На подступах к геному стиля Шекспира

Автор: Орехов Борис Валерьевич, Пешков Игорь Валентинович
Журнал: Новый филологический вестник @slovorggu
Рубрика: Прочтения
Статья в выпуске: 3 (26), 2013 года.
Бесплатный доступ
В работе предлагается оригинальная методика представления и анализа стиля. Стиль определяется как совокупность всех повторных коллокаций произведений автора. Методика применяется к корпусу пьес Шекспира. Из текстов, включенных в Первое Фолио, было получено два словника коллокаций с любой, вплоть до минимальной (присутствие хотя бы в двух пьесах корпуса), и максимальной (присутствие во всех 36 пьесах) повторностью единиц. Первый словник составил более 130000, второй 218 единиц. Сравнение с этими словниками отдельных произведений Шекспира, современников Шекспира и других авторов, писавших на английском языке, дало возможность авторам статьи сделать некоторые выводы об атрибуции отдельных художественных произведений и частей этих произведений, в частности подтвердить и уточнить феномены соавторства при создании определенных шекспировских пьес.
Короткий адрес: https://sciup.org/14914396
IDR: 14914396
The approaches to Shakespeare’s style
The paper proposes an original technique for representation and analysis of style. Style is defined as repeated collocations in the author’s works as a whole. This technique is applied to the corpus of Shakespeare’s plays. Two vocabularies of collocations resulted from the texts included in the First Folio. These vocabularies include all collocations up to a minimum (the presence in at least two plays in the corpus) and maximum (the presence in all 36 plays) of repeated units. The first list includes over 130,000 units, the second list includes 218 units. The comparison of these vocabularies with individual works of Shakespeare, Shakespeare’s contemporaries and other authors who wrote in English let the authors draw some conclusions on attribution of individual works and pieces of these works, in particular to confirm the phenomena of co-authorship of some of Shakespeare’s plays.
Текст научной статьи На подступах к геному стиля Шекспира
Казалось бы, при том внимании, которое традиционно уделяется Шекспиру, за прошедшие четыре сотни лет филологи и историки обязаны были до чего-то докопаться, а основные проблемы, по крайней мере, те, что вообще имеют решение, должны были быть разрешены (скорее всего, так должен полагать обычный читатель или зритель). Ничуть не бывало. Шекспир со всеми его загадками оказался человеку не по зубам. Осознав это, человек призвал себе на помощь компьютер. В 1990 г. был сделан показательный обзор1 уже трех существовавших к тому времени электронных изданий произведений Шекспира и программ, позволявших с этими изданиями работать, решая, впрочем, довольно примитивные по нынешним меркам задачи. Понятно, что с тех пор число приложений компьютерных технологий к исследованиям шекспировских текстов только росло - вместе с доступностью техники и ее вычислительными мощностями. При этом сам по себе компьютерный анализ (в том числе и анализ текста) качественно не отличается от того, который выполняется людьми. Да и методику для такого анализа тоже разрабатывает человек. Что-то находится, систематизируется, подсчитывается. Отличие только в том, что компьютер может обработать за единицу времени гораздо больше материала и тут уже есть шанс, что количество перейдет в качество: результаты подсчетов будут весомее, а выводы, сделанные на их основе (уже снова человеком), - устойчивее.
Разумеется, более всего компьютерных лингвистов интересовала проблема атрибуции текстов и, соответственно, проблема стиля2. Какое бы значение ни вкладывать в это слово, ясно, что к проблеме авторства стиль имеет самое прямое отношение. И тут уже все средства хороши: и нейронные сети, и анализ модальности3, и многие другие. Выводы основываются на строгой статистике, только подсчеты ведутся каждый раз по разным параметрам.
Кроме того, с Шекспиром сыграла компьютерную шутку его репутация основателя английской литературы. Постоянно находящиеся в центре внимания, известные всем и часто цитируемые, шекспировские тексты чаще других и становятся площадкой для испытания новых методик компьютерной лингвистики, будь то извлечение из текста его фрактальной геометрии4 или контент-анализ с целью описания эстетического эффекта5. Так что испытывать новый способ извлечения из текста некоторых его единиц и характеристик в первую очередь именно к Шекспиру - дело уже привычное.
И несмотря на все это, несмотря на столь давнюю, с точки зрения компьютерной истории традицию объединения в филологических штудиях Шекспира и компьютера, в нашей работе сложности возникли еще до того, как мы начали их осознавать. Прежде всего, оказалось трудно сформулировать саму задачу наших исследований. Формулировка «Определить стиль Шекспира», а именно к этому мы интуитивно стремились, сразу оказалась размытой, причем во всех своих терминах. Во-первых, нет достаточной ясности, что такое стиль. Это отдельная теоретическая проблема. Во-вторых, нет никакой ясности, кто такой Шекспир: это человек, бренд или псевдоним? В-третьих, наконец, при таких вводных становится неясным, что вообще значит «определить»...
Но поскольку решать задачу из трех неизвестных при отсутствии известных невозможно, то пришлось кое-что признать известным. Вот мы и решили, что исходя из своего исследовательского, читательского и просто житейского опыта кое-что уже знаем о стиле. Мы принимаем за лемму утверждение:
Стиль - это совокупность типичных сочетаний слов (исходная лемма А).
Уже чуть легче. Осталось найти сочетания слов у Шекспира и определить степень их типичности. Но тут же встает во весь рост вторая проблема: кто такой Шекспир? Теперь мы уже не можем назначать себе вторую лемму и исходить из того, что Шекспир это тот-то и тот-то, потому что лемма должна быть одна. И с одной-то не так все просто, а две леммы на старте рассуждений - это уже ни в какие ворота логики не войдет, поэтому от вопроса кто такой Шекспир в качестве исходного пункта нужно постараться просто уйти. В принципе это для шекспироведов традиционный уход: основная филологическая работа сосредоточена почти исключитель- но на произведениях Шекспира. To есть и мы начнем в русле исследовательской традиции.
