Многоуровневые алгоритмы отображения параллельных МР1-программ на вычислительные кластеры

Автор: Пазников Алексей Александрович, Курносов Михаил Георгиевич, Куприянов Михаил Степанович
Журнал: Проблемы информатики @problem-info
Рубрика: Системная информатика
Статья в выпуске: 1 (26), 2015 года.
Бесплатный доступ
В работе рассматривается задача отображения параллельных MPI-программ на иерархические кластерные вычислительные системы (ВС). Требуется по заданному информационному графу программы распределить ее процессы по процессорным ядрам системы с целью минимизации накладных расходов на межмашинные обмены. Для приближенного решения за¬дачи предложены алгоритмы, основанные на эвристических методах разбиения взвешенных графов. Оптимизация достигается за счет распределения интенсивно обменивающихся ветвей параллельной программы по процессорным ядрам, связанным быстрыми каналами связи. В алгоритмах учитываются все иерархические уровни коммуникационной сети ВС. Приводятся результаты экспериментов по отображению MPI-программ из пакетов SPEC MPI и NAS Parallel Benchmarks в пространственно-распределенную мультикластерную вычислительную систему.
Отображение параллельных программ, распределенные вычисли¬тельные системы, кластерные вычислительные системы
Короткий адрес: https://sciup.org/14320268
IDR: 14320268 | УДК: 004.272
Текст научной статьи Многоуровневые алгоритмы отображения параллельных МР1-программ на вычислительные кластеры
Введение. Пространственно-распределенная вычислительная система (ВС) — это совокупность территориально рассредоточенных вычислительных подсистем (вычислительных кластеров и/или проприетарных систем с массовым параллелизмом), логически объединенных в единую систему для решения на ней параллельных задач [1]. К классу пространственно-распределенных ВС относятся мультикластерные и GRID-системы. Параллельные программы для таких ВС разрабатываются в модели передачи сообщений, как
-
1 Работа, выполнена, при поддержке РФФИ (гранты № 15-07-02693, 15-07- 00653), а. также Министерства, образования и пауки Российской Федерации в рамках договора. № 02.G25.31.0058 от 12.02.2013 г.
правило, с использованием библиотек стандарта MPI (РАСХ [2], MCMPI [3], Stampi [4], NumGRID [5]) или специализированных пакетов распределенных вычислений (Х-Сот [6], BOINC [7]).
Одной из важных проблем организации функционирования пространственно-распределенных ВС является оптимизация отображения на них параллельных программ (task mapping, task allocation, task assignment). Под оптимальным отображением понимается такое распределение ветвей параллельной программы по процессорным ядрам ВС, при котором достигается минимум накладных расходов на межмашинные обмены информацией.
Коммуникационные среды пространственно-распределенных ВС имеют иерархическую организацию. Как правило, в них можно выделить минимум три уровня: первый уровень — сеть связи между подсистемами (кластерами); второй уровень — сеть связи между вычислительными узлами отдельной подсистемы (кластера); третий уровень — общая память вычислительных узлов. Время передачи информации между процессорными ядрами существенно зависит от их размещения в системе [8].
Существующие библиотеки MPI (MPICH2, Open MPI, Intel MPI и др.) реализуют алгоритмы отображения параллельных программ с учетом только двух уровней коммуникационной сети — сети межузловых связей и общей памяти вычислительных узлов. Например, пакет hwloc [9, 10], который входит в библиотеки MPICH2 и Open MPI, использует информацию об иерархической структуре распределенных ВС и реализует отображение при помощи библиотеки Scotch [11] разбиения графов.
Часть существующих работ направлена на вложение параллельных программ в фиксированные структуры коммуникационных сред ВС. Например, в работах [12, 13, 14] предложены алгоритмы вложения программ в системы, имеющие тороидальную структуру коммуникационной среды. В работах [15] и [16] оптимизируется вложение регулярных и нерегулярных информационных графов в структуры, представленные двумерными и трехмерными решетками и торами. В статье [17] предлагается специализированный алгоритм TreeMatch вложения, ориентированный на ВС с NUMA-узлами.
Некоторые из предложенных алгоритмов [18, 19] направлены на оптимизацию вложения MPI-программ лишь определенного класса.
Отдельные работы направлены на оптимизацию вложения виртуальных MPI-топологий. В работах [20, 21] рассматривается задача вложения виртуальных MPI-топологий в SMP-кластеры. Авторами работы [22] предлагаются подходы для повышения эффективности построения виртуальных топологий стандарта MPI. В статье [23] предлагаются алгоритмы вложения виртуальных MPI-топологий на основе анализа информационного графа параллельной программы и структуры системы, однако в нем не учитываются архитектурные особенности мультикластерных систем.
В работе [24] исследуются универсальные эвристические алгоритмы вложения в гетерогенные системы, проводится сравнение производительности алгоритмов и их масштабируемости на большемасштабных системах. В качестве показателей эффективности используется средняя длина пути (в смысле теории графов), пройденная сообщением, и минимальное время передачи сообщения.
В большей части работ при оптимизации вложения учитываются только дифференцированные обмены (point-to-point). Авторами статьи [25] предлагается подход, позволяющий учитывать коллективные операции при вложении. Однако данный подход ограничен в применении, так как требует информации об алгоритмах реализации коллективных обме- нов. В статье [26] рассматривается подход к оптимизации вложения с целью оптимизации коллективных операций в тороидальной сети системы Bine Gene/P и Bine Gene/Q.
