Mobile Localization Based on Clustering

Author: Malika BELKADI, Rachida AOUDJIT, Mehammed DAOUI, Mustapha LALAM
Journal: International Journal of Computer Network and Information Security(IJCNIS) @ijcnis
Article in issue: 9 vol.5, 2013.
Free access
This work presents a mobile location management technique based on the clustering. This technique can be implemented on next generation mobile networks by exploiting the data available on the users (age, function, address, workplace… etc), existing infrastructure (roads, location of base stations… etc) and the users' displacements history. The simulations are carried out using a realistic model of movements. The results show that our strategy requires a minimum number of location messages compared to the static and dynamic location management techniques.
Clustering, Location management, Mobile networks, Next generation networks
Short address: https://sciup.org/15011226
IDR: 15011226
Text of the scientific article Mobile Localization Based on Clustering
Published Online July 2013 in MECS (http://www.
Nowadays, mobile networks become an integral part of our daily life. Next generation networks open the way to new demands of services in multi-media and real time applications. These applications require more communication resources and higher Quality of Service (QoS) than traditional applications [1].
However, these networks are confronted to various problems including wasting resources, signal attenuation and interference that reduce the quality of service. Users’ mobility also generates QoS degradation and the network must deal with it.
Location management is an essential function in the mobile networks [2], [3], [4], [5], [6]: its aim is to locate the cell where a mobile user is, in order to make a call to him.
User mobility causes performance degradation in relation to the localization function. The network sends Page messages to several cells to locate the mobile. These messages consume a part of the already scarce bandwidth.
If the network has enough information about the mobile user displacements and if it integrates intelligent strategies to profit from this information, it can anticipate his future movement with high accuracy. Consequently, the network can better manage the mobilization and the sharing of its resources by sending a minimum (or nothing) of location messages.
In this work we present a solution for location based on the clustering. This technique is based on a human movement characteristics to predict the cell (or the set of cells) where the mobile can be.
The remainder of this paper is organized as follows. In section 2, we present location management techniques and we explain how we can deal with the location management problem. Section 3 gives the state of the art on the prediction methods in mobile networks. Section 4 and section 5 present our contribution. In section 4, we show how to use the clustering in location management and in section 5, we give the proposed solution. Section 6, presents the parameters adjustment and the evaluation of the solution. The last section concludes the paper.
-
II. LOCATION MANAGEMENT TECHNIQUES
To route a call to a mobile, the network must be able to determine its exact location without incurring excessive computation and communication costs.
Cellular networks partition their coverage area into a number of location areas. Each location area consists of a group of cells as shown in the Fig.1.
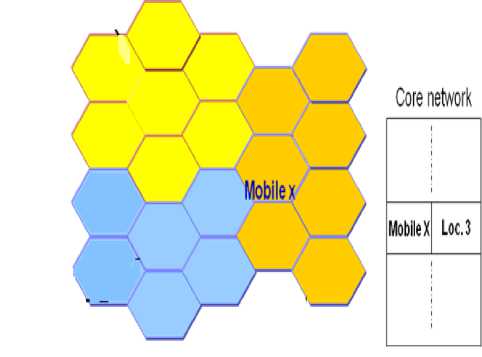
Location area 1
Location area 2
Location area 3
-
Figure 1 : Grouping cells in location areas
The location management technique uses two fundamental operations [2], which are:
-
• Location Update: Each mobile reports its
location to the network whenever it changes a location area, so that any incoming call to that mobile can thus be routed to the correct location area.
-
• Paging: the network locates the mobile by polling simultaneously all cells within the location area, when an incoming call arrives. Page messages are broadcasted in the current location area of the mobile. For example, if the mobile x moves from Location area 2 to Location area 3, as shown in Fig. 1, the page message will be broadcasted to all cells forming this last location area.
Generally, it is possible to use one or other of these operations. But in practice the two techniques are used conjointly to minimize the number of used messages.
When the mobile is in a location area, it doesn't need to update its position, when it passes from one area to another; it must send a location update message to the core network. This last knows the area where the mobile is, but does not know the exact cell. To find the cell where the mobile is, the network sends page messages to all cells constituting the area in which the mobile is localized.
