Obstacle Detection Techniques in Outdoor Environment: Process, Study and Analysis

Автор: Yadwinder Singh, Lakhwinder Kaur
Журнал: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Статья в выпуске: 5 vol.9, 2017 года.
Бесплатный доступ
Obstacle detection is the process in which the upcoming objects in the path are detected and collision with them is avoided by some sort of signalling to the visually impaired person. In this review paper we present a comprehensive and critical survey of Image Processing techniques like vision based, ground plane detection, feature extraction, etc. for detecting the obstacles. Two types of vision based techniques namely (a) Monocular vision based approach (b) Stereo Vision based approach are discussed. Further types of above described ap-proaches are also discussed in the survey. Survey dis-cusses the analysis of the associated work reported in literature in the field of SURF and SIFTS features, mo-nocular vision based approaches, texture features and ground plane obstacle detection.
Segmentation, Obstacle Detection, Fea-ture Extraction, Thresholding, Image Processing
Короткий адрес: https://sciup.org/15014188
IDR: 15014188
Текст научной статьи Obstacle Detection Techniques in Outdoor Environment: Process, Study and Analysis
Published Online May 2017 in MECS DOI: 10.5815/ijigsp.2017.05.05
-
I. Introduction and Motivation
It is very much difficult for blind person to roam safely as the density of the persons and traffic on road is going on increasing day by day. Blind persons need some assistance to roam safely. This assistance can be provided by any other normal person or by any device, as it is not always possible that the blind person will get the normal person to roam safely so a device is needed by them. This device must be easy to carry and enough responsive in real time situations. The device after detecting the upcoming objects (Obstacles) will make the blind person come to know about the object in the path by using proper mode of signaling [1, 2]. Distance of the object can also be signaled to the visually impaired person i.e. how far the object is, like if the beep method is used to signal the person then pace of the beep can be increased as the distance between the person and object decreases and if the object is far from the person then beep pace will be slow.
-
A. Motivation for Research
-
• Obstacle detection is the process of recognizing the objects in the path of the visually impaired persons and to guide them, so that they can move
easily. Therefore, this study presents a detailed analysis of different existing techniques implemented in the literature at each phase of the obstacle detection.
-
• We recognized the necessity of a well ordered literature study and review after considering progressive research in obstacle detection techniques. Therefore, we have summarized the available research based on a vast and methodical look in the existing database and present the research challenges for advanced research.
-
B. Paper Organization
The organization of the rest of paper is as follows: Section II presents the background of obstacle detection techniques, various types of sensors present, vision based techniques, ground plane detection, feature extraction. Sect. III describes the study of the various techniques for each level of obstacle detection and analyses it. Methodical literature survey results and conclusions are presented in section IV. Section V presents the discussions of this research work. Open issues and future research directions are presented in Sect. VI. Note, a glossary of acronyms used in this paper can be found in “Appendix 1”.
-
II. Background
To tackle the obstacle detection problem many researchers have proposed various techniques. Different types of sensors have been used to capture the data. So initially we classify the various types of sensors [1] used and then we will present the various types of vision based techniques followed by the discussion on the various phases of the obstacle detection. As it is presented that obstacle detection is a process consisting of many phases in it, all those phases are discussed in this research article.
-
A. Sensor Based Techniques
To capture scene related information like depth of object, color of object, distance etc. sensor is used [1]. Broad classification of sensor based techniques along with their key components is shown in Fig 1.
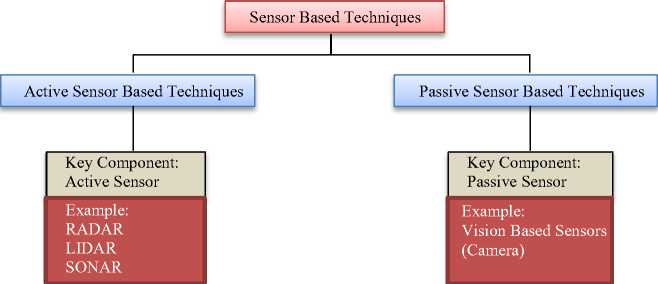
Fig.1. Various Sensor Based Techniques
-
1. Active Sensor Based Techniques
-
2. Passive Sensor Based Techniques
The sensors having their own source of energy are known as Active Sensors. For collecting the information, energy is transmitted by them only [1]. Active Sensor Based Techniques are the techniques that use the Active Sensor as the key Component.
The sensors those don’t have their own source of energy are known as passive sensors. They have to take the energy from the external source, for example vision based sensors [1]. Camera is used by the vision based sensors to capture the scene.
Merits and demerits of the Active Sensors and Passive Sensors are presented in Table 1. Active sensors are costly as compared to passive sensors. Excellent measurement of positioning and speed is the main advantage of Active sensor.
|
Table 1. Comparison of Active Sensors and Passive Sensors |
||
|
Active Sensors |
Passive Sensors |
|
|
Advantages |
Excellent Measurement of Positioning and Speed |
Very Cheap |
|
Disadvantages |
Very Costly |
Not able to generate the detailed information like active Sensors. |
-
B. Vision Based Techniques
Vision Based Techniques
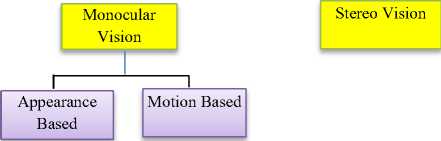
The technique in which camera is used to capture the information of scene to know about the upcoming objects in the path is known as a vision based technique. It is a strong mechanism. These techniques are very much cost effective as compared to the techniques using active sensors [1]. Various vision based techniques are discussed in Fig. 2.
-
1. Monocular Vision Based Approach
-
2. Stereo Vision Based Approach
The approach that uses one camera to capture the scene is known as a monocular vision based approach. Image is captured then processing is done on it [1, 3]. Further monocular vision based technique is of two types as displayed in Fig. 2, considerations and merits of these two types are discussed in following Table 2.
Table 2. Comparison of Appearance Based and Motion Based Techniques
|
Appearance Based |
Motion Based |
|||
|
Consideration |
1. |
Shape |
1. |
Strong Dis- |
|
2. |
Texture |
placement |
||
|
3. |
Colour |
of object is |
||
|
4. |
Edge |
2. |
needed. Size of ob- |
|
|
ject must be very large. |
||||
|
Advantages |
1. |
Speed |
||
|
2. |
Cost Effectiveness |
|||
|
3. |
Ability to detect very small obstacles. |
|||
The approach that uses two cameras in place of one to arrest the image at the same time is known as Stereo Vision Based Approach. The depth detail of the obstacle is easily obtained accurately from the images taken. The two images taken at same time are checked that whether there are any similar pixels present, which further helps to calculate depth and is known as disparity. Calibration is properly required between both two cameras present. Stereo vision based and monocular vision based tech-
Fig.2. Various Vision Based Techniques
niques are analyzed on the basis of some attributes like calibration, computational requirement, maintenance etc. as presented in the Table 3. As the Stereo Vision Based
Approach is more costly and have more computational requirements than Monocular Vision Based Approach, so it is less preferred as compared to Monocular Vision Based Approach.
Table 3. Comparison of Stereo Vision Approach and Monocular Vision Approach
|
Stereo Vision Approach |
Monocular Vision Approach |
|
|
No. of Cameras used |
2 |
1 |
|
Cost |
More Costly |
Less Costly |
|
Maintenance |
Requires more maintenance |
Requires less maintenance |
|
Use |
Not used in Real Time Situations |
Used in Real Time Situations |
|
Characteristics |
Motion Characteris- |
Appearance Char- |
|
used |
tics |
acteristics |
|
Computational Requirement |
More |
Less |
|
Calibration |
Required |
Not Required |
-
C. Ground Plane Detection
For sensing the Environment, Monocular Vision Based Approach can be used, but more accurate and fast methods are needed for real time processing of data gathered [2]. Techniques like texture segmentation, motion, inverse perspective mapping, color and ground plane detection etc. can be used with Monocular Vision Based Approach. In real time, ground plane detection technique can be used as it is computationally very simple among other techniques. In ground plane detection, image is partitioned into two regions -> ground and non-ground, based on certain characteristics of particular area. Then reference area is matched with properties of ground area. Properties of ground matches with the reference area and properties of non-ground don’t matches with the reference area. This process continues until complete image is processed. Obstacles are further checked for in nonground area. For detecting ground plane, techniques like Thresholding and Region Growing can be used. By removing the ground plane from image, feature extraction becomes simple and consumes less time.
-
D. Feature Extraction
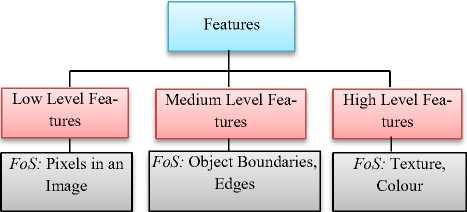
Fig.3. Various Levels of Features
After partitioning the image into ground and nonground region, further obstacles are checked for in the non-ground region. For the obstacle checking, feature extraction is done. Various types of features and their focus of study (FoS) are described in Fig. 3.
