Модифицированное безопасное скалярное произведение в конфиденциальном кластерном анализе k-means с вертикальным секционированием данных

Автор: Жуков Вадим Геннадьевич, Вашкевич Алексей Вячеславович
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 4 (50), 2013 года.
Бесплатный доступ
Рассматриваются актуальные проблемы в разработке и применении протоколов обеспечения конфиденциальности вычислений в многостороннем кластерном анализе данных. Приведено общее описание конфиденциальных многосторонних вычислений, определена модель нарушителя. Представлены недостатки одного из существующих решений конфиденциального кластерного анализа методом k-means при вертикальном секционировании данных; предложены пути их устранения с помощью корректного применения криптографического примитива, реализующего безопасное скалярное произведение. Приведённый математический аппарат описывает все аспекты исходного протокола и детали его модернизации. Статья содержит сравнительный анализ усовершенствованного криптографического примитива с аналогом - безопасной суммой. Сформулированы выводы об эффективности усовершенствованного криптографического примитива безопасного скалярного произведения и рекомендации по применению разработанной модели.
Конфиденциальные многосторонние вычисления, криптографические примитивы, кластерный анализ k-means, вертикальное секционирование, безопасное скалярное произведение
Короткий адрес: https://sciup.org/148177141
IDR: 148177141 | УДК: 004.056
A modified secure dot product in the privacy-preserving k-means clustering with the vertical partitioning data
The authors consider the actual problems in the design and implementation of the privacy-preserving computations in the multiparty data clustering. There is a basic description of the secure multiparty computations and the definition of the adversary model in it. This article presents the flaws of existing solutions of the privacy-preserving k-means clustering over the vertically partitioned data, and proposed ways to eliminate these disadvantages by the correct using the cryptographic primitive realized secure dot product. The mathematical apparatus given in this article describes all aspects of the original protocol and the details of its modernization. The article has a comparative analysis of the advanced cryptographic primitive with its analog - secure sum. There are conclusions about the effectiveness of improved cryptographic primitive of the secure dot product and recommendations on application of the developed model.
Текст научной статьи Модифицированное безопасное скалярное произведение в конфиденциальном кластерном анализе k-means с вертикальным секционированием данных
При проведении совместного анализа данных, принадлежащих разным организациям (пользователям) и являющихся конфиденциальными, не всегда достаточно обеспечения той конфиденциальности, что достигается при помощи традиционных криптосистем; необходимо обеспечить получение совместного результата без раскрытия самих исходных данных [1]. Задачи такого вида называются конфиденциальными многосторонними вычислениями (КМВ) – используются специальные протоколы, позволяющие нескольким участникам произвести вычисления на основе конфиденциальных входных данных каждого из них. После выполне- ния протокола КМВ каждый из участников получает результат вычисления, но ни один из них не должен иметь возможность получения никакой дополнительной информации о данных других участников.
В алгоритмах конфиденциальной кластеризации используется модель с получестными (semi-honest) участниками. Получестный участник следует протоколу, но волен использовать ту информацию, к которой он имеет доступ во время выполнения протокола, для попытки раскрытия данных других участников. При этом рассматривается возможность сговора (т. е. объединения знаний) некоторых из участников [2].
Работа поддержана грантом Президента молодым кандидатам наук, договор № 14.124.13.473-МК от 04.02.2013.
|
Участник №1 |
Участник №2 |
Участник №3 |
|||
|
Атрибут №1 |
Атрибут №2 |
Атрибут №1 |
Атрибут №1 |
Атрибут №2 |
Атрибут №3 |
Рис. 1. Пример вертикального секционирования
На первом этапе исследований по применению КМВ в кластерном анализе рассматривался алгоритм, позволяющий работать с большими объемами данных и имеющий простую структуру. Наиболее распространенным и изученным алгоритмом кластерного анализа, удовлетворяющим предъявляемым требованиям, является алгоритм k-means.
Данные для многостороннего кластерного анализа могут быть по-разному распределены между участниками. Существует вертикальное (участники содержат разные столбцы данных), горизонтальное (участники содержат разные строки данных) и арбитральное (произвольное) секционирования данных. В вертикальном секционировании данных (рис. 1) каждый участник имеет набор только некоторых атрибутов, но каждого из объектов. При таком секционирование начальный выбор центров кластеров не является конфиденциальным, а защищаются такие шаги k-means, как вычисление расстояний между каждой точкой и центрами, выбор минимального расстояния для каждой точки, а также проверка условия остановки кластерного анализа.Алгоритм конфиденциальной кластеризации методом k-means при вертикальном секционировании:
Требуется: r участников, k кластеров, n точек.