This solution is valid only if the areas are well chosen. For example, if the mobile frequently moves on the periphery of the areas, a lot of update messages are sent to the network. This consumes a certain amount of limited wireless bandwidth. If the network has information on the users’ profiles and the infrastructure (roads, workplace, means of transport …etc), it will be able to choose adapted location areas, capable to decrease (or to eliminate) the number of update or page messages. Our work aims to use the movement prediction to group judiciously the cells in location areas. The following section gives a state of the art on this domain.
-
III. STATE OF THE ART
Mobility management in cellular networks requires the ability to move freely within the coverage area and still be connected. The localization consists to determine the position of a mobile at any time.
Paging and location update signaling take up valuable bandwidth in the wireless and mobile network. There is an inherent tradeoff between the costs of those two operations. This has led to extensive research activity on the important area of location management. Existing location management schemes are often partitioned into two categories: Static and Dynamic.
In [5], authors present two extremes techniques: Always-update and never-update. In Always-update, the mobile updates its position at each change of cells. In Never-update, the mobile performs no update of its position. The network is required to search it in all cells of the network. The first strategy produces an overhead of Update messages and the second creates an overhead of Page messages. Another static scheme consists to group the cells into location areas to reduce the network overhead. The mobile does not update its location, unless it changes an area [6], [7]. The network is required to search the mobile only in the last location area.
In the dynamic location management [8], the cells are dynamically grouped into location areas depending on the network load and users’ profiles. In [8], four different location areas groups were compared by using an activity-based mobility model. Focused on the results reported in [8], the location area mapping resulting in the lowest total cost is selected. The selected scheme partitions the 45 radio cells into a total of eleven location areas, with three to five cells in each.
In [9] the location update of the mobile is based on the number of movements made by this mobile. When the number of movements reaches a threshold, the mobile sends to the core network its position. In [10] user updates its location at each predetermined interval of time. In [11] the mobility model is based on a Markov chain in discrete time. The localization is carried out by calculating the probability that a mobile is in a given cell as a function of its mobility model.
The mobility prediction plays an important role in the quality of service particularly in the resource reservation. Many studies were carried out on prediction. In [12], Zhuang and al monitor the signal power in the base station to predict the next cell. When the signal in a new base station increases in power, the system concludes that the mobile moves towards this base station. This solution was improved in [13] by adding the time factor to predict the mobile arrival time.
In [14], Choi et al. estimate the user mobility according to displacements history observed in each cell. In [15], Shen et al. develope a prediction system based on a pilot signal measurement by using fuzzy logic to take into account pilot signals interferences and users random movements.
In [16] the authors use mobiles localization information recovered by GPS, which they provide to a Markov model to predict the future location. This location is provided to the applications to use them (for example to arrange an appointment if two users want to meet in the same place in the future).
In [17], Soh et al. present and describe the use of a prediction technique which periodically incorporates roads topographic information (every second for example, the mobile provides its position to its base station). An algorithm identifies the segment of the road taken by the mobile and its estimated speed. The system then predicts the future base station and estimates the expected time to reach it.
These solutions are limited because they are based on either a probabilistic model which does not completely reflect the users’ behavior, or on the user individual history which can be missing or insufficient.
New solutions based on heuristic methods were used. The techniques presented in [18] and [19] use neural networks for prediction. In [18], the authors adopted a structure of a cell divided into 2-tier areas (a vicinity area and an edge area). When the mobile is in a cell edges area, its coordinates are provided as input to the neural network which predicts the next cell to be visited. In [19], the authors present a system which periodically captures the connections traces. These traces are progressively recorded in a history which will be used as input to the neural network to predict the next cell to be visited.
The disadvantage of these methods is that they require a long training phase on mobile user behavior before the prediction succeeds. Moreover, the mobile user can change his behavior during the training phase or can go to a location he has never visited before, thus making the prediction ineffective.
In [20], Samaan et al. present a solution which includes spatial and user contexts. The spatial context consists of a set of abstract maps describing the geographical environment in which the mobile user progresses. Places, buildings and roads which lead to these places are described in these maps. The user context includes a set of information related to the mobile user making it possible to predict his mobility. This information is then combined by using Dempster Shafer algorithm to predict the future mobile location. Even if this solution seems to provide suitable results when mobile history is lacking, it is however too constraining because it requires additional information not easy to acquire and likely to frequent change.
