Модели и алгоритмы автоматической группировки объектов на основе модели k-средних

Автор: Шкаберина Г.Ш., Казаковцев Л.А., Ли Ж.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 3 т.21, 2020 года.
Бесплатный доступ
Работа посвящена исследованию и разработке новых алгоритмов автоматической группировки объектов, которые позволяют повысить точность и стабильность результата решения практических задач, например, таких как задача выделения однородных партий промышленной продукции. В статье исследуется применение алгоритма k-средних с Евклидовым, Манхэттенским, Махаланобиса мерами расстояния для задачи автоматической группировки объектов с большим количеством параметров. Представлена новая модель для решения задач автоматической группировки промышленной продукции на основе модели k-средних с мерой расстояния Махаланобиса. Данная модель использует процедуру обучения путем вычисления усредненной оценки ковариационной матрицы для обучающей выборки (выборка с предварительно размеченными данными). Предложен новый алгоритм автоматической группировки объектов, основанный на оптимизационной модели k-средних с мерой расстояния Махаланобиса и средневзвешенной ковариационной матрицей, рассчитанной по обучающей выборке. Алгоритм позволяет снизить долю ошибок (повысить индекс Рэнда) при выявлении однородных производственных партий продукции по результатам тестовых испытаний. Представлен новый подход к разработке генетических алгоритмов для задачи k-средних с применением единой жадной агломеративной эвристической процедуры в качестве оператора скрещивания и оператора мутации. Вычислительный эксперимент показал, что новая процедура мутации является быстрой и эффективной по сравнению с исходной мутацией генетического алгоритма, показана высокая скорость сходимости целевой функции. Применение данного алгоритма позволяет статистически значимо повысить точность результата (улучшить достигаемое значение целевой функции в рамках выбранной математической модели решения задачи автоматической группировки), а также его стабильность за фиксированное время по сравнению с известными алгоритмами автоматической группировки. Результаты показывают, что идея включения нового оператора мутации в генетическом алгоритме значительно улучшает результаты простейшего генетического алгоритма для задачи k-средних.
Автоматическая группировка, k-средних, расстояние махаланобиса, генетический алгоритм
Короткий адрес: https://sciup.org/148321983
IDR: 148321983 | УДК: 519.6 | DOI: 10.31772/2587-6066-2020-21-3-347-354
Models and algorithms for automatic grouping of objects based on the k-means model
The paper is devoted to the study and development of new algorithms for automatic grouping of objects. The algorithms can improve the accuracy and stability of the result of solving practical problems, such as the problems of identifying homogeneous batches of industrial products. The paper examines the application of the k-means algorithm with the Euclidean, Manhattan, Mahalanobis distance measures for the problem of automatic grouping of objects with a large number of parameters. A new model is presented for solving problems of automatic grouping of industrial products based on the k-means model with the Mahalanobis distance measure. The model uses a training procedure by calculating the averaged estimate of the covariance matrix for the training sample (sample with pre-labeled data). A new algorithm for automatic grouping of objects based on an optimization model of k-means with the Mahalanobis distance measure and a weighted average covariance matrix calculated from a training sample is proposed. The algorithm allows reducing the proportion of errors (increasing the Rand index) when identifying homogeneous production batches of products based on the results of tests. A new approach to the development of genetic algorithms for the k-means problem with the use of a single greedy agglomerative heuristic procedure as the crossover operator and the mutation operator is presented. The computational experiment has shown that the new mutation procedure is fast and efficient in comparison with the original mutation of the genetic algorithm. The high rate of convergence of the objective function is shown. The use of this algorithm allows a statistically significant increase both in the accuracy of the result (improving the achieved value of the objective function within the framework of the chosen mathematical model for solving the problem of automatic grouping), and in its stability, in a fixed time, in comparison with the known algorithms of automatic grouping. The results show that the idea of including a new mutation operator in the genetic algorithm significantly improves the results of the simplest genetic algorithm for the k-means problem.
Текст научной статьи Модели и алгоритмы автоматической группировки объектов на основе модели k-средних
Введение. Автоматическая группировка (АГ) предполагает разделение множества объектов на подмножества (группы) так, чтобы объекты из одного подмножества были более похожи друг на друга, чем на объекты из других подмножеств по какому-либо критерию. В процессе группировки объектов некоторого множества на определенные группы (подмножества) учитываются общие признаки объекта и методы, с помощью которых происходило разделение.
Чтобы исключить появление ненадежных электрорадиоизделий, предназначенных для установки в бортовую аппаратуру космического корабля с длительным периодом активного существования, вся электронная компонентная база проходит через специализированные центры технических испытаний [1; 2]. Эти центры выполняют операции полного входного контроля электрорадиоизделий, дополнительные проверочные тесты, диагностического неразрушающего контроля и выборочного разрушающего физического анализа.