-
1: для всех участников j = 1, ..., r
-
2: для всех кластеров i = 1, ..., к
-
3: произвольная инициализация центров
кластеров ц ' j
-
4: повторять
-
5: для всех участников j = 1, ..., r
-
6: для всех кластеров i = 1, ..., к
-
7: Ц у =Ц ' у
-
8: кластер [ i ] = 0
-
9: для всех точек g = 1, ..., n
-
10: для всех участников j = 1, ..., r
-
11: {Вычисление вектора X j от точки g
до каждого центра кластера по измерению j }
-
12: для всех кластеров i = 1, ..., к
-
13: xij = |данные точки gj –
данные центра кластера Ц у |
-
14: каждый участник помещает g в кластер
[ближайший] {алгоритм определения ближайшего кластера должен сохранять конфиденциальность}
-
15: для всех участников j = 1, ..., r
-
16: для всех кластеров i = 1, ..., к
-
17: ц ' у - среднее всех точек кластера [ i ]
по атрибуту j
-
18: пока не выполнится условие останова {алгоритм проверки условия останова должен сохранять конфиденциальность}
За основу для модернизации [3] взята схема конфиденциального кластерного анализа k-means при вертикальном секционировании, предложенная Саметом и соавторами [4], так как в отличие от других решений для данного секционирования в ней отсутствуют так называемые «особые» участники, выполняющие дополнительные операции с данными.
Обозначим набор атрибутов, содержащихся у Pi (участника под номером i ), как
A i = { a i 1 , a i 2 , ..., a im } . Также P i владеет наборами атрибутов каждого из центров кластеров ц j7 = { ц j7 1 , ц j7 2 , ..., ц j im } . Затем каждый участник суммирует расстояния между соответствующими измерениями. Так, порция расстояния между точкой и центром кластера ц ji у участника P i будет выглядеть следующим образом (пример для квадрата евклидового расстояния):
dji = ( ai 1 — ц ji 1) + ( ai 2 — ц ji 2 ) + - + ( aim - ц jim )
Просуммировав по всем участникам эти расстояния, получим dj 1 + dj2 +... + djr, где r - число участников. Для центра другого кластера цq имеем похожую формулу dq 1 + dq2 +... + dqr. Чтобы определить, какой из кластеров ( j или q ) ближе к точке, нужно rr просуммировать значения Z (dji- dqi)= ^ di . Если i=1 i=1
результат положительный, цq будет ближе к точке, иначе ближе ц j. Этот шаг повторяется k -1 раз, чтобы найти минимальное из расстояний от точки до центра кластера. При этом ни одно из расстояний не раскрывается.
Однако реализация данной схемы Саметом и соавторами имела два существенных недостатка, которые обязательно требовалось устранить:
– для двух участников применялся криптографический примитив «безопасное скалярное произведение» [5], предложенный Малеком и Мири;
– для участников количеством более двух применялся примитив «безопасная сумма» [6], в котором раскрываются данные любого из участников при сговоре его соседей по алгоритму.
Схема применения Саметом и соавторами криптографического примитива «Безопасное скалярное произведение»:
0) Участник P 1 имеет конфиденциальное значение d j 1 — d q i = d 1 , а P 2 имеет конфиденциальное значение d j 2 — d q 2 = d 2 , требуется получить числа 1 1 и l 2 такие, чтоб 1 1 хранился у P 1 , l 2 у P2 и 1 1 • l 2 = d 1 + d 2;
-
1) P 1 генерирует случайное ненулевое число l 1 и
- | dl 1 |
создаёт вектор X = —,— , а р создаёт вектор I l i l i )
Y = ( 1; d 2 ) ;
-
2) P 1 и P 2 выполняют безопасное скалярное произведение [5] и P 2 получает число l 2 такое, что 1 1 • l 2 = d 1 + d 2.
-
3) P2 посылает знак 1 2. Если 1 2 = 0, то до обоих кластеров одинаковое расстояние, если l 2 * 0 , то знак показывает кластер, до которого расстояние меньше.
Формальное описание протокола безопасного скалярного произведения:
Предположим, что у двух участников (назовем их Алисой и Бобом) есть по n -мерному вектору: x = { x 1 , x 2 , -> x n } - у Алисы и y = { У 1 , y 2 , ..., У п } -у Боба. Каждое измерение вектора является конечным полем Fp , а пространство векторов – конечным n -мерным расширением Fp n конечного поля Fp .