Таким образом, несмотря на знаменитое определение «стиль это человек», работать мы будем не с человеком, а с текстом. Вернее, с корпусом текстов. Кстати, это практически единственное, что оставил после себя Шекспир. Корпус текстов. С этим корпусом тоже не все однозначно, но кое-что все-таки общепризнанно. Самым общепризнанным фактом в шекспироведении является то, что 36 пьес, изданных в 1623 г. в Первом Фолио, написал Шекспир. Так что мы просто считаем исходным текстовым материалом для определения стиля Шекспира пьесы Первого Фолио. Не будем углубляться в текстологию каждой пьесы (это отдельный вопрос), просто возьмем все тексты в их современной орфографии. (В качестве исходной точки нами было взято свободно распространяемое электронное издание пьес Шекспира в XML, подготовленное Джоном Босаком в 1999 г. на основе оцифрованных текстов Moby Lexical Tools6. Из входящих в собрание Босака пьес нами удален «Перикл», отсутствующий в Первом Фолио). Для предварительного, чернового анализа стиля этого достаточно и, более того, на этом нужно остановиться, помня об условности перевода в современную орфографию, но предполагая, что такой перевод произведен для всех анализируемых дальше текстов по одинаковому алгоритму. Для первой, черновой попытки стилистического анализа с этим предположением можно согласиться.
Итак, пока для нас нет самого Шекспира, но есть условно-полный текст Шекспира, из которого уже можно вычленять стиль, то есть определять сочетания слов. За слово в тексте примем последовательное сочетание букв между двумя небуквами (считая буквами также апостроф и дефис, а небуквами - любой другой типографский знак или пробел), то есть подходим к определению слова формально-графически. Для верности возьмем все сочетания (то есть рядоположения) от двух до шести слов и выберем те из них, которые появлялись хотя бы в двух пьесах Шекспира (этим и определяется типичность сочетаний). Вручную на эту операцию, вероятно, ушло бы полжизни, но компьютер делает все довольно быстро. В работу берутся только реплики персонажей. XML-разметка позволяет легко отсекать ремарки (скорее всего, в большинстве случаев не аутентично шекспировские), имена персонажей и прочие позднейшие пометы. Входящими в одно сочетание считаются даже слова, разделенные как границей строки, так и границей реплик разных персонажей. Значимой признается только граница акта. Таким образом, слово, которым оканчивается, например, I акт и слово, с которого начинается II акт, не будут входить в одно сочетание. (Хотя в принципе и от этой границы можно было бы отказаться.)
В результате мы получаем словник примерно из 133 тысяч коллокаций, так определяя сочетания слов, чтобы не путать с известным понятием из синтаксиса (словосочетание). Этот результат назовем максимальным или Большим словником Шекспира (Бел). На глаз для примерно 15 тысяч слов в языке автора7130 тысяч типичных коллокаций вполне нормально.
Теперь выберем самые типичные шекспировские коллокации: те, что имеются во всех 36 пьесах. Словник сузился до 218 единиц. Да, их мало, самых типичных, но они есть! Вот 10 самых-самых типичных сочетаний слов у Шекспира (правый крайний столбик показывает, сколько раз коллокация встретилась в корпусе):
|
1. |
I |
am |
1814 |
|
2 . |
I |
have |
1587 |
|
3. |
in |
the |
1557 |
|
4 . |
I |
will |
1550 |
|
5. |
to |
the |
1476 |
|
6. |
of |
the |
1355 |
|
7 . |
it |
is |
1069 |
|
8 . |
to |
be |
939 |
|
9. |
that I |
911 |
|
|
10 |
. I |
do |
810 |
Конечно, даже начинающему изучать английский язык сразу понятно, что перед нами одни из самых частотных сочетаний слов в языке вообще, и на первый взгляд кажется, что оригинальность стиля Великого барда с помощью этого, назовем так, Малого словника (Мел) Шекспира определить будет невозможно. По простому наличию этих коллокаций в любом тексте, разумеется, ничего не скажешь о стиле, зато по частотности разных коллокаций этого словника кое-что о стиле сказать будет можно. Для того, чтобы определить, насколько синтаксис текста (а малый словник явно отвечает за синтаксис, ибо состоит по преимуществу из служебных слов типа артиклей, предлогов, личных местоимений и глагольных связок!) приближается к шекспировскому, мы попробовали оценивать сумму мест по Мел (где единицы последовательно расположены от максимальной частоты вхождений к минимальной) первых ста коллокаций анализируемого текста. Например, так будет выглядеть начало списка для «Алисы в Стране Чудес» Л. Кэрролла:
|
N |
N(Мол) |
collocation |
quant |
quant(Мел) |
|
1 |
(6) |
of the |
125 |
1355 |
|
2 |
(47) |
in a |
97 |
436 |
|
3 |
(3) |
in the |
79 |
1557 |
|
4 |
(12) |
and the |
77 |
707 |
|
5 |
(5) |
to the |
69 |
1476 |
ПО
|
(= 73) |
|
6 (79) at the 60 329 |
|
7 (8) to be 48 939 |
|
8 (55) on the 34 413 |
|
9 (26) with the 33 532 |
|
10 (133) and then 29 235 |
(= 374)
Здесь N - позиция коллокации в частотном списке у Кэрролла, М(Мсл) - место той же коллокации в Мел, collocation - сама коллокация, quant - абсолютная встречаемость в «Алисе», quant(Mcn) - частота употреблений у Шекспира. В скобках со знаком «=» после пятой и десятой позиции - сумма мест по малому словнику.
В кратком виде, продолженном до 100-й позиции, это можно представить так:
|
Nposit |
positSum |
|
5 |
73 |
|
10 |
374 |
|
15 |
790 |
|
20 |
1313 |
|
25 |
1795 |
|
30 |
2385 |
|
40 |
3412 |
|
50 |
4592 |
|
75 |
7056 |
|
100 |
9284 |
Здесь Nposit - это позиция у Кэрролла, количество коллокаций в частотной для этого текста последовательности (от большей частоты употребления к меньшей), positSum - сумма мест, занимаемых этими коллокациями в Мел.
