Neural network recognition system for video transmitted through a binary symmetric channel

Author: Baboshina V.A., Orazaev A.R., Lyakhov P.A., Boyarskaya E.E.
Journal: Компьютерная оптика @computer-optics
Section: International conference on machine vision 2023
Article in issue: 4 т.48, 2024.
Free access
The demand for transmitting video data is increasing annually, necessitating the use of high-quality equipment for reception and processing. The paper presents a neural network recognition system for videos transmitted via a binary symmetrical channel. The presence of digital noise in the data makes it challenging to recognize objects in videos even with advanced neural networks. The proposed system consists of a noise interference detector, a noise purification system based on an adaptive median filter, and a neural network for recognition. The experiment results demonstrate that the proposed system effectively reduces video noise and accurately identifies multiple objects. This versatility makes the system applicable in various fields such as medicine, life safety, physics, and chemistry. The direction of further research may be to improve the model neural network, increasing the database for training or using other noises for modeling.
Neural networks, video recognition, YOLO, binary symmetric channel, video denoise
Short address: https://sciup.org/140308604
IDR: 140308604 | DOI: 10.18287/2412-6179-co-1388
Text of the scientific article Neural network recognition system for video transmitted through a binary symmetric channel
Currently, professionals in various fields are tasked with object recognition in video. Video processing has various applications in systems that track meteorological activity, locate individuals in large cities, the media, autopilot systems, smart home systems, and other areas that are now integral to our daily lives. The abundance of applications for object recognition in videos highlights the need to search for and develop mathematical and software tools that can automate this process by simulating the human brain. A common method for object recognition in videos is the use of neural networks. The choice of this tool for problem-solving is based on the fact that there is no universal algorithm that can work for all types of input data. The initial data can be large and have numerous parameters that can impact the final recognition outcome. The ability of neural networks to learn is the most promising way to solve recognition problems.
The YOLO (You Only Look Once) algorithm was first described by Joseph Redmon in 2015 as a real-time object recognition algorithm. Based on a convolutional neural network and detecting objects as a regression problem, YOLO has gained wide popularity in this field. The algorithm uses one forward propagation to segment and extract a class of objects in an image. Various modifications of this algorithm are used to detect bone fractures [1], to detect smoking scenes to prevent forest fires [2], to observe the behavior of the driver and passengers in the car [3], to recognize the location of figs [4], to detect plastic waste [5], and other real-time object recognition tasks.
During creation, transmission, and processing, video may be subject to various noises, for example, impulse [6] or salt and pepper noise [7]. When pixels are distorted by noise, the recognition of objects in the video deteriorates not only for neural networks but sometimes even for the human eye. Raw video transmission or data from urban surveillance cameras or unmanned vehicle cameras may be unsuitable for recognition without pre-processing. Scientists are currently developing algorithms and methods to accurately recognize noisy videos in real time.
A binary symmetric channel is the most basic type of communication channel. Most often, it is used to analyze communication channels in coding theory. When transmitting video, various interferences can occur, and research has been underway for a long time to develop a system that will reduce the amount of interference in communication channels. The paper [8] presents the SoftCast signaling scheme. The authors use decorrelation transformation and energy distribution between signal elements to improve the efficiency of uncoded transmission. The authors [9] utilize the same system to enhance noise and error tolerance by converting the noise into an approximation of the original video pixels. The research [10] introduces an unencrypted multi-user streaming video system that addresses the issue of optimizing power distribution in video transmission. The work [11] presents a routing protocol that will allow data to be transmitted over one or more paths in wireless sensor networks, based on the metric of the number of hops on the shortest path. The work [12] uses a clustering method that allows parallel computing in a multimedia wireless sensor net- work to improve localization performance and reduce communication costs without loss of transmission quality. The authors [13] proposed a video surveillance system that utilizes convolutional neural networks and the Internet of Things to analyze video data captured by urban surveillance cameras. The work [14] presents the results of the implementation of Blockchain technology for verifying the authenticity of video captured using IoT streaming. The paper [15] highlights the challenges of encoding and transmitting multimedia data through wireless sensors, which often results in poor performance and quality. It proposes a system that utilizes unequal error protection