Нейросетевые методы распознавания дорожных знаков в режиме реального времени

Автор: Бабаев А.М.
Журнал: Форум молодых ученых @forum-nauka
Статья в выпуске: 11-1 (27), 2018 года.
Бесплатный доступ
В статье рассматриваются топологии искусственных нейронных сетей в контексте задачи распознавания дорожных знаков. Было выполнено сравнение наиболее популярных регрессионных детекторов объектов на изображении. Главный акцент был сделан на выявление точного и не требовательного к вычислительным ресурсам алгоритма, способного выполнять поставленную задачу даже на мобильных устройствах.
Свёрточная нейронная сеть, распознавание объектов, локализация объектов, регрессионный детектор объектов, дорожные знаки
Короткий адрес: https://sciup.org/140280241
IDR: 140280241
Neural network methods of recognition of road signs in real time
The article discusses the topology of artificial neural networks in the context of the task of recognizing road signs. A comparison was made of the most popular regression detectors of objects in the image. The main emphasis was placed on the identification of an exact and not demanding to computing resources algorithm capable of performing the task even on mobile devices.
Текст научной статьи Нейросетевые методы распознавания дорожных знаков в режиме реального времени
Задача эффективной локализации и распознавания дорожных знаков на изображениях в режиме реального времени актуальна в связи с большим распространением беспилотных автомобилей. Также системы распознавания дорожных знаков оказывают помощь и водителям, давая им рекомендации в различных ситуациях на дороге.
Внешняя простота задачи является иллюзией. С одной стороны, дорожные знаки идеально подходят для задач распознавания изображений, так как каждый знак имеет четко стандартизированные размер и набор цветов и всегда устанавливается в одном положении. Но при тестировании систем распознавания знаков в реальных условиях дорожного движения выяснилось, что точность их работы значительно снижается из-за:
-
- различного уровня освещенности (знаки будут существенного отличаться по цвету в утреннее и вечернее время);
-
- различных точек наблюдения (знак будет наблюдаться под различными углами);
-
- наличия предметов, частично перекрывающих изображение знака с точки зрения наблюдателя.
Методы, применяемые для распознавания дорожных знаков, можно разделить на две группы [1]:
-
1. Распознавание на основе цвета и формы объекта.
-
2. Распознавание с помощью машинного обучения.
Технологии, относящиеся к первой группе, не могут быть использованы на практике: при различных точках и времени наблюдения за знаком его форма и цвет меняются в широких пределах. Поэтому на практике применяются либо только методы машинного обучения, либо комбинация методов первой и второй группы. В качестве основы системы распознавания дорожных знаков исследователи предлагают использовать детектор SURF [1], метод опорных векторов [2], двухслойную нейронную сеть прямого распространения [3], трехслойную свёрточную нейронную сеть [4].
Перечисленные методы имеют ряд недостатков, среди которых недостаточно высока точность (не более 89%), высокая вычислительная сложность, низкая устойчивость к небольшим искажениям на изображении. В связи с этим была поставлена задача разработки алгоритма распознавания дорожных знаков, обладающего точностью классификации выше 90% и низкой вычислительной сложностью. В качестве основы разрабатываемой системы было решено использовать свёрточные нейронные сети, которые за последние 6 лет совершили прорыв в области компьютерного зрения.
Особенности архитектуры свёрточных нейронных сетей
Свёрточные нейронные сети – это разновидность искусственных нейронных сетей. В общем случае свёрточная нейронная сеть состоит из комбинации нескольких слоев, выполняющих различные функции:
-
a) Свёрточный слой, в котором выполняется операция свёртки. Заключается она в том, что к входному изображению применяется матричный фильтр, кодирующий определенный признак на изображении, например, линии или углы. Обычно применяют матрицу размером 3×3. Для более эффективной работы CNN в каждом свёрточном слое изображение обрабатывается несколькими фильтрами. Благодаря этому формируется несколько карт признаков, что делает нейронную сеть многомерной. Процесс обучения такого слоя заключается в настройке ядер свёртки с помощью метода обратного распространения ошибки.
