Modified CNN Model for Network Intrusion Detection and Classification System Using Local Outlier Factor-based Recursive Feature Elimination

Author: Kondru Mounika, P. Venkateswara Rao, Anand Anbalagan
Journal: International Journal of Computer Network and Information Security @ijcnis
Article in issue: 1 vol.17, 2025.
Free access
An intrusion detection system (IDS) is either a part of a software or hardware environment that monitors data and analyses it to identify any attacks made against a system or a network. Traditional IDS approaches make the system more complicated and less efficient, because the analytical properties process is difficult and time-consuming. This is because the procedure is complex. Therefore, this research work focuses on a network intrusion detection and classification (NIDCS) system using a modified convolutional neural network (MCNN) with recursive feature elimination (RFE). Initially, the dataset is balanced with the help of the local outlier factor (LOF), which finds anomalies and outliers by comparing the amount of deviation that a single data point has with the amount of deviation that its neighbors have. Then, a feature extraction selection approach named RFE is applied to eliminate the weakest features until the desired number of features is achieved. Finally, the optimal features are trained with the MCNN classifier, which classifies intrusions like probe, denial-of-service (DoS), remote-to-user (R2U), user-to-root (U2R), and identifies normal data. The proposed NIDCS system resulted in higher performance with 99.3% accuracy and a 3.02 false alarm rate (FAR) as equated to state-of-the-art NIDCS approaches such as deep neural networks (DNN), ResNet, and gravitational search algorithms (GSA).
Network Intrusion Detection and Classification, Convolutional Neural Network, Recursive Feature Elimination, Local Outlier factor, Denial-of-service
Short address: https://sciup.org/15019628
IDR: 15019628 | DOI: 10.5815/ijcnis.2025.01.07
Text of the scientific article Modified CNN Model for Network Intrusion Detection and Classification System Using Local Outlier Factor-based Recursive Feature Elimination
1. Introduction and Related Works
An IDS is an advanced network security monitoring system that can identify any newly formed malicious activity. In addition, modern network security design necessitates an IDS environment [1]. For the most part, an IDS's job is to check every single packet that enters and leaves a network for any indication of an attack. An efficient IDS may either automatically write to security logs or issue warnings, depending on the nature of the bulk of incursion activity [2]. Differentiating IDSs by their principal detection mechanism is conceivable, with malware detection [3, 4] and anomaly detection being two examples. Malware detection relied on a knowledge-based detection method, whereby the user had to first identify the intrusion's characteristics before applying detection criteria. This technique for detecting misuse is very accurate and seldom returns false positives. However, before it can recognize novel threats, a feature library must be constructed [5]. Nevertheless, anomaly detection uses a technique based on observable behavior. To determine whether actual behavior deviates from what would be expected, it is necessary to first learn the network's characteristic behaviors.
To effectively identify anomalies in a network, it is necessary to first understand how the network typically operates. So, despite the high likelihood of false positives, it can discover risks that were previously unknown. IDSs are having a harder time than ever before as network architectures get more complex and intrusion techniques evolve to keep up. Anomaly-based detection is used to defend against zero-day or unknown threats [6] without requiring any changes to the existing infrastructure. Yet, a lot of false positives might come from using this method. Combining two or more forms of intrusion detection is what is meant by the term "hybrid-based detection." This is done so that the problems of using just one type of intrusion detection are avoided while also making the most of the benefits of utilizing two or more. There are three distinct methods that are used by the IDS in order to identify attacks. These methods include hybrid-based detection [7], anomaly-based detection [8], and signature-based detection [9]. Signature-based detection is meant to identify known attacks by using the signatures of such attacks in the investigation process. It performs quite well when attempting to detect pre-loaded known attacks included inside the IDS database. Because of this, it is often considered to be far more accurate in determining whether an attempt at intrusion or a recognized attack has occurred. Intrusion detection is a method that involves actively monitoring actions that are taking place inside a computer system or network, evaluating those activities to look for indications of possible issues, and restricting unauthorized access when necessary [10].
In many cases, this is accomplished by the automated collection of data from a variety of systems and network sources, followed by the analysis of the data to identify any possible security problems. Several research papers have proposed several machine learning algorithms for intrusion detection [11], with the goals of reducing the number of false positives and providing more accurate IDS. When working with Big Data, the traditional methods of machine learning, on the other hand, take a significant amount of time to learn and classify the data. The traditional challenges [12] faced by IDS, such as processing time and speed are circumvented using big data strategies and machine learning to build accurate IDS. The conventional methods are incapable of distinguishing between the various forms of attack.