to configure video compression standards in IoT networks with losses, aiming to achieve high-quality and cost-effective video transmission. In a smart city for video streaming systems, it is proposed to use the storage space and bandwidth of mobile devices to increase the space for storing and processing video data [16]. The authors [17] present a system for encoding and compressing video data from CCTV cameras obtained using the technology of the Internet of Things in smart cities for optimization and efficient use. The authors [18] propose an algorithm that controls the data transfer rate and the root mean square error of the code. This algorithm ensures efficient video transmission with minimal interference, taking into account memory and communication channel bandwidth limitations. The algorithm proposed in [19] aims to mask errors in intraframe interlacing of pixel rows, providing error resistance during the transmission of video data from unmanned aerial vehicles. In [20], a method was developed to clean the image from impulse and Gaussian noise, which is a modification of the bilateral filter for determining distorted impulses [21]. The method described in [22] improves upon the method presented in [20] by incorporating logarithmic function and threshold transformations. The research [23] compares methods [22] and [20] and proposes a modified version of method [20]. The method introduces a new statistic called the Local Consensus Index (LCI). The LCI is calculated by summing all the similarity values of pixels in its neighborhood and finding the central feature value. Thus, the area of receiving, processing, and transmitting video is quite wide. It is necessary to reduce the noise level during video transmission without increasing its cost. The motivation for the research is the creation of a detectorrecognizer complex for solving a wide range of problems. The existing methods do not provide a similar level of complexity as the proposed one. The authors consider ways to increase the efficiency of video data transmission, optimize power distribution, and increase resistance to transmission errors. The proposed system will be effective if error elimination methods do not work or if there is already noisy video.
The paper presents a neural network system for recognizing objects in videos transmitted through a binary symmetric channel with errors. The complex includes a pre-processing stage, which consists of a noisy pixel de- tector and a denoising filter, as well as a neural network that recognizes denoised videos. The proposed complex has high speed and accuracy due to the use of the developed cleaning method, which is superior to known methods, and the new YOLOv8 recognition algorithm. The experimental results confirm the effectiveness of the proposed method compared to existing methods.
The work includes several sections. The first two sections, "YOLO architecture and accuracy metrics" and "Distortion of images in a binary symmetric channel," provide preliminary information about the recognition algorithm and the noise that occurs when transmitting video through a binary symmetric channel. These sections also present the problem statement. The next section, "Proposed neural network system for recognition in noisy environments," describes the developed recognition system. The following section, "Experimental modeling of recognition system for noised video," presents recognition results and compares them with known video denoising methods. Finally, the Discussion and Conclusion sections analyze the results and evaluate the prospects of the research.
YOLO architecture and accuracy metrics
YOLO utilizes three methods: residual blocks, bounding box regression, and intersection over union (IOU). The uploaded image is initially divided into a grid of cells. Each cell analyzes the object within itself, and if the object's center is detected in a cell, that cell is responsible for its detection. After the cell has found the center of the object, a bounding box is built (Fig. 1). YOLO uses a single-bounding box regression to predict box parameters. Intersection Over Union (IOU) is a metric that describes the intersection of bounding boxes in order to understand how true the prediction is, that is, how much the predicted bounding box matches the real one. Using this method helps to eliminate incorrectly constructed frames (Fig. 2). Thus, the neural network divides the image into cells; each cell predicts the bounding boxes and gives a confidence score; and finally, the cells predict the probability that the object belongs to the class.
Each new YOLO model introduces exchange methods that increase the accuracy and efficiency of the model. YOLOv8 is the latest model released by Ultralytics on January 10, 2023. The new network model has been validated for its high level of accuracy using the COCO and Roboflow 100 open datasets. It also includes enhanced Python features. The model is available in five versions (nano, small, medium, large, extra large) to cater to user convenience and various tasks. Each version has fairly high accuracy; the nano and small versions are used for real-time object recognition; other versions have a fairly large weight and high recognition accuracy, so they can be used on a large scale. At the moment, there isn't any published works in which the authors of the algorithm would describe the research methodology, but the neural network repository gives some insight into the architecture and functions that will help to complete even complex tasks.
