Нейросетевая детекция голосовой активности для распознавания речи в реальном времени

Автор: Петряшин И. Е., Юдин Д. А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (60) т.15, 2023 года.
Бесплатный доступ
В статье исследуется задача распознавания речи в зашумленной среде в реальном времени. Предлагается оригинальный подход адаптации современных нейросетевых алгоритмов детекции голосовой активности RealVADR для решения задачи распознавания речи в реальном времени с использованием обработки интервалов звука. Рассматривается влияние параметров данного алгоритма на качество распознавания речи, а также методы оптимизации его параметров. Проведены эксперименты как на существующем открытом наборе данных CommonVoice, так и на нескольких собственных наборах данных, собранных в шумной робототехнической среде. Они показали, что применение предложенного подхода позволяет получить в реальном времени качество распознавания, сравнимое с офлайн-распознаванием.
Распознавание речи, детекция голосовой активности, нейронная сеть, алгоритм, набор данных
Короткий адрес: https://sciup.org/142240001
IDR: 142240001 | УДК: 004.032.26
Real-time neural network voice activity detection for speech recognition
The paper investigates the task of real-time speech recognition in a noisy environment. We propose an original approach of adapting modern neural network algorithms of voice activity detection RealVADR to solve the problem of real-time speech recognition using sound interval processing. The influence of the parameters of this algorithm on the quality of speech recognition is considered, as well as methods of optimising its parameters. Experiments have been conducted both on the existing open dataset CommonVoice and on several custom datasets collected in a noisy robotic environment. They showed that the application of the proposed approach allows obtaining in real time a recognition quality comparable to offline recognition.
Текст научной статьи Нейросетевая детекция голосовой активности для распознавания речи в реальном времени
Решение задачи распознавания речи является актуальным для множества, областей. Так, например, актуальными задачами являются распознавание речи в телефонных звонках и видеоконференциях, голосовое управление роботом и др.
Современные методы распознавания речи (ASR), такие как [1,2], достигают результатов, превосходящих качество распознавания, выполняемого человеком. Однако эффективность этих методов сильно зависит от условий записи звука, и его характеристик [3].
Для таких задач, как голосовое управление роботом, критичным является время, за которое обрабатывается сказанная команда. По этой причине необходимо использование алгоритмов, которые позволяют выделять из аудиопотока интервалы, содержащие голосовую активность. Эту задачу успешно решают нейросетевые алгоритмы детекции голосовой активности (VAD), такие как [4,5]. При этом качество работы этих алгоритмов практически не зависит от условий записи и характеристик аудио.
Однако применение нейросетевых моделей VAD в реальном времени ограничивается тем, что они предназначены для обработки предварительно записанных аудио и не оптимизированы для сценариев, в которых аудио поступает в систему фрагментированно.
В данной работе предлагается метод RealVADR, адаптирующий модели VAD для реального времени, который позволяет обрабатывать аудио с заданной заранее задержкой. Рассмотрено, как параметры предложенного метода влияют на качество современных моделей распознавания, а также показано, как приблизить качество распознавания в реальном времени к качеству офлайн-распознавания.
Программный код предложенного подхода и собранные наборы данных размещены в открытом доступе по ссылке
Также разработан датасет для распознавания речи, собранный в шумной робототехнической среде.
2. Методы распознавания речи и детекции голосовой активности
Современные методы распознавания речи основаны на использовании нейросетевых моделей [1,2,6-10]. Данные методы показывают качество, превосходящее качество распознавания человека, на датасетах, которые были использованы для их обучения [11-13]. Однако на данных, которые сильно отличаются от обучающих, например уровнем шума, качество работы данных методов ухудшается.
На данный момент методами, показывающими наилучшее качество, являются wav2vec2-xlsr [9] и Whisper [2]. wav2vec-xlsr представляет собой совокупность предобученной на множестве неразмеченных аудио моделей для извлечения признаков и построенной на ее выходе акустической модели, которая обучается на размеченных аудио. Whisper представляет собой классический трансформер, обученный на большом количестве размеченнных аудио с использованием многозадачного метода обучения, за счет чего показывает хорошее качество на всем разнообразии аудио.