Алиса и Боб хотят совместно и с сохранением конфиденциальности посчитать x • у . Результат протокола должен быть известен только Алисе. Входные данные каждого из участников не должны быть раскрыты друг другу. Для достижения этих целей Алиса и Боб выполняют следующий протокол:
-
1. Алиса генерирует случайные вектор фе Fpn и числа a , b , c , d е Fp такие, что ( ad - bc ) 1 * 0 е Fp . Алиса вычисляет следующие векторы:
-
2. Затем Алиса посылает векторы u и v Бобу.
3. Алиса вычисляет
u = ax + b ф,
v = cx + dф .
Зная свой вектор y , Боб вычисляет у • u и y • v. За- тем Боб отправляет результаты обратно Алисе.
(ad -bc) 1 (d(y • u)-b(y • v)), что эквивалентно x • y .
Следует отметить два момента, из-за которых применение данной схемы некорректно. Первым таким моментом является то, что примитив Малека и Мири предназначен для конечных полей. Таким образом, нельзя после выполнения примитива использовать знаки чисел l1 и l2 для достоверного определе- ния знака суммы d1 + d2.
Пример, доказывающий данное утверждение:
Есть конечное поле
-
{ - 5, - 4, - 3, - 2, - 1, 0, 1, 2, 3, 4, 5 } . d 1 = - 1, d 2 = - 2 .
Допустим, l 1 = 2. Тогда после проведения безопасного скалярного произведения будет получено 1 2 = 4 , так как в данном конечном поле 2 • 4 = - 1 - 2 .
Знаки чисел l1 и l2 оба положительные, а знак суммы отрицателен. Следовательно, данный протокол не всегда работает в конечных полях.
Таким образом, использование знаков после операций в конечных полях не всегда будет давать корректный результат. Данный недостаток устраняется использованием множества вещественных чисел вместо конечных полей. При этом все операции безопас- ного скалярного произведения сохраняют корректность. Данное решение также имеет полезность в том, что использование конечных полей ухудшает точность проведения кластерного анализа, так как необходимо было бы «накладывать» область допустимых значений на конечное поле, что породило бы погрешность из-за необходимости квантования.
Вторым моментом, из-за которого некорректно применение предложенной Саметом и соавторами схемы, является использование двумерных векторов
( 1; d 2 ) и
' d , ;1 ^ 1 1 1 l 1 J
. Анализ криптографического при- митива показал, что использование двумерных векторов раскрывает данные Боба Алисе. Причина в шаге 2 криптографического примитива, когда Боб посылает Алисе результаты скалярных произведений y • u и y • v. Алиса, таким образом, получает два уравнения с двумя неизвестными:
y 1 u 1 + y 2 u 2 = y • u ,
y1 v1 + у 2 v 2 = у • v , где векторы u и v уже известны Алисе, а результаты скалярных произведений y • u и y • v она получила от Боба. Решив эти уравнения, Алиса вычисляет значе- d1
ния и , откуда узнает d , т. е. косвенные сведе- l 1 l 1 1
ния о данных Боба ( d j 1 - d q 1 , разница между расстояниями от точки до одного кластера и до другого) становятся известны Алисе и, следовательно, нет обеспечения конфиденциальности данных одного из участников кластерного анализа.
Эту проблему можно решить, искусственно разбив два измерения векторов (1;d2) и —;—I на три. По-х I li 11)
сле разбиения векторы будут выглядеть следующим образом:
-
- вектор Алисы ( 1;1; d 2 ) ,
– вектор Боба
d1 + z _ - z _ 1 | v l1 к к J где z – случайное число, сгенерированное Бобом. Скалярное произведение данных векторов останется прежним, но теперь в двух уравнениях станет три не-
_ d + Z - z 1 _ _ _ известных: 1 , и , из которых «любопыт-l1 l1 l1
ному» (согласно модели нарушителя) участнику Алисе в общем случае будет нельзя получить значение d 1 Боба. Однако при определенных параметрах векторов u и v раскрытие информации все-таки останется возможным, поэтому Боб должен проверять присланные ему от Алисы векторы u и v на следующие условия (они могут выполняться по отдельности, но не одновременно):
u1 = u 2, v1 = v2
потому что при выполнении обоих этих условий из уравнений можно будет узнать отдельно di + z | - z | 1
--+ — I и —, а значит, получить
-
l 1 V l 1 J l 1
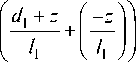
Также следует отметить, что безопасное скалярное произведение проводится для двух участников. При использовании этого примитива для нескольких участников следует применять схему, также описанную у Самета и соавторов. Пример для трёх участников:
-
1. P 3 дробит своё значение d 3 на случайные кусочки d 31 и d 32 такие, что d 31 + d 32 = d 3 , и выбирает случайное число r3 * 0.