YOLOv8 uses a convolutional neural network consisting of two main parts: a backbone and a head. The backbone of the system is a modified version of CSPDarknet53, which consists of 53 convolution layers and partial inter-stage connections. The head comprises convolutional layers and fully connected layers. The video is inputted into the neural network and passes through convolution layers that utilize batch normalization and a sigmoid activation function. The C2f module combines two parallel branches of the gradient flow to ensure a consistent and reliable flow of gradient information. The Spatial Pyramid Pooling Fusion (SPPF) module extracts contextual information from images at different scales, enhancing the model's ability to generalize. The architecture also includes an upsampling layer to address imbalanced data sets. Also, in a large architecture it is necessary to combine the output data of several layers, for which a concatenation layer is used. The blocks also have a split layer that divides the MAP Layer into new MAP layers based on the attribute values of its objects. The MaxPool2d layer applies 2D max pooling to an input signal consisting of multiple input planes. Bottleneck layers are used to obtain a reduced dimensionality representation of the input data, the Convolution2d layer is an extension of regular 1D convolution by convolving both the horizontal and vertical directions. The class loss is computed based on the binary cross-entropy loss for the confidence scores of each and every predicted bounding box. The bounding box loss is summed up over object spatial locations, object shapes and different aspect ratios and is computed as the mean squared error (MSE) between the predicted bounding box parameters and the ground truth ones. The pyramid object network enables the detection of objects at various sizes and scales. The architecture of the YOLOv8s network is shown in Fig. 3. Parameters for layers are shown in Tab. 1.
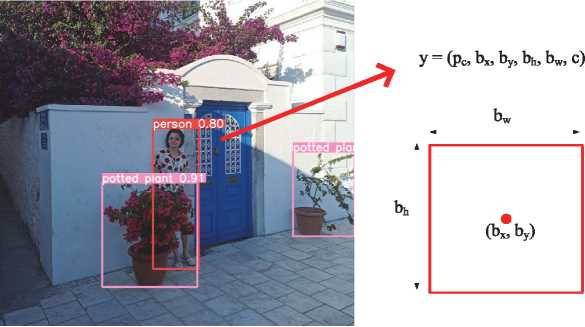
Fig. 1. YOLO bounding box on the image: b h – the height of the box, b w – the width of the box, (b x , b y ) – the center of the bounding box, c is the class of the object in the image, and p c is the probability of the object class

Fig. 2. Intersection over union mechanism: the white bounding box is real, the dotted boxes are not equal to white, and the IOU eliminates them
and Recall metric:
R = ,
TP + FN
where TP is true positive result, FP is false positive result, and FN is false negative recognition result. A precision-recall dependency curve is constructed based on these two metrics. The area of the figure under the curve is the Average Precision metric:
AP = ! 0P (r) dr, AP G
Mean Average Precision is defined as:
n mAP = -VAPi, ni~1
Mean Average Precision (mAP) is a performance indicator of a machine learning model and was used to evaluate the recognition accuracy of YOLOv8s on a custom video. It can be derived from the Precisions metric:
p = P'
TP + FP
where AP i is average accuracy for class i and n is a number of classes.
The mean Average Precision (mAP) maintains a balance between precision and recall by considering all false results obtained. This characteristic makes it a suitable metric for most detection applications.
Tab. 1. Parameters of YOLOv8 layers
|
Layer\Block |
Attributes |
|||
|
kernel |
stride |
padding |
||
|
Conv |
3 |
2 |
1 |
|
|
C2f |
Conv |
1 |
1 |
0 |
|
Bottleneck Conv |
3 |
1 |
1 |
|
|
SPPF Conv |
1 |
1 |
0 |
|
|
Detect |
Conv |
3 |
1 |
1 |
|
Conv2d |
1 |
1 |
0 |
|
Distortion of images in a binary symmetric channel
►( C2f ]

£Ё0
►^ Conv ) ^ C2f J

Conv j<
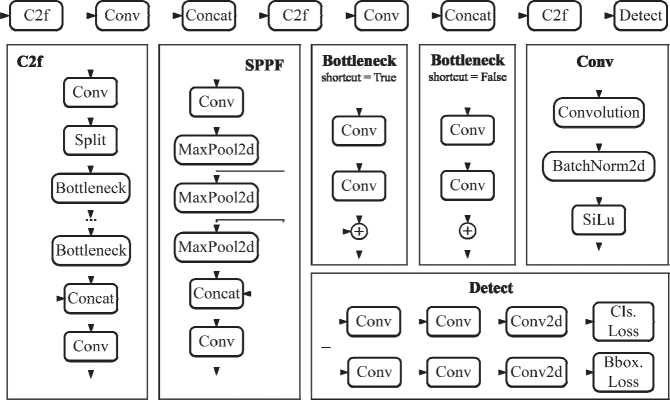
Fig. 3. Architecture of the YOLOv8s network
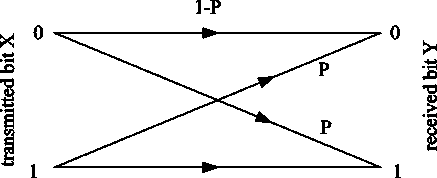
A binary symmetric channel is a channel with a binary input and output with equal probabilities of error and correct transmission. Binary symbols are transmitted over this channel, and due to non-ideal transmission in this communication channel, the receiving signal may receive an error; instead of 0, 1 can be received, or vice versa. Figure 4 depicts a diagram of a binary symmetric channel, where P is the error probability, 1– P is the probability of correct signal transmission. A symmetrical channel has both input and output X e {0,1} and Ye {0,1}, hence:
P ( X | Y ) =
Г 1 - p , ff X = Y [ P , ff X ^ Y .