Немаловажным является то, как в целевой функции (критерий оптимизации) учитывается интенсивность взаимодействия параллельных ветвей. Время выполнения программ с большим числом информационных обменов небольшого размера (это характерно для программ на языках семейства PGAS — Partition Global Address Space) существенно зависит от накладных расходов, связанных с латентностью при передаче информационных сообщений. В алгоритмах отображения таких программ целесообразно учитывать количество обменов, а не суммарный размер сообщений. Данное обстоятельство в недостаточной степени учитывается в существующих работах.
Применение известных методов отображения MPI-программ возможно и в пространственно-распределенных ВС, однако они не обеспечивают предельной эффективности использования ресурсов ВС, так как не учитывают все иерархические уровни коммуникационной среды. В пространственно-распределенных ВС важно учитывать наличие медленных каналов связи между подсистемами. Производительность этого уровня, как правило, значительно уступает остальным и существенным образом влияет на время выполнения параллельной программы.
В данной работе предлагаются эвристические алгоритмы отображения MPI-программ в пространственно-распределенные ВС. В предложенных алгоритмах учитываются все иерархические уровни коммуникационной сети ВС.
Отображение параллельных программ на кластерные ВС. Пусть имеется пространственно-распределенная ВС, состоящая из H подсистем. Коммуникационная среда системы имеет иерархическую организацию и может быть представлена в виде дерева, содержащего L уровней.
Рассмотрим отображение параллельной программы на подсистему из N элементарных машин (ЭМ), рис. 1. Для параллельной программы системой управления ресурсами выделяется подсистема (на рис. 1 обозначена серым цветом), которая также также имеет иерархическую структуру. Введем обозначения: n l — количество элементов на уровне l Е {1,2,... ,L}: n lk — количество прямых дочериих узлов элемента, k Е {1,2,... ,nl}, находящегося на уровне l; clk — количество ЭМ, принадлежащих потомкам данного элемента.
Параллельная программа, созданная в модели передачи сообщений, может быть представлена информационным графом G = (V,E), г де V = {1,2,... ,N } — множество ветвей параллельной программы, a E С V х V — множество информационно-логических связей между ветвями. Обозначим через d ij вес ребра (i,j ) Е E, отражающий интенсивность обменов данными между ветвями i и j при выполнении программы. В этой работе рассмотрено два способа задания весов ребер: 1) d ij — суммарный объем данных, передаваемых между ветвями i и j за время выполиения программы ([dij] == байт), 2) d ij — количество переданных сообщений между ветвями i и j. Заметим, что вес d ij ребра может отражать как абсолютные, так и относительные объем или количество информационных обменов. Эти значения могут быть получены путем профилирования параллельной программы.
Отображение параллельной программы на структуру ВС задается значениями переменных x ij Е {0,1}: x ij = 1, если ветвь i Е V назначена на процессорное ядро j Е {1,2,... ,N}. в против:юм случае x ij = 0.
Для оценки эффективности отображения программы на структуру ВС можно использовать различные показатели: время выполнения программы, энергопотребление системы и др. В данной работе в качестве показателя эффективности отображения использует-
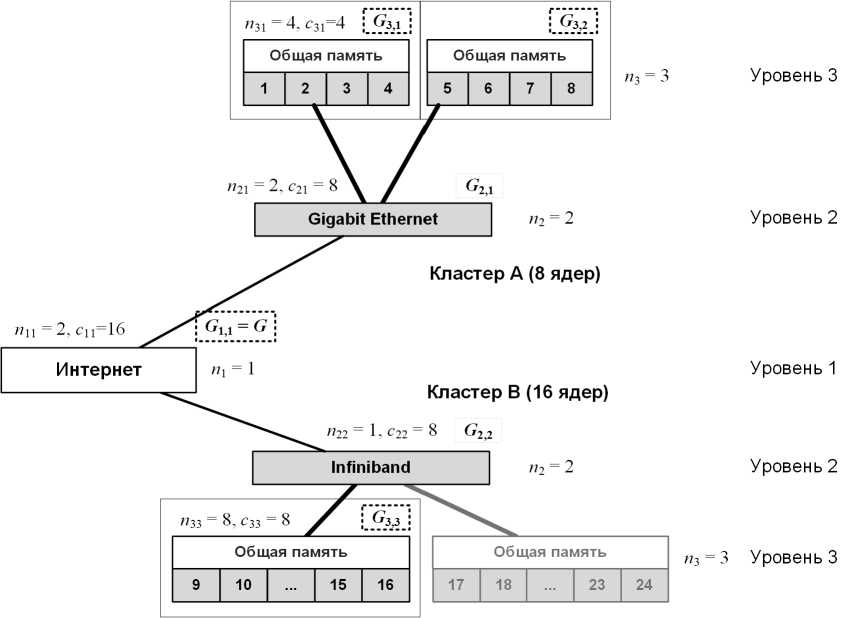
Рис. 1. Пример подсистемы ЭМ для решения параллельной задачи ранга N =16
ся время T выполнения информационных обменов. Оно определяется максимальным из времен выполнения обменов ветвями программы.
Обозначим t(i,j,p,q) — суммарное время взатюдсйствий между ветвями i,j Е V. назначенными на процессорные ядра p и q соответственно. Тогда
T (X ) = max t i = max i ∈ V i ∈ V
NNN
EEE j = 1 p =1 q =1
X ip X jq t(i,j,p,q)
Значение функции t(i,j,p,q) может быть получено согласно различным моделям дифференцированных обменов (LogP, LogGP, Hockney). Например, в случае модифицированной модели Хокни (R. Hockney) функция t принимает вид t(i,j,p,q) = d ij /b(p,q) где b(p,q ) — пропускная способность канала связи между процессорными ядрами p и q.
