О возможности смыслового анализа информации для выявления информационных интересов пользователей

Автор: Краснов Сергей Александрович
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 2, 2019 года.
Бесплатный доступ
Рассматривается возможность применения метода латентно-семантического анализа (ЛСА) для выявления информационных интересов пользователей в web-пространстве. Показана положительная динамика применения метода ЛСА в различных направлениях, где требуется смысловой анализ информации. Предложены основные модули и схема реализации программного комплекса, позволяющего осуществлять сбор, обработку и представление информационных интересов пользователей.
Латентно-семантический анализ, смысловой анализ информации, рубрикация, информационные интересы пользователей
Короткий адрес: https://sciup.org/148309530
IDR: 148309530 | УДК: 004.912+002.513.5 | DOI: 10.25586/RNU.V9187.19.02.P.157
About the possibility of semantic analysis of information to identify informational interests of users
Keywords: latent-semantic analysis, semantic analysis of information, rubrication, informational interests of users
Текст научной статьи О возможности смыслового анализа информации для выявления информационных интересов пользователей
158 в ыпуск 2/2019
ят вопросы поиска, отбора и автоматического смыслового рубрицирования информации в условиях динамичного изменения экономико-политической обстановки и ее факторов, когда многократно вырос перечень информационных агентств и порталов, объемы передаваемого ими контента. При этом перечень задач по информационному обеспечению руководства организаций и других заинтересованных сотрудников постоянно растет.
В настоящее время, несмотря на проведение работ по исследованию и разработке методов и программного обеспечения поиска, анализа и структурирования информации, их применение носит инициативный и разрозненный характер с задействованием прежде всего доступных коммерческих систем, которые не настроены на решение специфических задач поиска, отбора и рубрикации информации, востребованной пользователями. Кроме того, они реализованы на устаревших статистических методах и алгоритмах.
Сложившаяся ситуация затрудняет процессы мониторинга и анализа информационных интересов пользователей глобальной сети Интернет, ее автоматическое смысловое рубрицирование, необходимое для удобства анализа и включения полученной информации в процессы, направленные на выработку решений для адаптации организации к современным востребованным условиям.
Исходя из вышесказанного необходимо разработать программный комплекс, основанный на современных методах интеллектуального смыслового анализа информации, позволяющий структурировать получаемую информацию из глобальной сети Интернет в требуемом представлении. Ее предназначение заключается в непрерывном мониторинге и обобщении больших объемов текстовой информации, полученной из глобальной сети Интернет, в процессе наблюдения за одиночными информационными потребностями конкретного пользователя или группы пользователей.
Смысловое структурирование предлагается осуществлять на базе методов и методик смысловой обработки информации, принципиально отличающихся от доминирующих в настоящее время статистических методов, выявлением скрытых семантических взаимосвязей между информационными признаками всего множества неструктурированных данных с помощью метода ЛСА [3; 10].
Основная идея латентно-семантического анализа (ЛСА) заключается в том, что совокупность всех контекстов, в которых встречается и не встречается данное слово, задает множество обоюдных ограничений, которые позволяют определить похожесть смысловых значений слов и множеств слов между собой. Кроме того, ЛСА измеряет корреляционные зависимости типа «терм – терм», «терм – вектор» и «вектор – вектор». Результативность данного метода зависит не только от частот использования слов (термов) в документах, но и от выявления более глубоких (скрытых) связей.
Исходной информацией для ЛСА является матрица термов на документы, которая описывает используемый для обучения системы набор данных. Элементы этой матрицы содержат частоты использования каждого терма в каждом документе.
Один из самых распространенных вариантов ЛСА основан на использовании разложения исходной матрицы по сингулярным значениям (SVD – Singular-Value Decomposition). Используя SVD, большая исходная матрица разлагается во множество из k , обычно от 70 до 200 ортогональных матриц, линейная комбинация которых является хорошим приближением исходной матрицы.
Краснов С.А. О возможности смыслового анализа информации... 159
Согласно теореме о сингулярном разложении, любая вещественная прямоугольная матрица X может быть разложена в произведение трех матриц:
X = UΣVT, где матрицы U и V – ортогональные, а ∑ – диагональная матрица, значения на диагонали которой называются сингулярными значениями матрицы X.
Особенность такого разложения в том, что если в ∑ оставить только k наибольших сингулярных значений, а в матрицах U и V – только соответствующие этим значениям столбцы, то произведение получившихся матриц ∑lsa, U lsa и V lsa будет наилучшим приближением исходной матрицы X матрицей ранга k :
X ≅ X = U lsa∑lsa V lsa.
̑
Идея такого разложения и суть латентно-семантического анализа заключается в том, что если в качестве X использовалась матрица термов на документ, то матрица X, содержащая только k первых линейно независимых компонент X, отражает основную структуру ассоциативных зависимостей, присутствующих в исходной матрице, и в то же время не содержит шума.
Таким образом, каждый терм и документ представляются при помощи векторов в общем пространстве размерности k (так называемом пространстве гипотез). Близость между любой комбинацией термов или документов может быть легко вычислена при помощи скалярного произведения векторов.
