Многозадачное обучение для улучшения генерализации в задаче генерации структурированных запросов

Автор: Сомов О.Д.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 2 (62) т.16, 2024 года.
Бесплатный доступ
Семантический парсинг - это задача перевода выражения на естественном языке в логическое выражение на формальном языке. Примером практического применения семантического парсинга является преобразование текста в запрос к базе знаний. Наиболее популярными задачами преобразования текста в запрос являются задачи преобразования выражения в SQL и в SPARQL. Сдвиг распределения обучающей выборки - одна из главных проблем устойчивости семантических парсеров. Наиболее частым сдвигом в семантическом парсинге является композиционный сдвиг - необходимость генерации новых композиций кода из известных элементов синтаксиса целевого языка. В этой работе исследуется возможность использования предобученных языковых моделей (PLM) вместе с многозадачным обучением. Предлагаются специально разработанные разбиения наборов данных SPARQL и SQL, исходных датасетов LC-QuAD и WikiSQL для имитации сдвига распределения и сравнения оригинального подхода обучения генерации запроса с многозадачным подходом. В работе проведен углубленный анализ разбиений данных и предсказаний модели и показаны преимущества многозадачного подхода над оригинальным для задачи семантического парсинга.
Семантический парсинг, сдвиг распределения, многозадачное обучение
Короткий адрес: https://sciup.org/142242126
IDR: 142242126 | УДК: 004.852
Multi-task training for better generalization in structured query languages
Semantic parsing is a task of translating a natural language statement into a logical expression in a formal language. One of the applications of semantic parsing is text-to-query, where an natural language statement should be translated into an executable query for the knowledge base. The most popular text-to-query tasks are text-to-SQL tasks and text-to-SPARQL tasks. Semantic parsers often fall prey to the distribution shift problem. One of the most often shifts is compositional shift - the ability to generate novel code compositions from known syntax elements. In this work, we explore the robustness of using pretrained language models (PLM) along with multi-task training approach. We propose specifically designed data splits of the SPARQL and SQL datasets, LC-QuAD and WikiSQL, for emulating the distribution shift and compare the original state of the art text-to-query approach with multi-task. We provide an in-depth analysis of data splits and model predictions and show the advantages of multi-task approach over original for the text-to-query task.
Текст научной статьи Многозадачное обучение для улучшения генерализации в задаче генерации структурированных запросов
Семантический парсинг - это задача перевода выражения на естественном язвше в логическое выражение на формальном языке. Одним из применений семантического парсинга является преобразование текста в запрос к базе знаний. Наиболее популярными задачами преобразования текста в запрос являются задачи преобразования выражения в SQL или SPARQL [1]. Сегодня эти задачи решаются с помощью моделей архитектуры кодировщик-декодировщик (seq-to-seq), которые на хорошем уровне справляются с разнообразием естественного языка и умеют генерировать синтаксически правильные целевые запросы. Однако модели seq-to-seq работают плохо в условиях сдвига обучающей выборки [2].
Один из ключевых сдвигов в семантическом парсинге - композиционный сдвиг. Композиционный сдвиг естественен для задачи семантического парсинга, поскольку практически невозможно собрать все возможные синтаксические перестановки элементов логического языка вместе с соответствующими выражениями на естественном языке в обучающем наборе данных [3].
Известно, что многозадачный подход к обучению позволяет учить более устойчивые модели к различным видам сдвига в области NLP. Интуиция эффективности заключается в том, что одна модель обучается на разных источниках данных, которые обычно дополняют друг друга. Таким образом, модель может с разных сторон посмотреть на задачу и избежать проблемы переобучения, в том числе ложной корреляции. В NLP многозадачное обучение имеет два применения: решение одновременно множества семантически схожих задач (выделение именованных сущностей и их сопоставление)или разложение сложной проблемы на части, где каждая задача это решение глобальной подзадачи (задача семантического парсинга) [4].