After extraction of features, number of methods had been proposed in the literature for obstacle detection. Lowe proposed SIFT (Scale Invariant Feature Transform) [4] in 2004 and SURF (Speeded up Robust Features) [5] were proposed by Bay et al. in 2006. As comparison with SIFT, SURF is faster. Based on points of interest like blobs, corners etc. features are extracted by SURF. Unchanging property to illumination, rotation, scale and computational simplicity are main advantages of the SURF. After extracting the features of non-ground image, they are matched with the obstacle image features to select Region of Interest.
-
E. Obstacle Detection: Process
Fig 4 describes the basic steps used in an obstacle detection, which includes video as an input and then preprocessing is done to select the high quality frames followed by segmentation and feature extraction. Segmentation divides image into 2 parts, ground plane and nonground plane, here non-ground plane will be checked further for the obstacles presence. Features will be extracted from non-ground plane and then by referring to the particular obstacle image, obstacles will be checked for.
-
III. Obstacle Detection: Study and Analysis
Analysis and survey of most of existing techniques for each level of obstacle detection process is presented here.
-
A. Monocular Vision Based Approach
Vision based approach is preferred over the other methods due to computational simplicity. Focus of Study (FoS) of obstacle detection by evolution of monocular vision based approach across the various years are described in evolution of monocular vision based techniques as shown in Fig. 7. In 2000, Ulrich et al. [2] gave a technique for ambulant robots, in which each single pixel of an image is checked and classified on its color appearance, to check that whether it belongs to an obstacle or the ground. The technique performs in real time and outputs binary obstacle image at high resolution. This technique includes four steps as described in Figure 5. In 2005, Michels et al. [6] described a supervised learning based algorithm using monocular vision to detect object i.e. obstacle. They considered remote control car for this, running at high speeds. Their algorithm using laser range finder, learns the relative depths on single images using monocular visual sign. In 2006, Yamaguchi et al. [3] gave a technique for detection of obstacles that are in motion using ego-motion approximation. First of all the image was divided into small pieces and then local measurements on each image were calculated to have an estimate of ego motion. At the end all local measurements were clubbed up. Structure from motion algorithm was used to calculate vehicle ego-motion. Feature points that don’t contain obstacles were extricated from regions
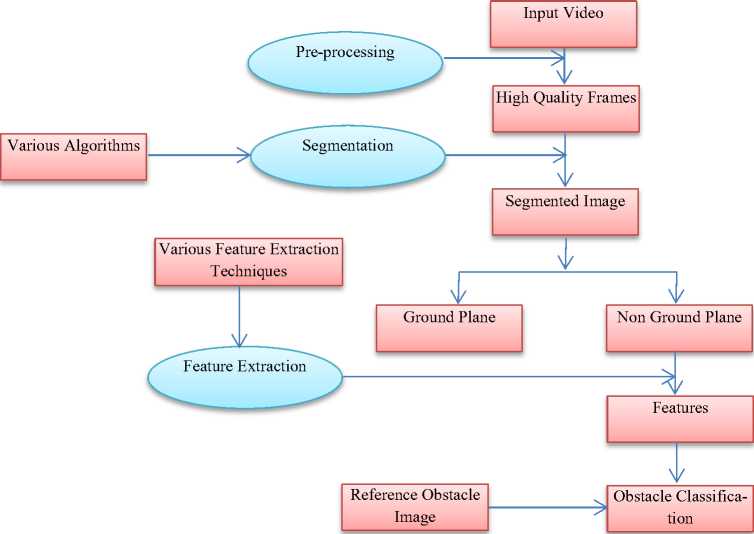
Fig.4. General Obstacle Detection Process
and feature points of various consecutive frames were followed to find obstacles in motion. In 2008, Song et al. [7] gave a technique to spot vehicles in different traffic situations. This method spotted vehicles in steps as described by Figure 6. In 2008, Zhan et al. [8] on basis of monocular vision gave a seamanship method for ambulant robots in untold habitat. Obstacle recognition, distance calculation, path organization were three tasks used in the recommended technique. For obstacle recognition, technique recommended in [2] was used. To calculate distance, variation equation between robot and image coordinate was used and grid map was used to organize path. In 2009, Muller et al. [9] suggested a rambler identification technique. Detection range was partitioned into sub regions, known as nearby regions and afar regions. Motion segmentation was employed to recognize nearby region obstacles and Inverse perspective mapping was implemented to identify afar region obstacles. In 2009, Viet et al. [10] proposed a classifying method for recognizing obstacles using touch and color. Touch came into existence when color fails.
Strain the colour input image

Conversion into HSI colour space

Histogramming of citation area

Corelation to citation histograms
Fig.5. Flowchart for Ambulant Robots
Creation of Prospect on basis of touch of vehicles

Employing PAF to figure vehicle Frontiers

Confirming Prospect by employing AdaBoost Algorithm
Fig.6. Flowchart for Spotting Vehicles
For color attributes, histogram comparing on basis of resemblance of two histograms was considered. For touch features LBP or statistical techniques with eight histograms was implemented. K-mean clustering algorithm was used for grouping. In 2010, Lin et al. [11] gave an ego-motion evaluation technique and grouping approach to slice ambulant obstacles from videos. Ellipsoid scene shape in ambulant model was implemented and a complex ego-ambulant evaluation formula was obtained.
SURF characteristics were used for motion recovery, for motion evaluation genetic algorithm was used and pixel level probability model was used for grouping. In 2011, Cherubini et al. [12] gave a technique that aided the machine to evade the new obstacles that were not present during the preparation. Circumnavigation and collision risk were used for this objective and were evaluated from potential vector field obtained from tenancy grid.
Circumnavigation [Cherubini et al. [12]]
Evolution of Monocular
Vision Based Tech-
Deformable Grid Framework [Kang et al. [18]]
+
Colour & Locomotion Statistics [Lim et al. [13]]
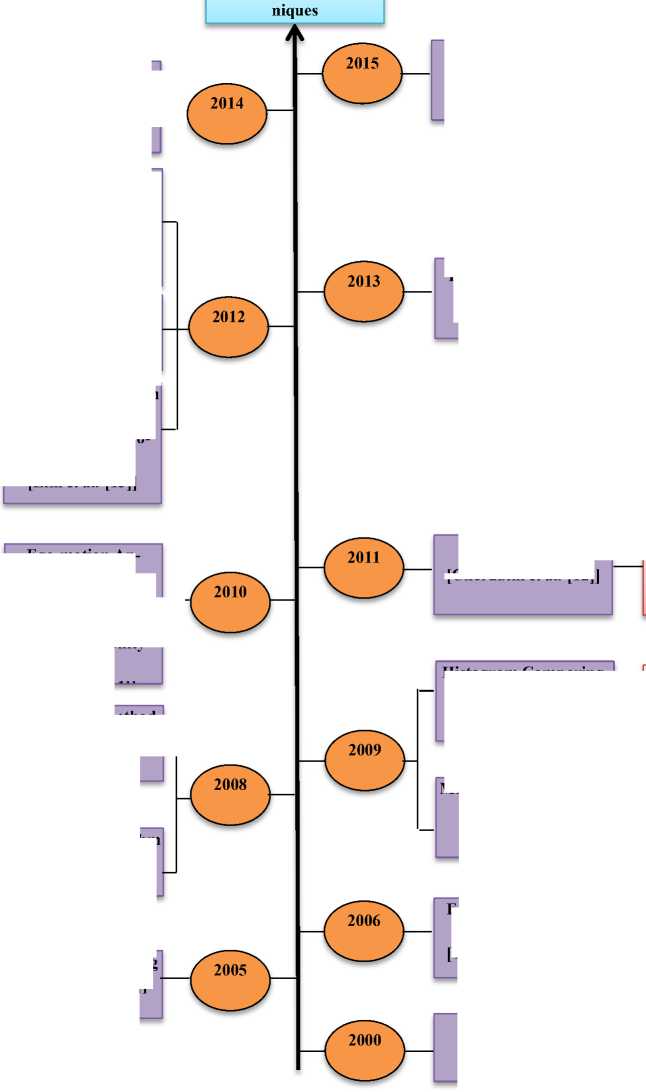
FoS: To aid the machine to evade new obstacles
FoS: Obstacle at a possibility of a clash
FoS: Each single pixel of an image is checked and classification is done on its colour appearance
FoS: Vehicle Ego Motion
FoS: Recognizing obstacle using touch & colour
FoS: Rambler Identification
Supervised Learning [Michels et al. [6]]
Ambulant Robots [Ulrich et al. [2]]
Motion Segmentation & Inverse Mapping [Muller et al. [9]]
Ego-Motion Approximation [Yamaguchi et al. [3]]
Histogram Comparing, LBP, K-mean Clustering [Viet et al [10]]
Seamanship method for ambulant robots [Zhan et al. [8]]
Fig.7. Evolution of Monocular Vision Based Techniques
|
FoS: Distinguishing ground plane & obstacles |
Two Successive Frames Prototype [Jia et al. [17]] |
|
Chasing Characteristics & Triangulating Features [Lalonde et al. [15]] |
||
|
FoS: 3D Recreation of Scene, Locomotion |
— |
|
|
FoS: Inconsistent pieces considered as an obstacles |
— |
Character Preference and chasing [Mishra et al. [14]] |
-
FoS: To recognize ramblers, EgoLocomotion
FoS: To slice ambulant obstacles from videos, Motion Recovery
Ego-motion Approach, Motion Evaluation Genetic Algorithm, Pixel Level Probability Model
|
Fast corner identifier |
FoS: Extricating |
|
|
[Lin et al. [16]] |
corner features, parking intervention |
FoS: Distance Calculation, Path Organization, Obstacle Recognition
FoS: Spotting Vehicles in different traffic situations
Ada-Boost Algorithm [Song et al. [7]]
FoS: High Speed and learning relative depth on single image
In 2012, Lim et al. [13] by using color and locomotion statistics gave a technique to recognize ramblers. Feature set was used to calculate ego-locomotion. By evaluating distinction between two successive images, region of interest was created. A number of feeble classifiers on basis of histogram of oriented Gaussian were uplifted using Ada-boost algorithm and block based method based on color information was used to identify ramblers.