А так эти же списки будут выглядеть для «Ромео и Джульетты»:
|
N |
N(Мол) |
collocation |
quant quant(Мел) |
||
|
1 |
(4) |
I will |
60 |
1550 |
|
|
2 |
(1) |
I am |
53 |
1814 |
|
|
3 |
(3) |
in the |
41 |
1557 |
|
|
4 |
(2) |
I have |
37 |
1587 |
|
|
5 |
(7) |
it is |
34 |
1069 |
|
|
(= 17) |
|
|
6 |
(6) of the 33 1355 |
|
7 |
(5) to the 31 1476 |
|
8 |
(15) is the 30 676 |
|
9 |
(31) thou art 27 508 |
|
10 |
(126) is my 23 250 (= 200) |
|
Nposit |
positSum |
|
5 |
17 |
|
10 |
200 |
|
15 |
327 |
|
20 |
560 |
|
25 |
717 |
|
30 |
938 |
|
40 |
1650 |
|
50 |
2176 |
|
75 |
3883 |
|
100 |
6756 |
Чем меньше сумма мест у определенного числа коллокаций, скажем десяти, тем ближе «синтаксис» текста к шекспировскому, поскольку последовательность наиболее частотных слов больше соответствует Мел.
Собственно говоря, это весь инструментарий. Большой шекспировский словник, состоящий из 133 тысяч единиц (Бел) и малый шекспировский словник, состоящий из 218 единиц (Мел), - это то, с чем уже можно сравнивать реальные тексты, прежде всего на предмет наличия в них единиц этого словника.
Мы сравнивали со словниками три группы текстов:
1)каждую из 36 пьес Шекспира (корпус по 1 Фолио);
-
2) произведения современников, ближайших предшественников (пока собственно только «Кентерберийские рассказы» Дж. Чосера) и ближайших литературных потомков («Потерянный рай» Мильтона);
-
3) более поздние тексты на английском языке самых разных жанров (поэзия Байрона, Шелли, проза Стерна, Филдинга, Дефо, Свифта, Диккенса, Теккерея, Кэрролла, Стивенсона, Лондона, Элиот, Мелвилла, Марка Твена, Агаты Кристи, Герберта Уэллса, Андре Нортон, а также «История затмений» Чамберса, «Золотая ветвь» Фрэзера, «Очерки молочной бактериологии» Рассела).
Для каждого произведения мы посчитали количество присутствующих шекспировских коллокаций по Бел и Мел, а также их плотность, то есть частоту употребления на единицу текста. Плотность присутствия еди- ниц словника (P) получалась простым делением числа разных коллокаций на количество слов в тексте, а плотность общего количества употреблений (Р ) этих единиц (каждую коллокацию в тексте можно было употребить не один раз) получалась делением числа всех шекспировских коллокаций, найденных в тексте, на количество слов.
В первой группе текстов мы получили типичные шекспировские показатели, последовательно обработав все пьесы. Так, например, выглядит картина по «Антонию и Клеопатре» (23684 слова):
шекспировских коллокаций из Бел: 14980 14980 : 23684 = 0.632 (Р)
21659 : 23684 = 0.914 (Pusp)
шекспировских коллокаций из Мел: 218
218 : 23684 = 0.009 (Р)
1975 : 23684 = 0.083 (Pusp)
Первые две операции деления относятся к Бел, а последние две - к Мел. Наиболее стилеразличающие показатели - это Р по Бел и Рц$е по Мел. Особенно несущественным пока представляется показатель Р по Мел, поскольку при достаточных объемах текста он зависит почти исключительно от общего количества анализируемых слов.
А вот как для «Антония и Клеопатры» выглядит таблица суммы мест по Мел:
|
Nposit |
positSum |
|
5 |
19 |
|
10 |
107 |
|
15 |
231 |
|
20 |
415 |
|
25 |
608 |
|
30 |
794 |
|
40 |
1226 |
|
50 |
2083 |
|
75 |
3705 |
|
100 |
6169 |
Так представлены результаты анализа. По первой, шекспировской, группе текстов выведены средние показатели: сумма Р была разделена на 36, по числу пьес в Первом Фолио. (Далее в целях апробирования методики мы применяли ее к отрезкам текста в 2000, 5000 и 30000 (или сколько есть в произведении) слов. В таких случаях среднее выводилось делением суммы показателей на число отрезков).
для Бел -
Р = 0.672
Pus„= 0.996 для Мел -
Р = 0.010
Pusp = 0.095
Nposit positSum
|
5. |
26 |
|
10 . |
109 |
|
15. |
227 |
|
20 . |
429 |
|
25. |
622 |
|
30 . |
872 |
|
40 . |
1495 |
|
50 . |
2151 |
|
75. |
4198 |
|
100. |
6758 |
Все показатели текстов второй и третьей группы отличаются от шекспировских. То есть можно надеяться, что в результате описанных подсчетов получаются не случайные цифры, а системно отражающий внутренние характеристики текста набор численно выражаемых параметров, по которым можно сравнивать и различать тексты между собой.
Вторая группа распадается на тексты, которые существенно ближе к шекспировским по этим показателям, и все остальные. Возьмем сначала пример из «остальных»: первые 30 000 слов из «Кентерберийских рассказов»:
шекспировских коллокаций из Бел: 7745 7745 : 30000 = 0.258
15756 : 30000 = 0.525
шекспировских коллокаций из Мел: 191 191 : 30000 = 0.006
2396 : 30000 = 0.079
Nposit positSum

И словарь (Бел), и синтаксис (Мел) существенно отличаются от шекспировских показателей.
Следующий пример уже из группы более близких по стилевым показателям к Шекспиру произведений (Бен Джонсон «Cynthia’s Revels»):
шекспировских коллокаций из Бел: 9951 9951 : 30000 = 0. 359
17800 : 30000 = 0.648
шекспировских коллокаций из Мел: 214 214 : 30000 = 0.007
2719 : 30000 = 0.094
Nposit positSum 520
Коэффициент плотности по Бел для этого произведения лишь чуть-чуть повыше, чем у Чосера, зато плотность употребления Мел (0.094) почти идентична среднешекспировскому показателю (0.095), да и наиболее частотные коллокации по Мел - тоже вполне шекспировские (о/ the, in the, to the, of his, to be), что предположительно объясняется сильным влиянием стиля Шекспира на Джонсона. На сознательном уровне Джонсон, конечно, этого не хотел и от прямого (лексического) подражания стилю Шекспира уходил, однако на уровне синтаксиса не избежал влияния. Так можно попытаться проинтерпретировать эти данные.
