Модель интеграции данных в единое информационное пространство предприятия с использованием метода n-грамм

Автор: Подобрий Александр Николаевич
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Механика и машиностроение
Статья в выпуске: 4-3 т.14, 2012 года.
Бесплатный доступ
В статье рассматривается подход к реализации сопоставления данных с помощью модифицированного метода n-грамм. Выводится модель интегрированной информационной системы и доступа к сопоставленным данным в рамках корпоративной информационной сети. Статья предназначена для специалистов, занимающихся внедрением автоматизированных систем управления предприятием, а также для специалистов занимающихся вопросами интеграции данных.
Интеграция данных, n-грамм, матрица доступа, предприятие, модель интеграции
Короткий адрес: https://sciup.org/148201307
IDR: 148201307 | УДК: 004.6
Data integration model in a common information space companies using method n-gram
In the article considers an approach to the implementation of mapping data with the modified method of n-gram and model of an integrated information system, and access to associated data within a corporate network information. Article is intended for professionals involved in the introduction of automated business management systems, as well as for all professionals involved in data integration.
Текст научной статьи Модель интеграции данных в единое информационное пространство предприятия с использованием метода n-грамм
Интеграция данных – обеспечение единого согласованного представления данных для ряда информационных ресурсов, объединенных общим смысловым содержанием, и/или на основе общего представления – частных представлений.
Интеграция данных в информационных системах понимается как обеспечение единого унифицированного интерфейса для доступа к некоторой совокупности, неоднородных независимых источников данных. Таким образом, для пользователя информационные ресурсы всей совокупности интегрируемых источников представляются как новый единый источник. Система, обеспечивающая пользователю такие возможности, называется системой интеграции данных [1, 2].
Система интеграции данных освобождает пользователей от необходимости знания, данные из каких источников, кроме интегрированного, они используют, каковы свойства этих источников и как осуществить доступ к ним. Доступ к данным многих источников обеспечивается через единый интерфейс, который представляет совокупность данных из множества независимых источников в терминах единой модели данных на основании прав доступа.
Существуют три основных типа информационного поиска: булевый, поиск по релевантности и поиск по сходству. Для сопоставления неоднозначных наименований объектов предлагается использовать метод нечеткого поиска основанный на релевантности – количественного критерия схожести. В основе данного метода лежит модифицированный метод n-грамм.
n-грамм, и матрицы прав доступа сотрудников предприятия.
МОДЕЛЬ ИНТЕГРИРОВАННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ
Основным понятием описываемой модели является понятие информационного объекта, являющимся сущностью информационной системы [3].
Набором информационных объектов назовем множество упорядоченных пар вида:
x = {< a J, bx >, < a 2, b 2 >,..., < a„, bn >}, ai <> aj для i <> j , i, j e {1..n}, где a – имя атрибута (идентификатор), b – характеристика (свойство) объекта.
Набор свойств bi можно представить как кортеж полей bi = {ei 1, ei2 v, ein } , каждое поле которого состоит из набора:
e ij = ( v j , s j) , где vij – значение атрибута, sij – тип атрибута
Таким образом, набор свойств информационного объекта заданных множеством характеристик ставят в соответствие каждому объекту некоторое свойство b i e B = { b 1 ,b 2,..., b n } .
Через O x обозначим множество атрибутов элемента x , через o i ( x ) - характеристика атрибута oi объекта x .
Информационную систему рассмотрим как структуру информационной схемы, описывающей характеристики входящих в эту систему информационных объектов.
Информационная схема включает в себя следующие характеристики:
-
- множество характеристик информационных объектов;
-
- множество атрибутов для информационных объектов каждой характеристики;
-
- множество используемых атрибутов;
-
- множество связей между информационными объектами;
-
- множество иерархий (вложенностей) объектов.
Связи между информационными объектами зададим элементами множества L = { l 1, l 2,..., l k } , где каждый элемент является тройкой:
lj= {oj1, oj2,. rj} , где Oj 1, Oj2 - два связанных между собой объекта, rj – наименование (вид) роли, по которой связываются объекты.
Иерархия (дерево вложенности) объектов опишем множеством T = {t 1, t 2,..., t n } , где каждый элемент - это пара t. = ( o i , O j ) , где i е {1.. п} , в которой первый элемент соответствует объекту с тем же индексом, а второй указывает на объект, который является родительским по отношению к данному в иерархии.