In [21], the authors suggest a method based on information theory in which each mobile device collects a set of clues such as its position in a particular road and its stay time during its previous displacements. These clues are then processed by the current cell to predict the future cell. The use of information theory and decision trees allows choosing the most relevant clues for prediction. Its disadvantage is the need to store these clues in the mobile itself, which consumes memory, energy and bandwidth when communicating this information to the cell.
In [22] and [23] authors investigate simultaneously spatial and temporal attributes of data and apply a spatiotemporal data mining technique to discover frequent mobility patterns for predicting the next location of a mobile node. Their approach is to mine frequent mobility patterns with time and then to make use of them to construct temporal weighted mobility rules. These mobility rules are utilized in predicting the next location of a mobile node.
In [24] and [25] the authors propose a solution based on an ant system to predict the future cell where a mobile will cross, based on past movements of the mobile itself and other mobiles that move in the same way. This solution provides good prediction results in environments where the mobile produces common behaviors such as cities.
-
IV. MOVEMENT PREDICTION AND CLUSTERING
Users’ movements are not completely random because they follow professional and social behavior. They are not completely deterministic because they obey the will of the individual. A study [26] carried out in the USA for better organizing public transport has shown that nearly 80% of users displacements relate to work and nearly 20% relate to social or cultural reasons. During holidays, the percentage is only nearly 2%. It has also shown that displacements are influenced by the infrastructures of the places (trades, highways, streets, paths… etc). Displacements for work and social reasons are the most frequent and the most usual. The knowledge of the history (habits) of a user and his current location (on a road for example) could be useful to determine his probable future location.
Data Mining is a useful approach to mobility prediction based on the log file of node mobility history. It is a set of techniques drawn from various fields like data analysis, information theory and artificial intelligence applied to a data set to analyze and draw either useful new information or hidden relationships between these data [27]. Clustering is one of the techniques widely used in Data Mining. Clustering is used to identify homogeneous groups of individuals with common characteristics without knowing or being interested in these characteristics. This technique which is widely used in marketing to achieve targeted advertising is suited for location management. We could identify with this technique homogeneous groups of cells to facilitate the search for a mobile. For example we can group all cells covering a university residence and a campus where we could locate a mobile user who is a student.
-
V. PRESENTATION OF THE SOLUTION
To implement our solution, we assume a mobile network architecture formed by a set of cells. Each cell is managed by a base station (BS) that deals with mobiles that are in its range. The base stations are connected to the core network with a wired backbone (Fig. 2).
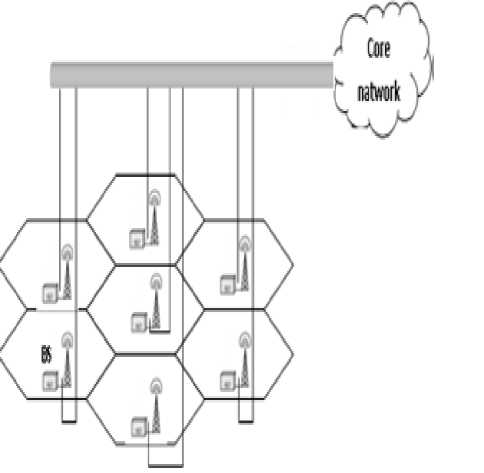
Figure 2: Mobile network architecture
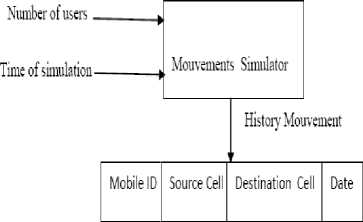
We also assume that each base station has a history of mobile user displacements. This history contains the mobile user identity (id), the cell from which he came (source cell), the cell to which he moved (destination cell)
and the date of travel (Fig. 3). This information can be retrieved in the log files of connections at each base station and store them in a database of the station itself.