The following is a list of the primary goals of this work:
-
• Development of hybrid NIDCS to detect the R2L, DoS, Probe, U2R attacks and normal class.
-
• Development of LOF detection, which is a density-based technique, identifies outliers and anomalies by
comparing the deviation of one data point in relation to its neighbors. This allows for the location of the outliers and anomalies.
• Implementation of RFE based forward feature selection, which does the opposite: accrete features rather than eliminate them, usually via greedy algorithm.
• Applying MCNN for classification of various classes and improved the individual class and overall attack detection performance.
2. Review of Previous Studies
3. Proposed Method
The rest of this article is divided as follows: In Section 2, we cover the important efforts of many distinct IDS models. In Section 3, we detail the architecture and implementation of the proposed NIDCS. In Section 4, we provide simulation results for the proposed method and compare them to existing state-of-the-art approaches in terms of performance. Section 5 offers some conclusions and directions for further research.
This section contains the related works of various existing IDS models. Authors suggested a broad AI-based NIDS technique in [13]. NIDS was first created using ML and DL techniques. Additionally, the NIDS included three main phases: the data processing phase, the training phase, and the testing phase. The taxonomy scheme of the intrusion detection system was proposed in [14] by the authors. In the beginning, taxonomy of IDS uses data objects as the primary dimension to categorize and compile IDS literature that is based on deep learning and machine learning. However, they resulted in poor classification performance due to the lack of relevant feature extraction. Authors suggested evaluating classification techniques for IDS in [15]. The first step is to evaluate the performance of various classification algorithms using various metrics. The active learning for instruction detection systems was suggested by authors in [16]. A load balancing technique that maximizes sensor usefulness utilizing sensor computing capabilities and sources is first required for intrusion detection, which may monitor the attack on the network. However, these approaches involved in detection of intrusion, but they have not addressed the classification of detected intrusion i.e., the type of intrusion.
The NIDS based on active semi-supervised learning was suggested by authors in [17]. In fact, sparse representations of features are learned using smoothed regularization. In [18], authors developed an automated detection methodology for spotting incoming aberrant traffic patterns that typically uses machine learning methods that are frequently used. To create an intelligent IDS, authors in [19] suggested the high ranking-based optimized ensemble learning model (HR-OELM), which makes use of three separate classifiers. The benchmark datasets are first collected during the first step of data collecting. But these NIDS methods failed to classify multiple classes of intrusions. A hybrid naive bayes and decision table technique-based signature-based intrusion detection model was suggested by authors in [20]. The first step in evaluating the recommended method's contribution is to contrast it with the body of prior research in the area. In [21], authors suggested an IDS based on deep neural networks and sparse autoencoders. To start, use smoothed regularization to guarantee the autoencoder's sparsity. Furthermore, attacks were predicted and classified using DNN. However, DNN is suffering with overfitting, and dropout issues, which may lead to reduced accuracy.
In [22], scientists suggested employing hybrid intelligent systems to detect network breaches. These blacklist-based traditional approaches are initially unable to forecast most phishing websites since they are continually being created and released on the Internet. Authors suggested an IDS in [23] to recognize different threats for IoT networks. In the beginning, essential IoT network properties are extracted using a mix of particle swarm optimization and grey wolf optimization. Machine learning algorithms for intrusion detection were first out by authors in [24]. Initially, a sizable number of methods that are based on machine learning strategies have been established. Additionally, each attack is supplied with attack categorization and a mapping of the attack properties.
Authors suggested the NIDS utilizing neural networks in [25]. To construct a NIDS, this technique first compares multi-layer preceptor and radial basis function networks. Finally, the benchmark NSL KDD dataset uses the multi-layer perceptron. An IDS based on a residual network (ResNet) that has been simplified was presented in [26]. Additionally, the experimental findings on NSL-KDD dataset demonstrate that the S-ResNet-based IDS outperforms the equal scale ResNet-based. However, it is still required to implement feature selection-based modified deep learning techniques for NIDS. The combination of effective feature selection strategies suggested by authors in [27]. The suggested method is initially based on a centralized intrusion detection system, which trains the model for identifying hostile and abnormal behaviors in the traffic using deep feature abstraction. In [28], authors suggested employing ensemble learning and several classifiers to identify computer network intrusions. They first built three distinct classifier types: logistic regression, decision trees, and neural networks. Additionally, they use ensemble learning to improve the intrusion detection algorithm's overall performance. But the computational complexity is quite higher due to the ensemble nature.