Информационной схемой назовем набор: M =< O , B , L , T > , где O = { о1,о 2,..., o n } - множество атрибутов информационных объектов;
B = { b1,b 2,..., b n } — множество возможных характеристик атрибутов;
L = {l1,l 2,..., l k } - множество связей между информационными объектами;
T = {t 1,1 2,..., t p } - множество иерархий (вложенностей) объектов
Информационной системой построенной по схеме M назовем набор:
SM =< M , S , в > , где M =< O , B , L , T > - информационная схема;
S = { x1,x 2,..., x n } - множествоинформационных объектов;
в : S ^ B - отображение, ставящее каждому объекту его характеристику.
Причем для каждого информационного объекта x ∈ S выполнено следующее условие:
Все атрибуты x имеют значение и тип, т.е. для любой пары е x существует b е в ( а ) .
Пусть M = { M 1,M 2,..., M n } - множество схем и нфор м ацион н ых систем. Используя SM = { S 1 M 1 , S 2 M 2 ,., S nMn }, обозначим множество информационных систем, каждая и з которых имеет соответствующую схему из M .
Для того, чтобы множества информационных систем можно было рассматривать как единую информационную систему, необходимо, чтобы разные информационные системы, входящие в S M могли иметь пересекающиеся множества атрибутов объектов и соответствующие им характеристики.
Таким образом, для построения интегрированной информационной системы, необходимо, чтобы отображения – B, ставящие каждому объекту его свойство на разных информационных системах совпадали.
Множество информационных систем SM неп р оти в оречи в о если существует SM = { S 1 M 1 , S 2 M 2 ,., S nMn } - множество информационных систем, где S iM =< M i , S i , в .> и M i =< O i , B i , L i , T > , для которых:
S = U S . , O = U O i , B = U B i , L = U L i , T = U T .
1 < i < N 1 < i < N 1 < i < N 1 < i < N 1 < i < N
При условии, что существует отображение β : S → B, являющееся расширением каждого отображения β i для 1 ≤ i ≤ n.
Таким образом, будем счи тать ин формационную систему S' =< M , S , в > , где M =< O,B,L,T > интегрированной на множестве S M .
ОПИСАНИЕ МОДЕЛИ СРАВНЕНИЯ ХАРАКТЕРИСТИК ИНФОРМАЦИОННЫХ ОБЪЕКТОВ
N-граммой на алфавите E некоторого языка L(E) будем представлять набор символов длиной n строки Y [5],
где E = {v,e1,e2,...,el} - алфавит;
L(E) – некоторый язык на алфавите E;
Y –строка символов.
N-грамма может совпадать с какой-либо строкой, быть его подстрокой или не входить в язык L(E):
-
- если алфавит E = { v , e 1, e 2,..., e l } и строка Y = { У 1 ,У 2 ,..., У п ,$} , где V i , y . е A ,то n-грамма – это последовательность из n символов, принадлежащая одному слову;
-
- если строки – это тексты, то n-грамма – это последовательность из N слов одного текста.
Число вхождений строки Y опишем множеством: C(w) = C(w1,w2,...,wn), где W = {w1,w2,...,wn} есть совокупность всех слов рассматриваемого языка L(E)
Вероятность P(W) появления n-граммы W = { w 1, w 2,..., w n } вычисляется по формуле:
P ( w . ) =
C (w.) X C (wj) , wj где wi – n – грамма;
C ( w i ) - количество вхождений w i ;
X C ( w j ) - общее число возможных n -грамм.
Если вероятность появления символов в любой позиции строки Y имеют одну и ту же вероятность, то формулу вероятности можно представить:
n
P ( w 1- wn ) = П P ( w )
i = 1
Таким образом, любые перестановки символов строки Y имеют одну и ту же вероятность.
Релевантность есть степень (коэффициент) соответствия поискового шаблона P = { p 1 ,p 2,..., pn } и просматриваемого текста. Данный коэффициент можно воспринимать как процент вхождения поисковой строки к общему объему текста.
Формулу релевантности можно представить как:
N
У r ( i )
R = ^----;
N sovp (str 1, str 2, i) + sovp (str 2, str 1, i)
r (1 ) = ------------------------------------------------
C (str 1, i) + C (str 2, i) ’ где sovp(Y1, Y2, i) - сумма совпадений всех подстрок длиной i из строки Y1 в строке Y,;
C ( str 1, i ) - общее число возможных n -грамм длиной i;
N – фиксированная длина максимальной подстроки.