|
Mobile ID |
Source Cell |
Destination Cell |
Date |
Figure 3 : Structure of a history line
The clustering can be used to group cells into location areas, as shown in Fig. 1. A location area is a restricted set of cells in which a mobile user can be located according to his profile and his history. We define the distance between two cells (Ci and Cj) relative to an individual X as follows:
D ( C i , C j ) =V n i 2 - n 2 j (1)
Where:
Number of appearances of the individual X in cell Ck
«к =
Total number of appearances ofX
The used clustering algorithm is a variant of the K-mean algorithm [28]. First, we set the desired number of clusters and then we apply an iterative algorithm from which we obtain the set of cells forming each cluster. The clustering algorithm is described as follows:
-
1. Determining the number of desired clusters (the parameter K).
-
2. Randomly choosing K cells that we consider as centers of the K clusters.
-
3. Calculating the distance between each cell of the
-
4. Assigning each cell to the nearest cluster according to the distance between this cell and the center cells by using the equation (1).
-
5. Recalculating the centers of the K clusters as follows:
network and the centers (centers cells).
-
a. For each cell C j of a given cluster, calculate the value :
∑D(Cj,Ci) with(j≠i) (2) i this represents the sum of the distances between this cell and the other cells Ci in the considered cluster.
-
b. The cell Cj with the smallest value of equation (2) is considered as a new center of the cluster.
-
6. Repeat steps 3, 4, 5 until the clusters become stable (the cells do not change the clusters).
Then we vary the parameter K to obtain the optimal number of clusters. Each cluster contains a set of cells having as a common factor the frequency of mobile visits. Thus, we bring out for a given mobile, a cluster in which it is frequently localized and another in which it is less frequently localized, and so on as given in Fig. 4.
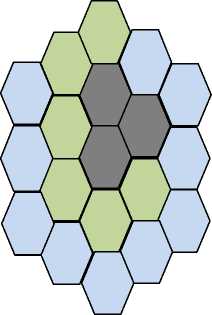
Location area in which the mobile is frequently located
0 Location area in which the mobile is less frequently located
0Location area in which the mobile is rarely located
Figure 4: Construction of zones by clustering
-
VI. ADJUSTMENT AND EVALUATION
The clustering algorithm requires training phase for adjusting its parameters. This training yields the optimal value of K that corresponds to the optimal number of location areas. This step must be conducted by using in general a sample of realistic data.
In the study of the mobility management and in the absence of a real trace of mobiles displacement, we can resort to a model. The choice of a realistic mobility model is essential. This model reproduces, in a realistic way, displacements of a set of users within a network. The majority of works presented in the literature use probabilistic models (Markov model, Poisson process…etc.) which generate either highly random displacements or highly deterministic displacements which do not reflect the real behavior of the mobile users.
For this we have chosen the activity model presented in [29]. This model is based on the work carried out by planning organizations and uses statistics drawn from five years surveys on users’ displacements. It simulates a set of users’ displacements during a number of days. Generated displacements are based on each users activity (work, study… etc.), the locations of these activities (house, work places, schools…etc) as well as the ways which lead to these locations.
The simulator that rests on the statistics of displacement led in the area of Waterloo [29] and recorded in the form of matrix called activity matrix indicating the probability of arrival of an activity and duration matrix indicating the probability that an activity takes a given period. These statistics as well as information concerning the users like the profile (fulltime employed, student, part-time employed…etc) and the infrastructures (roads, trade, stadium… etc) are recorded in the database of the simulator. The area of Waterloo is divided into 45 cells as indicated in Fig. 5. The draws indicate the roads between the cells.
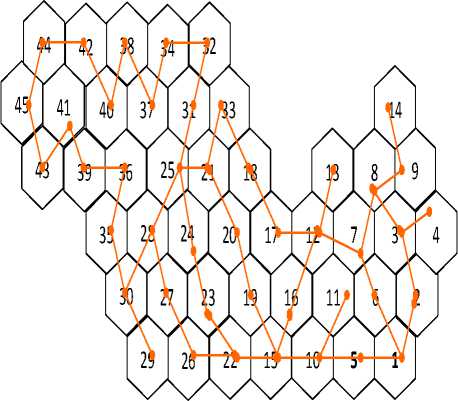
Figure 5 : Cellular structure of the simulator
According to the activity of the user, the simulator generates an activity event for a user based on the activity matrix and assigns it to a cell. It generates then the displacements relative to this activity before generating the following activity. The process continues until the end of the simulation. Fig. 6. describes the structure of the movement simulator.
