О формировании семантического поискового образа научной коллекции данных как web-ресурса

Автор: Рябухин С.И.
Журнал: Вестник Хабаровской государственной академии экономики и права @vestnik-ael
Рубрика: Информационные системы и технологии
Статья в выпуске: 2, 2019 года.
Бесплатный доступ
Описывается способ, позволяющий управлять формированием семантически-нагруженного поискового образа фактографической научной коллекции, представленной в виде WEB-ресурса. Для обеспечения семантической связи элементов поискового образа разрабатывается онтологическая модель научной коллекции. В целях обеспечения машиночитаемости онтологическая модель коллекции описывается RDF-триплетами в нотации Turtle.
Научная коллекция, поисковый образ ресурса, онтологическая модель
Короткий адрес: https://sciup.org/143168858
IDR: 143168858 | УДК: 004
Текст научной статьи О формировании семантического поискового образа научной коллекции данных как web-ресурса
ЦКП «Центр данных ДВО РАН»
The work was carried out with partial financial support of the basic research program of FEB RAS «Far East» (project № 18-5-104). The computing resources of CSC «FEB RAN Data Center» were used for the calculations.
Как известно, коллекцией называется совокупность предметов, систематизированная по некоему признаку и принадлежащая конкретному владельцу. Научная коллекция аккумулирует результаты научных исследований в виде фактов и знаний, проявляющихся в том числе в принципах систематизации собственно предметов такой коллекции. Электронные публикации научных коллекций представляют собой WEB-ресурcы и имену- ются научными электронными коллекциями. В качестве примера можно привести ресурс «Генетические и биологические (зоологические и ботанические) коллекции Российской Федерации» [1]. С одной стороны, подобную форму обеспечения публичности и транспарентности научных знаний трудно переоценить. С другой стороны, электронные научные коллекции являются информационными системами и в силу архитектуры информационных систем пользователи сети Ин- тернет получают доступ к данным таких коллекций либо посредством встроенного в такую систему пользовательского интерфейса, либо посредством специальных программных средств и технологий (например, посредством применения структурированных SQL-запросов). Таким образом, публичность научных коллекций в условиях применения общедоступных WEB-ориентированных программных средств (а именно браузеров) либо затруднена, либо невозможна. Дополнительные затруднения в данном случае создаёт известная проблема нерелевантности результатов поиска в сети Интернет какого-либо ресурса самого по себе. С одной стороны, данная проблема связана с принципами и алгоритмами работы сетевых информационно-поисковых систем (далее - ИПС). С другой стороны, релевантность результатов поиска зависит от формы представления сведений о коллекции или представления данных в самой коллекции. При этом заметим, что индексация базы данных научной коллекции средствами ИПС не представляется возможной. Одним из способов организации публичного доступа пользователей сети Интернет к сведениям, аккумулированным в электронной научной коллекции, может служить создание некоего виртуального представления о коллекции, во-первых, отличного от тривиальной текстовой аннотации, во-вторых, пригодного для управляемого создания ИПС поискового образа такой коллекции в WEB, в-третьих, пригодного для автоматического синтеза аннотаций в зависимости от запросов пользователей, в-четвёртых, реализованного стандартным машиночита- емым образом, в-пятых, позволяющего извлечь сведения из коллекции без обращения к базе данных коллекции. В соответствии с принципом систематизации объектов хранения научные коллекции разделяют на документальные и фактографические. В настоящей работе описывается способ обеспечения публичного доступа к научным электронным коллекциям второго типа посредством управления созданием поисковых образов таких коллекций WEB-ориентированными информационными поисковыми системами.