Обнаружение исходных однородных производственных партий электрорадиизделий из отгруженных партий является важных этапом во время тестирования [1].
Одной из наиболее известных моделей кластерного анализа является модель k-средних. Целью является нахождение k точек (центров) X 1 ,…X k в d -мерном пространстве, таких, чтобы сумма квадратов расстояний от известных точек (векторов данных) A 1 ,…,A N до ближайшей из искомых точек (центров) достигала минимума [3]:
argmin F ( X 1,..., Xk ) = ∑ i N = 1m in Xj - Ai II2 . (1)
В алгоритме k-средних необходимо первоначально спрогнозировать количество групп (подмножеств). Кроме того, полученный результат зависит от начального выбора центров. А также функция расстояния и ее определение играют важную роль в проблеме разделения исследуемого множества на группы.
Первый генетический алгоритм решения дискретной задачи p-медианы был предложен Хосейджем и Годшильдом [4]. Алгоритм [5] дает довольно точные результаты. Однако скорость сходимости целевой функции происходит очень медленно. В своей работе О. Алп, Э. Эркут, Ц. Дрезнер [6] представили более быстрый простой генетический алгоритм с особой процедурой рекомбинации, которая также дает точные результаты. Данные алгоритмы решают дискретные задачи. Авторы работы «Метод кластеризации на основе генетического алгоритма» [7] кодируют решения (хромосомы) в своих ГА как наборы центроидов, представленных их координатами (векторами действительных чисел) в многомерном пространстве.
Анализ литературы показал, что существующие решения в области АГ многомерных объектов обладают либо высокой точностью, либо обеспечивают стабильность результата при многократных запусках алгоритма, либо высокой скоростью работы, но не всеми этими качествами одновременно. На сегодняшний день разработаны алгоритмы k-средних и k-медиан лишь для наиболее распространенных мер расстояния (евклидово, манхэттенское). Однако, учет особенностей пространства признаков конкретной практической задачи при выборе меры расстояния может привести к повышению точности АГ объектов. В представленной работе в качестве меры точности кластеризации используем индекс Рэнда (Rand Index, RI) [8].
Улучшить результат АГ многомерных объектов с повышенными требованиями к точности и стабильности результата известными алгоритмами на текущий момент крайне трудно без значительного увеличения временных затрат. При решении практических задач АГ многомерных данных, например, при решении задач выделения однородных партий промышленной продукции, вопросы вызывает адекватность моделей и, как следствие, точность АГ промышленной продукции. Все же возможна разработка алгоритмов, обеспечивающих дальнейшее улучшение результата на основе выбранной модели, например, модели k-средних.
В многомерном пространстве признаков зачастую существует корреляция между отдельными признаками и группами признаков. Использование корреляционных зависимостей может быть задействовано путем перехода от поиска в пространстве с евклидовой или прямоугольной метрикой к поиску в пространстве с метрикой Махаланобиса [9-11]. Квадрат расстояния Махаланобиса D M определяется следующим образом:
D M ( X ) = ( X - µ ) TC - 1( X - µ ) (2) где X – вектор значений измеренных параметров, µ – вектор средних значений (например, центр кластера), С – ковариационная матрица.
Целью исследования в представленной работе является повышение точности и стабильности результата решения задач автоматической группировки объектов.
Идея работы состоит в том, чтобы использовать меру расстояния Махаланобиса c усредненной оценкой ковариационной матрицы в задаче k-средних для снижения доли ошибки АГ по сравнению с другими известными алгоритмами, а также задействовать оператор мутации в составе генетического алгоритма для повышения точности и стабильности решения по достигаемому значению целевой функции за фиксированное время выполнения по сравнению с известными алгоритмами разделения объектов.
Исходные данные . Исследование проведено на данных тестовых испытаний партий интегральных схем [12], предназначенных для установки в аппараты космического назначения, проведенных в специализированном центре технических испытаний. Данные представляют собой набор параметров электрорадиоизделий (ЭРИ). Исходная партия ЭРИ принадлежит разным однородным партиям, в соответствии с маркировкой производителя. Общее количество изделий составляет 3987 изделий. В каждой партии изделие описывается 205 измеряемыми параметрами. Партия 1 содержит 71 изделие, 116 изделий содержится в партии 2, 1867 в партии 3, 1250 в партии 4, 146 в партии 5, 113 в партии 6, 424 в партии 7.