A hybrid method and feature selection were suggested by the authors in [29] for NIDS, which is utilized to find irregularities in network traffic. Determining whether incoming network traffic is abnormal or genuine is another problem with network anomaly detection. Based on an ideal hybrid kernel extreme learning machine, the authors of [30] proposed an intrusion detection system. The HKELM parameters are first optimized using a hybrid of the genetic algorithm (GSA) and the differential evolution (DE) technique. As a result, the system is better able to optimize on a global and local scale during prediction attacks. For this purpose, no method exists that uses feature selection in tandem with MCNN to classify a wide variety of network attacks. In [31] authors introduced the Synthetic Minority Oversampling Technique (SMOTE) data balancing method for maintaining the equal number of records in each class. Further, the Gradient-Boosted Decision Tree (GBDT) model was trained with the SMOTE balanced features. However, the intrusion recognition performance of this approach must be improved.
NIDSs are crucial components of any cyber security strategy in the face of increasingly sophisticated cyberattacks on computer networks. Researchers now invest significant effort and resources into creating NIDS powered by deep learning. Training and evaluating deep learning-based NIDS requires access to high-quality, large-scale datasets. In Figure 1, shows the block representation of the proposed NIDCS procedure. Initially, the NSL-KDD dataset is given a thorough cleaning by means of the dataset preprocessing. The dataset is then balanced with the assistance of the LOF, which locates anomalies and outliers by comparing the amount of deviation that a single data point has with the amount of variation. This allows the LOF to identify anomalies and outliers. After that, a method of feature extraction selection known as RFE is used to get rid of the features that are the least useful up until the point where the required number of features is reached. In the last step, the ideal features are trained using the MCNN classifier, which is responsible for identifying normal data as well as classifying intrusions such as probe, DoS, R2U, and U2R.
-
3.1. Preprocessing
-
3.2. LOF Detection
The raw NSL-KDD dataset had noises and missing values, which made it more challenging to train the MCNN model. It will reduce the accuracy of classification and forecasting. Thus, data preparation is performed to get around these problems. Unknown symbols and missing values will be filled in with their closest-matching known symbols and values during the preprocessing step.
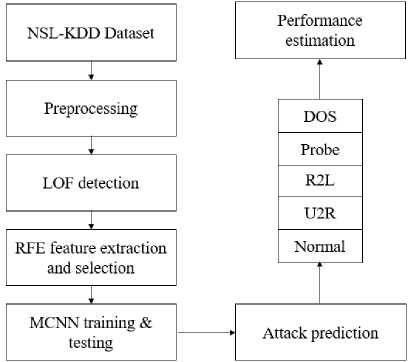
Fig.1. Proposed NIDCS block diagram
Unacceptable characteristics include elements like the picture's color, form, intricacy, and unpredictability. Features are the numerical qualities of an image. Also, by picking appropriate features, classification performance is improved. The given NIDS model can extract GLCM-based texture parameters in addition to standard color characteristics like mean and skewness.
RD(XA,XA')
= max(K - distance(XA'),distance(XA,XA'))
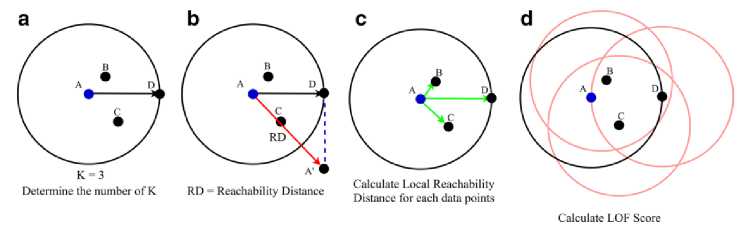
Fig.2. LOF process
Further, the LRD is estimated to compute the distance ratio for each closest neighbour within the cluster after obtaining the RD value.
LRDk(A) =
i
“ RD(A,Xj)
lx;:NkA iNk(A)
Here, Nk(A) represents the k-nearest neighbours. Then, the anomaly /LOF score is determined using the LRD value. The ratio of each data point's LRD value to the total number of data points is the LOF score.
