модель представлена функцией ранжирования, которая не сохраняет полный вектор документа, а вычисляет релевантность запросу:
Многоагентная организация системы обработки входящих писем с использованием метаграфовой модели
TF ( t , d )( k + 1 )
BM 25 ( t , q , d ) = IDF ( t )--------- 1 -----V
TF ( t , d ) + k 1 1 1 - b + b l df l I ^ avgdl )
где TF( t , d ) – количество вхождений слова t в письме d ;
IDF ( t )
TF ( t , d )( k 1 + 1 )
∣ df ∣ avgdl
TF (t, d) + k 11 1 - b + b мера уникальности слова t во всей коллекции писем, использование вероятностной формулы со сглаживанием добавляет устойчивость к редким словам: если df(t) = 0, то значение логарифма не становится бесконечным; N – общее число документов в корпусе; |d| – длина письма d (число слов); avgdl – средняя длина писем в коллекции; k1 – насыщение по частоте: параметр, регулирующий влияние частоты термина (обычно 1,2 ≤ k1 ≤ 2,0); b – насыщение по длине документа: параметр нормализации длины документа (обычно b = 0,75).
В разрабатываемой системе использовалось расширение BM25 – BM25F, позволяющее учитывать в отдельности несколько полей документа и каждому из них присваивать свой вес, а также нормализовать длины по каждому полю отдельно.
SBERT
Еще одним современным способом решения задачи определения сходства текстов является предобученная модель SBERT, которая строит представления текста в виде векторов, где косинусное сходство между ними отражает семантическую близость [18]. В отличие от традиционных подходов, основанных на частоте слов или шинглах, SBERT позволяет учитывать смысл, а не только формальное совпадение терминов [19; 20]. В контексте решаемой задачи эта модель показала высокую точность, однако специфика ее применения в том, что каждое новое письмо должно встраиваться в заново создаваемое векторное пространство, так что при значительном росте количества писем время обработки становится неприемлемым для онлайн-системы. Кроме того, модель не поддерживает дообучения и совершенно не интерпретируема.
Поэтому было принято решение использовать эту модель для нейтрализации недостатка других методов – BM25F и LSH. Эти методы не учитывают контекста терминов, а потому схожие по смыслу документы могут быть не распознаны. SBERT открывает возможность семантической коррекции: при поступлении нового документа его словарь расширяется с помощью поиска синонимов по SBERT, и дальнейшая обработка происходит уже с учетом этих синонимов.
Разработка многоагентной системы с холонической организацией. Было принято решение реализовать систему как холоническую многоагентную систему (далее – МАС), где каждый агент выполняет свою функцию (см. Таблицу 1).
Такая организация позволяет менять или дообучать отдельные компоненты без полного пересчёта всей системы – это ключевое преимущество гибридного подхода (см. Рисунок).
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 3
Таблица 1
Структура разработанной МАС
|
Агент |
Зона ответственности |
Вход |
Выход |
|
AgNLP |
Предобработка текста |
Неочищенный текст |
Токены, шинглы |
|
AgSrch |
Быстрый поиск похожих писем |
Шинглы |
top-K документов |
|
AgML |
Точное ранжирование через BM25F |
top-K документов |
Ранги документов |
|
AgSem |
Семантическая коррекция |
Эмбеддинги SBERT |
Расширенные шинглы |
|
AgUI |
Интерфейс сбора обратной связи |
Новое письмо |
Категория, пользовательский выбор |
|
AgAdapt |
Организация взаимодействия остальных агентов |
– |
– |
Источник: таблица составлена авторами.
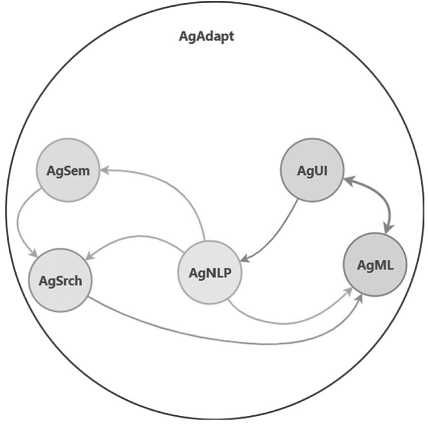
Рисунок. Взаимодействие агентов МАС Источник: рисунок выполнен авторами.