А вот анализ одной из пьес Кристофера Марло с наиболее шекспировскими (по сравнению с другими произведениями Марло) показателями («Мальтийский Еврей»):
|
шекспировских 8834 : 23312 14455 : 23312 |
коллокаций из Бел: 8834 = 0.426 = 0.669 |
|
шекспировских 216 : 23312 = |
коллокаций из Мел: 216 = 0.010 |
1985 : 23312 = 0.086
|
Nposit positSum 5 22 10 82 15 180 20 533 25 742 30 1004 40 1595 50 2500 75 5123 100 7773 |
Главный коэффициент, конечно, маловат, однако синтаксис до 50 коллокаций прямо-таки среднешекспировский!
Далее. Возьмем одну из многих пьес, изданных анонимно. «Edmund Ironside»:
|
шекспировских 7101 : 15599 10308 : 15599 |
коллокаций из Бел: 7101 = 0. 4 61 = 0.669 |
|
шекспировских 204 : 15599 = |
коллокаций из Мел: 204 = 0. 013 |
1205 : 15599 = 0.078
|
Nposit positSum 5 27 10 138 15 326 20 617 25 893 30 1245 40 2005 50 2747 75 4946 100 7181 |
По главному показателю (0.461) эта пьеса существенно ближе к Шекспиру чем пьеса Джонсона, и несколько ближе, чем пьеса Марло. Не случайно это произведение постоянно фигурирует в числе претендентов на шекспировское авторство. Очень шекспировская сумма мест первого десятка коллокаций. Пьеса нуждается в более пристальном анализе.
Аналогичный случай с еще лучшими показателями по Мел. («Damon and Pithias»):
шекспировских коллокаций из Бел: 7565
7565 : 18546 = 0.407
12853 : 18546 = 0.693
шекспировских коллокаций из Мел: 206
206 : 18546 =0.011
1761 : 18546 = 0.094
Nposit positSum
|
5 10 15 20 25 30 40 50 75 100 |
20 160 351 545 845 1108 1762 2477 4753 7641 |
Теперь из серии так называемых апокрифов, пьес, еще в шекспировское время или чуть-чуть позднее изданных под авторством Шекспира, которое потом было оспорено.
«Arden Of Feversham»:
шекспировских коллокаций из Бел: 10730 10730 : 24686 = 0.434 17587 : 24686 = 0.712
шекспировских коллокаций из Мел: 216 216 : 24686 = 0.008 2216 : 24686 = 0.089
|
Nposit |
positSum |
|
5 |
20 |
|
10 |
137 |
|
15 |
286 |
|
20 |
429 |
|
25 |
586 |
|
30 |
849 |
|
40 |
1512 |
|
50 |
2096 |
|
75 |
4186 |
|
100 |
6877 |
Достаточно высокий показатель по Бел подкрепляется почти стопроцентным попаданием по Мел. Другие апокрифы также демонстрируют большую близость к шекспировским параметрам, чем другие тексты. Один из апокрифов уже давно признан шекспировским («Перикл»), хотя его показатели не намного лучше, чем у других апокрифов и даже немногим более шекспировские, чем у «Мальтийского Еврея» Марло:
шекспировских коллокаций из Бел: 8502
8502 : 18365 = 0.462
12481 : 18365 = 0. 679
шекспировских коллокаций из Мел: 212
212 : 18365 = 0.011
1422 : 18365 = 0.077
|
Nposit |
positSum |
|
5 |
19 |
|
10 |
103 |
|
15 |
263 |
|
20 |
527 |
|
25 |
800 |
|
30 |
922 |
|
40 |
1563 |
|
50 |
2380 |
|
75 |
4184 |
|
100 |
6746 |
А вот тексты, заведомо считающиеся шекспировскими, на этих поэмах впервые напечатано имя «Шекспир» («Венера и Адонис» и «Обесчещенная Лукреция» вместе, потому что так они дают более релевантный для подсчетов объем):

шекспировских коллокаций из Бел: 8363
8363 : 25213 = 0.331
12949 : 25213 = 0.513
шекспировских коллокаций из Мел: 194
194 : 25213 = 0.007
1346 : 25213 = 0.053
|
Nposit 5 |
positSum 112 |
|
10 |
390 |
|
15 |
655 |
|
20 |
910 |
|
25 |
1577 |
|
30 |
1984 |
|
40 |
2930 |
|
50 |
3616 |
|
75 |
6391 |
|
100 |
9265 |
Ничего показательно шекспировского, в сравнении с апокрифами например, в них не обнаружилось. Волей-неволей остается задуматься либо над тем, «из чего состоит Шекспир»: это группа авторов под единым брендом или псевдоним (опять-таки одного человека или, скажем, учителя с учениками), либо над тем, как влияют на стиль жанровые особенности. Хотя не исключено, что и над тем, и над другим вместе.
И сонеты Шекспира только подливают масла в огонь этих размышлений:
шекспировских коллокаций из Бел: 7438 7438 : 19425 = 0.382
11500 : 19425 = 0.592 шекспировских коллокаций из Мел: 204 204 : 19425 = 0.010 1368 : 19425 = 0.070
Nposit positSum 5
100 8038
Мы, разумеется, не собираемся вот так сразу - даже осторожно - выдвигать предположение, что сонеты написал не Шекспир или не один Шекспир, просто в них меньше шекспировских коллокаций 36-ти пьес, чем во многих других текстах его современников, апокрифах или анонимных произведениях. Возможно, сонеты - особая жанровая форма индивидуального стиля, где меньше повторного.
Кстати, именно компьютерные подсчеты уже выявляли заметную разницу (по другим параметрам) между сонетами и шекспировским драматическим каноном8, так что сам по себе этот, возможно, не бросающийся в глаза при чтении, но выводимый из строгой математической статистики стилистический зазор между «Шекспиром сонетов» и «Шекспиром 36-ти пьес» не новость.
