Модифицированный алгоритм HITS

Автор: Зеленков Павел Викторович, Сидорова Галина Александровна
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 2 (35), 2011 года.
Бесплатный доступ
Показана проблема современных поисковых систем, связанная с ранжированием документов. Для решения данной проблемы в процессе поиска и обработки информации предлагается использовать модифицированный алгоритм HITS. Данный подход помогает решать проблемы поиска, определения релевантности найденной информации, а также производить ранжирование отклика системы.
Ранжирование, обработка информации, поиск информации
Короткий адрес: https://sciup.org/148176548
IDR: 148176548 | УДК: 62-506.1
Modificated HITS algorithm
In this paper the problem of modern search systems connected with documents ranking is shown. To solve this problem it is proposed to use the modified algorithm HITS in the process of searching and processing information. This approach helps to solve the problems of search, relevance determination of the information and also to rank system response.
Текст научной статьи Модифицированный алгоритм HITS
В настоящее время при создании и развитии технологий сбора и обработки информации основное внимание удаляется развитию существующих технологий, нацеленных на анализ баз данных поисковых сервисов сети Интернет, и развитию алгоритмов ранжирования [1; 2]. Однако если встает вопрос об организации подобных процедур в рамках локальных корпоративных систем, то возникает проблема в анализе информации и ее взаимосвязей на локальном уровне.
На сегодняшний день существует множество алгоритмов ранжирования информации в поисковых системах сети Интернет [3]. Один из самых распространенных – это алгоритм Клейнберга, для которого создано несколько модификаций. Наиболее значимым является метод HITS, который заключается в присвоении каждому документу в веб-множестве некоторых значений, которые называются весами документа. Существует два вида таких весов: a (authority) – вес авторитетного документа и h (hub) – вес хаб-документа. Авторитетный документ – это документ, соответствующий запросу пользователя, имеющий больший удельный вес среди документов данной тематики, т. е. большее число документов ссылается на данный документ. Хаб-документ – это документ, содержащий много ссылок на авторитетные документы. Соответственно, для каждой страницы рассчитывается не один, а два веса. Такой подход обусловлен наличием в Сети большого числа сообществ, т. е. наборов страниц близкой тематики, которые весьма сильно связаны друг с другом ссылками. Исходя из значе- ний весов, происходит формирование множества поиска и его ранжирование по релевантности.
Такой подход очень удобен, так как позволяет находить больше документов, соответствующих заданной тематике. Однако у него есть и недостатки, которые естественным образом вытекают из достоинств: во множество найденных документов может попасть большое количество страниц с низким коэффициентом релевантности, которые, тем не менее, имеют много ссылок друг на друга, и именно им будут присвоены наивысшие ранги. Это явление называется смещением тематики (diffusion, drift). Обычно оно происходит в направлении более широкой предметной области (или лучше представленной в Сети). Для решения этой проблемы Клейнберг предложил использовать анализ содержимого страниц, но оценивать не отдельные страницы, а разные сообщества целиком.
Описание модифицированного метода. Модифицированный метод может быть полезен для поиска как в корпоративных информационно-управляющих системах, так и в локальных и глобальных сетях. Основа метода – избирательный поиск не по всему веб-пространству, а по документам, принадлежащим внутренней сети.
Его очень удобно использовать в организациях, специализирующихся на узкой тематике и имеющих обширную базу данных. Разработанная на базе этого метода поисковая система будет не только обрабатывать нужные документы, но и производить пополнение внутренней базы документами смежной тематики, найденными в Сети.
Рассмотрим предлагаемый метод подробнее. Для этого введем обозначения: { W } – множество документов Сети; { K } – множество документов сети (корпоративной, локальной).
Каждое множество содержит конечное число элементов. Пусть W содержит N элементов, а K содержит M элементов, причем M < N . Тогда каждый документ можно представить в одном из следующих видов:
d i e W ,1 < i < N , если документ принадлежит Сети;
d j e K ,1 < j < M , если документ принадлежит локальной сети.