In 2012, Mishra et al. [14] suggested a technique that worked for different characteristics extraction from environment. This technique was based on characteristics preference and chasing. Feature vector space was constructed that afterwards passed to the model. This vector space was the homographic conversion that was used to search inconsistent pieces which could be considered as obstacles. In 2012, Lalonde et al. [15] proposed a method for parking system, in which 3 dimensional recreation of the scene was done to identify stable obstacles. Following are the 2 main initiatives used: Figuring out locomotion of vehicle then 3D recreation to identify obstacle. Locomotion was evaluated by chasing characteristics and 3D recreation was done by triangulating those features to build 3D prototype. In 2013, Lin et al. [16] gave a method for parking intervention, to identify obstacles. FAST corner identifier was used to extricate corner features and then checking was done to check that whether features belong to ground or obstacle by using IPM. In 2014, Jia et al. [17] gave a method to evaluate distinction between ground plane and obstacle using locomotion characteris- tics and this technique was known as Two Successive Frames prototype. For matching characteristics of two successive frames KLT corner detector was used. Obstacles were distinguished from shadows and road marking, considering locomotion characteristics. In 2015, Kang et al. [18] gave a new framework known as Deformable Grid for identifying the obstacles. Initially the DG is in normal shape which changes according to the locomotion of object in scene. Measuring the amount of malformation this DG method identifies the obstacle at a possibility of clash. All the various monocular vision based techniques are analyzed in the following Table 4. Merits and demerits of each technique are discussed.
Table 4. Analysis of various monocular vision based techniques
|
Author/Year |
Method |
Description |
Target/Equipment |
Merits |
Demerits |
|
Ulrich et al. [2]/2000 |
Passive Monocular Colour Vision |
Approach is purely based on appearance of pixels |
(1) Mobile Robots |
|
(1) This approach do not work properly if obstacles are present inside the trapezoidal reference area |
|
Michels et |
Super- |
Algorithm learns |
(1) High speed Re- |
(1) Problem of High Speed Naviga- |
(1) Car will crash into an Ob- |
|
al. [6]/2005 |
vised Learning |
relative depths on single images using only monocular visual cues |
mote Control Car (2) Laser Range Finder |
tion is Considered (2) Avoids Obstacle in Un-structured Outdoor Environment |
stacle when Obstacle is less than 5m away |
|
Yamaguchi |
Ego- |
Ego-motion for |
(1) Vehicle Mounted |
(1) Proposed method is able to detect |
(1) This approach does not |
|
et al. [3]/2006 |
Motion |
the vehicle is calculated |
Monocular Camera |
moving obstacles (2) Pedestrians are also detected |
detects stationary objects on road
|
|
Song et al. [7]/2008 |
Monocular Machine Vision System |
Detects vehicles in front or behind of our own vehicle |
(1) Ego- vehicle |
|
(1) Vehicle Candidates are generated by exploiting a fact that vehicle has vertical and horizontal lines and also rear and front shapes of vehicle show symmetry |
|
Zhan et al. |
Monoc- |
Navigation Meth- |
(1) Camera Mounted |
(1) Simple Computation |
(1) It outperforms when grid |
|
[8]/2008 |
ular Vision Based Navigation Method |
od for Mobile Robot in an unknown Environment |
Mobile Robot |
|
size is too large or very small
ground is flat
|
|
Muller et al. |
Pedes- |
To detect Pedes- |
(1) Single Monocular |
(1) Computational Efficiency that |
(1) It is difficult to track pedes- |
|
[9]/2009 |
trian Detection Algorithm |
trians and to predict possible collisions |
Camera Mounted Car |
enables system to run in real time
|
trians in close proximity to car (2) Detection of Head of Pedestrian is very difficult |
|
Viet et al. [10]/2009 |
Classification Algorithm |
Presented new Classification Algorithm using colour and texture for obstacle detection |
(1) Outdoor Robots |
|
|
|
Lin et al. |
Ego- |
To effectively |
(1) Moving Camera on |
(1) Proposed method can be applied to |
(1) Some Initial guesses are |
|
[11]/2010 |
motion Estimation and Back-ground/ Foreground Classification |
segment moving objects from videos |
Moving Platform |
detect moving obstacles with irregular camera movement
|
generated (2) Difficulty in estimating 10 degrees of freedom |
|
Cherubini et al. [12]/2011 |
Circum-navigation and Collision Risk |
To aid the machine to evade new obstacles |
(1) Robot |
|
|
|
Lim et al. |
Block |
To detect pedes- |
(1) Single camera on |
(1) It can track pedestrians with pos- |
(1) It cannot track pedestrians |
|
[13]/2012 |
Based Method |
trians using colour and motion information |
Mobile or Stationary System |
sibly partial occlusions
|
those who have recently entered in image frame (2) Interaction between detection and tracking is not considered |
|
Mishra et al. [14]/2012 |
Inmotion detection |
To detect and track moving obstacles |
(1) Mobile Robot |
Variations
|
(1) This method fails when surface is plain and doesn’t have distinguishing feature |
|
Lalonde et |
3D |
Detection of static |
(1) Car having rear |
(1) Very High Detection Rate |
(1) Least amount of disparity |
|
al. [15]/2012 |
Reconstruction Algorithm |
obstacles from single rear view parking camera |
mounted parking camera |
|
for given camera displacement |
|
Lin et al. |
Method |
Obstacle detection |
(1) Car having rear |
(1) Low Computing Power |
(1) The system will only work |
|
[16]/2013 |
for Parking Intervention |
for parking assistance |
mounted parking camera |
|
at driving speed under 30 km/hr (2) Detectable distance is up to 6 metres |
|
Jia et al. |
Two |
To evaluate dis- |
(1) Autonomous Navi- |
(1) It meets real time requirement |
(1) Too many miss detections |
|
[17]/2014 |
Successive Frames Prototype |
tinction between ground plane and obstacle |
gation Vehicle- Mobot |
|
and mismatched feature points in obstacle region may fail the system (2) Far away objects are considered as no obstacles |
|
Kang et al. |
De- |
Detecting obsta- |
(1) Smart Phone |
(1) Robustness towards motion track- |
(1) Unable to detect collision |
|
[18]/2015 |
forma- |
cles at the risk of |
(2) Tablets |
ing and ego-motion of the camera |
in region where the accurate |
|
ble Grid |
collision |
(3) Wearable Devices |
(2) Suitable for ETA systems using consumer devices like smart phones |
motion vector is not easily computed like walls, doors |
-
B. Key Frame Extraction
For detecting the obstacle we need an image, we are using camera to take the video, key frame must be extracted from the video sequence. The excessive grade frame that is enough capable of portraying and is able to reflect the obstacle clearly present, in a video sequence is considered as key frame. Focus of Study (FoS) of obstacle detection by evolution of key frame extraction across the various years is described in evolution of key frame extraction techniques as shown in Fig. 8.
In 1998, Zhuang et al. [19] proposed a technique on the basis of unsupervised clustering. For mastering the cluster density, threshold and color histogram of each frame of video computed in HSV color space was used. Key frame election was done only to clusters which were huge enough to be considered as key cluster. From every cluster a representative was picked as a key frame. In 2000, Zhao et al. [20] proposed a technique based on the concept of Nearest Feature Line. Both Feature Extrication and Distance Computation are considered as a whole process. Breakpoints of feature trajectory of a video shot are used as key frames and lines passing through these points are also used to represent the shot. In 2000, Dou-lamis et al. [21] proposed a frizzy based election technique. Every frame was depicted in form of frizzy color and locomotion histogram. Shortest spanning tree algorithm was used to part every frame. For every part a frizzy color and locomotion histogram was extricated and saved as a presenter. In 2000, Gong et al. [22] gave a method in which clusters were constructed using feature vectors. First of all 3D histograms were created for every block to assimilate spatial data of every frame and then theses histograms were clubbed up to form feature vector. The frame that was closest to the center of cluster was elected as a key frame. In 2007, Mukherjee et al. [23] gave a method on the basis of strayness of representation of the frames, to elect key frame from video shots. Spatial and Haar wavelet based characteristics were extricated for every frame. Individual characteristics were used to evaluate the strayness between frames and the frames with huge strayness were elected as key frames. In 2013, Liu et al. [24] proposed a technique to elect key frame for every action sequence of human using Ada-Boost learn- ing algorithm. For key frame selection, correlated pyramidal locomotion-characteristics for human action recognition were used. In 2014, Raikwar et al. [25] proposed a key frame extraction method that consists of two phases, in first step, size of input video shot is reduced by removing the frames that are not distinguishable and in 2nd step motion energy between the remaining frames is calculated for checking optical flow and the frames having maximum optical flow are only retained.