Скорее новость - обсчет по нашим параметрам знаменитого произведения Роберта Грина, как полагают многие шекспироведы, злейшего завистника Шекспира. Как раз в этом произведении сделан первый прозрачный намек на «потрясателя сцены» (shake scene), собственно этим оно и знаменито (хотя на это произведение стоило бы обратить более пристальное внимание)9.
«Groats-worth of Witte, bought with a million of Repentance»:
шекспировских коллокаций из Бел: 4912
4912 : 11359 = 0.432
7087 : 11359 = 0.623
шекспировских коллокаций из Мел: 186
186 : 11359 = 0. 016
312 : 11359 = 0.085
Nposit positSum
|
5 |
43 |
|
10 |
130 |
|
15 |
400 |
|
20 |
587 |
|
25 |
893 |
|
30 |
1159 |
|
40 |
2128 |
|
50 |
3016 |
|
75 |
4931 |
|
100 |
7742 |

Эти параметры не намного, но лучше, чем у автора сонетов. Опять-таки опрометчиво было бы заявить, что Грин как автор «На грош ума...» чуть-чуть более Шекспир, чем автор «Шекспировых сонетов». И тут нужны дополнительные исследования, некоторые мы уже осуществили (см. ниже), предварительные результаты выводятся как частный случай применения нашей методики к более коротким отрезкам произведений.
Средние параметры Бел по 36 пьесам Шекспира по отрезкам текста в 2000 слов такие:
Р = 0.875 (0.871 -по другой методике определения среднего)
Puse = 0.996
Для сонетов и «На грош ума...» по Бел имеем:
|
№ отрывка (2000) |
Рсонетов по Бел |
№ отрыв ка (2000) |
Р «На грош ума» по Бел |
|
1 |
0,478 |
1 |
0,486 |
|
2 |
0,549 |
2 |
0,564 |
|
3 |
0,567 |
3 |
0,540 |
|
4 |
0,552 |
4 |
0,541 |
|
5 |
0,565 |
5 |
0,575 |
|
6 |
0,519 |
6 |
0,545 |
|
7 |
0,521 |
Ср. 0,542 |
|
|
8 |
0,570 |
||
|
9 |
0,559 |
||
|
Ср. 0,542 |
Удивительное рядом: средняя плотность шекспировских коллокаций совпала до тысячных долей коэффициента!
Очень близка средняя плотность в отрывках «Обесчещенной Лукреции», «Венеры и Адониса» и поэзии Эдварда де Вера («Венера и Адонис» - 0,450 - отличаются от поэзии де Вера вообще всего на 3 тысячных):
й
|
№ отрывка (2000) |
Р соединенных «Венеры и Адониса» и «Обесчещенной Лукреции» по Бсл |
№ отрыв ка (2000) |
Р лирики Э. де Вера по Бсл |
|
1 |
0.443 |
1 |
0.422 |
|
2 |
0.449 |
2 |
0.471 |
|
3 |
0.435 |
3 |
0.448 |
|
4 |
0.439 |
Ср. 0.447 |
|
|
5 |
0.481 |
0.443 |
|
|
6 |
0.478 |
0.449 |
|
|
7 |
0.450 |
0.435 |
|
|
8 |
0.456 |
0.439 |
|
|
9 |
0.484 |
0.481 |
|
|
10 |
0.489 |
2253 |
|
|
11 |
0.456 |
Ср. 0.450 |
Для «Венеры…»! |
|
12 |
0.422 |
||
|
Ср. 0.457 |
Третья группа произведений составляет отдаленный фон и в какой-то степени может тестировать работу системы. Достаточно показать плотность шекспировских коллокаций по Бсл. Курсивом выделены минимальные значения по каждому произведению, полужирным – максимальные. Для удобства и наглядности в таблице и ниже в текстах из коэффициентов мы будем приводить только цифры после запятой (например, 876 = 0,876), в четырехзначных числах первая цифра будет до запятой (1234 = 1,234).
|
№ отрывка (2000) |
Byron Childe |
Byron Juan |
Carroll Alice in Wonder land |
Chestert on The Ballad of the White Horse |
Chestert on The Defendant |
Christie Agatha The Mysterious Affair at Styles |
Christie Agatha The Secret Adversary |
Coleridge Shakespeare Ben Jonson |
Defoe The Further Adventures of Robinson Crusoe |
Dickens Bleak House |
Dickens David Copper field |
|
1 |
401 |
440 |
421 |
444 |
416 |
416 |
386 |
320 |
595 |
354 |
426 |
|
2 |
285 |
420 |
435 |
429 |
352 |
406 |
429 |
334 |
580 |
415 |
414 |
|
3 |
313 |
483 |
387 |
403 |
443 |
423 |
410 |
384 |
533 |
432 |
432 |
|
4 |
351 |
475 |
402 |
487 |
417 |
412 |
431 |
400 |
565 |
521 |
505 |
|
5 |
385 |
404 |
405 |
428 |
401 |
478 |
429 |
397 |
529 |
520 |
505 |
|
6 |
298 |
496 |
394 |
391 |
413 |
387 |
460 |
399 |
577 |
531 |
518 |
|
7 |
335 |
470 |
369 |
389 |
373 |
511 |
374 |
385 |
591 |
477 |
443 |
|
8 |
383 |
485 |
349 |
392 |
384 |
480 |
383 |
392 |
518 |
446 |
493 |
|
9 |
406 |
422 |
382 |
421 |
404 |
480 |
381 |
394 |
537 |
444 |
441 |
|
10 |
420 |
416 |
393 |
412 |
469 |
414 |
345 |
515 |
509 |
513 |
|
|
11 |
383 |
438 |
308 |
397 |
495 |
399 |
372 |
529 |
461 |
478 |
|
|
12 |
423 |
450 |
356 |
390 |
443 |
417 |
397 |
495 |
476 |
496 |
|
|
Среднее (ср. 431) |
365 |
450 |
383 |
420 |
400 |
450 |
409 |
377 |
547 |
466 |
472 |
|
Перепад стиля (ср. 105) |
138 |
92 |
127 |
98 |
91 |
124 |
86 |
80 |
100 |
116 |
104 |
Прежде всего стоит заметить, что все произведения относительно однородны по присутствию в разных отрывках шекспировских коллокаций: максимальный перепад значений (138) в «Чайльд Гарольде» Байрона, минимальный – в работе Кольриджа о младших современниках Шекспира (80), средним (нормальным) перепадом можно считать примерно 100 единиц. Таким образом, количество шекспировских коллокаций в художественных текстах – это вовсе не случайное число и является, как можно предварительно судить по этим данным, достаточно стабильным показателем стиля для определенного художественного произведения.
