Об управлении группой объектов как о задаче системного анализа

Автор: Корнет М.Е., Медведев А.В., Ярещенко Д.И.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 2 т.21, 2020 года.
Бесплатный доступ
В настоящей работе рассматривается общая постановка задачи идентификации и управления группой объектов. Под группой понимается несколько объектов, объединенных для изготовления того или иного продукта. Главной особенностью является то, что при управлении подобными системами необходимо изменять задающие воздействия для каждого объекта. Сегодня технологический регламент во многих случаях оказывается более широким, чем следовало бы для качественного управления. А это есть следствие того, что нынешняя культура производства (это, в частности, показал опыт обработки данных технологического процесса производства транзисторов на «Светлане») довольно невысока. Это приводит к некоторым организационным проблемам. Следовательно, необходимо иметь те или иные модели объектов, которые естественно отличаются друг от друга и могут быть рассмотрены в условиях как параметрической, так и непараметрической неопределенности. Более того, могут быть случаи, когда объект рассматривается одновременно в условиях как параметрической, так и непараметрической неопределенности по различным каналам. Измерение некоторых переменных осуществляется в значительно больший интервал времени, чем постоянная объекта, поэтому необходимо отличать время измерения технологических переменных и, собственно, запаздывание, присущее самому технологическому процессу с учетом отличия каналов. Это приводит к тому, что динамические процессы по существу вынуждены рассматриваться как безынерционные с запаздыванием. Другой существенной особенностью является то, что компоненты выходных переменных стохастически зависимы заранее неизвестным образом. Использование в этом случае корреляционных или дисперсионных отношений не приводит к успеху. Необходим специальный анализ Т-процессов и умение моделировать подобные процессы. В частности, это является одной из задач настоящей статьи. В ней приведены: Т-процессы, Т-модели и соответствующие разнотипные алгоритмы управления. Рассмотрен процесс гидродепарафинизации дизельного топлива по имеющимся данным, о которых априори можно сказать, что они неполные, т. е. не отражают комплексное поведение технологического процесса. Отсюда становится ясно, что эти данные требуют пополнения, которое сегодня по разным причинам не осуществляется. Таким образом, процесс гидродепарафинизации может быть отнесен к Т-процессу. Моделирование многомерной системы по реальным данным показало, что в этой задаче задающее воздействие для различных объектов должно быть различным. Исключение составляют только задающие воздействия для всего комплекса или группы объектов. Моделирование осуществлялось на основании рассмотренных в статье Т-моделей. Уже отмечалось, что эти модели не следует воспринимать как завершенные, дающие представление о действительности. При дальнейших исследованиях они будут подлежать алгоритмическому уточнению. Решение об этом, естественно, принимает исследователь. Именно на этом этапе дается оценка, что в создавшихся условиях полученные модели и алгоритмы управления могут быть приняты для использования в производственных условиях. Попытка использования существующей теории идентификации и управления для процесса гидродепарафинизации неизбежно приведет к значительному ухудшению и увеличению стоимости компьютерной системы управления качеством данного процесса. (Русскоязычная версия представлена по адресу https://vestnik.sibsau.ru/articles/?id=677)
Группа объектов, идентификация, управление, задающие воздействия, непараметрические алгоритмы, т-процесс, многомерные объекты, адаптация
Короткий адрес: https://sciup.org/148321963
IDR: 148321963 | УДК: 519.711.3 | DOI: 10.31772/2587-6066-2020-21-2-176-186
Managing a group of objects as a task of system analysis
In this paper, we consider the general statement of the problem of identification and management of a group of objects. A group refers to several objects combined for the manufacture of a product. The main feature is that when managing such systems, it is necessary to change the setting actions for each object. This is due to the fact that today the technological regulations in many cases are wider than they should be for good operating. This is a consequence of the fact that the current production culture (this, in particular, has been shown by the experience of processing data from the technological process for the production of transistors at Svetlana) is rather low, which leads to some organizational problems. It is clear that it is necessary to have certain models of objects that naturally differ from each other and can be considered under conditions of both parametric and nonparametric uncertainty. Moreover, there may be cases when an object is considered simultaneously under conditions of both parametric and nonparametric uncertainty over various channels. Now, regarding the delay, due to the fact that the measurement of some variables is carried out in a significantly longer time interval than the object constant, it is necessary to distinguish the time of measuring technological variables and, in fact, the delay typical to the process itself, taking into account the difference between the channels. This leads to the fact that dynamic processes are essentially forced to be considered as inertialess with delay. Another significant feature is that the components of the output variables are stochastically dependent in advance in an unknown manner. The use of correlation or dispersion relations in this case does not lead to success. A special analysis of T-processes and the ability to simulate such processes are required. In particular, this is one of the tasks of this article. It contains: T-processes, T-models and the corresponding heterogeneous control algorithms. The process of hydrodeparaffinization of diesel fuel is considered according to available data, which can be said a priori that they are incomplete, that is they do not reflect the complex behavior of the process. From here it follows that these data require replenishment, which today is not carried out for various reasons. Thus, the process of hydrodewaxing can be taken to the T-process. Modeling a multidimensional system based on real data has shown that in this problem the presetting effect for different objects should be different. The exception is only the setting actions for the entire complex or group of objects. Modeling was carried out on the basis of T-models considered in the article. It has already been noted that these models should not be taken as complete, giving an idea of reality. They will be subject to algorithmic refinement during further research. The decision is made by the researcher. At this stage that an assessment is given that, under the circumstances, the resulting models and control algorithms can be adopted for use in a production environment. An attempt to use the existing theory of identification and control for the process of hydrodewaxing will inevitably lead to a significant degradation and increase in the cost of a computer system for operating the quality of this process.
