Модули внимания в сверточных нейронных сетях для распознавания малоразмерных объектов

Автор: Краснов Д.И.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 6 т.48, 2024 года.
Бесплатный доступ
Задача распознавания малоразмерных объектов часто встречается в биомедицинских системах и системах безопасности. При этом обнаружение таких объектов часто осложняется наличием плотных облаков или объектов инфраструктуры. В данной работе представлены результаты использования различных механизмов внимания для повышения точности в задаче сегментации малоразмерных объектов на изображении с помощью сверточных нейронных сетей. Были рассмотрены модули внимания по каналам и по пикселам. Подобный подход позволяет эффективно подавлять менее информативные каналы и области изображения и усиливать более информативные каналы и области изображения. При этом весовые коэффициенты в модулях внимания автоматически адаптируются к обучающим данным. Проведена оценка влияния механизмов внимания в архитектуре сверточной нейронной сети на ее способность подавлять сложный фон (облака, тучи и объекты инфраструктуры) и сегментировать малоразмерные объекты. Результаты представлены в виде таблиц с тестовыми метриками, графиков precision-recall и ROC-кривых и тепловых карт, показывающих эффективность подавления фона. Полученные результаты позволяют эффективно внедрять описанные модули внимания в сверточные нейронные сети любой сложности для повышения точности распознавания объектов размером 10 – 40 пикселей на сложном фоне.
Сегментация, малоразмерный объект, сверточная нейронная сеть, модуль внимания, компьютерное зрение
Короткий адрес: https://sciup.org/140310423
IDR: 140310423 | DOI: 10.18287/2412-6179-CO-1468
Attention modules in convolutional neural networks for small object recognition
A problem of small object recognition is frequently encountered in biomedical and security systems. However, the detection of such objects is often complicated by presence of dense clouds or infrastructure objects. Results of using various attention mechanisms to improve accuracy in small objects segmentation with convolutional neural networks are presented in this paper. Modules of channel attention and spatial attention are considered. This approach allows one to effectively suppress less informative channels and image areas, while enhancing more informative channels and image areas. Meanwhile, weights of the attention modules are automatically adapted to the input data during training. An assessment of influence of the attention mechanisms in convolutional neural network architecture on the ability to suppress complex backgrounds (clouds and infrastructure objects) and segment small objects is performed. The results are presented in the form of tables with test metrics and figures with precision-recall curves, ROC curves and heatmaps showing an effectiveness of background suppression. The results obtained allow one to implement the described attention modules in the convolutional neural networks of any complexity and increase the recognition accuracy of objects of 10-40 pixels in size on a complex background.
Текст научной статьи Модули внимания в сверточных нейронных сетях для распознавания малоразмерных объектов
В настоящее время системы компьютерного зрения на основе сверточных нейронных сетей используются во многих областях человеческой деятельности. Например, в биомедицинских системах для сегментации новообразований на снимках, полученных путем магнитно-резонансной томографии [1], или в системах безопасности для определения посторонних людей или объектов в защищенной зоне [2].
В описанных выше системах часто встречается задача распознавания маленьких объектов размером около 10–40 пикселей. Это могут быть небольшие кровяные клетки, опухоли или удаленные от объектива камеры летающие объекты (самолеты, вертолеты или беспилотные летательные аппараты). Маленькие объекты содержат в себе очень мало семантической информации, что затрудняет их определение даже человеческим глазом. Кроме того, малоразмерные объекты часто находятся на сложном фоне, например летательные аппараты на фоне кучевых облаков или объектов инфраструктуры прилегающей зоны. Все описанные выше факторы значительно затрудняют определение таких объектов в автоматических системах компьютерного зрения.
Существует множество принципиально различных подходов к распознаванию малых объектов, которые имеют свои достоинства и недостатки.
Одним из наиболее простых подходов в системах безопасности и специального назначения является использование классических алгоритмов обработки изображения. Это позволяет подавлять фон и выделять объект с помощью различных видов фильтрации: разность фильтров Гаусса [3], локальная контрастная фильтрация [4] или вейвлет-преобразование [5]. Стоит отметить, что такой подход наиболее часто применяется в обработке изображений инфракрасного диапазона, потому что объект на таком изображении имеет вид пятна, яркость которого может значительно отличаться от яркости фона.
Другим подходом является использование последовательности кадров аналогично зрительному аппарату человека. Это позволяет применять алгоритмы вычитания фона с последующей сегментацией [6], сверточные нейронные сети с блоками долгой краткосрочной памятью [7] или классификаторы для анализа траектории полета объекта [8].