Особо ценными для корпоративных сетей являются документы вида d j e K / W , т. е. внутренние документы корпоративной сети.
Поиск документов производится по объединению этих множеств, т. е. по W U K (рис. 1).
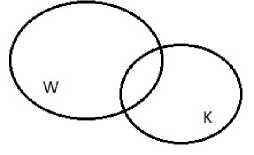
Рис. 1. Множество поиска
На множестве поиска строим граф G , называемый графом поиска. Для этого выделим множество документов R , которое представляет собой множество вершин графа G , и множество A ссылок между документами, которое является множеством ребер графа G . Таким образом, граф G [ R , A ] – граф поиска, в котором можно выделить подграф G′ [ R′ , A′ ], где R′ – множество документов, принадлежащих локальной сети, т. е. элементами которого являются документы вида d j e K ,1 < j < M ; A' - множество входящих и исходящих ссылок, принадлежащих документам из R′ (рис. 2).
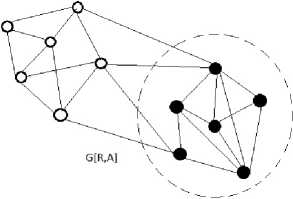
G'[R',A']
Рис. 2. Граф поиска
Ссылки в документах встречаются двух типов – входящие и исходящие. Количество входящих ссылок определяет авторитетный документ, количество исходящих ссылок определяет хаб-документ. Рассчитаем формулу для вычисления весов. Если вершина U является хаб-документом, а вершина V – авторитетный документ, то U ^ V; U, V e G [R, A]. Пусть на доку- мент V ссылается n хаб-документов, тогда Ui ^ V; Ui, V e G [R, A], i = 1...n. Аналогично формуле из метода HITS, вес авторитетного документа V вычисляется следующим образом:
n
A(V) = aV ^ H(Ui),
i = 1
U,^ V где H(Ui) – веса хаб-документов Ui, i = 1…n; aV – индекс сети, который мы приняли равным 1, в случае если документ V не принадлежит внутренней сети, 2 – если документ V принадлежит внутренней сети, т. е.
-
1, если V e W / K , aV = -
-
2, если V e K .
Таким образом, веса авторитетных документов, принадлежащих внутренней сети, будут в два раза выше, чем веса внешних авторитетных документов. Иными словами, релевантность документов сети будет выше, что позволит экономить внешний трафик и значительно увеличит скорость работы корпоративной сети.
Веса хаб-документов вычисляются через веса авторитетных документов. Пусть хаб-документ U ссылается на m авторитетных документов, т. е. U ^ V j ; U , V j e G [ R , A ], j = 1... m .
Тогда вес документа U вычисляется по формуле
m
H(U) = aV У A(Vj), j=1
U ^ vj где A(Vj) – веса авторитетных документов Vj, j = 1...m; aV – индекс сети.
Для каждого документа рассчитываются два веса: вес документа как первоисточника (авторитетный вес) и вес документа как посредника (хаб-вес). Документы, принадлежащие внутренней сети, после ранжирования будут иметь приоритетный ранг по сравнению с документами Сети, что позволит пользователю просматривать их в первую очередь.
Этапы работы модифицированного алгоритма. Модифицированный алгоритм HITS работает аналогично алгоритму, созданному Клейнбергом.
На первом этапе происходит составление корневого множества документов, релевантных запросу – Root Set. Для этого производится поиск по ключевым словам в базе данных информационно-управляющей системы и из ответа извлекается k первых результатов. Возьмем k ≤ 200 и рассмотрим процесс формирования Root Set (рис. 3).
На втором этапе к страницам из Root Set добавляются их ближайшие соседи, т. е. те страницы, на которые ссылаются страницы из Root Set, и те, которые сами имеют ссылки на страницы Root Set. Для поиска последних также используется поисковая система, причем берется не более d входящих ссылок на одну страницу. Так строится Base Set.