Мы видим, что отдаленный фон художественной литературы дает показатели от 365 (Байрон) до 547 (Дефо). За Дефо вслед идут два произведения Диккенса и одно Агаты Кристи. Средний показатель шекспировской плотности отдаленного фона 431.
С отдаленным фоном более или менее понятно: мы не думаем, что Дефо, Диккенс или Агата Кристи участвовали в создании текстов Шекспира. Наоборот, тексты Шекспира участвовали в создании Дефо и Диккенса. Тут все ясно: прямое и косвенное (через другие, также впитавшие Шекспи- ра тексты) влияние. Но возьмем произведения Роберта Грина, на которые вроде бы (по сложившимся шекспироведческим представлениям) Шекспир влиять не мог, поскольку в «На грош ума» заявлено о смерти Грина.
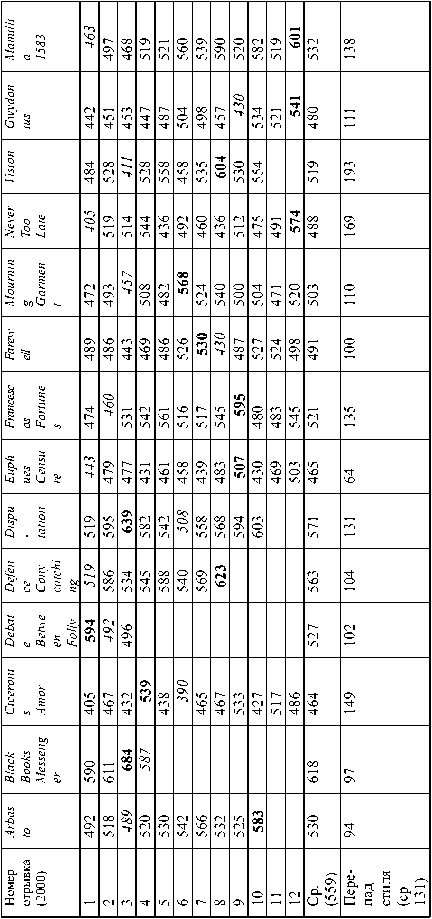

Средний показатель плотности коллокаций пьес Шекспира по 14 произведениям Грина впечатляет: 559, на 128 единиц выше, чем у отдаленного фона. Если исходить из того, что Шекспир не мог влиять на Грина, то в рамках классических представлений (Шекспир - это один единый автор, а Грин - другой единый автор) остается предполагать колоссальное влияние Грина на Шекспира. (Хотя теоретически можно предположить еще влияние какого-нибудь предшественника и на Грина, и на Шекспира, но на этой, черновой, стадии анализа такими тонкими вариантами влияний можно пренебречь). В этом, на первый взгляд, нет ничего невероятного. Юный будущий автор шекспировского канона зачитывался романами (романсами, точнее переводя, вернее просто калькируя, потому что английский термин romance мало общего имеет с нашими представлением как о романе, так и о романсе) и драмами Роберта Грина. Несколько настораживает уровень стилистического перепада как внутри отдельных произведений Грина (193, 169, 149: максимальные значения), так и между разными произведениями (перепад между средними показателями 154).
(Чтобы проверить гипотезу влияния Грина, нужно составить словники по Грину, аналогичные шекспировским, и сравнить с ними пьесы Шекспира и фона. Но эта проверка уже останется вне рамок данной статьи.)
Однако мы слишком рано нарушили наш собственный запрет на рассмотрение Шекспира как личности. Кто, собственно, дал нам право делать какие-то выводы о возрасте Шекспира и размышлять о том, что он мог читать в юности? Мы даже пока точно не знаем, один это автор или несколько. Мы знаем только, что Шекспир признан автором 36 пьес. Значит, и вернемся к анализу текстов Шекспира. Результаты анализа по Бел всех пьес Первого Фолио по 2000-м отрывкам тоже представим в виде таблиц.