Метод анализа динамики изменения сингулярных чисел матрицы «терм – документ» с автоматическим выбором диапазона используемых ранговых значений.
На первом шаге необходимо сформировать матрицу А «терм – документ», которая опишет анализируемые документы и будет содержать исходные данные для метода ЛСА. Ее элементы будут содержать веса термов, полученные после применения статистической меры tf – idf (отношение частоты слов к инверсной частоте документа) 0 ≤ dij ≤ 1 и НВ матрицы:
-
d == , w = tf log — , tf = , (1)
-
w . ' ' df . j' S ,".
где dij – нормированные веса по tf – idf , (частота встречаемости термина – обратная документная частота), 0 < d i. < 1;
w ij – нормированный вектор wij в евклидовом пространстве;
dfj – документная частота (число документов, в которых встретилось j -е слово);
| D | – число анализируемых документов;
ni – количество употреблений слова в документе;
∑ knk – общее количество слов содержащихся в документе;
tfi j – частота встречаемости слова в документе (число раз, которое j -е слово встретилось в i -м документе).
В tf – idf наибольший вес получают слова с высокой частотой в пределах документа и с небольшой частотой встречаемости в других документах. При НВ матрицы «терм – документ» скалярное произведение не зависит от нормы векторов. Это позволяет упростить сравнение результатов скалярных произведений. Операция нормирования производится перед расчетом l – степени соответствия документов.
Выпуск 2/2019
Далее необходимо выполнить сингулярное разложение матрицы А в произведение трех матриц:
A = UWVT, где U и V – унитарные матрицы, которые состоят из левых и правых сингулярных векторов, а W – матрица с неотрицательными элементами на диагонали, которые называются сингулярными значениями матрицы А.
Согласно теореме Эккарта – Янга, если в матрице W оставить только наибольшие сингулярные значения σ, а в матрицах U и V – соответствующие этим значениям столбцы, то матрицы U σ и V σ будут лучшими их приближениями, отражающими ассоциативные зависимости представления термов и документов в пространстве размерности σ [17; 20].
Следующим шагом является оптимальный выбор ненулевых сингулярных значений σ1 ≥ σ2 ≥ ... ≥ σ n > 0 матрицы A , которые влияют на результат выявления противоречивой и дублирующей информации. Результатом приведения матрицы A к рангам, имеющим близкие к нулю сингулярные значения, являются равные матрицы, учет которых ведет к увеличению вычислительной сложности метода ЛСА и тем самым снижает оперативность выявления противоречивой и дублирующей информации. Чтобы решить задачу оптимального выбора сингулярных значений предлагается описанный ниже эвристический метод выбора значимых рангов, который является сущностью метода анализа динамики изменения сингулярных чисел матрицы «терм –документ» с автоматическим выбором диапазона используемых ранговых значений.
Определим функцию f ( i ) = σ i , i ∈ N , i < P , где Р – количество документов. Значимыми рангами являются только ранги rp , rp +1, ..., rm –1, rm , p ≤ m , заключенные между соответствующими сингулярными значениями σ p ≥ σ m ≥ 0, претерпевающими резкое изменение ∆σ i = σ i – σ i –1, i ∈ { p ; m } относительно предыдущих сингулярных значений σ i ≥ σ p , i ≤ p; σ i ≥ σ m , i ≤ m .
Определение границ значимых рангов осуществляется с помощью понятия производной функции сингулярных значений f '( i ) = ст i - ст i —1, i e N, i < n.
Далее осуществляется поиск максимального значения производной функции f ' ma, , достижимого при σmax, 1 < max ≤ .
Затем определяется первый локальный минимум σp, следующий за σmax. Ранги r1, r2, ..., ri, ...,
rp–1, rp, i ≤ p, соответствующие сингулярным значениям, большим σp признаются не- значимыми.
В качестве правой границы значимых рангов выбирается ранг rn , соответствующий последнему ненулевому сингулярному значению σ n .
На заключительном этапе необходимо рассчитать λ документов, используя КМБ:
cos(X.,X ) = V x(i)x(i), j> if it^^=1 j i где x^x^ - элементы разных векторов, между которыми вычисляется мера близости; M – размерность пространства векторов.
Значения КМБ ограничены промежутком [–1; 1] при использовании операции НВ. Степень соответствия X ji векторов X t j , X i ( i < j < P ) вычисляется для каждого значимого ранга r , p < l < m . Далее необходимо вычислить результирующую X i j векторов - X j , - X i :
_ У m X l
X ,l = ^ l = p j , '' m — p + 1
.
Краснов С.А. О возможности смыслового анализа информации...
Таким образом, получаем результирующую степень соответствия для конкретной пары документов по всему значимому диапазону ранговых значений. Полученное значение необходимо сравнить, например, с пороговым значением для автоматического или автоматизированного принятия решения по устранению дублирующих и (или) противоречивых данных, классификации информации и (или) фильтрации информации.