В этой работе исследован многозадачный подход к разложению целевого запроса на несколько частей. Разработана контекстно-свободная грамматика (CFG) для двух языков структурированных запросов — SQL (WikiSQL [1]) и SPARQL (LC-QuAD [5]) — и использована для разложения целевого языка запросов в композиции. Созданные композиции выступают в качестве задач для многозадачного обучения, которое реализовано с помощью предобученной языковой модели PLM. Эффективность многозадачной модели оценена в задаче преобразования текста в запрос в сравнении с классическим дообучением PLM на различных разбиениях данных, которые имитируют различные сдвиги: случайное разбиение (IID) и 2 вида композиционных разбиений. Главный исследовательский вопрос данной работы: является ли стратегия многозадачного обучения более устойчивой к композиционным сдвигам при преобразовании текста в запрос?
2. Оценка композиционного обобщения
Качество моделей машинного обучения обуславливается их устойчивостью к изменениям входных данных. В домене семантического парсинга одним из признаков устойчивости является способность к композиционному обобщению. Это одна из важнейших способностей моделей семантического парсинга, позволяющая модели рекомбинировать известные синтаксические элементы в соответствии с входным вопросом. В контексте композицинного обобщения будут использованы термины токены и композиции.
Существуют токены набора данных SELECT, COUNT, SUM, Goals, Teams (Goals и Teams являются атрибутами таблицы). Последовательность произвольной длины этих токенов, например SELECT COUNT Goals, называется композициями. Примером композиционного обобщения является случай, когда композиции SELECT COUNT Goals, SELECT SUM Teams наблюдались во время обучения, а модель тестировалась на ранее не встречающейся композиции SELECT SUM Goals. Большинство доступных датасетов семантического парсинга разделены по принципу IID, поэтому напрямую невозможно оценить композиционное обобщение модели машинного обучения. Однако возможно вручную сформировать такие разбиения дан- ных по характеристикам целевой переменной для имитации - например, используя длину запроса как признак для разбиения. Короткие запросы оказываются в обучающих данных, длинные - в тестовом.
В представленной работе разработана контекстно-свободная грамматика для извлечения сложных композиций из целевых языков запросов (SQL/SPARQL) для организации многозадачного обучения и разделения данных для оценки композиционного обобщения.
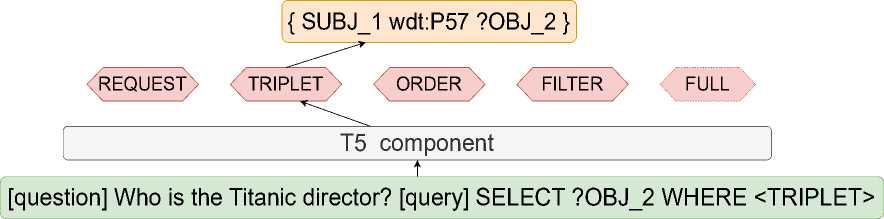
Рис. 1. Схема многозадачного обучения для языка SPARQL
3. Модель
Мы разработали многозадачную модель на основе предобученной модели Т5 [6] в архитектуре кодировщик-декодировщик. В исследуемоей постановке для обучения модели генерации запроса исходный запрос разбивается на несколько подзадач, чтобы каждый выходной слой (декодировщик) моделирования языковой последовательности генерировал свою часть запроса. Также добавляется дополнительный декодировщик, чтобы модель умела генерировать полностью запрос.
Композиции как задачи обучения Понятие композиций в семантическом парсинге помогает сформировать задачу обучения для многозадачного обучения. Логический запрос формируется из композиций, которые можно описать с помощью контекстно-свободной грамматики. Была разработана контекстно-свободная грамматика для каждой композиции для языков SQL и SPARQL. Для обучения маскирована одна из композиций запроса, и модель обучается предсказывать замаскированную композицию, учитывая вопрос и остальную часть запроса (которая не вошла в маску) в качестве контекста. Получается, что генерации каждой композиции соответствует эта отдельная задача и за ее решение отвечает отдельный декодировщик. В качестве кодировщика, используется предобученная модель.