Distorted signals occur in a binary symmetric channel due to various interferences that disrupt the correct reception of the signal. Interference can be either additive, which refers to random processes that are superimposed on the transmitted signals, or multiplicative, which refers to random changes in the characteristics of the channel itself. Additive interference includes three components: harmonic, or concentrated in frequency; impulse, or concentrated in time; and fluctuation. Impulse interference refers to a series of short-term pulses that are separated by intervals longer than the duration of transients in the channel. The causes of communication line disruptions can be attributed to lightning discharges, power line interference, design and manufacturing errors in transmission and power equipment, or operational issues.
Data transmission in a binary symmetric channel can be described using the Bernoulli scheme. Let A be a random variable that will count the number of failures. According to the Bernoulli scheme, the probability of the occurrence of k errors during transmission n bit is:
1-P
Fig. 4. Binary symmetric channel scheme
( n i
P ( A = k ) = l I P n — k q k , (6)
where n is the pixel capacity and P is the probability of distortion of one bit in a binary symmetric channel. Based on this, the noise density in the image is p = 1 - pn—k.
The distribution of distorted pixels on unencoded video transmitted through a binary symmetric channel tends to be uniform. Random noise with this distribution shares similar characteristics with random-valued impulse noise. If the least significant digits of a bit are damaged, the af- fected pixels will have values that are similar to the original ones. Cleaning methods that utilize median filtering are effective in removing noise interference. For preprocessing, four methods were used to clean images from noise: two known methods [22] and [23], as well as two improved methods from works [24] and [25]. These methods have shown their effectiveness in the field of image pre-processing before recognition by a neural network.
Proposed neural network system for recognition in noisy environments
The following section will outline the method developed for removing digital noise from video and identifying objects within it. The input is video transmitted through a binary symmetrical channel. The video is captured using a pixel detector that produces noisy images. A method has been developed to address the issue of identifying noisy pixels by assessing their similarity based on two criteria: the parameter a - the geometric distance between pixels, calculated using the Euclidean metric, and the parameter ц - the difference in pixel brightness within a local window Q :
a ( У е , f , У д , h ) = exp
Ц ( У е , f , У д , h ) =
( e , f ) - ( g , h ) 2 Ф 2
, У д , h eQ y ef ,(8)
1, if У е , f = У д^ , (9)
1 111 I Г У д ’ h G Q y e,f ,
-
1-- log 2 ye ,f - У д^ , if ye ,f * У д , h , z
where a ( У еf, У д , h ) - coefficient of influence of the geometric distance between pixels, ц ( x e f , х д , h ) - coefficient of influence of brightness difference, ф а - standard deviation parameter of the coefficient а ( у ,f , У д , h ), z - is the bit depth of the frame pixels, ( y e , f , y g , h ) – coordinates of pixels in the local window Q . The ц value is inversely related to the difference in brightness, and dividing by the bit depth ensures that ц remains non-negative. Next, we sort the array ц in ascending order and sum the first l / 2 elements of the sorted array, where l is the number of elements in the local window Q :
l /2
A ( У е , f , У д , h ) = £ ц k ( У е , f , У дЛ ) . (10)
k = 1
The similarity score between pixels M is calculated based on the difference in pixel brightness (8) and the geometric distance between pixels (10):
M ( У е , f , У д , h ) = а ( У е , f , У д , h ) * A ( У е , f , У д , h ) . (11)
To determine the presence of pixel distortion, a threshold Th is introduced:
G e , f =
0, ifM e , f > Th , 1, if M e,f < Th .