Отметим, что метод автоматического определения диапазона используемых ранговых значений позволяет с большей точностью гарантировать, что данные действительно противоречивые или дублирующие, потому что значения l всех пар векторов оцениваются на каждом значимом ранге. При этом случайные всплески полученных значений l при неправильных ранговых значениях сглаживаются, а значения l явно дублирующих (противоречивых) данных стремятся к единице, так как находится среднее арифметическое по всем значениям l одной пары векторов матриц, полученных из диапазона используемых ранговых значений.
Результаты исследований показали, что применение метода ЛСА в задачах поиска, рубрикации, выявления дублирующей информации позволяет эффективно выявлять смысловые взаимосвязи между термами. Это позволило повысить автоматизацию решения задачи устранения конфликтов и избыточности информации, повысить точность при поиске рубрикации информации. Гистограммы, представленные на рисунке, это подтверждают. Гистограмма на рисунке а указывает на меры близости различных групп документов, а на рисунке б – на дублирование заголовков [2; 6; 7; 11].
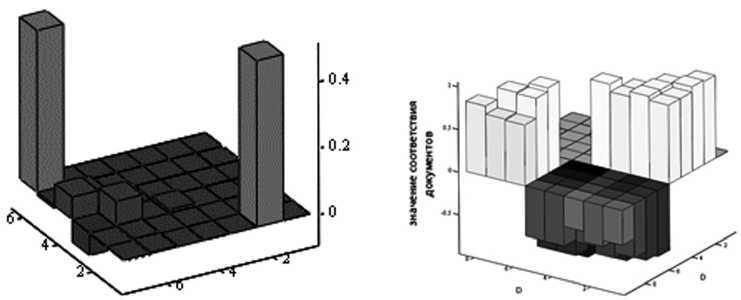
а
б
Гистограммы, показывающие эффективность применения метода ЛСА
Исходя из вышесказанного можно предположить, что для решения задачи выявления информационных интересов пользователей в глобальной сети Интернет будет эффективен метод ЛСА. Поэтому разрабатываемый ПК должен включать в себя модули:
-
• слежения за определенным диапазоном в истории посещения информационных ресурсов web-пространства;
-
• автоматического сбора информации;
-
• анализа, кластеризации и рубрикации информации на основе метода ЛСА;
-
• настраиваемых отчетных документов и форм.
Автоматизация и непрерывность процессов сбора и рубрикации информации на базе интеллектуальных методов и методик ее обработки (лексического, синтаксического и се-
162 в ыпуск 2/2019
мантического анализа) позволят повысить оперативность и точность рубрикации информации [1; 5; 7; 8; 9].
Для обеспечения процесса выявления информационных интересов пользователей необходимо:
-
1) выбрать определенный диапазон в истории посещения информационных ресурсов web-пространства отобранным пользователем или группой пользователей, т.е. отследить текущую или несколько сессий его или их работы;
-
2) последовательно пройтись по истории сессий, осуществить автоматический сбор текстовой информации с каждого информационного ресурса;
-
3) произвести кластеризацию с последующей рубрикацией полученной информации посещенных им или ими web-страниц при помощи методов смыслового анализа информации;
-
4) проанализировать результаты рубрикации;
-
5) сделать вывод об информационных интересах контролируемого пользователя или группы пользователей;
-
6) Выдать рекомендаций сотрудникам организации, корректирующие функционирование их деятельности с учетом изменения потребностей пользователей.
Применение предложенной схемы выявления потребностей пользователя позволит организации подстраиваться под их интересы своевременно. Это позволит организации находиться на ведущих позициях и своевременно подстраиваться под динамически изменяемую экономическую и политическую ситуацию как в стране, так и в мире.
Список литературы О возможности смыслового анализа информации для выявления информационных интересов пользователей
- Войцеховский С.В., Калиниченко С.В., Краснов С.А., Уланов А.В. Модель оценивания оперативности обработки устаревающей информации // Научное обозрение. 2014. № 3. С. 155-157.
- Краснов С.А., Илатовский А.С., Хомоненко А.Д., Арсеньев В.Н. Оценка семантической близости документов на основе латентно-семантического анализа с автоматическим выбором ранговых значений // Труды СПИИРАН. 2017. № 5 (54). С. 185-204.
- Краснов С.А. Математическая модель метода латентно-семантического анализа в системе семантической рубрикации документов // Компьютерные технологии и информационные системы: сб. науч. тр. ВА ВПВО ВС РФ. Смоленск, 2011. Вып. 18. C. 33-43.
- Краснов С.А. Обзор моделей поиска и методов тематического анализа текстовой информации // Компьютерные технологии и информационные системы: сб. науч. тр. ВА ВПВО ВС РФ. 2011. Вып. 20. C. 35-42.
- Краснов С.А. Уланов А.В, Матвеев С.В. Анализ оперативности обработки информации с ограниченным временем актуальности // Бюллетень результатов научных исследований: электрон. науч. журн. ПГУПС. 2013. Вып. 9 (4). С. 39-47.