FoS: Absolute distinction of histograms of successive frames
Thresholding [Sheena et al. [26]]
FoS: To extract key frame for every action sequence of human
Adaboost Algorithm, pyramidal locomotion characteristics [Liu et al. [24]]
FoS: 3D Histograms for every block
Feature Vectors [Gong et al. [22]]
FoS: Frizzy Colour and Locomotion Histogram
Frizzy Based Election Technique [Doulamis et al. [21]]
FoS: Extricating Key Frames
NFL [Zhao et al. [20]]

Key Frame Extraction [Raikwar et al. [25]]
Strayness Representation [Mukherjee et al. [23]]
Unsupervised Clustering [Zhuang et al. [19]]
FoS: Size of Input Video, Motion Energy between Frames
FoS: Spatial & Harwavelet characteristics, Strayness
FoS: Cluster Density, Threshold, Colour Histogram
Fig.8. Evolution of Key Frame Extraction Techniques
Table 5. Analysis of various key frame extraction techniques
|
Author/Year |
Method |
Description |
Merits |
|
|
Zhuang et [19]/1998 |
al. |
Unsupervised Clustering |
Key frame election was done only to clusters which were huge enough to be considered as key cluster. From every cluster a representative was picked as a key frame. |
|
|
Zhao et [20]/2000 |
al. |
Nearest Feature Line |
Breakpoints of feature trajectory of a video shot are used as key frames |
|
|
Doulamis et [21]/2000 |
al. |
Frizzy Based Election Technique |
Multidimensional fuzzy histogram is constructed for each video frame based on a collection of appropriate features, extracted using video sequence analysis techniques |
|
|
Gong et [22]/2000 |
al. |
Singular Value Decomposition |
For input video sequence a feature frame matrix is created and SVD is performed on it. |
|
|
Mukherjee al. [23]/2007 |
et |
Dempster-Shafer theory of evidence |
Works on basis of inter-relationship between different features of image frames in a video |
|
|
Liu et [24]/2013 |
al. |
Boosted key-frame selection and correlated PMF + Ada-boost Algorithm |
A method for human action recognition |
|
|
Raikwar et [25]/2014 |
al. |
Key Frame Extraction Method |
Two phase method in which in 1st step size of video shot is reduced and in second optical flow is calculated for maximum |
|
|
Sheena et [26]/2015 |
al. |
Absolute distinction of histograms of successive frames |
Two phase method to extract key frames in which in 1st step threshold of absolute distinction of successive frames is calculated and then in 2nd step threshold was analysed |
|
In 2015, Sheena et al. [26] gave a technique to extract key frames on the basis of absolute distinction of histograms of successive frames. This technique consist of 2 passes: threshold of absolute distinction of successive image frames was calculated in 1st pass and then in 2nd pass key frames were extracted by analyzing the threshold against absolute distinction of successive image frames. All the various key frame extraction techniques are analyzed in Table 5. Methods, merits and description are discussed.
-
C. Ground Plane Detection
Ground plane detection is a technique that can be incorporated to identify the obstacles. Evolution of ground plane detection techniques along with their Focus of Study (FoS) is discussed in Fig 9. In 2006, Zhou et al. [27] proposed an algorithm based on homography evaluation between 2 frames extracted from a chain. To evaluate homography, H-Clustering algorithm was implemented. In 2010, Conrad et al. [28] proposed a modification to EM (Expectation Maximization) algorithm for grouping of pixels in images as ground and non-ground pixel categories. Expected value on the basis of the ongo-
ing specifications of a probability task was evaluated by E-step. LM (Liebenberg-Marquardt) and simplex method were considered for M-step. Simplex method was better than other. In 2010, Jamal et al. [29] gave an obstacle identification method for ambulant machine seamanship by combining segmentation and optical flow methods. GMM (Gaussian Matrix Model) was implemented to learn stable characteristics of ground level. Then by using learned signatures, ground level was partitioned. If piece matches with ground level characteristics, it was parted as ground plane else was considered as non-ground level. This method was very simple. In 2010, Lin et al. [30] gave the method to evaluate distance between obstacle and machine on the basis of IPT. Homography was used to distort images. Pixels equating to the ground level were emulated in the considered images. Numerous cues were used to evade flaws and attain ruggedness. To categorize characteristics as ground and non-ground among successive frames, homography was used. First images were transformed to HSI color space and were parted using color homogeneity. Ground or non-ground region was categorized by matching pieces with distorted images. In 2012, Benenson et al. [31] gave a method to evalu
ate obstacle frontiers without evaluating depth map. To make the algorithm fast, dynamic programming was implemented. To evaluate ground level, v-disparity map- ping was considered. For identifying objects GPU rate was boosted.
FoS: Obstacle free area, Attainable part
Surface Normal, Technique to figure attainable segment [Koester et al. [34]]
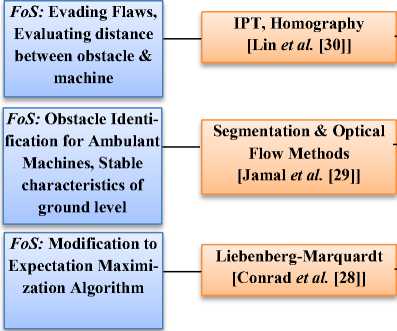
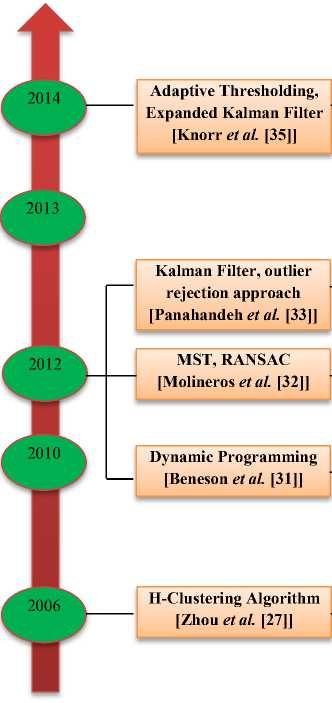

FoS: Homographic Evaluation between 2 Frames
Fig.9. Evolution of Ground Plane Detection Techniques
In 2012, Molineros et al. [32] attained ego-locomotion in integration with soupy optical flow that results into a residual locomotion map which was implemented to part 3D ambulating objects. For electing ground points, MST (Minimum Spanning Tree) was executed. To separate outliers RANSAC was implemented. Using disparity of optical flow evaluation, a residual locomotion map was generated. Algorithm also performed well when ground level in images was less. In 2012, Panahandeh et al. [33] figured locomotion by executing an IMU (Inertial Measurement Unit) and ground level in the images was identified in 2 steps. 1st on the basis of kalman-filter (nonlinear), planer homography was generated. Secondly on basis of evaluation of plane normal, outlier rejection approach was suggested. In 2013, Koester et al. [34] gave a technique to correctly figure the attainable segment (obstacle free area) of ground ahead of visually impaired person. Surface normal were evaluated by considering gradients in disparity maps and were used to figure the attainable part. In 2014, Knorr et al. [35] gave an approach in which large field of view of fish eye camera was used to ruggedly recognize outliers, where huge motion parallax vectors were present. They clubbed adaptive thresholding with expanded kalman filter for better execution. Results were upgraded by distorting images into a common frame to evade deformity. All the various ground plane detection techniques are analysed in Table 6. Methods, merits, demerits and description are discussed.