If the array G is considered a map of noisy pixels, then if an element in G is equal to 1, the corresponding pixel in the image is noisy.
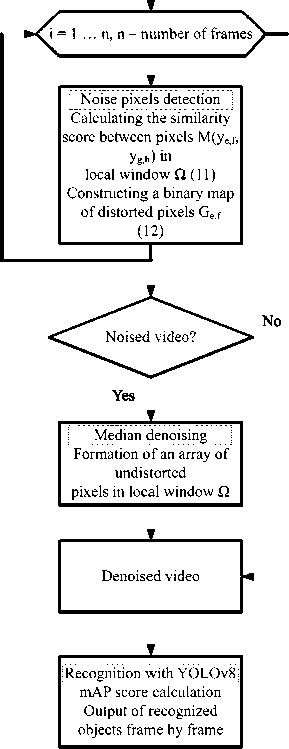
Fig. 5 shows the block diagram of the proposed system. The input signal is video transmitted over a binary symmetrical channel. The video is sent to a noise detector, which creates a map of the distorted pixels. If
-
- < 0.05, (13) r
where t is the ratio of noisy pixels and r is the total number of pixels, then we consider the video to be noise-free and transmit it directly to the neural network. We leave a value of 0.05 as a reserve for false positive detections. If t \ r > 0.05, we consider the video to be noisy. If noise is detected, the video is sent to a filter that matches the noisy pixels for each frame. A pixel is considered noisy if its brightness value differs from that of its neighbors. Cleaning is carried out by a median filter with an empirically selected threshold. After each frame is cleaned, it is sent to a neural network where more objects can be recognized compared to the noisy video.
Thus, the noisy pixel detector is a 3×3 filter in which the brightness of the central pixel is compared with the brightness of its neighbors. Distorted pixels may have a brightness value close to the original pixel's brightness value, or several noisy pixels may be located nearby. In this case, the method can be applied iteratively, but since a median filter is used, the video may turn out to be blurry after several iterations and reduce the quality of recognition, despite the fact that the median filter is adapted to clean only noisy pixels. Since the noise that appears after transmission through a binary symmetrical channel is similar in structure to random-valued impulse noise, the denoising circuit is identical. We will now present the results of an experiment that examines how different methods of removing noise from video transmission over a binary symmetric channel affect the accuracy of object recognition by a neural network.
Experimental modeling of recognition system for noised video
The YOLOv8s network selected for simulation demonstrates high object recognition accuracy, despite its compact size. Fig. 6 displays screenshots from the original videos recorded by the car's DVR. The network demonstrated high accuracy by correctly recognizing a significant number of objects. Fig. 7 shows a comparison of frames from two videos recognized in turn by the small YOLOv8 model, medium, and large. The larger the network, the more confident it is in the probability of the chosen class in the lower model. However, the frames recognized by the middle model indicate that some objects may still be incorrect. For instance, a small and large model correctly identified a car as a car, but the medium model misclassified it as a truck. Similarly, a medium model detected two people in a bus, while a large model only detected one person.
Input video
BSC
Output
Fig. 5. Block diagram of a neural network system for recognizing video transmitted through a binary-symmetric channel
The original video from the car's DVR was selected for the experiment. The video includes various objects such as a car, bus, truck, person, traffic light, and traffic signs. These categories are the most popular for recognition. Each RGB channel of every frame in the original video was impacted by a 10% noise level that arises during video transmission through a binary symmetric channel. Figure 8 shows that the number of recognized objects on the noisy video is much less than on the original one, which confirms the importance of denoising. The experiment involved introducing video noise, cleaning the video using established methods, and then using a small YOLOv8 neural network model to recognize the resulting video sequences. The network was pretrained on the COCO dataset, which contains 80 classes of objects, including vehicles, animals, and household items. The recognition problem was solved by developing a program in the Jupiter Notebook environment using the Conda core. At the beginning, the necessary libraries for work were loaded, including the Ultralytics package for accessing the YOLO model. Next, a 10-second video consisting of 301 frames was loaded into the pre-trained model. Noise and cleanup of such a video were carried out using the MatLAB application package and took 6 hours for each video. A class definition threshold of 50% was used, and the images inside the bounding boxes (crops) and labels for each frame were also saved. The saved labels are a txt file; in each line, the class number of the recognized object and the coordinates of its bounding box are indicated. Further, class numbers were selected from all saved labels; their number was calculated to create a table where, for each frame, the number of detected objects of each class was indicated. These matrices were used to evaluate the quality of noise removal. Tab. 2 displays the results of the system's operation with 10% video noise. Although our developed method recognized more objects than the [22], the mAP performance metric indicates that it performed better in cleaning up noisy video. The mAP evaluation compared the recognized labels on the original video with the predicted labels for the noisy and cleaned video. The method [23] allowed for the identification of more objects, but they were either assigned to the wrong classes or had incorrect bounding boxes.