Текст научной статьи Об управлении группой объектов как о задаче системного анализа
Введение. Моделирование многомерных безынерционных объектов продолжает оставаться актуальной задачей идентификации. При этом основной упор настоящей статьи делается на случай, когда вектор компонент выходных переменных стохастически зависим заранее неизвестным образом. В этом случае подход к моделированию подобных объектов не укладывается в рамках существующей теории идентификации. Примеров подобных объектов в действительности предостаточно. В частности, к ним могут быть отнесены процессы, возникающие в стройиндустрии (производство цемента), металлургии (процесс плавки стали), энергетике (процесс горения угля), нефтепереработке (процесс очистки дизельного топлива от сернистых соединений), а также практически во всех организационных процессах, включающих в себя образовательный [1; 2]. Можно привести в пример многомерный процесс на нефтеперерабатывающем заводе, где существует установка гидроочистки дизельного топлива от сернистых соединений, совмещенная с процессом гидродепарафинизации, повышения хладотекучести дизельного топлива [3]. Измерение основных выходных стохастически зависимых переменных данного процесса, например, таких как «плотность при температуре 15 оС» или «температура конца кипения», происходит один раз в сутки. При этом исследуемый процесс рассматривается как безынерционный с запаздыванием [4].
Следует заметить, что любому из этих процессов соответствует постановка отличающихся формулировок задач и это отличие обусловлено наличием различных априорных сведений об изучаемом процессе. Наиболее интересным является случай, когда характер стохастической связи между компонентами выхода оказывается неизвестным с точностью до параметров. На рис. 1 представлена наиболее простая схема последовательно соединенных объектов. Тем не менее, даже она показывает, что при анализе такой группы объектов возникает специфика и при моделировании и тем более при управлении подобным процессам в действительности.

Рис. 1. Группа объектов, реализующих технологический процесс
-
Fig. 1. The group of objects that implement a technological process
На рис. 1 приняты следующие обозначения: O, q = 1, r - количество объектов (технологических аппаратов), входящих в группу (группа состоит из локальных объектов); u = U, u 2,..., um ) - входные управляющие воздействия; ц = ( ц , ц ,..., ц ) - входные, неуправляемые, но контролируемые переменные (например, это могут быть всевозможные добавки, при работе с сыпучими материалами, которые поступают на вход объекта); x = ( x , x 2,..., xn ) - характеристики, определяющие состав исходного продукта х1 полуфабрикатов x ,..., x ; z – параметры, характеризующие готовый продукт (изделие). Все переменные – векторы. Протекание технологического процесса подчинено технологическому регламенту (ГОСТам), который определяет диапазоны значений всех технологических параметров.
Основная особенность, возникающая у группы процессов, в значительной степени обусловлена ее эмерджентностью [5] и неоправданно большими диапазонами технологического регламента. Причем сжатие технологического регламента на реальном производстве в большинстве случаев осуществить нельзя из-за возникающих организационных проблем. А в итоге это приводит, к сожалению, к выпуску некачественных изделий, а зачастую и к большой доли брака. Трудности еще усугубляются тем, что не всегда получившиеся изделия можно отправить на повторную переработку. Выход может быть найден на пути коррекции технологического регламента в каждом конкретном случае. Это, естественно, приводит к проблеме автоматизации подобного процесса в каждом локальном случае, на каждом переделе технологического процесса. В этой связи необходимо задачу идентификации и задачу управления решать для каждого технологического объекта, а уже потом объединять их в группу. Таким образом, возникает необходимость вести технологический процесс все время по-разному. Это сродни известной мысли, высказанной польским философом Фердинанда-Бронислава Трентовским в 1843 г. в книге «Отношение философии к кибернетике как к искусству управления народом»: «Применение искусства управления без сколько-нибудь серьезного изучения соответствующей теории подобно врачеванию без сколько-нибудь глубокого понимания медицинской науки».
Он подчеркивал, что действительно эффективное управление должно учитывать все важнейшие внешние и внутренние факторы, влияющие на объект управления: «При одной и той же политической идеологии кибернет должен управлять различно в Австрии, России или Пруссии. Точно так же и в одной и той же стране он должен управлять завтра иначе, чем сегодня».