LOFk(A) =
^ XjENk(A)LRDk ( xj )
\N k (A)\
LRD k (A)
Further, the Z-score is estimated to identify the boundary of features with cut-off levels for malicious and normal data. So, to find how far away from the dataset's mean ( m ), standard deviation ( std) each LOF score is, the LOF score is first transformed into a Z-score. Equations (4-6) are used to translate the LOF score to the Z-score ( z ) for each n data points.
m = -^}Xi П L L
std = ^^E ” (X i - m) 2
g _ LOF-m
n
Following the generation of the Z-score for each individual data point, the points are next dispersed according to the normal standard. The values of the data points are shown along the x-axis of this typical normal distribution, while the Z-scores are plotted along the y-axis. A cut-off value for the generation of the data subsets is determined by using the estimated standard deviation. The greatest score in the data distribution is the mean score, which is derived from the collection of data. The std of 3 indicates that 99.73% of the data is utilized while the remaining 2% will be discarded, while std of 2 indicates that 95.45% of the data will be utilized while the other 2% will be discarded. In addition, the std 1 value indicates that only 68.27% of the data will be used, while the remaining data will be discarded. These cut-off numbers indicate the distance from a perfect score that each LOF score and anomaly score.
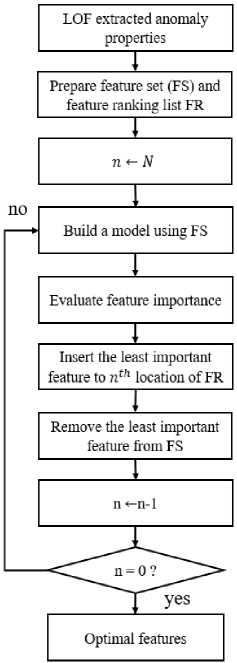
Fig.3. RFE feature extraction and selection
-
3.3. RFE Feature Extraction and Selection
The embedded feature selection method used in this strategy has demonstrated strong performance, making up for the drawbacks of the wrapper and filter methods. The RFE is a feature selection approach that seeks to choose the best feature subset Based on the learnt model and classification accuracy. After developing a classification model, conventional RFE systematically eliminates the worst feature that contributes to a decrease in "classification accuracy". The least significant features are chosen for elimination in a new RFE method that evaluates "feature (variable) importance" rather than "features extraction" using a LOF model. Figure 3 depicts the flow chart of RFE. Using a training dataset, a classifier is trained to provide feature weights that represent the relative relevance of each feature. The feature with the lowest weight value is eliminated after all features have been ranked according to weights. The classifier is then retrained using the remaining features until it runs out of features to train with. Finally, the complete ranking of features is acquired utilizing the feature-importance-based RFE technique.
Finding the hyperplane that separates classes most sharply is the goal of the LOF. High-dimensional data are effectively segregated using kernel approaches in the LOF. The linear kernel is used to calculate the values of the feature weight vector ( w ), and weight values were then utilized to determine the significance of features. Assume c represents number of classes and D (x) is the hyperplane's decision function. If there are more than two classes in the data, the number q, which represents all of the hyper-planes, is determined using the formula q = c(c — 1)/2 . Equation (8) was used for a multi-class dataset, while equation (7) pertains to decision function.
D(x) = sign(x * w) (7)
D(x) = sign(x * Wj),j = 1,2,3,.., q
The weight value ( W j ) for the LOF-RFE assessment of variable significance is obtained using equation (9).
1 V’Q
Wj = 1 ^ iWi
In the hyperplane supplying a linear decision function, w represents vector perpendicular to the hyperplane, and x is a vector containing the components of a specified intrusion region. One of the basic concepts of the LOF is that certain observations known as support vectors determine the decision boundary that divides the classes. The weighted vector shows how significant each variable is to the decision function. If the weighted vector contains high value for a certain feature, it means the feature can clearly differentiate the classes. Finally, the difference between class specific features is used to estimate the optimal features.
-
3.4. MCNN Classification
The deep learning models are trained with optimal features-based traffic data to capture the local characteristics. The most crucial component of the MCNN is the convolutional layer, which convolves the input pictures (or feature maps) with various convolutional kernels to produce various feature maps. Local information is extracted from shorter convolutional layers with a limited receptive field, whereas deeper layers with a wider visual field can collect global information. As a result, the size of the convolutional feature progressively gets coarser as the number of convolutional layers grows. Figure 4 shows the proposed MCNN architecture of NIDCS.