Сформулируем задачу оптимального отображения параллельной программы на ВС с иерархической организацией:
T (X) = max i ∈ V
NNN
X X E
X ip X jq t(i,j,p,q)
^ min
( x j )
при ограничениях
N
EXi,- = 1, i = 1,2, ...,N, j-1
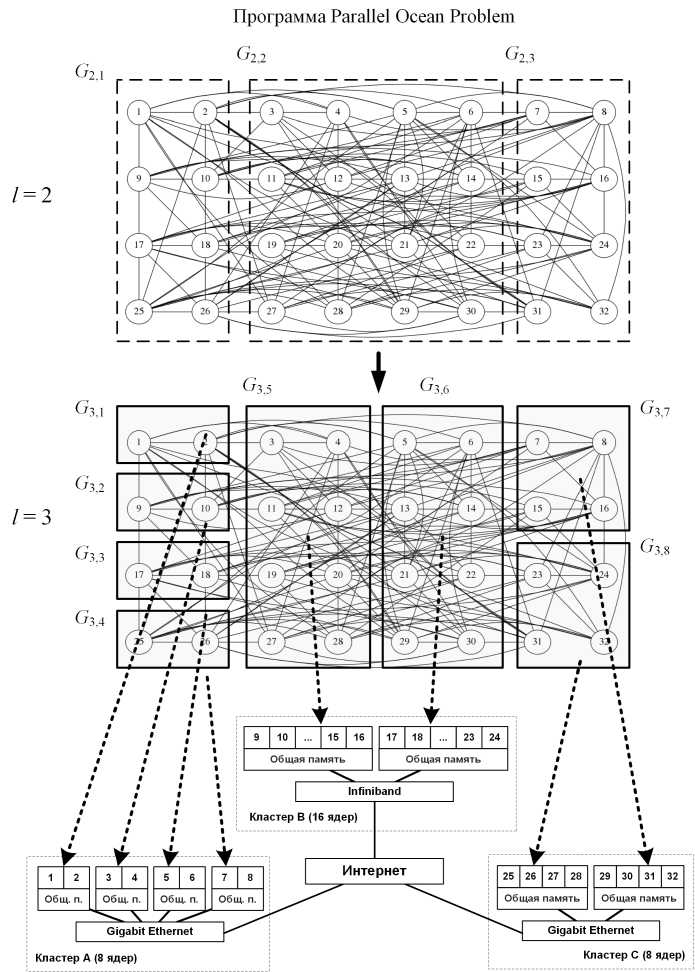
Рис. 2. Отображенеие программы Parallel Ocean Problem (POP) на подсистему из N = 32 ЭМ мегодом HierarchicTaskMap
N
МXij = 1, j = 1,2,...,N, i =1
x ij e {0,1}, i e V,j e{1,2,...,N }.
Ограничения (2), (4) гарантируют назначение каждой ветви параллельной программы на единственную ЭМ. Ограничение (3) обеспечивает назначение на машину одной ветви.
Задача (1)-(4) относится к дискретной оптимизации и является трудноразрешимой.
Рассмотрим приближенный метод ее решения.
Многоуровневые алгоритмы отображения параллельных программ на кластерные ВС. Метод основан на разбиении графа задачи на подмножества интенсивно об- менивающихся параллельных ветвей и отображении их на ЭМ, связанные быстрыми каналами связи. Цель разбиения — минимизация суммы весов ребер, инцидентных разным подмножествам разбиения. Разбиение выполняется многократно: для каждого уровня иерархии коммуникационной среды (рис. 2). Обозначим описанный метод HierarchicTaskMap. В листинге 1 приведен его псевдокод.
Листинг 1. Псевдокод метода HierachicTaskMap
HierachicTaskMap (Glk ,l,k)
Вход: G — информационный граф параллельной программы, l — уровень коммуникационной среды, k — номер текущего элемента.
Выход: x ij — отображеиие: x ij = 1. если ветвь i назначена, на ЭМ j. иначе x ij = 0.
-
1 if l < L then
-
2 (Gz +1 , 1 , Gl +1 , 2 ,. .. G l +i ,n lk ) = PARTGRAPH(Gik; n ik ; ci +i , i , ci +1 , 2 ,..., c l +i ,n lk )
-
3 for k = 1 t о n lk do
-
4 HierarchicTaskMap (Gl+1 , k, l +1, k)
-
■ 5 end for
-
6 else
-
7 return (Gl,i , Gl,2 ,..., GL,nL)
-
8 end if
Суть метода, рассмотрим на примере отображения параллельной программы на подсистему из 16 ЭМ (рис. 1). На первом шаге выполняется разбиение (PartGraph) исходного графа. G на n 11 подграфов (G21 11 G22) по c21 11 c22 вершин. Дгосе графы G 21 11 G 22 рекурсивно разбиваются на n21 и n22 част ей по c21 и c22 вершин соответственно. Полученные в результате подграфы G31, G32, G33 (их вершины — ветви программы) назначаются на узел 1 (процессорные ядра 1,... ,4) и узел 2 (процессорные ядра 5,... ,8) кластера А и узел 1 (процессорные ядра 9,... ,16) кластера В.