Наиболее эффективным подходом является использование сверточных нейронных сетей для обра- ботки одного кадра. В таком подходе часто используют вспомогательную сеть для повышения разрешения исследуемой области [9] или дополнительные блоки для подавления менее информативных областей и усиления более информативных областей [10]. Кроме того, возможно использование изображений инфракрасного диапазона [11 – 12], что позволяет генерировать обучающие данные в процессе обучения, помещая яркое пятно на инфракрасное изображение фона.
Следует отметить, что традиционные архитектуры нейронных сетей не способны справиться с задачей обнаружения малоразмерных объектов с достаточной точностью, поэтому данная задача остается актуальной. В работе исследованы блоки пространственного и межканального внимания для повышения точности распознавания малых объектов. Проведен эксперимент, показывающий повышение точности нейронной сети на реальных данных. Исследована способность нейронной сети подавлять сложный фон и концентрироваться на области, содержащей искомый объект. Результаты представлены в виде таблицы с тестовыми метриками (F-мера, мера Жаккара, ROC AUC и Average Precision), графиков с precision-recall кривыми и тепловых карт, полученных путем усреднения тензоров с последних слоев исследуемых нейронных сетей.
1. Набор данных
Для проведения исследования собран набор данных, содержащий 12242 изображения в видимом диапазоне с малоразмерными объектами в виде самолетов, вертолетов и беспилотных летательных аппаратов (БПЛА) размером от 5 до 70 пикселей. Набор данных был получен путем объединения трех других, находящихся в свободном доступе, с последующим исключением изображений, содержащих слишком большие объекты (больше 70 пикселей). Первый набор данных Purdue UAV Dataset [13] содержит в себе 50 размеченных видеофайлов с БПЛА, снятых в полете с установленной на одном из них камеры с разрешением 1920×1080. Эти видеофайлы были покадрово преобразованы в изображения, затем каждое изображение разделено на 9 перекрывающихся областей, для каждой из которых созданы маски, содержащие 0 на пикселах фона и 1 на пикселах объекта. Второй набор данных [14] содержит в себе видеофайлы с самолетами, вертолетами и дронами в разрешении 640×512. Видеофайлы были покадрово преобразованы в изображения, к которым были созданы маски аналогично описанному выше принципу. Третий набор данных [15] содержит размеченные видеофайлы с радиоуправляемыми самолетами и дронами, снятые с земли и воздуха, с разрешением 1280×720. Примеры полученных изображений с сегментационными масками представлены на рис. 1. Распределение объектов по их размеру в пикселях в итоговом наборе данных представлено на рис. 2.

Рис. 1. Примеры используемых изображений
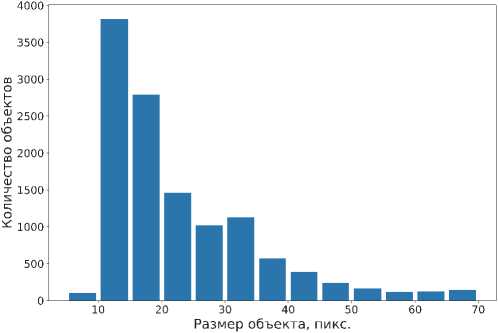
Рис. 2. Гистограмма распределения размера объектов в наборе данных
Описанные выше изображения были разделены на обучающую, валидационную и тестовую выборки по 8569, 2460 и 1213 изображений соответственно. В процессе обучения была использована аугментация изображений с помощью аффинных преобразований (повороты и отражения), моделирования погодных эффектов (дождь, снег и засветка) и моделирования помех камеры и оптической системы (шум, дефокусировка и смаз).
2. Обучаемые модели
В качестве базовой нейронной сети была выбрана симметричная сеть для семантической сегментации ESNet [16]. Архитектура базовой сети состоит из блоков (рис. 3), которые соединены последовательно. Блоки на схеме изображены условно, поскольку их структура не играет роли в рамках данного исследования. Базовая модель имеет типичную для задачи сегментации структуру энкодер-декодер, где энкодер отвечает за извлечение семантических признаков из входного изображения, а декодер за использование извлеченных признаков для сегментации объекта.
Наиболее часто применяемым методом повышения точности с минимальным изменением архитектуры нейронной сети является слияние признаков (feature fusion) [17]. Это позволяет использовать извлеченные семантические признаки с различными уровнями глубины одновременно. Выходные тензоры с нескольких последних блоков приводятся к одному разрешению с помощью интерполяции (upsampling) и соединяются вдоль каналов перед заключительным сверточным слоем (рис. 4). В данной работе для сли- яния признаков использовались выходные тензоры от блоков 3, 4 и 5 декодера базовой сети.