-
б) Слой субдискретизации (pooling), которые используются для понижения размерности карт признаков. Для снижения размерности вся карта признаков делится на непересекающиеся участки размером 2х2 нейрона, после чего применяется один из двух подходов: max pooling – из четырех нейронов каждой области выбирается нейрон с наибольшим значением и принимается за один нейрон в уменьшенной карте признаков –, или average pooling – один нейрон в уменьшенной карте признаков соответствует среднему значению нейронов в первоначальной карте. Благодаря данному слою уменьшается количество настраиваемых
параметров свёрточной нейронной сети. Кроме того, нейронная сеть становится инвариантна к смещению объекта и изменению его формы.
-
в) На выходе последнего слоя субдискретизации устанавливаются несколько слоев многослойной нейронной сети, на которые подаются окончательные карты признаков.
Свёрточные нейронные сети в задачах компьютерного зрения
Свёрточные нейронные сети получили большое распространение при решении задач классификации изображений. Наиболее популярными являются топологии AlexNet [5], VGG Net [6], GoogLeNet[7], ResNet [8] и MobileNet [9].
Еще одной популярной задачей, решаемой свёрточными нейронными сетями, является локализация (определение местоположения) объектов на изображении. Перечисленные выше топологии из-за особенностей архитектуры не могут решать данную задачу в режиме реального времени: они последовательно проверяют различные участки изображения, из-за чего обработка одного кадра может длиться до 1 секунды.
В этом случае более эффективным будет применение регрессионных детекторов объектов, которые решают проблему распознавания и локализации объектов как задачу регрессии. Наиболее популярными регрессионными детекторами являются YOLO и SSD.
YOLO и SSD
В качестве основы построения системы распознавания дорожных знаков было решено использовать один из регрессионных детекторов объектов. Ниже рассмотрим особенности архитектур нейронных сетей YOLO и SSD.
YOLO (You only Look Once) [10] – это технология локализации объектов на изображении, которая позволяет обрабатывать видеопоток в режиме реального времени. Главной особенностью YOLO является отказ от использования какого-либо из методов предложения регионов и последовательной классификации множества регионов посредством свёрточной нейронной сети. Вместо этого алгоритм один раз принимает на вход исходное изображение (кадр видеопотока) и на выходе предоставляет ограничительные окна и вероятности нахождения в их пределах объектов заданных классов.
YOLO делит изображение на сетку ячеек одинаковых размеров размером, например, S×S и соотносит с каждой ячейкой N фрагментов изображения c центром в этой ячейке. Рассмотрим пример распознавания 20 классов объектов на изображении с сеткой 7×7 ячеек и N=2 (рисунок 1). На выходе нейронной сети будет получен тензор 7×7×30. Элемент тензора 1×1×30 соответствует одной ячейке сетки. Первые 10 элементов служат для описания характеристик, связанных с ячейкой фрагментов по 5 на каждый из них. Остальные 20 элементов соответствуют распознаваемым классам. Эти величины обозначают оценку класса, которая является вероятностью принадлежности объекта классу, если объект присутствует в ячейке. Чтобы определить вероятность нахождения объектов конкретных классов в каком-либо фрагменте, необходимо вероятность присутствия объекта умножить поэлементно на все 20 оценок классов.
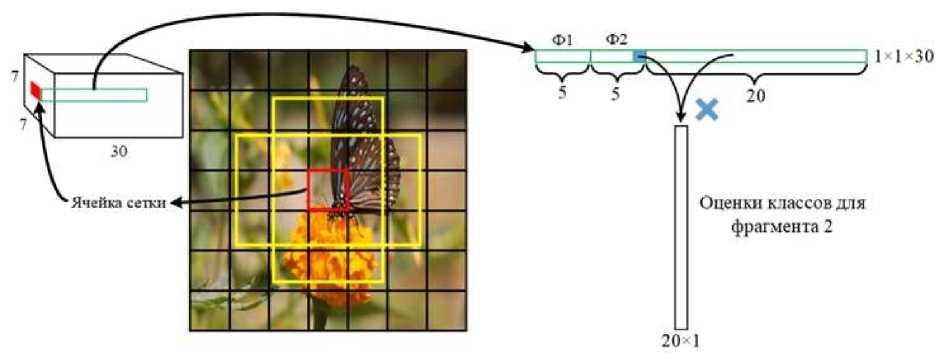
Рисунок 1 – Вычисление оценок класса для фрагмента изображения
Ключевая идея метода Single Shot Multibox Detector (SSD) [11] также состоит в использовании одной сети без какой-либо технологии предложения регионов. Архитектура применяемой сети приведена на рисунке 2. Сеть SSD300 принимает на вход изображение размером 300×300 пикселей и применяет к нему свёрточные слои. Используются как слои свёрточные слои нейронной сети VGG16 для распознавания небольших объектов, так и дополнительные слои свёрточные слои, позволяющие распознавать более крупные объекты.