О публичном доступе к данным научных электронных коллекций
Научные коллекции представляют собой информационные системы, как правило, включающие реляционную базу данных, программные средства обработки данных, а также средства обеспечения пользовательского и программного WEB-интерфейсов доступа к базе данных коллекции. С одной стороны, современные системы управления базами данных вполне позволяют внешним клиентам осуществлять запросы к базе данных коллекции (например, SQL-запросы) на уровне программного интерфейса. С другой стороны, такой способ доступа к данным коллекций возможен при условии предопределённой интегрированности клиентов и коллекции, в том числе, например, клиенту должна быть известна структура данных, а также должен быть предопределён статус клиента в системе идентификации клиентов и пользователей. В противном случае доступ к содержанию научной коллекции будет невозможен. В большинстве случаев коллекции оригинальных данных, как правило, за- крыты для внешних клиентов. В данной ситуации в целях обеспечения публичности и транспарентности результатов научных исследований, представленных в электронных коллекциях, владельцы таких ресурсов используют различные способы организации доступа к ресурсам как таковым. Например, силами ассоциаций владельцев коллекций создаются так называемые порталы – дополнительные WEB-ресурсы, аккумулирующие сведения в виде аннотаций предметных коллекций, например, для одной отрасли науки [0; 0]. Такие ресурсы могут иметь собственные информационно-поисковые механизмы [0], однако для их реализации необходимо наличие общих для категории коллекций или предметной области классификационных признаков, что в некоторых случаях представляется затруднительным, например, в случае оригинальности предметов коллекционирования или в случае новизны принципов структурирования данных коллекции. При этом заметим, что в отношении документальных коллекций, структурированных, как правило, на основании наборов библиографических атрибутов, организация навигации и поиска объектов хранения не составляет особых проблем [0].
Для большинства клиентов сети Интернет (то есть потенциальных пользователей научных коллекций) единственным приемлемым средством доступа к данным фактографических коллекций служит использование WEB-ориентированных информационно-поисковых систем общего назначения. При этом поиск электронных коллекций (впрочем, как и поиск любого другого ресурса) осуществляется на осно- вании абстрактных (неструктурированных) запросов пользователей и результатов индексации содержания XHTML-документов электронной коллекции. Известно также, что вероятность обнаружения пользователем ресурса с коллекцией, содержащей интересующие его сведения, крайне невелика. Причиной этому служит низкая релевантность результатов запросов, которая обусловлена, во-первых, содержанием XHTML-документов в составе электронной коллекции, во-вторых, содержанием сформированного поисковой системой на основании таких документов поискового образа ресурса, в-третьих, результатами анализа соответствия элементов поискового запроса и поискового образа ресурса, в-четвёртых, результатами накопленной статистики предыдущих посещений ресурса. При этом также известно, что формирование поискового образа ресурсов (в том числе и электронных коллекций) происходит случайным образом.
В настоящее время для повышения релевантности результатов поиска применяется несколько способов. Во-первых, в целях управления формированием поискового образа ресурса используются дополнительные способы структурирования XHTML-документов в составе ресурса. Для этого применяется специальная микроразметка XHTML-документов [0]. Машиночитаемые теги такой разметки позволяют ИПС создать более адекватный исходному XHTML-документу (но, заметим, не содержанию коллекции) поисковый образ и, как следствие, генерировать более релевантные запросу результаты поиска в виде краткой аннотации ресурса (или, иначе, «сниппета»). Во- вторых, применяются те же методы дополнительного структурирования
XHTML-документов, но уже на уровне описания семантики ресурса (то есть коллекции). С одной стороны, машиночитае-мость такого описания обеспечивается существованием и применением стандартов в области разметки XHTML-документов [0; 0; 0] . С другой стороны, для семантически связанного представления о содержании коллекции необходимо наличие, расширение существующей или создание новой онтологической модели научной коллекции.
Как известно, для создания онтологической модели домена необходимо определение концептов, установление отношений между концептами (например, таксономии), а также определение свойств концептов и их экземпляров [0] . При этом процесс создания онтологий следует квалифицировать как эвристический, не имеющий однозначных критериев «правильности» результатов (например, одним из критериев служит максимальная близость модели к объектам домена и отношениям между ними).
