Обнаружение вредоносного программного обеспечения с помощью методов анализа кода

Бесплатный доступ
Обнаружение вредоносных программ нулевого дня является постоянной проблемой. Сотни тысяч новых вредоносных программ ежедневно публикуются в Интернете. Хотя традиционные сигнатурные методы все еще широко используются, они полезны только для известных вредоносных программ. Многие исследования направлены на то, чтобы помочь выявить неизвестные подозрительные и вредоносные файлы.
Вредоносные программы, обфускация, дизассемблирование, анализ кода
Короткий адрес: https://sciup.org/140279445
IDR: 140279445
Malware detection using code analysis methods
The detection of zero-day malware is an ongoing problem. Hundreds of thousands of new malicious programs are published daily on the Internet. Although traditional signature methods are still widely used, they are useful only for known malware. Many studies are aimed at helping to identify unknown suspicious and malicious files.
Текст научной статьи Обнаружение вредоносного программного обеспечения с помощью методов анализа кода
Основные методы борьбы с вредоносным программным обеспечением можно классифицировать на анализ «песочницы», эвристический статический анализ или эмуляцию кода. Среди трех эвристический статический анализ является самым быстрым, пока дело не доходит до обфусцированной программы. Обфускация кода включает в себя упаковку, защиту, шифрование или вставку антиразборных трюков и используется для сдерживания процесса обратного проектирования и анализа кода. Около 80%-90% вредоносных программ используют какие-то упаковочные технологии [2], а около 50% новых вредоносных программ являются просто упакованными версиями более старых известных вредоносных программ [3].
В то время как вредоносные программы очень часто используют обфускацию кода, доброкачественные исполняемые файлы редко используют такие методы. Таким образом, стало обычной практикой помечать запущенный файл как подозрительный, а затем анализировать его с более дорогостоящим анализом, чтобы определить, является ли он вредоносным или нет.
Большинство текущих работ по обнаружению запутанных файлов основаны на характеристиках структуры исполняемой файловой системы. Многие публичные упаковщики, действительно, обнаруживают идентифицируемые изменения в упакованном исполняемом файле. Однако это не всегда имеет место с пользовательскими упаковщиками и самошифрующимися вредоносными программами. Более того, упаковка - не единственный метод обфускации, используемый писателями вредоносных программ. Вредоносные программы могут использовать трюки антианализа, которые препятствуют процессу разборки или анализа. Такие трюки могут не оставлять в заголовке никаких следов, поскольку они основаны на обфускации последовательности команд и потока выполнения программы.
Другие методы зависят от обнаружения сигнатуры известных упаковщиков в файле. Недостаток этого метода очевиден, так как он не работает с неизвестным и обычными упаковщиками и криптографами. Он также терпит неудачу, если подпись слегка изменена.
Вычисление энтропийного балла файла является другим методом идентификации упакованных и зашифрованных файлов. Этот метод может быть эффективным против шифрования или обфускации упаковки, но неэффективен против трюков с антиразборкой. Кроме того, показатель энтропии файла может быть уменьшен для достижения низкой энтропии, аналогичной показателю обычных программ.
В этой главе представлен новый метод обнаружения запутанных программ. Он заключается в создании рекурсивного дизассемблер обхода, который извлекает контрольный граф потоков двоичных файлов. Это позволяет обнаруживать наличие инструкций чередования, которые, как правило, указывают на непрозрачный трюк против дезадаптации. Система обнаружения использует некоторые новые функции, основанные на инструкциях, на которые ссылаются, и извлеченный граф потока управления, который четко различает запутанные и нормальные файлы. Когда они объединены с несколькими функциями, основанными на структуре файлов, достигается очень высокая скорость обнаружения запутанных файлов.
Основные преимущества данного метода:
-
1. Используется тот факт, что некоторые продвинутые запутанные вредоносные программы используют непрозрачные предикатные методы, чтобы препятствовать процессу разборки, и описывают методику, которая превращает эту силу в слабость, обнаруживая ее присутствие и помечая файл как подозрительный;
-
2. Определяются отличительные черты между запутанными и не упаковынными файлами, изучая их графы потоков управления. Эти функции помогают обнаруживать запутанные файлы, избегая недостатков других методов, которые полагаются на структуру файлов;
-
3. Достигается высокая скорость сканирования, несмотря на то, что этот метод включает в себя дизассемблирование, создание контрольного графа потока, извлечение признаков и анализ структуры файлов.