Алгоритм k-средних с расстоянием Махаланобиса с усредненной оценкой ковариационной матрицы по обучающей выборке. Вычислительные результаты экспериментов по автоматической группировке промышленной продукции с моделями k-медоид и k-средних, в которых применена метрика Махаланобиса, показывают повышение точности кластеризации при автоматической группировке на 2-6 кластеров и малом количестве объектов и информативных признаков [13].
Предложено вместо ковариационной матрицы из (2) по обучающей выборке рассчитать усредненную оценку ковариационной матрицы для однородных партий изделий (по предварительно размеченным данным):
k
C = - Z j (3)
n j = 1
где n j - количество объектов (изделий) в j -й партии, n-общий размер выборки, C j -ковариационные матрицы отдельных партий изделий.
В данной работе предложен алгоритм автоматической группировки объектов, основанный на модели k-средних с подстройкой параметра меры расстояния Махаланобиса (ковариационной матрицы) по обучающий выборке:___________________________________ Алгоритм 1. k-средних с расстоянием Махаланобиса с усредненной оценкой ковариационной матрицы
Шаг 1. Методом k-средних с евклидовым расстоянием разделить выборку на некоторое число к кластеров (здесь к - некоторая экспертная оценка возможного числа однородных групп, не обязательно точная);
Шаг 2. Для каждого кластера рассчитать центр ц , . Центр определяется как среднее арифметическое всех точек в кластере
M i =~ Z Х л m j = 1
где m - количество точек, X j - вектор значений одного измеряемого параметра (j= 1 ..m );
Шаг 3. Рассчитать усредненную оценку ковариационной матрицы (3). Если усредненная оценка ковариационной матрицы является вырожденной, перейти к шагу 4, иначе перейти к шагу 5;
Шаг 4. Увеличить число кластеров на (к+1) и повторить шаги 1 и 2. Сформировать новые кластеры с квадратом евклидова расстояния:
n
D ( X, , ц ) = Z ( X ,- ц , )2 (5)
i = 1
где n - количество параметров. Вернуться к шагу 3 с новым обучающим примером (набором).
Шаг 5. Сопоставить каждую точку ближайшему центроиду, используя квадрат расстояния Махаланобиса (2) с усредненной оценкой ковариационной матрицы С (3) для формирования новых кластеров.
Шаг 6. Повторить алгоритм с шага 2, пока кластеры не перестанут изменяться.
В работе представлены результаты трех групп экспериментов по данным образцов промышленной продукции.
Первая группа. Обучающая выборка соответствует рабочей выборке, для которой проводилась кластеризация.
Вторая группа. Обучающая и рабочая выборки не совпадают. На практике в качестве обучающей выборки тестовый центр может использовать ретроспективные данные поставок и тестирования изделий того же типономинала.
Третья группа. Обучающая и рабочая выборка также не совпадает, но в качестве обучающей выборки использовались результаты работы автоматической группировки изделий (k-средних в режиме мультистарта с евклидовой метрикой).
В каждой из групп экспериментов для каждой рабочей выборки алгоритм к-средних запущен по 30 раз с каждой из пяти исследуемых моделей кластеризации.
Модель DM 1 – k-средних с расстоянием Махаланобиса, ковариационная матрица рассчитана для всей обучающей выборки.
Модель DС – k-средних с расстоянием, аналогичным расстоянию Махаланобиса, но используется корреляционная матрица вместо ковариационной матрицы.
Модель DM 2 – k-средних с расстоянием Махаланобиса, с усредненной оценкой ковариационной матрицы.
Модель DR – k-средних с манхэттенским расстоянием.
Модель DE – k-средних с евклидовым расстоянием.