Функция PartGraph возвращает список подграфов, получаемых в результате разбиения исходного графа. Задача оптимального разбиения взвешенного графа на k непере-секающихся подмножеств является трудноразрешимой. Для ее решения существуют точные и приближенные алгоритмы различной вычислительной сложности. Интерес представляют многоуровневые алгоритмы разбиения графов [27, 28], позволяющие получать субоптимальные решения этой задачи и характеризующиеся невысокой вычислительной сложностью. Данные алгоритмы включают этапы сжатия графа, начального разбиения и улучшения разбиения. В основе большинства алгоритмов улучшения разбиений лежит модифицированная нетрудоемкая эвристика Кернигана-Лина (Kernighan-Lin) [29].
Вычислительная сложность метода, HierarchicTaskMap определяется количеством выполнений процедуры PartGraph. В случае, если используется многоуровневый алгоритм разбиения графа, трудоемкость ее составляет T P g = O(|E| log2 z ), где |Е| — количество ребер в графе, z — число подмножеств разбиения графа. Разбиение выполняется в пределах каждого уровня l = 1,..., L — 1 для всех его элементов k = 1,... ,n l (графы Glk\ Время работы метода приведено на рис. 3.
Выполнение многоуровневого алгоритма, при необходимости можно ограничить любым коммуникационным уровнем ВС. На основе метода, HIERARCHICMAP предложены алгоритмы, различающиеся между собой уровнями l коммуникационной среды, которые учи-
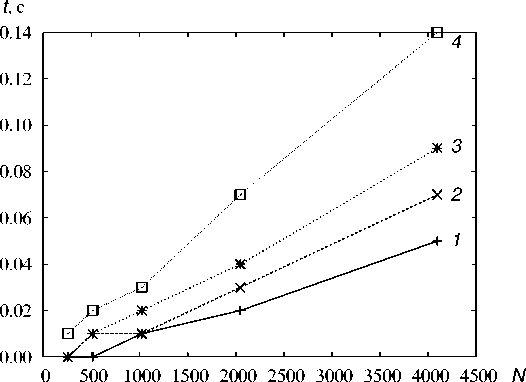
Рис.З. Зависимость времени работы алгоритма ЫМар от количества N ветвей в параллельной программе для различного числа k подмножеств разбиения (процессор Intel Xeon Е5420): 1 — k = 16, 2 - k = 32. 3 - k = 64. 4 - k = 128
тываются при формировании разбиения. Назовем ЫМАР алгоритм, учитывающий только уровень l = 1 связи между подсистемами (кластерами) и не учитывающий уровень связи между узлами, L2MAP — алгоритм, учитывающий только уровень l = 2 связи между узлами и не учитывающий уровень связи между подсистемами, L12MAP — алгоритм, учитывающий как уровень связи между узлами, так и уровень связи между подсистемами, и т. д.
Моделирование работы алгоритмов. Моделирование алгоритмов отображения проводилось на мультикластерной ВС Центра параллельных вычислительных технологий Сибирского государственного университета телекоммуникаций и информатики(ЦПВТ ФГОБУ ВПО ,,СибГУТИ“) и Лаборатории вычислительных систем Института физики полупроводников им. А. В. Ржанова СО РАН (ИФП СО РАН).
Средства запуска параллельных программ. Для запуска MPI-программ на ресурсах пространственно-распределенных подсистем реализован подход на основе межсетевого протокола IPv6 (рис. 4). В данном протоколе используется 128-битовая адресация, которая позволят выделять всем вычислительным узлам пространственно-распределенной ВС глобальные IP-адреса. Наличие уникальных адресов обеспечивает возможность установления сетевого IP-соединения между любой парой узлов системы для запуска на них MPI-программ. Получение адресов и взаимодействие между узлами подсистем осуществлялось с помощью протокола 6to4, который реализует передачу пакетов протокола IPv6 поверх сети IPv4. При этом сначала головным узлам, имеющим глобальный 1Ру4-адрес, по протоколу 6to4 выделялись 1Ру6-адреса, после чего средствами службы radvd 1Ру6-адреса от головных узлов всех подсистем раздавались вычислительным узлам.
Для запуска MPI-программ пользователь должен зайти на одну из подсистем и создать файл со списком узлов мультикластерной ВС для выполнения параллельной программы. После этого он запускает MPI-программу утилитой mpiexec (mpirun). Описанная схема запуска MPI-программ требует от библиотеки MPI поддержки протокола IPv6. В данной работе применялась библиотека Open MPI 1.4.5.
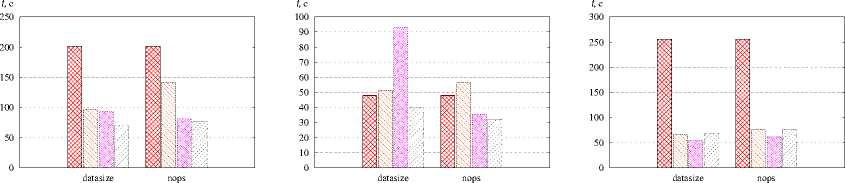
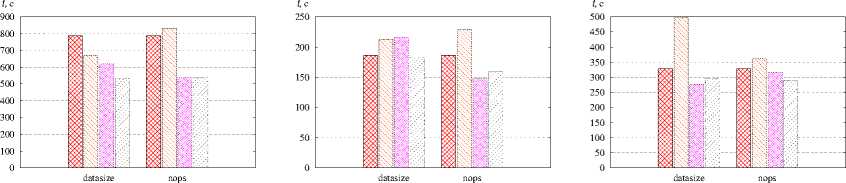
Рис. 4. Сравнение алгоритмов отображения параллельных программ, а — POP, r = 120, б — Sweep3D, r = 120. в - ХРВ MG. r = 64.