Данный метод позволяет получить схожие тексты информации с высокой долей вероятности. За счет увеличения фиксированной длины подстроки N, и в случае, когда N будет равно длине строки, при отсутствии точных дублей строк будет получено полностью равномерное распределение.
Недостатком данного метода можно считать низкую степень релевантности при сравнении строк с одинаковым набором слов, но с разным порядком следования.
Пример 1:
Вычислим коэффициент релевантности наименований двух атрибутов: Y 1 =(“Иванов Сергей”) и Y , =(“Сергей Иванов”)
При N=3 R= 0.72,
N=4 R=0.6
Для сравнения данных атрибутов разобьём строки Y1 и Y, на слова с помощью пробельного символа х, где G1 = {g 1,g2,...,gm} е Y — набор слов первой строки;
G2 = {g 1,g2,...,gk} е Y2 - набор слов вто- рой строки;
G 1 = m , G 2| = к
– количества слов в строках.
Таким образом, вероятность совпадения сло
-
ва g j строки Y 1 и строки Y , при длине n-грамма равной i получаем:
где sovp ( g j , str 2, i ) - сумма совпадений всех подстрок длиной i из набора слов G в строке Y ,;
C ( g j , i ) - общее число возможных n - грамм длиной i в слове G
Формула релевантности соответствия gi – отдельно взятого слова строки Y 1 со строкой Y , будет выражаться:
R ( g j ) =
N
У r ( i )
i = 1
N
Коэффициент релевантности строки Y 1 со строкой Y 2 :
m
У R ( g i )
R (G ‘) = -=1------ m где R(gj) - коэффициент релевантности gi слова строки Y1 ;
m - количество слов в строке Y 1 .
Аналогично выводится коэффициент реле вантности для строки Y2 .
Общий коэффициент соответствия двух строк Y 1 и Y 2 можно представить как:
= R (G1) + R (G2) v main 2 , где R(G1 ) - коэффициент релевантности строки Y1 со строкой Y2 ;
R ( G 2) - коэффициент релевантности строки Y 2 со строкой Y 1 .
Пример 2:
Вычислим коэффициент релевантности наименований двух атрибутов: Y 1 =(“Бензопила белая”) и Y , =(“Бензопила”)
При N=3,
R ( G 1 ) = 0.66, R ( G 2) =1, R main = 0.83
Таким образом, на основании полученных трех коэффициентов релевантности строк, фиксированная длина максимальной подстроки можно с высокой долей вероятности определить однозначные атрибуты. Для определения однозначного соответствия двух строк достаточно сделать длину подстроки плавающей в зависимости от максимальной длины gj .
Результат сопоставления можно увидеть на рис. 1, где данные берутся из разных корпоративных информационных систем и представляются в едином виде.
ПОСТРОЕНИЕ ЕДИНОГО ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА r (i) =
sovp ( g j , str 2, i ) C ( g j , ii )
Информационной основой автоматизированной интегрированной информационной си-
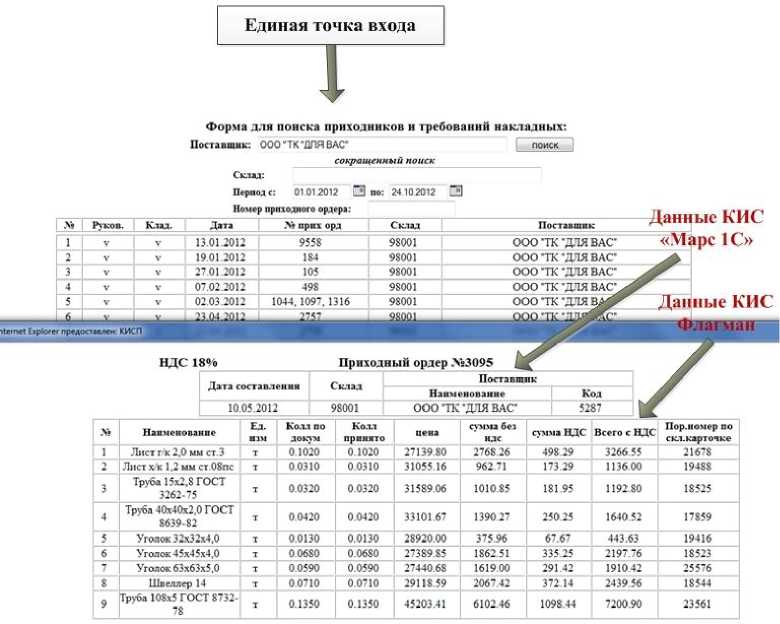
Рис. 1. Окно программы просмотра приходных ордеров из КИС “Марс 1С” и КИС “Флагман”
стемы управления предприятия должна являться единая распределенная база данных, в которой каждый пользователь, обладающий соответственными правами доступа, может своевременно получить информацию из разных информационных систем [7].