— cctbeJmCci
— h™ mi п1»1 Irion
:ra[_:i:;p^:d usrpnip HHttimt,
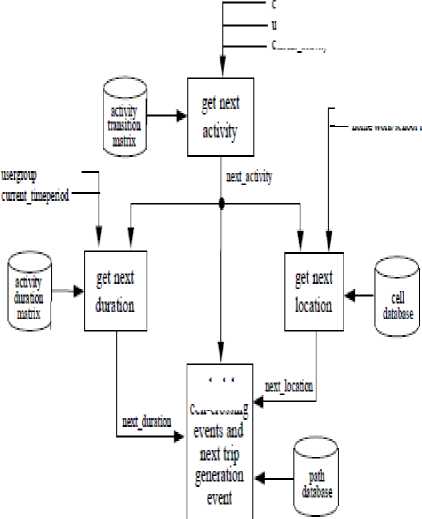
Figure 6: Structure of the movement simulator
schedule tell-таяпв
The simulation approach is represented in the Fig. 7. We use the movements’ simulator to generate realistic movements trace according to the number of users and the simulation time (in days) provided as parameters. Then, we provide this trace to our clustering and evaluation algorithm which returns the set of location areas for each mobile. The algorithm provides also the number of page and update messages according to the mean number of calls per day provided in entry to evaluate the solution.
Mean number of calls per day
+ ClusteringfEvaluation

• Mobile X
Areal {Cl, C2,C3]
Area2|C4,C5]
Area 3{C6,C7,C 8,(3]
Number of Page and Update messages
Figure 7: Simulation approach
The adjustment of the clustering algorithm consists in determining the value of K corresponding to the optimal number of location areas to create for the network. The evaluation is carried out based on the number of Page and Update messages necessary to the mobiles location. For 100 days of simulation, we varied K and calculated the total number of Page and Update messages. The results are presented in Fig. 8. The optimal number of location areas corresponds to 20 with Two to three cells per location.
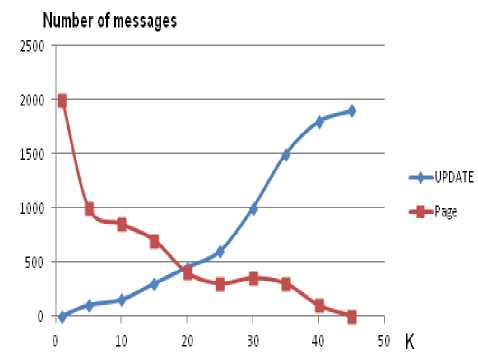
Figure 8: Number of Page and Update messages vs. K
We compared the algorithm obtained with a set of standards algorithms of location management; fixed and dynamic. In the fixed strategies, we grouped the 45 cells in fixed location areas (0, 1, 2 and 3). The strategy fixe 0 contains one cell per location area. In the strategy fixe 1 we created 13 location areas of three or four cells each one. In the strategy fixe 2, the areas contain three to five cells (generally different from fixed 1). In the strategy fixe 3 we divided the network into 5 areas with eight to ten cells per area. In the dynamic strategy, we used the algorithm defined in [30]. Fig. 9 and Fig. 10 give the average number of Update and Page messages for 50 days of simulation with 3, 9 and 12 calls per day and per user.