Задача детекции голосовой активности является более тривиальной задачей, поскольку представляет собой задачу классификации каждого отсчета аудио на содержащие и не содержащие голосовую активность. Качество нейросетевых алгоритмов [4,5], решающих данную задачу, близко к идеальному, независимо от условий записи и характеристик аудио.
3. Детекция голосовой активности
Имеется последовательность отсчетов аудио S = ( s i ,...,s t )• Задача детекции голосовой активности представляет собой задачу классификации каждого отсчета аудио на К-классов (в классической постановке К = 2):
Р = / (S ), (1)
где /(•) — нейросетевая модель детекции; Р — вектор вероятности принадлежности отсчетов к каждому из К-классов размерности К х Т.
В качестве класса для каждого отсчета обычно выбирается тот, вероятность которого максимальна:
У = argmax(P). (2)
к
Выход модели детекции f (•) также подвергается процессу постобработки для извлечения из аудиоинтервалов, которые задаются отсчетами начала и конца голосовой активности [14].
4. Детекция в реальном времени
В условиях реального времени последовательность отсчетов S не является фиксированной. Кроме того, необходимо для каждого приходящего интервала голосовой активности устанавливать, начался в нем новый отрезок голосовой активности или продолжается предыдущий. По этой причине невозможно напрямую использовать существующие алгоритмы VAD.
Поскольку интервалы голосовой активности поступают последовательно, необходимо хранить в буфере предыдущие интервалы, в которых была обнаружена голосовая активность, и на основании совместного анализа буфера и пришедшего интервала устанавливать, какому из следующих случаев соответствует ситуация:
-
• в интервале началась активность,
-
• в интервале продолжается активность,
-
• в интервале кончилась активность,
-
• в интервале кончилась активность и началась новая.
Кроме того, в рассмотрение необходимо принять величину порога, задающего максимальное расстояние между двумя последовательными детектированными интервалами речи. Если расстояние между интервалами больше порога, считается, что это два разных интервала речи, иначе считается, что это один интервал.
Тогда для анализа всевозможных наблюдаемых случаев достаточно ввести в рассмотрение три условия:
-
• а - пришедший интервал содержит голосовую активность,
-
• bi ~ предыдущие фрагменты буфера содержат голосовую активность,
-
• b2 — дистанция между началом голосовой активности пришедшего интервала и концом голосовой активности буфера меньше заданного порога.
Таблица!
Действия для выражений
|
Условие |
Случай |
Действие |
|
а Л —bi |
I |
Буфер дополняется пришедшим интервалом |
|
а Л Ь1 |
II |
Буфер дополняется пришедшим интервалом |
|
—а Л bi Л b2 |
III |
Элементы буфера с голосовой активностью объединяются в аудио, затем буфер обновляется |
|
а Л bi Л —b2 |
IV |
Элементы буфера с голосовой активностью объединяются в аудио, затем буфер обновляется, и в него добавляется пришедший интервал |
В табл. 1 представлены соответствующие наборы условий для каждого случая, а также указаны действия, которые необходимо выполнить с буфером и входящим интервалом. На основании данных условий представлен псевдокод алгоритма RealVADR 1.
Предложенный алгоритм оперирует всего двумя параметрами: размером входящего звукового интервала и пороговым значением. Для правильной настройки порога важно учесть естественные характеристики конкретного языка, на котором будет применяться данный алгоритм.
При определении размера интервала следует учесть, что алгоритм RealVADR выполняет прогнозирование после завершения каждого интервала, поэтому его продолжительность должна быть не меньше времени, необходимого для работы базовой модели VAD. С другой стороны, размер интервала также влияет на общую задержку алгоритма, поэтому важно найти баланс между размером интервала и количеством предсказаний, выполняемых мо делью.
Данный алгоритм был протестирован на русскоязычной части датасета CommonVoice [11], а также на датасете голосовых команд, собранных на роботе Husky. Оказалось, что оптимальной величиной порога является 100-500 мс, а оптимальным размером интервала 60-200 мс. На рис. 1 демонстрируется, как работает алгоритм (красным выделены интервалы, помещенные в буфер, зеленым - элементы буфера, объединенные в аудио).