Объект информационного ресурса интегрированной информационной системы можно представить как набор полей: h = {< aj,bx >,< a2,b2 >,...,< an,bn >}, ai <> aj для i <>j', _
i, j e{1..n}, ai e O, b e B , где a – идентификатор объекта,
-
b – значение объекта.
Информационным ресурсом интегрированной информационной системы есть набор:
U = {H, V, D} , где H = {h1, h2,..., hn} — множество объектов информационного ресурса;
V = { V 1 , v 2,..., v n } — множество представлений;
D = { d 1 , d 2,..., dn } - множество прав доступа пользователей;
Представлением V информационного ресурса интегрированной информационной системы называется именованная функция или процедура представления пользователю набора информационных сущностей одного типа, определенных в виде реляционной таблицы. Представление, в свою очередь, включает в себя следующие множества:
-
- набор входных параметров P = {p 1 ,p 2,..., pn } – на основании их значений и формируется конкретный экземпляр представления;
-
- набор выходных параметров K = {kx,k 2 ,...kn } – поля, обеспечивающие уникальность каждой записи.
Множество всех информационных ресурсов обозначим U = { и 1 , u 2,..., u l } , где l - количество всех ресурсов.
Матрица прав доступа сотрудников предприятия к интегрированным объектам информационных ресурсов представляется:
S
|
' S 11 S 12 |
S 12 .. 22 .. |
. S 1 k . S 2 k |
A |
|
... ( S 1 1 |
... .. S l 2 . |
. ... . S lk |
/ |
где Sij – множество прав доступа на просмотр и редактирование;
S l 1 - информационный ресурс из множества U;
S 1 k - информационный объект из множества Q . Множество прав доступа к информационным ресурсам Sij состоит из двоек вида:
( s p , s c ) , причем s p , s c e {0;1} , где s p – правила доступа на просмотр; sc – правила доступа на изменение. Таким образом матрицу прав доступа можно представить:
s =
(spH’scH) (S p21 ’S c21 )
...
v (spH’scH)
(Sp12,Sc12) ••• (Sp1k’Sc1k)(Sp22’Sc22) ••• (Sp2k’Sc2k)
... ... ...
Список литературы Модель интеграции данных в единое информационное пространство предприятия с использованием метода n-грамм
- Levy A.Y. Logic-Based Techniques in Data Integration. Logic-based Techniques in Data Integration. In: Logic Based Artificial Intelligence. Edited by J. Minker. Kluwer Publishers, 2000.
- Manolescu I., Florescu D., Kossman D. Answering XML Queries over Heterogeneous Data Sources. Proc. Of the 27th VLDB Conference, Roma, Italy, 2001.
- Петров В. Н. Информационные системы. СПб.: Питер, 2002. 430 c.
- Спирли, Э. Корпоративные хранилища данных. Планирование, разработка и реализация. Т.1. М.: Вильямс, 2001. 230 с.
- Ахатов А. Р. Алгоритмы программной системы контроля текстовой информации на основе n-граммной языковой модели//Актуальные проблемы современной науки. 2009. № 3. С. 156-161.
- Герасименко В.А., Малюк А.А. Основы защиты информации. М.: Инкомбук, 1997.
- Подобрий А.Н. Информационная модель безопасности веб-портала на предприятиях. Инноватика-2011: Материалы международной конференции. Махачкала (март 2011).
- Подобрий А.Н. Модель доступа к веб-порталу на современном предприятии//Известия Самарского научного центра РАН. 2011. Т.13. № 4(2). С. 475-478.