-
2. P 3 и P 1 выполняют SDP, и P 1 получает s 1 такое, что d 31 + d 1 = r 3 • s 1 .
-
3. P 3 и P 2 выполняют SDP, и P 2 получает s 2 такое, что d 32 + d 2 = r 3 • s 2 .
-
4. P 2 и P выполняют SDP для получения S 1 + s 2 .
-
5. На выходе получается:
-
6. Если r 1 = 0, P 1 рассылает всем флаг, что расстояния до кластеров одинаковые, иначе он посылает знак r 1 участнику P 2 , тот умножает знак r 1 на знак r 2 и посылает участнику P 3 . Участник P 3 умножает полученный знак на знак r 3 и узнает, какой из кластеров ближе к точке, а затем рассылает всем.
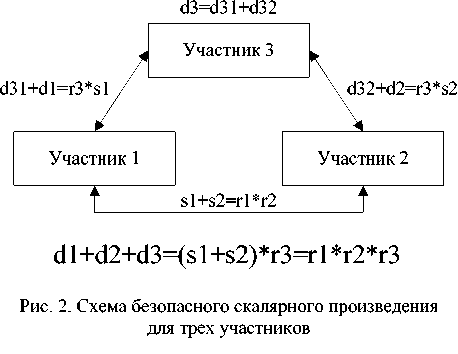
d 1 + d 2 + d 3 = r3 • ( S j + s 2 ) = r 1 • r2 • r3 (рис. 2).
Причем участник Pi знает только di и ri .
Основной минус данного алгоритма в том, что количество данных, передаваемых по сети, растёт пропорционально квадрату количества участников. Именно по этой причине алгоритм не подходит для кластерного анализа с большим количеством участников и обрабатываемых данных, поскольку он применяется на каждой итерации для каждого объекта данных к — 1 раз.
В связи с проектированием программного обеспечения, реализующего данный протокол, стало возможно сравнить сетевой трафик (рис. 3), генерируемый алгоритмом с использованием того или иного криптографического примитива.
Тем не менее, если к конфиденциальности предъявляются жёсткие требования, следует применять примитив «безопасное скалярное произведение», поскольку в нём гарантируется сохранение конфиденциальности даже при сговоре против одного из участников всех остальных (рис. 4).
Таким образом, устранив недостатки схемы по применению безопасного скалярного произведения, можно использовать данный криптографический примитив для определения ближайшего кластера. Однако применение безопасного скалярного произведения требует передачи данных от каждого участника каждому, что при большом количестве участников и большом количестве объектов данных приведет к большому объему трафика. Поэтому использование безопасного скалярного произведения рекомендуется к применению для малого количества объектов данных или участников, когда велик риск сговора и на первый план выходит обеспечение конфиденциальности данных в ущерб скорости работы алгоритма.
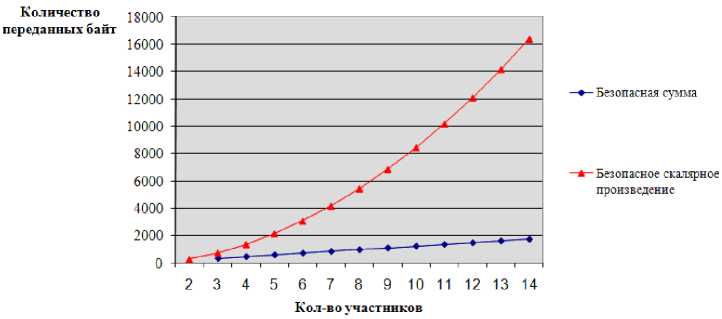
Рис. 3. Зависимость количества переданных байт за одну операцию сравнения расстояний от количества участников
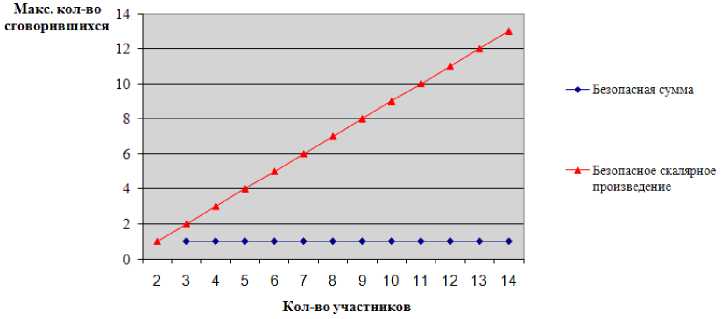
Рис. 4. Зависимость максимального допустимого количества сговорившихся участников от общего количества участников