Во время обучения используется стратегия префиксации Т5 [6] - вопрос, контекст запроса и схему (если она присутствует) базы знаний обозначаются с помощью служебных токенов [question], [query], [schema] . Каждая композиция маскируется названием соответствующей маски композиции, например маска
В результате для обучения сформированы следующие задачи для обучения:
-
• REQUEST - декодировщик отвечает за выбор запрашиваемых атрибутов запроса и возможных агрегатных функций. Например, select ?0BJ_3 в SPARQL и SELECT COUNT TD’s в SQL;
-
• TRIPLET - декодировщик отвечает за создание триплетов языка SPARQL. Например, SUBJ_1 р:Р97 ?0BJ_2.
-
• FILTER - декодировщик отвечает за создание операции фильтрации в запросах SPARQL. Например, filter ( ?0BJ_2 < NUM_VALUE_1 );
Алгоритм многозадачного обучения
-
1: Initialize (Д {wt}t&i,t2,...tn )
-
2: m ^ min(ltil, \t2\,...\tn | )
-
3: for iteration in m do
-
4: for t G t1,t2, ...tn do
-
5: (x,y) ^ Get BatchFromTask(t)
-
6: p ^ P(x)
-
7: p ^ Wt(p)
-
8: L ^ Loss(p,y)
-
9: P ^ P - pVpL
-
10: Wt ^ l.W — pVwtL
-
11: end for
-
12: end for
-
• ORDER - декодировщик отвечает за создание операции упорядочивания в запросах SPARQL. Например, order by asc ( ?0BJ_3 );
-
• COMPARISON - декодировщик отвечает за моделирование условий запроса в SQL. Например, Player = STR_VALUE_2. Он может включать AND или 0R операторы.
-
• FULL - декодировщик отвечает за моделирование полной последовательности запроса с контекстом NL и префиксом
.
В итоге, в многозаданое обучение входят следующие задачи (i) REQUEST, COMPARISON и ПОЛНЫЙ для обучения генерации SQL запроса; (ii) REQUEST, TRIPLET, ORDER, FILTER и FULL для обучения генерации SPARQL запроса.
Многозадачное обучение с планировщиком. Как показано на рис. 1, для обучения seq-to-seq PLM P заменяется единственный декодировщик w G Rh*v ft- размерность скрытого слоя кодировщика, V - размерность словаря языковой модели), множеством декодировщиков wt1 ,wt2,...,wtn для каждой задачи t, каждый из которых инициализирован случайными весами.
Во время обучения по порядку алгоритмом round-robin обучаются соответствующие декодировщик для задач wt1 ,wt2,...,wtn на данных задачи, а также сама PLM P модель. В качестве функции потерь L используется отрицательный логарифм правдоподобия для предсказания следующего токена уц учитывая предыдущую подпоследовательность токенов yt,t-iB наборе данных размером N длинной последовательности T и контекст обуче-ния(вопрос и незамаскированная часть запроса в многозадачном случае) С. Многозадачная модель [P,wt1 ,wt'2,...,wtn ] или классическая модель [P,w] параметризованы весами в.
N Т
£(у,0,С ) = — N ^^ logP(y4,tkt-i ,в,С).
v i=i t=i
Градиенты от функции Vwt, Vp потерь используются для последовательного обновления энкодера P и декодировщиков wt в режиме round-robin методом градиентного спуска. Выше представлен алгоритм обучения. Для каждого вопроса случайным образом выбирается одна из задач t. Данные подготовлены для задачи таким образом, что примеры для каждой задачи не пересекаются друг с другом.
4. Эксперименты4.1. Наборы данных
LC-QuAD - это набор пар выражений и соответствующих SPARQL запросов к WikiData графу знаний. WikiSQL - это набор пар выражений и соотвествующих SQL запросов, где каждому запросу соответствует своя таблица с данными. Учитывая, что схема графа знаний в LC-QuAD универсальна для всего набора данных, было решено не включать ее в качестве входных данных в модель. Однако в случае с WikiSQL, где схема уникальна для каждого примера, была добавлена к вопросу схема соответствующей таблицы в виде списка атрибутов таблицы. Для предварительной обработки данных были маскированы текстовые и численные значения в LC-QuAD и WikiSQL с помощью NUM_VALUE и STR_VALUE масок. В LC-QuAD были также нормализованы субъектные и объектные сущности: известные сущности языка SPARQL были замаскированы с помощью SUBJ/OBJ маски, неизвестные объекты - с помощью ?SUBJ/?OBJ маски. Чтобы модель умела верно заполнять слоты сущностей, ко всем замаскированным сущностям был добавлен индекс (например, SUBJ_1).