Fig. 9 shows which cleaning methods and their thresholds were used in the experiment. Fig. 10 represents object recognition in the same frames as Fig. 9. Obviously, proposed method has cleared the image enough to recognize the maximum number of objects. Some objects were difficult to recognize, such as a truck in the background, people near a crosswalk, a minivan in the foreground, and some cars.
Thus, by comparing noisy and cleaned videos, we have demonstrated the significance of preprocessing videos transmitted through a binary symmetric channel before they are recognized by a neural network. Objects, even people, are quite well defined on the cleaned videos, which is important when processing video recordings from city cameras. In general, Table 2 shows that the difference between cleaning methods is small, but even a small advantage can be decisive in some areas. Video transmission is of great importance in the modern world , and the proposed system will help improve the quality of even the noisiest video files for the convenience of their further use.
Discussion
It was observed during the work that this process would be labor-intensive, as it required comparing objects in 300 frames of each video with the original ones. Additionally, there was no confidence in the alignment of the recognized objects with the expert marks. So, having an original video and two versions of labels - expert and neural network predictions - the video, after processing and noise, went into the same neural network, and the object labels of the cleaned video were compared with the labels of the original. Situations arose when the cleaned video correctly recognized objects that were not recognized by the network in the original video but were actually there, and in this case there was a discrepancy. The object labels from the cleaned and original videos happened to be the same, but they were different from the expert labels. Thus, the results were averaged without taking into account such errors. The reasons for poor recognition of people in video have not been fully understood. The pictures showing the result of the experiment show that even after cleaning, the video quality noticeably deteriorated. So, if previously the neural network could recognize a person from different angles, then after making noise and cleaning, some angles became unrecognizable. Also, in the original video, there were people located approximately 30–40 meters from the shooting location, and after the video quality deteriorated, they became invisible to the artificial neural network, thereby reducing the total number of recognized people.

Fig. 6. Examples of recognition by the YOLOv8 network of objects on frames from a car DVR – original frames and processed images

Fig. 7. Examples of recognition by the YOLOv8 network of objects on frames from a car DVR – a) small model YOLOv8s, b) medium model YOLOv8m, c) large model YOLOv8l
Tab. 2. Results of object recognition on the original, noisy, and cleaned video of 300 frames in length for each class and scores mAP50 and mAP95
|
Video |
Recognized object class |
mAP50 |
mAP95 |
|||||||
|
person |
bicycle |
car |
bus |
truck |
traffic light |
all objects |
||||
|
Original |
15 |
0 |
1724 |
13 |
139 |
1 |
1892 |
- |
- |
|
|
Noised |
1 |
0 |
579 |
0 |
14 |
0 |
594 |
0,634 |
0,525 |
|
|
"U CD ^ ° 2 Рн О |
Th=16 |
2 |
3 |
1251 |
7 |
95 |
3 |
1361 |
0,698 |
0,593 |
|
Th=18 |
2 |
1 |
1253 |
5 |
92 |
0 |
1353 |
0,706 |
0,604 |
|
|
Th=20 |
0 |
0 |
1241 |
3 |
86 |
0 |
1330 |
0,668 |
0,574 |
|
|
Th=22 |
1 |
0 |
1207 |
4 |
80 |
0 |
1292 |
0,651 |
0,555 |
|
|
[23] |
2 |
1 |
1317 |
6 |
94 |
1 |
1421 |
0,651 |
0,556 |
|
|
[22] |
2 |
2 |
1272 |
6 |
93 |
2 |
1377 |
0,695 |
0,594 |
|

Fig. 8. Comparison of the number of recognized objects on three frames of the video selected for modeling -a) recognized objects on the original video, b) recognized objects on the noisy video



Fig. 9. Various methods for denoising video - a) original video, b) noisy video, c) video cleaned by proposed method with a threshold of 16, d) video cleaned by proposed method with a threshold of 18, e) video cleaned by proposed method with a threshold of 20, f) video cleaned by proposed method with a threshold of 22, g) video cleaned by method [23], h) video cleaned by method [22]
Conclusion
The paper considers the developed and tested neural network recognition system for videos transmitted through a binary symmetric channel. During the research, the issue of identifying and eliminating digital noise that arises when transmitting video through a binary symmetric channel was addressed. This was confirmed by the results obtained from the simulation. The high accuracy of object recognition on the cleaned video shows the advantage of using the proposed system in various areas; the accuracy increases to 0,011 – 0,079, which can be important when solving problems for various purposes. Despite the fact that 64 cars, one bus, two trucks, and one traffic light were recognized less in the video cleaned by the proposed method, the accuracy of these recognitions was higher than that of the method that recognized more objects, which is confirmed by the mAP performance evaluation.