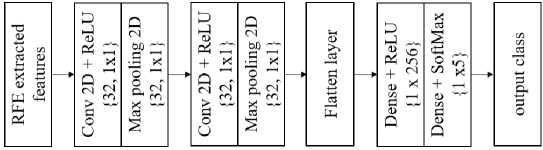
Fig.4. Proposed MCNN model
Convolution layer: This kind of layer is often used to calculate the yield of neurons in an input feature connected to a local area. In this instance, 32 filters are used to construct the coefficients of weight. The operation of the dot product between kernels or linked regions is carried out by each individual neuron. The Conv2D's ultimate dimension is {32 X 1 X 1}, with kernels that are 1X1 in size.
Max-pooling Layer: The down sampling procedure at this layer is dependent on the input feature. As a result, sampling by factor 2 is implicitly applied to the feature's width and height, producing a layer with the dimensions "{32 X 1 X 1}," where the feature's width and height are 32 and the filter size is 32.
Flatten layer: The input features are concatenated using this layer. Therefore, the layer size stays the same at 32 by 32 by 1, where 1 represents the dimension and 32 the height and breadth of the feature.
Dense Layer: Dense1 and Dense2 layers are combined, which forms the fully connected layer. Here, Dense1 contains the Rectified linear unit (ReLU) and Dense2 contains the SoftMax activation function. Here, ReLU performs only positive values selection, which eliminates all the negative values. Because the deep learning models function effectively on positive data compared to negative values.
SoftMax output layer: The SoftMax output layer probability is employed, which reduces inefficiencies during the attack recognition operation development. The SoftMax classifier develops the 5 different probability ranges as NIDCS performs five class classification. Finally, SoftMax classifies the DoS, Probe, R2L, U2R attacks and normal class.
4. Results
Results from the simulation, run in Python using the TensorFlow framework, are discussed in depth below. In addition, the novel NIDCS method's performance is validated in comparison to that of previously established approaches using the same dataset and a broad variety of tuning parameters.
-
4.1. Dataset
-
4.2. Performance Evaluation
NSL-KDD Dataset: The data in the Network Security Laboratory-Knowledge Discovery Databases (NSL-KDD) collection is categorized as either "normal" or "attack" data, with twenty-four distinct categories for each. These 24 attacks are broken down into four distinct types: U2R, DoS, Probe, and R2L. The various forms of attack captured in the sample are summarized in Table 1. In Figure 5, we see how the overall number of records is broken down by kind. Around 13,000 records have been stored across all these subheadings.
Table 1. Attacks in dataset
|
Attack |
Attack Type |
|
DoS |
Land, Neptune, Back, Smurf, Pod, Mailbomb, Teardrop, Udpstor, Processtable, Worm, Apache2. |
|
Probe |
IPsweep, Satan, Portsweep, Nmap, Sa int, Mscan |
|
R2L |
Ftp_write, Guess_password, Phf, Imap, Warezmaster, Multi hop, Xsnoop, Xlock, Snmpgetattack, Snmpgue ss, Sendmail, Httptunnel. |
|
U2R |
Loadmodule, Buffer_overflow, Perl, Rootkit, Xterm, Sqlattack, Ps |
This section gives the detailed analysis of class (attack) specific performance analysis of various methods. The different methods include FULL, RFE, standard deviation methods (STD1, STD2, STD3), GBDT- SMOTE, and proposed NIDCS. Here, FULL is an existing feature extraction method, which is used to extract the full features using data frame of accuracy, sensitivity, specificity, and FAR. The RFE, STD1, STD2, STD3 are also different existing feature extraction methods. In addition, GBDT-SMOTE [31] is IDS with SMOTE data balancing and GBDT classification.