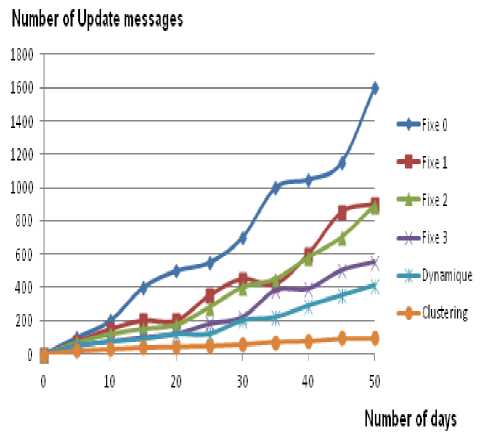
Figure 9: Average number of Update messages for the 6 strategies
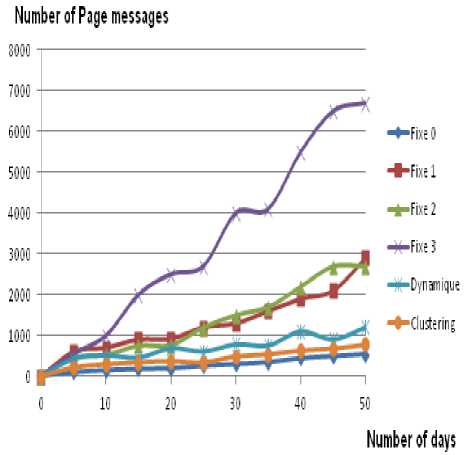
Figure 10: Average number of Page messages for the 6 strategies
We notice that our solution produced a minimum number of Page messages and a number of Update messages close to Fixe 0 as if the network knows exactly the cell in which the mobile is.
-
VII. CONCLUSION
Human displacements are often generated by socioprofessional needs (to go to work, to make purchases… etc). They are related to the existing infrastructure (roads, public transport, work-places...etc.). It is thus possible to predict them by seeking the relationship between these displacements and other available information like the users’ profiles and the site of the infrastructure.
Because of the complexity of the human displacements characteristics and the absence of reliable rules of movements’ prediction, clustering can constitute a solution to the location problem. Combined to other Data mining techniques as the classification and association rules, it is possible to refine the prediction of the displacements and the location management.
References Mobile Localization Based on Clustering
- Lorenz Pascal, "QoS in next generation networks," Proceedings of the 26th International Conference on Information Technology Interfaces, Cavtat, Croatia, 2004, pp. 13-18.
- Ian F. Akyildiz and Joseph S.M. Ho, "A mobile user location update and paging mechanism under delay constraints," Proceedings of the Conference on Applications, technologies, architectures, and protocols for computer communication, Cambridge, Massachusetts, United States, August 1995, pp. 244-255.
- SS. Frattasi, M. Monti, and R. Prasad, "Cooperative Mobile User Location for Next-Generation Wireless Cellular Networks," IEEE International Conference on Communications, Istanbul, Turkey, Proceedings, June 2006, pp. 5760-5765.
- Ahadur Rahaman, Jemal Abawajy and Michael Hobbs, "Taxonomy and Survey of Location Management Systems," 6th IEEE/ACIS International Conference on Computer and Information Science (ICIS 2007), Melbourne, Australia, 2007, pp. 369-374.
- B. Sidhu, H. Singh, "Location management in cellular networks," Proceedings of World Academy of Science, Engineering and Technology, vol. 21, 2007, pp. 314-319.
- A. Bar-noy, I. Kessler, "Tracking mobile users in wireless communication networks," IEEE transaction in information theory, vol. 39, n°6, 1993, pp. 1877-1886.
- M. Mouly and M. B. Pautet, "The GSM System for Mobile Communications," Telecom Publishing, 1992.
- J. Scourias and T. Kunz, "A dynamic individualized location management algorithm," The 8th IEEE International Symposium on Personal, Indoor, and Mobile Radio Communications, Proceedings, Helsinki, Finland, September 1997, pp. 1004-1008.
- Jang Hyun Baek , Jae Young Seo and Douglas C. Sicker, "Performance analysis and optimization of an improved dynamic movement based location update scheme in mobile cellular networks," International Conference of Computational Science and Its Applications (ICCSA), Proceedings, Singapore, May 2005, pp. 528-537.
- N. Das, "Performance analysis of dynamic location updation strategies for mobile users," International Conference of Distributed Computing System, Taipei, April 2000, pp. 428-435.
- R. Dugard and U. B Desai, "A tutorial on hidden markov models," Technical Report No. SPANN-96.1, Indian Institute of Technology Bombay, 1996.
- W. Zhuang, K.C. Chua and S. M. Jiang, "Measurement-Based Dynamic Bandwidth Reservation Scheme for Handoff in Mobile Multimedia Networks," Proceedings of Universal Personal Communications, Florence, October 1998, pp. 311-315.