Algorithm 1: Алгоритм обработки интервалов звука RealVADR
з
Data: buffer, newinterval, threshold
Result: updatedbuffer a = f(buffer, new interval) is not None ;
bi = buffer is not None ;
b2 = (maxrightbound(buffer) maxleft bound(newinterval)^
if a then
threshold
Добавить интервал в буфер;
if bi & -ib-2 then
Объединить элементы буфера с голосовой активностью в аудио;
Отправить аудио па распознавание;
Обновить буфер;
Добавить интервал в буфер else
Продолжить обработку следующих интервалов;
end else
if bi & Ьг then
Объединить элементы буфера с голосовой активностью в аудио;
Отправить аудио па распознавание;
Обновить буфер;
else
Продолжить обработку следующих интервалов;
end
end
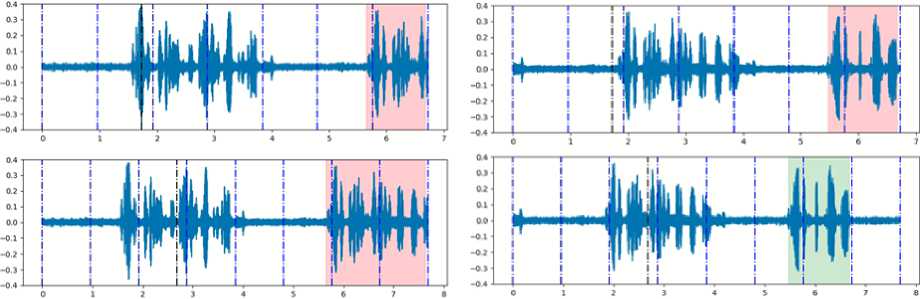
Рис. 1. Иллюстрация работы алгоритма.
5. Распознавание речи
Имеется последовательность отсчетов аудио О = (оі,...,от), которая выделена при помощи алгоритма RealVADR.
В статистической формулировке задача распознавания состоит в предсказании наиболее вероятной последовательности слов при условии наблюдаемой последовательности:
Н = argmax Р (Н |О). (3)
н
Качество предсказания оценивается метриками WER (word error rate) и CER (character error rate) [15], которые сравнивают предсказанный текст с оригинальным:
WER =
S + D + I N
100 =
S + D + 1
S + D + С
• 100 ,
где S - количество 'замен. D - количество удалений. I - количество вставок. С - количество корректных слов.
CER считается таким же образом, но все операции выполняются на уровне символов.
6. Эксперименты
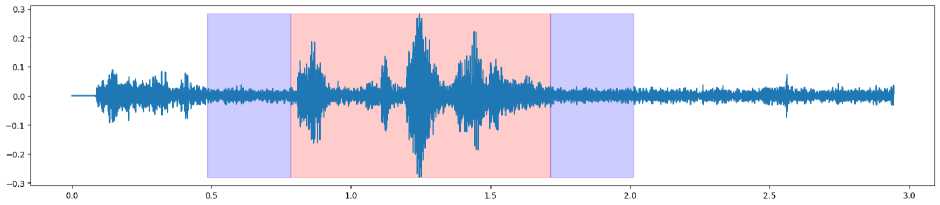
Рис. 2. Детектировапппый звук с добавленным зазором
Датасеты. Поскольку предложенный алгоритм используется для построения системы распознавания речи в реальном времени, его качество оценивается исходя из качества на датасетах для распознавания речи.
Для тестирования алгоритма RealVADR был создан датасет, записанный на роботе Husky в условиях шума, создаваемого роботом. Датасет состоит из коротких команд для робота и имеет четыре части:
-
• clear_voice - команды, записанные в условиях без шума,
-
• noise_voice_lm - команды, записанные в условиях шума, на расстоянии 1 м от робота,
-
• noise_voice_2m - команды, записанные в условиях шума на расстоянии 2 м от робота,
-
• road_voice - команды, записанные на фоне едущего робота.
Кроме того, для тестирования алгоритма используется тестовая выборка русскоязычной части датасета CommonVoice [11].
Влияние VAD на качество распознавания. Было замечено, что при использовании результатов VAD в качестве входных данных для моделей распознавания напрямую, качество оказывается хуже, чем при использовании целых аудио из датасета.