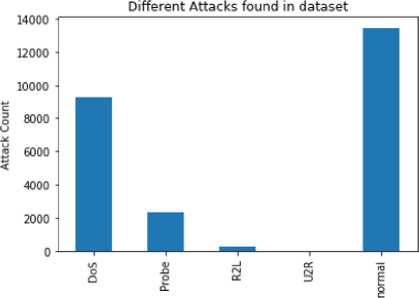
Attack Names
Fig.5. Number of records of each class in NSL-KDD dataset
Table 2, Table 3, Table 4, Table 5, and Table 6 provide the performance estimation of various methods on DoS, Probe, R2L, U2R attack and normal classes. In all tables, proposed NIDCS resulted in higher performance as equated to FULL, RFE, STD1, STD2, STD3, and GBDT-SMOTE [31] methods.
Table 2. Performance estimation of various methods on DoS attack
|
Class |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
FULL |
94.8908 |
94.9454 |
91.4286 |
08.5714 |
|
RFE |
95.000 |
95.7838 |
89.7436 |
10.2564 |
|
STD1 |
96.9365 |
96.000 |
87.5 |
12.5 |
|
STD2 |
97.9457 |
97.9457 |
93.1034 |
6.8966 |
|
STD3 |
98.000 |
98.8910 |
90.4762 |
09.5238 |
|
GBDT-SMOTE [31] |
100.000 |
99.9636 |
94.4444 |
05.5556 |
|
Proposed NIDCS |
99.8908 |
99.9271 |
96.3846 |
09.154 |
Table 3. Performance estimation of various methods on Probe attack
|
Class |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
FULL |
97.7812 |
97.8118 |
74.2857 |
25.7143 |
|
RFE |
97.7812 |
97.8118 |
74.2857 |
25.7143 |
|
STD1 |
98.7013 |
96.1039 |
75.0 |
25.0 |
|
STD2 |
98.7013 |
96.1039 |
75.0 |
25.0 |
|
STD3 |
96.9828 |
95.6897 |
85.7143 |
23.3 |
|
GBDT-SMOTE [31] |
99.7473 |
99.9638 |
55.5556 |
44.4444 |
|
Proposed NIDCS |
99.8497 |
99.5866 |
86.5385 |
13.4615 |
Table 4. Performance estimation of various methods on R2L attack
|
Class |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
FULL |
93.0233 |
92.5000 |
82.8571 |
17.1429 |
|
RFE |
92.6829 |
82.9268 |
89.7436 |
10.2564 |
|
STD1 |
66.6667 |
100.000 |
87.5 |
12.5 |
|
STD2 |
98.000 |
81.4815 |
82.7586 |
17.2414 |
|
STD3 |
85.1852 |
95.6522 |
76.1905 |
23.8095 |
|
GBDT-SMOTE [31] |
99.9225 |
99.9612 |
83.3333 |
16.6667 |
|
Proposed NIDCS |
99.3274 |
99.9624 |
93.4615 |
36.5385 |
Table 5. Performance estimation of various methods on U2R attack
|
Class |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
FULL |
66.6667 |
75.0000 |
91.4286 |
18.5714 |
|
RFE |
50.0000 |
100.000 |
97.4359 |
12.5641 |
|
STD1 |
50.0000 |
100.000 |
87.5 |
12.5 |
|
STD2 |
95.000 |
0 |
96.5517 |
13.4483 |
|
STD3 |
97.0415 |
0 |
97.000 |
15.66 |
|
GBDT-SMOTE [31] |
99.9624 |
99.9624 |
88.8889 |
11.1111 |
|
Proposed NIDCS |
99.7013 |
100 |
84.6154 |
15.3846 |
Table 6. Performance estimation of various methods on normal class
|
Class |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
FULL |
99.7784 |
99.2614 |
60.0000 |
40.0000 |
|
RFE |
99.6278 |
99.5144 |
41.0256 |
58.9744 |
|
STD1 |
99.8722 |
99.6805 |
62.5 |
37.5 |
|
STD2 |
100.000 |
99.4186 |
51.7241 |
48.2759 |
|
STD3 |
96.015 |
0 |
100.000 |
0 |
|
GBDT-SMOTE [31] |
99.6292 |
99.4809 |
77.7778 |
22.2222 |
|
Proposed NIDCS |
99.0799 |
98.6014 |
75.0000 |
25.0000 |
4.3. Overall Performance Comparison
5. Conclusions3.32%, sensitivity by 3.02%, and specificity by 4.26%, as compared to existing methods. In practice, this proposed NIDCS system can be applicable for dynamic data with enhanced classification accuracy of intrusions in the network due to its deep feature extraction nature with outlier detection by eliminating the weaker features. Further, the use of deep extreme learning-based feature extraction is the potential future scope to speed up this process with improved performance.