Таблица 1
Результаты вычислительного эксперимента над данными микросхемы 1526IE10_002 (3987 векторов данных размерностью 68), обучающая выборка состоит из 10 партий, Третья группа, рабочая выборка составлена из 7 партий изделий)
|
Серия V |
индекс Рэнда (RI) |
Целевая функция |
||||||||
|
Модель |
Модель |
|||||||||
|
DM1 |
DС |
DM2 |
DR |
DE |
DM1 |
DС |
DM2 |
DR |
DE |
|
|
Max |
0,767 |
0,658 |
0,749 |
0,740 |
0,735 |
255886 |
379167 |
281265 |
18897 |
6494,62 |
|
Min |
0,562 |
0,645 |
0,696 |
0,703 |
0,705 |
250839 |
36997 |
274506 |
17785 |
5009,42 |
|
Average |
0,632 |
0,650 |
0,725 |
0,714 |
0,719 |
252877 |
37178 |
277892 |
18240 |
5249,95 |
|
Std .Dev |
0,047 |
0,003 |
0,016 |
0,008 |
0,006 |
1164,5 |
152,8 |
2358,9 |
452,7 |
366,5 |
|
V |
0,461 |
0,411 |
0,849 |
2,482 |
6,981 |
|||||
|
R |
5047 |
920 |
6759 |
1112 |
1485 |
|||||
Установлено, что новая модель DM2 с усредненной оценкой ковариационной матрицы показывает лучшую точность среди представленных моделей практически во всех сериях экспериментов по индексу Рэнда (RI) и во всех случаях превосходит модель DE, где используется евклидово расстояние. Также в экспериментах показано, что в большинстве случаев коэффициент вариации значений целевой функции выше для модели DE, где используется евклидова мера расстояния, а также, что коэффициент размаха значений целевой функции имеет самые высокие значения для модели DM2, где используется мера расстояния Махаланобиса с усредненной оценкой ковариационной матрицы. Следовательно, для получения устойчиво хороших значений целевой функции требуются множественные попытки запуска алгоритма k-средних или использование других алгоритмов, основанных на модели k-средних (например, j-means [14] или алгоритмов метода жадных эвристик [15]).
Генетический алгоритм с перекрестной мутацией для задачи k-средних . Новый алгоритм позволяет повысить точность решения задачи k-средних и стабильность результата за фиксированное ограниченное время выполнения. В данной главе под точностью алгоритма будем понимать исключительно достигнутую величину целевой функции, не учитывая показатели адекватности модели и соответствие результатов алгоритма фактическому (реальному) разделению объектов, если таковое известно.
Для генетических алгоритмов решения задачи k-средних с вещественным кодированием решений известно очень ограниченное множество возможных операторов мутации. Например, авторы работы «Метод кластеризации на основе генетического алгоритма» [7] кодируют решения (хромосомы) в своих ГА как наборы центроидов, представленных их координатами (векторами действительных чисел) в многомерном пространстве. Каждая хромосома подвергается мутации с фиксированной вероятностью д . Процедура (оператор) мутации заключается в следующем.
Алгоритм 2 3.1 Процедура исходной мутации ГА для задачи k-средних
Шаг 1 . Генерация случайного числа b е (0,1] с равномерным распределением;
Шаг 2.ЕСЛИ Ь<д, ТО хромосома мутирует. Если положение текущего центроида и, то после мутации оно становится:
и ^1
и ± 2 х bхи, и * 0,
и ± 2 х b ,
и = 0.
Знаки «+» и «-» имеют одинаковую вероятность. Координаты центроида смещены случайным образом.
В своей работе мы заменили эту процедуру мутации для задачи k-средних следующей процедурой.
Алгоритм 3 3.2 Процедура перекрестной мутации ГА для задачи k-средних
Шаг 1. Генерация случайного начального решения S = { X i ... X k };
Шаг 2. Применить алгоритм k-средних к S для получения локального оптимума S ;
Шаг 3. Применить простую перекрестную процедуру для мутированного индивида S из популяции и S для получения нового решения S’’ ;
Шаг 4. Применить алгоритм k-средних к S для получения локального оптимума S ;
Шаг 5.ЕСЛИ F ( S ”)< F ( S ' ), ТО S ' ^ S ”. _____________________________________________
Предложенная процедура используется с вероятностью мутации равной 1, после каждого оператора скрещивания.
Результаты запуска исходного алгоритма 2, описанного с вероятностью мутации 0,01, и его версия с алгоритмом 3 в качестве оператора мутации представлена на рисунке (численность популяции N pop = 20 ). Новая процедура мутации является быстрой и эффективной по сравнению с исходной мутацией генетического алгоритма, показана высокая скорость сходимости целевой функции.
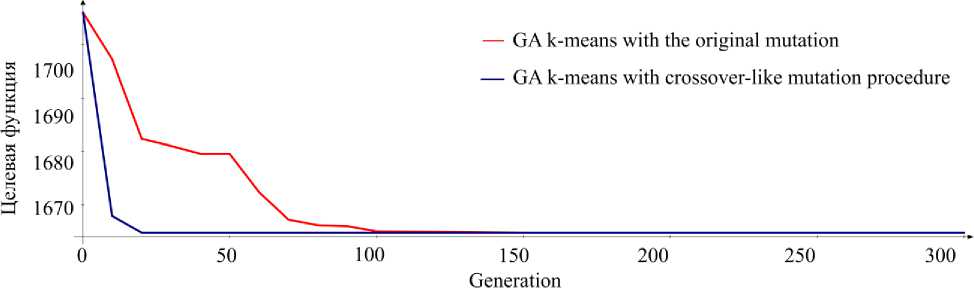
Результаты для набора данных Mopsi-Joensuu (6014 векторов данных размерностью 2), 300 кластеров, 3 минуты
Results for data set Mopsi-Joensuu (6014 data vectors of dimension 2), 300 clusters, time limition 3 minutes
Генетические алгоритмы метода жадных эвристик и многие другие эволюционные алгоритмы для задачи k-средних, обходятся без мутации. Идея жадной агломеративной эвристической процедуры заключается в объединении двух известных решений в одно недопустимое решение с избыточным числом центроидов и далее последовательно уменьшается количество центроидов. На каждой итерации удаляется центроид, который показывает наименьшее увеличение значения целевой функции (1).