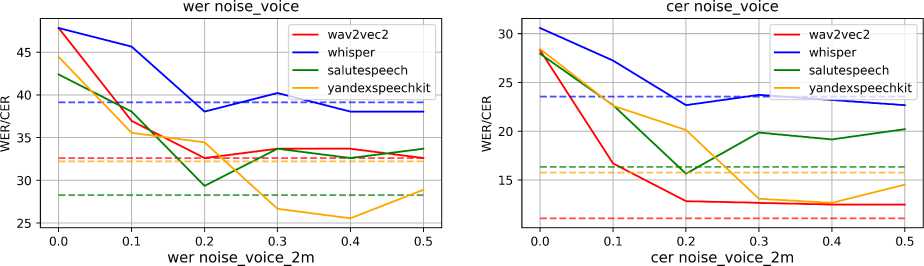
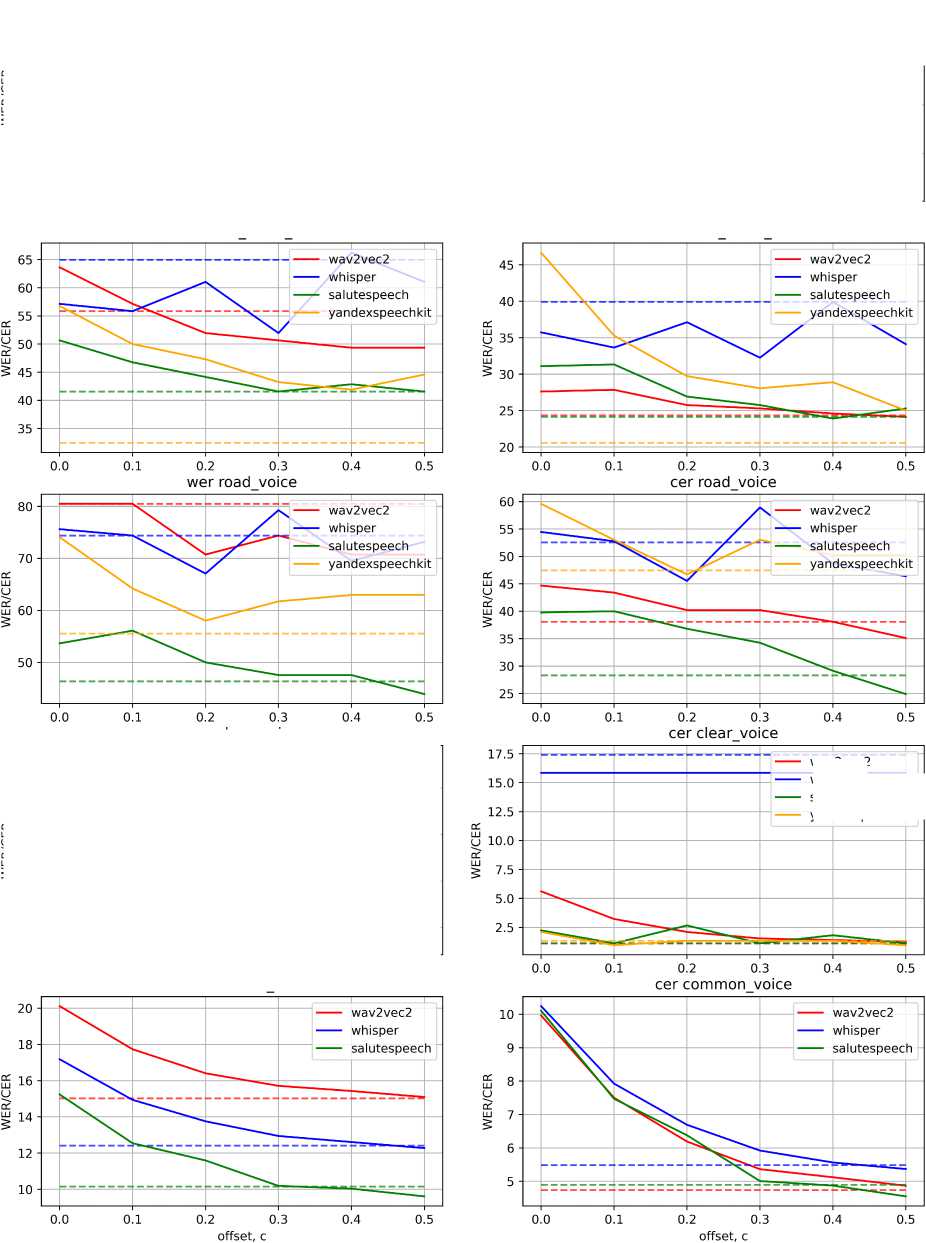
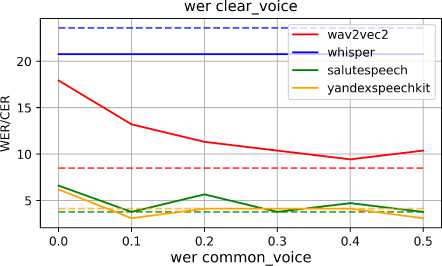
Рис. 3. Зависимость качества распознавания речи WER и CER от величины зазора, используемой в подходе RealVADR
wav2vec2
whisper salutespeech yandexspeechkit
Следует отметить, что результаты VAD обладают следующей особенностью: детектированные интервалы начинаются/заканчиваются ровно в моменты начала/окончания речи и не имеют отрезков без речи. С точки зрения распознавания это означает, что для модели недоступны отрезки, показывающие уровень шума в среде без голосовой активности, что, скорее всего, и приводит к снижению качества, то есть между выходным распределением данных VAD и входным распределением данных моделей ASR имеется сдвиг.