- L. Hsu, R. Purnadi and S.S. Peter Wang, "Maintaining Quality of Service (QoS) during Handoff in Cellular System with Movement Prediction Schemes," Vehicular Technology Conference, VTC 1999 - Fall. IEEE VTS 50th, Amsterdam, September 1999, pp. 2153-2157.
- S. Choi and K. G. Shin, "Predictive and Adaptive Bandwidth Reservation for Hand-offs in QoS-Sensitive Cellular Networks," Proceedings of the ACM SIGCOMM '98 conference on Applications, technologies, architectures, and protocols for computer communication, Vancouver, British Columbia, Canada , 1998, pp. 155-166.
- X. Shen, J. W. Mark and J. Ye, "User Mobility Profile Prediction: An Adaptive Fuzzy Interference Approach," Wireless Networks, vol. 6, n°5, 2000, pp. 363-374.
- D. Ashrook and T.Staruer, "Learning Significant Locations and Predicting user Movement with GPS," 6th IEEE International Symposium on Wearable Computers, Proceedings, Washington, DC, USA, 2002, pp. 101-108.
- W. S. Soh and H.S. Kim, "QoS Provisioning in Cellular Networks Based on Mobility Prediction Techniques," IEEE Communication Magazine, vol. 41, n°1, 2003, pp.86-92.
- S. C. Liou and H.C. Lu, "Applied Neural Network for Location Prediction and Resource Reservation Scheme in Wireless Networks," International Conference of Communication Technology, Beijng, China. April, 2003, pp. 958-961.
- J. Capka and R. Boutaba, "Mobility Prediction in Wireless Networks using Neural Networks," International Federation for information Processing, Proceedings, San Diego, California, USA, October 2004, pp. 320-333.
- N. Samaan, and A. Karmouch, "A Mobility Perdiction Architecture based on Contextual Knowledge and Conceptual Maps," IEEE transactions on mobile computing, vol. 4, n° 6, 2005, pp. 537-551.
- J. M. François and G. Leduc, "Entropy-Based Knowledge Spreading and Application to Mobility Prediction," ACM CoNEXT'05, Proceedings, Toulouse, France. October 2005, pp. 10-20.
- Thuy Van T. Duong and Dinh Que Tran, "An Effective Approach for Mobility Prediction in Wireless Network based on Temporal Weighted Mobility Rule," In International Journal of Computer Science and Telecommunications, vol. 3, n°2, February 2012, pp. 29-36.
- C. H. Tran, T. V. T. Duong and D. Q. Tran, "Future Location Prediction in Wireless Network Based on Spatiotemporal Data Mining," Journal of Communication and Computer vol. 9, issue 2012, pp. 473-480.
- M. Daoui, A. M'zoughi, M. Lalam, M. Belkadi and R. Aoudjit, "Mobility prediction based on an ant system," Computer Communications, vol. 31, n°14, 2008, pp. 3090-3097.
- M. Daoui, A. M'zoughi, M. Lalam, R. Aoudjit and M. Belkadi, "Forecasting models, methods and applications, mobility prediction in cellular network," In i-concepts press, 2010, pp. 221-232.
- P. Hu and J. Young, "1990 Nationwide Personal Transportation Survey (NPTS)," Office of Highway Information Management, October 1994.
- J. Han, M. Kamber, "Data mining concepts & techniques, Morgan Kaufmann," 2nd edition, 2006.
- X. Wu, V. Kumar, et al, "Top 10 algorithms in data mining. Knowledge and Information Systems," vol. 14, n°1, 2008, pp. 1-37.
- J. Scourias and T. Kunz, "An Activity-based Mobility Model and Location Management Simulation Framework," Second ACM International Workshop on Modeling, Analysis and Simulation of Wireless and Mobile Systems (MSWiM) Proceedings, Seattle, Washington, USA, 1999, pp. 61-68.
- J. Scorias and T. Kunz, "A dynamic individualized location management algorithm," In 8th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, 'Waves of the Year 2000'. PIMRC '97, Helsinki, September 1997, pp. 1004-1008.