Идея использования энтропии для поиска зашифрованных и упакованных файлов была представлена в работе R. Lyda и J. Hamrock [2]. Метод стал широко использоваться, поскольку он эффективен и прост в реализации. Однако некоторые файлы без упаковки могут иметь высокие значения энтропии и, следовательно, приводить к ложным срабатываниям. Например, файлы ahui.exe и dfrgntfs.exe имеют энтропию 6.51 и 6.59 соответственно для своего раздела .text (Эти два файла примера существуют в Windows XP 32-bit). Также простое XOR-шифрование на байтовом уровне может также обходить обнаружение энтропии.
Популярным инструментом для поиска упакованных файлов является PEiD, который использует около 620 паковщика и сигнатуры crypter [1]. Недостатком этого инструмента является то, что он может идентифицировать только известные упаковщики, в то время как сложные вредоносные программы используют специальные пакеты или процедуры шифрования. Более того, даже если используется известный упаковщик, создатель вредоносного ПО может изменить один байт сигнатуры упаковщика, чтобы избежать обнаружения в упакованном виде. Кроме того, инструмент известен своей высокой частотой ошибок [4].
Другие исследования, используют заголовок выполняемого файла и информацию о структуре для обнаружения упакованных файлов. Эти методы могут получить хорошие результаты только тогда, когда упаковщик изменяет заголовок PE заметным образом.
Помимо недостатков каждой техники, в частности, ни одна из вышеупомянутых методик не может статически обнаруживать присутствие трюков против разборки или других форм обфускации управляющего потока, но в настоящее время они широко используются широким спектром передовых вредоносных программ. Кроме того, описанная далее система не зависит от оценки энтропии файла или раздела, сигнатуры упаковщиков или особенностей заголовка файла. Таким образом, он способен преодолеть эти недостатки.
Авторы вредоносных программ используют различные анти-аналитические трюки для защиты от всех видов анализов. Одни из них – способы защиты от дизасемблирования. Приемы анти-дизасемблирования снижают эффективность статического анализа обнаружения вредоносных программ. Одним из наиболее распространенных методов является использование непрозрачного предиката. Хотя существуют законные причины включения непрозрачных предикатных трюков, таких как водяные знаки [5] и препятствующие реверс-инженирингу, они обычно используются во вредоносном ПО для препятствия анализу.
Нечеткие предикатные трюки [6] вставляют условные операторы (обычно управляющие инструкциями потока), результат которых является постоянным и известным автору вредоносного ПО, но не понятен в статическом анализе. Таким образом, дизассемблер будет следовать в обоих направлениях инструкции управления потоком, один из которых ведет к неправильной разборке и влияет на результирующий контрольный граф потока. В качестве примера на следующем рисунке показан непрозрачный трюк с предикатами, вставленный в строки 6 и 7 фрагмента кода. Так как
«команда сравнения» в строке 6 всегда будет иметь значение true, фиктивная ветвь никогда не будет взята во время выполнения. Однако для дизассемблера этот факт не является очевидным, и он будет оценивать оба пути.
|
1 |
xor eax, eax |
|
2 |
nop |
|
3 |
nop |
|
4 |
LI: |
|
5 |
push eax |
|
6 |
cmp eax, eax |
|
7 |
jne fake |
|
8 |
add ecx, 333h |
|
9 |
jmp skip |
|
10 |
fake: |
|
11 |
DB OFh |
|
12 |
skip: |
|
13 |
nop |
|
14 |
nop |
|
15 |
mov ecx, ecx |
|
16 |
mov edx, 44 4h |
|
17 |
push offset ProcName |
|
18 |
push eax |
|
19 |
call GetProcAddress |
В этом примере дизассемблер будет следовать указанию инструкции jne в строке 7, что приведет к байту данных в строке 11. Разборка будет продолжаться, начиная с этого байта, 0F, в результате чего будет выполнена запись в файл с кодом 0F9090 8BC9BA44.