В таких сложных многомерных процессах выходные переменные объекта каким-то образом зависимы, но зависимость эта априори оказывается неизвестной. Подобные процессы были названы Т-процессами, а их модели – Т-моделями [6]. Идентификация и управление такими процессами должны осуществляться не традиционным путем [7], так как он не приведет к успеху из-за недостатка априорной информации об исследуемом объекте. Особенностью является то, что вектор выходных компонент, обозначим его как x(t) = (x(t),x2(t),...,xn(t)), j = 1,n, таков, что компоненты этого вектора зависимы заранее неизвестным образом. Поэтому математическое описание объекта можно представить в виде системы неявных функций:
F j ( u ( t ) , ц ( t ) , x ( t )) = 0, j = 1, n ,
где u ( t ) = ( u ( t ), u2( t ), ..., um( t )), k = 1, m - вектор входных управляемых компонент;
(ц(t), ц(t),..., ц (t)) v = 1,p - вектор входных неуправляемых, но контролируемых компонент; компонента (t) - означает рассмотрение входных-выходных переменных в конкретный момент времени t. Задача идентификации рассматриваемых объектов сводится к тому, что необходимо решить систему неявных нелинейных уравнений (1) относительно компонент вектора выходных переменных x(t) при известных входных u(t),ц(t). Конечно, задача усложняется при наличии группы объектов, где каждый локальный объект придется рассматривать по отдельности.
Управление такими объектами рассматривается в условиях неопределенности, когда нет описание объекта с точностью до вектора параметров. Причем для группы объектов задающие воздействия для каждого отдельного объекта придется изменять.
Алгоритмы идентификации локальных объектов. Для моделирования группы объектов необходимым этапом является построение моделей самих локальных объектов. В этом случае необходимым будет рассмотрение известных методов, в частности, алгоритмов идентификации в узком и широком смыслах. Далее рассмотрим основные алгоритмы моделирования локальных объектов. Выделим два класса идентификации - параметрическая и непараметрическая.
Рассмотрим параметрическую идентификацию или идентификацию в узком смысле [8]. При идентификации в узком смысле рассматриваются обычно два основных этапа. Первый -определение параметрической структуры объекта с точностью до коэффициентов, второй -определение значений коэффициентов по результатам измерений входных-выходных переменных или оценки параметров. Чаще всего в различных источниках рассматриваются алгоритмы оценки параметров. Наиболее уязвимым этапом является выбор структуры модели объекта с точностью до коэффициентов. Совершенно ясно, что если структура модели выбрана неточно, то это приведет и к неточности модели. Здесь уместно вспомнить фразу древнегреческого философа Демокрита: «Даже незначительное отступление от истины в дальнейшем ведет к бесконечным ошибкам».
Таким образом, на первом этапе выбирается класс уравнений:
F(u,ц,x,а) = 0, j = 1,n, где u - входные управляемые переменные процесса, ц - входные неуправляемые, но контролируемые переменные процесса, x - выходные переменные, а - вектор параметров.
Алгоритмы оценки параметров основаны на методе стохастических аппроксимаций, в частности имеют следующий вид:
a k = ak s - 1 + Y s xs
s
N
\
k
Z a S И ' к ) Г ( u t ) .
i = 1
Подобных алгоритмов известно много, но на этом подробно останавливаться не будем.
В случае непараметрической идентификации или идентификации в широком смысле алгоритмы простых постановок задач могут быть основаны на непараметрических оценках функции регрессии Надарая-Ватсона [9]. Для многомерного случая вид этой оценки представляется в следующем виде:
s
m
Z хП Ф
uk
—
uki
x s ( u ) =
i = 1
k = 1
V
cs
sm
ZO Ф
i = 1 k = 1
u k
—
uki
V
cs
где колоколообразные функции Ф ( • ) и параметры размытости es удовлетворяют некоторым
условиям сходимости и удовлетворяют следующим свойствам [9]:
c s 1 f Ф ( с s 1 ( u k - u^Vu = 1;
Q ( u )
lim c Ф s ^^
( cs '( u k
- uki ) ) = ^ ( uk - u ki ) ;
0 < Ф ( cs 1 ut - u k^ ^ ;
cs > 0; lim c s = 0;
s ^M
lim sc m = to .
s ^TO
На практике чаще всего встречаются случаи, когда векторы выходных переменных объекта стохастически зависимы. В этом случае описание процесса может быть представлено в виде:
Fj ( u, ц , x ) = 0, j = 1, n .
А модель объекта в этом случае, на основе аппроксимации локального типа, может быть представлена следующим образом:
F j ( u, ц , x, U s , M s , X s ) = 0, j = 1, n, i = 1, s ,
где us , ц , xs - временные вектора (набор данных, поступивший к s-му моменту времени). Причем функции / ^(•) неизвестны, так как неизвестны зависимости выходных переменных процесса. Как было отмечено выше, процессы, имеющие стохастическую зависимость выходных переменных, были названы Т-процессами.
Рассмотрим каждый отдельный объект, входящий в группу, как отдельный многомерный объект с зависимостями входных и выходных переменных, а также неизвестными зависимостями выходных переменных между собой. Изобразим такой объект на рис. 2.
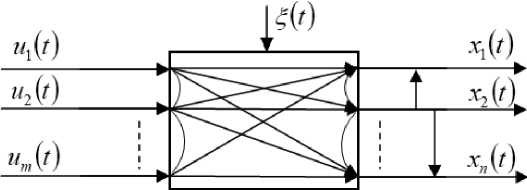
Рис. 2. Многомерный объект
Fig. 2. Multidimensional object
На рис. 2 на вход объекта поступает вектор входных переменных u = (ц,...,um ), на выходе наблюдается вектор выходных переменных x = (xv,...,xn), §(t) - случайные помехи, действующие на объект. При рассмотрении такого объекта можно заметить зависимости выходных переменных, которые могут быть не всегда известны. По различным каналам многомерного Т-объекта зависимость j-ой компоненты вектора выходных переменных x может быть представлена в виде некоторой зависимости от тех или иных компонент вектора входных переменных u : x
Модель такого процесса рассматривается в виде системы:
j u < j > , x < j > ) = 0, j = In , (6)
где функции F ( • ) продолжают оставаться неизвестными.