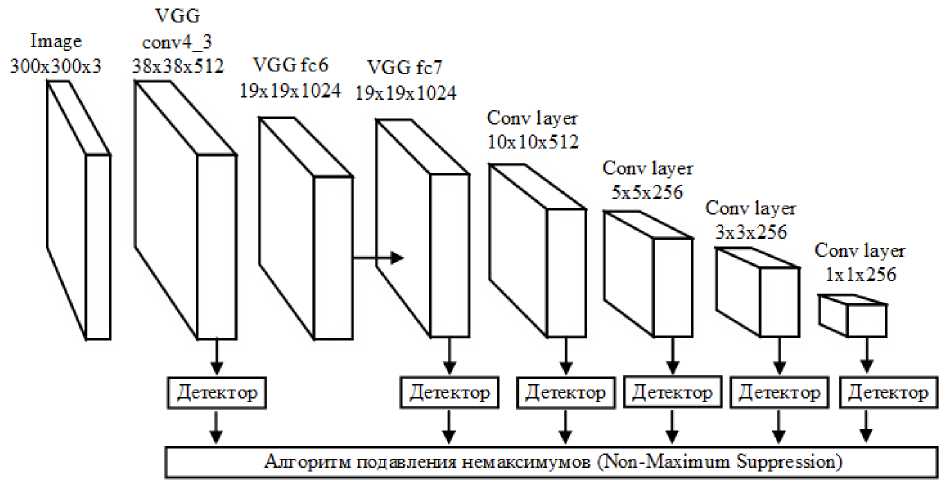
Рисунок 2 – Архитектура сети SSD
Каждый свёрточный слой формирует карту признаков для фрагментов изображения разных масштабов. Каждая ячейка карты признаков будет соответствовать определенному фрагменту изображения. Детектор отбирает регионы, которые с высокой вероятностью содержат объект одного из классов, и затем корректирует их границы. На последнем этапе из отобранных фрагментов с помощью метода подавления немаксимумов (nonmaximum suppression) будут получены итоговые области.
Обучающий набор данных
Для обучения YOLO и SSD набор данных German Traffic Sign Recognition Benchmark (GTSRB) [12], который был использован в соревнованиях по машинному обучению в рамках Международных объединенных конференций по нейронным сетям 2011. Данный набор данных включает в себя 51 839 изображений, размеры которых колеблются от 15×15 до 250×250 пикселей. Каждое из них содержит дорожный знак, относящийся к одному из 43 видов немецких дорожных знаков. Изображения уже разделены в соотношении 1:3 на тестовые и тренировочные данные соответственно. Тренировочные данные уже отсортированы на основе класса, изображенных на них дорожных знаков.
Представленные в GTSRB изображения относятся к так называемым положительным прецедентам (рисунок 3, а), т.е. содержат изображения дорожного знака. Однако на изображении знак может отсутствовать вовсе – это отрицательные прецеденты (рисунок 3, б). Для того чтобы нейронная сеть могла различать отрицательные и положительные прецеденты, к обучающим данным добавим еще изображения, не содержащие дорожные знаки и потенциально имеющие сходство с целевыми изображениями знаков (элементы дорожной разметки, вывески магазинов, фары и колеса автомобилей). Все изображения обучающей выборки приведены к размеру 128×128.