Разбиения данных. Для оценки композиционности, во время разбиения данных, требуется, чтобы каждый токен из тестового набора хотя бы один раз появлялся в наборе для обучения. Мы подготовили 3 разбиения данных для оценки метода обучения:
• Разделение IID: оно представляет собой случайное разбиение данных с обязательным условием, что обучающий и тестовый набор имели полное пересечение с точки зрения токенов.
• Разделение по длине запроса (Target Length): исходный датасет разделяется по длине запроса, так что тестовый набор данных содержит запросы другой длины, чем те, что находятся в обучающем наборе. В связи со спецификой набора данных LC-QuAD были помещены более длинные запросы в обучающий набор, а в наборе данных WikiSQL были помещены более длинные запросы в тестовый набор.
• Разделение по шаблонам(ТМСВ): исходный датасет разделяется по шаблонам запроса, так что шаблоны запроса из тестовой выборки не встречаются в шаблонах запросов обучающей выборки. Метод разбиения основан на алгоритме максимизации дивергенции композиций при удоволетворении условия композиционности [2].
4.2. Анализ результатов
Анализ разбиений. Каждый вопрос в каждом разбиении уникален, и между вопросами в обучающем и тестовом наборах нет пересечения. Целевые запросы этих наборов могут частично перекрываться. В частности, разделение IID LC-QuAD содержит пересечение 36% в целевых запросах, а разделение TMCD - 17%, целевые запросы не пересекаются в разбиении по flnnne(Target Length). Аналогично, разбиения WikiSQL IID и TMCD содержат пересечение 23% и 18% соответственно, целевые запросы не пересекаются в разбиении по длине. С точки зрения длины запроса разбиения LC-QuAD IID и TMCD средняя длина запроса составляет 17 токенов как в обучающем, так и в тестовом наборах. При разбиении Target Length средняя длина обучающих и тестовых запросов в Lc-QUAD датасете составляет 23 и 12 токена соответственно. В WikiSQL длина запросов обучающем и тестовом наборах составляют 9 и 14 токенов соответственно.
Метод оценки. В качестве оценки обучения использована метрика точного сопоставления ожидаемого вопроса и сгенерированного. Также использована метрику BLEU и для оценки качества нграммного пересечения(4 нграммы) и NGRAM Fl для оценки точности предсказания токенов, которые должны быть в запросе.
В сравнительном анализе метрик генерации запросов, представленных в табл. 1, наблюдается значительное улучшение точного соответствия по сравнению с моделью ERM для настройки IID (увеличение на 11%). Кроме того, показатель N-грамм F1 и показатель BLEU показали увеличение на 12% и 30% соответственно.
Приведенный компонентный анализ, как показано в табл. 2, продемонстрировал, что многозадачная модель МТ Т5 способна обобщать на новые компоненты со средним увели- чением на 23% по всем компонентам. В табл. 3 было исследовано, как экспериментальные модели работают с композициями, которых нет в обучающем наборе для каждого разделения. Результаты показывают, что, хотя многозадачный подход помогает лучше генерализировать на новые композиции при сдвиге распределения (+33%), классическая модель лучше справляется с разбиением IID. У МТ Т5 на этом разбиении наблюдается небольшое снижение па. 4%.