О разработке онтологической модели научной коллекции Вопросам создания онтологий посвящено множество работ, однако мы рассмотрим ситуацию с созданием онтологической модели для существующей научной коллекции, представляющей собой информационную систему с фактографической реляционной базой данных недедуктивного типа. Одним из известных решений данной задачи является синтез онтологической модели посредством анализа структуры логической мо- дели реляционной базы данных (или, иначе, анализа метаданных) [11; 12]. В силу фрагментированности реляционной базы данных, а также по причине возможного наличия суррогатных типов сущностей и атрибутов, не имеющих смыслового содержания, для верификации синтезируемых названным способом онтологий указанный метод предполагает применение тезаурусов из других онтологий. При наличии общих онтологий для предметной области такая задача вполне разрешима. Однако содержание или концепция научной коллекции могут иметь оригинальность и научную новизну, не согласующиеся с имеющимися онтологиями полностью либо частично. Очевидно, что в данном случае не приходится рассчитывать на адекватность результатов синтеза онтологии путём преобразования логической модели базы данных.
Следует заметить, что концепция архитектуры баз данных [13] предполагает существование трех уровней представления баз данных, а именно: концептуальный, логический и физический. При условии согласованности концептуальной, логической и физической моделей данных первая из таких моделей вполне может быть пригодна в качестве прототипа для создания онтологической модели (или являться ею изначально). К наиболее известным видам концептуальных моделей данных относятся ER-модели [14; 15], UML-модели [16; 17] и объектно-ролевые (ORM) модели [18;19]. Применение какого-либо из указанных видов – вопрос предпочтения, однако все такие модели хорошо отражают семантику домена, в частности, показывают концепты доменов
(в виде типов сущностей, классов или объектов-исполнителей ролей), соотношения между концептами, а также свойства концептов. Таким образом, любой из перечисленных видов моделей может быть использован для построения онтологической модели коллекции.
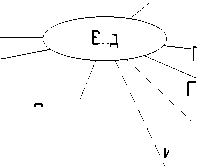
Рассмотрим в качестве примера концептуальную модель данных научной коллекции сведений об объектах живой природы, а именно сведений о видовом биоразнообразии сосудистых растений Хабаровского края в аспекте их приуроченности к определённым кластерам (например, географическим зонам, ареалам, районам, различного вида ценозам и т.д.). Данная концептуальная модель представлена в виде ER-схемы на рисунке 1.
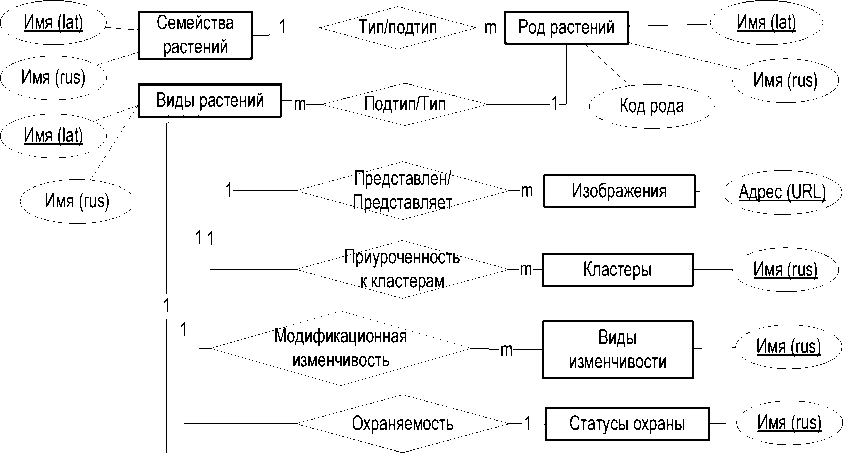
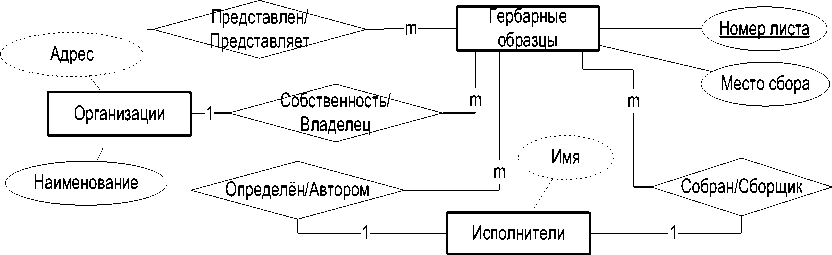
Рис 1 – ER-cхема коллекции
Рисунок 1 – ER-схема коллекции
Для упрощения понимания в ER-схеме концептуальной модели коллекции, приведённой на рисунке 1, использованы категории типов сведений, например кластеры, признаки вида, статусы охраны видов. Пример набора категорий типов сведений, используемых в научной коллекции сведений о растениях, приведён в таблице 1. С примерами экземпляров указанных типов сведений можно ознако- миться в сборнике «Сосудистые растения Хабаровского края и их охрана» [20]. Заметим, что в приведённом примере уникальность и оригинальность научной коллекции проявляется именно в составе и содержании наборов категорий, а также в содержании наборов типов в категориях. Таким образом, публикация сведений указанного характера представляется весьма полезной и даже необходимой.