Table 6. Analysis of various ground plane detection techniques
|
Author/Year |
Method |
Description |
Target/Equipment |
Merits/Applications |
Demerits |
|
Zhou et al. [27]/2006 |
Homography Based Ground Detection Ap proach |
To detect ground in mobile robot applications |
On-Board Camera |
(2)Practical Deployment
|
|
|
Conrad et al. [28]/2010 |
Modified EM Algorithm |
Indoor Navigation |
Mobile Robot |
plane is not smooth
|
|
|
Jamal et al. |
Combination of |
Mobile Robot Navi- |
Camera mounted on an |
(1) Navigation in outdoor |
(1) Fails when colour of |
|
[29]/2010 |
segmentation and Optical flow techniques |
gation |
in-house developed mobile platform |
structured and dynamic environment
|
the path is not uniform |
|
Lin et al. [30]/2010 |
Vision based obstacle avoidance |
To estimate distance of objects and avoid obstacles in an indoor environment |
Wheeled mobile robot |
processors |
|
|
Benenson et |
Fast Stixel Com- |
To estimate ground |
Stereo Image |
(1) Focuses on computing |
(1) Wrong quantization |
|
al. [31]/2012 |
putation |
obstacles boundary without calculating depth map |
exactly what we need (2) High Speed |
(2) Ignores horizontal gradient |
|
|
Molineros et |
Novel Image |
To detect obstacles |
Moving vehicle using |
(1) Works in cases with |
(1) Arbitrary pose detec- |
|
al. [32]/2012 |
Registration Algorithm - VOFOD |
from moving vehicle particularly children when backing up |
monocular wide angle camera |
very few ground points present
|
tions still needed to be improved (2) To eliminate false positives |
|
Panahandeh et |
Kalman filter + |
To determine ground |
Mobile camera mount- |
(1) Proposed approach is |
(1) False detected ground |
|
al. [33]/2012 |
outlier rejection approach |
plane features |
ed on inertial measurement unit (IMU) |
scene independent
|
features located around edges (2) Virtual plane false detection |
|
Koester et al. [34]/2013 |
Computer vision approach to detect accessible section |
To determine accessible section in front of walking person |
Walking person |
performance |
|
|
Knorr et al. [35]/2014 |
Adaptive thresholding + expanded kalman filter |
Robust homography estimation |
Fish eye cameras |
|
|
-
D. Texture Features
For categorization of objects, texture features are utilized. By evaluating characteristic values, it can be checked that whether the considered area belongs to obstacle or not. Pits, manholes etc. can be identified by collaborating texture feature techniques with obstacle identification technique. Characteristics of an image are evaluated and matched with citation characteristics to search for parallel characteristics. Further categorization of obstacles can be done. Different texture based techniques are present that we can use to do so. Some of the techniques present are- Local binary Patterns (LBP)[36][37], Grey Level Co-occurrence Matrix(GLCM)[38][39], kernel methods[36], feature combination[40], histograms based methods[41][42], Gabor filters[43]and boosting and baseline methods[44]. Best output can be attained by clubbing some of these techniques. Evolution of texture feature techniques along with their Focus of Study (FoS) is discussed in Fig 10. In 2000, Zitova et al. [45] proposed a technique to identify multi frame characteristic
points that remains constant towards rotation and noisy and unfocused images were also properly handled. This technique checked for common contents in various images to extract characteristics. Personal dataset of size 180 x 180 pixels was created and these images were rotated several times by different angles. These images were also softened using square convolution masks of varying sizes. They compared these techniques with another approaches and found that it gives best results in case of huge softening and minimum rotation. In 2001, Saisan et al. [46] proposed a technique that identifies and categories dynamic textures, where every touch was depicted specially, in lively structure. For PCA (Principal Component Analysis) and ICA (Independent Component Analysis), 3 distances were analyzed. They got best output in martin distance used for PCA. In 2006, Woolfe et al. [47] gave a technique to represent the locomotion of water, smoke etc. i.e. organic locomotion. They narrated sequence as multivariate AR (Autoregressive) structures. To figure
FoS: Feature set for humans how they recognize events
FoS: Dynamic Characteristics
FoS: Analysed different characteristics structures
FoS: Lively Touch, Fidelity Matter
FoS: Portraying the characteristics
FoS: Identifying Lively Touch, Facial Expressions
FoS: Identifying Object, Sturdy Characteristic Extrication
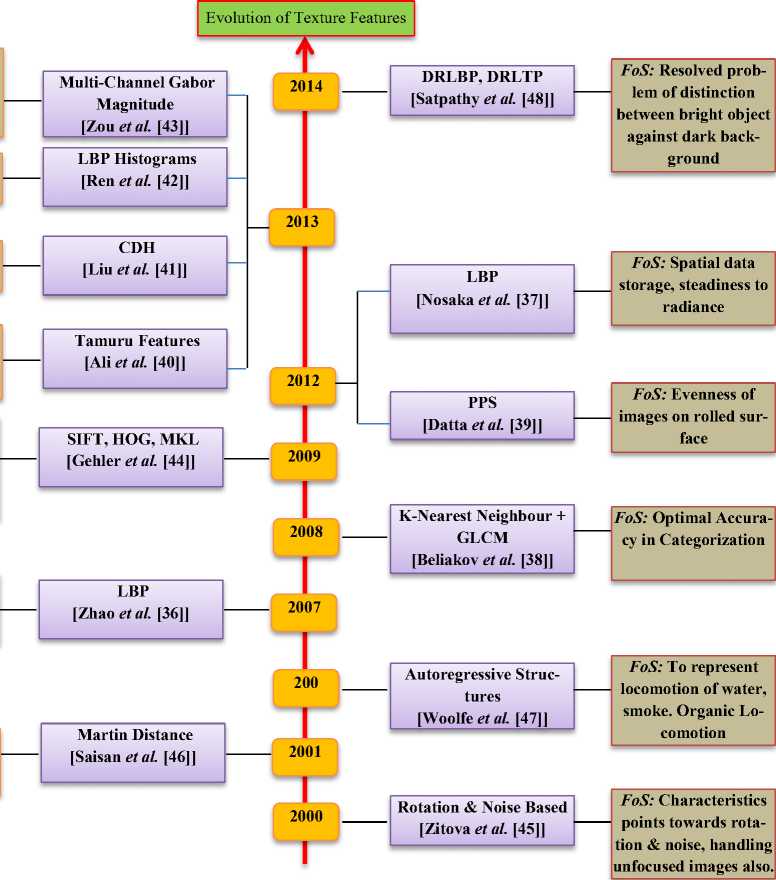
Fig.10. Evolution of Texture Features
the distance betwixt AR models, KL metric and chern off distance were evaluated. In 2007, Zhao et al. [36] pro posed a technique using LBP to identify lively touch. Volume LBP was implemented to club locomotion and impression to structure touch. This method delivered an application for identifying facial expressions. As in comparison with other methods, authors obtained huge identification rate. In 2008, Beliakov et al. [38] merged the GLCM entries with benchmark metrics and analyzed these metrics with various other aggregation approaches to check for optimal accuracy of categorization. GLCM metrics were expendable; converting arithmetic mean to quadratic mean notably upgraded the effectiveness. K-nearest neighbour on basis of GLCM results best in noise absence. In 2009, Gehler et al. [44] analyzed different characteristics structures like single features as shape, color, SIFT, HOG and combination characteristics like product, averaging and MKL. Different techniques were discovered on basis of uplifting. Simple baseline techniques resulted equally well in contrast to its equivalents and were very simple. These techniques can be implemented in real time framework. In 2012, Datta et al. [39] by analyzing the outcome of disparity PPS (Pixel Pair Spacing), evaluated the evenness of images of a rolled surface by GLCM technique. In 2012, Nosaka et al. [37] suggested a LBP based new image feature that was steady to radiance also. Real and co-occurrence of adjoining LBPs both were present in it. More spatial data was stored by this technique. Due to radiance results of gabor, raw was not appropriate. In 2013, Ali et al. [40] gave a new feature set on the basis of how humans recognize the events. Organic events were categorized in this suggested approach. For this tamuru features were used by roughness features and openness features used histograms. First of all, image was quantal into eight color levels and for color characteristics; canny edge identifier was executed to figure direction characteristics. Better output was obtained in this technique as comparable to others.
In 2013, Liu et al. [41] gave a method known as CDH (Color Difference Histogram) that concentrated on portraying of characteristics for retrieving images. Color distinction betwixt 2 points in respect of color and edge locations were ciphered in it. It showed better results for content based image retrieval techniques. In 2013, Ren et al. [42] used LBP histograms to identify lively touch on basis of temporal and spatial characteristics. On the basis of PCA (Principal Component Analysis), 2 approaches were suggested on learning to handle fidelity matter by histograms of LBP. They suggested super histograms also. In 2013, Zou et al. [43] suggested an approach to identify object by interpreting multichannel Gabor magnitude co-occurrence matrices. Gabor magnitude touch equality was its basis. For sturdy characteristics extrication, learning algorithm to rescale images was advised. In 2014, Satpathy et al. [48] proposed new set of edge touch characteristics, Distinctive Robust Local Binary Pattern (DRLBP) and Ternary Pattern (DRLTP). These features removed the limitations of the other Texture Features like LBP, LTP and Robust LBP. They solve the problem of discrimination betwixt a bright object against a dark background and vice-versa inherent in LBP and LTP. DRLBP also resolves the problem of RLBP whereby LBP keys and their complements in a like block are plotted to similar key.