В результате измерений входных и выходных переменных объекта может быть получена обучающая выборка { u , x } , i = 1, 5 . В этом случае при заданных значениях входных переменных u ( t ) необходимо решить систему (6) относительно компонент выходных переменных x ( t ) . В результате можно получить оценки компонент выходных переменных по известным входным, а в этом и заключается основное назначение искомой модели.
Т-модели. Выше было отмечено, что если выходные переменные имеют неизвестные стохастические зависимости, то они были названы Т-объектами, а их модели Т-моделями. Описание такого процесса принимается в следующем виде:
F j ( u < j > ( t ) , x < j > ( t ) ) = 0, j = In , (7)
где u < j > ( t ), x < j > ( t ) - составные векторы, вид функции F y( • ) неизвестен. Система моделей исследуемого объекта может быть представлена в следующем виде:
F j ( u < j > ( t ), x < j > ( t ), x , , u , ) = 0, j = 1, n , (8)
где xs , u - временные векторы, но и в этом случае F ( • ) продолжают оставаться неизвестными. Поэтому задача сводится к тому, что при заданном значении вектора входных переменных u ( t ) необходимо решить систему (8) относительно вектора выходных переменных x ( t ) . Общая схема решения такой системы сводится к непараметрической двушаговой алгоритмической цепочки, которая позволяет найти прогнозные значения вектора выходных переменных x ( t ) по известным входным u ( t ) .
Сначала вычисляются невязки по формуле
Е„= Fu < j * , x < j * ( i\x , , u , Ji j = 1, n , (9)
где функции f ( u < j > , x < j > ( i ), :xs , Hs ) принимаются в виде непараметрической оценки функции регрессии Надарая – Ватсона [9]:
s
< n >
s J ( i ) = fjjk u < J > , XJ ( i ) ) = XJ ( i )— 221
Z X j [ i ] П Ф
k = 1
s < n >
i = 1 k = 1
Г uk - u k [ i ]
k c suk
u k - u k [ i ]
,
k csu.t 7
где j = 1, n , , < m > - размерность составного вектора uk . Колоколообразные функции
Ф ( • ) и
параметр размытости c удовлетворяют некоторым условиям следующими свойствами [9]: Ф (;) <-/ ; lim^Ю С = 0;
сходимости и обладают
J Ф ( c -1 t ( u k - u k [ i ] ) ) du = 1;
Q ( u )
lim „ c 1 Ф ( c 1 ( u ‘ — u, s —^^ su ^ su k k k
— u k [ i ] ) ; lim s (/ sc s =да .
Далее оценивается условное математическое ожидание:
Xj = M { x | u < j > , s = o } , j = 1, n .
где за основу берется непараметрическая оценка функции регрессии. И в конечном итоге прогноз для каждой компоненты вектора выходной переменной будет находиться следующим образом:
s
< n >
Z -ФтП Ф
" u k 1
—
^ x ˆ j
i = 1
k 1 = 1
k c su
uk [ i ] 1 < m > ^1-п Ф
7 k 2 = 1
Г = k , [ i ] 1
v c s s
s
^ u k 1
—
k c su
uk [ i ] 1 < m T
— п Ф
7 k 2 = 1
Г S k 2 [ i ] 1
c k css 7
- , j = 1, n ,
где колоколообразные функции Ф ( • ) могут быть взяты в виде треугольного ядра для входов (13) и невязок (14):
Ф
^ Uk 1
—
Ф
Г f k x l i ] 1
« k , [ i ] )
k c s s 7
k c su 7
Непараметрический алгоритм (10) и (12) представляет собой двушаговую алгоритмическую цепочку, позволяющую находить прогнозные значения компонент вектора выхода при известных компонентах входных переменных, в случае стохастической зависимости выходных переменных [10].
Общая постановка задачи идентификации и управления группой объектов. Моделирование и управление группой объектов существенно отличается от моделирования и управления локальными объектами. И основное отличие состоит в том, что при управлении группой необходимо изменять задающие воздействия для управления локальными объектами, каждый раз изменяя при этом, по существу, технологический регламент. Этого требует реальность. Собственно, это и показывает приведенный ниже пример на нефтеперерабатывающем заводе. В противном случае технологическая карта требует расширения, но совершенно ясен результат исполнения этого расширенного технологического регламента, который неизбежно приведет к продукции низкого качества и даже к браку. Таким образом, цели, которые ставятся перед группой объектов, существенно отличаются от целей, которые ставятся перед локальными объектами. Остается еще раз заметить, что модели и алгоритмы управления не являются арифметической суммой моделей и алгоритмов группы объектов. Тем не менее, приведенные выше модели и алгоритмы управления могут быть приняты за основу. Изменится лишь содержание входных и выходных переменных локальных объектов и группы. Таким образом, для качественного управления группой необходимо отличие и в соответствующих технологических регламентах [11].