Рассматривая ER-схему (рисунок 1), нетрудно увидеть, что бинарные отношения могут быть представлены в виде предикатов первого порядка, например «Имя_отношения (Тип сущности 1, Тип сущности 2)». В таблице 2 показан очевидный результат такой интерпретации.
Наименования заголовков в таблице 2 соответствуют элементам предикатной схемы «Предикат (Субъект 1, Субъект 2)». Заметим, что в таблице 2 субъекты в первой колонке в целом составляют шесть типов, при этом предикаты во втором столбце – 10 типов.
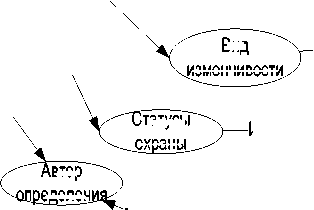
Некоторые субъекты в третьей колонке исполняют одновременно несколько предикатных ролей, например семейство, род и т.д. Сказанное означает, что такие субъекты участвуют в более чем одной тройке, например «субъект 1 – предикат – субъект 2» и «субъект 2 – предикат – субъект 3». На рисунке 2 приведена иллюстрация графа, соответствующего набору предикатов в таблице 2.
Таблица 1 – Категории типов сведений о растениях
|
Наименования категорий |
Наименования типов |
|
Кластеры |
Широтные ареалы Долготные ареалы Флористические районы Луговой фитоценоз Антропогенный фитоценоз Скальный фитоценоз Болотный фитоценоз Горно-тундровый фитоценоз Прибрежноводный фитоценоз Лесной фитоценоз |
|
Модификационная |
Габитус |
|
изменчивость |
Реликтовость Активность Высота Признаки по Раункиеру Фенологические признаки Виды побегов Подземные вегетативные органы |
|
Охраняемость вида |
Издания Красной книги Статусы охраны |
Таблица 2 – Предикатная форма концептуальной модели данных коллекции сведений о растениях
|
№ |
Субъект 1-го предиката |
Предикат |
Субъект 2-го предиката |
|
1 |
Вид растения |
Имеет свойство |
Наименование (русское) |
|
2 |
Вид растения |
Имеет свойство |
Наименование (латинское) |
|
3 |
Род растения |
Имеет свойство |
Наименование (русское) |
|
4 |
Род растения |
Имеет свойство |
Наименование (латинское) |
|
5 |
Род растения |
Имеет свойство |
Код рода растения |
|
6 |
Семейство растений |
Имеет свойство |
Наименование (латинское) |
|
7 |
Семейство растений |
Имеет свойство |
Наименование (русское) |
|
8 |
Вид растения |
Приуроченность |
Кластеры |
|
9 |
Вид растения |
Модификационная изменчивость |
Виды изменчивости |
|
10 |
Вид растения |
Представлен изображением |
Фотография |
|
11 |
Вид растения |
Представлен экземпляром |
Гербарный образец |
|
12 |
Вид растения |
Охраняемость вида |
Статусы охраны |
|
13 |
Вид растения |
Является подтипом |
Род растения |
|
14 |
Род растения |
Является подтипом |
Семейство растений |
|
15 |
Гербарный образец |
Имеет свойство |
Номер листа |
|
16 |
Гербарный образец |
Имеет свойство |
Код рода растения |
|
17 |
Гербарный образец |
Собственность |
Организация |
|
18 |
Гербарный образец |
Определён автором |
Исполнитель |
|
19 |
Гербарный образец |
Собран |
Исполнитель |
|
20 |
Гербарный образец |
Имеет свойство |
Место сбора |
|
21 |
Исполнитель |
Имеет свойство |
Имя |
|
22 |
Организация |
Имеет свойство |
Наименование |
|
23 |
Организация |
Имеет свойство |
Адрес |
Имя (lat)
Имеет свойство
Имеет свойство

Семейство
Является подтипом
Род
Имеет свойство
Имеет свойство
Имя (lat)
Имеет свойство
Имя (lat)
Имя (rus)
Имя (rus)