|
1 |
3 |
о |
3 |
ОО |
5 |
8 |
ОО |
8 |
3 |
3 |
3 |
3 |
8 |
5 |
|||
|
£ |
Ох |
Ох |
ОО |
ОО |
ОО |
ОО |
3 |
^ |
£ |
ОО |
8 |
3 |
3 |
||||
|
1 |
8 |
о |
о |
о |
р |
8 |
3 |
8 |
ОО |
3 |
S |
8 |
о |
ОО |
о |
||
|
1S |
3 |
8 |
3 |
8 |
2 |
ОО |
3 |
о |
3 |
3 |
5 |
о |
S |
3 |
ОО |
||
|
1 |
5 |
3 |
3 |
о |
ОО |
о |
3 |
3 |
о |
3 |
3 |
00 |
о |
3 |
|||
|
£ |
ОО |
8 |
§ |
о |
8 |
о |
3 |
3 |
3 |
3 |
3 |
о |
3 |
о |
8 |
3 |
|
|
1 -2 Ло о |
*о |
со |
о |
S |
00 |
со |
о |
||||||||||
|
S д' ^ |
ОО |
ОО |
о |
ОО |
о |
8 |
ОО |
3 |
3 |
о |
8 |
S |
ОО |
о |
ОО |
ГЦ |
|
|
6 |
8 |
ОО |
со |
со |
S |
о |
S |
со |
о |
со |
ОО |
со |
о |
о |
00 |
||
|
5 |
3 |
3 |
Ох |
3 |
8 |
о |
о |
СО |
|||||||||
|
^ ^32 .3 |
8 |
о |
3 |
со |
8 |
3 |
3 |
3 |
3 |
3 |
о |
ОО |
|||||
|
Т S > -S $ > |
§ |
S |
о |
8 |
о |
3 |
S |
СО |
3 |
3 |
3 |
—<1 XDI |
о |
о |
|||
|
= § S § ^ ^и о |
ОО |
о |
о |
ОО |
ОО |
ОО |
3 |
3 |
S |
о |
3 |
3 |
3 |
3 |
|||
|
& । 5 о о К $ о S в 3 С |
ОО |
о |
сч |
со |
ио |
d и |
К с о |
|
i 'к 5 с^ о ^ |
ОО |
о |
ОО |
о |
S |
3 |
3 |
3 |
S |
8 |
оо |
о |
оо |
о |
|
|
§ о |
S |
со |
8 |
5 |
оо |
3 |
3 |
8 |
оо |
$ |
3 |
8 |
3 |
3 |
8 |
|
о о "S СС ~Q -Си О Ьо < о о к к |
3 |
S |
о |
3 |
оо |
3 |
о |
3 |
3 |
8 |
о |
8 |
X |
||
|
Й g Л^ |
8 |
ОО |
о |
ОО |
3 |
00 |
3 |
8 |
3 |
о |
3 |
ОО |
|||
|
i |
3 |
3 |
3 |
3 |
о |
S |
оо |
з |
si |
о |
8 |
||||
|
р4 S ^ Й 5 ? К |
о |
о |
3 |
3 |
о |
S |
3 |
оо |
3 |
со |
3 |
со |
3 |
||
|
^ Л g |
о |
о |
о |
ОО |
8 |
з |
о |
оо |
3 |
3 |
3 |
о |
о |
||
|
i .у |
ОО |
3 |
$ |
о |
5 |
3 |
8 |
ох |
3 |
3 |
3 |
£ |
|||
|
8 |
ОО |
3 |
3 |
о |
3 |
оо |
о |
3 |
8 |
к |
3 |
8 |
3 |
8 |
|
|
О |
3 ох |
3 |
3 ОО |
оо сц |
3 со |
о а |
3 40 |
ОО Ох |
3 сц |
8 |
|||||
|
^ д ^ |
3 |
3 |
3 |
о |
о |
3 |
3 |
3 |
3 |
оо |
8 |
о |
|||
|
^ S |
о |
5 |
3 |
ОО |
3 |
ОО |
3 |
3 |
S |
3 |
3 |
3 |
^ |
||
|
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
3 |
8 |
оо |
8 |
|||
|
о ■ g о S д о 1^5^ |
1—1 |
со |
XD |
оо |
ОХ |
о |
СЦ |
d О |
& 5 § К с о |

|
£ |
|||||||||||||||||
|
V £D О и a |
V £D О и a |
||||||||||||||||
|
S 5 |
3 |
ОО |
ОО |
оо |
ОО |
ОО |
со |
S |
о |
о |
ОО |
||||||
|
Е-< by 5 ^ |
ОО |
о |
S |
й |
о |
ОО |
g |
S |
8 |
||||||||
|
р 19 ^ К a U о |
о |
§ |
о |
^ |
ОО |
с§ |
о |
S |
Я |
о |
ОО |
о |
00 |
||||
|
ОО |
^ |
ОО |
ОО |
ОО |
ОО |
ОО |
3 |
ОО |
ОО |
о |
|||||||
|
о |
ОО |
оо |
о |
$ |
ОО |
§ |
СО |
5 |
$ |
о |
|||||||
|
к й ^ |
о |
9 |
ОО |
о |
ОО |
о |
g |
£ |
S |
S |
|||||||
|
ОО |
ОО |
о |
S |
ОО |
ОО |
Г^ |
о |
о |
о |
ОО |
|||||||
|
К к |
§ |
я |
о |
2: |
§ |
00 |
й |
§ |
я |
||||||||
|
^ 5 |
S |
S |
а\ |
о |
S |
о |
§ |
g |
ОО |
ОО |
ОО |
S| |
ах |
о |
|||
|
S |
ОО |
ОО |
ОО |
S |
ОО |
ОО |
m |
о |
о |
||||||||
|
& ■ g о ^ -е 5 8 |
1—1 |
in |
ОО |
О' |
о |
'—1 |
СЧ |
со |
и |
К С о |

(Подчеркиванием выделены последние отрывки произведений меньше 1000 слов, где плотность коллокаций может резко увеличиваться чисто математически.)
Пока мы можем определенно сказать, что средний перепад стиля между отрывками в 2000 слов внутри шекспировских произведений для 36 пьес равен 158 против 105 в отдаленном фоне. Даже у очень разношерстного Грина средний уровень стилистического перепада ниже (131). Причины этого могут быть как чисто математические (у Шекспира, естественно, больше шекспировских коллокаций, а значит, и больше колебания числа этих коллокаций), так и историко-лингвистические (период становления английского языка в эпоху Шекспира, с одной стороны, и более устоявшийся язык в более поздние времена, с другой стороны). В любом случае, исходя лишь из анализа по Бел как пьес в целом, так и их отрывков по 2000 слов, мы пока не находим оснований сокращать шекспировский корпус.
Однако, проанализировав полученные данные, мы можем подозревать участие соавторов в некоторых пьесах. Например, начальные 2000 слов «Тита Андроника» резко выбиваются по коэффициенту шекспировских коллокаций, но не так резко, чтобы наши подозрения превратились сразу в нечто большее, хотя ученые сейчас практически не сомневаются в участии в пьесе нешекспировской руки, точнее руки Джорджа Пила. То есть, именно говоря об этом произведении, мы можем в какой-то степени проверить адекватность методики. Если отрывки, где у нас подозревается соавторство, совпадут с отрывками неШекспира, полученными по другим методикам, значит, методики первый тест на адекватность выдержали. Если не совпадут, потребуется коррекция, правда, чьей методики (нашей или иных), заранее сказать трудно.