В конце 70-х гг. одному из авторов довелось участвовать в исследованиях технологического процесса по производству транзисторов (производственное объединение «Светлана», г. Ленинград), в связи с тем, что объем бракованных изделий и изделий низкого качества достигали 85 %. Проведенные исследования показали, что диапазоны значений технологических параметров неправдоподобно широки во всех сечениях технологического процесса, хотя и соответствовали технологическому регламенту. Результаты исследований позволили дать соответствующие рекомендации, которые вошли в отраслевые руководящие материалы [12].
Широкий диапазон значений характерен для многих добывающих или перерабатывающих производств. Конечно, можно разработать на основе исследований, проведенных для каждого конкретного предприятия, более жесткий технологический регламент и далее следовать ему. Но этот путь не всегда можно осуществить, потому как жесткий технологический регламент можно реализовать только на предприятиях с высоким уровнем культуры производства. Это, прежде всего, высокое качество технологического оборудования, средств локальной автоматики, квалификации работающих и их отношение к делу.
Может быть и другой путь, нужно следовать имеющемуся технологическому регламенту, но оптимизировать режим ведения процесса в данном технологическом объекте с учетом фактически проведенной технологической операции на предыдущем объекте. Такой путь более реалистичен для предприятий, так как не требует капитальных затрат на реконструкцию и позволяет существенно повысить качество выпускаемой продукции и уменьшить потери при производстве тех или иных изделий. Для этого необходимо разработать и внедрить компьютерные системы для улучшения технологических режимов. Подобные компьютерные системы оказываются достаточно эффективными.
Рассмотрим схему управления локальным объектом с запаздыванием (рис. 3).
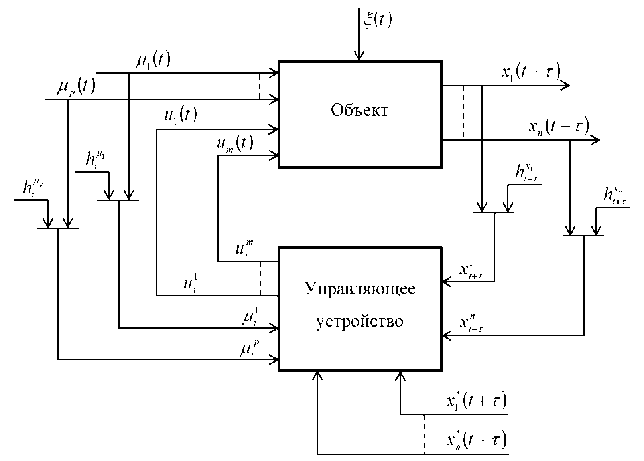
Рис. 3. Схема управления многомерным объектом
Fig. 3. Multidimensional Object Management Scheme
На рис. 3 приняты следующие обозначения: u(t) = (u[ (t),..., um (t)) — управляемые входные переменные; M(t Ы^(t )v; M (t)) - неуправляемые, но контролируемые переменные;
x ( t + т ) = ( X ] ( t + т ) ,..., xn ( t + т )) e R n
x * ( t + т ) = ( X ]* ( t + т ) ,..., x * ( t + т ) ) e R n
выходные переменные процесса;
задающие воздействия; ^, hM, h - случайные стационарные помехи, действующие на объект и в каналах измерения входных и выходных переменных; т - известное запаздывание по различным каналам многомерной системы.
Управление группой объектов должно осуществляться с учетом того, что переходя от одного объекта к другому необходимо изменять задающие воздействия.
Управление многомерными системами. Управление многомерными Т-объектами рассматривается в условиях непараметрической неопределенности, т. е. в условиях, когда модель процесса с точностью до вектора параметров отсутствует полностью [13]. В этом случае известные приемы не применимы и следует использовать другие подходы для решения задачи [14–18].
В задаче управления многомерным процессом со стохастической зависимостью выходных переменных используется многошаговая алгоритмическая цепочка. Она заключается в следующем: входная переменная ux * ( t ) берется произвольно из области Q ( u t) . Следующая входная переменная u * ( t ) находится в соответствии со следующим алгоритмом:
* u
s
Е u 2 Ф i = 1
* i
^ 1- ^ 1
к
c u
nx П Ф j = 1 к
* i xj- xj
c
x j
< р >
П Ф
V = 1 к
*
M v
-
м 1
c v
s
Е Ф i=1
( u,
*
-
ui'
к
cu 1
< n q >
П Ф
7 j = 1
v x v j
-
j
к
c
x j
< P w > (
П Ф
V = 1 к
v i
M v- M v
c
где < nq >, < pw > - размерность соответствующих составных векторов x им, < nq >< n, < pw >< p, q, w - количество компонент, входящих в составной вектор. Составные вектора определяются исследователем из имеющейся априорной информации. В случае если исследователь не располагает подобной информацией об объекте, он использует все компоненты входных и выходных переменных в составном векторе. Далее входная переменная и* (t) находится следующим образом:
s
*
*
u
Z иФ
i = 1
s
u
L
/
*
u
i
U 2
< n q >
*
к
/
*
cu 1
к
cu 2
п Ф
7 j = 1
x j
—
xl
< Pw >
*
Z Ф
i = 1
u 1
—
u '
*
ф
u 2
—
i u 2
< n q >
к
*
к
cu 1
к
cu 2
п Ф
7 j = 1
cx j
п Ф
A v
^“
A )
x j
—
xj'
V = 1
к
c A v
< pw >
/
*
.