Table 7 compares the proposed NIDCS technique with more traditional IDS systems and illustrates how well it performs. When compared to standard DNN [21], GWO–PSO–RF [23], ResNet [26], GSA [30], and GBDT-SMOTE [31], the results of this study showed that the suggested NIDCS achieved higher accuracy, sensitivity, and specificity while also reducing FAR.
Table 7. Performance comparison of proposed method with conventional approaches.
|
Method |
Accuracy |
Sensitivity |
Specificity |
FAR |
|
DNN [21] |
90.793 |
93.549 |
90.923 |
17.477 |
|
GWO–PSO–RF [23] |
92.198 |
93.987 |
91.873 |
16.298 |
|
ResNet [26] |
94.439 |
96.130 |
94.980 |
14.252 |
|
GSA [30] |
96.400 |
96.833 |
95.600 |
11.893 |
|
GBDT-SMOTE [31] |
99.100 |
99.282 |
99.159 |
5.026 |
|
Proposed NIDCS |
99.300 |
99.57 |
99.692 |
3.026 |
This article is focused on implementation of an NIDCS with preprocessing, and outlier detection techniques. At the outset of the extraction procedure, a preprocessing step is carried out to remove any non-standard characters. In addition, LOF is used to balance the dataset, which identifies outliers and anomalies by comparing the deviation of one data point about its neighbors. Further, RFE method adopted to fit a model, which is a feature extraction selection approach that eliminates the weakest features one at a time until the desired number of features has been achieved. In addition, the MCNN classifier is used to train the ideal features, which are then used to differentiate between normal classes and attacks like DoS, probing, R2L, and U2R. The simulation results on the NSL-KDD dataset show that the proposed NIDCS system outperformed the industry standard techniques of analysis. The proposed NIDCS improved accuracy by
References Modified CNN Model for Network Intrusion Detection and Classification System Using Local Outlier Factor-based Recursive Feature Elimination
- M. Chalé, and N. D. Bastian. "Generating realistic cyber data for training and evaluating machine learning classifiers for network intrusion detection systems." Expert Systems with Applications 207 (2022): 117936.
- G. Apruzzese, M. Andreolini, L. Ferretti, M. Marchetti, and M. Colajanni, (2022). Modeling realistic adversarial attacks against network intrusion detection systems. Digital Threats: Research and Practice (DTRAP), 3(3), 1-19.
- Apruzzese, G., Pajola, L., & Conti, M. (2022). The Cross-evaluation of Machine Learning-based Network Intrusion Detection Systems. IEEE Transactions on Network and Service Management.
- Zhang, C., Costa-Pérez, X., & Patras, P. (2022). Adversarial Attacks Against Deep Learning-Based Network Intrusion Detection Systems and Defense Mechanisms. IEEE/ACM Transactions on Networking.
- Asad, Hafizul, and Ilir Gashi. "Dynamical analysis of diversity in rule-based open source network intrusion detection systems." Empirical Software Engineering 27.1 (2022): 1-30.
- Sheatsley, R., Papernot, N., Weisman, M. J., Verma, G., & McDaniel, P. (2022). Adversarial examples for network intrusion detection systems. Journal of Computer Security, (Preprint), 1-26.
- Fu, Y., Du, Y., Cao, Z., Li, Q., & Xiang, W. (2022). A Deep Learning Model for Network Intrusion Detection with Imbalanced Data. Electronics, 11(6), 898.
- Magan-Carrion, R., Urda, D., Diaz-Cano, I., & Dorronsoro, B. (2022). Improving the Reliability of Network Intrusion Detection Systems through Dataset Aggregation. IEEE Transactions on Emerging Topics in Computing.
- Data, M., & Aritsugi, M. (2022, July). AB-HT: An Ensemble Incremental Learning Algorithm for Network Intrusion Detection Systems. In 2022 International Conference on Data Science and Its Applications (ICoDSA) (pp. 47-52). IEEE.
- Antunes, M., Oliveira, L., Seguro, A., Veríssimo, J., Salgado, R., & Murteira, T. (2022, March). Benchmarking Deep Learning Methods for Behaviour-Based Network Intrusion Detection. In Informatics (Vol. 9, No. 1, p. 29). MDPI.