В связи с этим логично добавить к результатам VAD зазор, не содержащий голосовой активности, как это показано на рис. 3. Такое преобразование может позволить устранить сдвиг в данных и улучшить качество распознавания.
Для экспериментов по оценке влияния величины зазора на качество распознавания было рассмотрено четыре модели: Whisper-large-v2, wav2vec2-xls-r-lb-russian, а также сервисы распознавания речи YandexSpeechKit и SaluteSpeech.
На рис. 3 показано, как зависят метрики CER и WER рассмотренных моделей для выбранных датасетов от величины зазора. Разными цветами показаны графики для рассмотренных моделей, а пунктирными линиями — офлайн-метрики моделей.
Для всех случаев характерно значительное улучшение метрик по сравнению с нулевым значением зазора (улучшение достигает порядка 10-15 единиц WER и CER), что говорит о возможности улучшения метрик путем введения зазора и устранении сдвига распределения между выходными данными модели VAD и входными данными моделей ASR.
Для наименее зашумленных датасетов clear_voice и CommonVoice метрики CER и WER улучшаются при увеличении зазора. При достижении зазором значения 0.5 метрики большинства моделей распознавания сравниваются с офлайн-метриками, а в некоторых случаях и незначительно превосходят их.
Для более зашумленных частей датасета такая зависимость также прослеживается, однако при увеличении зазора выше 0.2 с наблюдается флуктуация метрик и в некоторых случаях, например в случае с Whisper и YandexSpeechKit, они перестают улучшаться.
Опираясь на построенные графики, можно взять значение зазора 0.2 с за оптимальное и зафиксировать. В таком случае можно сравнить офлайн-метрики и значения метрик для всех алгоритмов при выбранном значении зазора. Данное сравнение приведено в табл. 2.
Можно отметить, что значения метрик для данной величины зазора незначительно хуже офлайн метрик (ухудшение составляет в среднем 1-5 единиц WER или CER), то есть итоговая система распознавания речи в реальном времени, построенная на основе метода RealVADR, будет близка по качеству к офлайн-распознаванию.