Алгоритм 4. Базовая жадная агломеративная эвристическая процедура
Дано
: начальное число кластеров
K
, необходимое количество кластеров
k, k
ШАГ 1. Улучшить начальное решение алгоритмом k-средних
ПОКА K>k
ЦИКЛ для каждого i ' ∈ {1, K} выполнить:
ШАГ 2. S ' ← S { X '}. Улучшить решение S’ алгоритмом k-средних и сохранить соответствующие полученные значения целевой функции (1), как переменные F i ' ← F { X '}.
Список литературы Модели и алгоритмы автоматической группировки объектов на основе модели k-средних
- Orlov V. I., Kazakovtsev L. A., Masich I. S., Stashkov D. V. Algoritmicheskoe obespechenie podderz-hki prinyatiya reshenii po otboru izdelii mikroelektroniki dlya kosmicheskogo priborostroeniya [Algorithmic support of decision-making on selection of microelectronics products for space industry]. Krasnoyarsk, 2017, 225 p.
- Kazakovtsev L. A., Antamoshkin A. N. [Greedy heuristic method for location problems]. Vestnik SibGAU. 2015, Vol. 16, No. 2, P. 317-325 (In Russ.).
- MacQueen J. Some methods for classification and analysis of multivariate observations. Proc. Fifth Berkeley Symp. Math. Stat. Probab. 1967, Vol. 1, P. 281-297.
- Hosage C. M., Goodchild M. F. Discrete Space Location-Allocation Solutions from Genetic Algorithms. Annals of Operations Research. 1986, Vol 6, P. 35-46. http://doi.org/10.1007/bf02027381
- Bozkaya B., Zhang J., Erkut E. A Genetic Algorithm for the p-Median Problem, Drezner Z., Hamacher H. (eds,), Facality Location: Applications and Theory, Springer, Berlin, 2002.
- Alp O., Erkut E., Drezner Z. An Efficient Genetic Algorithm for the p-Median Problem. Annals of Operations Research. 2003, Vol. 122, P. 21-42. doi: 10.1023/A:1026130003508
- Maulik U., Bandyopadhyay S. Genetic Algorithm-Based Clustering Technique. Pattern Recognition. 2000, Vol. 33, No. 9, P. 1455-1465. doi: 10.1016/S0031-3203(99)00137-5
- William M. Rand. Objective Criteria for the Evaluation of Clustering Methods. Journal of the American Statistical Association. 1971, Vol. 66, No. 336, P. 846-850.
- De Maesschalck R., Jouan-Rimbaud D., Massart D. L. The Mahalanobis distance. Chem Intell Lab Syst. 2000, Vol. 50, No. 1, P. 1-18. doi: 10.1016/S0169-7439(99)00047-7
- McLachlan G. J. Mahalanobis Distance. Resonance. 1999, Vol. 4, No. 20. doi: 10.1007/BF02834632.
- Xing E. P., Ng A. Y., Jordan M. I., Russel S. Distance metric learning with application to clustering with side-information. Advances in Neural Information Processing Systems. 2003, Vol. 15, P. 505-12.
- Orlov V. I., Fedosov V. V. ERC clustering dataset, 2016. http://levk.info/data1526.zip
- Orlov V. I., Shkaberina G. Sh., Rozhnov I. P., Stupina A. A., Kazakovtsev L. A. [Application pf clustering algorithm wirh special distance measures for the problem of automatic grouping of electronic and radio devices]. Control systems and information technologies. 2019, Vol. 3, No. 3, P. 42-46 (In Russ.).
- Hansen P., Mladenovic N. J-means: a new local search heuristic for minimum sum of squares clustering. Pattern recognition. 2001, Vol. 34, No. 2, P. 405-413.
- Kazakovtsev L. A., Antamoshkin A. N. Genetic Algorithm with Fast Greedy Heuristic for Clustering and Location Problems. Informatica. 2014, Vol. 38, No. 3, P. 229-240.