г - XPB SP. r = 64. 0 - XPB LU. r = 120. « - XPB ВТ. r = 64
!:■:■: :■:■:■:! — ЛИНбЙНОе ОТОбраЖвНИв, k\WN — L2Map, L_______ I — LlMdp, EZZZZ2 — L12Mtip
Инструментарий оптимизации отобраснсения на мулътикластерн'ые ВС. Разработанные алгоритмы реализованы в программном пакете MPIGridMap, который позволяет запускать MPI-программы на пространственно-распределенных ВС с субоптимальным распределением параллельных ветвей по элементарным машинам.
Схема использования пакета выглядит следующим образом (рис. 5). На первом шаге программа компилируется с подключенной библиотекой профилирования VampirTrace и запускается с линейным отображением (по умолчанию). Результат профилирования — протокол prog.otf выполнения программы в формате Open Trace Format (OTF). Данный протокол анализируется программой OTFParse для получения информационного графа prog, csr параллельной задачи в формате Compressed Sparse Row (CSR). Граф отражает количество (nops) или размеры (datasize) передаваемых сообщений в дифференцированных обменах (point-to-point) при выполнении МР1-программ.
Информационный граф подается вместе со списком machinefile узлов мультикластер-ной ВС на вход модуля MPIGridMap формирования отображения. При построении отображения могут быть использованы различные пакеты разбиения графов (METIS, Scotch, gpart). Результатом является файл rankfile, который содержит отображение параллельных ветвей программы на множество элементарных машин. Пользователь указывает файл rankfile при запуске MPI-программы.
Пакет MPIGridMap является свободно распространяемым. Он написан на языках С и C++ для операционной системы GNU/Linux.
Организация экспериментов. Натурные эксперименты по отображению тестовых MPI-программ проводились на действующей мультикластерной системе ЦПВТ ,,СибГУТИ“ и Лаборатории ВС ИФП СО РАН. Тестовая подсистема (рис. 6) включала в себя три вычислительных кластера:
— сегмент D: 4 узла (2 х Intel Xeon 5150, 16 процессорных ядер),
— сегмент Е: 4 узла (2 х Intel Xeon 5345, 32 процессорных ядра),
— сегмент F: 18 узлов (2 х Intel Xeon 5420, 144 процессорных ядра).
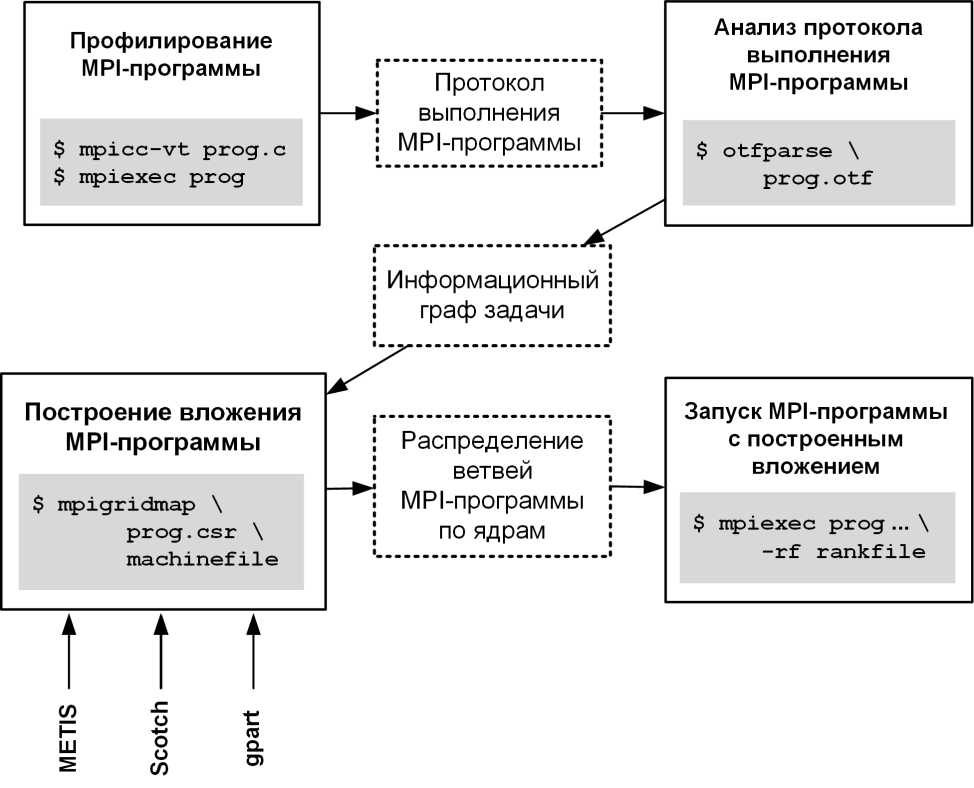
Рис. 5. Функциональная схема пакета MPIGridMap
Сеть связи между узлами — Gigabit Ethernet, сеть связи между сегментами ВС — Gigabit Ethernet.