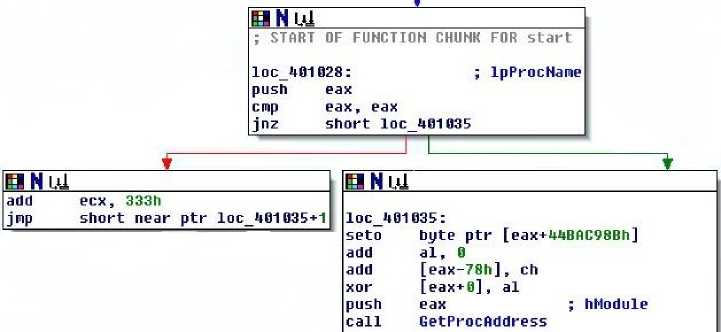
|
3300 98 90 50 3BC0 75 08 81С1 33030001 ЕВ 01 0F9090 8BC9BI 04 00 0068 88 3048 00 |
HOR ЕЙК,ЕЙК Hop NOP PUSH ЭД GHF JNE SHORT 00401035 ЙОС ECa, 333 JMP SHORT 00401036 SETO BVTE PTR OS:ЕЕЙХ+44ВЙС98В] ADD AL.,0 HUD 3VTi? PTR DS: lEA^-78j,CH ИОВ DvTE PTR OS' EI:'.^],HL |
50 РУ5Н ЕЯМ
E8 32000000 ЙЯкк <УГ1р;М^
В разработанном рекурсивном обходе дизассемблер способен обнаруживать код чередования и помечать соответствующий базовый блок как проблематичный, поэтому аналитик может легко узнать, где есть подозрительные участки кода. На следующем рисунке показана часть контрольного потокового графа, выводимого дизассемблером для этого примера. Два блока показаны красным цветом, чтобы показать, что они чередуются, и только один из них правильный.
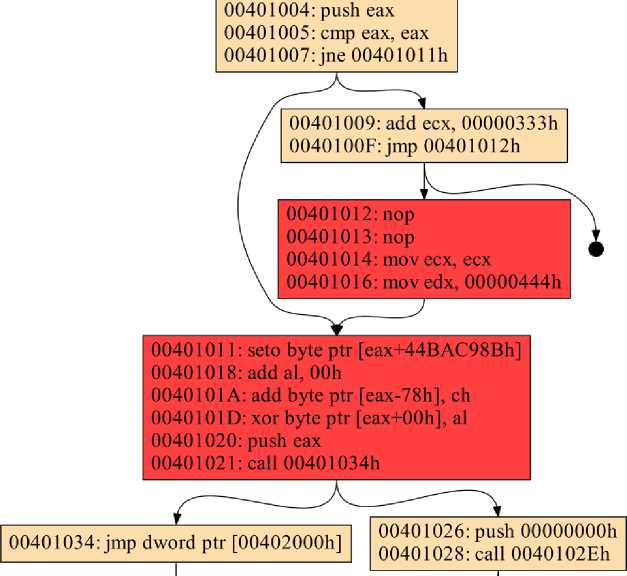
Список литературы Обнаружение вредоносного программного обеспечения с помощью методов анализа кода
- Saleh, M. E. Detection and classification of obfuscated maleware. Department of Computer Science / M. E. Saleh - College of Sciences, University of Texas at San Antonio, May 2016.
- Lyda, R. Using entropy analysis to find encrypted and packed malware. Security Privacy / R. Lyda, J. Hamrock - IEEE, 5(2), 2007, 40-45p.
- Stepan, A. Improving proactive detection of packed malware / A. Stepan - Virus Bulletin, 2006, 11-13 p.
- Shafiq, M. PE-probe: leveraging packer detection and structural information to detect malicious portable executables / M. Shafiq, S. Tabish, M. Farooq - In Proceedings of the Virus Bulletin Conference (VB), 2009, 29-33 p.
- Myles, G. Software watermarking via opaque predicates: Implementation, analysis, and attacks / G. Myles, Ch. Collberg - Electronic Commerce Research, 6(2), 2006, 155-171 p.
- Eilam, E. Reversing: Secrets of Reverse Engineering / E. Eilam - Wiley & Sons, 2008.