к
c xj
п Ф
V = 1
A v
—
A v
к
c A v
И далее алгоритм управления продолжается для нахождения каждой компоненты входа и * ( t ) объекта, причем с каждым последующим шагом в алгоритм добавляются вновь найденные на предыдущем шаге значения входных переменных. Запишем алгоритм управления для многомерной системы, который будет выглядеть следующим образом:
* uk
5 к —1 7
Zuk п ф i=1 к=1
* i
Uk — Uk
<Х п ф j=1 к
* i x x
x j
< P w > п ф v = 1
*
A v
к
—
c A
A )
5 k —1 7
^п Ф i = 1 к = 1 к
* i
Uk — Uk
nnx п ф j=1 к
* x * j
—
xi'
c xj
< P w >
п ф v=1 к
* i
A v- A v
к = 1, m .
В алгоритме управления (17) настраиваемыми параметрами остаются параметры размытости для входных и выходных переменных c , c и с , для них могут быть использованы следующие формулы: cUt = ^u* — ui| + n , cx. = вx* — xi| + П и cA = Ya”* — Alv I + П, где a, в и Y некоторые параметры большие 1, а параметр 0 < n < 1.
Следует обратить внимание на то, что выбор параметров размытости cUk , cx, и сА осуществляется на каждом такте управления. При этом если сначала определен c , то определение cx, и сА осуществляется с учетом этого факта. Очередность определения параметров размытости cUk, cx, и сА несущественна.
Группа объектов на нефтеперерабатывающем заводе. На нефтеперерабатывающем заводе функционирует установка гидроочистки дизельного топлива от сернистых соединений, совмещенная с процессом гидродепарафинизации, повышения хладотекучести дизельного топлива. Представим технологическую схему рассматриваемого процесса (рис. 4).
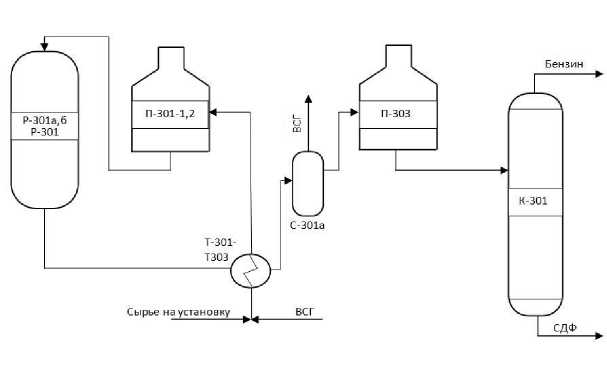
Рис. 4. Фрагмент схемы гидроочистки дизельного топлива и гидродепарафинизации Fig. 4. Fragment of a scheme for hydrotreating diesel fuel and hydrodewaxing
На рис. 4 представлен реакторный блок Р-301, в котором совмещены процессы гидроочистки и гидродепарафинизации, а также изображены блоки очистки циркуляционного водородсодержащего газа С-301а; стабилизации дизельного топлива с извлечением бокового погона К-301; стабилизации отгона бензина; очистки углеводородных газов. Входом является «Сырье на установку», а выходом «СДФ».
Изображенные блоки представляют собой группу объектов, при помощи которых происходят совмещенные процессы гидроочистки и гидродепарафинизации.
В процессе работы такой установки происходит сбор и накопление информации о протекании технологического процесса. Поэтому необходимо обрабатывать накопленную информацию с целью мониторинга за всем процессом и последующего принятия решений по его управлению [19].
Из-за недостатка априорной информации о процессе в нужном объеме для осуществления его моделирования и управления предлагается использовать методы непараметрических систем, которые помогут в определении текущего состояния технологических потоков на входе и выходе процесса, выявлении недостоверных данных, прогнозировании показателей качества готовой продукции на выходе, корректном управлении технологическим процессом.
Изобразим общую схему идентификации процессов гидроочистки и гидродепарафинизации в следующем виде (рис. 5).
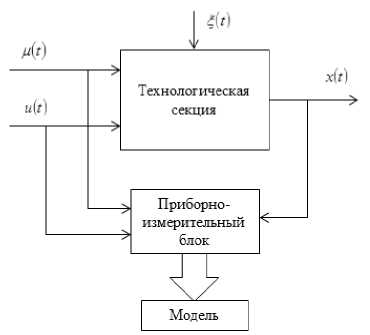
Рис. 5. Фрагмент моделирования процессов гидроочистки и гидродепарафинизации Fig. 5. Fragment of modeling hydrotreating and hydrodewaxing processes
Для процесса гидроочистки и гидродепарафинизации использовались следующие входные и выходные переменные: ux (t ) - плотность при 15 оС, кг/м3; фракционный состав, оС: иг (t ) -температура начала кипения; u3 ( t ) - температура выкипания 50 %; u4 ( t ) - температура выкипания 96 %; u5 ( t ) - температура конца кипения; u6 ( t ) - давление на входе в Р-301, кгс/см2; u7(t ) - температура входа в Р-301, оС; xx ( t ) - плотность при 15 оС, кг/м3; фракционный состав, оС: x2 ( t ) - температура начала кипения; x3(t ) - температура выкипания 50 %; x4 ( t ) - температура выкипания 96 %; x5(t ) - температура конца кипения; x6 ( t ) - температура помутнения.