На подсистемах установлена операционная система GNU/Linux. Использовались библиотека Open MPI 1.4.5 с поддержкой IPv6 и библиотека VampirTrace для профилирования MPI-программ.
Опираясь на известные распространенные схемы межмашинных обменов [30], были выбраны следующие тестовые MPI-программы: The Parallel Ocean Program (пакет моделирования климатических процессов в мировом океане), SWEEP3d (программа для моделирования процессов распространения нейтронов), GRAPH500 (тест производительности ВС на основе обработки неструктурированных данных графового типа) и программ LU, SP, MG, ВТ из пакета тестов производительности NAS Parallel Benchmarks.
При формировании отображений использовались библиотеки разбиения графов Scotch [31], METIS [32], и gpart. Все пакеты реализуют многоуровневые алгоритмы разбиения графов с использованием прямого метода разбиения на k непересекающихся подмножеств. Стоит заметить, что библиотека Scotch используется в пакете hwloc [9, 10] при отображении параллельных MPI-программ в пакетах MPICH2 и Open MPI.
Ранг r параллельной программы выбирался из множества {120, 64, 36, 32} в зависимости от задачи.
Для каждой программы генерировалось два информационных графа в зависимости от способа формирования весов dj ребер. В первом случае вес ребра отражал объем данных, передаваемых между ветвями i и j (datasize). Во втором графе вес ребра отражал количество информационных сообщений, передаваемых между ветвями i и j (nops).
Результаты экспериментов. На рис. 4 представлены некоторые результаты исследования алгоритмов. В процессе моделирования измерялось время выполнения параллельных
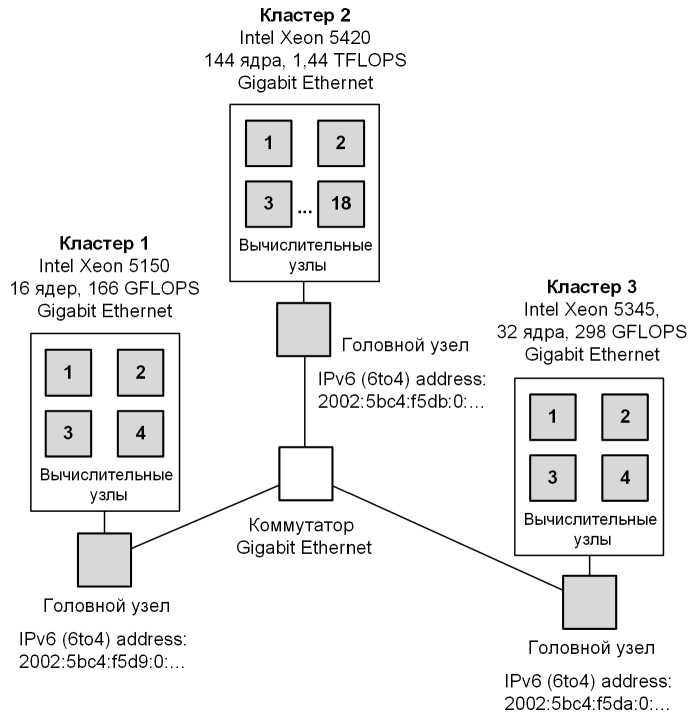
Рис. 6. Конфигурация тестовой подсистемы мультикластериой ВС программ при отображении их на мультикластерную ВС алгоритмами L2MAP, L1MAP и L12MAP. Для разбиения графов задач применялся пакет gpart. Выполнялось сравнение полученных отображений с линейным отображением, при котором ветви последовательно вкладываются в ЭМ выделенной подсистемы (такое отображение реализуется по умолчанию библиотеками MPI).
Время выполнения MPI-программ при отображении их алгоритмом L12MAP ниже по сравнению с остальными алгоритмами. Это объясняется тем, что данный алгоритм позволяет учитывать как внутрикластерную сеть связи между узлами, так и сеть связи между кластерами. Различие результатов LIMap и L2MAP обусловлено схемами межмашинных обменов в конкретных параллельных программах.
Уменьшение времени выполнения параллельных программ POP (в 2,5 раза, r = 120), Sweep3D (на. 30 %, r = 120). GRAPH50() (до 10 раз. r = 120). ХРВ МС1 (в 5 раз. r = 64). NPB SP (на 30%, r = 64), ХРВ LU (на 10%, r = 120) оптимизированного отображения по сравнению с линейным отображением обусловлено разреженностью и неоднородностью графов и преобладанием в программе дифференцированных MPI-обменов. В таких графах можно выделить подмножества параллельных ветвей, интенсивно обменивающиеся данными, и распределить их по ЭМ, которые соединены быстрыми каналами связи. Эффект от использования созданных алгоритмов при отображении параллельных программ
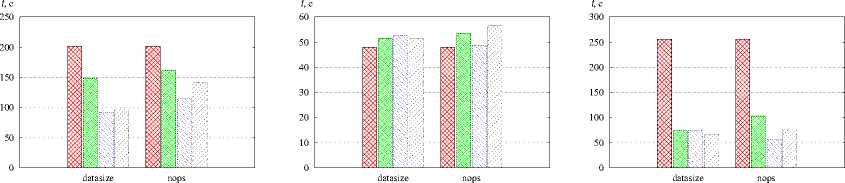
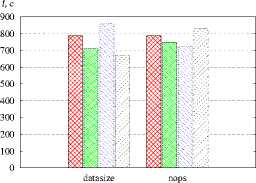
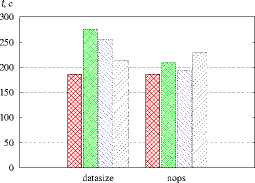
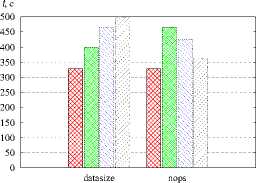
Рис. 7. Сравнение библиотек разбиения графов а — POP, r = 120, б — Sweep3D, r = 120, в — NPB MG, r = 64. г - XPB SP. r = 64. 0 - XPB LU. r = 120. e - XPB ВТ. r = 64
ezss — линейное отображение, ।---1 — METIS, । । — Scotch, гутл — gpart с однородными графами (NPB LU, NPB ВТ) и с графами недетерминированных обменов незначителен.