Место сбора
Является подтипом
Имеет свойство
Имеет свойство
Вид
Представлен
Приурочен
Представлен
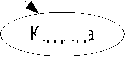
Код рода
Имя (rus)
Адрес (URL) Имеет свойство
Имеет свойство
ербарный образе
Имеет свойство
Номер листа
Организация
Собран
Адрес
Имеет свойство
Собственность
Определён автором
Имеет изменчивость Имеет статус охраны
Изображение
Кластер
Имеет свойство
Имя (rus)
Имеет адрес
Наименование
борщик образца
втор еделен татусы охраны
Вид изменчивости
Роль
Исполнитель
Роль
Имеет свойство
Имя (rus)
Имеет свойство
Имя (rus)
Имя
Имеет свойство
Рис 2 – Граф коллекции
Рисунок 2
Предположим, что нам удалось транслировать концептуальную модель базы данных в схему онтологической (а именно предикатной) модели научной коллекции. Далее полученную онтологическую модель следует преобразовать к машиночитаемому виду, пригодному для обработки WEB-ориентированными информационно-поисковыми системами, браузерами (например, Google, Yahoo!, Yandex и т.д.), а также семантическими WEB-сервисами в составе указанных программных систем. Как известно, машино-читаемость и семантическая согласованность предметных онтологических моделей в WEB 3.0 реализуется посредством применения тезаурусов в составе онтологий общего характера. При этом такие тезаурусы одновременно описывают пространство имён (или, иначе, набор машиночитаемых ключевых слов), а онтологии содержат схемы для машинного распознавания комбинаций элементов тезаурусов. В настоящее время в качестве таких онтологий применяются: RDF[7] – тезаурусы имён концептов, предикатов, а также схемы их соотношений; RDFS – тезаурусы имён категорий концептов, предикатов, а также категорий схем их соотношений [9]; OWL (Ontology Web Language) – тезаурус, схемы, отношения, а также ограничения. В соответствии с общей онтологией RDF отношения между элементами предметных онтологических моде-
– Граф коллекции лей описываются в виде так называемых триплетов – «объект – предикат – субъект». Нетрудно видеть, что предикатная форма концептуальной модели данных коллекции (таблица 2) может быть без потерь преобразована к такой схеме. При этом заметим, что исходная концептуальная модель должна соответствовать требованиям нотации ER-моделирования (в частности, содержать именно бинарные отношения).
Как было ранее сказано, триплетная онтологическая RDF-модель должна быть внедрена в XHTML-документ (или документы) в составе электронной научной коллекции (то есть WEB-ресурса). Для этих целей мы используем один из специальных форматов, предназначенных для сериализации графа RDF-триплетов, а именно Turtle (от англ. – Terse RDF Triple Language ), который был разработан Дэйвом Бэкеттом [21].
Во-первых, описание RDF-модели на языке разметки Turtle позволит семантическим WEB-сервисам сформировать заключения, основанные на схеме семантического графа (рисунок 2). Например, заключения о том, что в некоей коллекции (например, расположенной по адресу: присутствуют сведения следующего характера: семейства растений приурочены к такому-то фитоценозу и при этом характеризуются рядом признаков. При этом нетрудно видеть, что такие сведения изначально отсутствуют в RDF-графе на рисунке 2.