Таблица 1
Метрики для классической Т5 модели и многозадачной модели на датасетах WikiSQL и Lc-QuAD
|
Разбиение |
Модель |
Точность |
BLEU |
NGRAM Fl |
|||
|
WikiSQL |
LC-QuAD |
WikiSQL |
LC-QuAD |
WikiSQL |
LC-QuAD |
||
|
IID |
Т5 |
0.74 |
0.71 |
0.92 |
0.91 |
0.97 |
0.97 |
|
МТ Т5 |
0.89 |
0.78 |
0.95 |
0.95 |
0.98 |
0.98 |
|
|
Target Length |
Т5 |
0.17 |
0 |
0.69 |
0.16 |
0.87 |
0.68 |
|
МТ Т5 |
0.46 |
0.75 |
0.88 |
0.93 |
0.95 |
0.98 |
|
|
TMCD |
Т5 |
0.61 |
0.37 |
0.85 |
0.76 |
0.95 |
0.92 |
|
МТ Т5 |
0.75 |
0.85 |
0.89 |
0.96 |
0.97 |
0.99 |
|
Таблица 2
Покомпонентная точность для WikiSQL и LC-QuAD. Если ожидаемый и предсказанные запросы не содержат определенную композицию это засчитывается за верный ответ
|
Разбиение |
Модель |
REQUEST |
COMPARISON WikiSQL |
FILTER LC-QuAD |
TRIPLET LC-QuAD |
ORDER LC-QuAD |
|
|
WikiSQL |
LC-QuAD |
||||||
|
IID |
T5 |
0.85 |
0.88 |
0.9 |
0.97 |
0.87 |
1 |
|
MT T5 |
0.94 |
1 |
0.94 |
1 |
0.84 |
||
|
T5 |
0.58 |
0.18 |
0.54 |
1 |
0.08 |
1 |
|
|
Target Length |
MT T5 |
0.88 |
1 |
0.76 |
1 |
0.85 |
|
|
T5 |
0.76 |
0.73 |
0.82 |
0.99 |
0.61 |
1 |
|
|
TMCD |
MT T5 |
0.85 |
1 |
0.87 |
1 |
0.89 |
1 |
Таблица 3
Точность предсказания на ранее не встречающихся композициях
|
Разбиение |
Модель |
REQUEST WikiSQL |
COMPARISON WikiSQL |
TRIPLET LC-QuAD |
|
IID |
T5 |
0.59 |
0.75 |
0.48 |
|
MT T5 |
0.64 |
0.73 |
0.34 |
|
|
Target Length |
T5 |
0.33 |
0.26 |
0.02 |
|
MT T5 |
0.52 |
0.50 |
0.83 |
|
|
TMCD |
T5 |
0.49 |
0.62 |
0.27 |
|
MT T5 |
0.58 |
0.66 |
0.85 |
Что касается ошибок модели, было обнаружено, что основные ошибки возникают при неправильном предсказании предикатов в SPARQL запросах и неправильном выборе атрибутов в SQL запросах.
5. Заключение
Результаты проведенного исследования показывают, как стратегия многозадачного обучения, основанная на грамматике, помогает разработать более устойчивую модель в двух задачах преобразования текста в запрос. Чтобы оценить эту стратегию, было разработано три разбиения данных, два из которых имитируют композиционный сдвиг распределения, и оценено качество классической и многозадачной моделей. Результаты показывают, что многозадачное обучение демонстрируют значительно повышенную способность к композиционному обобщению, что делает их лучшим подходом для решения задачи семантического парсинга по сравнению со стандартным методом обучения. В дальнейшей работе планируется расширить исследования за счет внедрения данного подхода в другие семантические парсеры. Также планируется оценить многозадачный подход на более сложных датасетах, например PAUQ [7].
Список литературы Многозадачное обучение для улучшения генерализации в задаче генерации структурированных запросов
- Zhong V. [et al.]. Seq2sql: Generating structured queries from natural language using reinforcement learning // arXiv preprint. [2017]. arXiv: 1709.00103.
- Shaw P. [et al.]. Compositional generalization and natural language variation: Can a semantic parsing approach handle both? // arXiv preprint. [2020]. arXiv: 2010.12725.
- Hupkes D. [et al.]. Compositionalitv decomposed: How do neural networks generalise? // JAIR. 2020. V. 67. P. 757-795.
- Worsham J. [et al.]. Multi-task learning for natural language processing in the 2020s: Where are we going? // Pattern Recognition Letters. 2020. V. 136. P. 120-126.
- Dubey M. [et al.]. Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia // ISWC. 2019. V. 2. P. 69-78.
- Raffel C. [et al.]. Exploring the limits of transfer learning with a unified text-to-text transformer // JMLR. 2020. V. 21(1). P. 5485-5551.
- Bakshandaeva D. [et al.]. PAUQ: Text-to-SQL in Russian // EMNLP. 2022. V. 2022. P. 2355-2376.