В связи с тем, что характер зависимости входных и выходных переменных неизвестен, а также неизвестны зависимости выходных переменных между собой, то в дальнейшем используется двушаговый непараметрический алгоритм Т-модели (10) и (12), рассмотренный выше, для определения прогнозных значений компонент вектора выхода по известным компонентам входа.
Точность моделирования оценивалась по следующей формуле
s
El x - x s ( u ) _
5 j = ----------- , j = 1, n ,
El x- x = 1
где xi - наблюдения на объекте; x s ( u ) - прогноз выхода объекта; X - среднее значение по каждой компоненте вектора x .
Для моделирования проводим процедуру скользящего экзамена. Настраиваемыми параметрами будут параметры размытости с и c , которые в данном случае возьмем равным 0,5 и 0,4 соответственно (значения были определены в результате многочисленных экспериментов с целью уменьшения квадратичной ошибки между выходом объекта и модели). Объем выборки s = 115. Приведем результаты по выходной переменной x4 ( t ) -температура выкипания 96 % (рис. 6).
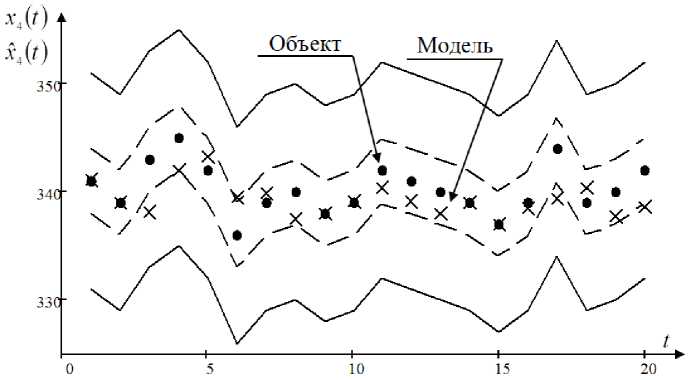
Рис. 6. Прогноз выходной компоненты x4 (t )
при соответствующих входных
переменных u
( • )
Fig. 6. Prediction of the output component x 4 ( t ) for the corresponding input variables u ( t )
На рис. 6 «точкой» обозначены выходы объекта, а «крестиком» выходы модели. Для наглядности представления результатов на графике показаны 20 точек выборки. Согласно ГОСТ Р 51069-97 Нефть и нефтепродукты. Метод определения плотности, относительной плотности и плотности в градусах API ареометром, показатели точности метода, полученные статистическим исследованием межлабораторных результатов испытаний, могут отклоняться, для x4 ( t ) минимальное значение составляет - 3 0 С , как показано на рис. 6 пунктирными линиями, а максимальное значение составляет – 10 0 С , как показано на рис. 6 сплошными линиями. Для каждой компоненты выхода объекта утверждены свои границы отклонений. Какие из границ выбрать, минимальные или максимальные, определяет технолог. По графику можно сказать, что получился вполне удовлетворительный прогноз, ошибка моделирования составила ^ = 0,04. Но стоит обратить внимание на то, что максимальные границы отклонений слишком широки во всех сечениях технологического процесса, и сам процесс должен проходить в минимальных границах отклонений. Получившиеся прогнозные значения иногда выходят за пределы минимальных границ, но лежат в пределах максимальных, на это могут влиять многие факторы, такие как малый объем обучающей выборки, недостоверность априорной информации, случайные помехи, действующие на процесс и т. д. Но хорошо настроенные модели позволяют повысить ее точность и в дальнейшем помогут для качественного управления технологическим процессом [20].
Заключение. В статье рассмотрены непараметрические алгоритмы моделирования и управления группой объектов в условиях как параметрической, так и непараметрической неопределенности. Создание групп обусловлено не только структурой предприятия, но и характером технологического процесса. Подчеркнута одна особенность, которая проявляется в том, что задающие воздействия для каждого объекта являются предметом специального рассмотрения на каждом такте управления. В работе приводятся модели и алгоритмы управления группой объектов, а также некоторых локальных и специально подчеркнуто свойство эмерджентности. Приведены модели многомерных безынерционных комплексов и рассмотрен, в частности, пример по результатам измерений реальных данных технологического совмещенного процесса гидроочистки и гидродепарафинизации дизельного топлива, происходящего на нефтеперерабатывающем заводе.
Список литературы Об управлении группой объектов как о задаче системного анализа
- Medvedev A. V., Yareshchenko D. I. [On modeling the process of acquiring knowledge by students at a university]. Vysshee obrazovanie. 2017, No. 1, P. 7-10 (In Russ.).
- Yareshchenko D. I. [Some notes on the assessment of knowledge of university students]. Otkrytoe obrazovanie. 2017, No. 4, P. 66-72 (In Russ.).