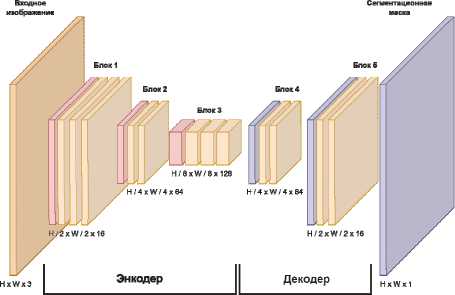
Рис. 3. Архитектура базовой модели
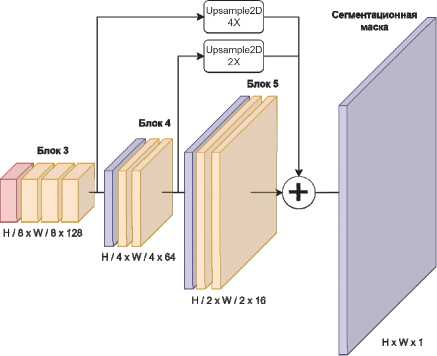
Рис. 4. Архитектура декодера модели с модулем слияния признаков
Исследуемые блоки межканального и пространственного внимания [18] имеют следующие архитектуры (рис. 5 и 6). Эти блоки являются самостоятельными единицами и могут быть встроены в нейронную сеть практически любой топологии. Принцип работы блока межканального внимания состоит в преобразовании входного тензора в одномерный вектор весов путем применения глобального пулинга (global max pooling или global average pooling). Длина вектора соответствует количеству каналов во входном тензоре. Полученный вектор весов проходит через последовательность сверточных слоев (Conv2D) с единичным ядром, что эквивалентно полносвязной сети, и нормируется с помощью сигмоидной функции (sigmoid). После этого каждый канал входного тензора умножается на соответствующий ему вес из вектора весов. Поскольку веса адаптируются к входным данным в процессе обучения, нейронная сеть будет автоматически подавлять менее информативные каналы и усиливать более информативные. Принцип работы блока пространственного внимания состоит в преобразовании входного тензора в нормированную маску весов с одним каналом и исходным разрешением с помощью последовательности сверточных слоев с функцией активации (ReLU) и сигмоидной функции. После этого полученная маска поэлементно умножается на входной тензор, в результате чего подавляются менее информативные области (фон) и усиливаются более информативные (объект). Для совместного использования двух блоков их выходные тензоры суммируются, т.к. они имеют одинаковые размерности.
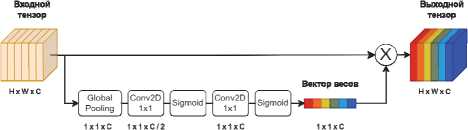
Рис. 5. Архитектура блока межканального внимания
Входной тензор
Выходной тензор
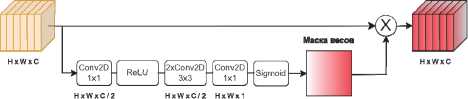
Рис. 6. Архитектура блока пространственного внимания
Для проведения эксперимента в топологию базовой сети были добавлены модуль слияния признаков, модуль межканального внимания, модуль пространственного внимания и модули пространственного и межканального внимания одновременно. Описанные выше блоки внедрены в декодер базовой модели после блоков 3, 4 и 5. Таким образом, были получены 5 архитектур сверточных нейронных сетей.
Полученные модели были обучены на выборке с использованием разрешения 512×512. Обучение проводилось на NVIDIA RTX 3060 12GB со следующими параметрами:
– размер пакета – 16;
– количество эпох – 200;
– оптимизатор Adam с learning rate 0,001 и экспоненциальным уменьшением 0,9;
– функция потерь dice loss [19].
В процессе обучения контролировались метрики по валидационной выборке: точность (precision), полнота (recall), IoU [20] (мера Жаккара) и average precision (AP).
3. Результаты
Результаты обучения пяти описанных выше моделей приведены в приложении А в табл. 1A. Значения функции потерь для обучающей выборки и метрик для валидационной выборки указаны для последней эпохи.
После обучения пяти моделей было проведено тестирование на выборке, которая не участвовала в обучении и валидации. Результаты тестирования моделей представлены в виде графиков precisionrecall кривых (рис. 7) и ROC-кривых (рис. 8).
Кроме того, остальные метрики: f-мера, IoU, площадь под ROC-кривой (ROC AUC) и площадь под PR-кривой (Average Precision) для тестовой выборки были собраны в табл. 1.