Время работы алгоритмов отображения не превышает 1 с (рис. 3). Оптимальный выбор способа формирования информационного графа (datasize или nops) зависит от типа параллельной программы и от ее ранга. Если известно, что в графе параллельной программы преобладают частые обмены сообщениями небольшого размера, рекомендуется использовать тип графа nops. В остальных случаях рекомендуется использовать datasize.
Проведено моделирование с целью сравнения эффективности пакетов METIS, Scotch и gpart разбиения графов (рис. 7). В качестве алгоритма отображения применялся L2MAP. Использование библиотеки Scotch обеспечивает незначительное сокращение времени выполнения программы POP по сравнению с другими пакетами. На остальных тестах все библиотеки дают сопоставимые или противоречивые результаты.
Заключение. Разработан метод HierarchicTaskMap и алгоритмы иерархического отображения в пространственно-распределенные ВС параллельных MPI-программ с целью минимизации времени их выполнения. Суть метода заключается в последовательном разбиении графа параллельной программы в соответствии с уровнями иерархии системы, что позволяет полностью учитывать структуру коммуникационной среды пространственно-распределенных ВС. Алгоритмы могут применяться не только при отображении MPI-программ, но также в run-time системах языков семейства PGAS.
Созданные алгоритмы позволяют сократить время выполнения параллельных программ в среднем на 30%. Результаты моделирования отображения реальных MPI-программ показали, что на всех тестовых задачах алгоритм L12MAP обеспечивает меньшее время выполнения программ. Данный алгоритм учитывает архитектурные особенности мультикластерных и GRID-систем, в которых вычислительные узлы разных подсистем взаимодействуют через медленные каналы связи.
Эффективность отображения зависит от объема и интенсивности передаваемой информации в дифференцированных обменах. Алгоритмы позволяют снизить время выполнения параллельных программ с информационными графами, имеющими разреженную структуру с преобладанием дифференцированных обменов (например, POP, NPG MG, GRAPH500).
Все предложенные алгоритмы характеризуются низкой вычислительной сложностью и позволяют вкладывать параллельные программы в большемасштабные ВС. Для уменьшения времени отображения алгоритмы могут быть эффективно распараллелены.
Список литературы Многоуровневые алгоритмы отображения параллельных МР1-программ на вычислительные кластеры
- ХОРОШЕВСКИЙ В. Г. Распределенные вычислительные системы с программируемой структурой//Вестник СибГУТИ. 2010. № 2 (10). Р. 3-41.
- GABRIEL Е., RESCH XL. RUHLE R. Implementing MPI with optimized algorithms for metacomputing//In Proc. of the third MPI Developer's and User's Conference. 1999. P. 31-41.
- SAITO H., TAURA K. Localitv-aware Connection Management and Rank Assignment for Wide-area MPI//In Proc. of the 7th IEEE International Symposium on Cluster Computing and the Grid (CCGRID 2007). 2007. P. 249-256.
- IMAMURA Т., TSUJITA Y., KOIDE H., TAKEMIYA H. An Architecture of Stampi: MPI Library on a cluster of parallel Computers//In Proc. of the 7th European PVM/MPI'2000. 2000. V. 1908. P. 200-207.
- MALYSHKIN N. V., Roux В., FOUGERE D., MALYSHKIN V. E. The NumGRID metacomputing system//In Bulletin of the Novosibirsk Computing Center, series Computer Science. 2004. N 21. P. 57-68.
- ФИЛАМОФИТСКИЙ М.П. Система поддержки метакомпьютерных расчетов X-COM: архитектура и технология работы//Вычислительные методы и программирование. 2004. Т. 5. Р. 123¬137.'
- ANDERSON D. P. Boinc: A system for public-resource computing and storage//5th IEEE/ACM International Workshop on Grid Computing. 2004. P. 4-10.
- ХОРОШЕВСКИЙ В.Г., КУРНОСОВ М.Г. Алгоритмы распределения ветвей параллельных программ по процессорным ядрам вычислительных систем//Автометрия. 2008. № 2 (44). С. 56-67.
- BROQUEDIS F., CLET-ORTEGA J., MOREAUD S., FURMENTO N., GOGLIN В., MERCIER G., THIBAULT S., NAMYST R. hwloc: a Generic Framework for Managing Hardware Affinities in HPC Applications//Int. Conference on Parallel, Distributed and Network-Based Processing (PDP2010). 2010. P. 180-186.
- MERCIER G., CLET-ORTEGA J. Towards an Efficient Process Placement Policy for MPI Applications in Multicore Environments//Proceedings of the 16th European PVM/MPI Users' Group Meeting on Recent Advances in Parallel Virtual Machine and Message Passing Interface. 2009. V. 5759. P. 104-115.