- Agafonov E. D., Medvedev A. V., Orlovskaya N. F., Sinyuta V. R., Yareshchenko D. I. [Predictive model of the process of catalytic hydrodeparaffinization in the absence of a priori information]. Izv. Tul'skogo gos. un-ta. Tekhn. Nauki. 2018, No. 9, P. 456-468 (In Russ.).
- Korneeva A. A., Sergeeva N. A. [On nonparametric identification of inertialess objects with delay]. Inform. tekhnologii modelirovaniya i upr. 2012, No. 5, P. 363-370 (In Russ.).
- Peregudov F. I., Tarasenko F. P. Vvedenie v sistem-nyy analiz [Introduction to Systems Analysis]. Moscow, Vysshaya shkola Publ., 1989, 367 p.
- Medvedev A. V. Osnovy teorii neparamet-richeskikh sistem. Identifikatsiya, upravlenie, prinyatie resheniy [Fundamentals of the theory of nonparametric
- systems. Identification, management, decision making]. Krasnoyarsk, SibGU im. M. F. Reshetneva Publ., 2018, 732 p.
- Tsypkin Ya. Z. Osnovy informatsionnoy teorii iden-tifikatsii [Fundamentals of the information theory of identification]. Moscow, Nauka Publ., 1984, 320 p.
- Eykkhoff P. Osnovy identifikatsii sistem uprav-leniya [The basics of identifying control systems]. Moscow, Mir Publ., 1975, 680 p.
- Nadaraya E. A. Neparametricheskoe otsenivanie plotnosti veroyatnostey i krivoy regressii [Nonparametric estimation of probability density and regression curve]. Tbilisi, Izd-vo Tbilisskogo un-ta Publ., 1983, 194 p.
- Medvedev A. V., Yareshchenko D. I. [Nonparametric modeling of T-processes in conditions of incomplete information]. Informatsionnye tekhnologii. 2019, No. 10, P. 579-584 (In Russ.).
- Medvedev A. V. Informatizatsiya upravleniya [Management Informatization]. Krasnoyarsk, SAA Publ., 1995, 80 p.
- Tipovaya sistema upravleniya kachestvom [Typical Quality Management System]. Leningrad, Elektronstandart Publ., 1977, 237 p.
- Medvedev A. V. [On the theory of nonparametric control systems]. Vestn. Tom. gos. un-ta. Upr., vychisl. tekhnika i informatika. 2013, No. 1, P. 6-19 (In Russ.).
- Pupkov K. A., Egupov N. D. Metody klassicheskoy i sovremennoy teorii avtomaticheskogo upravleniya. T. 1: Matematicheskie modeli, dinamicheskie kharakteristiki i analiz sistem upravleniya [Methods of the classical and modern theory of automatic control. Mathematical models, dynamic characteristics and analysis of control systems]. Moscow, MGTU im. N. E. Baumana Publ., 2004, 748 p.
- Pupkov K. A., Egupov N. D. Metody klassicheskoy i sovremennoy teorii avtomaticheskogo upravleniya. T. 2: Statisticheskaya dinamika i identifikatsiya sistem avtomaticheskogo upravleniya [Methods of the classical and modern theory of automatic control. Statistical dynamics and identification of automatic control systems]. Moscow, MGTU im. N. E. Baumana Publ., 2004, 640 p.
- Pupkov K. A., Egupov N. D. Metody klassi-cheskoy i sovremennoy teorii avtomaticheskogo uprav-leniya. T. 3: Sintez regulyatorov sistem avtomaticheskogo upravleniya [Methods of the classical and modern theory of automatic control. Synthesis of automatic control system regulators]. Moscow, MGTU im. N. E. Baumana Publ., 2004, 748 p.
- Pupkov K. A., Egupov N. D. Metody klassi-cheskoy i sovremennoy teorii avtomaticheskogo uprav-leniya. T. 4: Teoriya optimizatsii sistem avtomaticheskogo upravleniya [Methods of the classical and modern theory of automatic control. Theory of optimization of automatic control systems]. Moscow, MGTU im. N. E. Baumana Publ., 2004, 748 p.
- Pupkov K. A., Egupov N. D. Metody klassi-cheskoy i sovremennoy teorii avtomaticheskogo uprav-leniya. T. 5: Metody sovremennoy teorii avtomaticheskogo upravleniya [Methods of the classical and modern theory of automatic control. Methods of the modern theory of automatic control]. Moscow, MGTU im. N. E. Baumana Publ., 2004, 742 p.
- Faleev S. A., Belinskaya N. S., Ivanchina E. D. [Optimization of the hydrocarbon composition of raw materials in reforming and hydrodewaxing plants using mathematical modeling]. Neftepererabotka i neftekhimiya. Nauchno-tekhnicheskie dostizheniya i peredovoy opyt. 2013, No. 10, P. 14-18 (In Russ.).
- Kostenko A. V., Musaev A. A., Turanosov A. V. [Virtual Raw Flow Analyzer]. Neftepererabotka i neftekhimiya. Nauchno-tekhnicheskie dostizheniya i peredovoy opyt. 2006, No. 1, P. 1-13 (In Russ.).