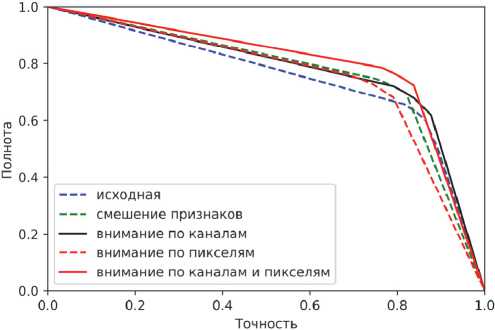
Рис. 7. Precision-recall кривые для тестовой выборки
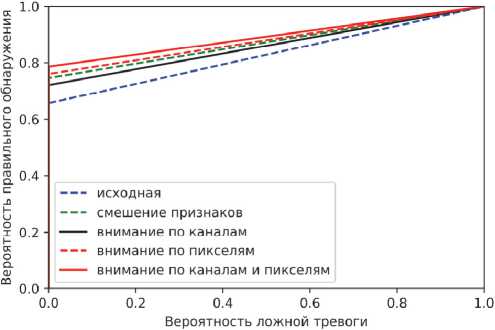
Рис. 8. ROC-кривые для тестовой выборки
Табл. 1. Метрики для тестовой выборки
|
Модель |
F-мера |
IoU |
ROC AUC |
AP |
|
Исходная |
0,706 |
0,547 |
0,824 |
0,571 |
|
Слияние признаков |
0,750 |
0,595 |
0,876 |
0,613 |
|
Внимание по каналам |
0,742 |
0,590 |
0,864 |
0,620 |
|
Внимание по пикселям |
0,715 |
0,552 |
0,873 |
0,582 |
|
Внимание по каналам и пикселям |
0,761 |
0,615 |
0,891 |
0,639 |
По графикам precision-recall и ROC-кривых можно заметить, что блок слияния признаков дает большое улучшение в точности сегментации объектов. Следует отметить, что такой блок практически не влияет на скорость работы модели, т.к. вносит всего лишь несколько дополнительных слоев. Блоки межканального и пространственного внимания по отдельности дают небольшой прирост точности, меньший, чем блок слияния признаков. Однако их комбинация позволяет увеличить точность модели по AP и IoU более чем на 10 % (табл. 2), что дает большее улучшение, чем модуль слияния признаков. По рис. 5 и 6 можно заметить, что описанные блоки немного усложняют архитектуру модели, однако они могут быть внедрены практически в любую топологию сверточной нейронной сети без существенного ухудшения производительности.
Для того чтобы оценить эффективность блоков внимания в задаче подавления сложного фона и локализации объекта, были построены тепловые карты, полученные путем усреднения выходного тензора с предпоследних слоев моделей (рис. 9а – в). Они позволяют визуально оценить, как модель с пространственными и межканальными блоками внимания подавляет области с фоном и уменьшает шумы, локализуя объект (рис. 9в) за счет назначения большего веса информативным областям. Можно заметить, что область объекта в базовой модели определяется нечетко (рис. 9б), в то время как в улучшенной модели грани-

Рис. 9. Тепловые карты внимания (а – входное изображение, б – базовая модель и в – модель с межканальным и пространственным вниманием)
Однако даже в эффективных блоках внимания может быть ложное срабатывание. На рис. 9 в для второго изображения видно, что модель с межканальным и пространственным вниманием ошибочно назначает большой вес области, не содержащей искомый объект. При этом внимание к истинному объекту значительно выше, что позволяет судить о высокой эффективности блоков внимания в задаче обнаружения малоразмерных объектов.
Заключение
В работе освещена проблема точного определения малоразмерных объектов на изображении с помощью сверточных нейронных сетей в различных системах компьютерного зрения и методы ее решения. Проведено исследование о влиянии внедрения блоков внимания в архитектуру сверточной нейронной сети на точность распознавания малоразмерных объектов (удаленных летательных аппаратов) в системах безопасности. Блоки внимания были внедрены в базовую нейронную сеть для семантической сегментации ESNet, в результате чего были получены 4 новые модели. Эти модели были обучены на смешанном наборе данных с малоразмерными летательными аппаратами. Результаты тестирования обученных моделей приведены в виде графиков precision-recall и ROC-кривых и таблиц с метриками f-меры, IoU, ROC AUC и AP. Результаты показали, что наилучший прирост точности по Average Precision и IoU (более 10%) обеспечило внедрение блоков межканального и пространственного внимания одновременно. Блок слияния признаков позволил получить лучшую точность по сравнению с отдельным использованием блоков межканального и пространственного внимания (IoU 0,595 против 0,590 и 0,552). По полученным тепловым картам можно судить о высокой эффективности подавления фона и локализации искомых объектов. Описанные блоки могут модернизироваться в зависимости от поставленной задачи и легко встраиваться в сверточную нейронную сеть с практически любой архитектурой, а их весовые коэффициенты адаптируются к входным данным автоматически в процессе обучения.
В настоящее время исследуется возможность внедрения пространственной фильтрации с помощью разности фильтров Гаусса или вейвлет-преобразования в сверточную нейронную сеть для лучшего подавления фона.