- Yu H., CHUNG I.-H., MOREIRA J. Topology mapping for Blue Gene/L supercomputer//In Proc. of SC'06. 2006. N. 116. P. 1-52.
- BHANOT G. Optimizing task layout on the Blue Gene/L supercomputer//IBM Journal of Research and Developmen. 2005. V. 49, N 2. P. 489-500.
- BALAJI P., GUPTA R., VISHNU R., BECKMAN P. Mapping Communication Layouts to Network Hardware Characteristics on Massive-Scale Blue Gene Systems//Special edition of the Springer Journal of Computer Science on Research and Development. 2011. V. 26. P. 247-256.
- BHATELE A., GUPTA G.R., KALE L.V., CHUNG I.H. Automated mapping of regular communication graphs on mesh interconnects//2010 International Conference on High Performance Computing. 2010. P. 1-10.
- BHATELE A., KALE L. V. Heuristic-Based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies//13th IEEE International Conference on High Performance Computing and Communication. 2011. P. 765-771.
- JEANNOT E., MERCIER G. Near-optimal placement of MPI processes on hierarchical NUMA architectures//Proceedings of the 16th international Euro-Par conference on Parallel processing: Part II. 2010. V. 6272. P. 199-210.
- BHATELE A., KALE L. V., KUMAR S. Dynamic topology aware load balancing algorithms for molecular dynamics applications//In Proc. of the 2009 ACM International Conference on Supercomputing (ICS'09). 2009. P. 110-116.
- LIFFLANDER J., MILLER P., VENKATARAMAN R. ET AL. Mapping Dense LU Factorization on Multicore Supercomputer Nodes//Parallel and Distributed Processing Symposium (IPDPS), 2012 IEEE 26th International. 2012. P. 596-606.
- TRAPP J.L. Implementing the MPI Process Topology Mechanism//Proceedings of the ACM/IEEE conference on Supercomputing. 2002. P. 1-14.
- KARLSSON C., DAVIES Т., CHEN Z. Optimizing Process-to-Core Mappings for Application Level Multi-dimensional MPI Communications//Proceedings of the 2012 IEEE International Conference on Cluster Computing. 2012. P. 486-494.
- HOEPLER Т., RABENSEIPNER R., RITZDORP H. ET AL. The scalable process topology interface of MPI 2.2//Concurr. Comput.: Pract. Exper. 2011. V. 23, N 4. P. 293-310.
- RASHTI M. J., GREEN J., BALAJI P. ET AL. Multi-core and network aware MPI topology functions//Proceedings of the 18th European MPI Users' Group conference on Recent advances in the message passing interface. 2011. V. 6960. P. 50-60.
- HOEPLER Т., SNIR M. Generic Topology Mapping Strategies for Large-scale Parallel Architectures//In Proc. of the 2011 ACM International Conference on Supercomputing (ICS'll). 2011. P. 75-85.
- ZHANG J., ZHAI J., CHEN W., ZHENG W. Process Mapping for MPI Collective Communications//Proceedings of the 15th International Euro-Par Conference on Parallel Processing. 2009. V. 5704. P. 81-92.
- BHATELE A., GAMBLIN Т., LANGER S.H. ET AL. Mapping applications with collectives over sub-communicators on torus networks//SC '12 Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. 2012. P. 1-11.
- HENDRICKSON В., LELAND R. A multilevel algorithm for partitioning graphs//Proc. of ACM/IEEE conference on Supercomputing. -San Diego: IEEE Press. 1995. P. 1-28.
- KARYPIS G., KUMAR V. Multilevel k-wav partitioning scheme for irregular graphs//Journal of Parallel and Distributed computing. 1998. V. 48(1). P. 96-129.
- FLDUCCLA I. MATTHEYSES R. M. A linear-time heuristic for improving network partitions//Proc. of conference "Design Automation". 1982. P. 175-181.
- ASANOVIC K. ET AL. The Landscape of Parallel Computing Research: A View from Berkeley//Electrical Engineering and Computer Sciences, University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. 2006. P. 1-54.
- PELLEGRINI F. Distillating knowledge about Scotch//Combinatorial Scientific Computing, Dagstuhl Seminar Proceedings series. 2009. N 09061. P. 1-12.
- ABOU-RJEILI A., KARYPISG. Multilevel Algorithms for Partitioning Power-Law Graphs//IEEE International Parallel k, Distributed Processing Symposium (IPDPS). 2006. P. 1-15.
- FERNANDEZ E., HEYMANN E., SENAR M.A. Supporting efficient execution of MPI applications across multiple sites//In Proc. of Euro-Par'2006. 2006. V. 4128. P. 383-392.
- TAKANO R., MATSUDA XL. KUDOH Т., KODAMA Y, OKAZAKI F., ISHIKAWA Y, YOSHIZAWA Y. High performance relay mechanism for MPI communication libraries run on multiple private IP address clusters//In Proc. of 8th IEEE international symposium on cluster computing and the grid (CCGRID 2008). 2008. P. 401-408.
- MERCIER G., JEANNOT E. Improving MPI applications performance on multicore clusters with rank reordering//Proceedings of the 18th European MPI Users' Group conference on Recent advances in the message passing interface. 2011. V. 6960. P. 39-49.
- SUBRAMONI H., POTLURI S., KANDALLA К. ET AL. Design of a scalable InfiniBand topology service to enable network-topologv-aware placement of processes//Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. 2012. P. 1-12.