This proves that the proposed system for clearing and recognizing videos transmitted via a binary symmetric channel has more efficiency than when using the same system with another data cleaning method. Since various interference and noise may occur when transmitting data over communication channels (wired or wireless), the introduction of a cleaning and recognition complex in areas where object recognition is necessary is promising, since several steps for video processing (detecting noise, cleaning, and recognition) are combined into one, which reduces processing time and resources. The presented system has ample opportunities for adaptation to different types of noise or different image databases. Future extensions of the study could be to use a larger model of YOLO neural network or use a different kind of noise for modeling. It is also possible to refine the system for wide application.


Fig. 10. Objects on frames cleaned by various methods- a) original video, b) noisy video, c) video cleaned by proposed method with a threshold of 16, d) video cleaned by proposed method with a threshold of 18, e) video cleaned by proposed method with a threshold of 20, f) video cleaned by proposed method with a threshold of 22, g) video cleaned by method [23], h) video cleaned by method [22]
Acknowledgments
The research in Section “Experimental modeling of recognition system for noised video” was supported by the North-Caucasus Center for Mathematical Research under agreement number 075-02-2023-938 with the Ministry of Science and Higher Education of the Russian Federation. The rest of the paper was funded by the Russian Science Foundation (Project No. 23-71-10013).
References Neural network recognition system for video transmitted through a binary symmetric channel
- Samothai P, Sanguansat P, Kheaksong A, Srisomboon K, Lee W. The evaluation of bone fracture detection of YOLO series. ITC-CSCC 2022 – 37th Int Technical Conf on Circuits/Systems, Computers and Communications 2022: 1054-1057. DOI: 10.1109/ITC-CSCC55581.2022.9895016.
- Ma Y, Yang J, Li Z, Ma Z. YOLO-Cigarette: An effective YOLO Network for outdoor smoking real-time object detection. 2021 9th Int Conf on Advanced Cloud and Big Data (CBD 2021) 2022: 121-126. DOI: 10.1109/CBD54617.2021.00029.
- Poon YS, Lin CC, Liu YH, Fan CP. YOLO-based deep learning design for in-cabin monitoring system with fisheye-lens camera. IEEE Int Conf on Consumer Electronics 2022: DOI: 10.1109/ICCE53296.2022.9730235.
- Yijing W, Yi Y, Xue-Fen W, Jian C, Xinyun L. Fig fruit recognition method based on YOLO v4 deep learning. 18th Int Conf on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON) 2021: 303-306. DOI: 10.1109/ECTI-CON51831.2021.9454904.
- Liu L, Zhou B, Liu G, Lian D, Zhang R. Yolo-based multi-model ensemble for plastic waste detection along railway lines. Int Geoscience and Remote Sensing Symposium (IGARSS) 2022: 7658-7661. DOI: 10.1109/IGARSS46834.2022.9883308.
- Alanazi TM, Berriri K, Albekairi M, Ben Atitallah A, Sahbani A, Kaaniche K. New real-time high-density impulsive noise removal method applied to medical images. Diagnostics 2023; 13: 1709. DOI: 10.3390/DIAGNOSTICS13101709.
- Kumain SC, Singh M, Govil MC, Pilli ES. An efficient salt and pepper noise reduction approach for video(s) using optimized filter approach. 2nd Int Conf on Emerging Frontiers in Electrical and Electronic Technologies (ICEFEET 2022) 2022. DOI: 10.1109/ICEFEET51821.2022.9847916.