Во-вторых, нотация RDF/Turtle, применяемая для разметки HTML-документа, находящегося в составе научной коллекции, позволит действующим ИПС (например, Google, Yahoo!, Yandex и т.д.) отобразить сведения о такой коллекции в составе сниппета, выдаваемого ИПС в ответ на пользовательские запросы. Другими словами, это даст возможность пользователям получить доступ к сведениям коллекции, используя исключительно общедоступные программные средства (интернет-браузеры).
В таблице 3 приведены десять типо- вых предикатов, соответствующих таблице 2 и графу на рисунке 3, а также их описание в нотации Turtle. Префиксы «rdf:», «foaf:» и «rdfs:» указывают на то, что используемые с такими префиксами наименования предикатов и субъектов определены во внешних справочниках (или, иначе, онтологиях [7]), например, «rdf: » (рисунок 3). Префикс «p:» означает, что имена предикатов и субъектов определены рекурсивным образом в локальном HTML-документе в составе коллекции-реcурса (например, рисунок 3).
Таблица 3 – Предикаты и элементы нотации RDF(Turtle)
|
№ |
Наименование предиката |
Описание в нотации RDF(Turtle) |
|
1 |
Имеет свойство |
rdf:name |
|
2 |
Приурочен |
p:приурочен |
|
3 |
Имеет изменчивость |
p:имеет |
|
4 |
Представлен изображением |
p:изменчивость |
|
5 |
Представлен экземпляром |
rdf:type |
|
6 |
Имеет статус охраны |
p:охраняемость |
|
7 |
Является подтипом |
rdfs:subclassOf |
|
8 |
Собственность |
rdf:ownerby |
|
9 |
Определен автором |
p:определил |
|
10 |
Собран |
p:собрал |
На рисунке 3 показан пример содержания HTML-документа, включающего сериализацию RDF-графа с применением нотации Turtle. Сделаем некоторые замечания и пояснения. В том случае, когда в качестве значений предикатной перемен- ной «Субъект 2» (то есть правой части RDF-триплета) ожидаются не элементы концептуальной ER-схемы, но литералы (то есть экземпляры типов), то в соответствующих триплетах RDF-схемы используются пустые узлы (обозначение – «[ ]»).
Символы «@ru» и «@la» означают ожидаемый язык для таких литералов. Нетрудно видеть, что в данном случае RDF-граф полностью отражает структуру концептуальной модели коллекции. При этом описание сериализованного RDF-графа составляет формальное представление коллекции в WEB.
В приведённом нами примере такое формальное описание позволит получить требуемый поисковый образ научной коллекции данных о связи видов растений с кластерами, данных о модификационной изменчивости видов и т.д.
В таблице 4 приведены субъекты предикатов, соответствующих таблице 2 и схеме графа на рисунке 2, а также их описание в нотации Turtle.
Таблица 4 – Субъекты предикатов и элементы RDF(Turtle)
|
№ |
Субъекты предикатов |
Описание в нотации RDF(Turtle) |
|
1 |
Вид растения |
p:Вид |
|
2 |
Наименование (русское) |
[ ]@ru |
|
3 |
Наименование (латинское) |
[ ]@la |
|
4 |
Род растения |
p:Род |
|
5 |
Семейство растений |
p:Семейство |
|
6 |
Кластеры |
p:Кластеры |
|
7 |
Виды изменчивости |
p:Модификации |
|
8 |
Фотография |
rdf:photo |
|
9 |
Гербарный образец |
p:Экземпляр |
|
10 |
Статусы охраны |
p:Статус |
|
11 |
Номер листа |
rdf:identifier |
|
12 |
Код рода растения |
rdf:identifier |
|
13 |
Организация |
rdf:organization |
|
14 |
Исполнитель |
p:Исполнители |
|
15 |
Имя исполнителя |
foaf:name 1 |
|
16 |
Место сбора |
rdf:place |
|
17 |
Адрес (организации) |
rdf:PostalAddres [ ] |
|
18 |
Автор определения |
p:Эксперт |
|
19 |
Сборщик образца |
p:Сборщик |
1-FOAF (Friend-of-a-Friend) – тезаурус онтологии [21] для описания людей, их деятельности и отношений с другими людьми и объектами.