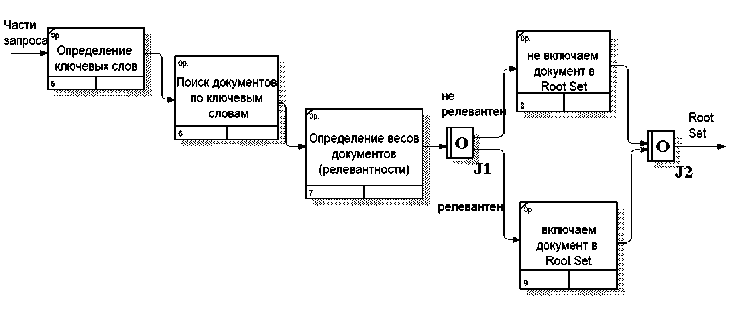
Рис. 3. Формирование Root Set
На третьем этапе к множеству Base Set применяется метод, приведенный выше, т. е. происходит построение графа поиска и вычисление весов документов. В качестве модификации предлагаемого метода выступает индекс сети aV . Зачастую в Сети встречаются страницы, имеющие высокие авторитетные и хаб-веса, но содержащие мало информации по искомой тематике. Это могут быть рекламные страницы либо страницы с искусственно завышенным рейтингом. Модифицированный метод помогает избежать попадания таких страниц в список найденных документов.
Ранжирование множества документов Base Set с помощью предложенного метода показано на рис. 4. Вычисление весов документов (процессы 16 и 17), согласно их принадлежности сети, происходит по следующим формулам:
nm a v = 2, A(V ) = 2 £ H(U^, H(U ) = 2 £ A(V j );
i = 1 j = 1
Ui ^ V U ^ Vj nm aV = 1, A(V) =£ H(Ui) H(U) =£ A(Vj).
i = 1 j = 1
U i ^ V U ^ V j
Таким образом , веса документов корпоративной сети будут иметь приоритетный коэффициент реле вантности относительно документов из Сети . Это по зволит пользователю находить более информативные документы , которые из - за невысокого рейтинга игно рируются другими поисковыми системами .
Модифицированный метод предназначен для об работки информации в корпоративных информацион - но - управляющих системах . На данный момент он ис пользуется в разработке демонстрационного прототи па корпоративной информационно - управляющей сис темы . Первые экспериментальные результаты работы модифицированного метода ожидаются в сентябре 2011 г . По теоретическим данным , метод снижает за груженность корпоративного интернет - трафика при поиске и обработке информации . Снижение внешнего интернет - трафика достигается благодаря формирова нию статистики наиболее часто используемых доку ментов и пополнению корпоративной базы данных согласно запросам пользователя . Кроме того , данный метод позволяет повысить ранг внутренних корпора тивных документов по сравнению с внешними , а тем самым – достоверность и , как следствие , качество ре зультирующей информационной выборки .
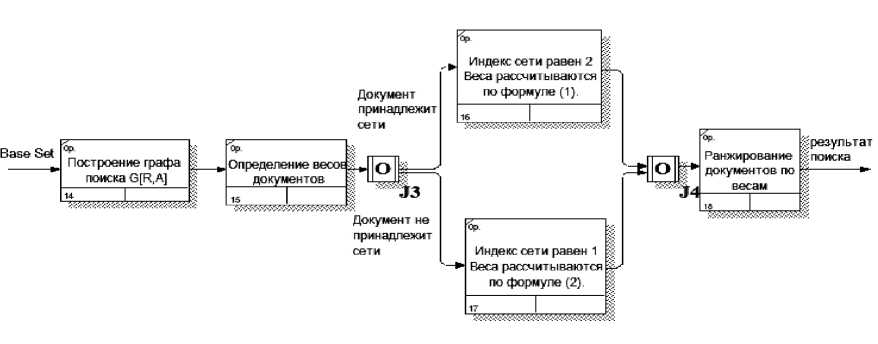
Рис . 4. Ранжирование