- Xiong R, Wu F, Xu J, Fan X, Luo C, Gao W. Analysis of decorrelation transform gain for uncoded wireless image and video communication. IEEE Trans Image Process 2016; 25: 1820-1833. DOI: 10.1109/TIP.2016.2535288.
- Jakubczak S, Katabi D. A cross-layer design for scalable mobile video. Proc Annual Int Conf on Mobile Computing and Networking (MOBICOM) 2011: 289-300. DOI: 10.1145/2030613.2030646.
- He C, Hu Y, Chen Y, Fan X, Li H, Zeng B. MUcast: Linear uncoded multiuser video streaming with channel assignment and power allocation optimization. IEEE Trans Circuits Syst Video Technol 2020; 30: 1136-1146. DOI: 10.1109/TCSVT.2019.2897649.
- Khan K, Goodridge W. Fault tolerant multi-criteria multi-path routing in wireless sensor networks. Int J Intell Syst Appl 2015; 7: 55-63. DOI: 10.5815/IJISA.2015.06.06.
- Wajgi DW, Tembhurne JV. Localization in wireless sensor networks and wireless multimedia sensor networks using clustering techniques. Multimed Tools Appl 2024; 83: 6829-6879. DOI: 10.1007/S11042-023-15956-Z.
- Khudhair AB, Ghani RF. IoT based smart video surveillance system using convolutional neural network. Proc 6th Int Engineering Conf “Sustainable Technology and Development” (IEC 2020) 2020: 163-168. DOI: 10.1109/IEC49899.2020.9122901.
- Danko D, Mercan S, Cebe M, Akkaya K. Assuring the integrity of videos from wireless-based IoT devices using blockchain. IEEE 16th Int Conf on Mobile Ad Hoc and Smart Systems Workshops (MASSW 2019) 2019: 48-52. DOI: 10.1109/MASSW.2019.00016.
- Ababzadeh R, Khansari M. On the unequal error protection in compressive video sensing for low power and lossy IoT networks. 4th Int Conf on Smart Cities, Internet of Things and Applications (SCIoT 2020) 2020: 52-57. DOI: 10.1109/SCIOT50840.2020.9250205.
- Kang S, Ji W, Rho S, Anu Padigala V, Chen Y. Cooperative mobile video transmission for traffic surveillance in smart cities. Comput Electr Eng 2016; 54: 16-25. DOI: 10.1016/J.COMPELECENG.2016.06.013.
- Tian L, Wang H, Zhou Y, Peng C. Video big data in smart city: Background construction and optimization for surveillance video processing. Future Gener Comput Syst 2018; 86: 1371-1382. DOI: 10.1016/J.FUTURE.2017.12.065.
- Belyaev EA, Turlikov AM. Rate-distortion control in video compression and transmission system with memory restriction on transmitter and receiver side. Computer Optics 2007; 31(2): 69-76.
- Wang T, Zheng Z, Lin Y, Yao S, Xie X. Reliable and robust unmanned aerial vehicle wireless video transmission. IEEE Trans Reliab 2018; 68(3): 1050-1060. DOI: 10.1109/TR.2018.2864683.
- Garnett R, Huegerich T, Chui C, He W. A universal noise removal algorithm with an impulse detector. IEEE Trans Image Process 2005; 14: 1747-1754. DOI: 10.1109/TIP.2005.857261.
- Tomasi C, Manduchi R. Bilateral filtering for gray and color images. Proc IEEE Int Conf on Computer Vision 1998: 839-846. DOI: 10.1109/ICCV.1998.710815.
- Dong Y, Chan RH, Xu S. A detection statistic for random-valued impulse noise. IEEE Trans Image Process 2007; 16: 1112-1120. DOI: 10.1109/TIP.2006.891348.
- Xiao X, Xiong NN, Lai J, Wang CD, Sun Z, Yan J. A local consensus index scheme for random-valued impulse noise detection systems. IEEE Trans Syst Man Cybern Syst 2021; 51: 3412-3428. DOI: 10.1109/TSMC.2019.2925886.
- Lyakhov PA, Orazaev AR. New method for detecting and removing random-valued impulse noise from images. Computer Optics 2023; 47(2): 262-271. DOI: 10.18287/2412-6179-CO-1145.
- Orazaev A, Lyakhov P, Baboshina V, Kalita D. Neural network system for recognizing images affected by random-valued impulse noise. Appl Sci 2023; 13(3): 1585. DOI: 10.3390/app13031585.