a

б
Рисунок 3 – Примеры данных обучающей выборки: a – положительные прецеденты; б – отрицательные прецеденты
Тестирование
Тестирование алгоритмов YOLO и SSD производилось на персональном компьютере с графической картой GeForce GTX 740M с установленным программным обеспечением CUDA и cuDNN. Это позволило достичь значительного ускорения работы алгоритмов и получить систему, работающую в режиме реального времени. Результаты приведены в таблице 1.
Таблица 1 – Результаты тестирования алгоритмов YOLO и SSD
|
Точность на тестовой выборке, % |
Скорость обработки видеопотока, кадр/с |
|
|
YOLO |
93.59 |
79 |
|
SSD |
95.87 |
42 |
По результатам тестирования можно сделать вывод, что технология SSD позволяет получить более высокую точность распознавания дорожных знаков. Однако в условиях ограниченных вычислительных ресурсов более предпочтительно использование алгоритма YOLO.
Выводы
Было выполнено сравнение популярных регрессионных детекторов YOLO и SSD на основе свёрточных нейронных сетей в задаче распознавания дорожных знаков в режиме реального времени. Оба метода показали высокие показатели точности распознавания и скорости обработки видеопотока. Система на основе SSD позволяет достичь самой высокой точности, равной 95.89%, но не подойдет для маломощных вычислительных устройств. Алгоритм YOLO имеет более низкие показатели точности, однако благодаря небольшим требованиям к вычислительным ресурсам, может быть применен даже на мобильных устройствах. Дальнейшая работа будет направлена увеличение точности распознавания путем применения различных техник предобработки изображений и повышения качествах данных в обучающей выборке.
Список литературы Нейросетевые методы распознавания дорожных знаков в режиме реального времени
- Краснобаев Е.А. Распознавание дорожных знаков на изображениях методом Speeded up robust features (SURF) // Вестник ВДУ. - 2013. - № 3(75). - С. 18-23.
- Лисицын С.О., Байда О.А. Распознавание дорожных знаков с помощью метода опорных векторов и гистограмм ориентированных градиентов // Компьютерная оптика. - 2012. - Т. 36, № 2. - С. 289-295.
- Милютин А.М., Черников А.Н. Нейронные сети использование многослойного персептрона Румельхарта для распознавания образов дорожных знаков // Актуальные направления научных исследований XXI века: теория и практика. - 2016. - Т. 4. - С. 96-102.
- Лаптева М. А., Фаворская М. Н., Болдырев К. М. Система распознавания регистрационных номеров автомобиля с применением нейронной сети // Актуальные проблемы авиации и космонавтики. - 2014. - № 10. - С. 309-310.
- Krizhevsky, A. ImageNet classification with deep convolutional neural networks / A. Krizhevsky, I. Sutskever, G.E. Hinton // NIPS'12 Proceedings of the 25th International Conference on Neural Information Processing Systems. - Volume 1. - 2012. - P. 1097-1105.
- Simonyan, K. Very Deep Convolutional Networks for Large-Scale Image Recognition / K. Simonyan, A. Zisserman // ICLR 2015. - 2015. - P. 587-601.
- Szegedy, C. Going deeper with convolutions / C. Szegedy, W. Liu, Y. Jia // Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on. - 2015. - P. 1-9.
- He, K. Deep Residual Learning for Image Recognition / K. He, X. Zhang, S. Ren, J. Sun // Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on. - 2016. - P. 1-12.
- Howard, A.G. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications / A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam // ArXiv. - 2017. - P. 1-9.
- Redmon, J. You only look once: Unified, real-time object detection / J. Redmon, S. Divvala, R. Girshick, A. Farhadi // Proceedings of the IEEE conference on computer vision and pattern. - 2016. - P. 1-10.
- Liu, W. SSD: Single Shot MultiBox Detector / W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, A.C. Berg /// Proceedings of the European Conference on Computer Vision (ECCV). - 2016. - P. 21-37.
- Dataset. German Traffic Sign Recognition Benchmark. URL: http://benchmark.ini.rub.de/?section=gtsrb&subsection=dataset (дата обращения 30.10.2018).