Большинство исследователей, занимавшихся проблемой атрибуции «Тита Андроника» и признававших факт соавторства, сходятся во мнении, что Дж. Пил написал первый акт, первую сцену второго акта и первую сцену четвертого акта. Тесты, проведенные с помощью компьютеров, это подтверждают10. Все эти исследования подсчитывали самые разные, но частные показатели стиля, начиная от соотношения мужских и женских окончаний стихов и кончая количеством более чем двусложных слов. Проведенный с помощью практического полного словника шекспировских коллокаций (133 тысячи единиц) анализ пьесы, последовательно разбитой на 2000-е и 1000-е отрывки, приводит к частично похожим выводам:
|
Номер фрагмента (2000) |
Акт, сцена «Тита Андроника» |
Плотность 2000-х |
Плотность 1000-х |
Номер фрагмента (1000) |
|
1 |
1 акт |
756 |
807 |
1 |
|
807 |
2 |
|||
|
2 |
1 акт |
848 |
868 |
3 |
|
905 |
4 |
|||
|
3 |
1 акт (248 слов) 2 акт 1 сц. 752 |
797 |
869 |
5 |
|
2.1. (295 слов) 2.2. |
773 |
6 |
||
|
4 |
2.2. 2.2. |
873 |
912 |
7 |
|
905 |
8 |
|||
|
5 |
2.2. 2.2. + 3.1. (207 слов) |
839 |
841 |
9 |
|
888 |
10 |
|||
|
6 |
3 акт 2 сц. и |
859 |
930 |
11 |
|
4 акт 1 сц. (1012 слов) |
844 |
12 |
||
|
7 |
4 акт 1 сц. (22 слова) |
852 |
901 |
13 |
|
884 |
14 |
|||
|
8 |
863 |
902 |
15 |
|
|
882 |
16 |
|||
|
9 |
946 |
975 |
17 |
|
|
1007 |
18 |
|||
|
10 |
813 |
830 |
19 |
|
|
855 |
20 |
|||
|
Среднее: |
845 (по 36 пьесам 871) |
897 (по 36 пьесам 901) |
Хотя мы видим, что наши 2000-е отрывки, естественно, не совпадают с делением по сценам, какие-то предварительные выводы сделать можно. Например, можно однозначно подтвердить, что текст первой половины 1 акта (чуть меньше) имеет показатель плотности коллокаций наименее шекспировский. Если признать, что соавтором был Пил, то самое начало в 2000 слов написал именно он. Затем 2000 слов идут со вполне шекспировскими показателями плотности. Возможно, вторую половину 1 акта все-таки написал главный Шекспир (условно пишем так, потому что при некоторых выводах из стилистических исследований и самого Пила логично считать Шекспиром). Самые последние 248 слов 1 акта и 1 сцена 2 акта (1047 слов) входят в нашу третью порцию по 2000 слов, которая имеет показатель плотности ниже среднего по пьесе и ниже среднего по 36 пьесам.
Вполне можно предположить авторство Пила. А вот последний отрывок, обычно приписывающийся Пилу, мы по анализу 2000-х отрывков атрибу тировать не можем, потому что он занимает лишь половину нашего шестого отрезка текста и самое начало седьмого. Однако и по анализу 1000-х отрывков картина получается неоднозначная. С одной стороны, наш 12-й отрывок, в который почти полностью вмещается подозреваемая на авторство Пила 1 сцена 4 акта, достаточно резко отличается от предыдущего, 11-го и последующего, 13-го. С другой стороны, в целом 12-й отрывок в 1000 слов вполне вписывается в шекспировские показатели. Если этот 12-й отрывок считать нешекспировским, то и 9, и 19 отрывок тоже нужно счи тать нешекспировскими по этим показателям.
Однако в целом наши результаты не противоречат результатам, полученным по другим методикам, да и, конечно, сами методики, которые сейчас применяются, наш подход никоим образом не отрицает. Главное отличие предлагаемой методики состоит в глобальности стилистического анализа: это сплошной анализ текста, который раньше можно было проводить только в ручном режиме, а значит, охватывались только незначительные отрезки текста в единицу времени, сопоставимую с творческой жизнью исследователя.
Список литературы На подступах к геному стиля Шекспира
- Bolton W. The Bard in Bits: Electronic Editions of Shakespeare and Programs to Analyze Them//Computers and the Humanities. 1990. Vol. 24. №. 4 (Aug.). P. 275-287
- Lowe D., Matthews R. Shakespeare Vs. Fletcher: A Stylometric Analysis by Radial Basis Functions//Computers and the Humanities. 1995. Vol. 29. № 6 (Dec.). P. 449-461
- Elliott W.E., Valenza R.J. A Touchstone for the Bard//Computers and the Humanities. 1991.Vol. 25. № 4 (Aug.). P. 199-209
- Eftekhari A. Fractal geometry of texts: An initial application to the works of Shakespeare//Journal of Quantitative Linguistics. 2006. Vol. 13. № 2-3. P. 177-193
- Simonton D.K. Lexical Choices and Aesthetic Success: A Computer Content Analysis of 154 Shakespeare Sonnets//Computers and the Humanities. 1990. Vol. 24. № 4 (Aug.). P. 251-264
- http://research.cs.wisc.edu/niagara/data/shakes/shaksper.htm
- Ward E.Y. Elliott and Robert J. Valenza. Shakespeare’s Vocabulary: Did it Dwarf All Others?//Stylistics and Shakespeare’s Language/Eds Mireille Ravassat and Jonathan Culpeper. London; New York, 2011. P. 34-41
- Zhang Katherine T., Zhang Zhiyi. Shakespearean Sonnets versus Shakespearean Canon//Journal of Quantitative Linguistics. 2010. Vol. 17. № 2. P. 81-93
- Пешков И.В. Почему Роберт Грин за грош ума (остроумия) каялся на миллион, или Львиная природа авторства//Бестиарий в словесности и изобразительном искусстве. М., 2012. С. 97-126
- MacDonald P. Jackson. Studies in Attribution: Middleton and Shakespeare. Salzburg, 1979. P. 147-153
- Tarlinskaja M. Shakespeare's Verse: Iambic Pentameter and the Poet's Idiosyncrasies. New York, 1987. P. 121-124
- Vickers B. Shakespeare, Co-Author: A Historical Study of Five Collaborative Plays. Oxford, 2002. P. 219-239