@prefix rdf: <>.
@prefix rdfs: <>.
@prefix foaf: <>.
@prefix p:
p:Семейство a rdfs:Class.
p:Семейство rdf:name [ ]@ru.
p:Семейство rdf:name [ ]@la.
p:Род rdfs:subclassOf p:Семейство.
p:Род rdf:name [ ]@ru.
p:Род rdf:name [ ]@la.
p:Род rdf:identifier [ ].
p:Вид rdfs:subclassOf p:Род.
p:Вид rdf:name [ ]@ru.
p:Вид rdf:name [ ]@la.
p:Вид rdf:photo [ ]@url.
p:Экземпляр rdf:type p:Вид.
p:Экземпляр rdf:FindAction rdf:place.
p:Экземпляр rdf:ownerby rdf:organization.
p:Экземпляр rdf:identifier [ ].
rdf:organization rdf:name [ ].
rdf:organization rdf:PostalAddres [ ].
p:Кластеры a rdfs:Class.
p:Кластеры rdf:name [ ]@ru.
p:КластерыN rdfs:subclassOf p:Кластеры
p:КластерыN rdf:name [ ]@ru.
p:приурочен a rdf:Property.
p:Вид p:приурочен p:КластерN.
p:Модификации a rdfs:Class.
p:Модификации rdf:name [ ]@ru.
p:МодификацииN rdfs:subclassOf p:ВидOfChanges.
p:МодификацииN rdf:name [ ]@ru.
p:изменчивость a rdf:Property.
p:Вид p:изменчивость p:Модификации.
p:Статус a rdfs:Class.
p:Статус rdf:name [ ]@ru.
p:СтатусN rdfs:subclassOf p:Статус.
p:охраняемость a rdf:Property.
p:Вид p:охраняемость p:СтатусN.
p:Исполнители rdfs:subClassOf foaf:Person.
p:Исполнители foaf:name [ ]@ru.
p:Эксперт rdf:type p:Исполнители.
p:Сборщик rdf:type p:Исполнители.
p:определил a rdf:Property.
p:Эксперт p:определил p:Экземпляр.
p:собрал a rdf:Property.
Рисунок 3 – Пример сериализации графа RDF в нотации Turtle
Заключение
В настоящей работе рассматривается способ обеспечения доступа широкого круга пользователей сети Интернет, не обладающих знаниями в области программирования и не владеющих специальными проблемно-ориентированными программными средствами, к данным научной электронной коллекции. В частности, описывается подход при формировании поискового образа научной коллекции данных для случая, когда потенциальные пользователи коллекции имеют в своём распоряжении исключительно общедоступные программные средства (а именно WEB-браузеры, а также семантические сервисы стандарта WEB 3.0). Структура и содержание поискового образа коллекции формируются в ходе преобразования концептуальной ER-схемы данных коллекции в триплетный RDF-граф с последующей сериализацией такого графа с применением нотации Turtle. Полученное сериализованное описание RDF-графа пригодно для внедрения в структуру HTML-документа в составе электронной коллекции. В свою очередь, структурированное посредством HTML описание коллекции является, во-первых, средством управления алгоритмами индексации общедоступных информационно-поисковых систем (например, Google, Yahoo!, Yandex и т.д.), во-вторых, пригодно для обработки семантическими WEB-сервисами.
Построение поискового образа научной коллекции рассматривается на примере коллекции данных о биоразнообразии растений на территории Хабаровского края, однако описываемый принцип может быть также применён и для любых других случаев фактографических научных коллекций.
Список литературы О формировании семантического поискового образа научной коллекции данных как web-ресурса
- Генетические и биологические (зоологические и ботанические) коллекции Российской Федерации // www.sevin.ru/collections (дата обращения 30.05.2019).
- Байков К. С. Электронные коллекции и проблемы биоразнообразия / К. С. Байков, Н. Б. Ермаков, И. Ю. Коропачинский, А. М. Федотов, Н. А. Колчанов, Ю. И. Шокин // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: вторая Всероссийская научная конференция. 26-28 сентября 2000 года.