Реализация самоорганизации через контейнерный агент
Для полноценной самоорганизации была реализована логика контейнерного агента. В рамках метаграфового подхода к моделированию гибридных интеллектуальных информационных систем контейнерный агент определяется как структура, содержащая:
-
• метаграф данных и знаний (MGdata);
-
• множество правил (R);
-
• config – параметры, определяющие поведение и последовательность работы агентов;
-
• другие агенты в виде списка (Gagents).
Таким образом, контейнерный агент может быть формально представлен следующим образом:
AgAdapt = (MGdata, R , config, G agents).
Многоагентная организация системы обработки входящих писем с использованием метаграфовой модели
При получении сигнала о необходимости адаптации, например, на основе ошибок классификации
-
• агент анализирует статистику и обратную связь;
-
• находит новые паттерны;
-
• обновляет R;
-
• может создать новую метавершину (например, определить специфичную для предметной области синонимичность двух терминов);
-
• может изменить порядок выполнения агентов, в том числе и исключить выполнение одного из агентов.
Такой подход позволяет считать контейнерный агент центральным элементом организации системы, где он не просто хранит других агентов, но и управляет их поведением.
Результаты
Для тестирования была собрана выборка из 500+ писем сотрудников и студентов МЭИ. Данные были размечены вручную и сохранены в xlsx-файл. После этого была проведена серия экспериментов, целью которых являлось сравнение качества классификации моделей в различной комбинации друг с другом (см. Таблицу 2).
Таблица 2
Результаты тестирования возможных конфигураций системы
|
Метод |
Precision |
Recall |
F1-score |
Время на запрос, мс |
Качество |
|
TF-IDF |
0,68 |
0,72 |
0,70 |
350 |
Базовое представление |
|
BM25F |
0,74 |
0,71 |
0,72 |
380 |
Учтены поля письма |
|
Jaccard + шинглы |
0,62 |
0,65 |
0,63 |
120 |
Быстро, но не точно |
|
CosSim + SBERT |
0,82 |
0,69 |
0,75 |
1200 |
Высокая точность, но требует GPU |
|
BM25F + Jaccard |
0,76 |
0,73 |
0,74 |
390 |
Позволяет комбинировать статистику и структуру |
|
MinHash+LSH + BM25F |
0,84 |
0,71 |
0,77 |
150 |
Баланс скорости и точности |
|
MinHash+LSH + SBERT |
0,92 |
0,88 |
0,90 |
1100 |
Высокая точность, но замедляет работу |
|
MinHash+LSH + BM25F + SBERT |
0,95 |
0,93 |
0,94 |
160 |
Наилучшая модель |
Необходимо отметить, что тестирование качества классификации разных моделей является также и проверкой функционирования AgAdapt, так как с помощью контейнерного агента изменение конфигурации системы не требует внесения изменений в код, а только ее настройку.
Анализ полученных результатов
Результаты показали, что оптимальной является следующая структура системы: AgNLP проводит шинглирование терминов корпуса документов при обучении системы, формируя вершины метаграфа на первом уровне (термины) и метавершины (шинглы).
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 3
Взаимодействие этого агента с AgSem делает возможным дообучение системы, так как новые письма семантически расширяются с помощью SBERT. AgNLP также рассчитывает сигнатуры документов с помощью MinHash. AgSrch выполняет быстрый поиск с помощью LSH и формирует список из K наиболее подходящих документов. Этот список получает AgML, где BM25F уточняет релевантность документов:
c q = arg max ^ score d , c d e Bq ( c )
где B q( c ) – документы из бакета Bq, относящиеся к категории c; c q – категория с наибольшим суммарным BM25F-рангом.
Такой гибридный подход превосходит одноагентные решения по F1-score, достигнув значения 0,94, при этом сохранив высокую степень объяснимости.
Заключение
В работе предложена, исследована и реализована многоагентная система классификации текстовых сообщений, основанная на метаграфовом подходе к формализации знаний. Гибридный подход к построению архитектуры системы позволил увеличить точность классификации на 4…5 % относительно аналогичных работ, использующих единственный метод (LLM [21] и метод опорных векторов [22]). При этом следует отметить, что возможность дообучения является отличительной чертой разработанной системы и не представлена в упомянутых разработках. Благодаря использованию контейнерного агента как средства организации предложенная система способна к обучению на различных данных и имеет гибкую структуру, а значит, может быть адаптирована для других предметных областей. Это делает её не только частным решением, но и научно обоснованным подходом к обработке текстовой информации.