-
E. SURF and SIFT Features
In 2004, David G. Lowe discovered distinctive image characteristics for comparing various images and was also steady to scaling and spinning of images [4]. This approach was known as SIFT (Scale Invariant Feature Transform). In 2006 Bay et al. discovered SURF (Speeded up Robust Features), which were very much fast and better than all other approaches proposed [5]. Object recognition can also be done by using SIFT features. Individual characteristics were compared with huge database of characteristics which contained object features using fast nearest neighbour approach. SIFT features from cited images were extricated and stored in the database. Evolution of SURF and SIFT feature techniques along with their Focus of Study (FoS) is discussed in Fig 11. In 2006, Bay et al. [5] discovered SURF (Speeded up Robust Features), that was steady towards spinning and scale. First of all, interest points were nominated at various locations in image. For this Hessian based detectors were executed. In 2nd step, interest points were presented as characteristic vector. In 3rd step characteristic vector in various images were compared. In terms of sturdiness, individuality, rapidity and clarity, this technique comes out to be better than all other approaches. In 2008, Zhang et al. [49] implemented SURF for identification of indicator points from image in SLAM (Simultaneous Localization and Mapping) technique. Landmarks extricated by using SURF features and EKF (Extended Kalman Filter) figured the position of camera and landmarks. For comparison of SURF features, Euclidean distance was utilized. In 2009, Lampert et al. [50] resolved the problem to categorize objects when training and test sets differ. Objects were identified by human described elucidation that contained color or any other geographic data. Categorization was done by direct and indirect feature prediction. In 2009, Ta et al. [51] gave a technique to recognize image and predict characteristics in a video by optimizing the interest points. Alternative of computing feature descriptors of 2D images, candidate features were explored and compared in community neighbourhood within the 3D image pyramid. In 2009, Yu et al. [52] resolved the steadiness of SIFT features associated with angles those describe camera axis spinning. Transition tilt, a new framework was discovered. It managed more transition tilts than its equivalents. In 2010, Besbes et al. [53] suggested a SVM and SURF based technique to identify the rambler. For categorizing SURF features, RNN was utilized. For fastening the extrication of features, stratified codebook was utilized. That boosted the categorization output along with the upgradation of characteristic extrication. In 2010, Sande et al. [54] gave color rubrics to boost steadiness against radiance and discerning power. For various datasets, various descriptors must be utilized.
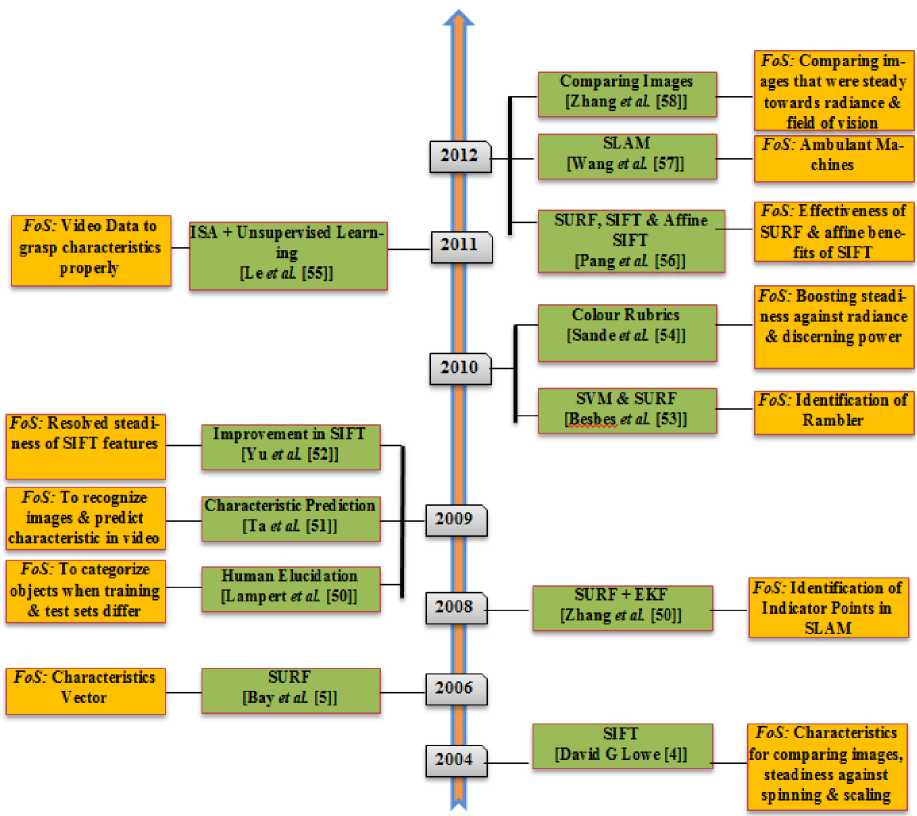
Fig.11. Evolution of SURF and SIFT Features
Instead of discrete rubrics, proper amalgamation of colour descriptors gave better results. In 2011, Le et al. [55] suggested a technique on the basis of video data to grasp characteristics rightly from it. Unsupervised learning was utilised as an addition to ISA (Independent Subspace Analysis) algorithm. This approach in collaboration with approaches like stacking and convolution gave better results. In 2012, Pang et al. [56] predicted that SURF, SIFT and Affine Sift, none of them were fully affine. They gave a wholly affine steady algorithm on basis of SURF. Effectiveness of SURF and affine benefits of SIFT were considered by evading their limitations. This advanced SURF technique comes out with fewer complications than ASIFT. In 2012, Wang et al. [57] suggested technique in SLAM (Simultaneous Localization and Mapping) for ambulant machines. For equivalent characteristic points, epi-polar constraints were explained and SURF features were exploited for having good and sturdy identification. In 2012, Yu et al. [58] gave a technique to compare images that were steady towards radiance and field of vision. Normalization of radiance, conversion of images field of vision, evaluation of relative view and radiance was done to boost fidelity, steadiness and exactness of the system. If initial field of vision and radiance approach fades, this approach also fades, so valid angle and valid radiance were suggested.
-
IV. Results and Conclusions
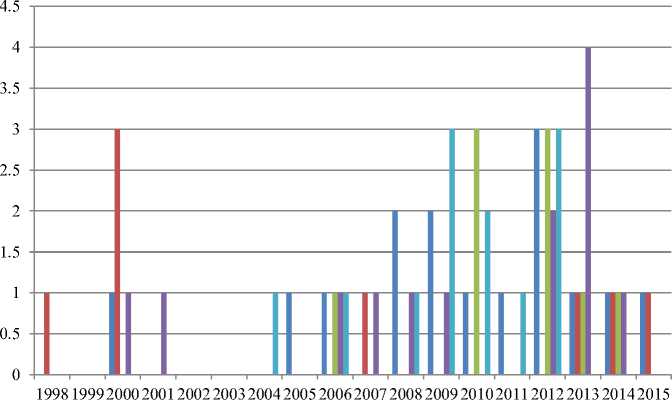
Exploring the existing research in field of obstacle detection is the main objective of this review. Out of 58 research papers, 23 are publicized in eminent journals and the remaining are publicized in workshops, conferences and symposiums on obstacle detection. It is merit expressing about the publication for that research articles on ground plane detection, monocular vision approach, key frame extraction, feature extraction and SURF and SIFT features are published in comprehensive variety of journals and conference proceedings. We observed that IEEE conferences/symposiums like IEEE Intelligent Vehicles Symposium, IEEE Conference on Robotics, IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE International Conference on Fuzzy Systems, IEEE 12th International Conference on Computer Vision contribute large part of research articles. Prime journals like International Journal of Computer Vision, The Visual Computer, Journal of signal processing, Pattern Recognition, Neuro computing, EURASIP Journal on Advances in Signal Processing, contributed significantly to our review area. Figure 12 depicts the percentage of research papers analyzed at various phases of the obstacle detection process like as the figure depicts 26% in Monocular vision based approach, 14% in key frame extraction, 16% in ground plane detection, 23% in texture features, 21% in SURF and SIFT features. Study consists of 45% research articles publicized in conferences and 40% in eminent journals, 7% literature appeared in workshops and 9% of the study publicized in symposiums. Conferences acquire major part of publications (26 papers) followed by 19 papers in journals. Fig. 13 depicts the number of research papers published in the various areas against the different steps included in obstacle detection from year 1998 to 2015.
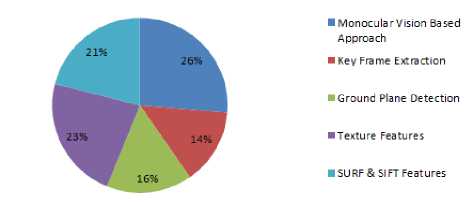
Fig.12. Obstacle detection mechanism
■ Monocular Vision Based Approach
■ Key Frame Extraction
■ Ground Plane Detection
■ Texture Features
Fig.13. Time based count in obstacle detection against various fields
From year 2000 – 2015, no. of research papers against monocular vision based approach are described in the Figure 13. Maximum 3 research papers were published in year 2012. In the field of key frame extraction, research is discussed from year 1998 – 2015, with maximum research done in year 2000, leading towards 3 research papers. Ground plane detection is also discussed over years from 2006- 2014, having maximum research articles published in year 2012 and year 2010 with the count of three. Maximum 4 research articles in field of Texture Features in year 2013. SURF and SIFT originated in year 2004 with maximum research done against this filed in the year 2009 and year 2012 leading towards 3 research articles.