- Захаров А. А. / А. А. Захаров, В. И. Филиппов // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: труды 11-й Всероссийской научной конференции. Петрозаводск, Россия, 2009.
- Зоологическая государственная коллекция Мюнхена // www.zsm.mwn.de/e/ (дата обращения 30.05.2019).
- Смирнов И. С. Развитие информационно-поисковой системы ЭКОАНТ на основе электронной коллекции беспозвоночных Арктики и Антарктики / И. С. Смирнов, А. Л. Лобанов, А. В. Неелов, А. Г. Кирейчук // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: труды 15-й Всероссийской научной конференции. 14-17 октября 2013 года. Ярославль, 2013.
- Когаловский М. Р. Систематика коллекций информационных ресурсов в электронных библиотеках / М. Р. Когаловский // Программирование. 2000. № 3. С. 31-52.
- Спецификация языка микроразметки // schema.org (дата обращения 30.05.2019).
- Спецификация онтологии RDF // www.w3.org/RDF (дата обращения 30.05.2019).
- Спецификация онтологии RDFS // www.w3.org/2000/01/rdf-schema (дата обращения 30.05.2019).
- Когаловский М. Концептуальное моделирование и онтологические модели / М. Когаловский, Л. Калиниченко // Онтологическое моделирование: труды симпозиума в г. Звенигороде. 19-20 мая. Звенигород, 2008.
- Биряльцев Е. В. О доступе к электронным коллекциям в виде реляционных баз данных на основе онтологий / Е. В. Биряльцев, А. М. Гусенков, А. М. Елизаров // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: труды 9-й Всероссийской научной конференции. Переславль-Залесский, 2007.
- Вдовицын В. Т. Онтологии для тематического поиска данных в коллекциях электронной библиотеки / В. Т. Вдовицын, В. А. Лебедев // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: труды 10-й Всероссийской научной конференции. Дубна, 2008.
- ANSI/X3/SPARC Study Group on Data Base Management Systems: 1975, Interim Report. FDT, ACM SIGMOD bulletin. Volume 7, No. 2.ANSI/X3/SPARC Study Group on Data Base Management Systems: 1975, Interim Report. FDT, ACM SIGMOD bulletin. Volume 7, No. 2.
- Peter Pin-Shan Chen. The Entity-Relationship Model-Toward a Unified View of Data. ACM Transactions on Database Systems, Volume 1, Number 1, 1976.
- R. do Nascimento Fidalgo, E. Souza, S. Espaсa, J. de Castro, and O. Pastor EERMM: A Metamodel for the Enhanced Entity-Relationship Model. ER, volume 7532 of Lecture Notes in Computer Science, page 515-524. Springer, 2012.
- Olive Conceptual Modeling of Information Systems.: Springer-Verlag Berlin Heidelberg, 2007.
- Eriksson Hans-Erik, Penker Magnus. Business Modeling with UML: Business Patterns at wo rk. Wiley Computer Publishing, February, 2000.
- G. M. Nijssen, Terry A. Halpin Conceptual schema and relational database design - a fact oriented approach.: Prentice Hall, 1989, , pp. I-XIV, 1-342.
- ISBN: 978-0-7248-0151-0
- T. Halpin Object-role modeling (ORM/NIAM). In P. Bernus, K. Mertins, & G. Schmidt (Eds.), Handbook on architectures of information systems (2nd ed.), 2006, pp. 81-103. Heidelberg, Germany: Springer.
- Шлотгауэр С. Д. Сосудистые растения Хабаровского края и их охрана / С. Д. Шлотгауэр, М. В. Крюкова, Л. А. Антонова. Владивосток - Хабаровск: ДВО РАН, 2001. 195 с.
- Спецификация языка описания языка Turtle // www.w3.org/TR/turtle/#sec-intro (дата обращения 30.05.2019).
- Спецификация онтологии FOAF // xmlns.com/foaf/0.1 (дата обращения 30.05.2019).