- Moizuddin, M. D., & Jose, M. V. (2022). A bio-inspired hybrid deep learning model for network intrusion detection. Knowledge-Based Systems, 238, 107894.
- Sarhan, M., Layeghy, S., & Portmann, M. (2022). Towards a standard feature set for network intrusion detection system datasets. Mobile Networks and Applications, 27(1), 357-370.
- Habeeb, Mohammed Sayeeduddin, and T. Ranga Babu. "Network intrusion detection system: A survey on artificial intelligence‐based techniques." Expert Systems (2022): e13066.
- Hindy, Hanan and Brosset, David and Bayne, Ethan and Seeam, Amar and Tachtatzis, Christos and Atkinson, Robert and Bellekens, Xavier (2018) A taxonomy and survey of intrusion detection system design techniques, network threats and datasets.
- Salih, Azar Abid, and Adnan Mohsin Abdulazeez. "Evaluation of classification algorithms for intrusion detection system: A review." Journal of Soft Computing and Data Mining 2.1 (2021): 31-40.
- Dang, Quang-Vinh. "Active Learning for Intrusion Detection Systems." IEEE Research, Innovation and Vision for the Future. 2020.
- Li, Jieling, et al. "Semi-supervised machine learning framework for network intrusion detection." The Journal of Supercomputing (2022): 1-23.
- Al-Safi, Ali Hussein Shamman, Zaid Ibrahim Rasool Hani, and Musaddak M. Abdul Zahra. "Using a hybrid algorithm and feature selection for network anomaly intrusion detection." J. Mech. Eng. Res. Dev 44 (2021): 253-262.
- Gopalakrishnan, B., and P. Purusothaman. "A new design of intrusion detection in IoT sector using optimal feature selection and high ranking-based ensemble learning model." Peer-to-Peer Networking and Applications 15.5 (2022): 2199-2226.
- Panigrahi, R., Borah, S., Pramanik, M., Bhoi, A. K., Barsocchi, P., Nayak, S. R., & Alnumay, W. (2022). Intrusion detection in cyber–physical environment using hybrid Naïve Bayes—Decision table and multi-objective evolutionary feature selection. Computer Communications, 188, 133-144.
- Rao, K. Narayana, K. Venkata Rao, and Prasad Reddy PVGD. "A hybrid intrusion detection system based on sparse autoencoder and deep neural network." Computer Communications 180 (2021): 77-88.
- Tait, Kathryn-Ann, et al. "Intrusion detection using machine learning techniques: an experimental comparison." 2021 International Congress of Advanced Technology and Engineering (ICOTEN). IEEE, 2021.
- Keserwani, Pankaj Kumar, et al. "A smart anomaly-based intrusion detection system for the Internet of Things (IoT) network using GWO–PSO–RF model." Journal of Reliable Intelligent Environments 7.1 (2021): 3-21.
- Mishra, Preeti, et al. "A detailed investigation and analysis of using machine learning techniques for intrusion detection." IEEE communications surveys & tutorials 21.1 (2018): 686-728.
- Rodda, Sireesha. "Network intrusion detection systems using neural networks." Information systems design and intelligent applications. Springer, Singapore, 2018. 903-908.
- Xiao, Yuelei, and Xing Xiao. "An intrusion detection system based on a simplified residual network." Information 10.11 (2019): 356.
- Rahman, Md Arafatur, et al. "Effective combining of feature selection techniques for machine learning-enabled IoT intrusion detection." Multimedia Tools and Applications 80.20 (2021): 31381-31399.
- Al-Duwairi, Basheer, et al. "SIEM-based detection and mitigation of IoT-botnet DDoS attacks." International Journal of Electrical and Computer Engineering 10.2 (2020): 2182.
- Krishnaveni, Sivamohan, et al. "Efficient feature selection and classification through ensemble method for network intrusion detection on cloud computing." Cluster Computing 24.3 (2021): 1761-1779.z
- Raj, Meghana G., and Santosh Kumar Pani. "A meta-analytic review of intelligent intrusion detection techniques in cloud computing environment." International Journal of Advanced Computer Science and Applications 12.10 (2021).
- K. Mounika and P. V. Rao, "IDCSNet: Intrusion Detection and Classification System using Unified Gradient-Boosted Decision Tree Classifier," International Conference on Automation, Computing and Renewable Systems (ICACRS), Pudukkottai, India, 2022, pp. 1159-1164.