Т а б л и ц а 2 Сравнение метрик качества WER/CER методов на различных наборах данных
|
Метод |
noise voice Im |
noise voice 2m |
road voice |
clear voice |
commonvoice |
|
wav2vec2 (offline) |
32.60 / 11.07 |
55.84 / 24.36 |
80.48 / 38.05 |
8.49 / 1.12 |
15.01 / 4.74 |
|
Real VADR( wav2vec2) |
32.60 / 12.82 |
51.94 / 25.75 |
70.73 / 40.21 |
11.32 /2.10 |
16.40 / 6.19 |
|
Whisper (offline) |
39.30 / 23.55 |
64.93/ 39.91 |
74.39 / 52.55 |
23.58 / 17.39 |
12.41 / 5.48 |
|
Real VADR( Whisper) |
38.04 / 22.67 |
61.03 / 37.12 |
67.07 / 45.54 |
20.75 / 15.84 |
13.75 / 6.69 |
|
YandexSpeechKit (offline) |
32.22/ 15.76 |
32. 43/ 20.55 |
55.55 / 47.47 |
4.12 / 1.34 |
/ |
|
RealVADR( YandexSpeech) |
34.44 / 20.12 |
47.29 / 29.72 |
58.02 / 46.71 |
4.12 / 1.34 |
/ |
|
SaluteSpeech (offline) |
28.26 / 16.34 |
41.55 / 24.12 |
46.34 / 28.29 |
3.77 / 1.12 |
10.15 / 4.89 |
|
RealVADR (SaluteSpeech) |
29.34 / 15.64 |
44.15 / 26.91 |
50.00 / 36.81 |
5.66 / 2.66 |
11.59 / 6.37 |
7. Выводы
В работе предложен и описан алгоритм RealVADR, позволяющий адаптировать существующие методы детекции голосовой активности к условиям реального времени, когда звук поступает частями. Метод имеет всего два параметра, что позволяет эффективно его оптимизировать.
Исследовано, как влияют параметры предложенного алгоритма на качество распознавания современных моделей. Показано, что регулирование зазора при обработке результатов детекции голосовой активности позволяет значительно улучшить качество распознавания и приблизить его к качеству офлайн-распознавания.
Работа выполнена при поддержке Аналитического центра при Правительстве Российской Федерации в соответствии с договором о субсидии (идентификатор договора 000000D730321P5Q0002; грант № 70-2021-00138).
Список литературы Нейросетевая детекция голосовой активности для распознавания речи в реальном времени
- Schneider S., Baevski A., Collobert R., Auli M. wav2vec: Unsupervised Pre-training for Speech Recognition // CoRR. 2019. V. abs/1904.05862. arXiv: 1904.05862.
- Radford A., Kim J.W., Xu T., Brockman G., McLeavey Ch., Sutskever I. Robust Speech Recognition via Large-Scale Weak Supervision // Proceedings of the 40th International Conference on Machine Learning. 2023. N 1182. P. 28492–28518.
- Iashchenko A., Andreev P., Shchekotov I., Babaev N., Vetrov D. UnDiff: Unsupervised Voice Restoration with Unconditional Diffusion Model // arXiv preprint arXiv:2306.00721. 2023.
- Bredin H., Yin R., Coria J.M., Gelly G., Korshunov P., Lavechin M., Fustes D., Titeux H., Bouaziz W., Gill M.-P. pyannote.audio: neural building blocks for speaker diarization // arXiv: 1911.01255.
- Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier. 2021.
- Baevski A., Zhou H., Mohamed A., Auli M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations // CoRR. 2020. V. abs/2006.11477. arXiv: 2006.11477.
- Baevski A., Schneider S., Auli M. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations // CoRR. 2019. V. abs/1910.05453. arXiv: 1910.05453.
- Baevski A., Hsu W., Conneau A., Auli M. Unsupervised Speech Recognition // CoRR. 2021. V. abs/2105.11084. arXiv: 2105.11084.
- Conneau A., Baevski A., Collobert R., Mohamed A., Auli M. Unsupervised Cross-lingual Representation Learning for Speech Recognition // CoRR. 2020. V. abs/2006.13979. arXiv: 2006.13979.
- Gandhi S., von Platen P., Rush A.M. Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling // arXiv: 2311.00430 2023.
- Ardila R., Branson M., Davis K., Henretty M., Kohler M., Meyer J., Morais R., Saunders L., Tyers F. M., Weber G. Common voice: A massively-multilingual speech corpus // arXiv preprint arXiv:1912.06670. 2019.
- Karpov N., Denisenko A., Minkin F. Golos: Russian dataset for speech research // arXiv preprint arXiv:2106.10161. 2021.
- Panayotov V., Chen G., Povey D., Khudanpur S. Librispeech: an asr corpus based on public domain audio books // 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE. 2015. P. 5206–5210.
- Mihalache S., Ivanov I.A., Burileanu D. Deep Neural Networks for Voice Activity Detection // 2021 44th International Conference on Telecommunications and Signal Processing (TSP). IEEE. 2021. P. 191–194.
- Ali A., Renals S. Word error rate estimation for speech recognition: e-WER // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. P. 20–24.