After analyzing all the research carried in various fields, conclusions are presented like in field of monocular vision based approach, it is concluded that deformable grid proposed by Kang et al. [18] is a good method for detecting obstacles at the risk of collision, where as to evaluate distinction between ground plane and obstacle, two successive frames prototype proposed by Jia et al. [17] comes out to be appropriate as no calibration or any prior knowledge of the camera is required and is cost effective also. For detecting and tracking moving obstacles, in-motion detection method proposed by Mishra et al. [14] is concluded to be the appropriate one as it is computationally simple having better time response. Block based method by Lim et al. [13] can be used to detect the pedestrians. For key frame extraction, if fast processing is required, method proposed by Raikwar et al. [25] is the appropriate one as it requires very less time for extraction of key frames, where as if high accuracy and simplicity is considered then absolute distinction of histograms of successive frames method proposed by Sheena et al. [26] comes out to be appropriate one. In ground plane detection phase, to determine ground plane features, kalman filter and outlier rejection approach proposed by Panahandeh et al. [33] is concluded to be a good method. To detect obstacles from moving vehicles, novel image registration algorithm VOFOD by Mo-lineros et al. [32] is the appropriate one. To guide the walking person about the obstacles around, computer vision approach to detect accessible section by Koester et al. [34] is the appropriate method.
-
V. Discussions
Total 58 research articles out of 761 have been reviewed to study Obstacle Detection techniques and to provide a surmised summary. Unlike erstwhile reviews, our supreme emphasis is on the research done at each phase of Obstacle Detection process, and existing research work from diverse main sub-topics is categorized. We have used quality analysis procedures and have done a wider literature survey on obstacle detection up to 2015. Research issues of monocular vision based approach, key frame extraction and ground plane detection are explored. We explored the obstacle detection mechanisms and their subtypes in detail for each and every phase of obstacle detection and compared the various mechanisms. No such survey has been proposed that consist of the literature of each and every step included in the obstacle detection process. From this survey, authors can easily find the recent research carried out after year 1998, all the existing studies are logically categorized into various sections.
-
VI. Future Research Directions
This research article presents a well ordered survey on obstacle detection techniques. As obstacle detection is a complete process having various phases in it. Study is done for all of the phases. First of all various Monocular vision techniques are discussed and are analyzed. Then various key frame extrication techniques are studied and analyzed, after that various ground plane detection techniques are also discussed. Feature extrication is also discussed along with the SIFT and SURF features. Various vision based approaches are also discussed in the research conducted, like Stereo Vision based approach and Monocular Vision based approach. It is concluded that Monocular Vision based approach is less costly then Stereovision Based approach and also have low complexity leading towards fast processing in real time. The main objective of this research is to find the suitable technique at every phase having low cost and fast operating in real time environment with high accuracy. We have also identified a number of open issues that would benefit from further studies. To the best of our knowledge, such an analysis has not been done so far and could lead to identifying novel areas for the application of obstacle detection techniques in the context of aiding the visually impaired persons.
Though a lot of progress has been achieved in the obstacle detection techniques, at each phase of obstacle detection process, various techniques are applied, still there are many issues and challenges in this field that needs to be addressed. Future research directions have been identified for monocular vision based approach and ground plane detection phases of obstacle detection process. The following research directions have been identified from the existing literature [Ulrich et al. [2]; Michels et al. [6]; Yamaguchi et al. [3]; Song et al. [7]; Zhan et al. [8]; Muller et al. [9]; Viet et al. [10]; Lin et al. [11]; Cherubini et al. [12]; Lim et al. [13]; Mishra et al. [14];
Lalonde et al. [15]; Lin et al. [16]; Jia et al. [17]; Kang et al. [18]] of monocular vision based approach.
-
• Monocular vision based approach must work properly if the obstacles are present inside the trapezoidal reference area.
-
• Obstacles less than 5m away must be detected and avoided, preventing the car crash.
-
• Stationary objects present on road must be detected.
-
• Region detection accuracy must be improved.
-
• Outperformance when grid size is too large or too small, performing only when ground is flat, detecting the over changing obstacles are open research issues.
-
• Based on existing research, we found that tracking pedestrian in close proximity to car and detection of head of pedestrian are open research issues.
-
• Training set should represent real population as learning algorithm can only model variations presented in training set.
-
• Visual occlusions provoked by obstacles must be considered.
-
• Tracking pedestrian those who have recently entered in image frame is also found to be an open research issue.
-
• Interaction between detection and tracking must be considered.
-
• Further research when surface is plain and doesn’t have distinguishing feature is an open research issue.
-
• Disparity for given camera displacement must be considered automatically.
-
• Too many miss detections and mismatched feature points in obstacle region may fail the system.
-
• Far away objects are considered as no obstacles.
-
• Detecting collision in region where the accurate motion vector is not easily computed like walls, doors is also found to be an open issue.
-
• Developing the system working at driving speed more than 30 km/hr and increasing the detectable distance beyond 6 metres are also found to be an open research issues.
The following research directions have been identified from the existing literature [Zhou et al. [27]; Conrad et al. [28]; Jamal et al. [29]; Lin et al. [30]; Benenson et al. [31]; Molineros et al. [32]; Panahandeh et al. [33]; Koester et al. [34]; Knorr et al. [35]] of ground plane detection.
-
• Considering the objects that are very close and occupies large portion of the image is an open research issue.
-
• Handling noise in the point’s correspondence.
-
• Guiding a robot is found to be an open research issue.
-
• Multiple plane detection for indoor navigation.
-
• Extending the system to detect ground plane when
colour of the path is not uniform.
-
• Increasing the resolution of the image to distin
guish very far away objects is also found to be an open research issue.
-
• Avoiding obstacles in blind zone by increasing the
view angle.
-
• We found that considering horizontal gradient and
quantization is also an open research issue.
-
• Improvement in arbitrary pose detections is still
needed.
-
• More degree of freedom is required.
-
• Improvement of virtual plane detection and
ground features located around edges is needed.
-
• Recognising large parts of ground section.
-
• Identification of more distant points and very
small obstacles is also an open research issue.
Appendix 1: Acronyms
SURF
Speeded up Robust Features
SIFT
Scale Invariant Feature Transform
FoS
Focus of Study
RADAR
Radio Detection and Ranging
LIDAR
Light Detection and Ranging
SONAR
Sound Navigation and Ranging
LBP
Local Binary Patterns
GLCM
Grey Level Co-occurrence Matrix
PPS
Pixel Pair Spacing
CDH
Colour Difference Histogram
DRLBP
Distinctive Robust Local Binary Pattern
DRLTP
Distinctive Robust Local Ternary Pattern
SLAM
Simultaneous Localization and Mapping
ISA
Independent Subspace Analysis
RLBP
Robust Local Binary Patterns
EM
Expectation Maximization
GMM
Gaussian Matrix Model
IMU
Inertial Measurement Unit
MST
Minimum Spanning Tree
PCA
Principal Component Analysis
EKF
Extended Kalman Filter
-
Acknowledgment
We would like to thank all the anonymous reviewers for their valuable comments and suggestions for improving the paper.
Список литературы Obstacle Detection Techniques in Outdoor Environment: Process, Study and Analysis
- N. B. Romdhane, M. Hammami and H. B. Abdallah, “A generic obstacle detection method for collision avoidance,” IEEE Intelligent Vehicles Symposium (IV), pp. 491–496, 2011.
- I. Ulrich and I. Nourbakhsh, “Appearance-based obstacle detection with monocular color vision,” AAAI/IAAI, 2000.
- K. Yamaguchi, T. Kato and Y. Ninomiya, “Moving Obsta-cle Detection using Monocular Vision,” In IEEE Intelligent Vehicles Symposium, pp. 288–293, 2006.
- D. G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004.
- H. Bay, T. Tuytelaars and L. Van Gool, “Surf: Speeded up robust features,” Comput. Vision–ECCV, pp. 404-417, 2006.
- J. Michels, A. Saxena and A. Y. Ng, “High speed obstacle avoidance using monocular vision and reinforcement learning,” In Proceedings of the 22nd International Con-ference on Machine Learning, pp. 593-600, 2005.
- G. Y. Song, K. Y. Lee and J. W. Lee, “Vehicle detection by edge-based candidate generation and appearance-based classification,” In IEEE Intelligent Vehicles Symposium, pp. 428–433, 2008.
- Q. Zhan, S. Huang and J. Wu, “Automatic navigation for a mobile robot with monocular vision,” IEEE Conference on Robotics, Automation and Mechatronics, pp. 1005–1010, 2008.
- G. Ma, D. Muller, S. B. Park, S. M. Schneiders and A. Kummert, “Pedestrian detection using a single-monochrome camera,” IET Intelligent Transport Systems, vol. 3, no. 1, pp. 42–56, 2009.
- C. Viet and I. Marshall, “An efficient obstacle detection algorithm using colour and texture,” World Academy of Science, Engineering and Technology, pp. 132–137, 2009.
- C.C. Lin and M. Wolf, “Detecting Moving Objects Using a Camera on a Moving Platform,” 20th International Con-ference on Pattern Recognition, pp. 460–463, 2010.
- A. Cherubini and F. Chaumette, “Visual navigation with obstacle avoidance,” IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 1593–1598, 2011.
- J. Lim and W. Kim, “Detecting and tracking of multiple pedestrians using motion, color information and the Ada-Boost algorithm,” Multimedia Tools and Applications, vol. 65, no. 1, pp. 161–179, 2012.
- P. Mishra, T. U. Vivek, G. Adithya and J. K. Kishore, “Vision based in-motion detection of dynamic obstacles for autonomous robot navigation,” In Annual IEEE India Conference (INDICON), pp. 149–154, Dec. 2012.
- J. Lalonde, R. Laganiere and L. Martel, “Single-view ob-stacle detection for smart back-up camera systems,” IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1–8, 2012.
- Y. Lin, C. Lin, W. Liu and L. Chen, “A vision-based ob-stacle detection system for parking assistance,” 8th IEEE Conference on Industrial Electronics and Applications (ICIEA), pp. 1627–1630, 2013.
- B. Jia, L. Rui and Z. Ming, "Real-time obstacle detection with motion features using monocular vision", The Visual Computer, pp. 1-13, 2014.
- Mun-Cheon Kang, Sung-HoChae, Jee-Young son, Jin-Woo Yoo and Sung-Jeako,” A novel Obstacle Detection Method based on Deformable Grid for the Visually Impaired,” IEEE Transactions on Consumer Electronics, vol. 61, no. 3, pp. 376-383, 2015.
- Y Zhuang, Y Rui, T.S Huang and S Mehrotra, “ Adaptive key-frame extraction using unsupervised clustering”, Pro-ceedings of International conference on Image Processing, pp. 866-870, 1998.
- Li Zhao, Wei Qi, Stan Z. Li, Shi-Qiang Yang, H. J. Zhang, “Key-frame extraction and shot retrieval using nearest fea-ture line”,Proceedings of ACM Workshop on Multimedia, pp. 217- 220, 2000.
- A.D. Doulamis, N.D. Doulamis, S.D. Kollias, “A fuzzy video content representation for video summarization and content based retrieval”, Journal of signal processing, pp.1049-1060, 2000.
- Y Gong and X Liu, “Video summarization using singular value decomposition”, Proceedings of Computer Vision and Pattern Recognition, pp. 347-358, 2000.
- D.P. Mukherjee, S.K. Das, S. Saha, “Key-frame estimation in video using randomness measure of feature point pattern”, IEEE transactions on circuits on systems for video technology, vol.7, no.5, pp. 612-620, 2007.
- Li Liu, Ling Shao, Peter Rockett, “Boosted key-frame and correlated pyramidal motion feature representation for human action recognition”, Pattern Recognition, pp. 1810-1818, 2013.
- Suresh C Raikwar, Charul Bhatnagar and Anand Singh Jalal, “A frame work for key-frame extraction from sur-veillance Video”, 5th International Conference on Computer and Communication Technology”, IEEE, pp. 297-300, 2014.
- Sheena C V, N.K. Narayanan, “ Key- Frame extraction by analysis of histograms of video frames using stastical method”, 4th International Conference on Eco-Friendly Computing and Communication Systems, Procedia Com-puter Science pp. 36-40, 2015.
- J. Zhou and B. Li, “Homography-based ground detection for a mobile robot platform using a single camera,” In Proceedings of IEEE International Conference on Robotics and Automation(ICRA), pp. 4100–4105, 2006.
- D. Conrad and G. DeSouza, “Homography-based ground plane detection for mobile robot navigation using a modified em algorithm,” IEEE International Conference on Robotics and Automation (ICRA), pp. 910–915, 2010.
- A. Jamal, P. Mishra, S. Rakshit, A. K. Singh and M. Kumar, “Real-time ground plane segmentation and obstacle detection for mobile robot navigation,” IEEE 49 Interna-tional Conference on Emerging Trends in Robotics and Communication Technologies (INTERACT), pp. 314–317, 2010.
- C. Lin, S. Jiang, Y. Pu and K. Song, “Robust ground plane detection for obstacle avoidance of mobile robots using a monocular camera,” IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS), pp. 3706–3711, 2010.
- R. Benenson, M. Mathias, R. Timofte and L. V. Gool, “Fast stixel computation for fast pedestrian detection,” In Workshops and Demonstrations Computer Vision–ECCV, pp. 11–20, 2012.
- J. Molineros, S. Cheng, Y. Owechko, D. Levi and W. Zhang, “Monocular rear-view obstacle detection using re-sidual flow,” In Workshops and Demonstrations Computer Vision–ECCV, pp. 504-514, 2012.
- G. Panahandeh, N. Mohammadiha and M. Jansson, “Ground plane feature detection in mobile vision-aided in-ertial navigation,” IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3607–3611, 2012.
- D. Koester, B. Schauerte and R. Stiefelhagen, “Accessible section detection for visual guidance,” IEEE International Conference on Multimedia and Expo Workshops (ICMEW), pp. 1-6, 2013.
- M. Knorr, W. Niehsen and C. Stiller, "Robust ground plane induced homography estimation for wide angle fisheye cameras", In Proceedings of IEEE Intelligent Vehicles Symposium, pp. 1288-1293, 2014.
- G. Zhao and M. Pietikainen, “Dynamic texture recognition using local binary patterns with an application to facial ex-pressions,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 6, pp. 915–928, 2007.
- R. Nosaka, Y. Ohkawa and K. Fukui, “Feature extraction based on co-occurrence of adjacent local binary patterns,” Advances in Image and Video Technology, pp. 82–91, 2012.
- G. Beliakov, S. James and L. Troiano, “Texture recognition by using GLCM and various aggregation functions,” IEEE International Conference on Fuzzy Systems, pp. 1472-1476, 2008
- A. Datta, S. Dutta, S. K. Pal, R. Sen and S. Mukhopadhyay, “Texture Analysis of Turned Surface Images Using Grey Level Co-Occurrence Technique,” Advanced Materials Research, pp. 38–43, 2012.
- M. M. Ali, M. B. Fayek and E. E. Hemayed, “Human-inspired features for natural scene classification,” Pattern Recognition Letters., vol. 34, no. 13, pp. 1525–1530, 2013.
- G.-H. Liu and J. Y. Yang, “Content-based image retrieval using color difference histogram,” Pattern Recognition, vol. 46, no. 1, pp. 188–198, 2013.
- J. Ren, X. Jiang and J. Yuan, “Dynamic texture recognition using enhanced lbp features,” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 2400-2404, 2013.
- J. Zou, C.-C. Liu, Y. Zhang and G.-F. Lu, “Object recogni-tion using Gabor co-occurrence similarity,” Pattern Recognition, vol. 46, no. 1, pp. 434–448, 2013.
- P. Gehler and S. Nowozin, “On feature combination for multiclass object classification,” IEEE 12th International Conference on Computer Vision, pp. 221–228, 2009.
- B. Zitova, J. Flusser, J. Kautsky and G. Peters, “Feature point detection in multiframe images,” In Czech Pattern Recognition Workshop, no. 3, pp. 117–122, 2000.
- P. Saisan, G. Doretto, Y. N. Wu and S. Soatto, “Dynamic Texture Recognition,” In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2001.
- F. Woolfe and A. Fitzgibbon, “Shift-invariant dynamic texture recognition,” In Computer Vision–ECCV, pp. 549–562, 2006.
- A. Satpathy, X. Jiang and H.L. Eng,” LBP-Based Edge- Texture Features for Object Recognition,” IEEE Transac-tions on Image Processing, vol. 23, no. 5, pp. 1953-1964, 2014.
- Z. Zhang, Y. Huang, C. Li and Y. Kang, “Monocular vision simultaneous localization and mapping using SURF,” IEEE 7th World Conference on Intelligent Control and Au-tomation (WCICA), pp. 1651–1656, 2008.
- C. H. Lampert, H. Nickisch and S. Harmeling, “Learning to detect unseen object classes by between-class attribute transfer,” IEEE Conference on Computer Vision and Pat-tern Recognition(CVPR), pp. 951–958, 2009.
- D. Ta, W. Chen, N. Gelfand and K. Pulli, “SURFTrac: Efficient tracking and continuous object recognition using local feature descriptors,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2937–2944, 2009.
- G. Yu and J. Morel, “A fully affine invariant image com-parison method,” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 1597–1600, 2009.
- B. Besbes, A. Rogozan and A. Bensrhair, “Pedestrian recognition based on hierarchical codebook of SURF fea-tures in visible and infrared images,” In IEEE Intelligent Vehicles Symposium (IV), pp. 156–161, 2010.
- K. E. A. Sande, T. Gevers and C. G. M. Snoek, “Evaluating color descriptors for object and scene recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1582–1596, 2010.
- Q. V. Le, W. Y. Zou, S. Y. Yeung and A. Y. Ng, “Learn-ing hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3361–3368, 2011.
- Y. Pang, W. Li, Y. Yuan and J. Pan, “Fully affine invariant SURF for image matching,” Neurocomputing, vol. 85, pp. 6–10, 2012.
- Y.-T. Wang, C.-H. Sun and M.-J. Chiou, “Detection of moving objects in image plane for robot navigation using monocular vision,” EURASIP Journal on Advances in Sig-nal Processing, pp. 1-22, 2012.
- Y. Yu, K. Huang, W. Chen and T. Tan, “A novel algorithm for view and illumination invariant image matching,” IEEE Transactions on Image Processing, vol. 21, no. 1, pp. 229–40, 2012.
